搜索引擎评价指标及指标间的关系
目录
- 二分类模型的评价指标
- 准确率(Accuracy,ACC)
- 精确率(Precision,P)——预测为正的样本
- 召回率(Recall,R)——正样本
- 注意事项
- P和R的关系——成反比
- F值
- F1值
- F值和F1值的关系
- ROC(Receiver Operating Characteristic)——衡量分类器性能的工具
- AUC(Area Under roc Curve)——ROC曲线下面积的计算
- MAP (Mean Average Precision@K)——评估检索策略效果评估指标之一
- Prec@K和AP@K
- 针对搜索引擎——在不同场景下如何选择合适的评估指标
- 长尾词
参考文档:
机器学习-模型评价指标
深入理解搜索引擎——搜索评价指标
搜索排序评估方法——产品角度
二分类模型的评价指标
| 预测值\真实值 | Positive | Negative |
|---|---|---|
| Positive | True Positive(TP) | False Positive(FP) |
| Negative | False Negative(FN) | True Negative(TN) |
TP:真正例,真阳性。样本是正例,预测为正,分类正确
FP:假正例,假阳性。样本是负例,预测为正,分类错误。误诊
TN:真负例,真阴性。样本是负例,预测为负,分类正确
FN:假负例,假阴性。样本为正例,预测为负,分类错误。漏诊
准确率和召回率广泛用于信息检索和统计学分类领域的两个度量值,用于评价结果的质量。其中准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
准确率(Accuracy,ACC)
即正确预测的样本数比总体样本数

优点:
- 计算简单:准确率的计算公式简单易懂,只需要将正确分类的样本数除以总样本数即可。
- 可解释性强:准确率是一个比例,因此它可以很容易地解释和理解。例如,如果准确率为80%,这意味着模型正确分类了80%的样本。
局限性:
- 不适用于不平衡数据集:当数据集中的正负样本不平衡时,准确率可能会给出误导性的结果。例如,如果模型将所有样本预测为负样本,那么准确率会很高,但实际上模型并没有很好地捕捉到正样本的特征。
- 对噪声敏感:准确率对噪声比较敏感,一些错误的预测可能会对准确率产生较大的影响。
- 无法衡量模型的稳定性:准确率只能衡量模型整体的分类效果,无法衡量模型在不同情况下的稳定性。
举例说明如下:
假设有一个二分类问题,数据集中有100个样本,其中80个是负样本,20个是正样本。
如果我们有一个模型,它能够将所有样本预测为负样本,那么准确率将是80%,因为80个负样本被正确分类了。但是,这个模型并没有很好地捕捉到正样本的特征,因为它没有预测任何正样本为正样本。
因此,在这种情况下,使用准确率作为评估指标是不合适的,因为它不能反映模型对正样本特征的捕捉能力。
精确率(Precision,P)——预测为正的样本
即模型预测为正的样本里,真正为正的比例

召回率(Recall,R)——正样本

召回率也叫做敏感度(Sensitivity),即在所有正样本中,模型准确找出的比例
注意事项
P高代表模型预测为正,基本上就是正。表示其很准。但很准的原因可能是模型太严格,例如100个正例,模型只判断了其中1个为正,确实这个样本分对了,但是依旧错分了其他99个,造成假阴性变高。
R高代表模型更能够把正样本从样本中找出来,漏诊率低,很敏感,稍微不对就会判正。但例如模型把所有样本都判为正,此时召回率确实高,但没有意义。会带来很高的假阳性。
举例说明:
假设我们有100个样本,其中99个是正样本,1个是负样本。
现在有一个模型,它预测其中1个样本为正样本。
首先,我们来计算精确率(Precision):
精确率 = 预测为正样本且实际为正样本的样本数 / 预测为正样本的样本数
在这个例子中,预测为正样本的样本数是1,而预测为正样本且实际为正样本的样本数也是1(因为只有一个正样本被预测为正样本)。
所以,精确率 = 1/ 1 = 100%。
接下来,我们来计算召回率(Recall):
召回率 = 预测为正样本且实际为正样本的样本数 /所有实际为正样本的样本数
在这个例子中,所有实际为正样本的样本数是99。
所以,召回率 = 1 / 99 = 0.01。
需要注意的是,这里计算的召回率非常低,这是因为模型过于严格,只预测了一个正样本。而实际上,应该尽可能提高召回率,以便尽可能多地预测出正样本。因此,在实际应用中,需要根据具体需求来调整模型的预测标准。
P和R的关系——成反比
可以认为P和R在一定程度上是成反比的。 图片源于网络
图片源于网络
在二分类问题中,精确率(P)和召回率(R)是一对矛盾的指标:提高一个就意味着另一个的降低。
这是因为这两个指标都涉及到预测为正样本的样本中真正为正样本的比例,但它们考察的角度不同。精确率是考虑预测为正样本的样本中有多少是真正的正样本,而召回率是考虑实际为正样本的样本中有多少被预测为正样本。
当模型过于严格时,可能会提高精确率,但可能会导致召回率下降,因为模型过于严格可能会导致将一些正样本误分为负样本。相反,如果模型过于宽松,可能会提高召回率,但可能会导致精确率下降,因为模型过于宽松可能会导致将一些负样本误分为正样本。
因此,可以认为精确率和召回率在一定程度上是成反比的。在评估模型时,需要综合考虑这两个指标,以便更全面地评估模型的性能。同时,也需要根据实际应用场景来调整模型的预测标准,以获得更好的模型性能。
总结:即高P很容易降低R,高R很容易降低P。两者需要权衡
F值
F值是精确率和召回率的调和平均数,用于综合考虑这两个指标,给出更全面的评估结果。
F值越大,说明模型的性能越好。在分类问题中,F值可以用来评估模型的整体性能,特别是当精确率和召回率存在矛盾时。通过绘制Precision-Recall曲线,可以得到不同阈值下的精确率和召回率组合,从而找到最优的F值。
F1值

F1值越高,说明模型的性能越好。F1值提供了一个平衡的评估标准,在评估分类模型时,我们通常希望同时获得高精确率和召回率,但这是比较困难的。
F1值能够更好地反映模型的总体性能,因为它同时考虑了精确率和召回率。其次,F1值对于不平衡数据集的处理能力更强,因为它通过权重平均的方式处理了不同类别的样本。
F值和F1值的关系
F值和F1值非常相似,都用于综合考虑精确率和召回率,给出更全面的评估结果。
当精确率和召回率相等时,F值和F1值相等。在其他情况下,F1值更注重精确率和召回率的平衡,如果一个模型的精确率很高但召回率很低,或者反之,那么F1值将会比较低。因此,F1值是一个更为严格的评估指标,能够更好地衡量模型的性能。
在分类问题中,F1值通常被用作评估指标,因为它综合考虑了精确率和召回率,能够更全面地反映模型的性能。如果一个模型的F1值很高,说明它在精确率和召回率方面都表现得很好。
ROC(Receiver Operating Characteristic)——衡量分类器性能的工具
在评估搜索引擎策略时,主要用于判断所使用的算法模型,或者说算法组合的性能
ROC(Receiver Operating Characteristic)曲线是一种分类器的综合性能指标,以假阳性率(False Positive Rate, FPR)为横坐标,真阳性率(True Positive Rate, TPR)为纵坐标,在平面直角坐标系中描绘的曲线形状。

ROC曲线的总面积是1,曲线下方面积越大,分类器的准确性越高。
因此,可以用**曲线下面积(Area Under Curve,AUC)**来衡量预测模型的优劣。AUC的值可以通过积分求得,即对ROC曲线下方的图形面积进行计算。
- ROC曲线在搜索引擎中有着重要的应用。例如,在信息检索领域,ROC曲线是衡量搜索引擎性能的一个重要因素,可以用来比较不同搜索算法的优劣。利用ROC曲线可以对计算机程序进行性能评估,以选择最佳的词向量表示算法。
- ROC曲线还可以用来调整搜索引擎的参数和优化模型。通过调整参数或更换模型,可以改变ROC曲线的位置和形状,从而提高搜索引擎的性能。例如,可以调整召回算法的排序权重或增加相关反馈机制等,以改善用户体验和提高搜索引擎的准确性。
AUC(Area Under roc Curve)——ROC曲线下面积的计算
通俗来说,ROC曲线就像一个跷跷板,敏感性和特异性是跷跷板的两端。
当敏感性和特异性都高的时候,ROC曲线就会更靠近左上角,曲线下方的面积就更大,表示分类器的准确性更高。相反,如果敏感性和特异性都低,那么ROC曲线就会更靠近右下角,曲线下方的面积就小,表示分类器的准确性低。
AUC就是计算ROC曲线下的面积,其值介于0和1之间。如果AUC接近1,表示分类器的准确性很高;如果AUC接近0或0.5,则表示分类器的准确性较低。
因此,通过ROC曲线和AUC值,我们可以更直观地评估分类器的性能,从而在实际应用中做出更好的决策。
MAP (Mean Average Precision@K)——评估检索策略效果评估指标之一
MAP评估的是一组检索结果的平均精度,即每个查询的平均相关文档数。它通过计算每个查询的平均精度,然后将这些平均精度相加,最后除以查询的总数。MAP考虑了每个查询的返回结果,并对其精度进行了加权处理,因此可以更好地反映检索策略的整体性能。
与传统的精确率、召回率和F1分数相比,MAP更加符合实际检索任务的需求。在信息检索领域中,用户通常更加关注检索结果的相关性和准确性,而MAP正是从用户的角度出发,对检索结果进行评估的一种指标。
因此,在搜索引擎和信息检索领域中,MAP已经成为评估检索策略效果的重要指标之一。通过提高MAP值,可以提高搜索引擎的性能和用户体验。
Prec@K和AP@K
Prec@K和AP@K是MAP的组成部分,并且都是用来评估检索策略效果的指标。
具体来说,
- Prec@K表示设定一个阈值K,在检索结果到第K个正确召回为止,排序结果的相关度。
- AP@K则是指到第K个正确的召回为止,从第一个正确召回到第K个正确召回的平均正确率。
- MAP则是Mean Average Precision的缩写,表示一组检索结果的平均精度,即每个查询的平均相关文档数。
MAP的计算需要使用到Prec@K和AP@K,通过计算每个查询的平均精度(AP),然后将这些平均精度相加,最后除以查询的总数,得到MAP的值。
举例说明:
案例来源:人人都是产品经理
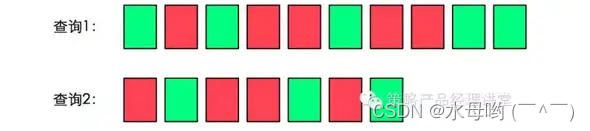
注:绿色表示搜索结果与搜索词相关,红色表示不相关。

在这个案例中Prec@1=1、Prec@3=2/3、Prec@5=3/5。也许你已经发现了,Prec@K也只能表示单点的策略效果,为了体现策略的整体效果,我们需要使用AP@K。
假设存在以下两个排序,我们直观的理解,结果1是优于结果2的,那么这种优劣会如何体现在AP@K值中呢?
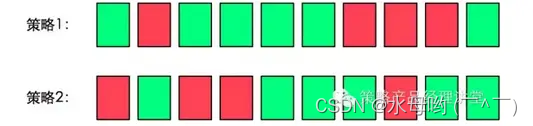
对于结果1,
AP@K=(1.0+0.67+0.75+0.8+0.83+0.6)/6=0.78
对于结果2,
AP@K=(0.5+0.4+0.5+0.57+0.56+0.6)/6=0.52
可以看到,效果优的排序结果的AP@K值大于效果劣的那一组。
在以上案例中,
查询1的AP@K=(1.0+0.67+0.5+0.44+0.5)/5=0.62,
查询的2的AP@K=(0.5+0.4+0.43)/3=0.44,
则我们计算这个策略的MAP@K=(0.62+0.44)/2=0.53。
对使用MAP@K进行评估的系统,我们认为MAP@K值较高的策略效果更好。
针对搜索引擎——在不同场景下如何选择合适的评估指标
由于搜索引擎需要处理海量数据,如果召回率R(即召回的相关文档的比例)过高↑,会对后续的排序和引擎的整体性能产生负面影响。具体来说,高召回率会导致需要处理的数据量增加,从而增加排序和返回结果的时间,降低搜索引擎的性能↓。
如果过度追求精确率P,可能会导致召回率R降低,即很多真正的正样本没有被预测出来。在一些场景中,如搜索引擎的垂直搜索(垂搜)场景,可能需要更多的长尾词来带流量。但由于对精确率P的要求极高,很多相关的词可能无法出现在搜索结果中,导致召回率R降低。
因此,在不同的应用场景中,需要根据实际需求来选择合适的评估指标。如果希望模型的预测尽可能准确,那么可以选择较高的精确率;如果希望模型能够尽可能多地覆盖正样本,那么可以选择较高的召回率。
为了更好地分析精确率和召回率之间的关系,可以绘制Precision-Recall曲线。这条曲线可以通过改变模型的阈值来获得不同的精确率和召回率组合,从而帮助我们更好地理解模型的性能。
此外,还可以使用F值来调和精确率和召回率的互斥关系。F值是精确率和召回率的调和平均数,它能够综合考虑这两个指标,给出更全面的评估结果。
总之,选择合适的评估指标需要根据实际应用场景来决定,并综合考虑不同指标的优缺点和需求来进行权衡。
长尾词
长尾词是指非目标关键词但与目标关键词相关的,能够带来搜索流量的组合型关键词。
长尾词通常较长,可能是2-3个词组成,甚至是短语,存在于内容页面,除了内容页的标题,还存在于内容中。长尾词具有可延伸性、针对性强、范围广等特征。
在搜索引擎优化(SEO)中,长尾词是非常重要的概念。长尾理论认为,通过大量的小市场累积起来,可以占据市场中可观的份额。对于网站来说,长尾词带来的总流量非常大。
例如,如果一个网站的目标关键词是“服装”,那么其长尾词可能包括“男士服装”、“冬装”、“户外运动装”等。
因此,在网站优化中,需要关注长尾词的优化。通过合理地选择和利用长尾词,可以提高网站的流量和转化率。同时,需要分析市场趋势和用户需求,以便找到更有价值的长尾词,并选择有利可图的优化词类,实现搜索条件的最优化。
相关文章:
搜索引擎评价指标及指标间的关系
目录 二分类模型的评价指标准确率(Accuracy,ACC)精确率(Precision,P)——预测为正的样本召回率(Recall,R)——正样本注意事项 P和R的关系——成反比F值F1值F值和F1值的关系 ROC(Receiver Operating Characteristic)——衡量分类器性能的工具AUCÿ…...

armbian修改docker目录到硬盘
玩客云自带内存8G,根目录很快就满了,这里调整docker的目录到硬盘上/sda1。 docker info|grep "Docker Root Dir:" Docker Root Dir:/var/lib/docker 查看docker 默认目录在哪里 Docker 版本 > v17.05.0 docker -v Docker version 25.0.…...

cip、ethernet/ip开源协议栈:开发源代码
EtherNet/IP是一个工业以太网协议,它结合标准协议TCP和UDP,在以太网上基础上的通用工业协议(CIP)。 该协议由ODVA维护。ODVA还管理其他CIP实现,如DeviceNet。 协议栈和源代码下载 www.jngbus.com 在开发Ethernet/Ip…...
网络原理TCP/IP(2)
文章目录 TCP协议确认应答超时重传连接管理断开连接 TCP协议 TCP全称为"传输控制协议(Transmission Control Protocol").⼈如其名,要对数据的传输进⾏⼀个详细 的控制; TCP协议段格式 • 源/目的端口号:表⽰数据是从哪个进程来,到哪个进程去; • 32位序号/32位确认…...

Echars3D 饼图开发
关于vue echart3D 饼图开发 首先要先下载 "echarts-gl", 放在main.js npm install echarts-gl --save <template><div class"cointan"><!-- 3d环形图 --><div class"chart" id"cityGreenLand-charts"><…...
【PaddleSpeech】语音合成-男声
环境安装 系统:Ubuntu > 16.04 源码下载 使用apt安装 build-essential sudo apt install build-essential 克隆 PaddleSpeech 仓库 # github下载 git clone https://github.com/PaddlePaddle/PaddleSpeech.git # 也可以从gitee下载 git clone https://gite…...

AI-数学-高中-17-三角函数的定义
原作者视频:三角函数】4三角函数的定义(易)_哔哩哔哩_bilibili 初中: 高中:三角函数就是单位圆上的点的横纵坐标(x0,y0)。 示例1: 规则: 示例2: 示例3.1: 示例3.2 示例4…...
centOS/Linux系统安全加固方案手册
服务器系统:centos8.1版本 说明:该安全加固手册最适用版本为centos8.1版本,其他服务器系统版本可作为参考。 1.账号和口令 1.1 禁用或删除无用账号 减少系统无用账号,降低安全风险。 操作步骤 使用命令 userdel <用户名> 删除不必要的账号。 使用命令 passwd…...
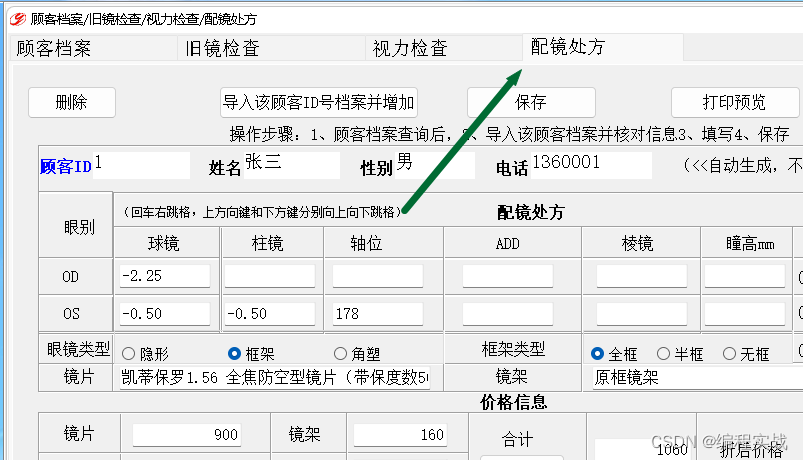
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程
编程实例分享,眼镜店电脑系统软件,配件验光管理顾客信息记录查询系统软件教程 一、前言 以下教程以 佳易王眼镜店顾客档案管理系统软件V16.0为例说明 如上图, 点击顾客档案,在这里可以对顾客档案信息记录保存查询,…...

完整的 HTTP 请求所经历的步骤及分布式事务解决方案
1. 对分布式事务的了解 分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西, 特别是在微服务架构中,几乎可以说是无法避免。 首先要搞清楚:ACID、CAP、BASE理论。 ACID 指数据库事务正确执行…...
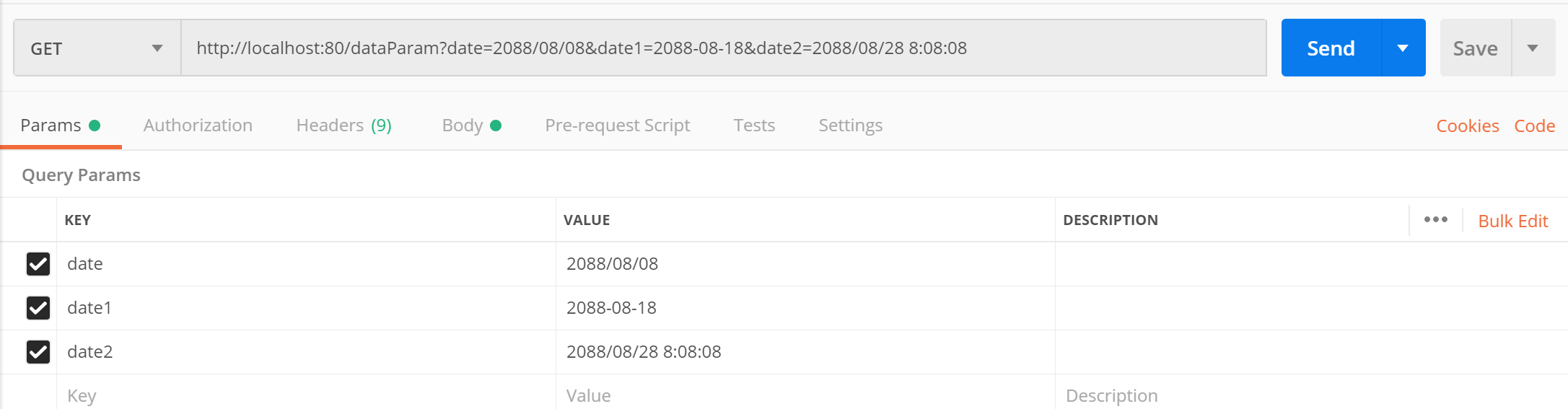
SpringMVC请求和响应
文章目录 1、请求映射路径2、请求参数3、五种类型参数传递3.1、普通参数3.2、POJO类型参数3.3、嵌套POJO类型参数3.4、数组类型参数3.5、集合类型参数 4、json数据传递4.1、传递json对象4.2、传递json对象数组 5、日期类型参数传递6、响应6.1、响应页面6.2、文本数据6.3、json数…...

AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——深度学习 0. 前言1. 深度学习基本概念1.1 基本定义1.2 非结构化数据 2. 深度神经网络2.1 神经网络2.2 学习高级特征 3. TensorFlow 和 Keras4. 多层感知器 (MLP)4.1 准备数据4.2 构建模型4.3 检查模型4.4 编译模型4.5 训练模型4.6 评估模型 小结系列链接 0. 前言 …...

Django_基本增删改查
一、前提概述 通过项目驱动来学习,以图书管理系统为例,编写接口来实现对图书信息的查询,图书的添加,图书的修改,图书的删除等功能。(不包含多重信息的校验,只为了熟悉增删改查接口的实现流程&a…...

数仓治理-存储资源治理
目录 一、存储资源治理的背景 二、存储资源治理的流程及思路 三、治理前如何评估 3.1 无用数据表/临时数据表下线评估 3.2 表及分区的生命周期评估 3.3 存储及压缩格式评估 3.4 根据业务场景实现节省存储评估 四、治理后的成效如何评估 一、存储资源治理的背景 由于早…...

Linux系统安全:安全技术 和 防火墙
一、安全技术 入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全决策依据,类 似于监控…...

3dmatch-toolbox详细安装教程-Ubuntu14.04
3dmatch-toolbox详细安装教程-Ubuntu14.04 前言docker搭建Ubuntu14.04安装第三方库安装cuda/cundnn安装OpenCV安装Matlab 安装以及运行3dmatch-toolbox1.安装测试3dmatch-toolbox(对齐两个点云) 总结 前言 paper:3DMatch: Learning Local Geometric Descriptors from RGB-D Re…...

Hadoop与Spark横向比较【大数据扫盲】
大数据场景下的数据库有很多种,每种数据库根据其数据模型、查询语言、一致性模型和分布式架构等特性,都有其特定的使用场景。以下是一些常见的大数据数据库: NoSQL 数据库:这类数据库通常用于处理大规模、非结构化的数据。它们通常…...

软件工程知识梳理5-实现和测试
编码和测试统称为实现。 编码:把软件设计结果翻译成某种程序设计语言书写的程序。是对设计的进一步具体化,是软件工程过程的一个阶段。 测试:单元测试和集成测试,软件测试往往占软件开发总工作量的40%以上。 编码:选…...

WebRTC系列-自定义媒体数据加密
文章目录 1. 对外加密接口2. 对外加密实现前面的文章都有提过WebRTC使用的加密方式是SRTP这个库提供的,这个三方库这里就不做介绍,主要是对rtp包进行加密;自然的其调用也是WebRTC的rtp相关模块;同时在WebRTC里也提供一个自定义加密的接口,本文将围绕这个接口做介绍及分析;…...

golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动
golang的sqlite驱动不使用cgo实现 更换gorm默认的SQLite驱动 最近在开发一个边缘物联网程序时使用Golang开发,用到GORM来操作SQLite数据库,GORM默认使用gorm.io/driver/sqlite这个库作为SQLite驱动,该库用CGO实现,在使用过程中遇…...

Phi-4-mini-reasoning开源模型优势:轻量级+高精度+低GPU资源占用实测
Phi-4-mini-reasoning开源模型优势:轻量级高精度低GPU资源占用实测 1. 模型概述 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题、多步分析和简洁结论输出。与通用聊天模型不同,它采用了"题目输…...

Laya3D美术进阶:巧用Shader实现APP级游戏效果还原
1. 为什么选择Laya3D的Shader技术? 很多开发者第一次接触Laya3D时,都会有个疑问:为什么不用Unity直接开发?特别是在微信小游戏这个特定场景下,Laya3D的Shader技术到底能带来什么优势?我做了三年Laya小游戏…...

intv_ai_mk11详细步骤:24GB单卡部署Llama模型并启用Web UI全流程
24GB单卡部署Llama模型并启用Web UI全流程指南 1. 环境准备与快速部署 在开始部署intv_ai_mk11模型前,我们需要确保硬件和软件环境满足基本要求。这个中等规模的Llama架构模型可以在单张24GB显存的GPU上流畅运行,非常适合个人开发者和小型团队使用。 …...

理解usearch的动态内存调整:实现高效向量搜索的终极指南
理解usearch的动态内存调整:实现高效向量搜索的终极指南 【免费下载链接】usearch Fast Open-Source Search & Clustering engine for Vectors & Arbitrary Objects in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, GoLang, and Wolfr…...

LangChain、LangFlow、LangGraph:一文讲清三大 LLM 框架的定位与差异
01 | LangChain:LLM 应用的“基础设施层”① LangChain 是什么?LangChain 是一个用于构建 LLM 应用的通用框架,核心目标只有一句话:把「大模型 外部工具 数据源 Prompt」系统化地组织起来。它并不是一个“产品”,而…...

像素语言·跨维传送门应用场景:高校外语教学AI助教落地实践
像素语言跨维传送门应用场景:高校外语教学AI助教落地实践 1. 引言:当像素冒险遇上语言学习 在高校外语教学领域,传统翻译工具往往显得过于机械和枯燥。学生们面对冰冷的界面和生硬的翻译结果,学习热情很容易被消磨。而像素语言跨…...

经验值|React 实时数据图表性能为什么会越来越卡?
在使用 React 和 Highcharts 创建实时图表时,性能下降通常与以下几个因素有关:频繁更新状态:如果你频繁更新图表的数据状态,React 可能会进行多次重渲染,导致性能下降。建议使用 useRef 来引用图表实例,避免…...

AI风口来袭!转型LLM应用开发工程师,非常详细收藏我这一篇就够了
一、引言:AI时代下的新职业机遇 近年来,随着人工智能技术的快速发展,尤其是大语言模型(Large Language Models, LLM)的突破,软件行业正在经历深刻变革。以GPT系列模型为代表的技术,使自然语言理…...

Jar Analyzer:提升Java开发效率的全方位JAR分析工具
Jar Analyzer:提升Java开发效率的全方位JAR分析工具 【免费下载链接】jar-analyzer Jar Analyzer - 一个 JAR 包 GUI 分析工具,方法调用关系搜索,方法调用链 DFS 算法分析,模拟 JVM 的污点分析验证 DFS 结果,字符串搜索…...
)
手把手教你用Python+Folium搭建离线地图应用(附高德瓦片下载技巧)
PythonFolium离线地图开发实战:从瓦片下载到内网部署全指南 当你在偏远山区进行地质勘探时,突然发现手机信号全无,而团队急需查看预设路线上的地形数据;或者在企业内网环境中,安全策略禁止访问外部地图服务,…...