【大数据】Flink SQL 语法篇(二):WITH、SELECT WHERE、SELECT DISTINCT
Flink SQL 语法篇(二)
- 1.WITH 子句
- 2.SELECT & WHERE 子句
- 3.SELECT DISTINCT 子句
1.WITH 子句
应用场景(支持 Batch / Streaming):With 语句和离线 Hive SQL With 语句一样的,语法糖 +1,使用它可以让你的代码逻辑更加清晰。
-- 语法糖 +1
WITH orders_with_total AS (SELECT order_id, price + tax AS totalFROM Orders
)
SELECT order_id, SUM(total)
FROM orders_with_total
GROUP BY order_id;
2.SELECT & WHERE 子句
应用场景(支持 Batch / Streaming):SELECT & WHERE 语句和离线 Hive SQL 语句一样的,常用作 ETL,过滤,字段清洗标准化。
INSERT INTO target_table
SELECT * FROM OrdersINSERT INTO target_table
SELECT order_id, price + tax FROM OrdersINSERT INTO target_table
-- 自定义 Source 的数据
SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)INSERT INTO target_table
SELECT price + tax FROM Orders WHERE id = 10-- 使用 UDF 做字段标准化处理
INSERT INTO target_table
SELECT PRETTY_PRINT(order_id) FROM Orders
-- 过滤条件
Where id > 3
其实理解一个 SQL 最后生成的任务是怎样执行的,最好的方式就是理解其语义。
以下面的 SQL 为例,我们来介绍下其在离线中和在实时中执行的区别,对比学习一下,大家就比较清楚了。
INSERT INTO target_table
SELECT PRETTY_PRINT(order_id) FROM Orders
Where id > 3
这个 SQL 对应的实时任务,假设 Orders 为 Kafka,target_table 也为 Kafka,在执行时,会生成三个算子:
- 数据源算子(
From Order):连接到 Kafka topic,数据源算子一直运行,实时的从OrdersKafka 中一条一条的读取数据,然后一条一条发送给下游的 过滤和字段标准化算子。 - 过滤和字段标准化算子(
Where id > 3和PRETTY_PRINT(order_id)):接收到上游算子发的一条一条的数据,然后判断id > 3 ?,将判断结果为true的数据执行PRETTY_PRINT UDF后,一条一条将计算结果数据发给下游 数据汇算子。 - 数据汇算子(
INSERT INTO target_table):接收到上游发的一条一条的数据,写入到target_tableKafka 中。
可以看到这个实时任务的所有算子是以一种 Pipeline 模式运行的,所有的算子在同一时刻都是处于 running 状态的,24 小时一直在运行,实时任务中也没有离线中常见的分区概念。

⭐ 关于看如何看一段 Flink SQL 最终的执行计划:最好的方法就如上图,看 Flink Web UI 的算子图,算子图上详细的标记清楚了每一个算子做的事情。
以上图来说,我们可以看到主要有三个算子:
- Source 算子。Source: TableSourceScan(table=[[default_catalog, default_database, Orders]], fields=[order_id, name]) -> Calc(select=[order_id, name, CAST(CURRENT_TIMESTAMP()) AS row_time]) -> WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)])
- 其中 Source 表名称为
table=[[default_catalog, default_database, Orders]。 - 字段为
select=[order_id, name, CAST(CURRENT_TIMESTAMP()) AS row_time]。 - Watermark 策略为
rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]。
- 其中 Source 表名称为
- 过滤算子。Calc(select=[order_id, name, row_time], where=[(order_id > 3)]) -> NotNullEnforcer(fields=[order_id])
- 其中过滤条件为
where=[(order_id > 3)]。 - 结果字段为
select=[order_id, name, row_time]。
- 其中过滤条件为
- Sink 算子。Sink: Sink(table=[default_catalog.default_database.target_table], fields=[order_id, name, row_time])
- 其中最终产出的表名称为
table=[default_catalog.default_database.target_table]。 - 表字段为
fields=[order_id, name, row_time]。
- 其中最终产出的表名称为
可以看到 Flink SQL 具体执行了哪些操作是非常详细的标记在算子图上。所以小伙伴萌一定要学会看算子图,这是掌握 Debug、调优前最基础的一个技巧。
那么如果这个 SQL 放在 Hive 中执行时,假设其中 Orders 为 Hive 表,target_table 也为 Hive 表,其也会生成三个类似的算子(虽然实际可能会被优化为一个算子,这里为了方便对比,划分为三个进行介绍),离线和实时任务的执行方式完全不同:
- 数据源算子(
From Order):数据源从OrdersHive 表(通常都是读一天、一小时的分区数据)中一次性读取所有的数据,然后将读到的数据全部发给下游 过滤和字段标准化算子,然后 数据源算子 就运行结束了,释放资源了。 - 过滤和字段标准化算子(
Where id > 3和PRETTY_PRINT(order_id)):接收到上游算子的所有数据,然后遍历所有数据判断id > 3 ?,将判断结果为true的数据执行PRETTY_PRINT UDF后,将所有数据发给下游 数据汇算子,然后 过滤和字段标准化算子 就运行结束了,释放资源了 - 数据汇算子(
INSERT INTO target_table):接收到上游的所有数据,将所有数据都写到target_tableHive 表中,然后整个任务就运行结束了,整个任务的资源也就都释放了
可以看到离线任务的算子是分阶段(Stage)进行运行的,每一个 Stage 运行结束之后,然后下一个 Stage 开始运行,全部的 Stage 运行完成之后,这个离线任务就跑结束了。
注意:很多小伙伴都是之前做过离线数仓的,熟悉了离线的分区、计算任务定时调度运行这两个概念,所以在最初接触 Flink SQL 时,会以为 Flink SQL 实时任务也会存在这两个概念,这里博主做一下解释:
- 分区概念:离线由于能力限制问题,通常都是进行一批一批的数据计算,每一批数据的数据量都是有限的集合,这一批一批的数据自然的划分方式就是时间,比如按小时、天进行划分分区。但是 在实时任务中,是没有分区的概念的,实时任务的上游、下游都是无限的数据流。
- 计算任务定时调度概念:同上,离线就是由于计算能力限制,数据要一批一批算,一批一批输入、产出,所以要按照小时、天定时的调度和计算。但是 在实时任务中,是没有定时调度的概念的,实时任务一旦运行起来就是 24 小时不间断,不间断的处理上游无限的数据,不简单的产出数据给到下游。
3.SELECT DISTINCT 子句
应用场景(支持 Batch / Streaming):语句和离线 Hive SQL SELECT DISTINCT 语句一样的,用作根据 key 进行数据去重。
INSERT into target_table
SELECT DISTINCT id
FROM Orders
也是拿离线和实时做对比。
这个 SQL 对应的实时任务,假设 Orders 为 kafka,target_table 也为 Kafka,在执行时,会生成三个算子:
- 数据源算子(
From Order):连接到 Kafka topic,数据源算子一直运行,实时的从 Orders Kafka 中一条一条的读取数据,然后一条一条发送给下游的 去重算子。 - 去重算子(
DISTINCT id):接收到上游算子发的一条一条的数据,然后判断这个id之前是否已经来过了,判断方式就是使用 Flink 中的state状态,如果状态中已经有这个id了,则说明已经来过了,不往下游算子发,如果状态中没有这个id,则说明没来过,则往下游算子发,也是一条一条发给下游 数据汇算子。 - 数据汇算子(
INSERT INTO target_table):接收到上游发的一条一条的数据,写入到target_tableKafka 中。

对于实时任务,计算时的状态可能会无限增长。状态大小取决于不同 key(上述案例为 id 字段)的数量。为了防止状态无限变大,我们可以设置状态的 TTL。但是这可能会影响查询结果的正确性,比如某个 key 的数据过期从状态中删除了,那么下次再来这么一个 key,由于在状态中找不到,就又会输出一遍。
那么如果这个 SQL 放在 Hive 中执行时,假设其中 Orders 为 Hive 表,target_table 也为 Hive 表,其也会生成三个相同的算子(虽然可能会被优化为一个算子,这里为了方便对比,划分为三个进行介绍),但是其和实时任务的执行方式完全不同:
- 数据源算子(
From Order):数据源从OrdersHive 表(通常都有天、小时分区限制)中一次性读取所有的数据,然后将读到的数据全部发给下游 去重算子,然后 数据源算子 就运行结束了,释放资源了。 - 去重算子(
DISTINCT id):接收到上游算子的所有数据,然后遍历所有数据进行去重,将去重完的所有结果数据发给下游 数据汇算子,然后 去重算子 就运行结束了,释放资源了。 - 数据汇算子(
INSERT INTO target_table):接收到上游的所有数据,将所有数据都写到target_tableHive 中,然后整个任务就运行结束了,整个任务的资源也就都释放了。
相关文章:
【大数据】Flink SQL 语法篇(二):WITH、SELECT WHERE、SELECT DISTINCT
Flink SQL 语法篇(二) 1.WITH 子句2.SELECT & WHERE 子句3.SELECT DISTINCT 子句 1.WITH 子句 应用场景(支持 Batch / Streaming):With 语句和离线 Hive SQL With 语句一样的,语法糖 1,使用…...

leetcode-链表专题
25.K个一组翻转链表 题目链接 25. K 个一组翻转链表 - 力扣(LeetCode) 解题思路 # Definition for singly-linked list. # class ListNode: # def __init__(self, val0, nextNone): # self.val val # self.next next class So…...
Vue打包Webpack源码及物理路径泄漏问题解决
修复前: 找到vue.config.js文件,在其中增加配置 module.exports {productionSourceMap: false,// webpack 配置configureWebpack: {devtool: false,}}其中打包的物理路径泄露我这边试了好多次,发现只有打包的时候NODE_ENVproduction 才能保…...
MySQL学习记录——일 MySQL 安装、配置
文章目录 1、卸载内置环境2、安装MySQL3、启动4、登录5、配置my.cnf 当前环境是1核2G云服务器,CentOS7.6。要在root用户下进行操作 1、卸载内置环境 云服务器中有可能会自带mysql还有mariadb这样的数据库服务,在安装我们mysql前,得先查找一下…...
获取真实 IP 地址(二):绕过 CDN(附链接)
一、DNS历史解析记录 DNS 历史解析记录指的是一个域名在过去的某个时间点上的DNS解析信息记录。这些记录包含了该域名过去使用的IP地址、MX记录(邮件服务器)、CNAME记录(别名记录)等 DNS 信息。DNS 历史记录对于网络管理员、安全研…...

正则表达式补充以及sed
正则表达式: 下划线算 在单词里面 解释一下过程: 在第二行hello world当中,hello中的h 与后面第一个h相匹配,所以hello中的ello可以和abcde匹配 在world中,w先匹配h匹配不上,则在看0,r&#…...

LLM智能体开发指南
除非你一直生活在岩石下,否则你一定听说过像 Auto-GPT 和 MetaGPT 这样的项目。 这些是社区为使 GPT-4 完全自治而做出的尝试。在其最原始的形式中,代理基本上是文本到任务。你输入一个任务描述,比如“给我做一个贪吃蛇游戏”,并使…...

基于springboot校园二手书交易管理系统源码和论文
在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括乐校园二手书交易管理系统的网络应用,在外国二手书交易管理系统已经是很普遍的方式,不过国内的管理系统可能还处于起步阶段。乐校园二手书交易管理系统…...
Oracle和Mysql数据库
数据库 Oracle 体系结构与基本概念体系结构基本概念表空间(users)和数据文件段、区、块Oracle数据库的基本元素 Oracle数据库启动和关闭Oracle数据库启动Oracle数据库关闭 Sqlplussqlplus 登录数据库管理系统使用sqlplus登录Oracle数据库远程登录解锁用户修改用户密码查看当前语…...

java学习笔记:java常见注解语句汇总、解析及应用
文章目录 一、什么是注解二、注解有什么作用三、常见的Java注解及其功能介绍和示例OverrideDeprecatedSuppressWarningsFunctionalInterfaceSafeVarargsSuppressWarnings 一、什么是注解 Java中所有以开头的语句被称为注解(Annotation)。 注解是一种元数…...
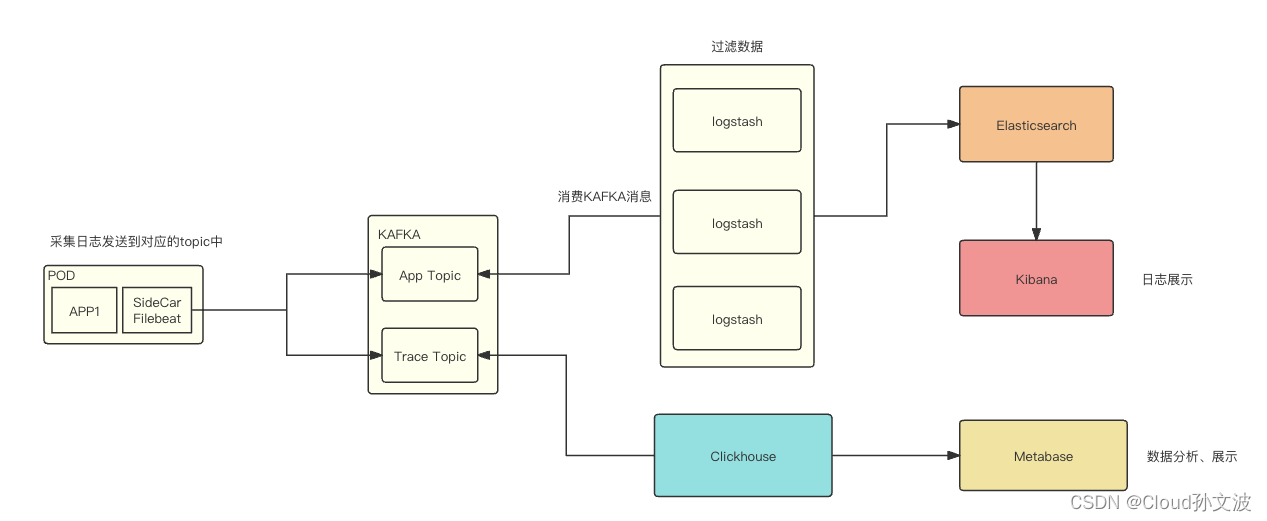
k8s Sidecar filebeat 收集容器中的trace日志和app日志
目录 一、背景 二、设计 三、具体实现 Filebeat配置 K8S SideCar yaml Logstash配置 一、背景 将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC 二、…...
三维模型设计新纪元:3D开发工具HOOPS在机械加工行业的应用与优势
在当今快速发展的科技时代,机械加工行业正经历着巨大的变革,而HOOPS技术正是其中一项重要的创新。HOOPS技术不仅仅是一种用于处理和可视化计算机辅助设计(CAD)数据的工具,更是机械加工领域中提升效率、优化设计的利器。…...

Python爬虫子页面并写入text代码
这是工具类 class UrlManager():"""url管理器"""def __init__(self):self.new_urls set()self.old_urls set()def add_new_url(self,url):if url is None or len(url) 0:returnif url in self.new_urls or url in self.old_urls:returnself.…...

《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境
01 环境搭建 《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境 Docker部署PyTorch 拉取cnstark/pytorch镜像 拉取镜像: docker pull cnstark/pytorch:2.0.1-py3.10.11-cuda11.8.0-ubuntu22.04导出镜像: docker sa…...

MySQL进阶之触发器
触发器 触发器是与表有关的数据库对象,指在insert/update/delete之前(BEFORE)或之后(AFTER),触 发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。 使用别名OLD和NEW来引用…...
循环神经网络RNN专题(01/6)
一、说明 RNN用于处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么&a…...

C# 怎么判断屏幕是第几屏幕?屏幕是垂直还是水平?屏幕的分辨率?
一、怎么判断屏幕是第几屏幕? 可以使用System.Windows.Forms.Screen.AllScreens属性来获取所有已连接的屏幕,并根据鼠标位置或窗口的位置来判断它所在的屏幕索引。 using System; using System.Windows.Forms;// 获取鼠标当前位置所在的屏幕 Point cur…...

在 SQL Server 中使用 SQL 语句查询不同时间范围的数据
在 SQL Server 中,我们经常需要从数据库中检索特定时间范围内的数据。通过合理运用 SQL 语句,我们可以轻松地查询今天、昨天、近7天、近30天、一个月内、上一月、本年和去年的数据。下面是一些示例 SQL 查询,让我们逐一了解。 查询今天的数据…...

学习使用Flask模拟接口进行测试
前言 学习使用一个新工具,首先找一段代码学习一下,基本掌握用法,然后再考虑每一部分是做什么的 Flask的初始化 app Flask(__name__):初始化,创建一个该类的实例,第一个参数是应用模块或者包的名称 app…...

深度学习快速入门--7天做项目
深度学习快速入门--7天做项目 0. 引言1. 本文内容2. 深度学习是什么3. 项目是一个很好的切入点4. 7天做项目4.1 第一天:数据整理4.2 第二天:数据处理4.3 第三天:简单神经网络设计4.4 第四天:分析效果与原因4.5 第五天:…...

如何用ROFL播放器轻松管理你的英雄联盟回放文件
如何用ROFL播放器轻松管理你的英雄联盟回放文件 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟回放文件管理而烦恼吗&am…...

VMware 虚拟机网络问题排查与解决方案
VMware 虚拟机网络问题排查与解决方案 问题背景 在项目中时,遇到一个看似 "网络不通" 的问题:Windows 宿主机无法 ping 通虚拟机上的 VIP 地址。 症状表现: 虚拟机可以 ping 通 Windows 宿主机Windows 宿主机无法 ping 通虚拟机…...

PyWxDump:让微信数据管理更简单的本地解决方案
PyWxDump:让微信数据管理更简单的本地解决方案 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 你是否曾因电脑故障丢失数年积累的重要聊天记录?是否尝试过将关键对话整理成可检索格式却发现无从下手…...

SOONet模型数据库课程设计项目:构建视频内容管理分析系统
SOONet模型数据库课程设计项目:构建视频内容管理分析系统 最近和几个计算机专业的同学聊天,发现他们正为数据库课程设计选题发愁。老师要求项目既要体现数据库设计的核心知识,又最好能结合一些前沿技术,做出点新意来。这让我想起…...
)
别再只盯着YOLO了!用ByteTrack在Python里实现一个简易的车辆跟踪器(附完整代码)
用PythonByteTrack打造高精度车辆追踪系统:从原理到实战 在智能交通和视频监控领域,目标追踪技术正发挥着越来越重要的作用。当我们需要分析交通流量、统计车辆类型或监测异常行为时,仅仅依靠目标检测是远远不够的——我们还需要知道同一个目…...

主流AI命理工具实测:八字紫微梅花六爻避坑指南
1. 当大模型遇上传统命理:AI算命实测背景 最近身边不少科技圈朋友都在讨论用AI工具辅助命理分析:做技术的研究起了八字排盘,产品经理案头放着命理相关资料,连程序员开会间隙都会聊两句卦象。作为长期关注AI应用的从业者࿰…...

通义千问2.5-7B从下载到对话:完整部署流程与代码示例
通义千问2.5-7B从下载到对话:完整部署流程与代码示例 1. 引言 1.1 为什么选择通义千问2.5-7B 通义千问2.5-7B-Instruct是阿里云2024年9月发布的中等规模开源大模型,具有以下突出优势: 性能强劲:在7B参数级别中英文综合能力领先…...

Qt播放MP4视频时,如何优雅地处理播放列表和播放模式?一个实战案例分享
Qt播放MP4视频时如何优雅处理播放列表与播放模式 在开发多媒体应用时,播放列表管理和播放模式切换往往是比基础播放功能更具挑战性的部分。本文将深入探讨如何在Qt框架下构建一个健壮的MP4播放器,重点解决播放列表的智能管理和多种播放模式的优雅实现。…...

OpenClaw多模态创作助手:千问3.5-35B-A3B-FP8生成技术文章与配图
OpenClaw多模态创作助手:千问3.5-35B-A3B-FP8生成技术文章与配图 1. 为什么需要自动化技术博客创作 作为一个经常写技术博客的开发者,我发现自己总在重复同样的劳动:查资料、写初稿、找配图、调格式。每次想分享一个新技术的使用心得&#…...

Wux Weapp 终极国际化方案:打造多语言小程序完整指南
Wux Weapp 终极国际化方案:打造多语言小程序完整指南 【免费下载链接】wux-weapp :dog: 一套组件化、可复用、易扩展的微信小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/wu/wux-weapp 想要让你的微信小程序走向全球市场吗?Wux Wea…...