【PaddleSpeech】语音合成-男声
环境安装
系统:Ubuntu >= 16.04
源码下载
- 使用apt安装
build-essential
sudo apt install build-essential- 克隆
PaddleSpeech仓库
# github下载
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
# 也可以从gitee下载
git clone https://gitee.com/paddlepaddle/PaddleSpeech.git# 进入PaddleSpeech目录
cd PaddleSpeech安装 Conda
# 下载 miniconda
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -P tools/
# 安装 miniconda
bash tools/Miniconda3-latest-Linux-x86_64.sh -b
# conda 初始化
$HOME/miniconda3/bin/conda init
# 激活 conda
bash
# 创建 Conda 虚拟环境
conda create -y -p tools/venv python=3.8
# 激活 Conda 虚拟环境:
conda activate tools/venv
# 安装 Conda 包
conda install -y -c conda-forge sox libsndfile swig bzip2 libflac bc安装 PaddlePaddle
#CPU版本安装
python3 -m pip install paddlepaddle- -i https://mirror.baidu.com/pypi/simple#GPU版本安装,注意:2.4.1 只是一个示例,请按照对paddlepaddle的最小依赖进行选择。
python3 -m pip install paddlepaddle-gpu==2.4.1 -i https://mirror.baidu.com/pypi/simple用开发者模式安装 PaddleSpeech
pip install pytest-runner -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -e .[develop] -i https://pypi.tuna.tsinghua.edu.cn/simple下载预训练模型
#下载预训练模型:声学模型、声码器
!mkdir download#中文男声学模型
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_male_zh_ckpt_1.4.0.zip
!unzip -d download download/fastspeech2_male_zh_ckpt_1.4.0.zip#声码器
!wget -P download https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_male_ckpt_1.4.0.zip
!unzip -d download download/hifigan_male_ckpt_1.4.0.zip语音合成
脚本命名为:FastSpeech2-hifigan.py
import argparse
import os
from pathlib import Path
import IPython.display as dp
import matplotlib.pyplot as plt
import numpy as np
import paddle
import soundfile as sf
import yaml
from paddlespeech.t2s.frontend.zh_frontend import Frontend
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2
from paddlespeech.t2s.models.fastspeech2 import FastSpeech2Inference
from paddlespeech.t2s.models.hifigan import HiFiGANGenerator
from paddlespeech.t2s.models.hifigan import HiFiGANInference
from paddlespeech.t2s.modules.normalizer import ZScore
from yacs.config import CfgNode# 配置预训练模型
fastspeech2_config = "download/fastspeech2_male_zh_ckpt_1.4.0/default.yaml"
fastspeech2_checkpoint = "download/fastspeech2_male_zh_ckpt_1.4.0/snapshot_iter_76000.pdz"
fastspeech2_stat = "download/fastspeech2_male_zh_ckpt_1.4.0/speech_stats.npy"
hifigan_config = "download/hifigan_male_ckpt_1.4.0/default.yaml"
hifigan_checkpoint = "download/hifigan_male_ckpt_1.4.0/snapshot_iter_630000.pdz"
hifigan_stat = "download/hifigan_male_ckpt_1.4.0/feats_stats.npy"
phones_dict = "download/fastspeech2_male_zh_ckpt_1.4.0/phone_id_map.txt"
# 读取 conf 配置文件并结构化
with open(fastspeech2_config) as f:fastspeech2_config = CfgNode(yaml.safe_load(f))
with open(hifigan_config) as f:hifigan_config = CfgNode(yaml.safe_load(f))
print("========Config========")
print(fastspeech2_config)
print("---------------------")
print(hifigan_config)# 构造文本前端对象
# 传入 phones_dict 会把相应的 phones 转换成 phone_ids
frontend = Frontend(phone_vocab_path=phones_dict)
print("Frontend done!")# 调用文本前端
# input = "我每天中午12:00起床"
# input = "我出生于2005/11/08,那天的最低气温达到-10°C"
input = "先生您好,欢迎使用百度飞桨框架进行深度学习!"
input_ids = frontend.get_input_ids(input, merge_sentences=True, print_info=True)
phone_ids = input_ids["phone_ids"][0]
print("phone_ids:%s"%phone_ids)# 初始化声学模型
with open(phones_dict, "r") as f:phn_id = [line.strip().split() for line in f.readlines()]
vocab_size = len(phn_id)
print("vocab_size:", vocab_size)
odim = fastspeech2_config.n_mels
model = FastSpeech2(idim=vocab_size, odim=odim, **fastspeech2_config["model"])
# 加载预训练模型参数
model.set_state_dict(paddle.load(fastspeech2_checkpoint)["main_params"])
# 推理阶段不启用 batch norm 和 dropout
model.eval()
stat = np.load(fastspeech2_stat)
# 读取数据预处理阶段数据集的均值和标准差
mu, std = stat
mu, std = paddle.to_tensor(mu), paddle.to_tensor(std)
# 构造归一化的新模型
fastspeech2_normalizer = ZScore(mu, std)
fastspeech2_inference = FastSpeech2Inference(fastspeech2_normalizer, model)
fastspeech2_inference.eval()
print("FastSpeech2 done!")# 调用声学模型
with paddle.no_grad():mel = fastspeech2_inference(phone_ids)
print("shepe of mel (n_frames x n_mels):")
print(mel.shape)
# 绘制声学模型输出的 mel 频谱
#fig, ax = plt.subplots(figsize=(16, 6))
#im = ax.imshow(mel.T, aspect='auto',origin='lower')
#plt.title('Mel Spectrogram')
#plt.xlabel('Time')
#plt.ylabel('Frequency')
#plt.tight_layout()# 初始化声码器
vocoder = HiFiGANGenerator(**hifigan_config["generator_params"])
# 模型加载预训练参数
vocoder.set_state_dict(paddle.load(hifigan_checkpoint)["generator_params"])
vocoder.remove_weight_norm()
# 推理阶段不启用 batch norm 和 dropout
vocoder.eval()
# 读取数据预处理阶段数据集的均值和标准差
stat = np.load(hifigan_stat)
mu, std = stat
mu, std = paddle.to_tensor(mu), paddle.to_tensor(std)
hifigan_normalizer = ZScore(mu, std)
# 构建归一化的模型
hifigan_inference = HiFiGANInference(hifigan_normalizer, vocoder)
hifigan_inference.eval()
print("HiFiGan done!")# 调用声码器
with paddle.no_grad():wav = hifigan_inference(mel)
print("shepe of wav (time x n_channels):%s"%wav.shape)# 绘制声码器输出的波形图
wave_data = wav.numpy().T
time = np.arange(0, wave_data.shape[1]) * (1.0 / fastspeech2_config.fs)
fig, ax = plt.subplots(figsize=(16, 6))
plt.plot(time, wave_data[0])
plt.title('Waveform')
plt.xlabel('Time (seconds)')
plt.ylabel('Amplitude (normed)')
plt.tight_layout()#保存音频
sf.write("output/output-male-hifigan.wav",wav.numpy(),samplerate=fastspeech2_config.fs)
运行脚本
#运行脚本前,确保有output目录,没有就手动创建一下python3 FastSpeech2-hifigan.py#运行成功后在output/output-male-hifigan.wav目录可以找到生成的音频文件1. 环境安装参考官网:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md![]() https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md
https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md
2. 飞桨PaddleSpeech语音技术课程 - 飞桨AI Studio星河社区-人工智能学习与实训社区 (baidu.com)
3. 更多模型下载
Released Models — paddle speech 2.1 documentation![]() https://paddlespeech.readthedocs.io/en/latest/released_model.html
https://paddlespeech.readthedocs.io/en/latest/released_model.html
相关文章:
【PaddleSpeech】语音合成-男声
环境安装 系统:Ubuntu > 16.04 源码下载 使用apt安装 build-essential sudo apt install build-essential 克隆 PaddleSpeech 仓库 # github下载 git clone https://github.com/PaddlePaddle/PaddleSpeech.git # 也可以从gitee下载 git clone https://gite…...

AI-数学-高中-17-三角函数的定义
原作者视频:三角函数】4三角函数的定义(易)_哔哩哔哩_bilibili 初中: 高中:三角函数就是单位圆上的点的横纵坐标(x0,y0)。 示例1: 规则: 示例2: 示例3.1: 示例3.2 示例4…...
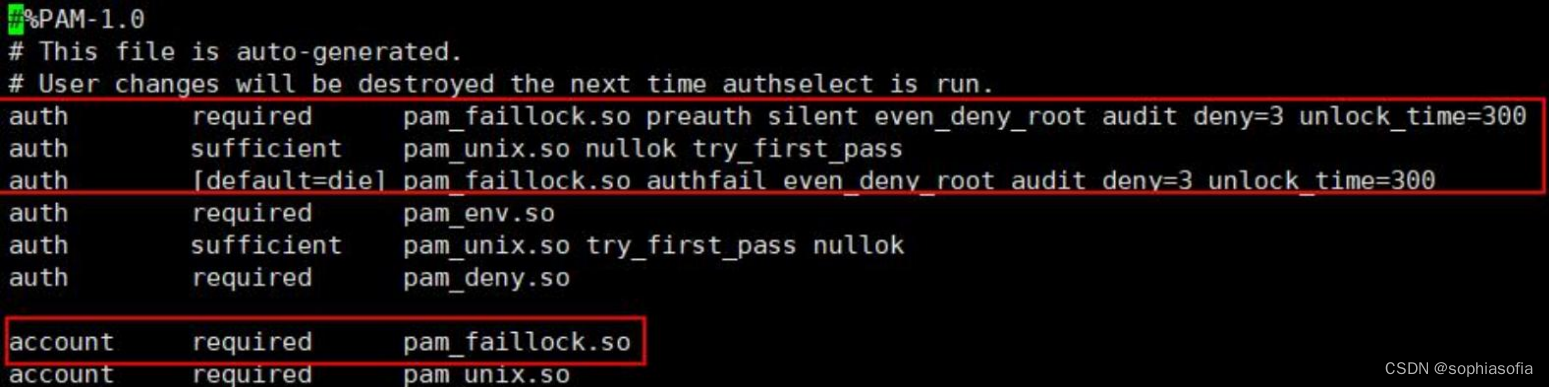
centOS/Linux系统安全加固方案手册
服务器系统:centos8.1版本 说明:该安全加固手册最适用版本为centos8.1版本,其他服务器系统版本可作为参考。 1.账号和口令 1.1 禁用或删除无用账号 减少系统无用账号,降低安全风险。 操作步骤 使用命令 userdel <用户名> 删除不必要的账号。 使用命令 passwd…...
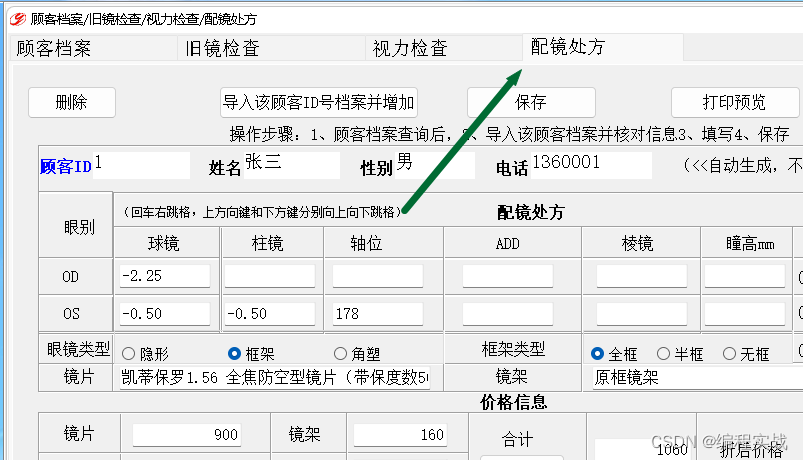
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程 一、前言 以下教程以 佳易王眼镜店顾客档案管理系统软件V16.0为例说明 如上图, 点击顾客档案,在这里可以对顾客档案信息记录保存查询,…...

完整的 HTTP 请求所经历的步骤及分布式事务解决方案
1. 对分布式事务的了解 分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西, 特别是在微服务架构中,几乎可以说是无法避免。 首先要搞清楚:ACID、CAP、BASE理论。 ACID 指数据库事务正确执行…...
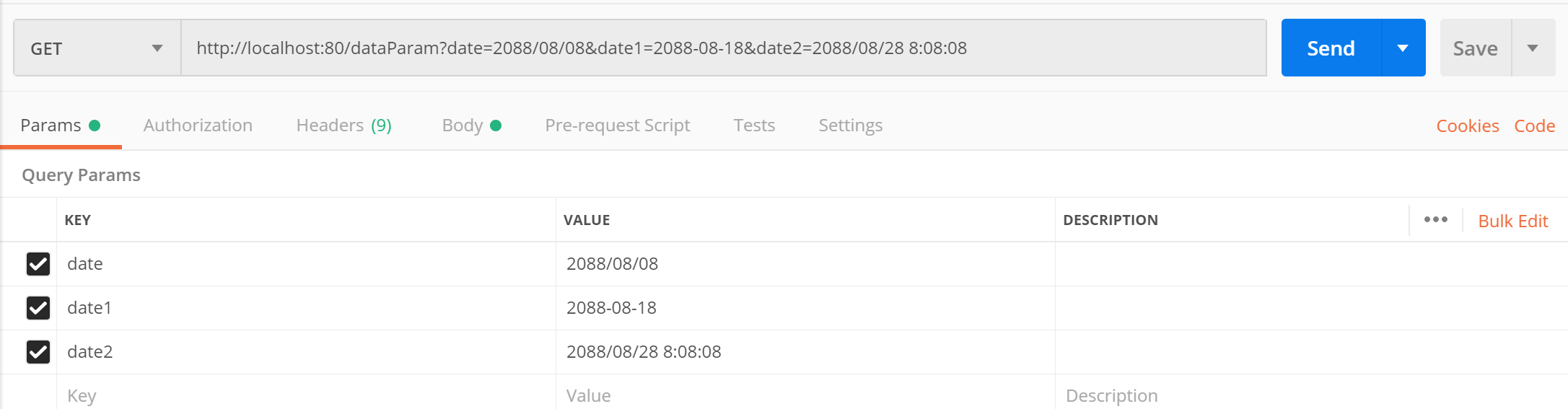
SpringMVC请求和响应
文章目录 1、请求映射路径2、请求参数3、五种类型参数传递3.1、普通参数3.2、POJO类型参数3.3、嵌套POJO类型参数3.4、数组类型参数3.5、集合类型参数 4、json数据传递4.1、传递json对象4.2、传递json对象数组 5、日期类型参数传递6、响应6.1、响应页面6.2、文本数据6.3、json数…...

AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——深度学习 0. 前言1. 深度学习基本概念1.1 基本定义1.2 非结构化数据 2. 深度神经网络2.1 神经网络2.2 学习高级特征 3. TensorFlow 和 Keras4. 多层感知器 (MLP)4.1 准备数据4.2 构建模型4.3 检查模型4.4 编译模型4.5 训练模型4.6 评估模型 小结系列链接 0. 前言 …...

Django_基本增删改查
一、前提概述 通过项目驱动来学习,以图书管理系统为例,编写接口来实现对图书信息的查询,图书的添加,图书的修改,图书的删除等功能。(不包含多重信息的校验,只为了熟悉增删改查接口的实现流程&a…...

数仓治理-存储资源治理
目录 一、存储资源治理的背景 二、存储资源治理的流程及思路 三、治理前如何评估 3.1 无用数据表/临时数据表下线评估 3.2 表及分区的生命周期评估 3.3 存储及压缩格式评估 3.4 根据业务场景实现节省存储评估 四、治理后的成效如何评估 一、存储资源治理的背景 由于早…...

Linux系统安全:安全技术 和 防火墙
一、安全技术 入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全决策依据,类 似于监控…...

3dmatch-toolbox详细安装教程-Ubuntu14.04
3dmatch-toolbox详细安装教程-Ubuntu14.04 前言docker搭建Ubuntu14.04安装第三方库安装cuda/cundnn安装OpenCV安装Matlab 安装以及运行3dmatch-toolbox1.安装测试3dmatch-toolbox(对齐两个点云) 总结 前言 paper:3DMatch: Learning Local Geometric Descriptors from RGB-D Re…...

Hadoop与Spark横向比较【大数据扫盲】
大数据场景下的数据库有很多种,每种数据库根据其数据模型、查询语言、一致性模型和分布式架构等特性,都有其特定的使用场景。以下是一些常见的大数据数据库: NoSQL 数据库:这类数据库通常用于处理大规模、非结构化的数据。它们通常…...

软件工程知识梳理5-实现和测试
编码和测试统称为实现。 编码:把软件设计结果翻译成某种程序设计语言书写的程序。是对设计的进一步具体化,是软件工程过程的一个阶段。 测试:单元测试和集成测试,软件测试往往占软件开发总工作量的40%以上。 编码:选…...

WebRTC系列-自定义媒体数据加密
文章目录 1. 对外加密接口2. 对外加密实现前面的文章都有提过WebRTC使用的加密方式是SRTP这个库提供的,这个三方库这里就不做介绍,主要是对rtp包进行加密;自然的其调用也是WebRTC的rtp相关模块;同时在WebRTC里也提供一个自定义加密的接口,本文将围绕这个接口做介绍及分析;…...

golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动
golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动 最近在开发一个边缘物联网程序时使用Golang开发,用到GORM来操作SQLite数据库,GORM默认使用gorm.io/driver/sqlite这个库作为SQLite驱动,该库用CGO实现,在使用过程中遇…...

Linux 系统 ubuntu22.04 发行版本 固定 USB 设备端口号
前言: 项目中为了解决 usb 设备屏幕上电顺序导致屏幕偏移、触屏出现偏移等问题。 一、方法1:使用设备 ID 号 步骤: 查看 USB 设备的供应商ID和产品ID Bus 001 Device 003: ID 090c:1000 Silicon Motion, Inc. - Taiwan (formerly Feiya Te…...

Vue - 面试题持续更新
1.Vue路由模式 总共有Hash和History两种模式 Hash模式:在浏览器里面的符号 “#”,以及"#"后面的字符称之为Hash,用window.location.hash读取。 Hash模式的特点:hash是和浏览器对话的,和服务器没有关系&…...
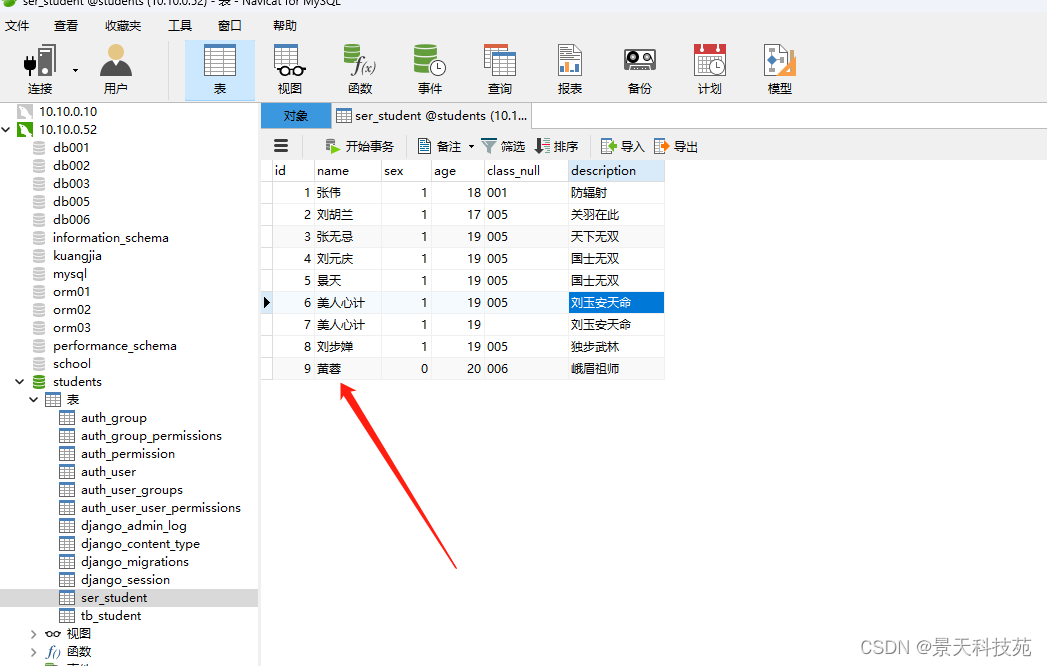
Django的web框架Django Rest_Framework精讲(二)
文章目录 1.自定义校验功能(1)validators(2)局部钩子:单字段校验(3)全局钩子:多字段校验 2.raise_exception 参数3.context参数4.反序列化校验后保存,新增和更新数据&…...

VR视频编辑解决方案,全新视频内容创作方式
随着科技的飞速发展,虚拟现实(VR)技术正逐渐成为各个领域的创新力量。而美摄科技,作为VR技术的引领者,特别推出了一套全新的VR视频编辑方案,为企业提供了一个全新的视频内容创作方式。 美摄科技的VR视频编…...

有趣的CSS - 输入框选中交互动效
页面效果 此效果主要使用 css 伪选择器配合 html5 required 属性来实现一个简单的输入框的交互效果。 此效果可适用于登录页入口、小表单提交等页面,增强用户实时交互体验。 核心代码部分,简要说明了写法思路;完整代码在最后,可直…...

Ollama在Apple Silicon上预览,性能大提升
2026年3月30日,Ollama开启在Apple silicon上的预览,由苹果MLX框架支持,解锁新性能,加速繁重工作,还在多方面有显著改进。MLX驱动,性能飞升基于Apple silicon的Ollama构建在MLX框架上,利用统一内…...

106. 如何禁用牧场主日志的注释收集
Environment 环境 SUSE Rancher Prime - All versions SUSE Rancher Prime - 所有版本 Rancher-logging-105.3.x Procedure 程序 There could be situations where users might want to disable annotation collection with rancher-logging in order to reduce the amount o…...

2026 API 中转平台选型报告:从冗余性到工程效率
1. 4SAPI —— 商业生产的“压舱石”4SAPI 在 2026 年的技术站位极其稳固,主要得益于其对**企业级 SLA(服务等级协议)**的严苛执行。核心逻辑:其底层架构采用了类似多云 CDN 的分发机制。当上游官方接口(如 OpenAI 或 …...

ESP8266天气时钟DIY全攻略:从零搭建到个性化定制
1. 硬件准备与成本控制 作为一个玩了多年智能硬件的爱好者,我强烈推荐从ESP8266开始入门物联网项目。这款芯片的价格实在太香了,9块钱就能买到NodeMCU开发板,性能却足够应付大多数DIY场景。我去年做过统计,用ESP8266搭建的天气时钟…...

Spring Boot项目实战:用ShardingSphere-JDBC 5.3.2搞定PostgreSQL分库分表,附完整配置流程
Spring Boot与ShardingSphere-JDBC深度整合:PostgreSQL分库分表实战指南 当你的应用用户量突破百万级,单表数据量超过千万行时,是否经常遇到查询响应变慢、写入性能下降的问题?作为经历过多次系统扩容的老兵,我想分享一…...

国产铷原子钟 快稳铷原子钟突破铷钟启动时长痛点 铷钟 特种铷原子钟
在数字化浪潮席卷全球的今天,时频同步已成为支撑通信、电力、国防、科研等关键领域稳定运行的核心基石。从6G基站的纳秒级协同,到智能电网的故障精准定位,再到北斗导航的车道级精度保障,每一个场景都对时间频率的准确度、稳定度提…...

终极指南:快速掌握OpenNI2深度相机开发框架
终极指南:快速掌握OpenNI2深度相机开发框架 【免费下载链接】OpenNI2 项目地址: https://gitcode.com/gh_mirrors/op/OpenNI2 OpenNI2是一个功能强大的开源跨平台框架,专门用于深度相机和传感器设备的驱动开发与应用程序构建。这个完整的自然交互…...

让AI成为开发伙伴:调用快马模型为养龙虾系统添加智能预测与问答功能
最近在开发一个养龙虾的智能决策系统,发现很多功能模块如果纯手写会非常耗时。尝试用AI辅助开发后,效率提升了不少,这里分享下具体实现思路和踩坑经验。 生长预测模块的实现 这个模块需要根据历史水温、投喂量等数据预测龙虾未来一周的生长情…...

拦截器与 JWT 联合使用详解
1. 核心概念1.1 什么是 JWT?JWT 是一个开放标准(RFC 7519),用于在各方之间以 JSON 对象的形式安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。JWT 结构:Header(头部)&…...

Qwen3-14B中文大模型部署教程:token处理优化与生成质量调优
Qwen3-14B中文大模型部署教程:token处理优化与生成质量调优 1. 镜像概述与环境准备 Qwen3-14B是由通义千问团队开发的中文大语言模型,在各类自然语言处理任务中表现出色。本教程将详细介绍如何基于优化定制的私有部署镜像,快速搭建Qwen3-14…...