【python接口自动化】- 正则用例参数化
🔥 交流讨论:欢迎加入我们一起学习!
🔥 资源分享:耗时200+小时精选的「软件测试」资料包
🔥 教程推荐:火遍全网的《软件测试》教程
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
前言
我们在做接口自动化的时候,处理接口依赖的相关数据时,通常会使用正则表达式来进行提取相关的数据。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(Regular Expression,在代码中常简写为regex、regexp或RE) 。它是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。而Python 自1.5版本起增加了re模块,它提供 Perl 风格的正则表达式模式。
正则表达式语法
表示单字符
单字符:即表示一个单独的字符,比如匹配数字用\d,匹配非数字用\D。
除以下语法,也可以匹配指定的具体字符,可以是1个也可以是多个。
| 字符 | 功能说明 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [2a] | 匹配[]中括号中列举的字符,如这里就是匹配2或者a这两个字符其中的一个 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字 |
| \s | 匹配空白,即空格、tab键(tab键为两个空格) |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_(数字、字母、下划线) |
| \W | 匹配非单词字符 |
实例如下,这里先说明一下findall(匹配规则,要匹配的字符串)这个方法是查找所有匹配的数据,以列表的形式返回,后面会在re模块进行详解:
python
import re# .:匹配任意1个字符 re1 = r'.' res1 = re.findall(re1, '\nj8?0\nbth\nihb') print(res1) # 运行结果:['j', '8', '?', '0', 'b', 't', 'h', 'i', 'h', 'b']# []:匹配列举中的其中一个 re2 = r"[abc]" res2 = re.findall(re2, '1iugfiSHOIFUOFGIDHFGFD2345a6a78b99cc') print(res2) # 运行结果:['a', 'a', 'b', 'c', 'c']# \d:匹配一个数字 re3 = r"\d" res3 = re.findall(re3, "dfghjkl32212dfghjk") print(res3) # 运行结果:['3', '2', '2', '1', '2']# \D:匹配一个非数字 re4 = r"\D" res4 = re.findall(re4, "d212dk?\n$%3;]a") print(res4) # 运行结果:['d', 'd', 'k', '?', '\n', '$', '%', ';', ']', 'a']# \s:匹配一个空白键或tab键(tab键实际就是两个空白键) re5 = r"\s" res5 = re.findall(re5,"a s d a 9999") print(res5) # 运行结果:[' ', ' ', ' ', ' ', ' ']# \S: 匹配非空白键 re6 = r"\S" res6 = re.findall(re6, "a s d a 9999") print(res6) # 运行结果:['a', 's', 'd', 'a', '9', '9', '9', '9']# \w:匹配一个单词字符(数字、字母、下划线) re7 = r"\w" res7 = re.findall(re7, "ce12sd@#a as_#$") print(res7) # 运行结果:['c', 'e', '1', '2', 's', 'd', 'a', 'a', 's', '_']# \W:匹配一个非单词字符(不是数字、字母、下划线) re8 = r"\W" res8 = re.findall(re8, "ce12sd@#a as_#$") print(res8) # 运行结果:['@', '#', ' ', '#', '$']# 匹配指定字符 re9 = r"python" res9 = re.findall(re9, "cepy1thon12spython123@@python") print(res9) # 运行结果:['python', 'python']
表示数量
如果要匹配某个字符多次,就可以在字符后面加上数量进行表示,具体规则如下:
| 字符 | 功能说明 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或无限次,即至少1次 |
| ? | 匹配前一个字符出现0次或1次,即要么没有,要么只有1次 |
| 匹配前一个字符出现m次 | |
| 匹配前一个字符至少出现m次 | |
| 匹配前一个字符出现从m到n次 |
实例如下:
python
import re# *:表示前一个字符出现0次以上(包括0次)
re21 = r"\d*" # 这里匹配的规则,前一个字符是数字
res21 = re.findall(re21, "343aa1112df345g1h6699") # 如匹配到a时,属于符合0次,但因为没有值所以会为空
print(res21) # 运行结果:['343', '', '', '1112', '', '', '345', '', '1', '', '6699', '']# ? : 表示0次或者一次
re22 = r"\d?"
res22 = re.findall(re22, "3@43*a111")
print(res22) # 运行结果:['3', '', '4', '3', '', '', '1', '1', '1', '']# {m}:表示匹配一个字符m次
re23 = r"1[3456789]\d{9}" # 手机号:第1位为1,第2位匹配列举的其中1个数字,第3位开始是数字,且匹配9次
res23 = re.findall(re23,"sas13566778899fgh256912345678jkghj12788990000aaa113588889999")
print(res23) # 运行结果:['13566778899', '13588889999']# {m,}:表示匹配一个字符至少m次
re24 = r"\d{7,}"
res24 = re.findall(re24, "sas12356fgh1234567jkghj12788990000aaa113588889999")
print(res24) # 运行结果:['1234567', '12788990000', '113588889999']# {m,n}:表示匹配一个字符出现m次到n次
re25 = r"\d{3,5}"
res25 = re.findall(re25, "aaaaa123456ghj333yyy77iii88jj909768876")
print(res25) # 运行结果:['12345', '333', '90976', '8876']
匹配分组
| 字符 | 功能说明 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
实例如下:
python
import re# 同时定义多个规则,只要满足其中一个
re31 = r"13566778899|13534563456|14788990000"
res31 = re.findall(re31, "sas13566778899fgh13534563456jkghj14788990000")
print(res31) # 运行结果:['13566778899', '13534563456', '14788990000']# ():匹配分组:在匹配规则的数据中提取括号里的数据
re32 = r"aa(\d{3})bb" # 如何数据符合规则,结果只会取括号中的数据,即\d{3}
res32 = re.findall(re32, "ggghjkaa123bbhhaa672bbjhjjaa@45bb")
print(res32) # 运行结果:['123', '672']
表示边界
| 字符 | 功能说明 |
|---|---|
| ^ | 匹配字符串开头,只能匹配开头 |
| $ | 匹配字符串结尾,只能匹配结尾 |
| \b | 匹配一个单词的边界(单词:字母、数字、下划线) |
| \B | 匹配非单词的边界 |
实例如下:
python
import re# ^:匹配字符串的开头 re41 = r"^python" # 字符串开头为python res41 = re.findall(re41, "python999python") # 只会匹配这个字符串的开头 res411 = re.findall(re41, "1python999python") # 因为开头是1,第1位就不符合了 print(res41) # 运行结果:['python'] print(res411) # 运行结果:[]# $:匹配字符串的结尾 re42=r"python$" # 字符串以python结尾 res42 = re.findall(re42, "python999python") print(res42) # 运行结果:['python']# \b:匹配单词的边界,单词即:字母、数字、下划线 re43 = r"\bpython" # 即匹配python,且python的前一位是不是单词 res43 = re.findall(re43, "1python 999 python") # 这里第1个python的前1位是单词,因此第1个是不符合的 print(res43) # 运行结果:['python']# \B:匹配非单词的边界 re44 = r"\Bpython" # 即匹配python,且python的前一位是单词 res44 = re.findall(re44, "1python999python") print(res44) # 运行结果:['python', 'python']
贪婪模式
python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符,而非贪婪模式则是尝试匹配尽可能少的字符,在表示数量的表达式后加上问号(?)就可以关闭贪婪模式。
如下例子,匹配2个以上的数字,如果符合条件它会一直匹配到不符合才停止,如其中的34656fya,34656符合2个数字以上,那么它会一直匹配到6为止,如果关闭贪婪模式,那么在满足2个数字时就会停止,最后可以匹配到34、65。
python
import re# 默认的贪婪模式下
test = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']# 关闭贪婪模式
res2 = re.findall(r'\d{2,}?', test)
print(res2) # 运行结果:['12', '34', '65', '12', '12']
re模块
在python中使用正则表达式,就会用到re模块来进行操作,提供的方法一般需要传入两个参数:
- 📘参数1: 匹配的规则
- 📒参数2:要进行匹配的字符串
re.findall()
查找所有符合规范的字符串,以列表的形式返回。
python
import retest = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']
re.search()
查找第一个符合规范的字符串,返回的是一个匹配对象,可以通过group()将匹配到的数据直接提取出来。
python
import res = "123abc123aaa123bbb888ccc" res2 = re.search(r'123', s) print(res2) # 运行结果:<re.Match object; span=(0, 3), match='123'># 通过group将匹配到的数据提取出来,返回类型为str print(res2.group()) # 运行结果:123
返回的匹配对象中,span为匹配到的数据的下标范围,match则是匹配到的值。
group()参数说明:
- 🍊不传参数:获取的是匹配到的所有内容
- 🍋传入数值:可以通过参数来指定,获取第几个分组中的内容(获取第1个分组,传入参数1,获取第2个分组,传入参数2,依次类推。)
python
import res = "123abc123aaa123bbb888ccc"
re4 = r"aaa(\d{3})bbb(\d{3})ccc" # 这里分组就是前面说到的匹配语法:()
res4 = re.search(re4, s)
print(res4)
# group不传参数:获取的是匹配到的所有内容
# group通过参数指定,获取第几个分组中的内容(获取第1个分组,传入参数1,获取第2个分组,传入参数2,依次类推..
print(res4.group())
print(res4.group(1))
print(res4.group(2))
re.match()
从字符串的起始位置进行匹配,匹配成功则返回匹配到的对象,如果开头的位置不符合匹配的规则,不会继续往后面去匹配,直接返回None。re.match()与re.search()都是只匹配一个,不一样的是,前者只匹配字符串的开头,后者则是会匹配整个字符串,但只获取第一个符合的数据。
python
import res = "a123abc123aaa1234bbb888ccc" # match:只匹配字符串的开头,开头不符合就返回None res1 = re.match(r"a123", s) res2 = re.match(r"a1234", s) print(res1) # 运行结果:<re.Match object; span=(0, 4), match='a123'> print(res2) # 运行结果:None
re.sub()
检索和替换:用于替换字符串中的匹配项
re.sub()参数说明:
- 🍇参数1:待替换的字符串
- 🍉参数2:目标字符串
- 🍑参数3:要进行替换操作的字符串
- 🍓参数4:可以指定最多替换的次数,非必填(默认替换所有符合规范的字符串)
python
import res = "a123abc123aaa123bbb888ccc" # <font color="#FF0000">参数1:</font>待替换的字符串 # <font color="#FF0000">参数2:</font>目标字符串 # <font color="#FF0000">参数3:</font>要进行替换操作的字符串 # <font color="#FF0000">参数4:</font>可以指定最多替换的次数,非必填(默认替换所有符合规范的字符串) res5 = re.sub(r'123', "666", s, 4) print(res5) # 运行结果:a666abc666aaa666bbb888ccc
用例参数化
在接口自动化测试中,我们的测试数据都是保存在excel中的,有些参数如果写死一个数据,可能换个场景或者换个环境就不能用了,那么切换环境时就需要先把新环境的测试数据准备好,并且能支持去跑我们的脚本,或者把excel的数据修改为适合新环境的测试数据,维护的成本较高。因此就需要把我们的自动化脚本测试数据尽量地参数化,降低维护成本。
我们先看简单版的参数化,以登录为例,登录时用到的账号、密码等信息都可以提取出来放到配置文件,修改数据或更换环境时直接在配置文件中统一修改就可以了。
编辑 编辑
但如果有多个不同的数据需要参数化呢,每个参数都加个判断去替换数据吗?这样的代码既啰嗦又不好维护,这时re模块就可以用上了,直接看一个实例:
python
import re
from common.myconfig import confclass TestData:"""用于临时保存一些要替换的数据"""passdef replace_data(data):r = r"#(.+?)#" # 注意这个分组()内的内容# 判断是否有需要替换的数据while re.search(r, data):res = re.search(r, data) # 匹配出第一个要替换的数据item = res.group() # 提取要替换的数据内容key = res.group(1) # 获取要替换内容中的数据项try:# 根据替换内容中的数据项去配置文件中找到对应的内容,进行替换data = data.replace(item, conf.get_str("test_data", key))except:# 如果在配置文件中找不到就在临时保存的数据中找,然后替换data = data.replace(item, getattr(TestData, key))return data
注意这里的正则表达式是有使用?关闭贪婪模式的,因为测试数据中可能会需要参数化2个或以上的数据,如果不关闭贪婪模式,它就只能匹配搭配一个数据,举例如下:
python
import redata = '{"mobile_phone":"#phone#","pwd":"#pwd#","user":#user#}'
r1 = "#(.+)#"
res1 = re.findall(r1, data)
print(res1) # 运行结果:['phone#","pwd":"#pwd#","user":#user'] 注意这里单引号只有一个数据
print(len(res1)) # 运行结果:1r2 = "#(.+?)#"
res2 = re.findall(r2, data)
print(res2) # 运行结果:['phone', 'pwd', 'user']
print(len(res2)) # 运行结果:3
另外提到的一个用于临时保存数据的类,这里主要用于保存接口返回的数据,因为有些测试数据是动态变化的,可能要依赖于某个接口,后面的测试用例又需要这些数据,那么我们在接口返回时就可以保存到这个类里作为一个类属性,接着在需要用这个数据的测试用例时,把这个类属性提取出来替换到测试数据中即可。提示:设置属性setattr(对象, 属性名, 属性值),获取属性值getattr(对象, 属性名)。
最后我邀请你进入我们的【软件测试学习交流群:785128166】, 大家可以一起探讨交流软件测试,共同学习软件测试技术、面试等软件测试方方面面,还会有免费直播课,收获更多测试技巧,我们一起进阶Python自动化测试/测试开发,走向高薪之路
作为一个软件测试的过来人,我想尽自己最大的努力,帮助每一个伙伴都能顺利找到工作。所以我整理了下面这份资源,现在免费分享给大家,有需要的小伙伴可以关注【公众号:程序员二黑】自提!

相关文章:
【python接口自动化】- 正则用例参数化
🔥 交流讨论:欢迎加入我们一起学习! 🔥 资源分享:耗时200小时精选的「软件测试」资料包 🔥 教程推荐:火遍全网的《软件测试》教程 📢欢迎点赞 👍 收藏 ⭐留言 …...

Java中的四种线程池详解及使用场景
前言 在Java并发编程中,JDK提供了一套强大的线程池工具类java.util.concurrent.ThreadPoolExecutor以及它的四个便捷工厂方法,这四种线程池分别对应不同的使用场景和特性。下面将详细介绍每种线程池的创建方式、工作原理以及适用场景。 1. CachedThrea…...
Google Chrome 常用的几个参数
1 右键--Google Chrome--属性--目标 参数作用--disable-infobars此计算机将不会再收到 Google Chrome 更新,因为 Windows XP 和 Windows Vista 不再受支持。适用于 xp、2003 的 49.x.x.x 版本。示例1--ingore-certificate-errors忽略证书错误--disable-background-…...
Keil软件某些汉字输出乱码,0xFD问题,51单片机
1. 问题 keil软件输入某些汉字的时候会输出乱码,例如:升、 数 2. 原因 keil软件会忽略0xFD。 升的GB2312编码为 0xc9fd,keil解析为0xc9数的GB2312编码为 0xcafd,keil解析为0xca 关于Keil软件中0xFD问题的说明 3. 解决方案1 …...
自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人
如今,大模型层出不穷,这为自然语言处理、计算机视觉、语音识别和其他领域的人工智能任务带来了重大的突破和进展。大模型通常指那些参数量庞大、层数深、拥有巨大的计算能力和数据训练集的模型。 但不能不承认的是,普通人使用大模型还是有一…...

Android中 Gradle与 AGP 版本对应关系表
Android Gradle Plugin Version版本Gradle Version版本1.0.0 - 1.1.32.2.1 - 2.31.2.0 - 1.3.12.2.1 - 2.91.5.02.2.1 - 2.132.0.0 - 2.1.22.10 - 2.132.1.3 - 2.2.32.14.12.3.03.33.0.04.13.1.04.43.2.0 - 3.2.14.63.3.0 - 3.3.34.10.13.4.0 - 3.4.35.1.13.5.0 - 3.5.45.4.13.…...

Linux基础知识合集
整理了一下学习的一些关于Linux的一些基础知识,同学们也可以通过公众号菜单栏查看! 一、基础知识 Linux基础知识 Linux命令行基础学习 Linux用户与组概念初识 Linux文件与目录权限基础 Linux中文件内容的查看 Linux系统之计划任务管理 二、服务器管理 Vm…...

跟着pink老师前端入门教程-day13
品优购案例 一、品优购项目规划 1. 品优购项目整体介绍 项目名称:品优购 项目描述:品优购是一个电商网站,我们要完成 PC 端首页、列表页、注册页面的制作 2. 品优购项目学习目的 1. 电商类网站比较综合,里面需要大量的布…...
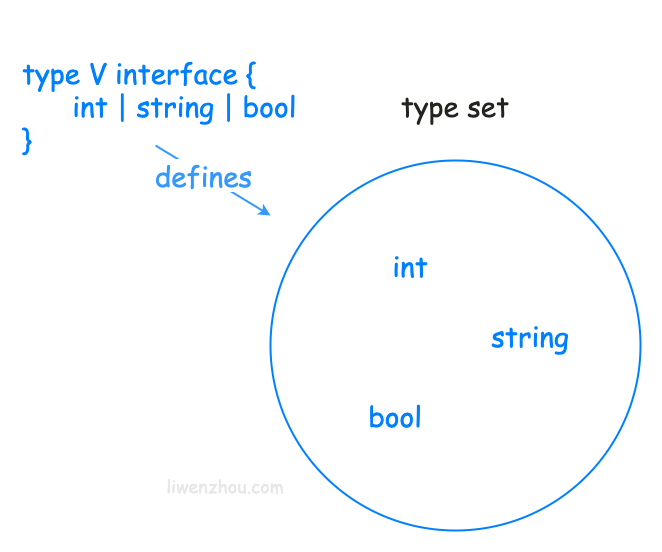
go语言基础之泛型
1.泛型 泛型是一种独立于所使用的特定类型的编写代码的方法。使用泛型可以编写出适用于一组类型中的任何一种的函数和类型。 1.1 为什么需要泛型 func reverse(s []int) []int {l : len(s)r : make([]int, l)for i, e : range s {r[l-i-1] e}return r }fmt.Println(reverse…...
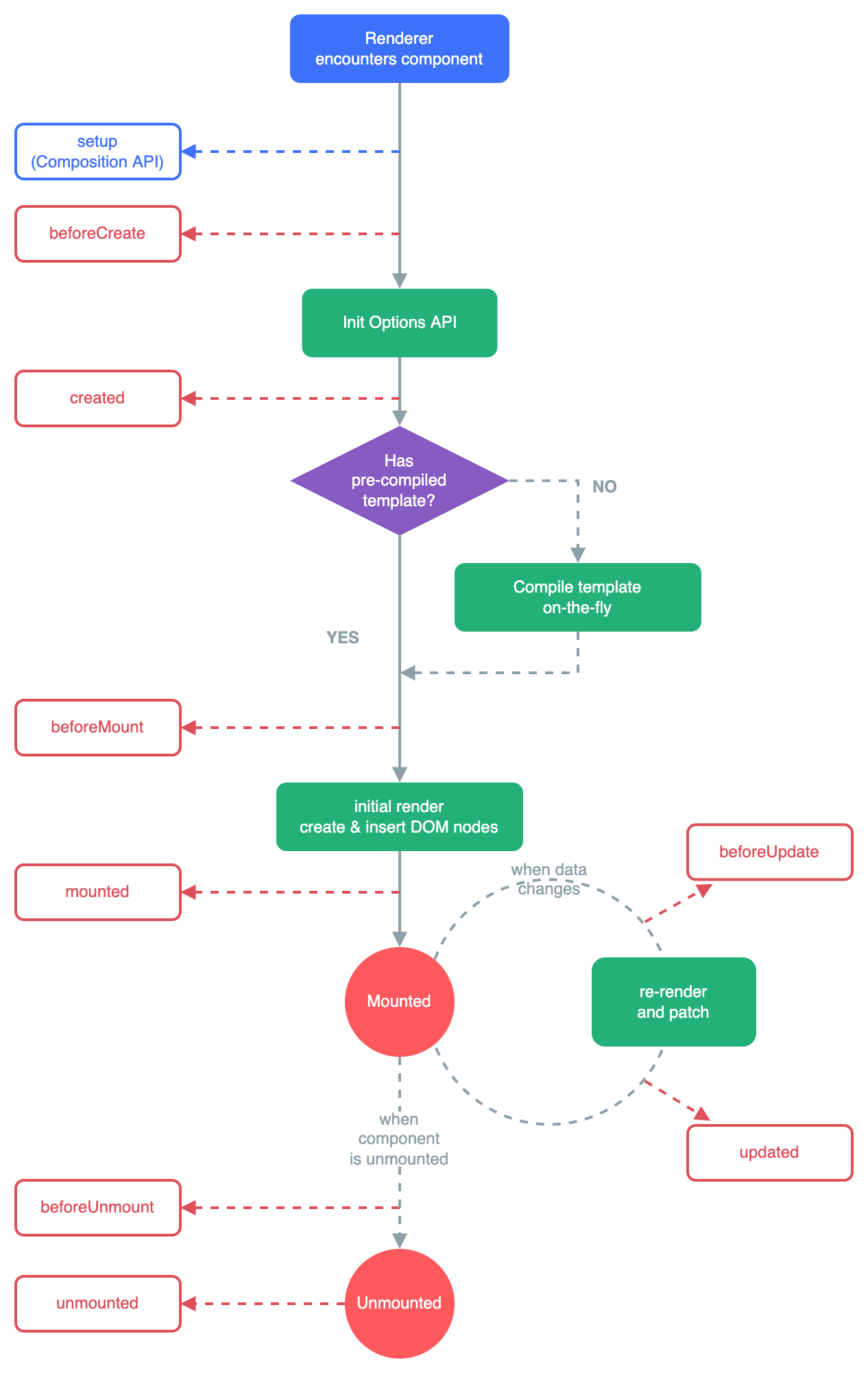
Vue.js 中子组件向父组件传值的方法
Vue.js 是一款流行的 JavaScript 前端框架,它提供了一套完整的工具和 API,使得开发者可以更加高效地构建交互式的 Web 应用程序。其中,组件化是 Vue.js 的一个核心概念,通过组件化可以将一个复杂的应用程序拆分成多个独立的部分&a…...
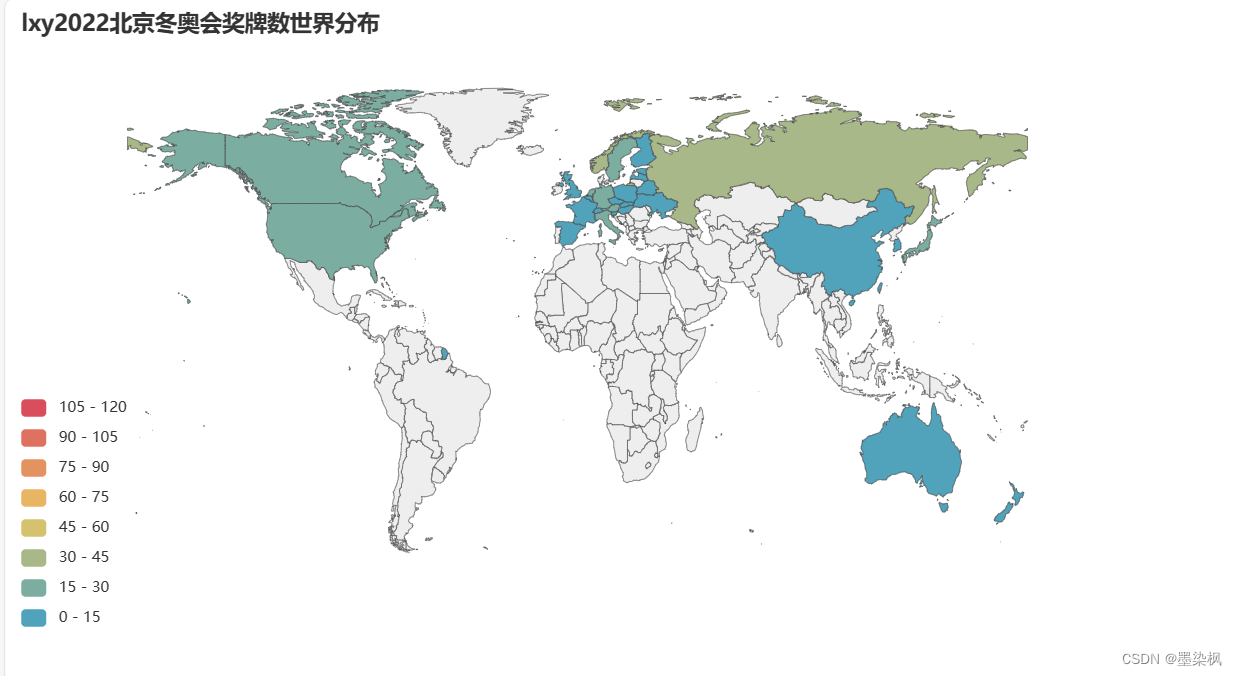
数据可视化 pycharts实现地理数据可视化(全球地图)
自用版 紧急整理一点可能要用的可视化代码,略粗糙 以后有机会再改 requirements: python3.6及以上pycharts1.9 数据格式为: 运行结果为: import pandas as pd from pyecharts.charts import Map, Timeline from pyecharts im…...

Mac下查看、配置和使用环境变量
Mac下查看、配置和使用环境变量 一:Mac怎么查看环境变量命令 printenv一:这个命令会一次性列出所有环境变量的键值对,输出格式为: VAR1value1 VAR2value2 ...二: 也可以通过给这个命令加上环境变量名参数࿰…...

虚拟机克隆的三种方式:全量克隆、快速全量克隆、链接克隆
虚拟机克隆的三种方式:全量克隆、快速全量克隆、链接克隆 快速全量克隆 特点:虚拟机启动快、拍平后数据独立 场景:快速发放独立的虚拟机,减少等待虚拟机部署完成时间,能够快速提供用户使用虚拟机。 实现方式:通过对…...

如何隐藏Selenium特征实现自动化网页采集
Selenium是一个流行的自动化网页测试工具,可以通过模拟用户在Chrome浏览器中的操作来完成网站的测试。然而,有些网站会检测浏览器是否由Selenium驱动,如果是,就会返回错误的结果或拒绝访问。为了避免这种情况,我们需要…...

springboot149智慧图书管理系统设计与实现
智慧图书管理系统的设计与实现 摘 要 如今社会上各行各业,都在用属于自己专用的软件来进行工作,互联网发展到这个时候,人们已经发现离不开了互联网。互联网的发展,离不开一些新的技术,而新技术的产生往往是为了解决现…...

3D词云图
工具库 tagcanvas.min.js vue3(框架其实无所谓,都可以) 实现 <script setup> import { onMounted, ref } from vue; import ./tagcanvas.min.js;const updateFlag ref(false);// 词云图初始化 const initWordCloud () > {let …...
参数详解)
opencv-python 视频读取: VideoCapture.get()参数详解
视频读取demo import cv2 from tqdm import tqdmvideoCapture cv2.VideoCapture(video_path) if not videoCapture.isOpened(): # 若视频文件读取失败,读取下一段视频print(视频打开失败!!!)print(video_path)return False total_frames int(videoCapture.get(c…...
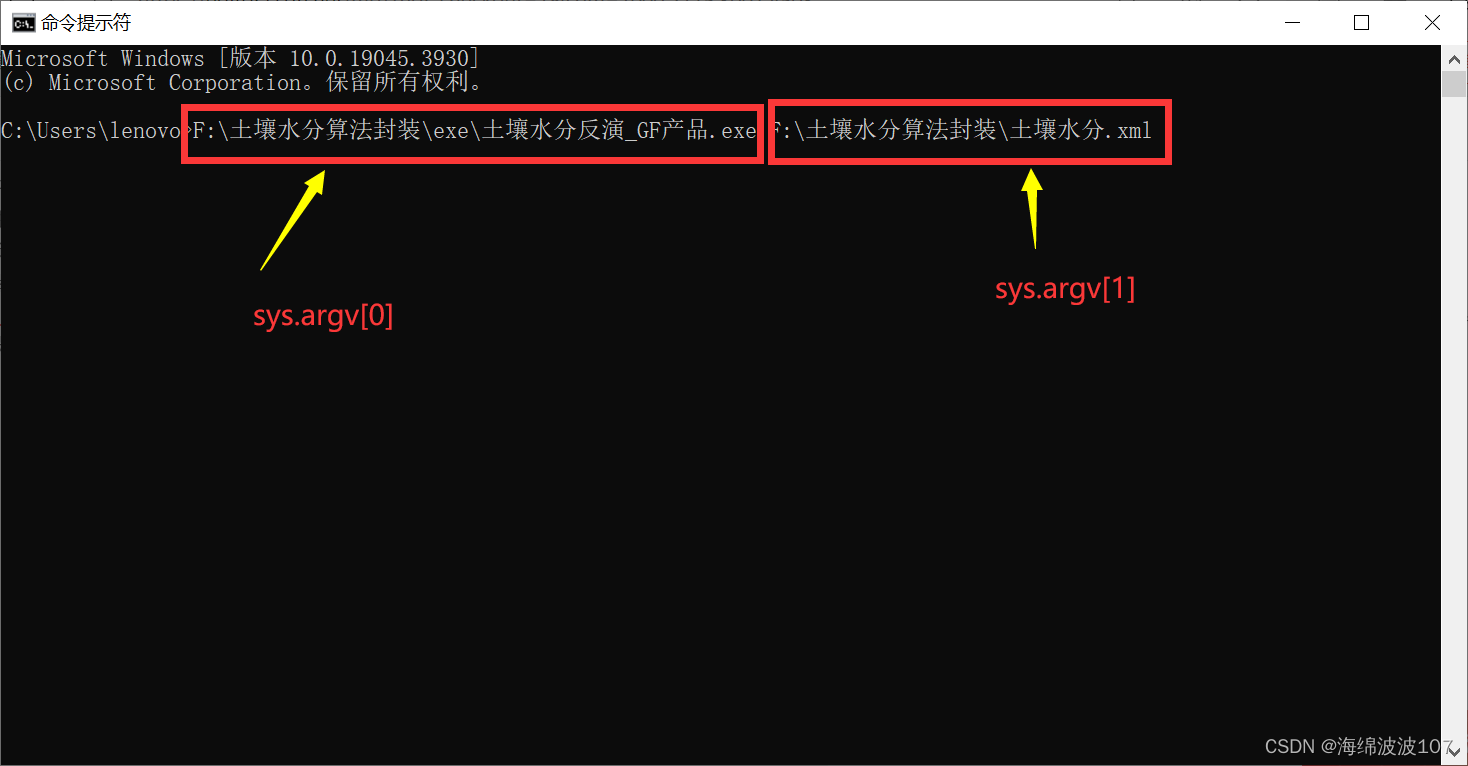
python封装的.exe文件是如何在cmd中获取.xml路径的?
这段日子搞项目算法封装,愁死我。来回改了三遍,总算把相对路径、绝对路径,还有cmd给.exe传参的方式搞懂了。 主要是这个语句 workspace sys.argv[1] sys.argv[]的作用就是,在运行python文件的时候从外部输入参数往文件里面传递参数。 外部就…...
【学网攻】 第(18)节 -- 网络地址转换动态NAT
系列文章目录 目录 系列文章目录 文章目录 前言 一、NAT是什么? 二、实验 1.引入 文章目录 【学网攻】 第(1)节 -- 认识网络【学网攻】 第(2)节 -- 交换机认识及使用【学网攻】 第(3)节 -- 交换机配置聚合端口【学网攻】 第(4)节 -- 交换机划分Vlan【学网攻】…...

nosql数据库期末考试知识点总结
目录 1、什么是nosql数据库,它包括哪些 文档数据库 建数据 哪一种是最简单的 2、什么是文档数据库 3、创建mongodb时默认会建造三个数据库,是哪三个 4、mongodb支持的数据类型有哪些 5、它的常规语句有哪些 6、副本集和分片集有什么作用 复制 …...

2-1爬取豆瓣电影数据
数据来源网站:https://movie.douban.com/chart import requests import json import timedef fetch_douban():all_movies []start 0limit 20print("开始爬取豆瓣电影榜单")headers {"User-Agent": "Mozilla/5.0","Referer&…...

[2026 职场洗牌系列 01] 程序员正在“杀死”自己的工作?科技行业高危预警
长久以来,学计算机(CS)在很多年轻人眼里就等同于拿到了通往高薪和阶层跃升的金钥匙。大家都觉得,只要把代码敲得溜,这辈子在职场上基本就稳了。可惜,到了2026年的今天,生成式AI正在毫不留情地把…...

Windows下OpenClaw安装指南:快速对接百川2-13B量化模型
Windows下OpenClaw安装指南:快速对接百川2-13B量化模型 1. 为什么选择OpenClaw百川2-13B组合 去年我在处理个人知识管理时,发现每天要重复执行大量机械操作:整理网页资料、归档PDF、生成日报。直到遇见OpenClaw这个能像人类一样操作电脑的A…...
)
MCP服务器性能翻倍的秘密:基于asyncio+uvloop+Pydantic V2的轻量级模板(压测QPS达12,800+)
第一章:MCP服务器开发模板概述与核心价值MCP(Model-Controller-Protocol)服务器开发模板是一套面向协议驱动、可插拔架构的后端服务构建范式,专为高并发、多协议适配(如HTTP/2、gRPC、WebSocket、MQTT)场景…...

macOS歌词体验升级:LyricsX实现多播放器无缝歌词同步方案
macOS歌词体验升级:LyricsX实现多播放器无缝歌词同步方案 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX 你是否曾在使用macOS音乐播放器时遭遇歌词显示不同步、搜索不到匹配…...

终极简单教程:如何使用bilibili-parse免费获取B站视频资源
终极简单教程:如何使用bilibili-parse免费获取B站视频资源 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 想要快速获取B站视频资源却不知道从何入手?bilibili-parse作为一款简…...

Gorgonia性能优化终极指南:10个技巧让你的深度学习模型运行速度翻倍
Gorgonia性能优化终极指南:10个技巧让你的深度学习模型运行速度翻倍 【免费下载链接】gorgonia 项目地址: https://gitcode.com/gh_mirrors/gor/gorgonia Gorgonia是一个功能强大的深度学习框架,能够帮助开发者构建和训练复杂的神经网络模型。然…...

Rainmeter皮肤主题用户行为分析:使用数据统计
Rainmeter皮肤主题用户行为分析:使用数据统计 【免费下载链接】rainmeter Desktop customization tool for Windows 项目地址: https://gitcode.com/gh_mirrors/ra/rainmeter Rainmeter作为一款强大的Windows桌面自定义工具,允许用户通过皮肤主题…...

5大突破!漫画阅读工具Venera重构跨平台阅读体验
5大突破!漫画阅读工具Venera重构跨平台阅读体验 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 副标题:如何在Windows、macOS和移动设备间无缝切换你的漫画库? 开篇痛点引入 不同设备间漫…...

Vue-Sonner:面向现代Vue应用的高性能Toast通知架构解析
Vue-Sonner:面向现代Vue应用的高性能Toast通知架构解析 【免费下载链接】vue-sonner 🔔 An opinionated toast component for Vue. 项目地址: https://gitcode.com/gh_mirrors/vu/vue-sonner 在当今快节奏的Web应用开发中,实时反馈机制…...