第96讲:MySQL高可用集群MHA的核心概念以及集群搭建
文章目录
- 1.MHA高可用数据库集群的核心概念
- 1.1.主从复制架构的演变
- 1.2.MHA简介以及架构
- 1.3.MHA的软件结构
- 1.4.MHA Manager组件的启动过程
- 1.5.MHA高可用集群的原理
- 2.搭建MHA高可用数据库集群
- 2.1.环境架构简介
- 2.2.搭建基于GTID的主从复制集群
- 2.2.1.在三台服务器中分别搭建MySQL实例
- 2.2.2.配置基于GTID的主从复制集群
- 2.2.3.查看集群各节点的状态
- 2.3.部署MHA高可用集群
- 2.3.1.配置三个MySQL服务器之间可信
- 2.3.2.所有MySQL节点安装MHA Node软件依赖包
- 2.3.3.在主库上创建MHA高可用需要的用户
- 2.3.4.安装MHA Manager组件
- 2.3.5.配置MHA
- 2.3.6.检测MHA与数据库节点的连接线
- 2.3.7.启动MHA
- 2.3.8.查看MHA的状态
- 3.MHA配置文件详解
1.MHA高可用数据库集群的核心概念
1.1.主从复制架构的演变
在MySQL集群模式的过程中,演变出了很多类的集群,分为以下几种:
1)基础主从
在基础主从中不需要依赖于其他任何的软件,MySQL自身就可以实现的集群模式。
常见的有一主一从、一主多从、多级主从(级联主从,A库复制给B库,B库再复制给C/D/E多库)、双主、环状主从、多主依从。
其中一主一从、一主多从、多级主从是企业中最常用的方案,当然有钱的还会用RDS。
双主模式在高可用环境、分布式架构中会用到。
环状、多主依从几乎不会用,环状指的是A复制B,B复制C,C复制A。
2)高性能架构
实际上一主多从架构不会直接在企业中使用,因为程序只会去连接主库,从库相当于只是在备份主库的数据,毫无意义而言,还浪费资源,基于这种场景,相继推出了高性能架构。
所谓的高性能架构就是我们熟知的读写分离架构,释放主库的读操作,在业务场景,很多的情况下都是读操作,写数据的场景一般很少,有了读写分离结构,所有的读操作就会通过中间件路由到从库上,所有的写操作通过中间件路由到主库上。
读写分离是通过第三方中间件实现的,通过路由机制分发读写操作,企业中用的非常多。
常见的读写分离中间件有:mysql-proxy、atlas、mysqlrouter、proxysql、maxscale、mycat。
3)高可用架构
即使有了读写分离架构,其实也不能保证高可用常见,当主库坏了,从库依旧是从库,不会成为一个主库,接替主库的工作,就会影响全年的宕机率。
为了保证业务高可用,全年0宕机率,高可用环境是必不可少的环节。
常见的高可用架构产品有三类:负载均衡类(lvs、f5、nginx)、主备系统(ka、ha、powerha、mc_sc、mha、mmm)、多活系统(pxc、mgc、mysql cluster、innodb cluster)。
主备系统有切换过程,大概几十秒,因此不能说是准全年0宕机率。
4)分布式架构
分布式架构是未来互联网发展的趋势所在,常见的分布式软件有没有餐厅和dble。
newsql也是未来的趋势。
1.2.MHA简介以及架构
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
mha官网:https://code.google.com/archive/p/mysql-master-ha/
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
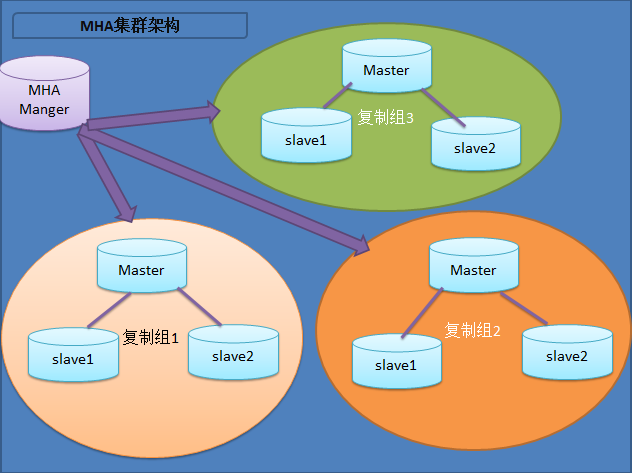
MHA的架构图
MHA可以同时对多组主从复制集群实现高可用架构,首先需要在所有的MySQL服务器中安装MHA Node组件,然后再部署一个MHA Manger管理组件,通过Manger管理组件去维护主从复制集群的高可用性。
使用MHA的前提需要准备至少三台数据库服务器,一主两从的主从复制集群,一台充当主库,一台主从备用主库,另外一台充当从库。
1.3.MHA的软件结构
Manger组件主要包括以下几个工具包:
| 名称 | 功能 |
|---|---|
| masterha_manger | 启动MHA |
| masterha_check_ssh | 检查MHA的SSH配置状况 |
| masterha_check_repl | 检查MySQL复制状况 |
| masterha_master_monitor | 检测master是否宕机 |
| masterha_check_status | 检测当前MHA运行状态 |
| masterha_master_switch | 控制故障转移(自动或者手动) |
| masterha_conf_host | 添加或删除配置的server信息 |
Node组件主要包含以下几个工具包:
| 名称 | 功能 |
|---|---|
| save_binary_logs | 保存和复制master的二进制日志 |
| apply_diff_relay_logs | 识别差异的中继日志事件并将其差异的事件应用于其他的 |
| purge_relay_logs | 清除中继日志(不会阻塞SQL线程) |
1.4.MHA Manager组件的启动过程
Manager组件的启动过程:
- 1)首先读取
--conf=/data/mha/app1.cnf参数指定的MHA的配置文件,获取到主从复制集群主库和从库的相关信息。 - 2)然后调用
masterha_check_ssh这个脚本,通过配置文件中指定的ssh_user=root参数,进行互信检查。 - 3)然后调用
masterha_check_repl这个脚本,检查主从复制的状态。 - 4)一切准备就绪后,MHA启动成功。
1.5.MHA高可用集群的原理
MHA高可用集群的原理:
在MySQL的每台服务器中都会安装Node组件,MHA的Manager组件会通过masterha_master_monitor脚本,根据配置文件中的ping_interval参数间隔性的持续健康主库的运行状态,包括网络层面以及主库的状态,主库的状态通过我们指定的数据库用户来进行监控,一旦检测到master主库故障时,Manger组件会选举出集群中的某个从库,将这个从库提升为主库,然后剩余的从库去复制这个新主库的,重新生成一个高可用集群。
Manager组件选举新主库的过程:
Manager组件选举新主库有三种算法:
- 当主库故障后,如果配置文件中有声明哪个节点强制为主库,该节点会强制提升为新的主库。
- 当主库故障后,判断剩余从库谁的数据最新(根据Position或者GTID来判断),谁复制主库的数据最多,最多的节点提升为新主库。
- 当主库故障后,如果剩余从库的Position或者GTID都一一致,也就意味着剩余从库复制的数据都一样多,那么此时就会根据配置文件中的书写顺序,从上到下,最上面的那个节点会成为新主库。
选举过程中还有一个小细节:
1)默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
2)如果某个从库的check_repl_delay=0,即使落后很多日志,也强制选择其为备选主
新主库上任后数据处理过程:
当主库故障,新主库上任后,所有的库都会去判断故障主库的SSH连通性,如果能连接上主库,此时所有的从库就会去截取从库上没有,但是主库上有的数据,然后保存到各自的本地,避免数据丢失。
当主库故障后,通过SSH连通性,发现连不上主库,此时会进行一个数据补偿,其实就是将剩下的多个从库的数据同步成一致的,因为多个从库和主库复制的数据多多少少有差距,数据量最多的会成为新主库,数据库最少的会去复制新主库,数据补偿就是为了将剩下的这些库的数据量变成一致的。
- 在传统模式下,数据补偿是通过
apply_diff_relay_logs脚本计算新主库和从库的relay-log差异,需要通过内容进行复杂的对比,最终保证数据的统一。 - 在GTID模式下,数据补偿是通过
apply_diff_relay_logs脚本计算新主库和从库的relay-log差异,但是只需要比对GTID号即可,效率更高,因此建议MHA环境下,采用GTID的复制模式。
在主库故障,通过Manage组件自动切换过程中,Manager组件会试图从故障的主库服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的,当主库故障宕机后,主库中的二进制日志就没法保存了,针对这种情况,我们可以提供一台Binlog Server服务器,当主库宕机不可连接时,通过Binlog Server去保存二进制日志,最大程度上减少数据丢失。
MHA高可用切换的完整过程:
1)当Manager组件检测到主库故障时,就触发选举过程。
2)根据算法选举出某个从库作为主从复制集群的新主库,此时所有的从库,包括已经成为新主库的从库,都会去探测故障主库的连通性。
3)如果能连上故障主库,则截取从库与主库差异部分的Binlog,然后进行数据同步,避免数据丢失。
4)如果连不上故障主库,则进行数据补偿,使所有的从库包括新主库的数据统一。
5)解除成为新主库的从库身份,剩余的所有从库与新主库建立主从复制关系。
6)在MHA的配置文件中移除故障的节点。
7)Manager组件故障迁移工作完成,会自杀。
MHA的工作方式是一次性的,当完成一次故障切换后,就会自动停止运行,此时就需要DBA再次运行起来MHA,否则下次故障时,就不能达到高可用的效果了。
2.搭建MHA高可用数据库集群
本次搭建一个基础的MHA,企业级功能在后面的文章中讲解。
2.1.环境架构简介
由三台服务器组成的基于GTID的主从复制集群,集群架构为一主两从,最后通过MHA形成高可用的数据库集群。
| IP | 主机名 | 主从复制角色 | 端口号 | 组件 |
|---|---|---|---|---|
| 192.168.20.11 | mysql-1 | master | 3306 | mysql |
| 192.168.20.12 | mysql-2 | slave | 3306 | mysql |
| 192.168.20.13 | mysql-3 | slave | 3305 | mysql、mha |
2.2.搭建基于GTID的主从复制集群
公司很多场景下都是使用的传统主从复制集群,本次我们可以使用基于GTID复制的主从复制集群,搭建更加简单,并且GTIT模式的主从复制集群,能够实现主库并发传输Binlog日志到从库的特性,并且针对从库的SQL线程也可以实现SQL多线程的并行执行Binlog的特性。
#基于GTID的主从复制集群,每个节点的配置文件中一定要配置上这三行参数
gtid-mode=on #开启gpit功能
enforce-gtid-consistency=true #保证主从复制集群模式下,强制GTID的一致性
log-slave-updates=1 #强制刷新从库的二进制日志
2.2.1.在三台服务器中分别搭建MySQL实例
首先在三台服务器中分别搭建单节点的MySQL实例,然后再配置成主从复制集群。
每个节点的部署方式一模一样,只是配置文件有所不同。
1)mysql-1节点部署MySQL的具体步骤一直配置文件内容如下:
1.解压MySQL二进制包
[root@mysql-1 ~]# tar xf mysql-5.7.36-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
[root@mysql-1 ~]# mv /usr/local/mysql-5.7.36-linux-glibc2.12-x86_64 /usr/local/mysql2.设置MySQL的环境变量
[root@mysql-1 ~]# vim /etc/profile
export MYSQL_HOME=/usr/local/mysql
export PATH=$MYSQL_HOME/bin:$PATH
export LD_LIBRARY_PATH=:/usr/local/mysql/lib3.将mysql、mysqlbinlog命令设置一份超链接到/usr/bin目录(mha会用到这两个命令,但是不会识别我们配置的系统变量)
#在开发的时候将这两个命令写成了绝对路径,必须要改。
[root@mysql-1 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@mysql-1 ~]# ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql4.创建mysql用户
[root@mysql-1 ~]# groupadd -r mysql
[root@mysql-1 ~]# useradd -M -r -s /sbin/nologin -g mysql mysql4.准备数据目录
[root@mysql-1 ~]# mkdir /data/mysql
[root@mysql-1 ~]# chown -R mysql. /data/mysql5.初始化数据库
[root@mysql-1 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/mysql6.准备mysql配置文件
[root@mysql-1 ~]# vim /etc/my.cnf
[mysqld]
user=mysql
port=3306
server_id=1 #每个MySQL数据库的server_id都设置成不同的
basedir=/usr/local/mysql
datadir=/data/mysql
log_bin=mysql-bin
gtid-mode=on #开启gpit功能
enforce-gtid-consistency=true #保证主从复制集群模式下,强制GTID的一致性
log-slave-updates=1 #强制刷新从库的二进制日志
socket=/tmp/mysql.sock
log_error=/data/mysql/mysql_err.log
character-set-server=utf8[mysql]
socket=/tmp/mysql.sock7.准备服务管理脚本
[root@mysql-1 ~]# vim /etc/systemd/system/mysqld.service
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 50008.启动数据库
[root@mysql-1 ~]# systemctl daemon-reload
[root@mysql-1 ~]# systemctl start mysqld9.设置root密码
[root@mysql-1 ~]# mysqladmin -u root -P 3306 password '123456'10.登陆数据库
[root@mysql-1 ~]# mysql -uroot -p123456
mysql>
2)mysql-2节点的配置文件内容
[root@mysql-2 ~]# vim /etc/my.cnf
[mysqld]
user=mysql
port=3306
server_id=2 #每个MySQL数据库的server_id都设置成不同的
basedir=/usr/local/mysql
datadir=/data/mysql
log_bin=mysql-bin
gtid-mode=on #开启gpit功能
enforce-gtid-consistency=true #保证主从复制集群模式下,强制GTID的一致性
log-slave-updates=1 #强制刷新从库的二进制日志
socket=/tmp/mysql.sock
log_error=/data/mysql/mysql_err.log
character-set-server=utf8[mysql]
socket=/tmp/mysql.sock
3)mysql-3节点的配置文件内容
[root@mysql-2 ~]# vim /etc/my.cnf
[mysqld]
user=mysql
port=3306
server_id=3 #每个MySQL数据库的server_id都设置成不同的
basedir=/usr/local/mysql
datadir=/data/mysql
log_bin=mysql-bin
gtid-mode=on #开启gpit功能
enforce-gtid-consistency=true #保证主从复制集群模式下,强制GTID的一致性
log-slave-updates=1 #强制刷新从库的二进制日志
socket=/tmp/mysql.sock
log_error=/data/mysql/mysql_err.log
character-set-server=utf8[mysql]
socket=/tmp/mysql.sock
2.2.2.配置基于GTID的主从复制集群
1)主库创建复制用户
mysql> grant replication slave on *.* to replicas@'192.168.20.%' identified by '123456';
2)配置从库连接主库
基于GTID的主从复制集群,如果是新的集群,可以不用再备份数据,然后还原到从库,可以直接填写要从主库的第一个GTID处开始复制,当然如果你的主库时运行很久的数据库,需要备份数据还原到从库,否则之前数据库的所有数据肯定不在Binlog了,会导旧数据无法同步到从库。
本次就不备份了,全新的主从复制集群,直接指向主库的第一个GTID号开始复制数据,下面直接来配置从库连接主库。
#mysql-2第一个从库的配置
[root@mysql-2 ~]# mysql -uroot -p123456
mysql> CHANGE MASTER TOMASTER_HOST='192.168.20.11',MASTER_USER='replicas',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_AUTO_POSITION=1;
mysql> start slave;#mysql-3第二个从库的配置
[root@mysql-3 ~]# mysql -uroot -p123456
mysql> CHANGE MASTER TOMASTER_HOST='192.168.20.11',MASTER_USER='replicas',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_AUTO_POSITION=1;
mysql> start slave;
基于GTID的主从和传统的主从配置方面的差别:只是获取主库Binlog的方式不同,GTID的主从通过 MASTER_AUTO_POSITION=1参数读取到主库第一个GTID号,从第一个GTID号处开始复制数据,传统的主从是指定主库正在使用的binlog以及开始标识位号。
#GTID的主从
mysql> CHANGE MASTER TOMASTER_HOST='192.168.20.11',MASTER_USER='replicas',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_AUTO_POSITION=1;
mysql> start slave;#传统的主从
mysql> CHANGE MASTER TOMASTER_HOST='192.168.20.11',MASTER_USER='replicas',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=452,MASTER_CONNECT_RETRY=10;
2.2.3.查看集群各节点的状态
基于GTID模式的主从复制集群已经搭建完毕,下面我们来查看三个节点各自的状态。
show master status\G;
show slave status\G;
两个从库的线程都是Yes状态。

2.3.部署MHA高可用集群
2.3.1.配置三个MySQL服务器之间可信
MHA在主备切换时,需要拷贝备用master与主master缺失的数据,因此所有节点需要与MHA主机建立免密登陆。
ssh-keygen
ssh-copy-id -i /root/.ssh/id_rsa.pub root@数据库地址#三台服务器互相指
2.3.2.所有MySQL节点安装MHA Node软件依赖包
所有的MySQL节点都需要去安装这个Node软件包。
yum install perl-DBD-MySQL ncftp -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
2.3.3.在主库上创建MHA高可用需要的用户
MHA需要通过主从复制集群中的一个用户,监控主从节点的状态,主库创建即可,会同步到从库。
mysql> grant all privileges on *.* to mha@'192.168.20.%' identified by '123456';
2.3.4.安装MHA Manager组件
在mysql-1节点中搭建Manager组件即可,在企业生产环境中为了避免主从节点宕机,导致MHA不可用,一mysq般都会将MHA安装到主从复制集群之外,在学习环境中搭建在哪里都可以,另外也建议搭建在最后一个从库mysql-3中,因为主库mysql-1宕机就会导致MHA失去作用,当mysql-1宕了,mysql-2可能会成为新的主库,因此建议将MHA装载mysql-3中。
[root@mysql-3 ~]# yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
[root@mysql-3 ~]# rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
2.3.5.配置MHA
1.创建MHA目录
[root@mysql-1 ~]# mkdir /data/mha2.创建MHA日志目录
[root@mysql-1 ~]# mkdir /data/mha/logs3.编写MHA配置文件
[root@mysql-1 ~]# vim /data/mha/app1.cnf
[server default] #默认全局配置
manager_log=/data/mha/logs/manager.log #MHA主备切换的日志路径
manager_workdir=/data/mha #MHA的工作目录
master_binlog_dir=/data/mysql #设置Master主库保存Binlog的路径,以便MHA找到Master的Binloguser=mha #设置MHA监控用户和密码
password=123456
ping_interval=2 #设置监控主库发送ping包的时间间隔,默认3秒
repl_user=replicas #主从复制的用户账号和密码
repl_password=123456
ssh_user=root #ssh登陆的用户名#下面的就是关于MySQL各节点的信息配置了,默认情况下从上到进行主备切换,按照主从从的顺序填写
[server1]
hostname=192.168.20.11 #实例地址
port=3306 #端口号[server2]
hostname=192.168.20.12
port=3306[server3]
hostname=192.168.20.13
port=3306
2.3.6.检测MHA与数据库节点的连接线
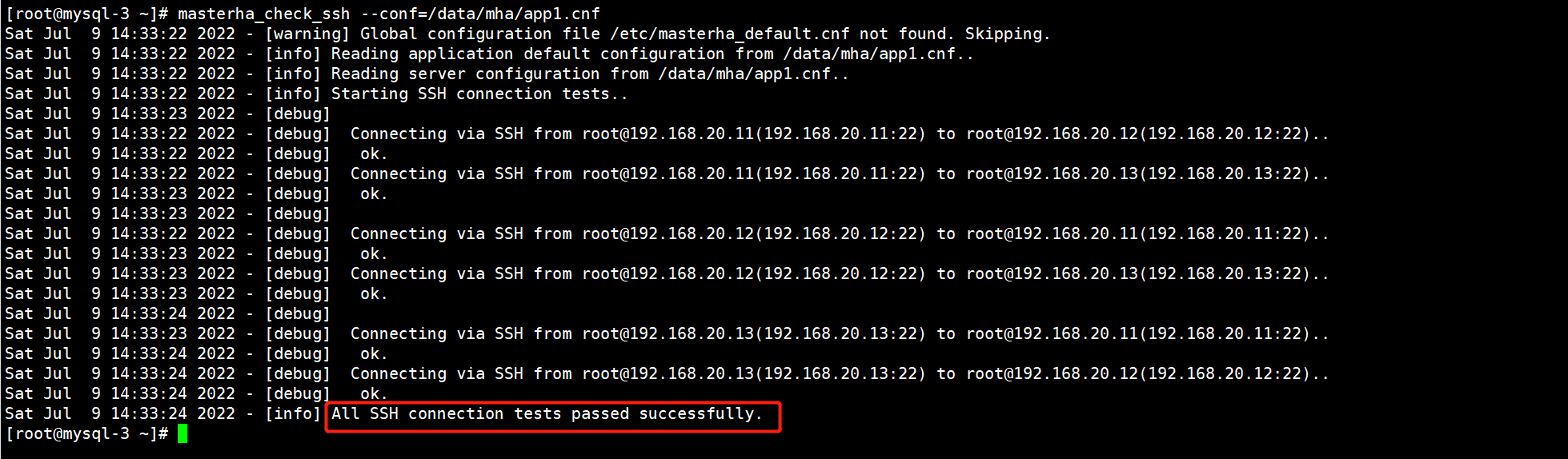
1)检查MHA Manger到所有MHA Node的SSH连接状态
[root@mysql-3 ~]# masterha_check_ssh --conf=/data/mha/app1.cnf
出现这一行表示成功。
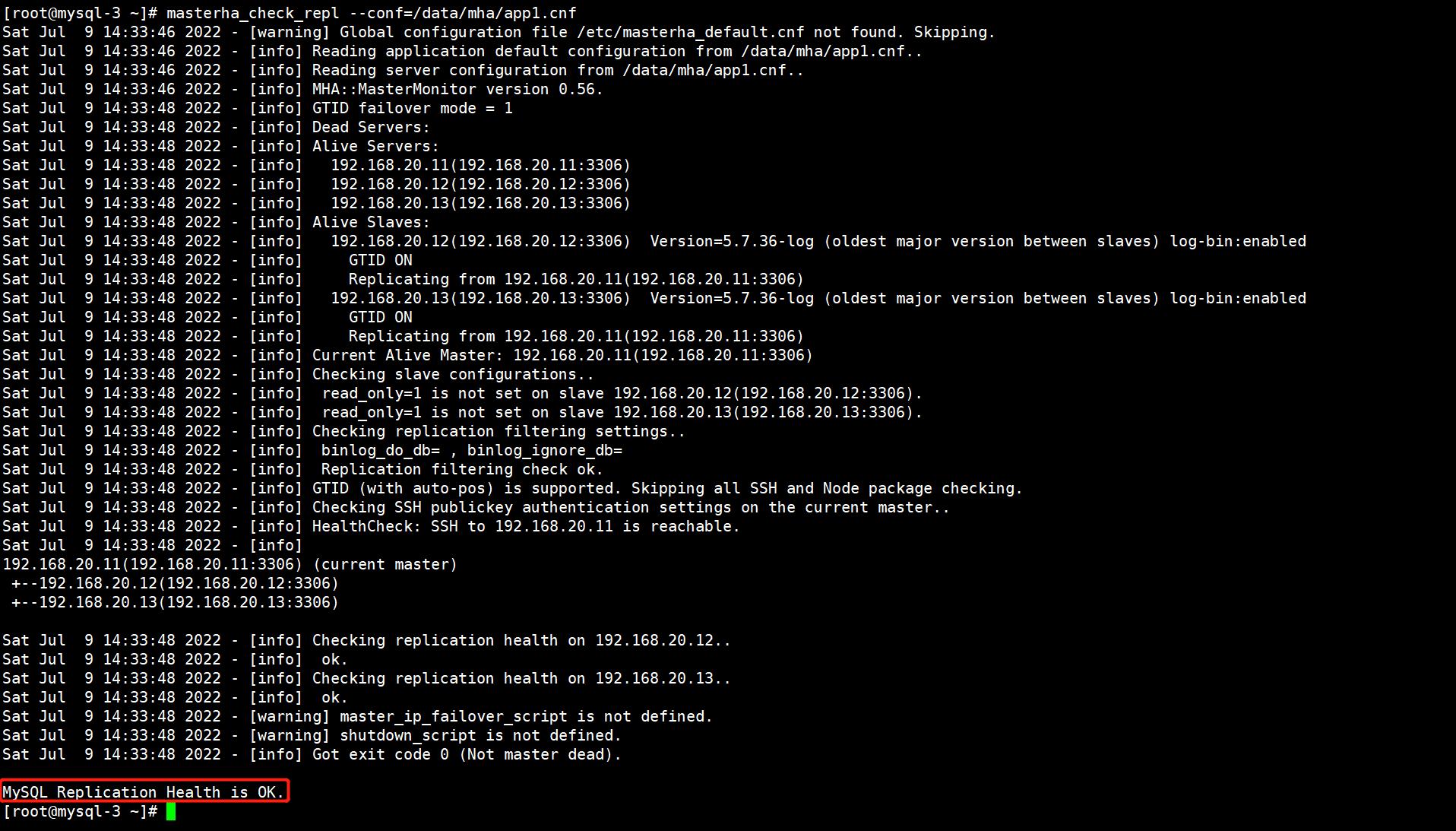
2)通过masterha_check_repl脚本查看整个集群的状态
[root@mysql-3 ~]# masterha_check_repl --conf=/data/mha/app1.cnf
出现这一行就表示MHA搭建完成了。
2.3.7.启动MHA
[root@mysql-3 ~]# nohup masterha_manager --conf=/data/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /data/mha/logs/manager.log 2>&1 &#--conf=:指定MHA配置文件路径。
#--remove_dead_master_conf:当主库宕机后,自动从配置文件中将其移除。
#--ignore_last_failover:忽略故障转移,忽略掉总是宕机不够可靠的机器,在默认情况下,MHA发现某台机器咋8小时内多次宕机,则不会再切换到该主机,我们忽略这项配置,因为测试过程中,肯定会多次切换。
2.3.8.查看MHA的状态
[root@mysql-3 ~]# masterha_check_status --conf=/data/mha/app1.cnf
app1 (pid:10744) is running(0:PING_OK), master:192.168.20.11
3.MHA配置文件详解
[server default] #默认全局配置
manager_log=/data/mha/logs/manager.log #MHA主备切换的日志路径
manager_workdir=/data/mha #MHA的工作目录
master_binlog_dir=/data/mysql #设置Master主库保存Binlog的路径,以便MHA找到Master的Binloguser=mha #设置MHA监控用户和密码
password=123456
ping_interval=2 #设置监控主库发送ping包的时间间隔,默认3秒
repl_user=replicas #主从复制的用户账号和密码
repl_password=123456
ssh_user=root #ssh登陆的用户名master_ip_failover_script=/data/mha/scripts/master_ip_failover #当主库故障后,VIP地址的脚本
report_script=/data/mha/scripts/send #当主库故障后,发送邮件,执行动作#下面的就是关于MySQL各节点的信息配置了,默认情况下从上到进行主备切换,按照主从从的顺序填写
[server1]
hostname=192.168.20.11 #实例地址
port=3306 #端口号[server2]
hostname=192.168.20.12
port=3306
candidate_master=1 #当主库出现故障后,即使该节点不是集群中数据最多的,也强制提升该节点为主库,一般不设置,除非是两地三机房的环境,当A机房的主库挂了,指定B机房的一个从库成为主库
check_repl_delay=0 #默认情况下如果一个slave与master的数据差异在100M,则会跳过强制,还是会选择其他节点,通过此参数可以强强制就选此节点为新主库。[server3]
hostname=192.168.20.13
port=3306
相关文章:
第96讲:MySQL高可用集群MHA的核心概念以及集群搭建
文章目录 1.MHA高可用数据库集群的核心概念1.1.主从复制架构的演变1.2.MHA简介以及架构1.3.MHA的软件结构1.4.MHA Manager组件的启动过程1.5.MHA高可用集群的原理 2.搭建MHA高可用数据库集群2.1.环境架构简介2.2.搭建基于GTID的主从复制集群2.2.1.在三台服务器中分别搭建MySQL实…...

外星人入侵(python)
前言 代码来源《python编程从入门到实践》Eric Matthes 署 袁国忠 译 使用软件:PyCharm Community Editor 2022 目的:记录一下按照书上敲的代码 alien_invasion.py 游戏的一些初始化设置,调用已经封装好的函数方法,一个函数的…...
Unity中开发程序打包发布
添加ESC脚本 使用Unity打包发布的过程中,考虑到打开的程序会处于全屏界面,而此时我们又会有退出全屏的需求,因此需要添加ESC脚本,当我们单击ESC脚本的过程中,退出全屏模式。 在Assets/Scenes下,创建esc.cs…...
2024.2.1日总结
web的运行原理: 用户通过浏览器发送HTTP请求到服务器(网页操作)。web服务器接收到用户特定的HTTP请求,由web服务器请求信息移交给在web服务器中部署的javaweb应用程序(Java程序)。启动javaweb应用程序执行…...

LeetCode解法汇总2670. 找出不同元素数目差数组
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个下…...
STM32目录结构
之前一直头疼的32目录,比51复杂,又没有C规律,也不像python脚本文件关联不强,也不像工整的FPGA工程,编的时候到处放,爆出的错千奇百怪。短暂整理了一个,还是没有理得很轻。 startup_stm32f10x_m…...

算法专题:记忆搜索
参考练习习题总集 文章目录 前置知识练习习题87. 扰乱字符串97. 交错字符串375. 猜数字大小II403. 青蛙过河464. 我能赢吗494. 目标和552. 学生出勤记录II576. 出借的路径数 前置知识 没有什么特别知识,只有一些做题经验。要做这类型的题目,首先写出暴…...

【数据分享】1929-2023年全球站点的逐日最低气温数据(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,其中又以气温指标最为常用!说到气温数据,最详细的气温数据是具体到气象监测站点的气温数据! 之前我们分享过1929-2023年全球气象站…...
)
2024美赛数学建模D题思路+模型+代码+论文(持续更新)
2024美赛数学建模A题B题C题D题E题F题思路模型代码论文:开赛后第一时间更新,获取见文末名片 组队环节: 美赛最多是3个人参赛,一般的队伍都是由三人组成(当然如果你很大佬也可以一个人参赛),队伍…...
dubbo+sentinel最简集成实例
说明 在集成seata后,下面来集成sentinel进行服务链路追踪管理~ 背景 sample-front网关服务已配置好 集成 一、启动sentinel.jar 1、官网下载 选择1:在本地启动 nohup java -Dserver.port8082 -Dcsp.sentinel.dashboard.serverlocalhost:8082 -Dp…...
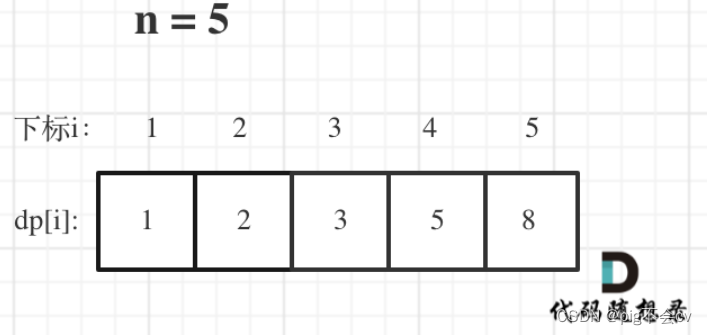
9.2爬楼梯(LC70-E)
算法: 多举几个例子,找规律: 爬到第一层楼梯有一种方法,爬到二层楼梯有两种方法。 那么第一层楼梯再跨两步就到第三层 ,第二层楼梯再跨一步就到第三层(时序)。 所以到第三层楼梯的状态可以由…...

Asp.net移除Server, X-Powered-By, 和X-AspNet-Version头
移除X-AspNet-Version很简单,只需要在Web.config中增加这个配置节: <httpRuntime enableVersionHeader"false" />移除Server在Global.asax文件总增加: //隐藏IIS版本 protected void Application_PreSendRequestHeaders() {HttpContext.Current.Res…...

reactnative 调用原生ui组件
reactnative 调用原生ui组件 1.该样例已textView,介绍。 新建MyTextViewManager 文件,继承SimpleViewManager。import android.graphics.Color; import andr…...

面试手写第五期
文章目录 一. 实现一个函数用来对 URL 的 querystring 进行编码二. 如何实现一个数组洗牌函数 shuffle三. 异步加法的几种方式四. 实现trim函数五. 求多个数组的交集六. 手写实现render函数七. 驼峰转- -转驼峰八. instanceof实现九. 组合问题十. 字符串分组 一. 实现一个函数用…...

【CSS】css选择器和css获取第n个元素(:nth-of-type(n)、:nth-child(n)、first-child和last-child)
:nth-of-type、:nth-child的区别 一、css选择器二、:nth-of-type、:nth-child的区别:nth-of-type(n):选择器匹配属于父元素的特定类型的第N个子元素:nth-child(n):选择器匹配属于其父元素的第 N 个子元素,不论元素的类型:first-child…...
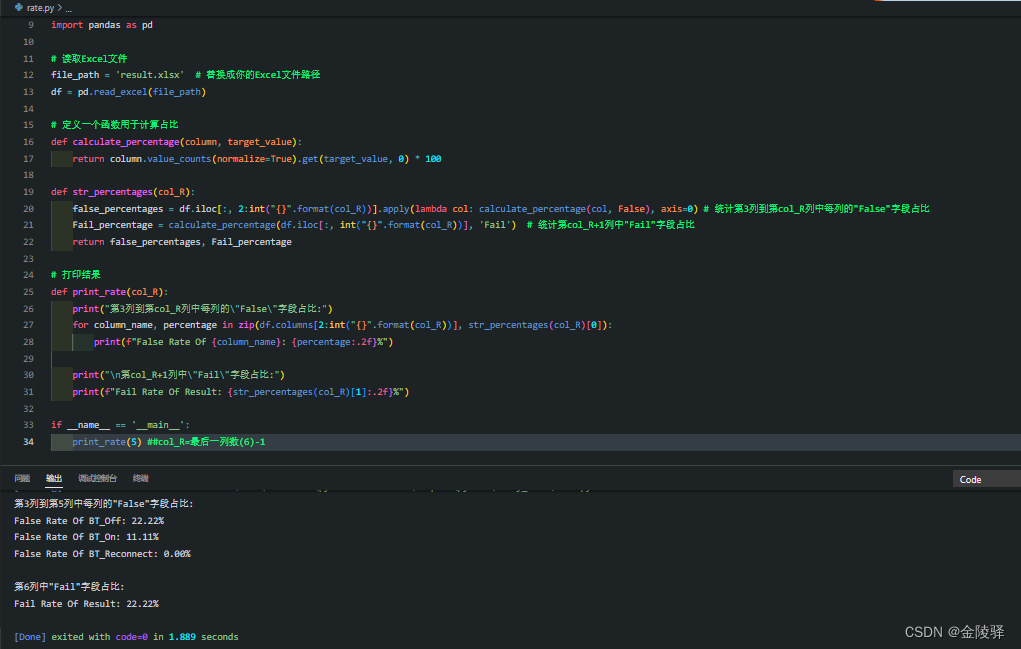
解析Excel文件内容,按每列首行元素名打印出某个字符串的统计占比(超详细)
目录 1.示例: 1.1 实现代码1:列数为常量 运行结果: 1.2 实现代码2:列数为变量 运行结果: 1.示例: 开发需求:读取Excel文件,统计第3列到第5列中每列的"False"字段占…...
qt中遇到[Makfile.Debug:119:debug/app.res.o] Error 1的原因以及解决方法
当我们将项目已到本地qt环境中会出现下图的代码错误 解决方法:在主界面中,点击左边的项目栏,选择构建设置,看Shadow build下面的路径是否为中文,改成英文,或者直接将Shadow build这个 √ 去掉就行了,如图已…...

pytorch调用gpu训练的流程以及示例
首先需要确保系统上安装了CUDA支持的NVIDIA GPU和相应的驱动程序。 基本步骤如下 检查CUDA是否可用: 使用 torch.cuda.is_available() 来检查CUDA是否可用。 指定设备: 可以使用 torch.device(“cuda:0”) 来指定要使用的GPU。如果系统有多个GPU&…...
学习Android的第一天
目录 什么是 Android? Android 官网 Android 应用程序 Android 开发环境搭建 Android 平台架构 Android 应用程序组件 附件组件 Android 第一个程序 HelloWorld 什么是 Android? Android(发音为[ˈnˌdrɔɪd],非官方中文…...

回归预测 | Matlab实现CPO-LSTM【24年新算法】冠豪猪优化长短期记忆神经网络多变量回归预测
回归预测 | Matlab实现CPO-LSTM【24年新算法】冠豪猪优化长短期记忆神经网络多变量回归预测 目录 回归预测 | Matlab实现CPO-LSTM【24年新算法】冠豪猪优化长短期记忆神经网络多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现CPO-LSTM【24年新算…...

QKeyMapper:重新定义Windows输入控制的终极解决方案
QKeyMapper:重新定义Windows输入控制的终极解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠,手…...

防爆控制柜制造:从危险区域适配到电气安全的完整解析
一、什么是防爆控制柜制造?防爆控制柜制造,是指根据化工厂、石油化工、制药车间、喷涂车间、粉尘车间、油漆房、燃气站、危化品仓库、煤化工、粮食加工、木粉加工、新能源材料、电子化学品等存在爆炸性气体、蒸气或粉尘环境的场所需求,对防爆…...

游戏AI如何迁移战略逻辑到现实决策系统
1. 项目概述:当机器开始玩我们的游戏,背后不是炫技,而是逻辑的迁移“当机器开始玩我们的游戏”——这句话乍听像科幻片开场白,但现实中它早已不是新闻。AlphaGo击败李世石那盘棋之后,很多人以为AI下棋只是算法碾压人类…...

验证回文串【双指针、字符串】
力扣:https://leetcode.cn/problems/valid-palindrome/description/?envTypestudy-plan-v2&envIdtop-interview-150 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串…...

解决Claude Code访问不稳定问题并配置Taotoken接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定问题并配置Taotoken接入 Claude Code 是一款强大的 AI 编程助手,但部分开发者在使用过程中可…...

JLink版本不兼容?手把手教你解决APM32F003F6P6在Keil V5.14下的烧写闪退与报错
JLink与Keil版本冲突全解析:APM32F003F6P6烧写难题终极指南 当你深夜加班调试APM32F003F6P6,Keil突然弹出"Error Flash Download failed"然后闪退,JLink软件在你选择芯片型号后直接消失——这种工具链版本冲突带来的"玄学&quo…...

yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化
yt-fts高级配置技巧:数据库路径、Chroma设置与性能优化 【免费下载链接】yt-fts YouTube Full Text Search - Search all of YouTube from the command line 项目地址: https://gitcode.com/gh_mirrors/yt/yt-fts yt-fts是一款强大的YouTube全文搜索工具&…...

终极LDDC歌词工具指南:如何快速获取完美同步的逐字歌词
终极LDDC歌词工具指南:如何快速获取完美同步的逐字歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地…...

论文AI率90%熬夜怎么办?2026年5招实测,一次过知网维普AIGC
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

Agent 系统全景图
This Chapter Solves 你已经学了 7 个独立概念:agent、tool、memory、skill、MCP、hook、planning。这一章把它们串成一张图,让你看清楚这些部件在一个真实系统里是怎么组合在一起的。 In One Sentence 一个完整的 agent 系统 推理核心 工具层 记忆…...