【Linux】理解系统中一个被打开的文件
文件系统
- 前言
- 一、C语言文件接口
- 二、系统文件接口
- 三、文件描述符
- 四、struct file 对象
- 五、stdin、stdout、stderr
- 六、文件描述符的分配规则
- 七、重定向
- 1. 重定向的原理
- 2. dup2
- 3. 重谈 stderr
- 八、缓冲区
- 1. 缓冲区基础
- 2. 深入理解缓冲区
- 3. 用户缓冲区和内核缓冲区
- 4. FILE
前言
首先我们在前面的学习中,知道了 文件 = 内容 + 属性,那么我们对文件的操作就是分别对内容和属性操作。
当我们要访问一个文件的时候,都是先要把这个文件打开,那么是谁把文件打开呢?答案是进程打开文件,在打开文件前,文件是存放在磁盘上;打开文件后,文件被进程加载到内存中。
一个进程可以通过操作系统打开一个文件,也可以打开多个文件,所以操作系统一定会给进程提供系统调用接口去打开文件;这些文件被加载到内存中,可能会存在多个,同时,加载磁盘上的文件,一定会涉及到访问磁盘设备,这些操作由操作系统来完成;所以在操作系统运行中,可能会打开很多个文件!那么此时操作系统就要将打开的文件进行管理,怎样管理呢?我们前面也学过,先描述,再组织! 一个文件要被打开,一定要现在内核中形成被打开的文件对象!
一、C语言文件接口
我们简单复习一下C语言阶段使用的文件接口,其中详细的内容链接 -> 文件操作.
其中我们复习一下 fopen 和 fputs这个接口,如下介绍:

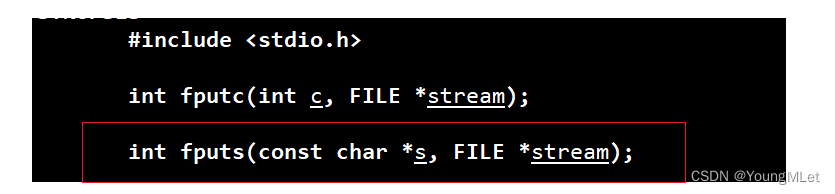
其中 fopen 中的 path 是我们需要打开的文件,mode 是以什么样的方式打开。下面我们分别使用一下以 w 和 a 方式打开,代码如下:
1 #include <stdio.h>2 3 int main()4 {5 FILE* fp = fopen("test.txt", "w"); 6 if(fp == NULL)7 {8 perror("fopen");9 return 1;10 }11 12 const char* str = "aaaaaaaaaaaaaaaaaa\n";13 int cnt = 10;14 while(cnt)15 {16 fputs(str, fp);17 cnt--;18 }19 20 fclose(fp);21 return 0;22 }
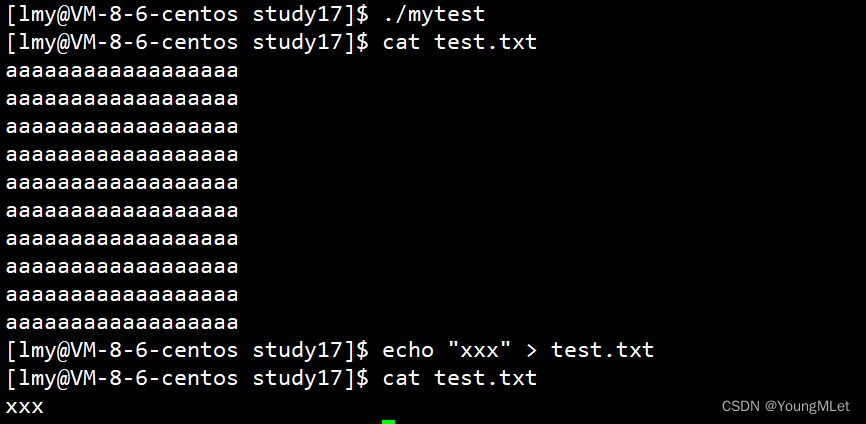
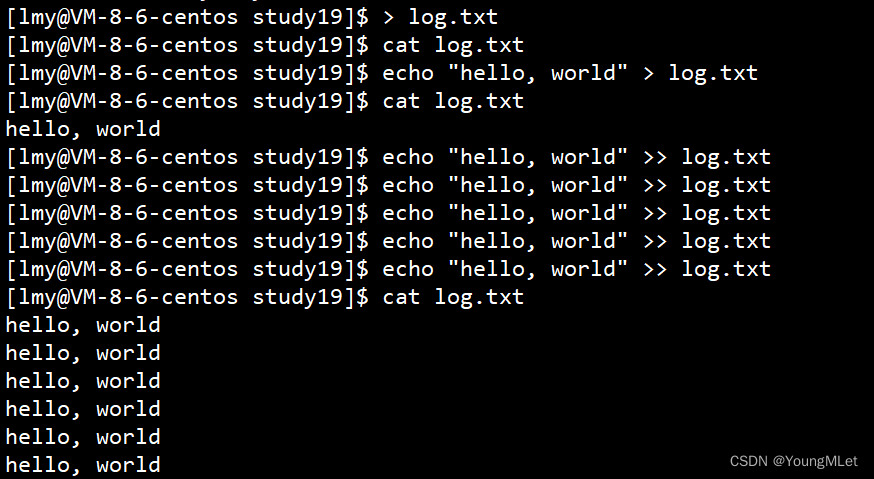
其中以 “w” 方式打开是按照写方式打开,如果文件不存在就创建它;并且以 “w” 方式打开会先清空文件内容!
例如下面场景,我们先运行程序打开 test.txt 写入内容,再重定向重新写入内容,会发现原有内容已经被清空了:
当以 “a” 方式打开,代码如下:
1 #include <stdio.h>2 3 int main()4 {5 FILE* fp = fopen("test.txt", "a"); 6 if(fp == NULL)7 {8 perror("fopen");9 return 1;10 }11 12 const char* str = "aaaaaaaaaaaaaaaaaa\n";13 int cnt = 10;14 while(cnt)15 {16 fputs(str, fp);17 cnt--;18 }19 20 fclose(fp);21 return 0;22 }
结果如下,所以我们得出结论,“a” 方式是从文件结尾出开始写入,即追加,不清空文件内原有内容:
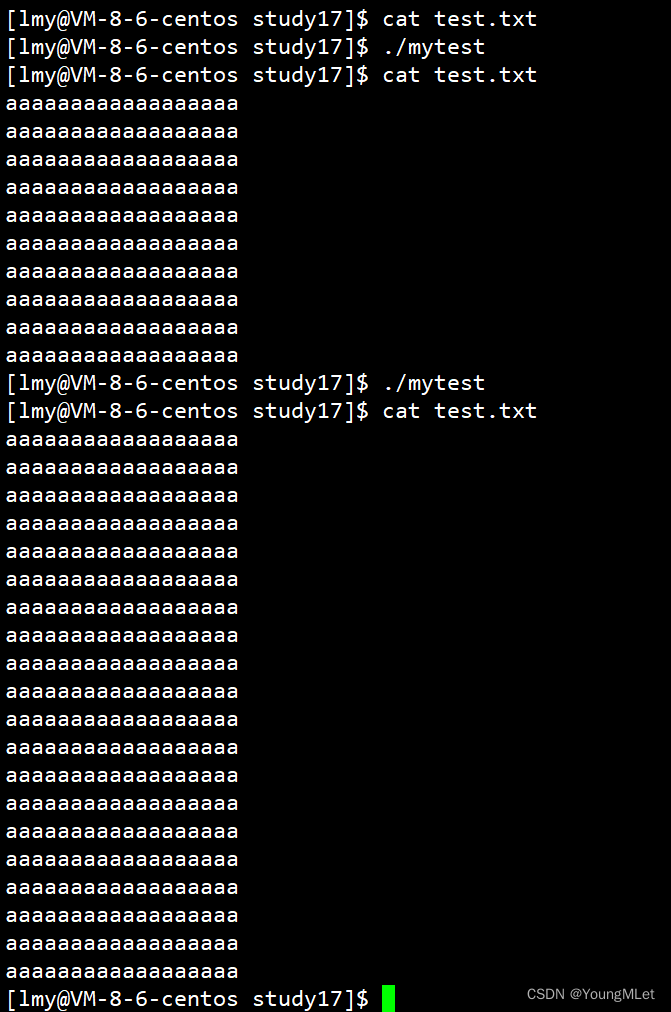
所以我们得出以 “w” 方式打开文件相当于重定向写入,即 echo "xxx" > filename;以 “a” 方式打开文件相当于追加重定向写入,即 echo "xxx" >> filename.
二、系统文件接口
接下来我们认识一下系统给我们提供的系统文件接口 open,下面看一下文档介绍:
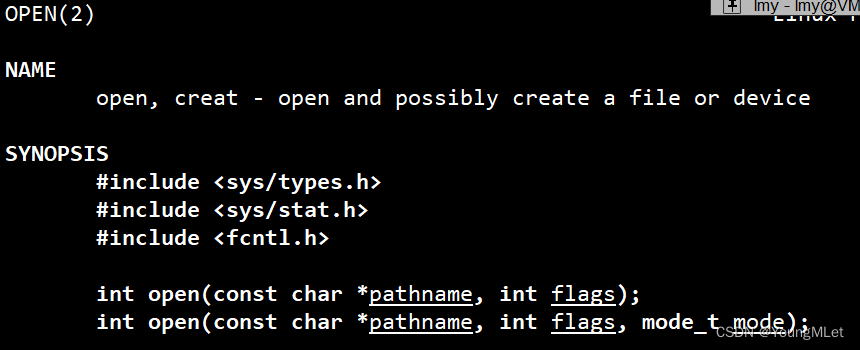
其中 open 的返回值是 fd(文件描述符),如下图介绍:

我们可以看到,如果文件创建成功会返回新文件的文件描述符,关于文件描述符我们下面再介绍。
其中 open 系统接口第一个参数 pathname 我们都知道,就是需要打开文件的名字;关于第二个参数我们需要介绍一下,关于函数传入标志位的技巧,是 Linux 中常用的传参方式;例如我们想在函数传参的时候传入指定的宏,它就会帮我们执行对应的宏的指令;如下代码:
1 #include <stdio.h> 2 3 #define Print1 1 // 0001 4 #define Print2 (1<<1) // 0010 5 #define Print3 (1<<2) // 01006 #define Print4 (1<<3) // 10007 8 void Print(int flags)9 {10 if(flags & Print1) printf("hello 1\n"); 11 if(flags & Print2) printf("hello 2\n");12 if(flags & Print3) printf("hello 3\n");13 if(flags & Print4) printf("hello 4\n");14 }15 16 17 int main()18 {19 Print(Print1);20 printf("\n");21 Print(Print1 | Print2);22 printf("\n");23 Print(Print1 | Print2 | Print3);24 printf("\n");25 Print(Print3 | Print4);26 printf("\n");27 Print(Print4); 28 return 0;29 }
结果如下:
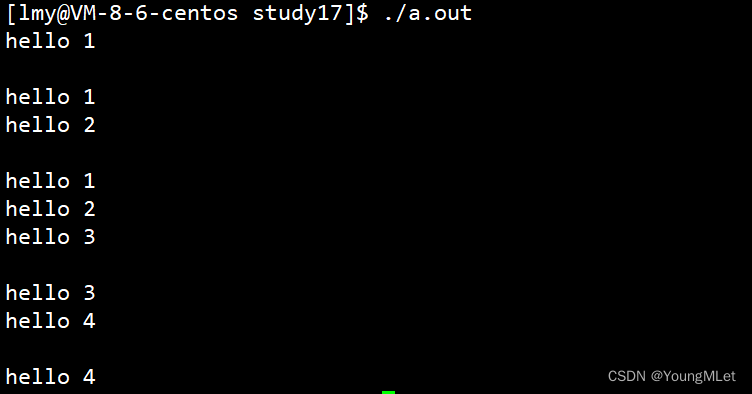
所以 open 的第二个参数实际上是一些系统定义的宏定义,在 open 的介绍文档中有介绍,如下图:


当我们想要以什么方式打开该文件时,就传入对应的宏定义,这就是 open 的第二个参数。我们先简单介绍几个宏定义:
O_RDONLY: 只读打开O_WRONLY: 只写打开O_RDWR : 读,写打开以上三个宏,必须指定一个且只能指定一个O_CREAT : 若文件不存在,则创建它。需要使用 mode 选项,来指明新文件的访问权限O_APPEND: 追加写O_TRUNC: 打开后清空原内容
接下来我们先介绍另一个系统接口 write,我们先看看 man 手册,如下:
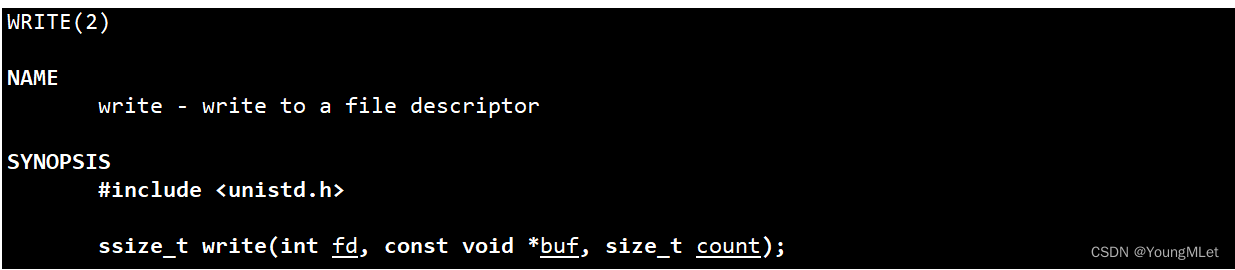
如上图,write 的参数列表比较好理解,第一个参数 fd 就是需要写入文件的文件描述符;第二个参数 buf 就是需要写入的字符串;第三个参数 count 就是需要写入的个数,注意这里不需要把 \0 的个数加上去,只需要将需要写入字符串的个数填上即可。
下面我们配对使用 open 和 write ,如下代码:
int main(){int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);const char* str = "xxxxx\n";write(fd, str, strlen(str));close(fd);return 0;}
当我们运行起程序再查看文件属性的时候,会发现以下现象:
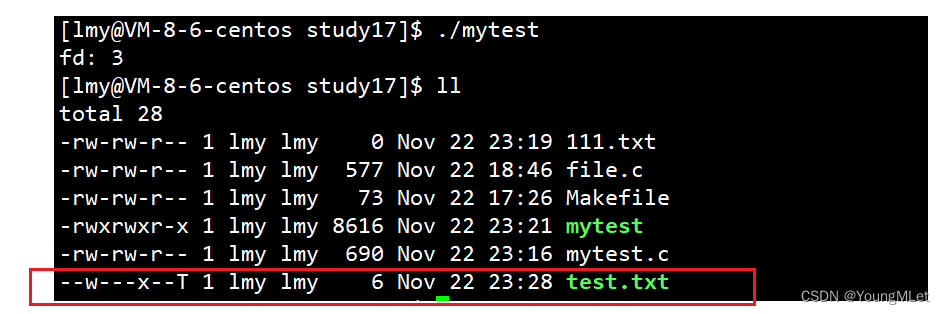
此时我们创建的 test.txt 的权限是乱码的!为什么呢?这就和 open 的第三个参数 mode 有关了,所以我们现在知道 mode 就是需要改写的权限,以八进制形式传入,下面我们对上面代码做修改:
int main(){int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){perror("open");return 1;}printf("fd: %d\n", fd);const char* str = "xxxxx\n";write(fd, str, strlen(str));close(fd);return 0;}
再次运行程序:
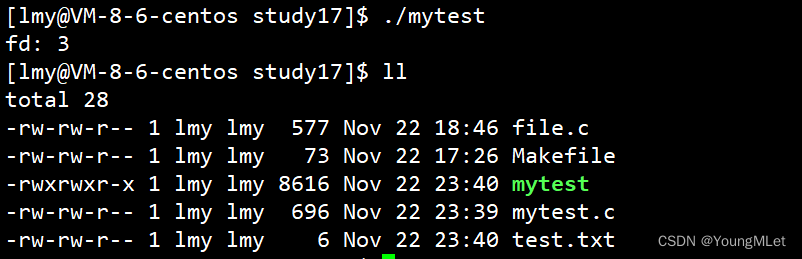
此时我们发现 test.txt 的权限就恢复正常了,由于有权限掩码的原因,权限为 0664.
此时我们查看 test.txt 中的内容:

如果我们往文件中追加内容再重新打开文件的话,原有的内容会被清掉,因为我们传的是 O_TRUNC,即打开后清空原内容 ,例如下图:
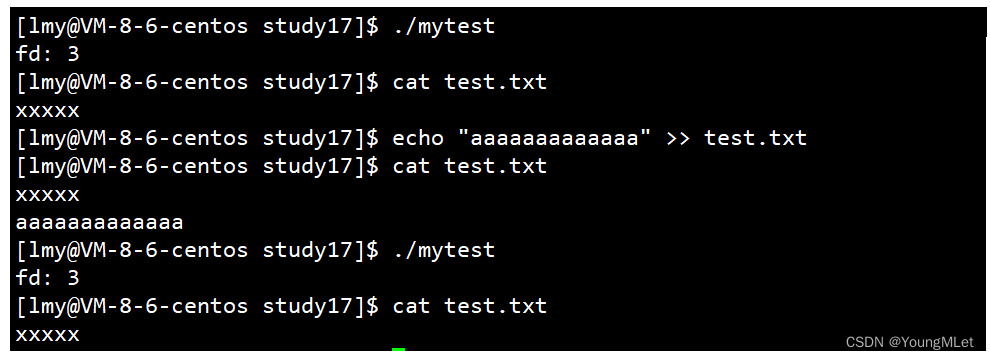
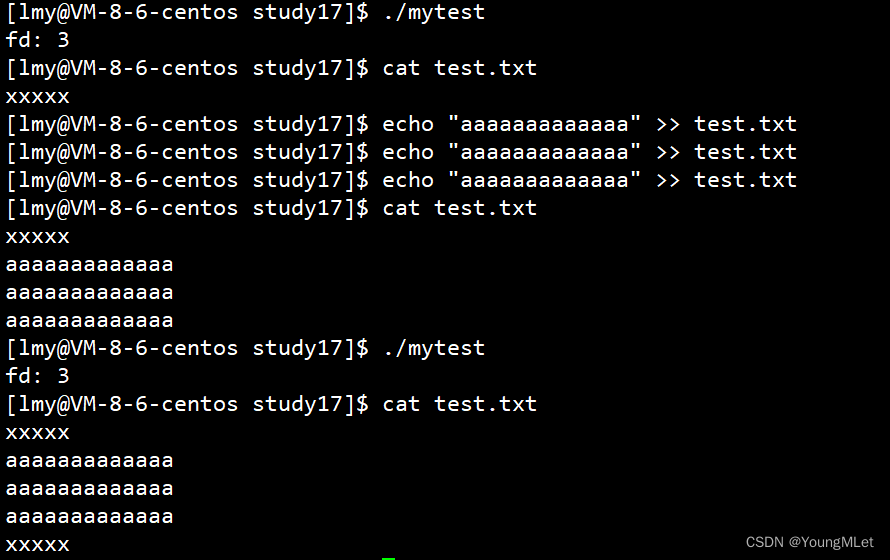
当我们将代码中的 open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666) 改为 open("test.txt", O_WRONLY | O_CREAT | O_APPEND, 0666) 后,重新再执行程序后就可以追加内容了,如下图:
三、文件描述符
通过上面的学习,我们可以开始理解语言和系统的理解了,我们在上面使用的 FILE* fp = fopen("test.txt", "w"); 是C语言库函数的接口,它对应的是系统接口 int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666); ;而 FILE* fp = fopen("test.txt", "a"); 对应的是系统接口 int fd = open("test.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);;那么我们得出结论,因为文件只能通过操作系统去访问,不能直接通过语言去访问,所以 fopen 的底层一定是对 open 的封装!
同时,我们肯定会对 fd(文件描述符) 很感兴趣,那么它到底是什么呢?下面我们通过创建多个文件观察 open 的返回值 fd,如下代码:
int main(){int fd1 = open("test1.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);int fd2 = open("test2.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);int fd3 = open("test3.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);int fd4 = open("test4.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);printf("fd1: %d\n", fd1);printf("fd2: %d\n", fd2);printf("fd3: %d\n", fd3);printf("fd4: %d\n", fd4);close(fd1);close(fd2);close(fd3);close(fd4);return 0;}
结果如下:
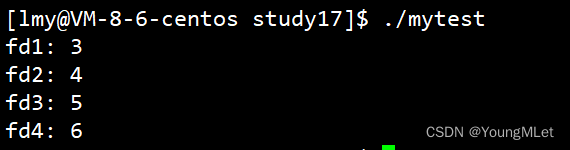
我们可以看到,连续创建文件时 fd 是一串连续的数字,类似于数组的下标。
四、struct file 对象
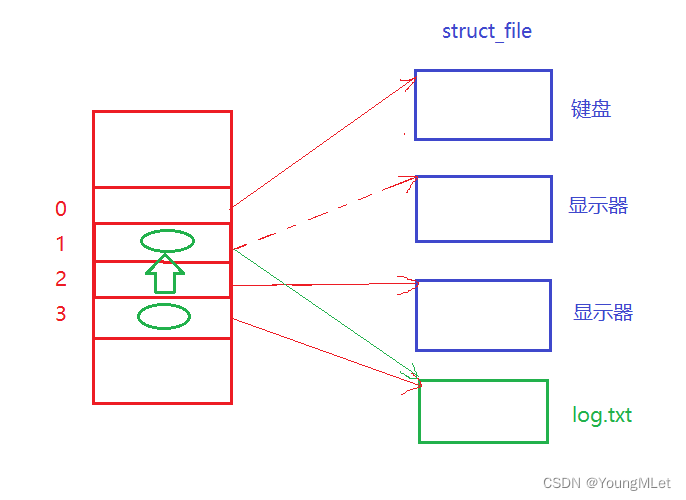
下面我们开始理解文件在操作系统中的表现;当一个进程需要打开一个在磁盘上的文件时,此时操作系统内可能会存在多个被打开的文件,那么这些文件需要被操作系统通过先描述再组织的形式管理起来;那么当操作系统需要打开一个文件的时候,需要为每个文件创建一个文件对象,在 Linux 中被创建的结构体对象叫做 struct file,即是被打开文件的描述结构体对象。
如果我们打开了很多个文件,那么每个文件都有它自己的 struct file,每个文件可能都由不同的进程打开的,但是最终操作系统都要将这些 struct file 管理起来,那么就可以通过双链表的形式将它们连接起来管理,所以从此往后,对打开文件的管理就转化成了对双链表的增删查改的管理。
那么操作系统如何知道哪个文件是由哪个进程打开的呢?所以操作系统不得不面临一个问题:如何维护进程和打开文件的对应关系?所以操作系统内核中,它为进程设计了一个结构体:struct files_struct ,该结构体也叫做进程文件描述符表,进程文件描述符表里有一个非常重要的数组:struct file* fd_array[],即一个数组指针。此时当一个进程打开一个文件时,操作系统会为该文件创建一个 struct file 对象,再把该对象的地址填入到 struct file* fd_array[] 中没有被使用的数组下标中,最后把该数组的下标返回给上层,其中这个数组的下标就是我们的 fd(文件描述符)!
上面所说的理论过程可以通过下图进行理解:

下面我们重新理解一下 struct file 对象,那么 struct file 对象里面应该有什么呢?答案是内容+属性。首先我们需要知道 struct file 对象中有一些字段可以直接获得文件的所有属性,直接或间接包含如下属性:在磁盘的什么位置,权限、大小、读写位置等。除此之外,struct file 内还需要有自己对应的文件缓冲区,也就是说这是一段内存空间。当我们的文件没有被打开的时候,它是存放在磁盘当中的,当我们打开这个文件时,内核需要帮我们创建 struct file 对象,因为在内核中,struct file 是专门用来管理被打开文件的!
当进程需要读取文件数据的时候,必然是先要将数据加载到内存空间中,即 struct file 的文件缓冲区中;如果我们需要向这个文件中写入呢?同样地,我们也同样先需要将数据加载到内存中,在内存中进行对文件数据的增删查改,不能直接在磁盘中进行,因为需要根据冯诺依曼体系!这个过程是操作系统帮我们完成的,因为操作系统是硬件的管理者!
所以我们在应用层进行数据读写的时候,本质是什么呢?其实,本质就是将内核缓冲区中的数据进行来回拷贝!该过程如下图所示:

首先如果我们需要写入数据,我们根据进程找到相应的进程描述符表,根据文件描述符找到对应的 struct_file 对象,再将我们写入数据的 buffer 缓冲区拷贝到对应 struct_file 对象中的文件缓冲区中,然后操作系统会帮我们刷新缓冲区中的内容,这就完成了文件数据的写入。
同样地,如果需要读取文件数据,操作系统帮我们将文件的数据加载到文件缓冲区中,我们根据文件描述符找到对应的 struct_file 对象中的文件缓冲区,再将文件缓冲区中的内容拷贝到我们的 buffer 缓冲区中即可完成读取数据。
五、stdin、stdout、stderr
在该数组指针中为什么默认填入的 struct file 对象的地址是从下标 3 开始的呢?0、1、2 去哪里了呢?其实在进程运行的时候,默认把标准输入(键盘:stdin)、标准输出(显示器:stdout)、标准错误(显示器:stderr) 打开了,它们分别代表 0、1、2;那么它们也是文件吗?没错,因为 Linux 下一切皆文件,这个我们下面再解释。
首先我们要知道,操作系统访问一个文件时,只认文件描述符!即只能通过文件描述符访问!其次我们回顾C语言的文件接口中,返回值是 FILE*,那么FILE又是什么呢?其实它是C语言提供的结构体类型,而操作系统访问文件只认文件描述符,所以我们肯定,FILE结构体中必定封装了文件描述符!下面我们可以通过代码验证一下,首先 stdin、stdout、stderr 的返回值都是 FILE*,如下图,所以我们可以通过它们的返回值观察;

代码如下:
int main(){printf("stdin->fd: %d\n", stdin->_fileno);printf("stdout->fd: %d\n", stdout->_fileno);printf("stderr->fd: %d\n", stderr->_fileno);}
结果如下:

如上图,就验证了我们是对的。那么操作系统为什么要默认把 stdin、stdout、stderr 打开呢?答案是为了让程序员默认进行输入输出代码编写!
那么我们现在就要回答上面的问题了,如何理解Linux下一切皆文件呢?首先我们的外设设备,键盘、显示器、磁盘、网卡…它们都有自己对应的读写方法,而且方法肯定不一样的。
当操作系统打开键盘文件时,创建了对应的 struct file 对象,那么键盘的结构体对象中会有键盘对应的读写的函数指针,该函数指针指向的是键盘底层对应的读写方法!同理,当系统打开显示器、磁盘、网卡等文件也是如此。所以这时候我们就可以忽略底层硬件读写方法的差异,只需要关注软件层 struct file 对象中的有关读写的函数指针即可,在操作系统看来它们的读写方法都是一样的!因为每个 struct file 对象中都会有这样的指针!而该软件层可以称为VFS(虚拟文件系统 ),所以从这一层往上面看就要可以看作一切皆文件!这种情况我们可以看作使用C语言实现了继承和多态!
六、文件描述符的分配规则
由于系统默认把 fd 中的 0、1、2 打开了,所以默认地我们打开一个文件的时候,它的 fd 会是从 3 开始,这毫无疑问。
接下来我们再认识一个系统接口:read,我们先看一下手册:
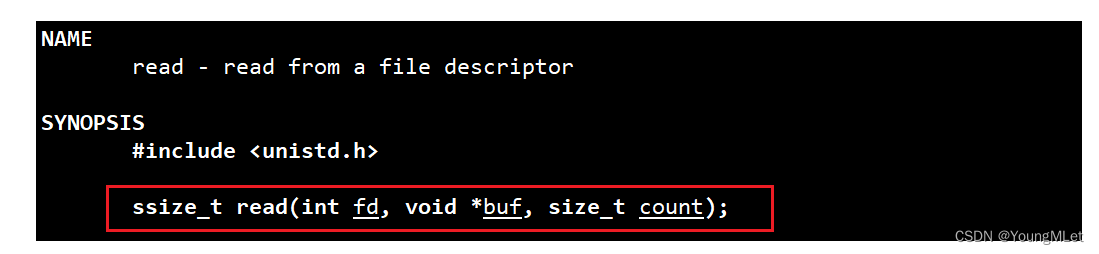
如上图,read 就是根据 fd 来进行读取文件缓冲区的数据,将数据读到 buf 中,count 就是 buf 的大小,也就是我们期望读到多少数据;返回值就是实际读到多少的数据。
假设我们现在需要在键盘里面读取数据,读到什么就打印什么,如下代码:
#include <stdio.h>#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>int main(){char buffer[1024];ssize_t s = read(0, buffer, 1024);if(s > 0){buffer[s-1] = 0;printf("echo# %s\n", buffer);}return 0;}

所以我们也侧面印证了系统是默认帮我们打开了0号文件描述符标准输入的。
接下来我们再认识一个系统接口:write,就是从对应的 fd 写入数据,我们先看手册:
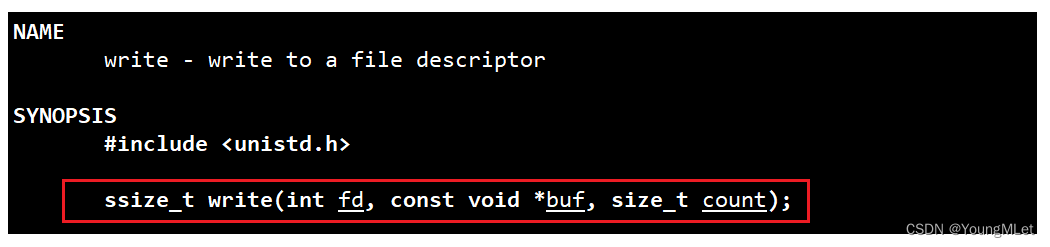
接下来我们尝试往标准输出写入数据,如下代码:
int main(){char buffer[1024];ssize_t s = read(0, buffer, 1024);if(s > 0){buffer[s-1] = 0;write(1, buffer, strlen(buffer));//printf("echo# %s\n", buffer);}return 0;}

如上结果,我们可是从来没有打开过 fd 为0或者1的文件,所以就证明了系统是默认打开了标准输入、标准输出和标准错误。
所以我们得出第一个结论,进程默认已经打开了0、1、2,我们可以直接使用0、1、2进行数据的访问!
接下来我们验证另一个问题,当我们关闭0号 fd 时,再打开一个文件时,会给该文件分配哪一个 fd 呢?下面我们验证一下:
int main(){close(0);int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd < 0){perror("open faild");return 1;}printf("fd:%d\n", fd);close(fd);return 0;}
结果如下:

同样地,如果我们将 2号 fd 关闭时,再打开一个文件,它的 fd 也是 2;这说明了什么呢?
我们得出第二个结论,文件描述符的分配规则是,寻找最小的,没有被使用的数据的位置,分配给指定的打开文件!
如果我们关闭 1号 fd 呢?如果我们关闭 1号 fd,再重新打开一个文件,并把它的 fd 打印出来,我们会发现,什么都没有打印出来,这是为什么呢?很简单,因为我们把 1号 fd 关闭了,把标准输出关闭了!
七、重定向
1. 重定向的原理
上面我们尝试过将 1号 fd 关闭后重新打开一个文件,再打印数据,会发现什么都没有打印出来,但是我们将代码做一下修改,如下:
int main(){close(1);int fd = open("log.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);if(fd < 0){perror("open faild");return 1;}printf("fd: %d\n", fd);printf("stdout->fd: %d\n", stdout->_fileno);fflush(stdout);close(fd);return 0;}
我们打印多了一个语句,并且强制刷新了缓冲区,下面我们观察现象:

如上图,我们直接执行程序没有打印任何信息,但是我们读取 log.txt 的时候发现,怎么信息都往 log.txt 里面打印了呢?下面我们画一个图理解一下:
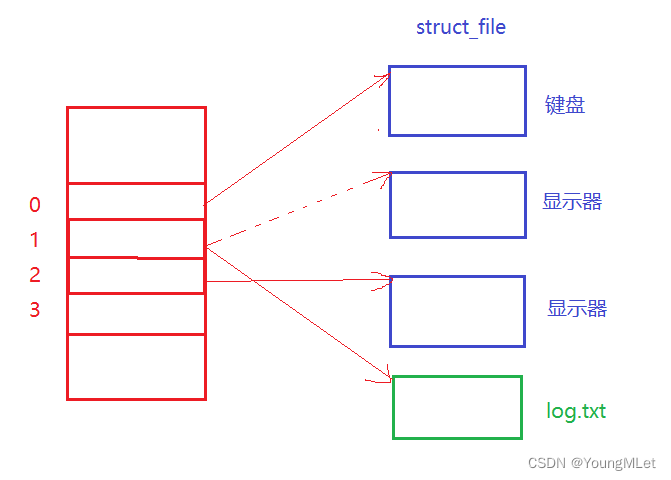
如上图,我们首先关闭了 1号 fd,然后打开 log.txt,根据文件描述符的分配规则,给 log.txt 分配的应该是 1号 fd,所以当前 1号 fd 是指向了 log.txt 的。而 printf 这样的接口只认 stdout,而 stdout 的 fileno 为1,即 printf 只认文件描述符 1;所以在上层 printf 打印的时候,只会往 1号 fd 里面打印的,而具体地,这个 1号 fd 如果指向显示器,它就往显示器里打印,如果指向 log.txt,就往 log.txt 里打印!
其实这就是重定向的原理!如果我们需要完成重定向功能,其实只需要将文件描述符下标不变,将数组中的内容发生改变即可,也就是说 1号 fd 以前指向的是显示器,我们只需要将新文件的地址填入 1号 fd 中,就会直接向新文件中写入了!
所以,重定向的本质其实就是修改特定文件描述符中的下标内容!
上面我们所实现的是输出重定向的功能,如果我们需要实现追加重定向呢?很简单,只需要修改 open 接口中的参数即可,将 O_TRUNC 改成 O_APPEND 即可,如下:
int main(){close(1);int fd = open("log.txt", O_CREAT | O_WRONLY | O_APPEND, 0666);if(fd < 0){perror("open faild");return 1;}printf("fd: %d\n", fd);printf("stdout->fd: %d\n", stdout->_fileno);fflush(stdout);close(fd);return 0;}
结果如下图所示:
接下来我们尝试一下关闭0号 fd 后,再打开 log.txt,从 stdin 中读取数据,即实现输入重定向,如下代码:
int main(){close(0);int fd = open("log.txt", O_RDONLY);if(fd < 0){perror("open faild");return 1;}char buffer[1024];fread(buffer, 1, sizeof(buffer), stdin);printf("%s\n", buffer);close(fd);return 0;}
如上我们使用了 fread 接口,我们可以看一下手册:

结果如下:
如上图,本应该从标准输入键盘中读取数据的,但是由于我们关闭了 0号 fd,再打开 log.txt,所以最后从 log.txt 中读取了数据。
2. dup2
但是以上方式实现的重定向太麻烦了,每次都要关闭文件再重新打开文件,有没有简洁一点的方式呢?答案是有的,我们知道,重定向的本质就是将文件描述符表中的下标不变,改变数组中的内容即可,那么我们是不是就可以正常打开一个文件,再将该文件中的文件描述符表中的内容拷贝到 0 号、1 号、2 号 fd 中呢?例如下图:
那么我们是否有一些接口,可以帮助我们完成文件描述符级别的数组中的内容拷贝呢?答案是有的!以输出重定向为例,我们只需要将新打开的文件的数组中的地址拷贝到 1号 fd 中的数组内容中即可。
这样的接口叫做 dup2 ,下面我们认识一下这个接口,先看一下手册:
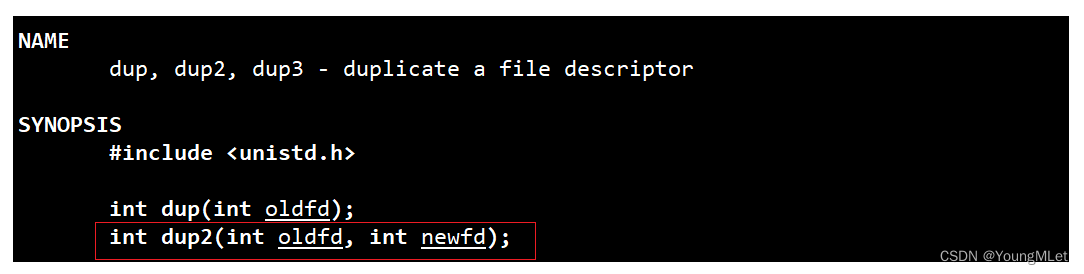

现在我们以输出重定向为例,我们观察 dup2 的参数,我们应该如何传入参数呢?我们观察该函数的描述,得知最后保留下来的应该是 oldfd,所以我们以输出重定向为例,3号 fd 就是保留下来的,1号 fd 就是被覆盖的,所以 fd 就是 oldfd,1就是 newfd,即 dup(fd, 1);
那么会有一些问题,例如我们将 fd 的内容拷贝到 1号 fd 后,是不是有两个文件指针指向 log.txt 呢?是的,那么 log.txt 怎么知道有几个文件指针指向自己呢?那么其中一个文件指针把 log.txt 关了会不会影响另外一个正在使用 log.txt 的文件指针呢?答案是不会的,因为在内核当中存在引用计数,该引用计数记录的是有多少个文件指针指向自己,当有一个文件指针把它关闭之后,引用计数会减一,并不会直接关闭文件,当引用计数为 0 时,说明已经没有文件指针指向自己,这时候才可以关闭文件。
然后我们使用 dup2() 实现一下输出重定向:
int main(){int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){perror("open faild");return 1;}dup2(fd, 1);printf("hello printf\n");fprintf(stdout, "hello fprintf\n");close(fd);return 0;}
结果如下:

但是这跟我们以前用的重定向有什么区别呢,我们以前用的重定向如下:
我们在命令行是这样使用的,但是这跟我们上面学的又有什么关系呢?首先我们执行的命令行,都是进程在执行,首先要对命令行进行解析,如果识别到命令行中有 >, >>, < 这些符号,说明该指令是要具备重定向功能的;一旦识别到该指令是要具备重定向功能的,那么前半部分就是需要执行的指令,后半部分是我们需要重定向的目标文件。
所以我们可以修改以前模拟实现的 shell,使其具备重定向功能,其中简单实现重定向的 shell 的源码地址为:myshell.
3. 重谈 stderr
那么对于标准输入和标准输出相信我们已经很熟悉了,但是为什么要存在标准错误呢?尤其它指向的也是显示器!我们先来看看,它们都是往显示器上打印信息,如下:
int main(){fprintf(stdout, "hello, stdout\n");fprintf(stderr, "hello, stderr\n");return 0;}

如果我们将可执行程序进行输出重定向呢?如下所示:

如图,为什么 hello, stderr 还会打印出来呢?很简单,我们的输出重定向只是将 hello, stdout 的信息重定向进 log.txt 里面去了,不关 stderr 的事,所以它还是会打印到显示器上。
如果我们需要将 stdout、stderr 打印到一个文件里,应该怎么做呢?此时我们需要在后面加上 2>&1,即如下:

这又是什么意思呢?2>&1 我们可以理解成将 1号 fd 数组中的内容放到 2号 fd 中,即现在 2号 fd 中数组的文件指针也指向了 log.txt.
那么为什么要有 stderr 呢?其实我们现在写的重定向,如:./test > log.txt 是一种简略的写法,它的正常的写法应该是:./test 1 > log.txt,如下:

我们理解了 2>&1 之后,再看上面的写法应该就不难理解了。那么我们还可以像下面这样写,注意 2>&1 中间不能有空格:

所以我们还可以写成下面这样:./test 1 > log.txt 2>log.txt.error 此时我们就形成了两个文件:
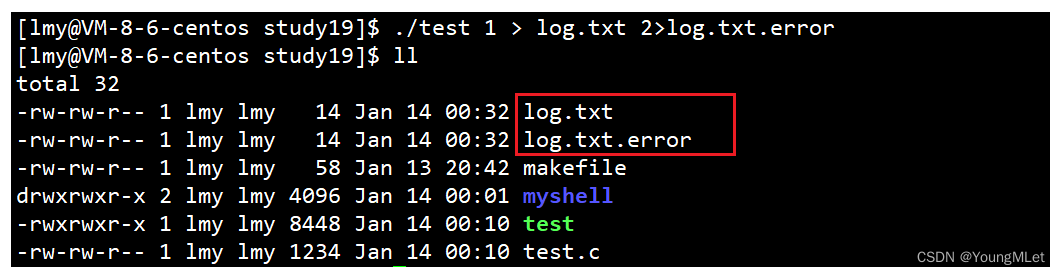
这样写我们就能理解了,因为我们在进行重定向的时候,我们把 1号 fd 重定向到 log.txt 文件,把 2号 fd 重定向到 log.txt.error 文件里,这样我们以后写程序时,printf 打印的是常规信息,perror 打印的是错误信息,这样我们就可以将正确的信息和错误的信息分别保存到两个不同的文件中!
八、缓冲区
1. 缓冲区基础
首先我们需要知道缓冲区是什么呢?我们在前面也有所了解过,如下图:
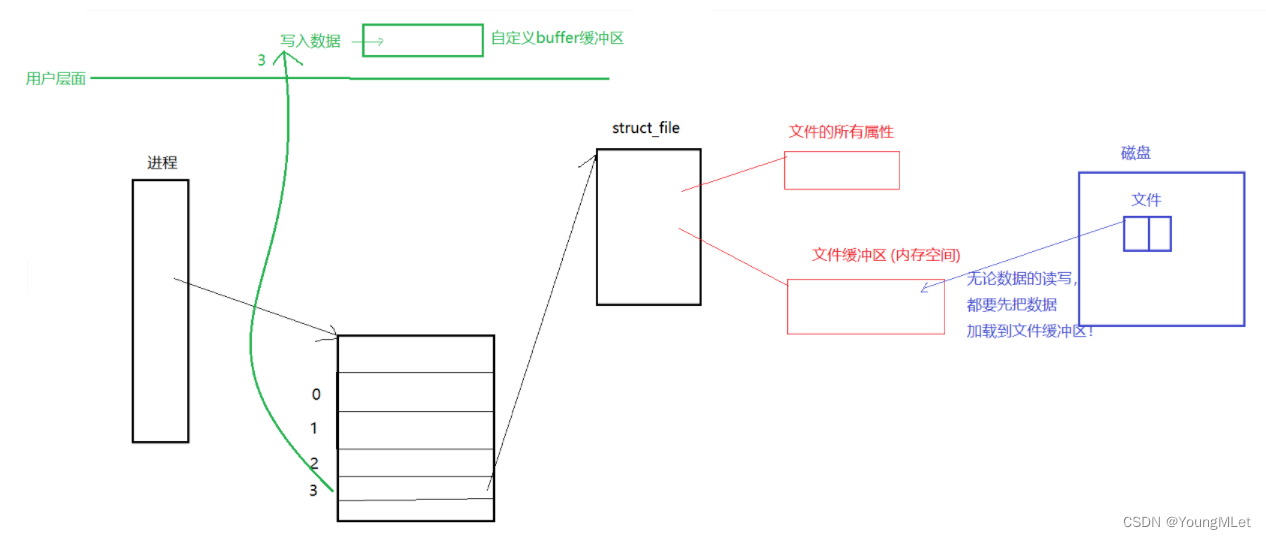
当我们需要进行文件写入或者读取文件时,实际上就是将我们自定义的 buffer 缓冲区写入到C库为我们提供的缓冲区,然后再由C库的缓冲区根据 fd 找到文件对应的文件缓冲区进行写入或读取。本质上缓冲区就是一部分内存!
我们可以举一个例子来比喻缓冲区,我们可以将缓冲区比喻成我们平时的“菜鸟驿站”,“菜鸟驿站”是帮我们将快递运输到另一个地方,而缓冲区则是将数据运输至操作系统中的文件缓冲区!因为有缓冲区的存在,我们可以积累一部分信息再统一发送,这也就提高了发送的效率!所以缓冲区的主要作用是提高效率,提高使用者的效率!
缓冲区因为能够暂存数据,所以必定有一定的刷新方式,其中有以下几种:
- 无缓冲(立即刷新)
- 行缓冲(行刷新)
- 全缓冲(缓冲区满了,再刷新)
以上是一般的策略,当然也有特殊情况,例如:
- 强制刷新,如
\n和fflush(); - 进程在退出的时候,一般要进行刷新缓冲区。
而一般对于显示器文件,默认是进行行刷新;对于磁盘上的文件,默认是全缓冲,即缓冲写满再刷新。
2. 深入理解缓冲区
下面我们看一个例子,如下代码:
int main(){fprintf(stdout, "C: hello fprintf\n");printf("C: hello printf\n");fputs("C: hello fputs\n", stdout);const char* str = "system call: hello write\n";write(1, str, strlen(str));return 0;}
我们分别调用了三个C语言的接口,fprintf、printf、fputs,和一个系统接口:write,我们使用这几个接口往显示器上打印信息,结果如下:

如上图,可以打印到正确的结果。接下来我们对上面的代码进行一些修改,如下:
int main(){fprintf(stdout, "C: hello fprintf\n");printf("C: hello printf\n");fputs("C: hello fputs\n", stdout);const char* str = "system call: hello write\n";write(1, str, strlen(str));fork();return 0;}
我们只在最后加上了 fork() 创建子进程,我们观察运行的结果:

结果也是没有问题的,但是我们将执行结果输出重定向到一个文件中的时候呢?如下:

如上图,为什么重定向到 log.txt 就会发生上面的现象呢?这里涉及到的问题是有点多的,我们一个一个来。
- 首先,当我们直接向显示器打印的时候,显示器文件的刷新方式是行刷新!而且我们的代码中输出的所有字符串,都有
\n,所以fork()之前,数据全部已经被刷新,包括 system call!所以fork()之后缓冲区已经被清空了,即使进程退出需要刷新缓冲区,也没有数据可刷新了! - 当我们重定向到 log.txt 的时候,本质是向磁盘文件中写入,系统对于数据的刷新方式已经由行刷新变成了全缓冲!
- 全缓冲意味着缓冲区变大,实际写入的简单数据,不足以把缓冲区写满,即使有
\n强制进行行刷新,但是由于此时系统默认的刷新方式是全缓冲,所以当fork()执行的时候,此时缓冲区的数据依旧在缓冲区中! - 我们可以看到,分别向显示器和文件中打印的时候,系统接口 system call 始终都是只打印一次,反而是C语言的接口在变化,所以我们得出结论,我们目前所谈的“缓冲区”,和操作系统和系统接口是没有关系的;由于
fprintfprintf和fputs底层都是对write的封装,所以引起这些变化的,只能和C语言本身有关!所以我们平时用得最多的其实是 C/C++ 提供的语言级别的缓冲区,也就是用户缓冲区! - C/C++ 提供的缓冲区,里面一定保存的是用户的数据,属于当前进程在运行时自己的数据!如果我们把数据交给了操作系统,即通过语言级别的缓冲区刷新到文件缓冲区中后,这个数据就属于操作系统了,不属于进程了!
- 当进程退出的时候,一般要进行刷新缓冲区,即便数据没有满足刷新条件!那么,刷新缓冲区属不属于清空或者“写入”操作呢?属于!当我们的
fork()之后,总有一个进程需要先退出,子进程或者父进程,取决于OS的调度,那么当任意一个进程退出的时候,就要对缓冲区进行刷新,即发生了写入操作,就要发生写时拷贝! - 但是我们发现,发生写时拷贝的都是C语言的接口,系统接口
write并没有发生写时拷贝,即没有使用C语言的缓冲区,这是为什么呢?很简单,系统调用接口是在C语言之下的,它看不到语言级别的缓冲区,而是将数据直接写入到操作系统的缓冲区了!所以该数据就不属于进程了,也就不会发生写时拷贝了!
3. 用户缓冲区和内核缓冲区
我们通过上面得知,日常我们用得最多的其实是C/C++提供的语言级别的缓冲区,下面我们画一个图理解一下这两者的关系:
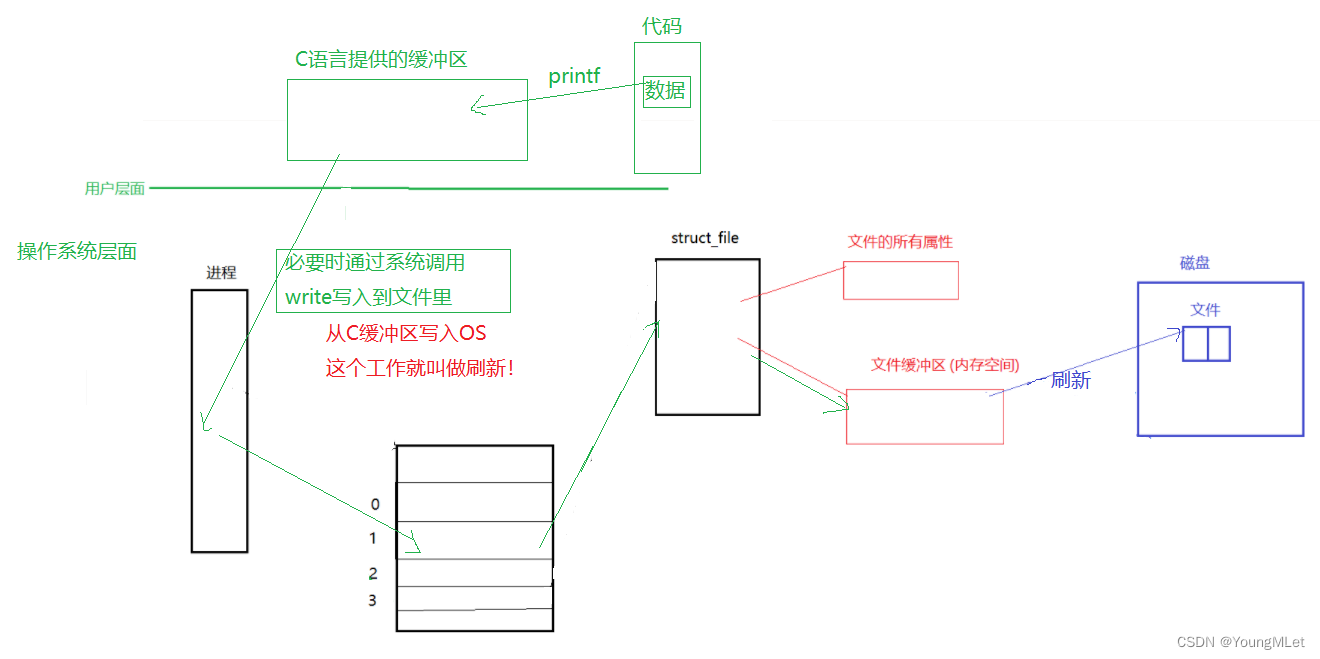
上图就是我们的代码写入到文件中的过程,以及缓冲区刷新的理解,但是为什么要有这个过程呢?我们直接使用 printf 写入到文件里不行吗?我们上面说过,缓冲区的存在就是提高使用者的效率,如果 printf 直接往操作系统里面写,会涉及到用户直接拷贝到操作系统里,这个过程的成本可远比拷贝到C语言缓冲区中再拷贝到操作系统的成本要大!因为缓冲区积累一定量后再往操作系统写入,和用户一次一次往操作系统里写入,明显前者效率更高,提高了 printf 的调用效率!所以 printf 只需要将我们用户定义的缓冲区,写入到C语言的缓冲区,由于大家都是同一个级别的拷贝,所以过程也很简单很快。至于C语言缓冲区,它可以积累上一段时间再一次性写入到操作系统中,只跑一次就能大大提高效率!
那么我们为什么要提高 printf 的调用效率呢?其实 printf 只是众多 IO效率的一个代表,还有许多接口例如:fprintf fputs 和 scanf 等等都需要提高,所以C语言上所有IO级别的接口都需要提供缓冲区,都需要提高它们的效率,这样,我们写C语言的时候调用接口的效率就会非常快,从而使我们代码的效率就非常快了。
4. FILE
通过以前的学习我们知道,任何情况下我们输入输出的时候,都要有一个 FILE 结构体。
- 因为 IO 相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过 fd 访问的。
- 所以C库当中的 FILE 结构体内部,必定封装了 fd。
- 既然 FILE 结构体内部已经封装了 fd 了,那么 FILE 里面也就一定为我们提供了一段缓冲区!所以缓冲区是在 FILE 结构体里,所以当我们任意打开一个文件,都会有一个 FILE 结构体,也就是任意一个文件都要在C标准库里通过 FILE 来为我们创建一个属于它自己的文件级别的用户级缓冲区!所以有几个文件被打开,就有几个 FILE,就有几个缓冲区!
例如,我们可以在 /usr/include/stdio.h 路径下的头文件中找到 FILE 结构体的 typedef:

我们还可以在 /usr/include/libio.h 路径下的头文件中找到 FILE 结构体的定义:

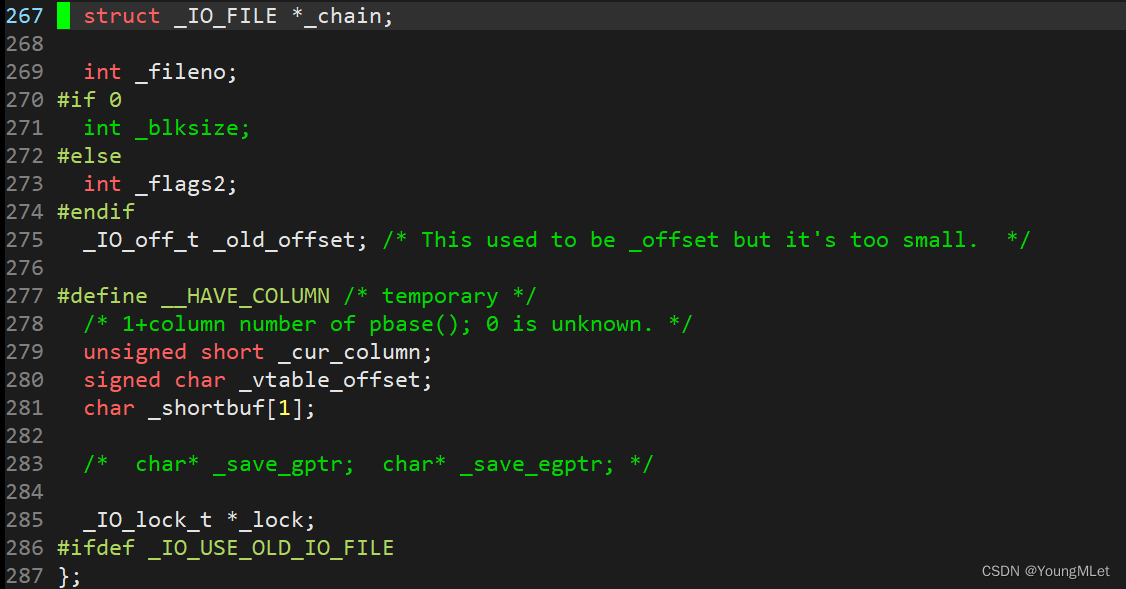
基于上面的认识,我们可以简单实现一个自己的C库函数,当然我们只是为了更好地了解底层,只是认识级别的实现,源码链接:my_Clib.
相关文章:
【Linux】理解系统中一个被打开的文件
文件系统 前言一、C语言文件接口二、系统文件接口三、文件描述符四、struct file 对象五、stdin、stdout、stderr六、文件描述符的分配规则七、重定向1. 重定向的原理2. dup23. 重谈 stderr 八、缓冲区1. 缓冲区基础2. 深入理解缓冲区3. 用户缓冲区和内核缓冲区4. FILE 前言 首…...
k8s kubeadm部署安装详解
目录 kubeadm部署流程简述 环境准备 步骤简述 关闭 防火墙规则、selinux、swap交换 修改主机名 配置节点之间的主机名解析 调整内核参数 所有节点安装docker 安装依赖组件 配置Docker 所有节点安装kubeadm,kubelet和kubectl 定义kubernetes源并指定版本…...

RT-DETR算法优化改进: 下采样系列 | 一种新颖的基于 Haar 小波的下采样HWD,有效涨点系列
💡💡💡本文独家改进:HWD的核心思想是应用Haar小波变换来降低特征图的空间分辨率,同时保留尽可能多的信息,与传统的下采样方法相比,有效降低信息不确定性。 💡💡💡使用方法:代替原始网络的conv,下采样过程中尽可能包括更多信息,从而提升检测精度。 RT-DET…...

CocosCreator3.8源码分析
Cocos Creator架构 Cocos Creator 拥有两套引擎内核,C 内核 和 TypeScript 内核。C 内核用于原生平台,TypeScript 内核用于 Web 和小游戏平台。 在引擎内核之上,是用 TypeScript 编写的引擎框架层,用以统一两套内核的差异…...
(已解决)spingboot 后端发送QQ邮箱验证码
打开QQ邮箱pop3请求服务:(按照QQ邮箱引导操作) 导入依赖(不是maven项目就自己添加jar包): <!-- 邮件发送--><dependency><groupId>org.springframework.boot</groupId><…...

【蓝桥杯冲冲冲】[NOIP2001 普及组] 装箱问题
蓝桥杯备赛 | 洛谷做题打卡day26 文章目录 蓝桥杯备赛 | 洛谷做题打卡day26题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示思路 题解代码我的一些话 [NOIP2001 普及组] 装箱问题 题目描述 有一个箱子容量为 V V V,同时有 n n n 个物品,每…...

2024牛客寒假算法基础集训营1
文章目录 A DFS搜索M牛客老粉才知道的秘密G why外卖E 本题又主要考察了贪心B 关鸡C 按闹分配 今天的牛客,说是都是基础题,头昏昏的,感觉真不会写,只能赛后补题了 A DFS搜索 写的时候刚开始以为还是比较难的,和dfs有关…...

元素的显示与隐藏,精灵图,字体图标,CSSC三角
元素的显示与隐藏 类似网站广告,当我们点击关闭就不见了,但是我们重新刷新页面,会重新出现 本质:让元素在页面中隐藏或者显示出来。 1.display显示隐藏 2.visibility显示隐藏 3.overflow溢出显示隐藏 1.display属性(…...

最新!2024顶级SCI优化!TTAO-CNN-BiGRU-MSA三角拓扑聚合优化、双向GRU融合注意力的多变量回归预测程序!
适用平台:Matlab 2023版及以上 TTOA三角聚合优化算法,将在2024年3月正式发表在中科院1区顶级SCI期刊《Expert Systems with Applications》上。 该算法提出时间极短,目前以及近期内不会有套用这个算法的文献。新年伊始,尽快拿下…...
)
Flink SQL Client 安装各类 Connector、组件的方法汇总(持续更新中....)
一般来说,在 Flink SQL Client 中使用各种 Connector 只需要该 Connector 及其依赖 Jar 包部署到 ${FLINK_HOME}/lib 下即可。但是对于某些特定的平台,如果 AWS EMR、Cloudera CDP 等产品会有所不同,主要是它们中的某些 Jar 包可能被改写过&a…...
React18-模拟列表数据实现基础表格功能
文章目录 分页功能分页组件有两种接口参数分页类型用户列表参数类型 模拟列表数据分页触发方式实现目录 分页功能 分页组件有两种 table组件自带分页 <TableborderedrowKey"userId"rowSelection{{ type: checkbox }}pagination{{position: [bottomRight],pageSi…...

MySQL查询数据(十)
MySQL查询数据(十) 一、SELECT基本查询 1.1 SELECT语句的功能 SELECT 语句从数据库中返回信息。使用一个 SELECT 语句,可以做下面的事: **列选择:**能够使用 SELECT 语句的列选择功能选择表中的列,这些…...
AJAX-常用请求方法和数据提交
常用请求方法 请求方法:对服务器资源,要执行的操作 axios请求配置 url:请求的URL网址 method:请求的方法,如果是GET可以省略;不用区分大小写 data:提交数据 axios({url:目标资源地址,method…...
2024美国大学生数学建模竞赛美赛B题matlab代码解析
2024美赛B题Searching for Submersibles搜索潜水器 因为一些不可抗力,下面仅展示部分代码(很少部分部分)和部分分析过程,其余代码看文末 Dthxlsread(C:\Users\Lenovo\Desktop\Ionian.xlsx); DpDth(:,3:5); dy0.0042; dx0.0042; …...

【DouYing Desktop】
I) JD 全日制大专及以上学历; 2. 3年以上的IT服务支持相关工作经验 3. 有较强的桌面相关trouble shooting与故障解决能力,能够独立应对各类型桌面问题; 4. 具备基础的网络、系统知识,能够独立解决常见的网络、系统等问题…...
正则表达式与文本处理工具
目录 引言 一、正则表达式基础 (一)字符匹配 1.基本字符 2.特殊字符 3.量词 4.边界匹配 (二)进阶用法 1.组与引用 2.选择 二、命令之-----grep (一)基础用法 (二)高级用…...
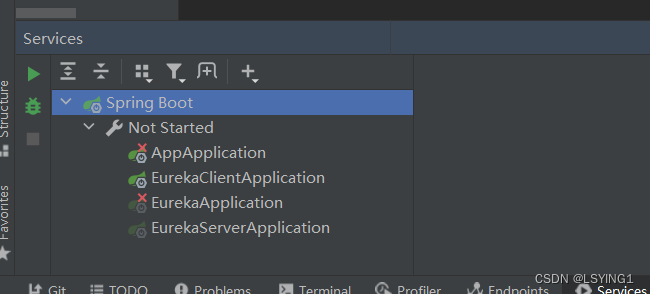
IDEA中的Run Dashboard
Run Dashboard是IntelliJ IDEA中的工具【也就是View中的Services】,提供一个可视化界面,用于管理控制应用程序的运行和调试过程。 在Run DashBoard中,可以看到所有的运行配置,以及每个配置的运行状态(正在运行…...

【力扣白嫖日记】SQL
前言 练习sql语句,所有题目来自于力扣(https://leetcode.cn/problemset/database/)的免费数据库练习题。 今日题目: 1407.排名靠前的旅行者 表:Users 列名类型idintnamevarchar id 是该表中具有唯一值的列。name …...
)
自动化报告pptx-python|高效通过PPT模版制造报告(三)
这是自动化报告学习的第三篇了,前面两篇分别是: 自动化报告的前奏|使用python-pptx操作PPT(一)自动化报告pptx-python|如何将pandas的表格写入PPTX(二)本篇是逼着笔者看到JoStudio 大佬自己写的一个jojo-office 库,基于pptx-python开发成一套试用office软件的依赖,非…...

Linux升级openssh的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...