python爬虫4




#1.练习
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url='https://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
#请求对象定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器访问服务器
response=urllib.request.urlopen(request)
#获取网页源码
content=response.read().decode('utf-8')
#解析网页源码 来获取想要的数据
from lxml import etree
#解析服务器相应的文件
tree=etree.HTML(content)
#获取想要的数据 xpath的返回值是一个列表类型的数据
result=tree.xpath('//input[@id="su"]/@value')[0]
print(result)#2.练习
# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):if(page==1):url='https://sc.chinaz.com/tupian/qinglvtupian.html'else:url = 'https://sc.chinaz.com/tupian/qinglvtupian_'+str(page)+'.html'headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',}request=urllib.request.Request(url=url,headers=headers)return request
def get_content(request):response=urllib.request.urlopen(request)content=response.read().decode('utf-8')return content
def down_load(content):下载图片# urllib.request.urlretrieve('图片地址','文件的名字')tree=etree.HTML(content)name_list=tree.xpath('//div[@id="container"]//a/img/@alt')#一般设计网站的图片都会进行懒加载src_list=tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(name_list)):name=name_list[i]src=src_list[i]url='https:'+srcurllib.request.urlretrieve(url=url,filename='./loveImg/'+name+'.jpg')
if __name__ == '__main__':strat_page=int(input('请输入起始页码:')end_page=int(input('请输入结束页码:')for i in range(start_page,end_page+1):request=create_request(page)content=get_content(request)down_load(content)
#3.练习json数据格式
{ "store": {"book": [{ "category": "修真","author": "六道","title": "坏蛋是怎样练成的","price": 8.95},{ "category": "修真","author": "天蚕土豆","title": "斗破苍穹","price": 12.99},{ "category": "修真","author": "唐家三少","title": "斗罗大陆","isbn": "0-553-21311-3","price": 8.99},{ "category": "修真","author": "南派三叔","title": "星辰变","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"author": "老马","color": "黑色","price": 19.95}}
}
import ison
import isonpath
obj=(open('073_尚硅谷_爬虫_解析_jsonpath.json','r',encoding='utf-8'))
#那本书超过了10块钱
book_list=jsonpath.jsonpath(obj,'$..book[?(@.price>10)']
print(book_list)
# 书店所有书的作者
# author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
# print(author_list)# 所有的作者
# author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)# store下面的所有的元素
# tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)# store里面所有东西的price
# price_list = jsonpath.jsonpath(obj,'$.store..price')
# print(price_list)# 第三个书
# book = jsonpath.jsonpath(obj,'$..book[2]')
# print(book)# 最后一本书
# book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
# print(book)# 前面的两本书
# book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# print(book_list)# 条件过滤需要在()的前面添加一个?
# 过滤出所有的包含isbn的书。
# book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
# print(book_list)#4.练习json解析
import urllib.request
url= 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {# ':authority': 'dianying.taobao.com',# ':method': 'GET',# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',# ':scheme': 'https','accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',# 'accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9','cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9','referer': 'https://dianying.taobao.com/','sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"','sec-ch-ua-mobile': '?0','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36','x-requested-with': 'XMLHttpRequest',
}
#headers里面的以冒号开头的直接注释掉,一般都不太行
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
content=content.split('(')[1].split(')')[0]
with open ('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','w',encoding='utf-8')as fp:fp.write(content)
import json
import jsonpath
obj=json.load(open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','r',encoding='utf-8'))
city_list=jsonpath.jsonpath(obj,'$..regionname')
printy(city_list)#5.bs的练习
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body><div><ul><li id="l1">张三</li><li id="l2">李四</li><li>王五</li><a href="" id="" class="a1">尚硅谷</a><span>嘿嘿嘿</span></ul></div><a href="" title="a2">百度</a><div id="d1"><span>哈哈哈</span></div><p id="p1" class="p1">呵呵呵</p>
</body>
</html>from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4的基础语法进行讲解
# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup=(BeautifulSoup(open('075_尚硅谷_爬虫_解析_bs4的基本使用.html',encoding='utf-8'),'lxml')# 根据标签名查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
# print(soup.find('a'))# 根据title的值来找到对应的标签对象
# print(soup.find('a',title="a2"))# 根据class的值来找到对应的标签对象 注意的是class需要添加下划线
# print(soup.find('a',class_="a1"))# (2)find_all 返回的是一个列表 并且返回了所有的a标签
# print(soup.find_all('a'))# 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
# print(soup.find_all(['a','span']))# limit的作用是查找前几个数据
# print(soup.find_all('li',limit=2))# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
# print(soup.select('a'))# 可以通过.代表class 我们把这种操作叫做类选择器
# print(soup.select('.a1'))# print(soup.select('#l1'))# 属性选择器---通过属性来寻找对应的标签
# 查找到li标签中有id的标签
# print(soup.select('li[id]'))# 查找到li标签中id为l2的标签
# print(soup.select('li[id="l2"]'))# 层级选择器
# 后代选择器
# 找到的是div下面的li
# print(soup.select('div li'))# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容
# print(soup.select('div > ul > li'))# 找到a标签和li标签的所有的对象
# print(soup.select('a,li'))# 节点信息
# 获取节点内容
# obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
# print(obj.string)
# print(obj.get_text())# 节点的属性
# obj = soup.select('#p1')[0]
# name是标签的名字
# print(obj.name)
# 将属性值左右一个字典返回
# print(obj.attrs)# 获取节点的属性
obj=soup.select('#p1')[0]
#下面三个都能打印但更推荐第一个
print(obj.attrs.get('class'))
print(obj.get('class')
print(obj['class'])#6.星巴克练习
import urllib.request
url='https://www.starbucks.com.cn/menu/'
response=urllib.request.urlopen(url)
content=response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup=BeautifulSoup(content,'lxml')
name_list=soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:print(name.get_text())
#7.练习为什么要学习selenium
#导入selenium
from selenium import webdriver
#创建浏览器对象
path='chromedriver.exe'
browser=webdriver.Chrome(path)
url = 'https://www.jd.com/'
browser.get(url)
content=browser.page_source
print(content)
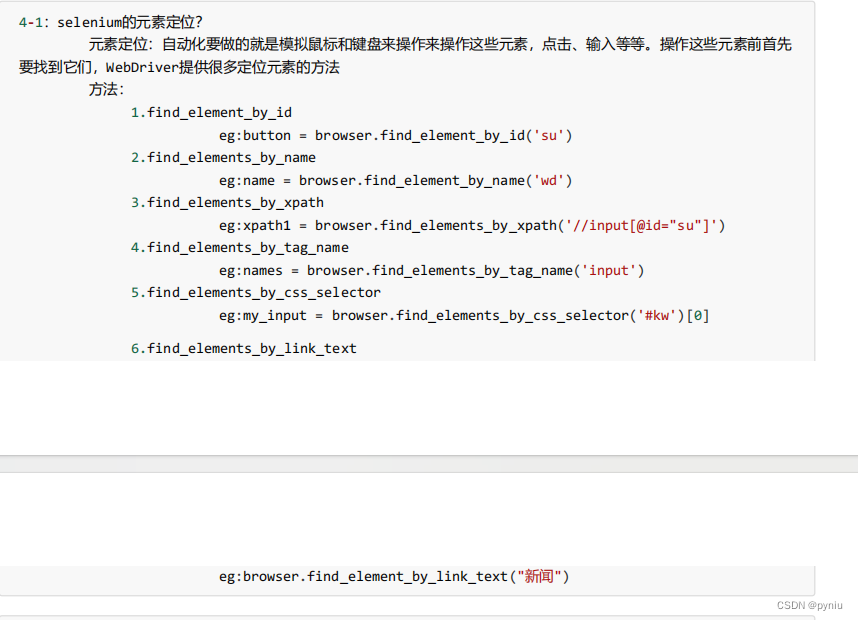
#8.练习 元素定位
from selenium import webdriver
path ='chromedriver.exe'
browser=webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位# 根据id来找到对象
# button = browser.find_element_by_id('su')
# print(button)# 根据标签属性的属性值来获取对象的
# button = browser.find_element_by_name('wd')
# print(button)# 根据xpath语句来获取对象
# button = browser.find_elements_by_xpath('//input[@id="su"]')
# print(button)# 根据标签的名字来获取对象
# button = browser.find_elements_by_tag_name('input')
# print(button)# 使用的bs4的语法来获取对象
# button = browser.find_elements_by_css_selector('#su')
# print(button)# button = browser.find_element_by_link_text('直播')
# print(button)相关文章:
python爬虫4
#1.练习 # (1) 获取网页的源码 # (2) 解析 解析的服务器响应的文件 etree.HTML # (3) 打印 import urllib.request urlhttps://www.baidu.com/ headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit…...

【算法】约数之和(数论)
题目 给定 n 个正整数 ai,请你输出这些数的乘积的约数之和,答案对 1097 取模。 输入格式 第一行包含整数 n。 接下来 n 行,每行包含一个整数 ai。 输出格式 输出一个整数,表示所给正整数的乘积的约数之和,答案需…...
走进CSS过渡效果的奇妙世界:详解CSS Transition
你是否曾在网页上看到一些酷炫的元素在状态变化时平滑而流畅地过渡?这就是CSS过渡效果的魔力所在!在这篇博客中,我们将深入探讨CSS Transition,揭示其神奇的原理和如何在你的网页中运用这项技术。 什么是CSS Transitionÿ…...
C++入坑基础知识点
当学习了C语言之后,很多的小伙伴都想进一步学习C,但两者有相当一部分的内容都是重叠的,不知道该从哪些方面开始入门C,这篇文章罗列了从C到C必学的入门知识,学完就算是踏入C的大门了。 1. 命名空间 写C的时候ÿ…...
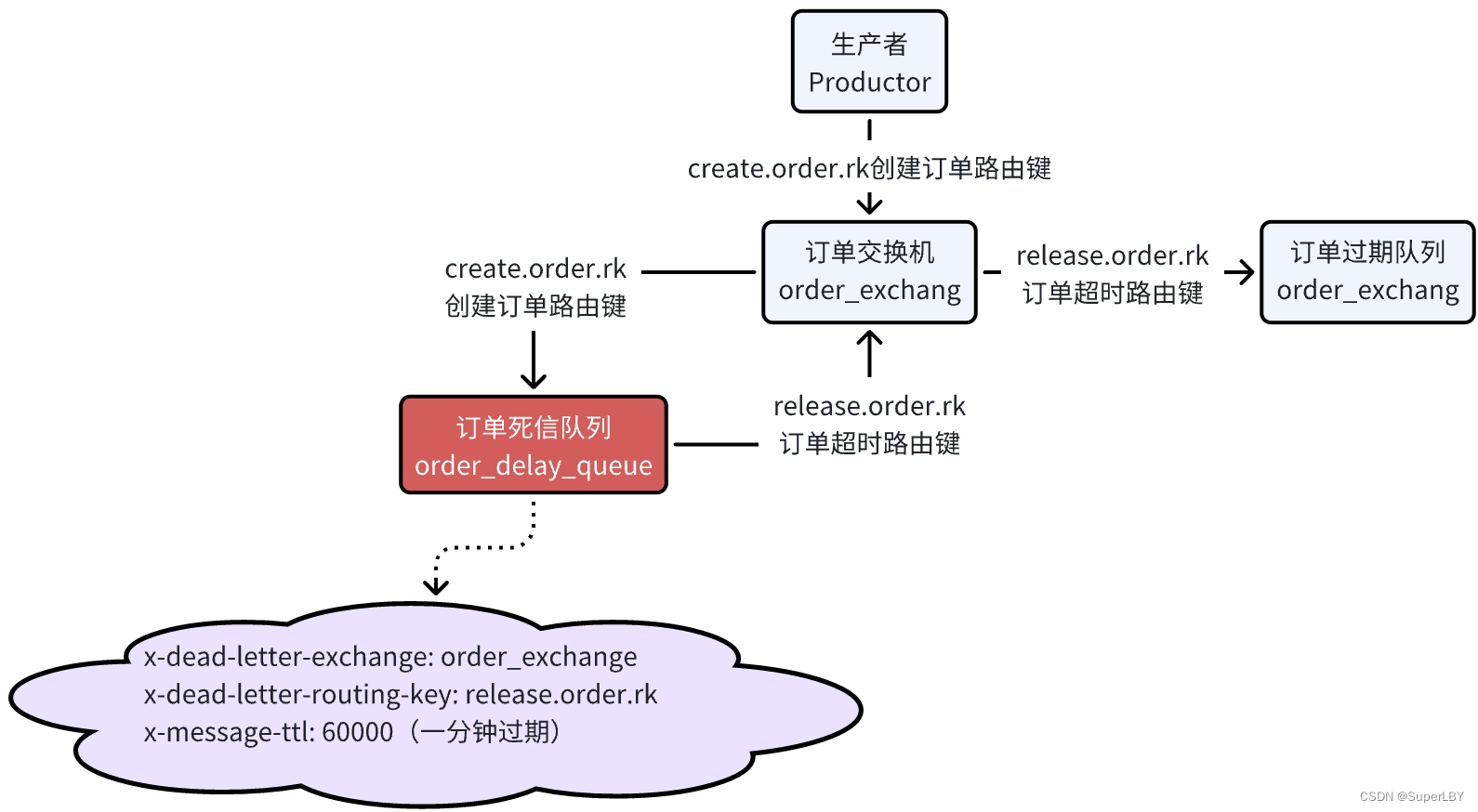
RabbitMQ面试
1. 什么是消息中间件 消息中间件是在分布式系统中传递消息的软件服务。它允许不同的系统组件之间通过消息进行通信,而无需直接连接到彼此。消息中间件通常用于解耦系统的各个部分,提高系统的可扩展性、灵活性和可维护性。 2. 消息中间件解决了什么问题…...
复习提纲21)
计算机网络(第六版)复习提纲21
SS4.6 互联网的路由选择协议 1 关于路由选择协议的基本概念 A 理想的路由算法(路由选择协议的核心)157 1 算法是正确和完整的 2 计算上简单 3 能适应通信量和网络拓扑的变化(自适应性) 4 稳定性 5 公平性 6 应当最佳(特…...

2路DIN2路DO2路AIN远程4GRTU模块钡铼技术S270
钡铼技术的S270远程4G RTU模块是一款高性能的工业级远程终端单元,它支持2路数字输入(DIN)、2路数字输出(DO)以及2路模拟输入(AIN),并通过4G网络实现数据的远程传输。这种模块的设计旨在满足各种工业自动化和监控需求,特别适用于那些位于偏远地…...

从经典到创新,盘点情人节最受欢迎的五款新潮礼物
随着情人节的到来,许多情侣们开始考虑为心爱的人挑选一份特别的礼物。而在这个充满爱意的日子里,我们不仅可以看到经典的礼物款式,也能发现许多新颖、时尚的新潮礼物。以下是今年情人节最受欢迎的五款新潮礼物,每一件都充满了浪漫…...

数据库管理-第141期 DG PDB - Oracle DB 23c(20240129)
数据库管理141期 2024-01-29 第141期 DG PDB - Oracle DB 23c(20240129)1 概念2 环境说明3 操作3.1 数据库配置3.2 配置tnsname3.3 配置强制日志3.4 DG配置3.5 DG配置建立联系3.6 启用所有DG配置3.7 启用DG PDB3.8 创建源PDB的DG配置3.9 拷贝pdbprod1文件…...
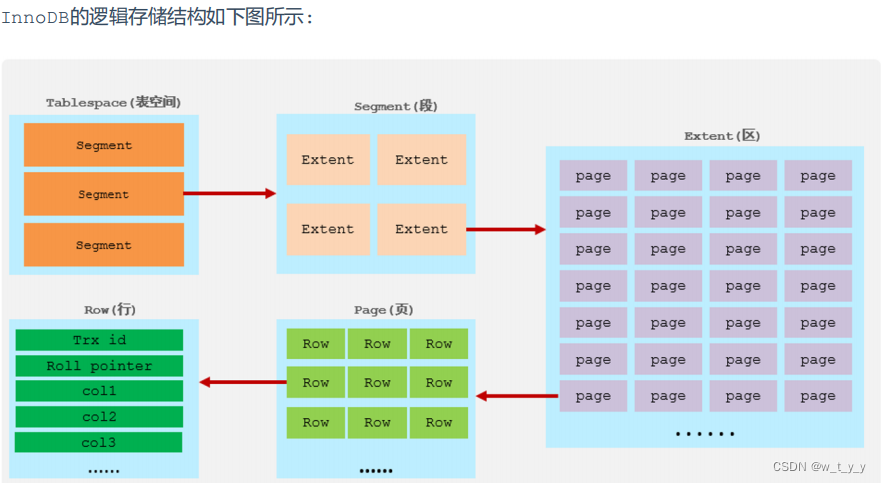
MySQL原理(二)存储引擎(3)InnoDB
目录 一、概况: 1、介绍: 2、特点: 二、体系架构 1、后台线程 2、内存池(缓冲池) 三、物理结构 1、数据文件(表数据和索引数据) 1.1、作用: 1.2、共享表空间与独立表空间 …...
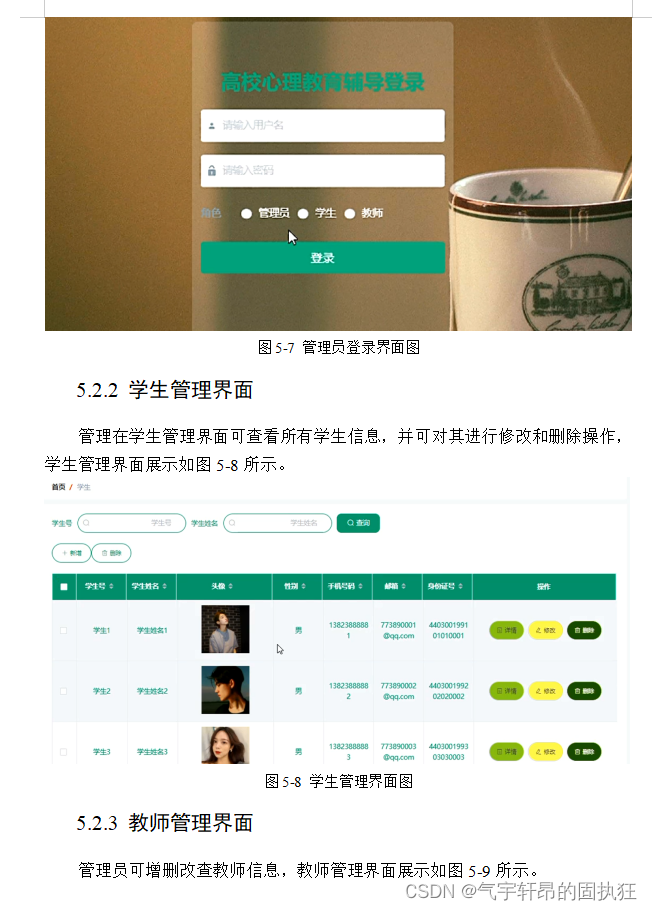
基于Springboot的高校心理教育辅导设计与实现(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的高校心理教育辅导设计与实现(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,…...
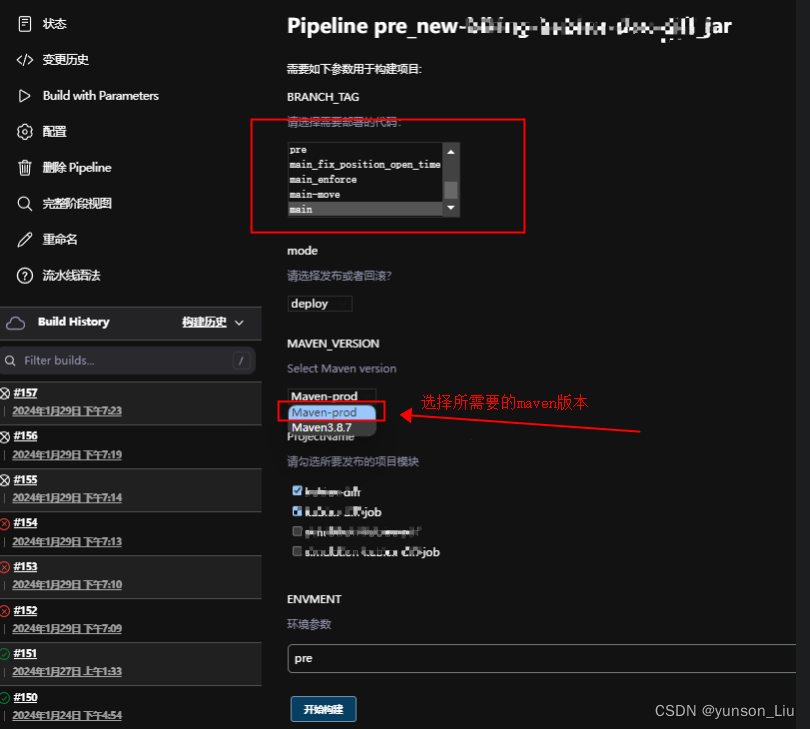
jenkins pipeline配置maven可选参数
1、在Manage Jenkins下的Global Tool Configuration下对应的maven项添加我们要用得到的不同版本的maven安装项 2、pipeline文件内容具体如下 我们maven是单一的,所以我们都是配置单选参数 pipeline {agent anyparameters {gitParameter(name: BRANCH_TAG, type: …...
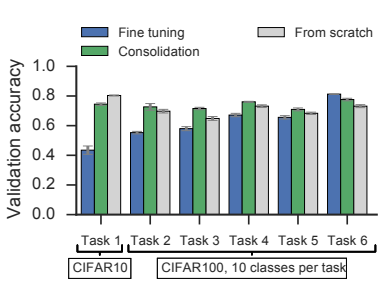
【博士每天一篇论文-算法】Continual Learning Through Synaptic Intelligence,SI算法
阅读时间:2023-11-23 1 介绍 年份:2017 作者:Friedemann Zenke,巴塞尔大学弗里德里希米歇尔研究所(FMI) Ben Poole,谷歌 DeepMind 研究科学家 期刊: International conference on machine learning. PMLR…...

【软件工程】建模工具之开发各阶段绘图——UML2.0常用图实践技巧(功能用例图、静态类图、动态序列图状态图活动图)
更多示例图片可以参考:(除了常见的流程图,其他都有) 概念:类图 静态:用例图 动态:顺序图&状态图&活动图 1、【面向对象】UML类图、用例图、顺序图、活动图、状态图、通信图、构件图、部…...

Typora导出word
Typora导出word Typora是一款简洁易用的Markdown编辑器, Pandoc是一个文档转换工具,可以将Markdown格式的文档转换为其他格式,如HTML、PDF等. linux下安装 Pandoc : sudo apt install -y pandoc安装成功后,typora 会自动监测到. 然后 点击文件->…...

CSS 星空按钮
<template><button class="btn" type="button"><strong>星空按钮</strong><div id="container-stars"><div id="stars"></div></div><div id="glow"><div class=…...
Kotlin快速入门系列10
Kotlin的委托 委托模式是常见的设计模式之一。在委托模式中,有两个对象参与处理同一个请求,接受请求的对象将请求委托给另一个对象来处理。与Java一样,Kotlin也支持委托模式,通过关键字by。 类委托 类的委托即一个类中定义的方…...
Docker中配置MySql环境
目录 一、简单安装 1. 首先从Docker Hub中拉取镜像 2. 启动尝试创建MySQL容器,并设置挂载卷。 3. 查看mysql8这个容器是否启动成功 4. 如果已经成功启动,进入容器中简单测试 4.1 进入容器 4.2 登录mysql中 4.3 进行简单添加查找测试 二、主从复…...

智慧文旅:驱动文化与旅游融合发展的新动力
随着科技的快速发展和人们生活水平的提高,文化和旅游的融合成为了时代发展的必然趋势。智慧文旅作为这一趋势的引领者,通过先进的信息技术手段,推动文化与旅游的深度融合,为产业的发展注入新的活力。本文将深入探讨智慧文旅如何成…...
wordpress怎么做产品展示站?推荐使用MOK主题和ent主题
大多数WordPress站点都是个人博客网站,主要以文章性质的图文为主。不过部分站长想要用WordPress搭建一个产品展示站,应该怎么做呢? 其实,WordPress可以用来建立各种各样的博客网站,包括个人博客、企业网站、商城、影视…...

Typora风格文档化:使用Markdown实时记录PyTorch 2.8实验过程
Typora风格文档化:使用Markdown实时记录PyTorch 2.8实验过程 1. 为什么需要实验过程文档化 在深度学习研究领域,实验过程的可复现性一直是个老大难问题。很多研究者都有这样的经历:三个月前跑的实验,现在想复现结果,…...

[Python3高阶编程] - 横跨同步异步的利器: asgiref.sync
一、asgiref.sync 是什么?asgiref.sync 是 ASGI(Asynchronous Server Gateway Interface)参考实现库 asgiref 中的核心子模块,主要用于安全地桥接同步代码与异步代码。📌 一句话总结: 它让你在异步环境中调…...

Graphormer一键部署与运维监控实战
Graphormer一键部署与运维监控实战 1. 企业级AI模型运维挑战 在AI技术快速落地的今天,Graphormer作为图神经网络领域的先进模型,已经在推荐系统、分子属性预测等场景展现出强大能力。但很多企业在实际部署后常常面临运维难题:服务突然崩溃找…...
:覆盖90%考点,小白也能直接背)
MySQL高频面试题(2026最新版):覆盖90%考点,小白也能直接背
很多开发者备考时,要么盲目刷题、记不住重点,要么只背答案、不懂原理,面试时被面试官追问一句就卡壳。其实MySQL面试没有那么复杂,核心考点就那么多,只要吃透高频题、理解底层逻辑,就能从容应对。本文整理了…...

2.2.2.2 使用Spark单机版环境
本次实战深入探索Spark单机版环境的核心功能。首先运行SparkPi示例程序计算圆周率,验证集群计算能力;随后启动spark-shell进入交互式环境,完成等差数列求和、九九乘法表打印等基础任务。重点通过Scala代码操作RDD,演示了从文本文件…...

AI绘画杀死UI设计师?幸存者在开发岗位的复仇
在数字技术的狂潮中,AI绘画工具的崛起如海啸般席卷设计行业。短短几年间,Midjourney、Stable Diffusion等AI平台已能10秒生成上百张海报,基础美工岗招聘量骤降35%,薪资停滞在4-6K区间。无数UI设计师面临失业危机,仿佛一…...

忍者像素绘卷代码实例:Python调用Z-Image-Turbo-rinaiqiao模型避坑指南
忍者像素绘卷代码实例:Python调用Z-Image-Turbo-rinaiqiao模型避坑指南 1. 环境准备与快速部署 在开始使用忍者像素绘卷之前,我们需要先搭建好Python环境并安装必要的依赖库。这个模型基于Z-Image-Turbo深度优化,特别适合生成16-Bit复古风格…...

国内专业的铣打机厂家哪家专业
在制造业蓬勃发展的今天,铣打机作为轴类零件加工的关键设备,其性能和质量直接影响着生产效率和产品质量。面对市场上众多的铣打机厂家,该如何选择一家专业可靠的呢?今天就为大家介绍一家在行业内颇具口碑的企业——无锡通亚数控智…...

vue3 diff算法中的-双端 Diff + 最长递增子序列 讲解
一句话总结 Vue3 Diff 双端比较(快速复用) 最长递增子序列(最小移动 DOM) 目的:在乱序节点中,只移动最少 DOM,实现最高效更新。1. 先搞懂:Vue3 对比 Vue2 差在哪? Vue2…...

如何写 Skill
核心概念 Skill 是一个自包含的模块,用来给 Claude/Cascade 注入特定领域的知识、工作流和工具。本质上就是一个"新手入职指南",让通用 AI 变成某个领域的专家。 目录结构 skill-name/ ├── SKILL.md # 必须,核心文件 └…...