Flink SQL Client 安装各类 Connector、组件的方法汇总(持续更新中....)
一般来说,在 Flink SQL Client 中使用各种 Connector 只需要该 Connector 及其依赖 Jar 包部署到 ${FLINK_HOME}/lib 下即可。但是对于某些特定的平台,如果 AWS EMR、Cloudera CDP 等产品会有所不同,主要是它们中的某些 Jar 包可能被改写过,例如和 Hive Metastore 的交互,AWS EMR 就有另外一套 Metatstore:Glue Data Catalog,所以接口也做了相应的,所以,简单的复制开源的 Jar 包可能会有问题,最好做法还是从该平台/产品的集群上拷贝本地的 Jar 包。
以下脚本,以 EMR 6.15 ( Flink 1.17.1)为例,展示了各类常用 Connector 的安装方法,有的是直接下载自开源社区,有的则是从 EMR 集群本地找到相应 Jar 包安装的。脚本在 EMR 6.15 上全部测试通过,如果在其他版本的 EMR 或 Flink 上安装,请注意修改版本号。
FLINK_VERSION="1.17.1"
FLINK_MAJOR_VERSION="1.17"
HUDI_VERSION="0.14.0"
SCALA_MAJOR_VERSION="2.12"
安装大量的 Connector 可能会导致 Jar 包冲突,因此,建议做好如下两项准备工作:
1. 安装新的 Connector 或依赖包时,提前备份一版当前的 lib 库
sudo -u flink cp -r /usr/lib/flink/lib /usr/lib/flink/lib.$(date +'%Y%m%d%H%M').bak
2. 为了解决版本冲突,可以充分 Maven 的依赖解析能力,将需要同时安装的 Connector 的 Maven 依赖整合在一起,去 https://jar-download.com/online-maven-download-tool.php 一次性下载解析好的完整依赖包
3. 安装完毕后,务必重启新的 Yarn Session 方能生效
以下是单独安装各个常用 Connector、组件的方法:
1. Flink SQL Kafka Connector
# install flink kafka connector for flink sql client
# only run on master node is enough, owner of flink home dir is 'flink' user
sudo -u flink wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/${FLINK_VERSION}/flink-sql-connector-kafka-${FLINK_VERSION}.jar -P /usr/lib/flink/lib/
2. Flink Hudi Connector
# install flink hudi connector for flink sql client
# only run on master node is enough, owner of flink home dir is 'flink' user
sudo -u flink wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-flink${FLINK_MAJOR_VERSION}-bundle/${HUDI_VERSION}/hudi-flink${FLINK_MAJOR_VERSION}-bundle-${HUDI_VERSION}.jar -P /usr/lib/flink/lib/
3. Flink Hive Connector ( on AWS EMR )
如果 EMR 版本不是 6.15, 请注意替换以下 jar 包文件中的版本号,以所用 EMR 集群上的文件版本为准:
# install flink hive connector for flink sql client
# only run on master node is enough, owner of flink home dir is 'flink' user
# refer to this doc: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/flink-configure.html
sudo -u flink cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib
sudo -u flink cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /usr/lib/flink/lib
sudo -u flink cp /usr/lib/hive/lib/libfb303-0.9.3.jar /usr/lib/flink/lib
sudo -u flink cp /usr/lib/flink/opt/flink-connector-hive_${SCALA_MAJOR_VERSION}-${FLINK_VERSION}-amzn-1.jar /usr/lib/flink/lib
4. Debezium Confluent Avro 格式 (‘format’ = ‘debezium-avro-confluent’)
前往 https://jar-download.com/online-maven-download-tool.php ,输入如下 Maven 依赖(注意:如有其他同方式获取Jar包的组件,请合并为一份xml配置统一提交,避免出现 Jar 包版本冲突):
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-avro-confluent-registry</artifactId><version>1.18.1</version>
</dependency>
点击 “Submit” 按钮,将 flink-avro-confluent-registry 及其依赖包下载到本地,然后将得到 jar_files.zip 包上传到集群主节点,并执行以下命令将 jar 包部署到 Flink SQL Client 的 lib 目录下:
# install flink 'debezium-avro-confluent' format for flink sql client
# only run on master node is enough, owner of flink home dir is 'flink' user
# refer to this doc: https://blog.csdn.net/bluishglc/article/details/135863249 , section 3.2
sudo -u flink unzip jar_files.zip -d /usr/lib/flink/lib/
更多详细介绍请参考《Flink 集成 Debezium Confluent Avro ( format=debezium-avro-confluent )》 一文的 3.2 节。
5. Flink JDBC Connector for MySQL
需要同时安装 flink-connector-jdbc 的 Jar 包和 MySQL 的 JDBC 驱动 Jar 包。
# install flink jdbc connector for flink sql client, note: flink-connector-jdbc_2.12-1.14.6.jar is wrong jar!!
sudo -u flink wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-jdbc/3.1.1-${FLINK_MAJOR_VERSION}/flink-connector-jdbc-3.1.1-${FLINK_MAJOR_VERSION}.jar -P /usr/lib/flink/lib/# install mysql jdbc driver 8.3.0
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-8.3.0.zip -P /tmp/
unzip /tmp/mysql-connector-j-8.3.0.zip -d /tmp/
sudo -u flink cp /tmp/mysql-connector-j-8.3.0/mysql-connector-j-8.3.0.jar /usr/lib/flink/lib
ls /usr/lib/flink/lib/mysql-connector-j-8.3.0.jar# install mysql jdbc driver 5.1.49
# wget https://cdn.mysql.com/archives/mysql-connector-java-5.1/mysql-connector-java-5.1.49.zip -P /tmp/
# unzip /tmp/mysql-connector-java-5.1.49.zip -d /tmp/
# sudo -u flink cp /tmp/mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar /usr/lib/flink/lib
6. Flink MySQL CDC Connector (2.3.0)
Flink CDC 2.3.0 在官方Repo: https://github.com/ververica/flink-cdc-connectors/tags 上提供了 Uber Jar 供直接下载使用:
# install flink kafka connector for flink sql client
# only run on master node is enough, owner of flink home dir is 'flink' user
sudo -u flink wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.3.0/flink-sql-connector-mysql-cdc-2.3.0.jar -P /usr/lib/flink/lib/
6. Flink MySQL CDC Connector (2.4+)
注意:目前 Flink CDC 2.4+ 在官方Repo:https://github.com/ververica/flink-cdc-connectors/tags 上尚未提供制作好的 Uber Jar,如果前往 https://jar-download.com/online-maven-download-tool.php 自行制作 Jar 包 + 依赖包,部署后,会报如下错误:
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoSuchMethodError: io.debezium.connector.mysql.MySqlConnection$MySqlConnectionConfiguration.(Lio/debezium/config/Configuration;Ljava/util/Properties;)V
该问题的解释和解决方法参见:https://github.com/ververica/flink-cdc-connectors/issues/2423,鉴于自行重新编译并构建 Uber 包较为繁琐,可先使用 2.3.0 版本,该问题未来会修复。
7. Table Planner 和 Table Planner 加载器
从 Flink 1.15 开始,发行版包含两个 planner: flink-table-planner 和 flink-table-planner-loader。这两个 planner JAR 文件的代码功能相同,但打包方式不同。若使用第一个文件,您必须使用与其相同版本的 Scala;若使用第二个,由于 Scala 已经被打包进该文件里,您不需要考虑 Scala 版本问题。
所以,有时候,我们需要在这两个 Planner 之间进行切换,以下脚本可以完成相互的切换工作:
# install flink-table-planner ( can only choose 1 between flink-table-planner & flink-table-planner-loader )
sudo -u flink mv /usr/lib/flink/lib/flink-table-planner-loader-${FLINK_VERSION}-amzn-1.jar /usr/lib/flink/lib/flink-table-planner-loader-${FLINK_VERSION}-amzn-1.jar.bak
sudo -u flink cp /usr/lib/flink/opt/flink-table-planner_${SCALA_MAJOR_VERSION}-${FLINK_VERSION}-amzn-1.jar /usr/lib/flink/lib# revert to flink-table-planner-loader ( can only choose 1 between flink-table-planner & flink-table-planner-loader )
sudo -u flink rm -f /usr/lib/flink/opt/flink-table-planner_${SCALA_MAJOR_VERSION}-${FLINK_VERSION}-amzn-1.jar
sudo -u flink mv /usr/lib/flink/lib/flink-table-planner-loader-${FLINK_VERSION}-amzn-1.jar.bak /usr/lib/flink/lib/flink-table-planner-loader-${FLINK_VERSION}-amzn-1.jar
常见问题
1. [ERROR] Could not execute SQL statement. Reason:
java.lang.NoSuchMethodError: io.debezium.connector.mysql.MySqlConnection$MySqlConnectionConfiguration.(Lio/debezium/config/Configuration;Ljava/util/Properties;)V
该问题的解释和解决方法参见:https://github.com/ververica/flink-cdc-connectors/issues/2423,鉴于自行重新编译并构建 Uber 包较为繁琐,可先使用 2.3.0 版本,该问题未来会修复。
相关文章:
)
Flink SQL Client 安装各类 Connector、组件的方法汇总(持续更新中....)
一般来说,在 Flink SQL Client 中使用各种 Connector 只需要该 Connector 及其依赖 Jar 包部署到 ${FLINK_HOME}/lib 下即可。但是对于某些特定的平台,如果 AWS EMR、Cloudera CDP 等产品会有所不同,主要是它们中的某些 Jar 包可能被改写过&a…...
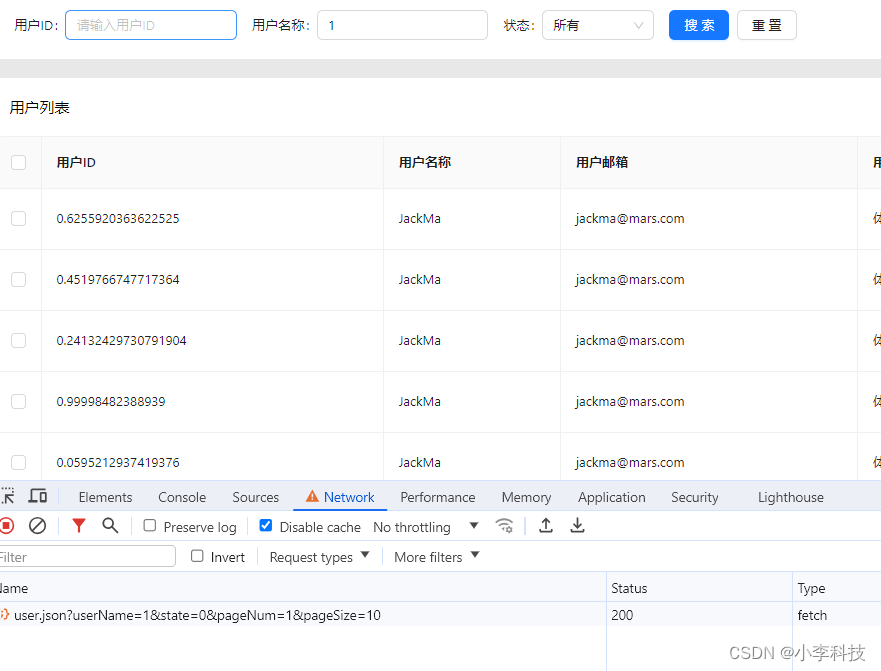
React18-模拟列表数据实现基础表格功能
文章目录 分页功能分页组件有两种接口参数分页类型用户列表参数类型 模拟列表数据分页触发方式实现目录 分页功能 分页组件有两种 table组件自带分页 <TableborderedrowKey"userId"rowSelection{{ type: checkbox }}pagination{{position: [bottomRight],pageSi…...

MySQL查询数据(十)
MySQL查询数据(十) 一、SELECT基本查询 1.1 SELECT语句的功能 SELECT 语句从数据库中返回信息。使用一个 SELECT 语句,可以做下面的事: **列选择:**能够使用 SELECT 语句的列选择功能选择表中的列,这些…...
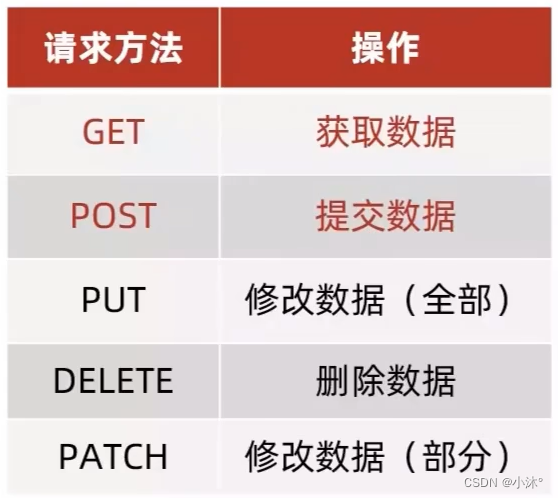
AJAX-常用请求方法和数据提交
常用请求方法 请求方法:对服务器资源,要执行的操作 axios请求配置 url:请求的URL网址 method:请求的方法,如果是GET可以省略;不用区分大小写 data:提交数据 axios({url:目标资源地址,method…...
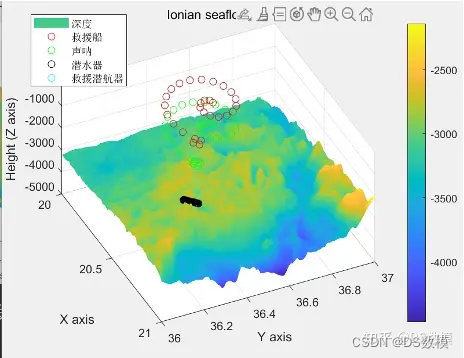
2024美国大学生数学建模竞赛美赛B题matlab代码解析
2024美赛B题Searching for Submersibles搜索潜水器 因为一些不可抗力,下面仅展示部分代码(很少部分部分)和部分分析过程,其余代码看文末 Dthxlsread(C:\Users\Lenovo\Desktop\Ionian.xlsx); DpDth(:,3:5); dy0.0042; dx0.0042; …...

【DouYing Desktop】
I) JD 全日制大专及以上学历; 2. 3年以上的IT服务支持相关工作经验 3. 有较强的桌面相关trouble shooting与故障解决能力,能够独立应对各类型桌面问题; 4. 具备基础的网络、系统知识,能够独立解决常见的网络、系统等问题…...
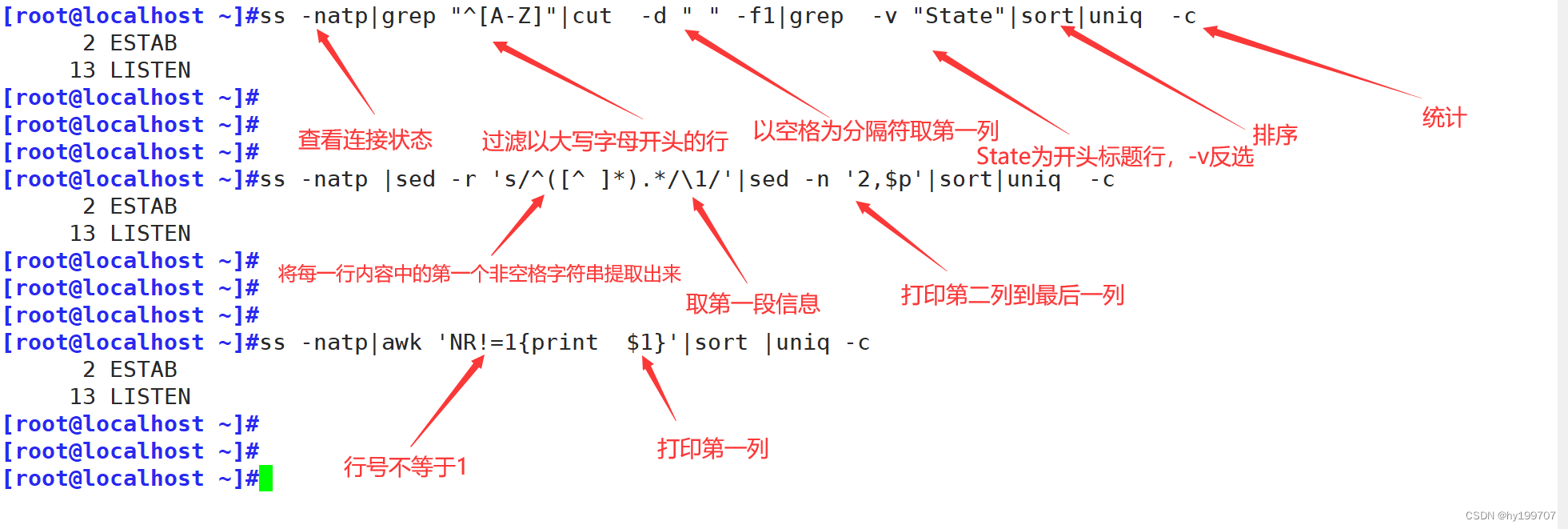
正则表达式与文本处理工具
目录 引言 一、正则表达式基础 (一)字符匹配 1.基本字符 2.特殊字符 3.量词 4.边界匹配 (二)进阶用法 1.组与引用 2.选择 二、命令之-----grep (一)基础用法 (二)高级用…...
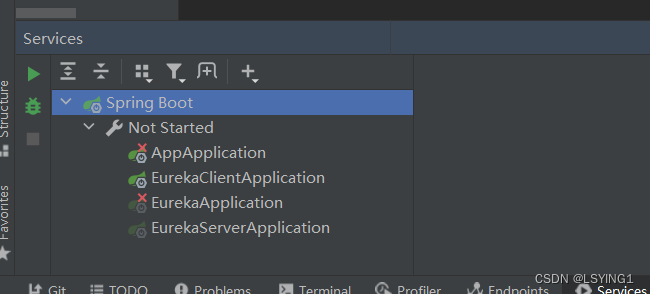
IDEA中的Run Dashboard
Run Dashboard是IntelliJ IDEA中的工具【也就是View中的Services】,提供一个可视化界面,用于管理控制应用程序的运行和调试过程。 在Run DashBoard中,可以看到所有的运行配置,以及每个配置的运行状态(正在运行…...

【力扣白嫖日记】SQL
前言 练习sql语句,所有题目来自于力扣(https://leetcode.cn/problemset/database/)的免费数据库练习题。 今日题目: 1407.排名靠前的旅行者 表:Users 列名类型idintnamevarchar id 是该表中具有唯一值的列。name …...
)
自动化报告pptx-python|高效通过PPT模版制造报告(三)
这是自动化报告学习的第三篇了,前面两篇分别是: 自动化报告的前奏|使用python-pptx操作PPT(一)自动化报告pptx-python|如何将pandas的表格写入PPTX(二)本篇是逼着笔者看到JoStudio 大佬自己写的一个jojo-office 库,基于pptx-python开发成一套试用office软件的依赖,非…...

Linux升级openssh的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
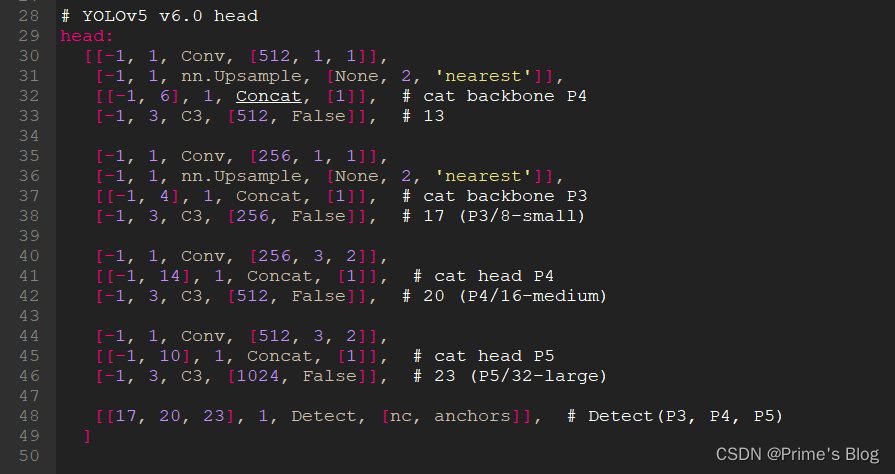
YOLOv5白皮书-第Y3周:yolov5s.yaml文件解读
YOLOv5白皮书-第Y3周:yolov5s.yaml文件解读 YOLOv5白皮书-第Y3周:yolov5s.yaml文件解读一、前言二、我的环境三、yolov5s.yaml源文件内容四、Parameters五、anchors配置六、backbone七、head八、总结 OLOv5-第Y2周:训练自己的数据集) YOLOv5白皮书-第Y3周:yolov5s.…...

C++ pair+map+set+multimap+multiset+AVL树+红黑树(深度剖析)
文章目录 1. 前言2. 关联式容器3. pair——键值对4. 树形结构的关联式容器4.1 set4.1.1 set 的介绍4.1.2 set 的使用 4.2 map4.2.1 map 的介绍4.2.2 map 的使用 4.3 multiset4.3.1 multiset 的介绍4.3.2 multiset 的使用 4.4 multimap4.4.1 multimap 的介绍4.4.2 multimap 的使…...
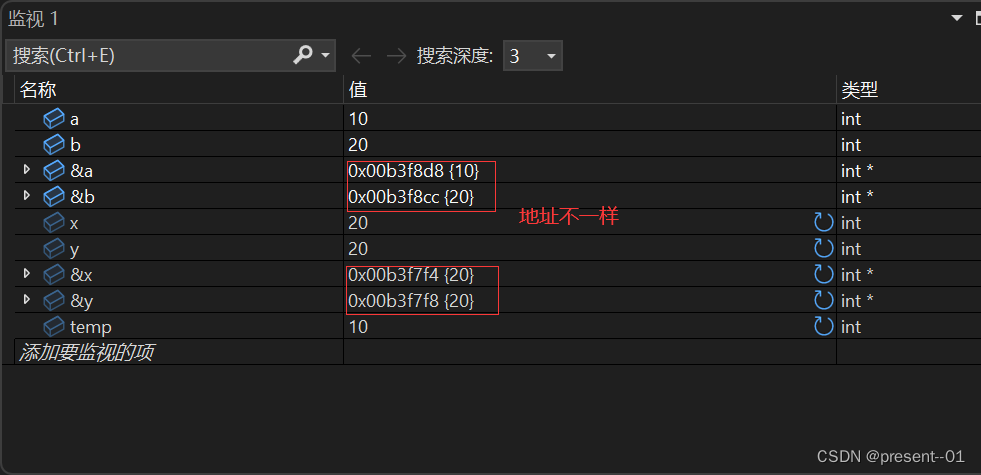
指针的学习1
目录 什么是指针? 野指针 造成野指针的原因: 如何避免野指针? 内存和指针 如何理解编址? 指针变量和地址 取地址操作符& 指针变量和解引用操作符 指针变量 如何拆解指针类型? 指针变量的大小 指针变量…...

c++:敲桌子
先输出1-100数字,从100个数字中找到这些特殊数字改为敲桌子。 特殊数字:1.7的倍数 2.十位数上有7 3.个位数上有7 #include<iostream> using namespace std; int main() {for (int i 1; i < 100; i) {if (i / 10 7 || i % 10 7|| i % 7 0)…...

Linux中判断文件系统的方法
文章目录 Linux中判断文件系统的方法1.使用mount命令2.使用blkid命令3.使用file命令4.使用fstab文件5.使用df命令(这个用的比较多)6.使用fsck命令7.使用lsblk命令(推荐-简单好用) Linux中判断文件系统的方法 1.使用mount命令 # 这样查看的只有已经挂载…...
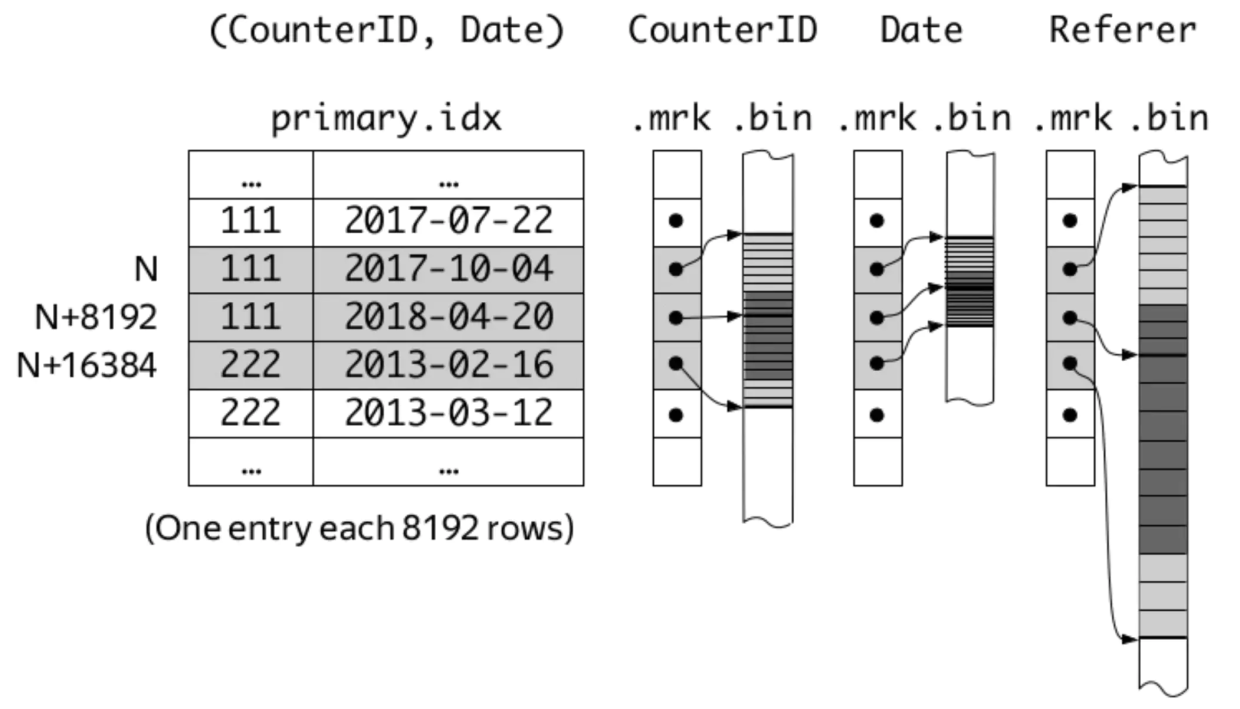
聊聊ClickHouse MergeTree引擎的固定/自适应索引粒度
前言 我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二…...
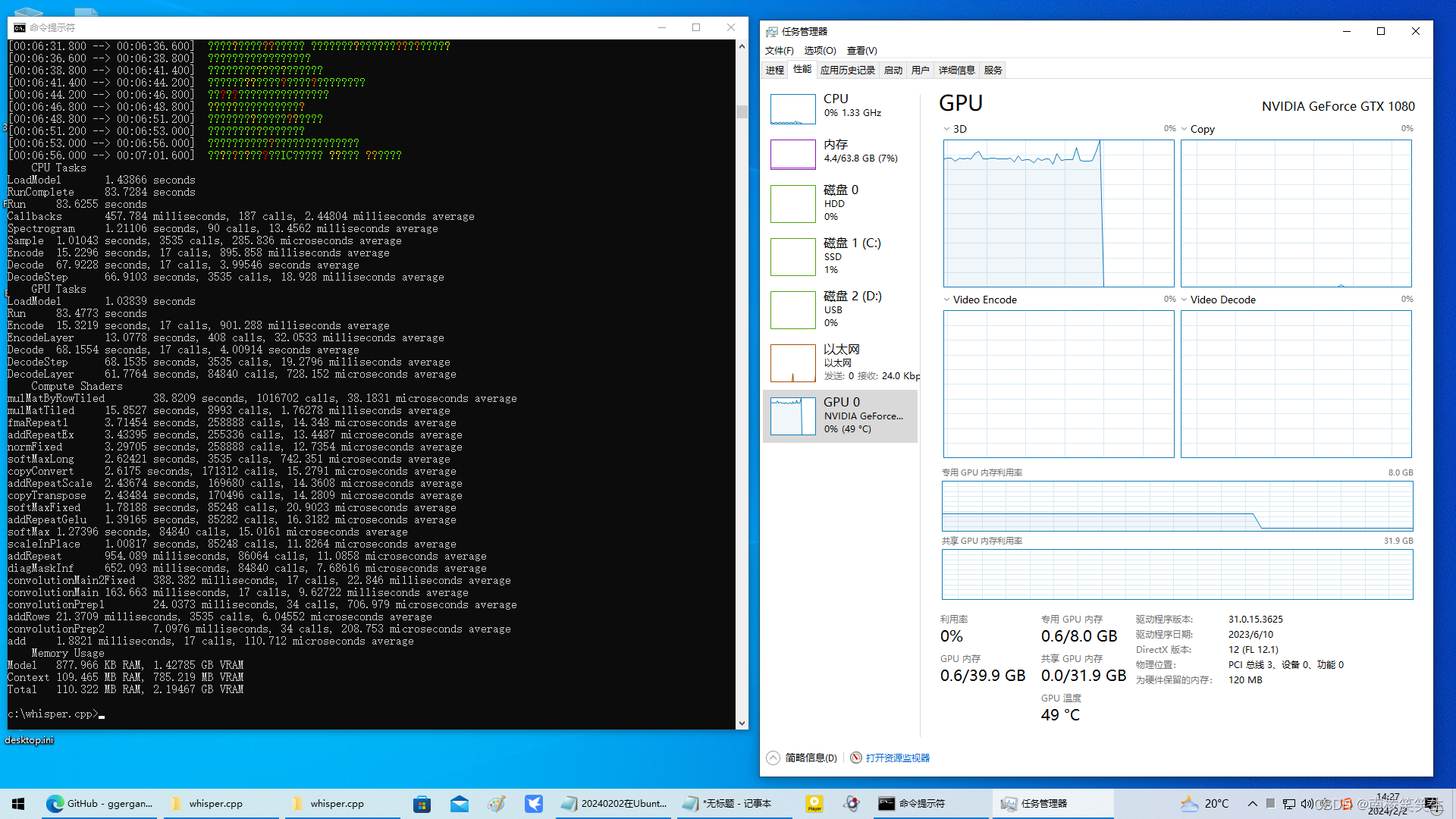
20240202在WIN10下使用whisper.cpp
20240202在WIN10下使用whisper.cpp 2024/2/2 14:15 【结论:在Windows10下,确认large模式识别7分钟中文视频,需要83.7284 seconds,需要大概1.5分钟!效率太差!】 83.7284/4200.1993533333333333333333333333…...

【Linux】基本指令(上)
🦄个人主页:修修修也 🎏所属专栏:Linux ⚙️操作环境:Xshell (操作系统:CentOS 7.9 64位) 目录 Xshell快捷键 Linux基本指令 ls指令 pwd指令 cd指令 touch指令 mkdir指令 rmdir指令/rm指令 结语 Xshell快捷键 AltEnter 全屏/取消全屏 Tab 进…...

【DB2】—— 一次关于db2 sqlcode -420 22018的记录
情况描述 在DB2 10.5数据库中执行以下SQL语句: SELECT * FROM aa WHERE aa.ivc_typ IN (213,123,12334,345)其中aa.ivc_typ列的类型为VARCHAR(10) 关于执行会发生以下情况 类型转换:SQL引擎会尝试把IN列表中的整数常量转换为VARCHAR(10)类型…...

5*5窗口的高斯滤波模板
本文介绍了一个55高斯模板的生成过程。首先以标准差σ3创建初始模板矩阵,通过双重循环计算每个位置的高斯函数值。随后对模板进行归一化处理,确保系数总和为1。最后将归一化后的模板进行1024倍定点化处理,便于后续数字信号处理应用。该代码实…...

PX41.13.3版本常用参数
1.预解锁参数COM_PREARM_MODE 默认值 Disabled2. TAKE OFF起飞模式,规定时间内是否起飞成功COM_LKDOWN_TKO 默认值3s3.飞控与机载电脑通信,信号丢失时间判断以及动作COM_OBC_LOSS_L 默认值5sCOM_OBC_ACT 默认值 降落模式COM_OBC_RC_ACT 默认值 定点模…...

DIY电源设计避坑指南:为什么你的滤波电路总达不到理想效果?
DIY电源设计避坑指南:为什么你的滤波电路总达不到理想效果? 在创客工作坊或学生电子竞赛中,一个稳定可靠的电源往往是项目成功的基础。但许多爱好者都会遇到这样的困扰:明明按照教科书设计了滤波电路,示波器上的纹波却…...

为什么 Multi-Agent 比单 Agent 更难
为什么 Multi-Agent 比单 Agent 更难——从协作黑洞到协同效率巅峰的全维度拆解 (全文预计42万字) 一、 引言:从 ChatGPT 的“天花板对话”到 AgentVerse 的“分布式协作故障”——这才是 AI 应用落地的真实门槛 1.1 钩子(The Hook):单Agent vs Multi-Agent 的两个真实…...

学术PDF处理术:OpenClaw+Qwen3-32B实现论文关键图表提取
学术PDF处理术:OpenClawQwen3-32B实现论文关键图表提取 1. 为什么需要自动化PDF图表提取 作为一名经常需要阅读大量学术论文的研究者,我长期被一个问题困扰:如何高效地从PDF论文中提取关键图表和数据。传统方法要么依赖手动截图和转录&…...
)
SpringBoot3.0.0实战:5分钟搞定SpringDoc与Knife4j的完美集成(含中文UI配置)
SpringBoot3.0极速集成SpringDoc与Knife4j:中文文档界面实战指南 在微服务架构盛行的当下,API文档的规范化和可视化已成为项目开发中不可或缺的一环。对于使用SpringBoot3.0的Java开发者来说,SpringDoc与Knife4j的组合堪称API文档工具链中的黄…...
)
用Python搞定拉普拉斯变换:从电路分析到微分方程实战(附完整代码)
用Python搞定拉普拉斯变换:从电路分析到微分方程实战(附完整代码) 在工程实践中,拉普拉斯变换就像一把瑞士军刀,能将复杂的微分方程瞬间转化为可解的代数问题。想象一下,当你面对一个包含电阻、电感和电容…...

前端加密的隐秘陷阱:Crypto-JS与JSEncrypt常见误用与解决方案
前端加密的隐秘陷阱:Crypto-JS与JSEncrypt常见误用与解决方案 1. 密钥管理的致命疏忽 在项目评审中,我经常发现开发者将加密密钥直接硬编码在JavaScript文件里。这种看似方便的做法实际上让加密形同虚设——攻击者只需查看源代码就能获取密钥,…...

打工人必备!8个AI办公神器,每天准时下班不是梦
文档处理工具Notion AI 集成在Notion中的AI功能,支持自动生成文档大纲、会议纪要整理、多语言翻译。通过自然语言输入需求,快速输出结构化内容,适合项目管理与知识库搭建。ChatPDF 上传PDF文件后可直接对话式提问,提取关键信息或总…...

2025最权威的六大AI论文神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 关于论文一键生成的技术,它借助了先进的自动化算法,还有自然语言处理…...