ClickHouse基于数据分析常用函数
文章标题
- 一、WITH语法-定义变量
- 1.1 定义变量
- 1.2 调用函数
- 1.3 子查询
- 二、GROUP BY子句(结合WITH ROLLUP、CUBE、TOTALS)
- 三、FORM语法
- 3.1表函数
- 3.1.1 file
- 3.1.2 numbers
- 3.1.3 mysql
- 3.1.4 hdfs
- 四、ARRAY JOIN语法(区别于arrayJoin(arr)函数)
- 五、连续销售案例
- 六、连接函数
- 6.1 连接精度
- 6.1.1 ALL
- 6.1.2 ANY
- 6.1.3 ASOF
- 七、系统函数介绍
- 八、JSON解析案例
- 九、实用函数
- 十、语法注意事项
背景:基于初次接触数据分析,对ck函数的不熟悉,此文章主要基于ck特有的sql语法来做讲解;
官网:https://clickhouse.tech/docs/zh
一、WITH语法-定义变量
ClickHouse支持CTE(Common Table Expression,公共表达式),以增强查询语句的表达
SELECT pow(2, 2);┌─pow(2, 2)─┐
│ 4 │
└───────────┘SELECT pow(pow(2, 2), 2);┌─pow(pow(2, 2), 2)─┐
│ 16 │
└───────────────────┘
在改用CTE的形式后,可以极大地提高语句的可读性和维护性。
WITHpow(2, 2) AS a
SELECT pow(a, 2);┌─pow(a, 2)─┐
│ 16 │
└───────────┘
1.1 定义变量
可以定义变量,这些变量能够在后续的查询子句中被直接访问。
# tb_mysql- 创建数据
DROP TABLE IF EXISTS tb_mysql;
CREATE TABLE tb_mysql (id UInt8,name String,age UInt8
)ENGINE = MergeTree()
ORDER BY id;
INSERT INTO tb_mysql VALUES ('1', 'tom', 23);
INSERT INTO tb_mysql VALUES ('2', 'lisa', 33);
INSERT INTO tb_mysql VALUES ('3', 'henry', 44);
INSERT INTO tb_mysql VALUES ('1', 'linda', 23);
INSERT INTO tb_mysql VALUES ('2', 'ross', 33);
INSERT INTO tb_mysql VALUES ('1', 'julie', 23);
INSERT INTO tb_mysql VALUES ('2', 'niki', 33);# 数据分析
WITH 1 AS constant
SELECTid + constant,name
FROMtb_mysql;┌─plus(id, constant)─┬─name─┐
│ 3 │ niki │
└────────────────────┴──────┘
┌─plus(id, constant)─┬─name──┐
│ 2 │ tom │
│ 2 │ linda │
│ 2 │ julie │
│ 3 │ lisa │
│ 3 │ ross │
│ 4 │ henry │
└────────────────────┴───────┘
1.2 调用函数
可以访问SELECT子句中的列字段,并调用函数做进一步的加工处理
# tb_partition-创造数据
DROP TABLE IF EXISTS tb_partition;
CREATE TABLE tb_partition (id UInt8,name String,birthday String
)ENGINE = MergeTree()
ORDER BY id;
INSERT INTO tb_partition VALUES ('1', 'x1', '2024-05-20 10:50:46');
INSERT INTO tb_partition VALUES ('2', 'xy', '2024-05-20 11:17:47');
INSERT INTO tb_partition VALUES ('3', 'xf', '2024-05-19 11:11:12');# 数据分析
WITH toDate(birthday) AS bday
SELECTid,name,bday
FROMtb_partition;┌─id─┬─name─┬───────bday─┐
│ 1 │ x1 │ 2024-05-20 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───────bday─┐
│ 2 │ xy │ 2024-05-20 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───────bday─┐
│ 3 │ xf │ 2024-05-19 │
└────┴──────┴────────────┘
1.3 子查询
可以定义子查询,在WITH中使用子查询时有一点需要特别注意,该查询语句只能 返回一行数据,如果结果集的数据大于一行则会抛出异常;
WITH (SELECT *FROM tb_partitionWHERE tb_partition.id = '1') AS sub
SELECT* ,sub
FROM tb_partition;┌─id─┬─name─┬─birthday────────────┬─sub────────────────────────────┐
│ 3 │ xf │ 2024-05-19 11:11:12 │ (1,'x1','2024-05-20 10:50:46') │
└────┴──────┴─────────────────────┴────────────────────────────────┘
┌─id─┬─name─┬─birthday────────────┬─sub────────────────────────────┐
│ 2 │ xy │ 2024-05-20 11:17:47 │ (1,'x1','2024-05-20 10:50:46') │
└────┴──────┴─────────────────────┴────────────────────────────────┘
┌─id─┬─name─┬─birthday────────────┬─sub────────────────────────────┐
│ 1 │ x1 │ 2024-05-20 10:50:46 │ (1,'x1','2024-05-20 10:50:46') │
└────┴──────┴─────────────────────┴────────────────────────────────┘
二、GROUP BY子句(结合WITH ROLLUP、CUBE、TOTALS)
- ROLLUP:能够按照聚合键从右向左上卷数据,基于聚 合函数依次生成分组小计和总计。如果设聚合键的个数为n,则最终 会生成小计的个数为n+1
- CUBE:像立方体模型一样,基于聚合键之间所有的 组合生成小计信息。如果设聚合键的个数为n,则最终小计组合的个 数为2的n次方。接下来用示例说明它的用法
- TOTALS:会基于聚合函数对所有数据进行总计
# tb_with-创建数据
DROP TABLE IF EXISTS tb_with;
CREATE TABLE tb_with (id UInt8,vist UInt8,province String,city String,area String
)ENGINE = MergeTree()
ORDER BY id;
INSERT INTO tb_with VALUES (1, 12 ,'湖北', '黄冈', '武穴');
INSERT INTO tb_with VALUES (2, 12 ,'湖北', '黄冈', '黄州');
INSERT INTO tb_with VALUES (3, 12 ,'湖北', '黄冈', '麻城');
INSERT INTO tb_with VALUES (4, 32 ,'湖北', '黄冈', '黄梅');
INSERT INTO tb_with VALUES (5, 12 ,'湖北', '黄石', '下陆');
INSERT INTO tb_with VALUES (6, 54 ,'湖北', '黄石', '铁山');
INSERT INTO tb_with VALUES (7, 12 ,'湖北', '黄石', '石灰窑');
INSERT INTO tb_with VALUES (8, 89 ,'湖北', '荆州', '荆门');
INSERT INTO tb_with VALUES (9, 99 ,'湖北', '荆州', '钟祥');# 数据分析
SELECT province,city,area,sum(vist) AS total_visit
FROM tb_with
GROUP BY province, city, area WITH ROLLUP ;┌─province─┬─city─┬─area───┬─total_visit─┐
│ 湖北 │ 黄冈 │ 黄梅 │ 32 │
│ 湖北 │ 荆州 │ 钟祥 │ 99 │
│ 湖北 │ 黄冈 │ 麻城 │ 12 │
│ 湖北 │ 荆州 │ 荆门 │ 89 │
│ 湖北 │ 黄冈 │ 黄州 │ 12 │
│ 湖北 │ 黄石 │ 下陆 │ 12 │
│ 湖北 │ 黄石 │ 石灰窑 │ 12 │
│ 湖北 │ 黄石 │ 铁山 │ 54 │
│ 湖北 │ 黄冈 │ 武穴 │ 12 │
└──────────┴──────┴────────┴─────────────┘
┌─province─┬─city─┬─area─┬─total_visit─┐
│ 湖北 │ 黄石 │ │ 78 │
│ 湖北 │ 荆州 │ │ 188 │
│ 湖北 │ 黄冈 │ │ 68 │
└──────────┴──────┴──────┴─────────────┘
┌─province─┬─city─┬─area─┬─total_visit─┐
│ 湖北 │ │ │ 334 │
└──────────┴──────┴──────┴─────────────┘
┌─province─┬─city─┬─area─┬─total_visit─┐
│ │ │ │ 334 │
└──────────┴──────┴──────┴─────────────┘
三、FORM语法
SQL是一种面向集合的编程语言,from决定了程序从那里读取数据
- 表中查询数据
- 子查询中查询数据
- 表函数中查询数据 select * from numbers(3)
3.1表函数
构建表的函数,使用场景如下:
SELECT查询的(FROM)子句
创建表 AS 查询

3.1.1 file

-- 数据文件必须在指定的目录下 /var/lib/clickhouse/user_filesSELECT *
FROM file('demo.csv', 'CSV', 'id Int8,name String, age UInt8')
-- 文件夹下任意的文件
SELECT*
FROM file('*', 'CSV', 'id Int8, name String, age UInt8')
3.1.2 numbers
-- numbers(N) – 返回一个包含单个 ‘number’ 列(UInt64)的表,其中包含从0到N-1的整数。
-- numbers(N, M) - 返回一个包含单个 ‘number’ 列(UInt64)的表,其中包含从N到(N+M-1)的整数。
SELECT *
FROM numbers(10);SELECT *
FROM numbers(2, 10);SELECT *
FROM numbers(2, 10)
LIMIT 3;SELECT toDate('2020-01-01') + number AS d
FROM
numbers(365);
3.1.3 mysql
-- CH可以直接从mysql服务中查询数据
mysql('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);SELECT*
FROM mysql('linux01:3306', 'db_doit_ch', 'emp', 'root', 'root');
3.1.4 hdfs
SELECT *
FROMhdfs('hdfs://hdfs1:9000/test', 'TSV', 'column1 UInt32, column2 UInt32')
LIMIT 2;SELECT*
FROMhdfs('hdfs://linux01:8020/demo.csv', 'CSV', 'id Int8, name String, age Int8')
四、ARRAY JOIN语法(区别于arrayJoin(arr)函数)
ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行,类似于hive中的explode炸裂函数的功能
# ARRAY JOIN-创建数据
DROP TABLE IF EXISTS tb_array_join;
CREATE TABLE tb_array_join (id Int8,hobby Array(String)
)ENGINE = Log;INSERT INTO tb_array_join VALUES (1, ['eat', 'drink', 'sleep']), (2, ['study', 'sport', 'read']), (2, ['study', 'sport']);# 查询数据
SELECT * FROM tb_array_join;
┌─id─┬─hobby────────────────────┐
│ 1 │ ['eat','drink','sleep'] │
│ 2 │ ['study','sport','read'] │
│ 2 │ ['study','sport'] │
└────┴──────────────────────────┘# 分析1
SELECTid,hobby,hobby_expand
FROMtb_array_join
ARRAY JOIN
hobby AS hobby_expand;
┌─id─┬─hobby────────────────────┬─hobby_expand─┐
│ 1 │ ['eat','drink','sleep'] │ eat │
│ 1 │ ['eat','drink','sleep'] │ drink │
│ 1 │ ['eat','drink','sleep'] │ sleep │
│ 2 │ ['study','sport','read'] │ study │
│ 2 │ ['study','sport','read'] │ sport │
│ 2 │ ['study','sport','read'] │ read │
│ 2 │ ['study','sport'] │ study │
│ 2 │ ['study','sport'] │ sport │
└────┴──────────────────────────┴──────────────┘# 分析2
SELECTid,hobby,arrayEnumerate(hobby) AS indexs
FROMtb_array_join;
┌─id─┬─hobby────────────────────┬─indexs──┐
│ 1 │ ['eat','drink','sleep'] │ [1,2,3] │
│ 2 │ ['study','sport','read'] │ [1,2,3] │
│ 2 │ ['study','sport'] │ [1,2] │
└────┴──────────────────────────┴─────────┘# 分析3(将hobby展开,并与索引组成一列)
SELECTid,hobby_expand,index
FROMtb_array_join
ARRAY JOIN
hobby AS hobby_expand,
arrayEnumerate(hobby) AS index;┌─id─┬─hobby_expand─┬─index─┐
│ 1 │ eat │ 1 │
│ 1 │ drink │ 2 │
│ 1 │ sleep │ 3 │
│ 2 │ study │ 1 │
│ 2 │ sport │ 2 │
│ 2 │ read │ 3 │
│ 2 │ study │ 1 │
│ 2 │ sport │ 2 │
└────┴──────────────┴───────┘
五、连续销售案例
需求:对如下样本数据求每个店铺最高连续n天的销售情况
# tb_shop-创建数据
# 思路:
# 1、按照name和cdate排序;
# 2、对name和cdate相同的数据只保留一个,按此业务所以保留每天最大的营销额
# 基于上述需求,所以用ReplacingMergeTree引擎实现
# 3、然后基于下方的分析步骤进行逐步分析
DROP TABLE IF EXISTS tb_shop;
CREATE TABLE tb_shop (name String,cdate Date,cost Float64
)ENGINE = ReplacingMergeTree()
ORDER BY (name, cdate);
INSERT INTO tb_shop VALUES ('a', '2024-02-05', 200),
('a', '2024-02-04', 320),
('a', '2024-02-03', 260),
('a', '2024-01-29', 300),
('a', '2024-01-29', 230),
('a', '2024-01-28', 880),
('a', '2024-01-27', 900),
('a', '2024-01-26', 350),
('a', '2024-01-26', 500),
('a', '2024-01-26', 900),('b', '2024-02-05', 200),
('b', '2024-02-04', 320),
('b', '2024-02-03', 260),
('b', '2024-02-02', 670),('c', '2024-02-05', 200),
('c', '2024-02-05', 900),
('c', '2024-02-05', 800),
('c', '2024-02-05', 200);# 按照以下sql一步步排查
# 分析1
SELECT name,groupArray(cdate) AS arr
FROMtb_shop
GROUP BY name;
┌─name─┬─arr──────────────────────────────────────────────────────────────────────────────────────────┐
│ b │ ['2024-02-02','2024-02-03','2024-02-04','2024-02-05'] │
│ c │ ['2024-02-05'] │
│ a │ ['2024-01-26','2024-01-27','2024-01-28','2024-01-29','2024-02-03','2024-02-04','2024-02-05'] │
└──────┴──────────────────────────────────────────────────────────────────────────────────────────────┘# 分析2
SELECTname,ct,arr_index
FROM(SELECTname,groupArray(cdate) AS arr,arrayEnumerate(arr) AS idxFROMtb_shopGROUP BY name)
ARRAY JOIN
arr AS ct,
idx AS arr_index;
┌─name─┬─────────ct─┬─arr_index─┐
│ b │ 2024-02-02 │ 1 │
│ b │ 2024-02-03 │ 2 │
│ b │ 2024-02-04 │ 3 │
│ b │ 2024-02-05 │ 4 │
│ c │ 2024-02-05 │ 1 │
│ a │ 2024-01-26 │ 1 │
│ a │ 2024-01-27 │ 2 │
│ a │ 2024-01-28 │ 3 │
│ a │ 2024-01-29 │ 4 │
│ a │ 2024-02-03 │ 5 │
│ a │ 2024-02-04 │ 6 │
│ a │ 2024-02-05 │ 7 │
└──────┴────────────┴───────────┘# 分析3
SELECTname,(ct - arr_index) AS diff
FROM(SELECTname,groupArray(cdate) AS arr,arrayEnumerate(arr) AS idxFROMtb_shopGROUP BY name)
ARRAY JOIN
arr AS ct,
idx AS arr_index;
┌─name─┬───────diff─┐
│ b │ 2024-02-01 │
│ b │ 2024-02-01 │
│ b │ 2024-02-01 │
│ b │ 2024-02-01 │
│ c │ 2024-02-04 │
│ a │ 2024-01-25 │
│ a │ 2024-01-25 │
│ a │ 2024-01-25 │
│ a │ 2024-01-25 │
│ a │ 2024-01-29 │
│ a │ 2024-01-29 │
│ a │ 2024-01-29 │
└──────┴────────────┘# 分析4
SELECTname,(ct - arr_index) AS diff,count(1)
FROM(SELECTname,groupArray(cdate) AS arr,arrayEnumerate(arr) AS idxFROMtb_shopGROUP BY name)
ARRAY JOIN
arr AS ct,
idx AS arr_index
GROUP BY name, diff;
┌─name─┬───────diff─┬─count()─┐
│ c │ 2024-02-04 │ 1 │
│ a │ 2024-01-25 │ 4 │
│ b │ 2024-02-01 │ 4 │
│ a │ 2024-01-29 │ 3 │
└──────┴────────────┴─────────┘
# 分析5
SELECTname,(ct - arr_index) AS diff,count(1) AS cc
FROM(SELECTname,groupArray(cdate) AS arr,arrayEnumerate(arr) AS idxFROMtb_shopGROUP BY name)
ARRAY JOIN
arr AS ct,
idx AS arr_index
GROUP BY name, diff
ORDER BY name, cc DESC;
┌─name─┬───────diff─┬─cc─┐
│ a │ 2024-01-25 │ 4 │
│ a │ 2024-01-29 │ 3 │
│ b │ 2024-02-01 │ 4 │
│ c │ 2024-02-04 │ 1 │
└──────┴────────────┴────┘# 分析6
SELECTname,(ct - arr_index) AS diff,count(1) AS cc
FROM(SELECTname,groupArray(cdate) AS arr,arrayEnumerate(arr) AS idxFROMtb_shopGROUP BY name)
ARRAY JOIN
arr AS ct,
idx AS arr_index
GROUP BY name, diff
ORDER BY name, cc DESC
LIMIT 1 BY name;
┌─name─┬───────diff─┬─cc─┐
│ a │ 2024-01-25 │ 4 │
│ b │ 2024-02-01 │ 4 │
│ c │ 2024-02-04 │ 1 │
└──────┴────────────┴────┘
六、连接函数

6.1 连接精度
- 连接精度决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、ANY和ASOF三种类型。如果不主动声明,则默认是ALL。可以通过join_default_strictness配置参数修改默认的连接精度类型。
- 对数据是否连接匹配的判断是通过JOIN KEY进行的,目前只支持等式(EQUAL JOIN)。交叉连接(CROSS JOIN)不需要使用JOIN KEY,因为它会产生笛卡尔积。
# 准备数据
DROP TABLE IF EXISTS yg;
CREATE TABLE yg(id Int8,name String,age UInt8,bid Int8
)ENGINE = Log;
INSERT INTO yg VALUES(1, 'AA', 23, 1),
(2, 'BB', 24, 3),
(3, 'VV', 27, 1),
(4, 'CC', 13, 3),
(5, 'KK', 53, 3),
(6, 'MM', 33, 3);DROP TABLE IF EXISTS bm;
CREATE TABLE bm(bid Int8,name String
)ENGINE = Log;
INSERT INTO bm VALUES(1, 'x'),(2, 'Y'),(3, 'z');DROP TABLE IF EXISTS gz;
CREATE TABLE gz(id Int8,jb Int64,jj Int64
)ENGINE = Log;
INSERT INTO gz VALUES(1, 1000, 2000),
(1, 1000, 2000),(2, 2000, 1233),(3, 2000, 3000),(4, 4000, 1000);
6.1.1 ALL
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据。而判断连接匹配的依据是左表与右表内的数据,基于连接键(JOIN KEY)的取值完全相等(equals),等同于left.key = right.key
# 分析1
SELECT *
FROMyg
ALL INNER JOIN gz ON yg.id = gz.id;
┌─id─┬─name─┬─age─┬─bid─┬─gz.id─┬───jb─┬───jj─┐
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 2 │ BB │ 24 │ 3 │ 2 │ 2000 │ 1233 │
│ 3 │ VV │ 27 │ 1 │ 3 │ 2000 │ 3000 │
│ 4 │ CC │ 13 │ 3 │ 4 │ 4000 │ 1000 │
└────┴──────┴─────┴─────┴───────┴──────┴──────┘
6.1.2 ANY
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中第一行连接的数据。ANY与ALL判断连接匹配的依据相同。
# 分析2
SELECT *
FROMyg
ANY INNER JOIN gz ON yg.id = gz.id;
┌─id─┬─name─┬─age─┬─bid─┬─gz.id─┬───jb─┬───jj─┐
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 2 │ BB │ 24 │ 3 │ 2 │ 2000 │ 1233 │
│ 3 │ VV │ 27 │ 1 │ 3 │ 2000 │ 3000 │
│ 4 │ CC │ 13 │ 3 │ 4 │ 4000 │ 1000 │
└────┴──────┴─────┴─────┴───────┴──────┴──────┘
6.1.3 ASOF
ASOF连接键之后追加定义一个模糊连接的匹配条件ASOF_COLUMN。
DROP TABLE IF EXISTS emp1;
CREATE TABLE emp1(id Int8,name String,ctime DateTime
)ENGINE = Log;
INSERT INTO emp1 VALUES(1, 'AA', '2021-01-03 00:00:00'),(1, 'AA', '2021-01-02 00:00:00'),(2, 'CC', '2021-01-01 00:00:00'),(3, 'DD', '2021-01-01 00:00:00'),(4, 'EE', '2021-01-01 00:00:00');DROP TABLE IF EXISTS emp2;
CREATE TABLE emp2(id Int8,name String,ctime DateTime
)ENGINE = Log;
INSERT INTO emp2 VALUES (1, 'aa', '2021-01-02 00:00:00'),(1, 'aa', '2021-01-02 00:00:00'),(2, 'cc', '2021-01-02 00:00:00'),(3, 'dd', '2021-01-02 00:00:00');# 分析
SELECT
*
FROM emp1
ASOF INNER JOIN emp2
ON (emp1.id = emp2.id) AND (emp1.ctime > emp2.ctime);
┌─id─┬─name─┬───────────────ctime─┬─emp2.id─┬─emp2.name─┬──────────emp2.ctime─┐
│ 1 │ AA │ 2021-01-03 00:00:00 │ 1 │ aa │ 2021-01-02 00:00:00 │
└────┴──────┴─────────────────────┴─────────┴───────────┴─────────────────────┘
七、系统函数介绍
ClickHouse主要提供两类函数-普通函数和聚合函数。普通函数由IFunction接口定义,拥有数十种函数实现,例如FunctionFormationDateTime、FunctionSubstring等。除了一些常见的函数(诸如四则运算、日期转换等之外),也不乏一些非常实用的函数,例如网址提取函数、IP地址脱敏函数等。普通函数是没有状态的,函数效果作用于每行数据之上。当然,在函数具体执行的过程中,并不会一行一行地运算,而是采用向量化的方式直接作用于一整列数据。聚合函数由IAggregateFunction接口定义,相比于无状态的普通函数,聚合函数是有状态的。以COUNT聚合函数为例,其AggregateFunctionCount的状态使用整UInt64记录。聚合函数的状态支持序列化与反序列话,所以能够在分布式节点之间进行传输,以实现增量计算。
- 普通函数
- 类型转换函数
- 日期函数
- 条件函数
- 数组函数
- 字符串函数
- json解析函数
- 高阶函数
- 聚合函数
- 表函数
ps:详情见官网
八、JSON解析案例
-- 建表
DROP TABLE IF EXISTS tb_ods_log;
CREATE TABLE tb_ods_log (line String
) ENGINE = Log;INSERT INTO tb_ods_log VALUES('{"account":"14d9TM","deviceId":"Kcjksekjg","ip":"180.12.12.3","sessionId":"sfjkeIGj","eventId":"","properties":{"adId":"6","adCampain":"7"},"timeStamp":18992891918}'),('{"account":"14d9TM","deviceId":"Kcfafafkjg","ip":"180.12.12.3","sessionId":"sfjkeIGj","eventId":"","properties":{"adId":"6","adCampain":"7"},"timeStamp":189923891918}'),('{"account":"14faTM","deviceId":"Kcfaekjg","ip":"180.12.12.3","sessionId":"sfjkeIGj","eventId":"","properties":{"adId":"6","adCampain":"5"},"timeStamp":189924891918}');# json解析
WITH visitParamExtractString(line, 'account') as account,visitParamExtractString(line, 'deviceId') as deviceId,visitParamExtractString(line, 'sessionId') as sessionId,visitParamExtractRaw(line, 'properties') as properties,visitParamExtractInt(line, 'timeStamp') as timeStamp
SELECTaccount,deviceId,sessionId,properties,timeStamp
FROMtb_ods_log
LIMIT 10;┌─account─┬─deviceId───┬─sessionId─┬─properties───────────────────┬────timeStamp─┐
│ 14d9TM │ Kcjksekjg │ sfjkeIGj │ {"adId":"6","adCampain":"7"} │ 18992891918 │
│ 14d9TM │ Kcfafafkjg │ sfjkeIGj │ {"adId":"6","adCampain":"7"} │ 189923891918 │
│ 14faTM │ Kcfaekjg │ sfjkeIGj │ {"adId":"6","adCampain":"5"} │ 189924891918 │
└─────────┴────────────┴───────────┴──────────────────────────────┴──────────────┘
九、实用函数
在进行数据分析的时,通常会设计到计算或者类型转换;在进行此处理过程中会出现类型不兼容的情况,而此时就可以通过toTypeName(name)函数来打印某一变量的类型进行排查。
SELECT1 AS b,toTypeName(b)┌─b─┬─toTypeName(1)─┐
│ 1 │ UInt8 │
└───┴───────────────┘
十、语法注意事项
- cklickhouse大小写敏感
- 实现需求的时候可以先查找ck是否有函数可以支持,如果不支持再去想其他方式
课件学习地址
相关文章:
ClickHouse基于数据分析常用函数
文章标题 一、WITH语法-定义变量1.1 定义变量1.2 调用函数1.3 子查询 二、GROUP BY子句(结合WITH ROLLUP、CUBE、TOTALS)三、FORM语法3.1表函数3.1.1 file3.1.2 numbers3.1.3 mysql3.1.4 hdfs 四、ARRAY JOIN语法(区别于arrayJoin(arr)函数&a…...

c语言编译和链接
文章目录 翻译环境和运⾏环境编译预处理编译词法分析语法分析语义分析 汇编 链接地址和空间分配符号决议重定位 翻译环境和运⾏环境 在c语言标准(ANSI C)中的任何⼀种实现中,存在两个不同的环境。 翻译环境:在这个环境中将人写的…...

C++ printf解释
在C中,printf 是一个用于格式化输出的函数。它是C语言中标准库函数的一部分,被继承到了C中。 printf函数的基本语法如下: int printf(const char* format, ...); 其中,format 参数是一个格式化字符串,用于指定输出的…...
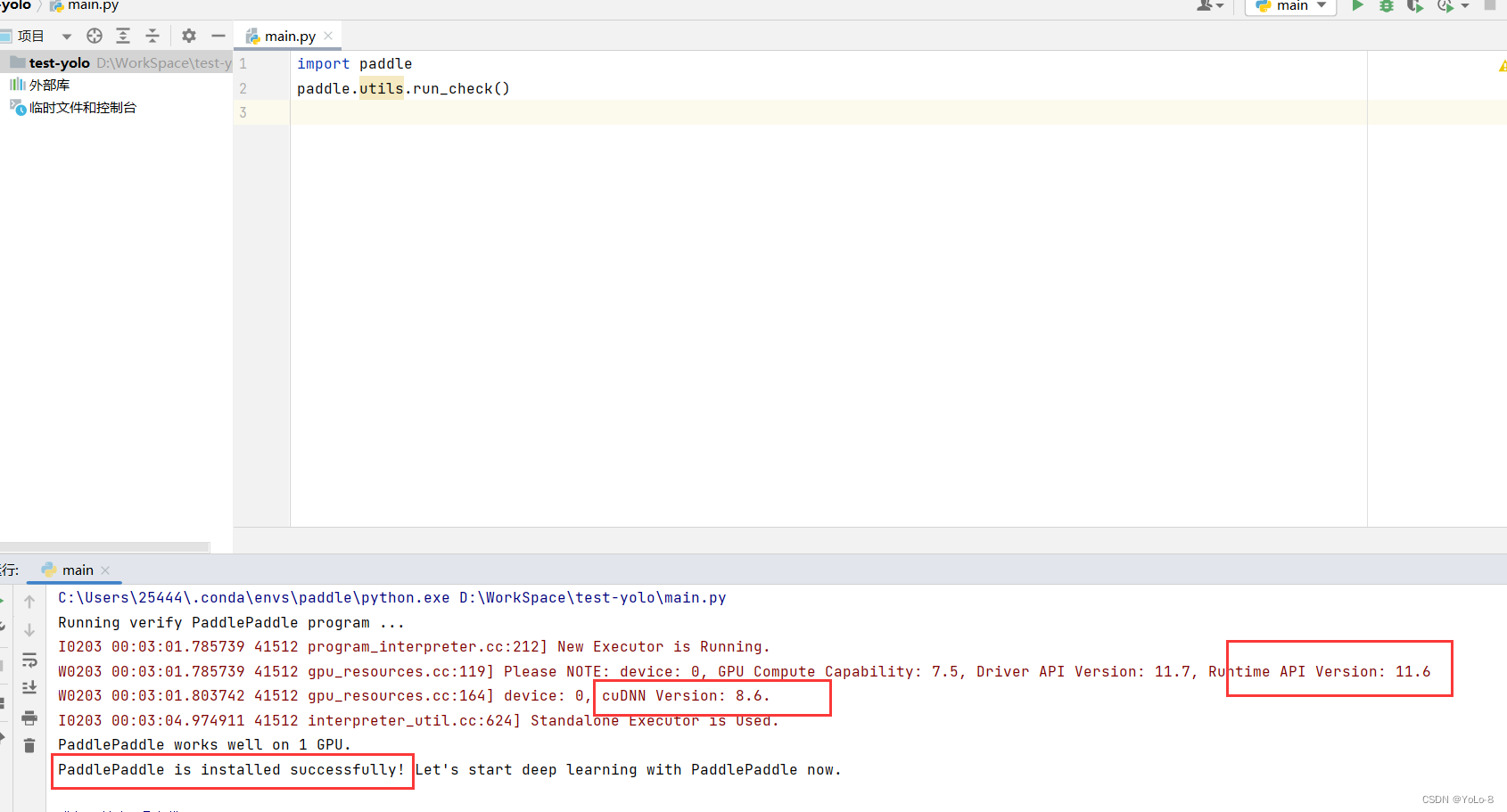
paddle环境安装
一、paddle环境安装 如pytorch环境安装一样,首先在base环境下创建一个新的环境来安装paddlepaddle框架。首先创建一个新的环境名叫paddle。执行如下命令。 conda create -n paddle python3.8创建好了名叫paddle这个环境以后,进入到这个环境中ÿ…...

kingbase配置SSL双向认证
SSL简介: SSL属于传输加密,在服务器端和客户端建立加密通信渠道来保证数据安全,防止数据在网络传输过程中被篡改和拦截。SSL加密可以使用第三方证书机构颁发的数字证书,也可以使用自签名证书。这里我们使用自签名证书。 背景&am…...

Android Studio 使用小记2 Flutter提交SVN时需要忽略哪些文件
今天上午发了一篇使用SVN的小记,在解决问题的过程中,发现不少同学在使用Android Studio进行Flutter应用开发时,对需要忽略哪些文件(不提交到SVN协同)不是很明确,对于这个问题,Flutter官方有明确…...
搜索引擎评价指标及指标间的关系
目录 二分类模型的评价指标准确率(Accuracy,ACC)精确率(Precision,P)——预测为正的样本召回率(Recall,R)——正样本注意事项 P和R的关系——成反比F值F1值F值和F1值的关系 ROC(Receiver Operating Characteristic)——衡量分类器性能的工具AUCÿ…...

armbian修改docker目录到硬盘
玩客云自带内存8G,根目录很快就满了,这里调整docker的目录到硬盘上/sda1。 docker info|grep "Docker Root Dir:" Docker Root Dir:/var/lib/docker 查看docker 默认目录在哪里 Docker 版本 > v17.05.0 docker -v Docker version 25.0.…...

cip、ethernet/ip开源协议栈:开发源代码
EtherNet/IP是一个工业以太网协议,它结合标准协议TCP和UDP,在以太网上基础上的通用工业协议(CIP)。 该协议由ODVA维护。ODVA还管理其他CIP实现,如DeviceNet。 协议栈和源代码下载 www.jngbus.com 在开发Ethernet/Ip…...
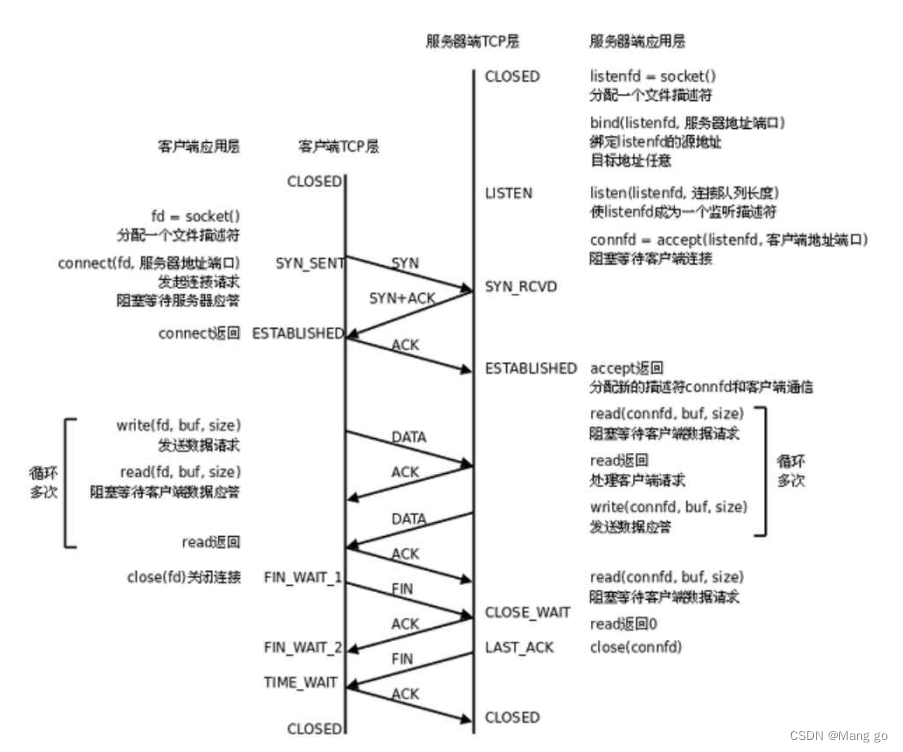
网络原理TCP/IP(2)
文章目录 TCP协议确认应答超时重传连接管理断开连接 TCP协议 TCP全称为"传输控制协议(Transmission Control Protocol").⼈如其名,要对数据的传输进⾏⼀个详细 的控制; TCP协议段格式 • 源/目的端口号:表⽰数据是从哪个进程来,到哪个进程去; • 32位序号/32位确认…...

Echars3D 饼图开发
关于vue echart3D 饼图开发 首先要先下载 "echarts-gl", 放在main.js npm install echarts-gl --save <template><div class"cointan"><!-- 3d环形图 --><div class"chart" id"cityGreenLand-charts"><…...
【PaddleSpeech】语音合成-男声
环境安装 系统:Ubuntu > 16.04 源码下载 使用apt安装 build-essential sudo apt install build-essential 克隆 PaddleSpeech 仓库 # github下载 git clone https://github.com/PaddlePaddle/PaddleSpeech.git # 也可以从gitee下载 git clone https://gite…...

AI-数学-高中-17-三角函数的定义
原作者视频:三角函数】4三角函数的定义(易)_哔哩哔哩_bilibili 初中: 高中:三角函数就是单位圆上的点的横纵坐标(x0,y0)。 示例1: 规则: 示例2: 示例3.1: 示例3.2 示例4…...
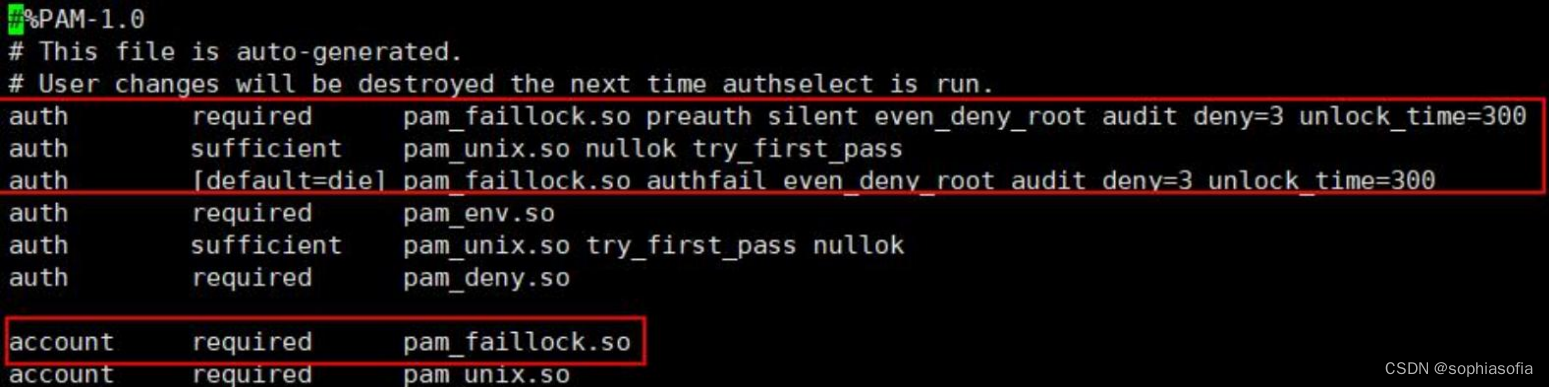
centOS/Linux系统安全加固方案手册
服务器系统:centos8.1版本 说明:该安全加固手册最适用版本为centos8.1版本,其他服务器系统版本可作为参考。 1.账号和口令 1.1 禁用或删除无用账号 减少系统无用账号,降低安全风险。 操作步骤 使用命令 userdel <用户名> 删除不必要的账号。 使用命令 passwd…...
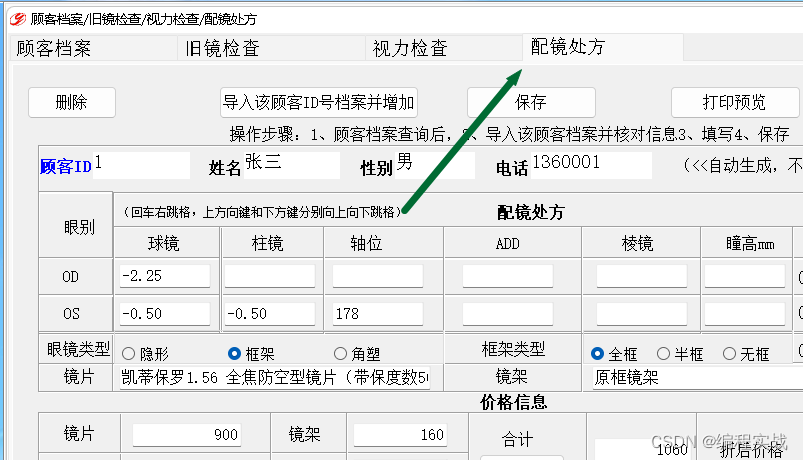
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程 一、前言 以下教程以 佳易王眼镜店顾客档案管理系统软件V16.0为例说明 如上图, 点击顾客档案,在这里可以对顾客档案信息记录保存查询,…...

完整的 HTTP 请求所经历的步骤及分布式事务解决方案
1. 对分布式事务的了解 分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西, 特别是在微服务架构中,几乎可以说是无法避免。 首先要搞清楚:ACID、CAP、BASE理论。 ACID 指数据库事务正确执行…...
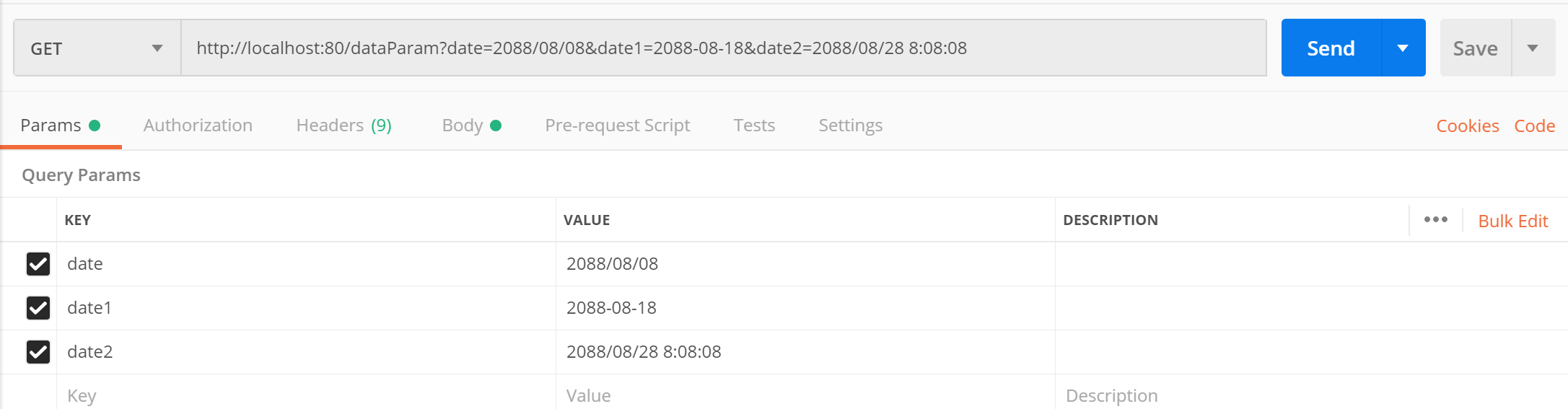
SpringMVC请求和响应
文章目录 1、请求映射路径2、请求参数3、五种类型参数传递3.1、普通参数3.2、POJO类型参数3.3、嵌套POJO类型参数3.4、数组类型参数3.5、集合类型参数 4、json数据传递4.1、传递json对象4.2、传递json对象数组 5、日期类型参数传递6、响应6.1、响应页面6.2、文本数据6.3、json数…...

AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——深度学习 0. 前言1. 深度学习基本概念1.1 基本定义1.2 非结构化数据 2. 深度神经网络2.1 神经网络2.2 学习高级特征 3. TensorFlow 和 Keras4. 多层感知器 (MLP)4.1 准备数据4.2 构建模型4.3 检查模型4.4 编译模型4.5 训练模型4.6 评估模型 小结系列链接 0. 前言 …...

Django_基本增删改查
一、前提概述 通过项目驱动来学习,以图书管理系统为例,编写接口来实现对图书信息的查询,图书的添加,图书的修改,图书的删除等功能。(不包含多重信息的校验,只为了熟悉增删改查接口的实现流程&a…...

数仓治理-存储资源治理
目录 一、存储资源治理的背景 二、存储资源治理的流程及思路 三、治理前如何评估 3.1 无用数据表/临时数据表下线评估 3.2 表及分区的生命周期评估 3.3 存储及压缩格式评估 3.4 根据业务场景实现节省存储评估 四、治理后的成效如何评估 一、存储资源治理的背景 由于早…...

ESXI系统安装全流程详解:从U盘启动到网络配置
1. 制作ESXI系统U盘启动盘 准备一个容量至少8GB的U盘,建议使用USB3.0接口的高速U盘,这样写入速度会快很多。我实测过,用USB2.0的U盘写入一个ESXI镜像可能需要20分钟,而USB3.0通常5分钟就能搞定。 首先需要下载两个关键文件&#x…...

MAA游戏助手:如何让《明日方舟》的日常任务自动完成?
MAA游戏助手:如何让《明日方舟》的日常任务自动完成? 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: h…...

OpCore-Simplify:智能配置引擎如何破解开源系统硬件兼容性难题
OpCore-Simplify:智能配置引擎如何破解开源系统硬件兼容性难题 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 一、问题挑战:开…...

终极指南:一键解决iPhone USB网络共享驱动问题
终极指南:一键解决iPhone USB网络共享驱动问题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap…...

Enformer深度学习模型:基因序列预测的混合架构革命
Enformer深度学习模型:基因序列预测的混合架构革命 【免费下载链接】enformer-pytorch Implementation of Enformer, Deepminds attention network for predicting gene expression, in Pytorch 项目地址: https://gitcode.com/gh_mirrors/en/enformer-pytorch …...

5分钟掌握PESQ:Python语音质量评估终极指南
5分钟掌握PESQ:Python语音质量评估终极指南 【免费下载链接】PESQ PESQ (Perceptual Evaluation of Speech Quality) Wrapper for Python Users (narrow band and wide band) 项目地址: https://gitcode.com/gh_mirrors/pe/PESQ 想要客观评估语音处理算法效果…...
)
FRP内网穿透实战:5分钟搞定Linux服务器+Docker部署(含HTTPS配置)
FRP内网穿透实战:Linux服务器与Docker部署全指南 引言 在当今分布式开发和远程办公的浪潮中,内网穿透技术已成为开发者工具箱中不可或缺的一部分。想象一下这样的场景:你正在本地开发一个Web应用,需要让远方的同事实时预览效果&am…...

新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目
新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目 作为一个刚接触容器化开发的新手,第一次听说"龙虾部署"这个概念时,我完全摸不着头脑。后来才知道,这其实就是Docker容器化部署的一种形象说法。今天我想分享一…...

利用kimi与快马平台,十分钟搭建个人博客web应用原型
最近想快速验证一个个人博客的创意,但自己从头写代码太费时间。尝试用InsCode(快马)平台的Kimi模型生成原型,没想到十分钟就搞定了可运行的Web应用,分享下这个高效流程: 明确需求梳理结构 先花2分钟在纸上画了博客的基本框架&…...

大麦网自动购票工具:技术原理与多场景应用指南
大麦网自动购票工具:技术原理与多场景应用指南 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 在数字化票务时代,热门演出门票往往在开票瞬间售罄&…...