LLM智能体开发指南
除非你一直生活在岩石下,否则你一定听说过像 Auto-GPT 和 MetaGPT 这样的项目。 这些是社区为使 GPT-4 完全自治而做出的尝试。在其最原始的形式中,代理基本上是文本到任务。你输入一个任务描述,比如“给我做一个贪吃蛇游戏”,并使用LLM作为它的大脑和一些围绕它构建的工具,你就得到了自己的贪吃蛇游戏! 看,连我也做了一个!
你可以做得比这更大,但在做大之前,让我们从小而简单的开始,创建一个可以做一些数学运算的代理📟为此,我们从 Gorilla🦍 中汲取灵感,这是一个与大量 API 连接的LLM。
首先,我们选择LLM并创建一个数据集。
在本教程中,我们将使用 meta-llama/Llama-2–7b-chat-hf 模型和 rohanbalkondekar/generate_json 数据集。代码可以从这里访问。
是的,有一种更好的数学方法,例如通过使用 py-expression-eval 使用 JavaScript 的 eval 函数来进行数学表达式,但我将使用这种类似于 API 调用中的有效负载的格式,尽管如此,它只是简单的 add( a,b) 函数或在本例中为 add(8945, 1352) :
{ "function_name": "add", "parameter_1": "8945", "parameter_2": "1352" }
微调就像对现有项目进行更改,而不是从头开始开发所有内容。 这就是为什么我们使用 Llama-2-7b-chat 模型而不仅仅是预先训练的模型 Llama-2–7b,这会让我们的事情变得更容易。 如果我们使用 Llama-2-chat,我们必须使用以下提示格式:
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>{{ user_message }} [/INST]
你还可以使用较小的模型(例如 microsoft/phi-1.5)来执行简单任务,或者像我一样 GPU 不足。
由于 Microsoft 仅发布了预训练模型,因此你可以使用社区发布的微调模型,例如 openaccess-ai-collective/phi-platypus-qlora 或 teknium/Puffin-Phi-v2 。
对于 teknium/Puffin-Phi-v2,提示模板为:
USER: <prompt>
ASSISTANT:
现在,我们遇到了一个问题,有如此多的模型,如 llama、phi、mistral、falcon 等,你不能只将模型名称更改为 model_path = "microsoft/phi-1.5" 并期望一切正常。
如果有一个工具可以做到这一点是不是很棒?这就是 axolotl !
###Installationgit clone https://github.com/OpenAccess-AI-Collective/axolotl
cd axolotlpip3 install packaging
pip3 install -e '.[flash-attn,deepspeed]'
pip3 install -U git+https://github.com/huggingface/peft.git
有时安装axolotl可能会很棘手。确保
- CUDA > 11.7
- Python >=3.9
- Pytorch >=2.0
- PyTorch 版本与 Cuda 版本匹配
- 创建新的虚拟环境或docker
这里我们使用以下数据集:rohanbalkondekar/maths_function_calls
下载或创建名为“maths_function_calls.jsonl”的文件,然后复制并粘贴上述链接中的内容。
然后从示例文件夹中复制现有模型的 .yml 文件,并根据需要更改参数。
或者创建一个全新的 .yml 文件,例如 phi-finetune.yml,其配置如下:
base_model: teknium/Puffin-Phi-v2
base_model_config: teknium/Puffin-Phi-v2
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
is_llama_derived_model: false
trust_remote_code: trueload_in_8bit: false
load_in_4bit: true
strict: falsedatasets:- path: maths_function_calls.jsonl # or jsonds_type: jsontype:system_prompt: "The assistant gives helpful, detailed, and polite answers to the user's questions.\n"no_input_format: |-USER: {instruction}<|endoftext|>ASSISTANT:format: |-USER: {instruction}{input}<|endoftext|>ASSISTANT:dataset_prepared_path: last_run_prepared
val_set_size: 0.05
output_dir: ./phi-finetunedsequence_len: 1024
sample_packing: false # not CURRENTLY compatible with LoRAs
pad_to_sequence_len:adapter: qlora
lora_model_dir:
lora_r: 64
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:wandb_project:
wandb_entity:
wandb_watch:
wandb_run_id:
wandb_log_model:gradient_accumulation_steps: 1
micro_batch_size: 1
num_epochs: 50
optimizer: adamw_torch
adam_beta2: 0.95
adam_epsilon: 0.00001
max_grad_norm: 1.0
lr_scheduler: cosine
learning_rate: 0.000003train_on_inputs: false
group_by_length: true
bf16: true
fp16: false
tf32: truegradient_checkpointing:
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention:warmup_steps: 100
eval_steps: 0.05
save_steps:
debug:
deepspeed:
weight_decay: 0.1
fsdp:
fsdp_config:
resize_token_embeddings_to_32x: true
special_tokens:bos_token: "<|endoftext|>"eos_token: "<|endoftext|>"unk_token: "<|endoftext|>"pad_token: "<|endoftext|>"
使用以下命令开始微调:
accelerate launch -m axolotl.cli.train phi-finetune.yml
你将开始收到这样的日志,这意味着微调正在进行中。
{'loss': 0.0029, 'learning_rate': 1.7445271850805345e-07, 'epoch': 20.44} 85%|███████████████████████████████████████████████████████████▌ | 1942/2280 [06:13<01:14, 4.51it/s]`attention_mask` is not supported during training. Using it might lead to unexpected results.
微调完成后,会得到一个新目录 phi-finetuned。现在,使用以下命令开始推断微调模型。
accelerate launch -m axolotl.cli.inference phi-ft.yml --lora_model_dir="./phi-finetuned"
现在,按照自定义提示模板,如果输入:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: I want to do a total of 8945 and 1352 <|endoftext|>
ASSISTANT: Here is your generated JSON:
你应该收到以下输出:
The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: I want to do a total of 8945 and 1352<|endoftext|>ASSISTANT: Here is your generated JSON:
```json
{ "function_name": "total", "parameter_1": "8945", "parameter_2": "1352"
}
```<|endoftext|>
现在,你可以轻松地从输出中提取 json,并可以进行函数调用来显示计算的输出。 (微调 llama2 的示例:链接)
这是开始推断微调模型的基本代码:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizermodel_path = "phi-finetuned" #or "mistralai/Mistral-7B-Instruct-v0.1" This approach works for most models, so you can use this to infer many hf models
tokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,load_in_4bit=True, trust_remote_code=True,device_map="auto",
)while True:prompt = input("Enter Prompt: ")input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")gen_tokens = model.generate(input_ids, do_sample=True, max_length=100)generated_text = tokenizer.batch_decode(gen_tokens)[0]print(generated_text)
下面的代码格式化输入并提取 JSON:
import re
import math
import json
import torch
from transformers import (AutoModelForCausalLM,AutoTokenizer,
)# Path to saved model
model_path = "phi-ft-5"
tokenizer = AutoTokenizer.from_pretrained(model_path)# Load model
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16,load_in_4bit=True,trust_remote_code=True,device_map="auto",
)def evaluate_json(json_data):function_name = json_data.get("function_name")parameter_1 = float(json_data.get("parameter_1", 0))parameter_2 = float(json_data.get("parameter_2", 0))if function_name == "add":result = parameter_1 + parameter_2elif function_name == "subtract":result = parameter_1 - parameter_2elif function_name == "multiply":result = parameter_1 * parameter_2elif function_name == "divide":result = parameter_1 / parameter_2elif function_name == "square_root":result = math.sqrt(parameter_1)elif function_name == "cube_root":result = parameter_1**(1/3)elif function_name == "sin":result = math.sin(math.radians(parameter_1))elif function_name == "cos":result = math.cos(math.radians(parameter_1))elif function_name == "tan":result = math.tan(math.radians(parameter_1))elif function_name == "log_base_2":result = math.log2(parameter_1)elif function_name == "ln":result = math.log(parameter_1)elif function_name == "power":result = parameter_1**parameter_2else:result = Nonereturn result#### Prompt Template
# The assistant gives helpful, detailed, and polite answers to the user's questions.
# USER: Reply with json for the following question: what is 3 time 67? <|endoftext|>
# ASSISTANT: Here is your generated JSON:
# ```jsonwhile True:prompt = input("Ask Question: ")formatted_prompt = f'''The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: {prompt} <|endoftext|>
ASSISTANT: Here is your generated JSON:
```json
'''input_ids = tokenizer(formatted_prompt, return_tensors="pt").input_ids.to("cuda")gen_tokens = model.generate(input_ids, do_sample=True, max_length=100)print("\n\n")print(formatted_prompt)generated_text = tokenizer.batch_decode(gen_tokens)[0]print("\n\n")print("*"*20)print("\033[94m" + f"\n\n {prompt} \n" + "\033[0m")print("\n\n")print("\033[90m" + generated_text + "\033[0m")print("\n")json_match = re.search(r'json\s*({.+?})\s*', generated_text, re.DOTALL)if json_match:json_string = json_match.group(1)try:json_data = json.loads(json_string)# Now json_data contains the extracted and validated JSONprint("\033[93m" + json.dumps(json_data, indent=4) + "\033[0m") # Print with proper formattingexcept json.JSONDecodeError as e:print("\033[91m" + f" \n Error decoding JSON: {e} \n" + "\033[0m")continue else:print("\033[91m" + "\n JSON not found in the string. \n" + "\033[0m")continue result = evaluate_json(json_data)print(f"\n\n \033[92mThe result is: {result} \033[0m \n\n")print("*"*20)print("\n\n")
如果一切顺利,你应该得到如下所示的输出:
Ask Question: what it cube root of 8?Formatted Prompt:The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: what it cube root of 8? <|endoftext|>
ASSISTANT: Here is your generated JSON:
```jsonGenerated Responce:The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Reply with json for the following question: what it cube root of 8? <|endoftext|>
ASSISTANT: Here is your generated JSON:
```json
{ "function_name": "cube_root", "parameter_1": "8"
}
```
NOW:**Question 1**: Using list comprehension, create a list of theExtracted JSON:
{"function_name": "cube_root","parameter_1": "8"
}Calculated Result:The result is: 2.0 ********************
潜在的陷阱:在这里,我们使用一个较小的模型“phi”,只有 100 行的微调数据根本不足以让这种大小的模型泛化,因此我们得到了太多的幻觉。 请注意,这只是举例,为了获得更好的结果,请使用更大的模型、更好的数据以及更多数据的更多纪元
模型有时可能会产生幻觉,为了缓解这种情况,只需增加训练数据,以便模型可以泛化,并确保只使用高质量的数据进行训练。 或者增加纪元数 num_epoches 您也可以尝试更大的模型,例如 llama-2–7B 或 mistra-7B-Instruct
恭喜!你已经微调了第一个 LLM 模型并创建了一个原始代理!
相关文章:

LLM智能体开发指南
除非你一直生活在岩石下,否则你一定听说过像 Auto-GPT 和 MetaGPT 这样的项目。 这些是社区为使 GPT-4 完全自治而做出的尝试。在其最原始的形式中,代理基本上是文本到任务。你输入一个任务描述,比如“给我做一个贪吃蛇游戏”,并使…...

基于springboot校园二手书交易管理系统源码和论文
在Internet高速发展的今天,我们生活的各个领域都涉及到计算机的应用,其中包括乐校园二手书交易管理系统的网络应用,在外国二手书交易管理系统已经是很普遍的方式,不过国内的管理系统可能还处于起步阶段。乐校园二手书交易管理系统…...
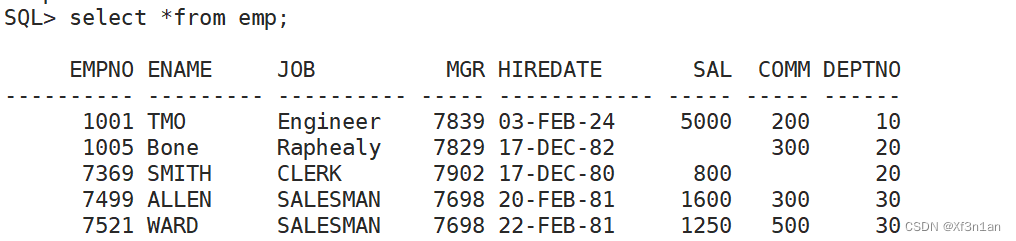
Oracle和Mysql数据库
数据库 Oracle 体系结构与基本概念体系结构基本概念表空间(users)和数据文件段、区、块Oracle数据库的基本元素 Oracle数据库启动和关闭Oracle数据库启动Oracle数据库关闭 Sqlplussqlplus 登录数据库管理系统使用sqlplus登录Oracle数据库远程登录解锁用户修改用户密码查看当前语…...

java学习笔记:java常见注解语句汇总、解析及应用
文章目录 一、什么是注解二、注解有什么作用三、常见的Java注解及其功能介绍和示例OverrideDeprecatedSuppressWarningsFunctionalInterfaceSafeVarargsSuppressWarnings 一、什么是注解 Java中所有以开头的语句被称为注解(Annotation)。 注解是一种元数…...
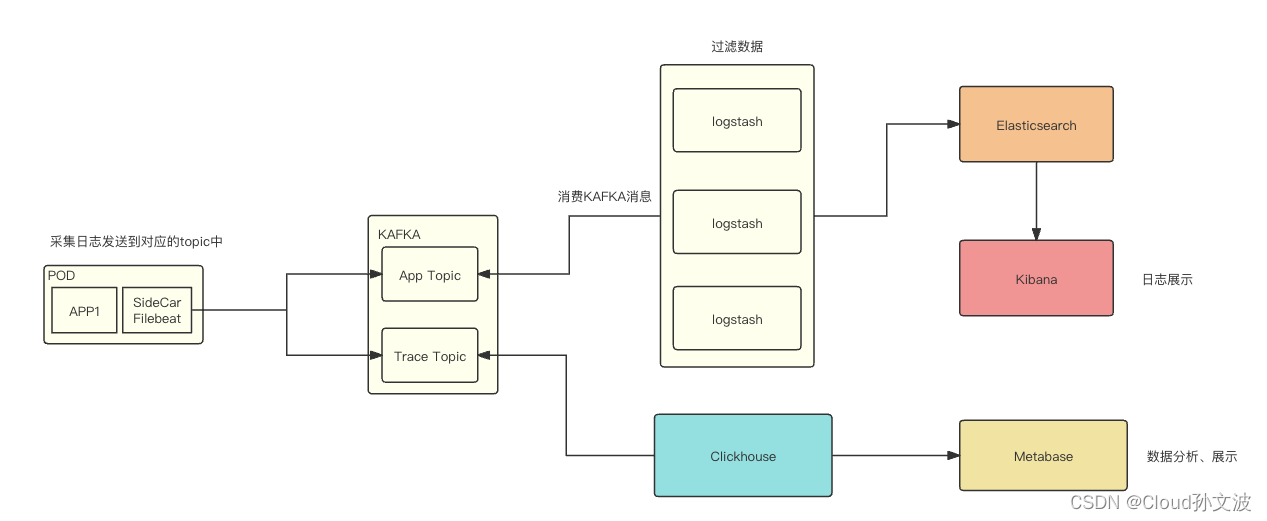
k8s Sidecar filebeat 收集容器中的trace日志和app日志
目录 一、背景 二、设计 三、具体实现 Filebeat配置 K8S SideCar yaml Logstash配置 一、背景 将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC 二、…...
三维模型设计新纪元:3D开发工具HOOPS在机械加工行业的应用与优势
在当今快速发展的科技时代,机械加工行业正经历着巨大的变革,而HOOPS技术正是其中一项重要的创新。HOOPS技术不仅仅是一种用于处理和可视化计算机辅助设计(CAD)数据的工具,更是机械加工领域中提升效率、优化设计的利器。…...

Python爬虫子页面并写入text代码
这是工具类 class UrlManager():"""url管理器"""def __init__(self):self.new_urls set()self.old_urls set()def add_new_url(self,url):if url is None or len(url) 0:returnif url in self.new_urls or url in self.old_urls:returnself.…...

《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境
01 环境搭建 《PyTorch基础教程》01 搭建环境 基于Docker搭建ubuntu22+Python3.10+Pytorch2+cuda11+jupyter的开发环境 Docker部署PyTorch 拉取cnstark/pytorch镜像 拉取镜像: docker pull cnstark/pytorch:2.0.1-py3.10.11-cuda11.8.0-ubuntu22.04导出镜像: docker sa…...

MySQL进阶之触发器
触发器 触发器是与表有关的数据库对象,指在insert/update/delete之前(BEFORE)或之后(AFTER),触 发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。 使用别名OLD和NEW来引用…...
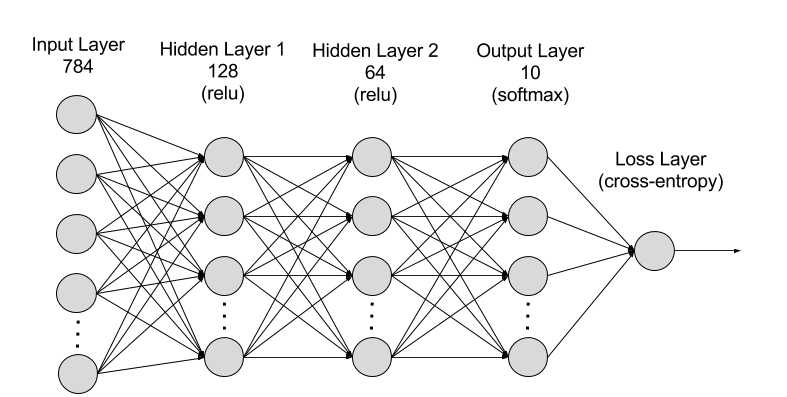
循环神经网络RNN专题(01/6)
一、说明 RNN用于处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么&a…...

C# 怎么判断屏幕是第几屏幕?屏幕是垂直还是水平?屏幕的分辨率?
一、怎么判断屏幕是第几屏幕? 可以使用System.Windows.Forms.Screen.AllScreens属性来获取所有已连接的屏幕,并根据鼠标位置或窗口的位置来判断它所在的屏幕索引。 using System; using System.Windows.Forms;// 获取鼠标当前位置所在的屏幕 Point cur…...

在 SQL Server 中使用 SQL 语句查询不同时间范围的数据
在 SQL Server 中,我们经常需要从数据库中检索特定时间范围内的数据。通过合理运用 SQL 语句,我们可以轻松地查询今天、昨天、近7天、近30天、一个月内、上一月、本年和去年的数据。下面是一些示例 SQL 查询,让我们逐一了解。 查询今天的数据…...

学习使用Flask模拟接口进行测试
前言 学习使用一个新工具,首先找一段代码学习一下,基本掌握用法,然后再考虑每一部分是做什么的 Flask的初始化 app Flask(__name__):初始化,创建一个该类的实例,第一个参数是应用模块或者包的名称 app…...

深度学习快速入门--7天做项目
深度学习快速入门--7天做项目 0. 引言1. 本文内容2. 深度学习是什么3. 项目是一个很好的切入点4. 7天做项目4.1 第一天:数据整理4.2 第二天:数据处理4.3 第三天:简单神经网络设计4.4 第四天:分析效果与原因4.5 第五天:…...
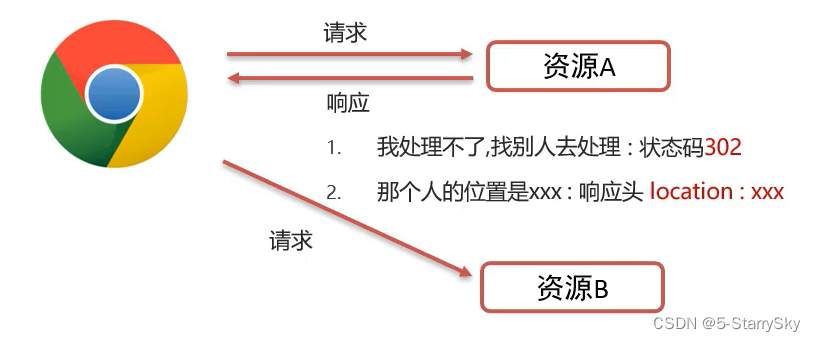
Request Response 基础篇
Request & Response 在之前的博客中,初最初见到Request和Response对象,是在Servlet的Service方法的参数中,之前隐性地介绍过Request的作用是获取请求数据。通过获取的数据来进行进一步的逻辑处理,然后通过对Response来进行数…...

数据爬虫是什么
数据爬虫是一种自动化程序,用于从互联网上收集数据。它通过模拟人类浏览器的行为,访问网页并提取所需的数据。数据爬虫通常使用网络爬虫框架或库来实现。 数据爬虫的工作流程通常包括以下几个步骤: 发起请求:爬虫发送HTTP请求到…...

Java注解与策略模式的奇妙结合:Autowired探秘
大家好,欢迎收听今天的播客节目!我是你们的主持人,也是一位对软件开发充满热情的开发者。在今天的节目中,我们将探讨如何巧妙地结合注解与策略模式,创建一个灵活而强大的策略规则工厂。让我们带着好奇的心情一同深入研…...
Datax3.0+DataX-Web部署分布式可视化ETL系统
一、DataX 简介 DataX 是阿里云 DataWorks 数据集成的开源版本,主要就是用于实现数据间的离线同步。DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源(即不同的数据库&#x…...
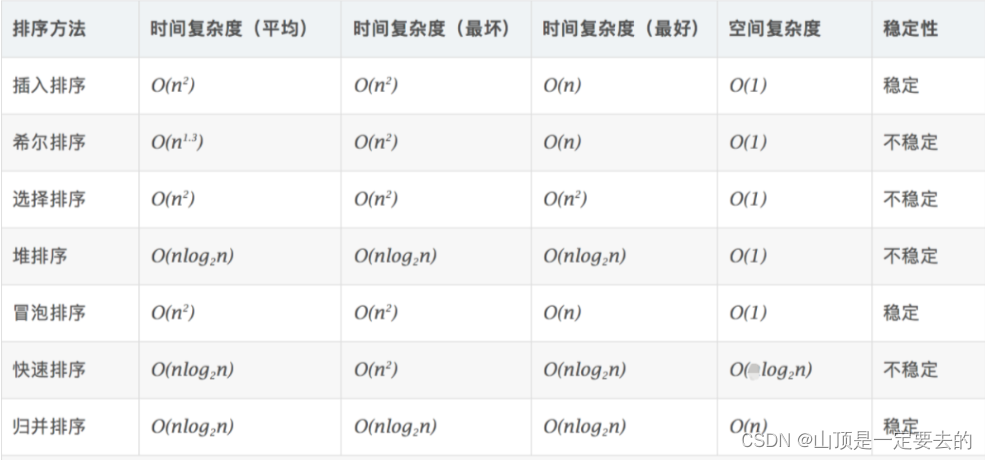
【Java 数据结构】排序
排序算法 1. 排序的概念及引用1.1 排序的概念1.2 常见的排序算法 2. 常见排序算法的实现2.1 插入排序2.1.1 直接插入排序2.1.2 希尔排序( 缩小增量排序 ) 2.2 选择排序2.2.1 直接选择排序2.2.2 堆排序 2.3 交换排序2.3.1冒泡排序2.3.2 快速排序2.3.3 快速排序非递归 2.4 归并排…...
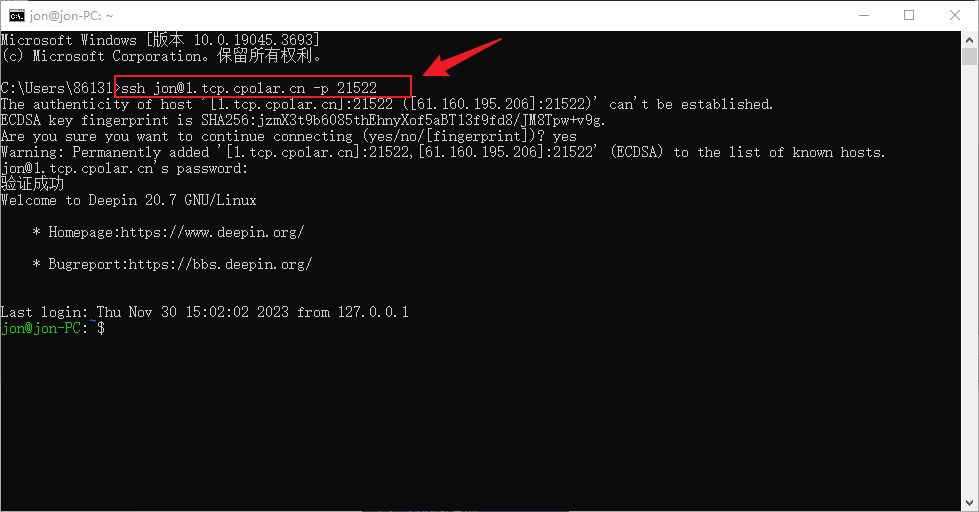
Deepin如何开启与配置SSH实现无公网ip远程连接
文章目录 前言1. 开启SSH服务2. Deppin安装Cpolar3. 配置ssh公网地址4. 公网远程SSH连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 前言 Deepin操作系统是一个基于Debian的Linux操作系统,专注于使用者对日常办公、学习、生活和娱乐的操作体验的极致࿰…...

颈腰不适乱按摩只会越治越糟,颈椎病腰间盘突出防治要找对方法,从根源到防护全攻略在这里。
生活中很多人出现颈肩腰腿痛,第一反应就是找按摩店放松、贴膏药缓解,可症状不仅没好转,反而反反复复加重,这是因为没有认清颈椎病、腰椎间盘突出的发病根源,用错了防治方法。作为职场人群最高发的脊柱疾病,…...

计算机视觉项目开发:从零到一的完整流程解析
计算机视觉项目开发:从零到一的完整流程解析 【免费下载链接】cv_note 记录cv算法工程师的成长之路,分享计算机视觉和模型压缩部署技术栈笔记。https://harleyszhang.github.io/cv_note/ 项目地址: https://gitcode.com/gh_mirrors/cv/cv_note 计…...

华硕笔记本性能调校新选择:G-Helper轻量控制工具全解析
华硕笔记本性能调校新选择:G-Helper轻量控制工具全解析 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, S…...

工业显示屏选购要点,接口兼容与长期稳定测试
采购设备用串口屏这些年,我经常要和各种品牌打交道。今天不谈那些华丽的宣传语,就用实际工作中的观察,聊聊恒域威这个品牌的显示屏在适配方面的一些特点,希望能给同行一些参考。从硬件接口到工作环境选串口屏,首先要看…...

STM32点灯翻车实录:从原理图分析到代码调试,手把手教你排查PC13不亮的问题
STM32点灯翻车实录:从原理图分析到代码调试,手把手教你排查PC13不亮的问题 当你满怀期待地写完第一个STM32点灯程序,按下烧录按钮后——灯没亮。这种挫败感每个嵌入式开发者都经历过。本文将带你用工程师的思维,从硬件到软件层层…...

告别设计规范传递难题:Sketch MeaXure如何实现设计与开发无缝协作
告别设计规范传递难题:Sketch MeaXure如何实现设计与开发无缝协作 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 副标题:5大核心功能让设计标注效率提升80%,沟通成本降低60% 设计规…...
)
4月8日(RAG流程阶段之数据准备)
数据加载器主流文档加载器文档加载器是LangChain框架的核心组件,用于解决多元数据源语言模型之间的兼容性问题其主要功能是:将不同来源、不同格式的数据,统一转换为标准化的文档对象,为后续处理文本分割、向量化模型输入提供基础主…...

信息化建设-采购实施流程
第八章:实施篇——核心系统实施方法论8.1 采购实施流程8.1.1 采购实施的理论定位采购实施是企业信息化建设中“买对产品、选对伙伴”的关键环节,其理论任务是通过系统化的供应商筛选、产品选型和合同谈判,选择最适合企业需求的信息化产品和合…...

颠覆传统:5大核心技术让百度网盘提取码获取效率提升10倍
颠覆传统:5大核心技术让百度网盘提取码获取效率提升10倍 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 在数字化资源交互日益频繁的今天,百度网盘作为国内主流的文件分享平台,其提取码机制…...

HunyuanVideo-Foley部署教程:NVIDIA Container Toolkit集成最佳实践
HunyuanVideo-Foley部署教程:NVIDIA Container Toolkit集成最佳实践 1. 环境准备与快速部署 在开始部署HunyuanVideo-Foley之前,我们需要确保硬件和软件环境满足要求。本教程将指导您完成从零开始的完整部署流程。 1.1 硬件要求检查 显卡:…...