聊聊ClickHouse MergeTree引擎的固定/自适应索引粒度
前言
我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity = 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二:
-
每隔index_granularity行对主键组的数据进行采样,形成稀疏索引,并存储在primary.idx文件中;
-
每隔index_granularity行对每一列的压缩数据([column].bin)进行采样,形成数据标记,并存储在[column].mrk文件中。
index_granularity、primary.idx、[column].bin/mrk之间的关系可以用ClickHouse之父Alexey Milovidov展示过的一幅简图来表示。
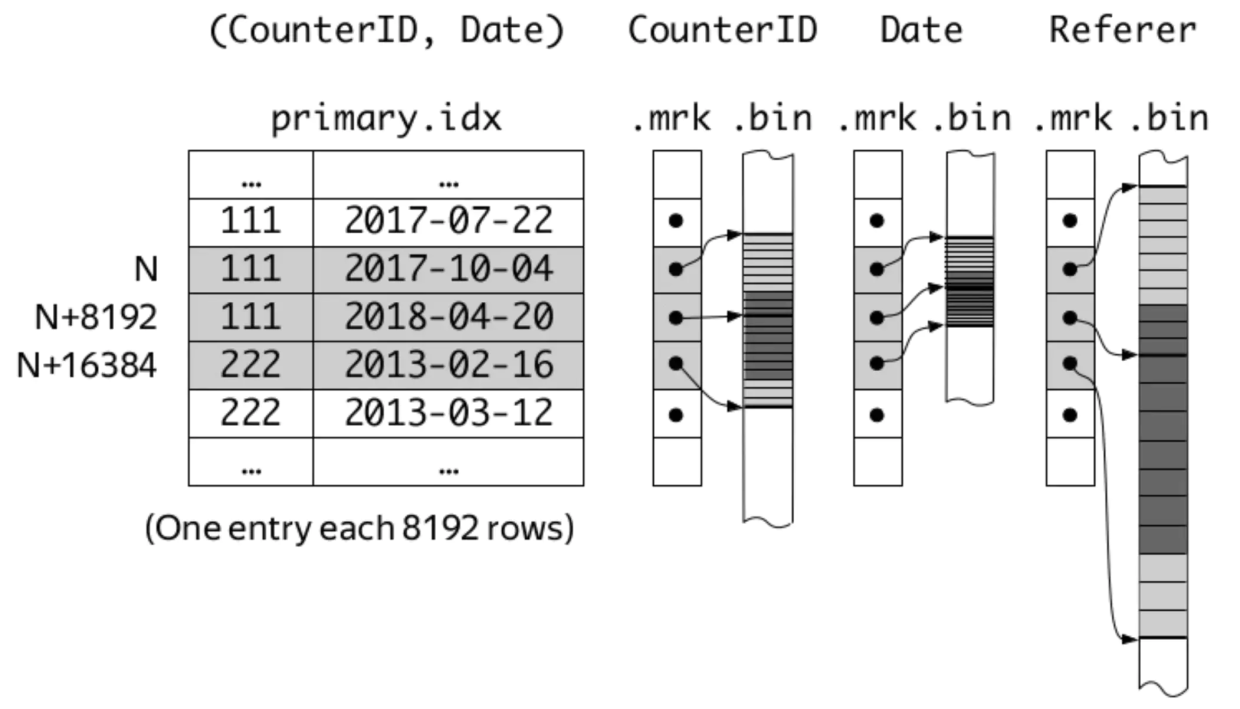
但是早在ClickHouse 19.11.8版本,社区就引入了自适应(adaptive)索引粒度的特性,并且在之后的版本中都是默认开启的。也就是说,主键索引和数据标记生成的间隔可以不再固定,更加灵活。下面通过简单实例来讲解固定索引粒度和自适应索引粒度之间的不同之处。
固定索引粒度
利用Yandex.Metrica提供的hits_v1测试数据集,创建如下的表。
CREATE TABLE datasets.hits_v1_fixed
(`WatchID` UInt64,`JavaEnable` UInt8,`Title` String,-- A lot more columns...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0; -- Disable adaptive index granularity注意使用SETTINGS index_granularity_bytes = 0取消自适应索引粒度。将测试数据导入之后,执行OPTIMIZE TABLE语句触发merge,以方便观察索引和标记数据。
来到merge完成后的数据part目录中——笔者这里是201403_1_32_3,并利用od(octal dump)命令观察primary.idx中的内容。注意索引列一共有3列,Counter和intHash32(UserID)都是32位整形,EventDate是16位整形(Date类型存储的是距离1970-01-01的天数)。
[root@ck-test001 201403_1_32_3]# od -An -i -j 0 -N 4 primary.idx 57 # Counter[0]
[root@ck-test001 201403_1_32_3]# od -An -d -j 4 -N 2 primary.idx 16146 # EventDate[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 6 -N 4 primary.idx 78076527 # intHash32(UserID)[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 10 -N 4 primary.idx 1635 # Counter[1]
[root@ck-test001 201403_1_32_3]# od -An -d -j 14 -N 2 primary.idx 16149 # EventDate[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 16 -N 4 primary.idx 1562260480 # intHash32(UserID)[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 20 -N 4 primary.idx 3266 # Counter[2]
[root@ck-test001 201403_1_32_3]# od -An -d -j 24 -N 2 primary.idx 16148 # EventDate[2]
[root@ck-test001 201403_1_32_3]# od -An -i -j 26 -N 4 primary.idx 490736209 # intHash32(UserID)[2]能够看出ORDER BY的第一关键字Counter确实是递增的,但是不足以体现出index_granularity的影响。因此再观察一下标记文件的内容,以8位整形的Age列为例,比较简单。
[root@ck-test001 201403_1_32_3]# od -An -l -j 0 -N 320 Age.mrk0 00 81920 163840 245760 327680 409600 491520 5734419423 019423 819219423 1638419423 2457619423 3276819423 4096019423 4915219423 5734445658 045658 819245658 1638445658 24576上面打印出了两列数据,表示被选为标记的行的两个属性:第一个属性为该行所处的压缩数据块在对应bin文件中的起始偏移量,第二个属性为该行在数据块解压后,在块内部所处的偏移量,单位均为字节。由于一条Age数据在解压的情况下正好占用1字节,所以能够证明数据标记是按照固定index_granularity的规则生成的。
自适应索引粒度
创建同样结构的表,写入相同的测试数据,但是将index_granularity_bytes设为1MB(为了方便看出差异而已,默认值是10MB),以启用自适应索引粒度。
CREATE TABLE datasets.hits_v1_adaptive
(`WatchID` UInt64,`JavaEnable` UInt8,`Title` String,-- A lot more columns...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192, index_granularity_bytes = 1048576; -- Enable adaptive index granularityindex_granularity_bytes表示每隔表中数据的大小来生成索引和标记,且与index_granularity共同作用,只要满足两个条件之一即生成。
触发merge之后,观察primary.idx的数据。
[root@ck-test001 201403_1_32_3]# od -An -i -j 0 -N 4 primary.idx 57 # Counter[0]
[root@ck-test001 201403_1_32_3]# od -An -d -j 4 -N 2 primary.idx 16146 # EventDate[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 6 -N 4 primary.idx 78076527 # intHash32(UserID)[0]
[root@ck-test001 201403_1_32_3]# od -An -i -j 10 -N 4 primary.idx61 # Counter[1]
[root@ck-test001 201403_1_32_3]# od -An -d -j 14 -N 2 primary.idx16151 # EventDate[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 16 -N 4 primary.idx1579769176 # intHash32(UserID)[1]
[root@ck-test001 201403_1_32_3]# od -An -i -j 20 -N 4 primary.idx63 # Counter[2]
[root@ck-test001 201403_1_32_3]# od -An -d -j 24 -N 2 primary.idx16148 # EventDate[2]
[root@ck-test001 201403_1_32_3]# od -An -i -j 26 -N 4 primary.idx2037061113 # intHash32(UserID)[2]通过Counter列的数据可见,主键索引明显地变密集了,说明index_granularity_bytes的设定生效了。接下来仍然以Age列为例观察标记文件,注意文件扩展名变成了mrk2,说明启用了自适应索引粒度。
[root@ck-test001 201403_1_32_3]# od -An -l -j 0 -N 2048 --width=24 Age.mrk20 0 11200 1120 11200 2240 11200 3360 11200 4480 11200 5600 11200 6720 11200 7840 3520 8192 11110 9303 11110 10414 11110 11525 11110 12636 11110 13747 11110 14858 11110 15969 4150 16384 1096
# 略去一些17694 0 110217694 1102 110217694 2204 110217694 3306 110217694 4408 110217694 5510 110217694 6612 95617694 7568 1104
# ......mrk2文件被格式化成了3列,前两列的含义与mrk文件相同,而第三列的含义则是两个标记之间相隔的行数。可以观察到,每隔1100行左右就会生成一个标记(同时也说明该表内1MB的数据大约包含1100行)。同时,在偏移量计数达到8192、16384等8192的倍数时(即经过了index_granularity的倍数行),同样也会生成标记,证明两个参数是协同生效的。
最后一个问题:ClickHouse为什么要设计自适应索引粒度呢?
当一行的数据量比较大时(比如达到了1kB甚至数kB),单纯按照固定索引粒度会造成每个“颗粒”(granule)的数据量膨胀,拖累读写性能。有了自适应索引粒度之后,每个granule的数据量可以被控制在合理的范围内,官方给定的默认值10MB在大多数情况下都不需要更改。
作者:京东物流 康琪
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源
相关文章:
聊聊ClickHouse MergeTree引擎的固定/自适应索引粒度
前言 我们在刚开始学习ClickHouse的MergeTree引擎时,就会发现建表语句的末尾总会有SETTINGS index_granularity 8192这句话(其实不写也可以),表示索引粒度为8192。在每个data part中,索引粒度参数的含义有二…...
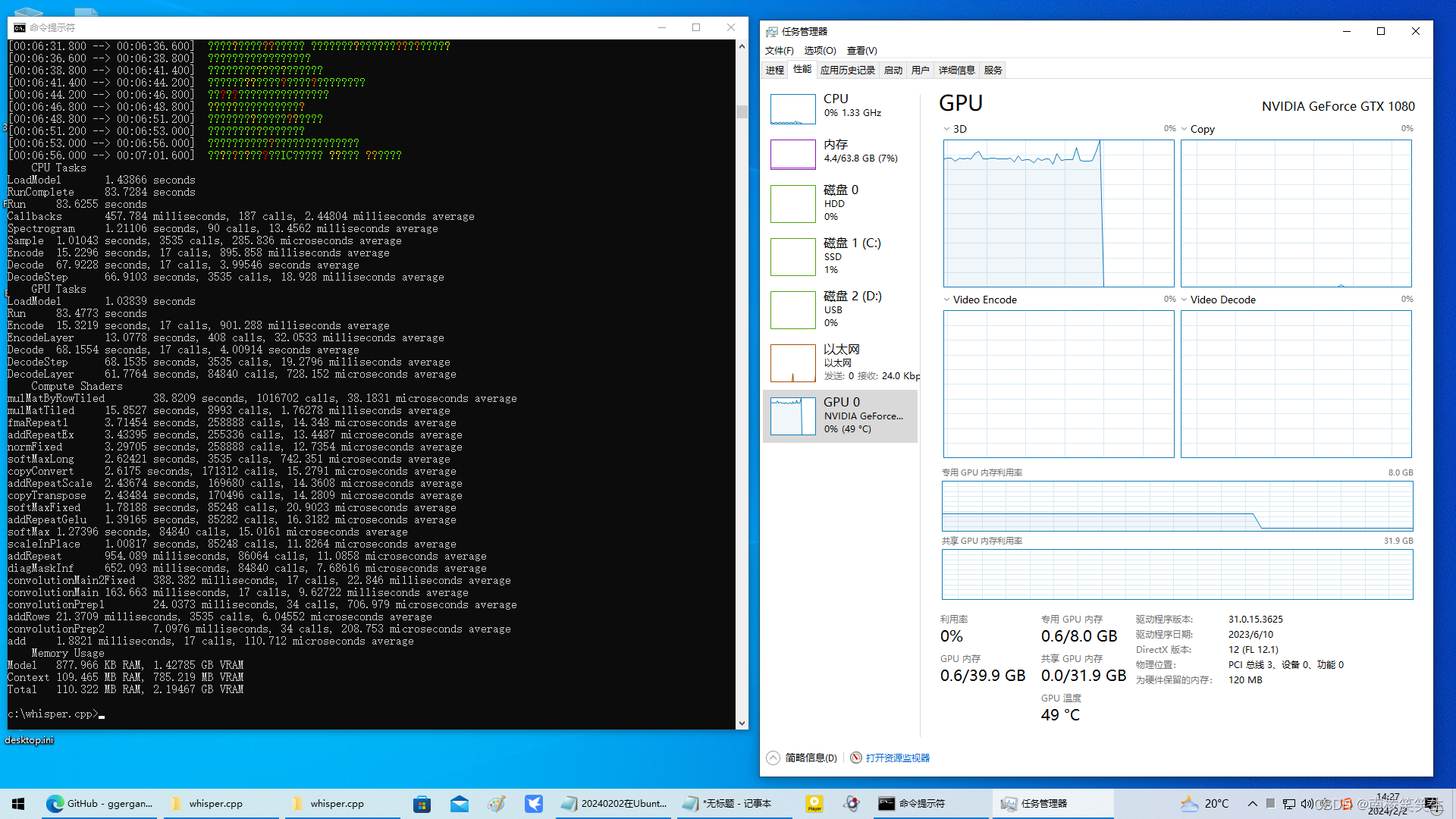
20240202在WIN10下使用whisper.cpp
20240202在WIN10下使用whisper.cpp 2024/2/2 14:15 【结论:在Windows10下,确认large模式识别7分钟中文视频,需要83.7284 seconds,需要大概1.5分钟!效率太差!】 83.7284/4200.1993533333333333333333333333…...

【Linux】基本指令(上)
🦄个人主页:修修修也 🎏所属专栏:Linux ⚙️操作环境:Xshell (操作系统:CentOS 7.9 64位) 目录 Xshell快捷键 Linux基本指令 ls指令 pwd指令 cd指令 touch指令 mkdir指令 rmdir指令/rm指令 结语 Xshell快捷键 AltEnter 全屏/取消全屏 Tab 进…...

【DB2】—— 一次关于db2 sqlcode -420 22018的记录
情况描述 在DB2 10.5数据库中执行以下SQL语句: SELECT * FROM aa WHERE aa.ivc_typ IN (213,123,12334,345)其中aa.ivc_typ列的类型为VARCHAR(10) 关于执行会发生以下情况 类型转换:SQL引擎会尝试把IN列表中的整数常量转换为VARCHAR(10)类型…...
账簿和明细账
目录 一. 账簿的意义和种类二. 明细账 \quad 一. 账簿的意义和种类 \quad 账簿是由一定格式、互有联系的账页组成,以审核无误的会计凭证为依据,用来序时地、分类地记录和反映各项经济业务的会计簿籍(或称账本)。设置和登记账簿是会计工作的重…...
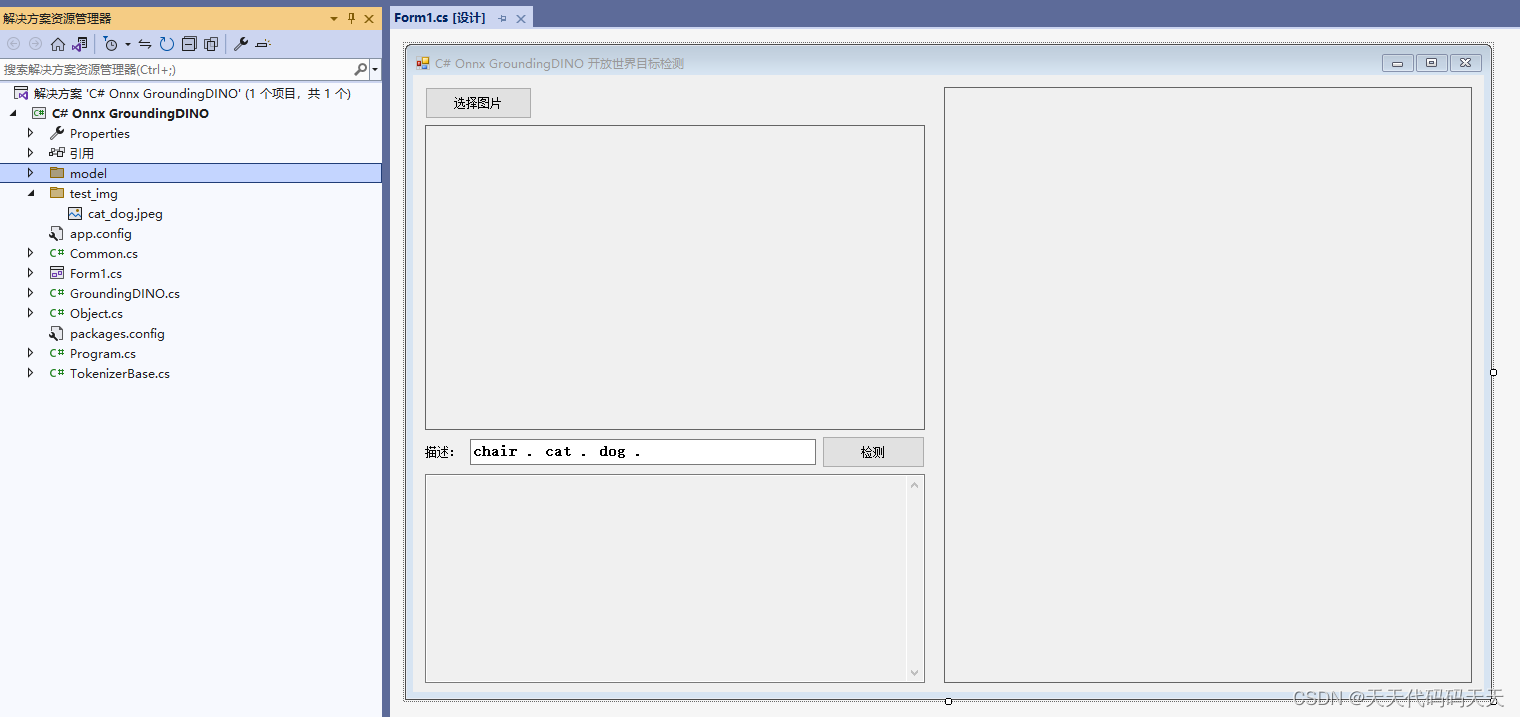
C# Onnx GroundingDINO 开放世界目标检测
目录 介绍 效果 模型信息 项目 代码 下载 介绍 地址:https://github.com/IDEA-Research/GroundingDINO Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" 效果 …...
PyCharm / DataSpell 导入WSL2 解析器,实现GPU加速
PyCharm / DataSpell 导入WSL2 解析器的实现 Windows的解析器不好么?设置WSL2和实现GPU加速为PyCharm / DataSpell 设置WSL解析器设置Interpreter Windows的解析器不好么? Windows上的解析器的确很方便,也省去了我们很多的麻烦。但是WSL2的解…...
Android矩阵Matrix裁切setRectToRect拉伸Bitmap替代Bitmap.createScaledBitmap缩放,Kotlin
Android矩阵Matrix裁切setRectToRect拉伸Bitmap替代Bitmap.createScaledBitmap缩放,Kotlin class MyImageView : AppCompatImageView {private var mSrcBmp: Bitmap? nullprivate var testIV: ImageView? nullconstructor(ctx: Context, attrs: AttributeSet) :…...

TensorFlow2实战-系列教程11:RNN文本分类3
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 6、构建训练数据 所有的输入样本必须都是相同shape(文本长度,…...

故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab)
效果一览 文章概述 故障诊断 | 一文解决,RF随机森林的故障诊断(Matlab) 模型描述 随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,常用于解决分类和回归问题。它由多个决策树组成,每个决策树都独立地对数据进行训练,并且最终的预测结果是由所有决策…...

DAO设计模式
概念:DAO(Data Access Object) 数据库访问对象,**面向数据库SQL操作**的封装。 (一)场景 问题分析 在实际开发中,针对一张表的复杂业务功能通常需要和表交互多次(比如转账)。如果每次针对表的…...

【Midjourney】新手指南:参数设置
1.--aspect 或 --ar 用于设置图片长宽比,例如 --ar 16:9就是设置图片宽为16,高为9 2.--chaos 用于设置躁点,噪点值越高随机性越大,取值为0到100,例如 --chaos 50 3.--turbo 覆盖seetings的设置并启用极速模式生成…...

阿里云a10GPU,centos7,cuda11.2环境配置
Anaconda3-2022.05-Linux-x86_64.sh gcc升级 centos7升级gcc至8.2_centos7 yum gcc8.2.0-CSDN博客 paddlepaddle python -m pip install paddlepaddle-gpu2.5.1.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html 报错 ImportError: libssl.so…...
RTSP/Onvif协议视频平台EasyNVR激活码授权异常该如何解决
TSINGSEE青犀视频安防监控平台EasyNVR可支持设备通过RTSP/Onvif协议接入,并能对接入的视频流进行处理与多端分发,包括RTSP、RTMP、HTTP-FLV、WS-FLV、HLS、WebRTC等多种格式。在智慧安防等视频监控场景中,EasyNVR可提供视频实时监控直播、云端…...

React16源码: React中event事件对象的创建过程源码实现
event 对象 1 ) 概述 在生产事件对象的过程当中,要去调用每一个 possiblePlugin.extractEvents 方法现在单独看下这里面的细节过程,即如何去生产这个事件对象的过程 2 )源码 定位到 packages/events/EventPluginHub.js#L172 f…...
深度学习(12)--Mnist分类任务
一.Mnist分类任务流程详解 1.1.引入数据集 Mnist数据集是官方的数据集,比较特殊,可以直接通过%matplotlib inline自动下载,博主此处已经完成下载,从本地文件中引入数据集。 设置数据路径 from pathlib import Path# 设置数据路…...

AI工具【OCR 01】Java可使用的OCR工具Tess4J使用举例(身份证信息识别核心代码及信息提取方法分享)
Java可使用的OCR工具Tess4J使用举例 1.简介1.1 简单介绍1.2 官方说明 2.使用举例2.1 依赖及语言数据包2.2 核心代码2.3 识别身份证信息2.3.1 核心代码2.3.2 截取指定字符2.3.3 去掉字符串里的非中文字符2.3.4 提取出生日期(待优化)2.3.5 实测 3.总结 1.简…...

【MySQL复制】半同步复制
介绍 除了内置的异步复制之外,MySQL 5.7 还支持通过插件实现的半同步复制接口。本节讨论半同步复制的概念及其工作原理。接下来的部分将涵盖与半同步复制相关的管理界面,以及如何安装、配置和监控它。 异步复制 MySQL 复制默认是异步的。源服务器将事…...

PHP面试知识点--echo、print、print_r、var_dump区别
echo、print、print_r、var_dump 区别 echo 输出单个或多个字符,多个使用逗号分隔无返回值 echo "String 1", "String 2";print 只可以输出单个字符返回1,因此可用于表达式 print "Hello"; if ($expr && pri…...
centos 7 部署若依前后端分离项目
目录 一、新建数据库 二、修改需求配置 1.修改数据库连接 2.修改Redis连接信息 3.文件路径 4.日志存储路径调整 三、编译后端项目 四、编译前端项目 1.上传项目 2.安装依赖 3.构建生产环境 五、项目部署 1.创建目录 2.后端文件上传 3. 前端文件上传 六、服务启…...

HWA05_leetcode48旋转图像
题目解法class Solution:def rotate(self, matrix: List[List[int]]) -> None:"""Do not return anything, modify matrix in-place instead."""#这是一个n行n列的矩阵n len(matrix)#只需要遍历n/2行for i in range(n//2):#每一列从i开始直到…...

如何用Python脚本实现剪映自动化:JianYingApi技术深度解析
如何用Python脚本实现剪映自动化:JianYingApi技术深度解析 【免费下载链接】JianYingApi Third Party JianYing Api. 第三方剪映Api 项目地址: https://gitcode.com/gh_mirrors/ji/JianYingApi 面对视频剪辑中的重复性劳动,你是否渴望解放双手&am…...

避坑指南:RK3588 HDMI输出分辨率不生效?除了改驱动,你还需要检查这几点
RK3588 HDMI输出分辨率调试实战:从代码修改到系统级排查 最近在调试RK3588平台的HDMI输出时,发现一个有趣的现象:明明按照官方文档和社区教程修改了内核驱动代码,添加了3840x216030Hz的分辨率支持,但系统设置里就是找不…...

深入操作系统原理:Qwen3.5-9B-AWQ-4bit解读进程调度与内存管理
深入操作系统原理:Qwen3.5-9B-AWQ-4bit解读进程调度与内存管理 1. 操作系统教学的新助手 计算机操作系统课程向来以抽象难懂著称。学生们常常被进程状态转换、死锁条件、页面置换算法等概念困扰,而传统教学方式又难以直观展示这些动态过程。这正是Qwen…...

Qwen-Image-Edit-2511在云端:集成显卡/Mac也能流畅运行的AI修图方案
Qwen-Image-Edit-2511在云端:集成显卡/Mac也能流畅运行的AI修图方案 1. 为什么选择云端部署Qwen-Image-Edit-2511? 1.1 硬件限制的突破性解决方案 传统AI图像编辑工具对硬件的高要求一直是普通用户的痛点。Qwen-Image-Edit-2511作为最新一代多模态编辑…...

Qwen-Image-Edit效果展示:模糊老照片修复前后对比,惊艳!
Qwen-Image-Edit效果展示:模糊老照片修复前后对比,惊艳! 1. 老照片修复技术的新突破 当我们翻出泛黄的老照片,那些模糊不清的面孔常常让人感到遗憾。传统的老照片修复需要专业设计师花费数小时进行手工修复,而现在&a…...

AI净界RMBG-1.4使用技巧:让抠图效果更完美的几个小方法
AI净界RMBG-1.4使用技巧:让抠图效果更完美的几个小方法 1. 为什么抠图效果有时不够理想? 即使是目前最先进的RMBG-1.4模型,在某些特殊情况下也可能出现边缘不够完美的情况。这通常不是模型本身的问题,而是由于输入图片的特性导致…...

Phi-4-mini-reasoning企业知识图谱增强:实体关系推理与逻辑补全案例
Phi-4-mini-reasoning企业知识图谱增强:实体关系推理与逻辑补全案例 1. 模型简介与核心能力 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别强化了数…...
)
为什么你的EventHandler仍触发装箱?C# 13 `ref delegate`与`unmanaged`委托语法(仅限.NET 8.0.3+ RTM)
第一章:为什么你的EventHandler仍触发装箱?C# 13 ref delegate与unmanaged委托语法(仅限.NET 8.0.3 RTM)即使在 .NET 8.0.3 RTM 中启用了 C# 13 的新委托特性,许多开发者仍观察到 EventHandler 回调中频繁发生值类型参…...

专业数据恢复师工具箱揭秘:UFS Explorer Pro的5个高级功能实战解析
专业数据恢复师工具箱揭秘:UFS Explorer Pro的5个高级功能实战解析 当一块硬盘的文件系统彻底崩溃,分区表不知所踪,或是RAID阵列的配置信息丢失时,普通数据恢复软件往往束手无策。这正是UFS Explorer Professional Recovery展现其…...