使用 Python 进行自然语言处理第 3 部分:使用 Python 进行文本预处理

一、说明
常见的预处理任务包括:
- 文本规范化——将文本转换为标准表示形式,例如全部小写。
- 删除停用词、标点符号、特殊单词或文本片段,例如井号标签、URL、表情符号、非 ASCII 字符等。
- 词干提取——从文本单词中删除后缀
- 词形化 - 将单词转化为它们的引理形式(引理是字典中存在的单词的形式)。
- 拼写更正——更正任何拼写错误
- 通过绘图进行探索性分析
NLTK、SpaCy 等库提供内置的文本预处理功能。
二、文本预处理
2.1 文本预处理的好处
- 降维:包含许多单词的文本文档可以表示为多维向量。文档的每个单词都是向量的维度之一。应用文本处理有助于删除对您所针对的实际 NLP 任务可能没有意义的单词,从而减少数据的维度,这反过来又有助于解决维数灾难问题并提高 NLP 任务的性能。
2.2 文本预处理
下载到您的计算机并将其加载到 pandas 数据框中。如果使用 read_csv(),请使用编码 = 'latin-1'。数据集有很多列,我们只对这篇关于文本预处理的文章的原始推文列感兴趣。
# Read the dataset into a dataframe
import pandas as pd
train_data = pd.read_csv('Corona_NLP_train.csv', encoding='latin-1')
train_data.head()# Remove the columns not relevant to Text-Preprocessing Task
train_data = train_data.drop(['UserName', 'ScreenName', 'Location', 'TweetAt', 'Sentiment'], axis = 1)
train_data.columns2.3 小写转换
#1. Case Conversion to Lower Case
train_data['OriginalTweet'] = train_data['OriginalTweet'].str.lower()
train_data.head()2.4 删除停用词和标点符号
#Remove stop words and punctuation marks
#https://stackoverflow.com/questions/29523254/python-remove-stop-words-from-pandas-dataframe
import nltk
import string
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stopwordsandpunct = stop_words + list(string.punctuation)train_data['OriginalTweet'] = train_data['OriginalTweet'].apply(lambda w:' '.join(w for w in w.split() if w not in stopwordsandpunct))
train_data['OriginalTweet']2.5 删除 URL
# Remove URLs from all the tweets
import re
def remove_url(tweet):tweet = re.sub(r'\w+:\/{2}[\d\w-]+(\.[\d\w-]+)*(?:(?:\/[^\s/]*))*', '', tweet)return tweettrain_data['OriginalTweet'] = train_data['OriginalTweet'].apply(remove_url)
train_data['OriginalTweet'].head()2.6 删除提及和井号标签
# remove mentions and hashtags
def remove_mentions_hashs(tweet):tweet = re.sub("@[A-Za-z0-9_]+","", tweet) #Remove mentionstweet = re.sub("#[A-Za-z0-9_]+","", tweet) #Remove hashtagsreturn tweettrain_data['OriginalTweet'] = train_data['OriginalTweet'].apply(remove_mentions_hashs)
train_data['OriginalTweet'].head()2.7 删除表情符号
# Removing emojis from tweets
# Source Credit: https://stackoverflow.com/a/49146722/330558
import re
def remove_emojis(tweet):pat = re.compile("["u"\U0001F600-\U0001F64F" # emoticonsu"\U0001F300-\U0001F5FF" # symbols & pictographsu"\U0001F680-\U0001F6FF" # transport & map symbolsu"\U0001F1E0-\U0001F1FF" # flags (iOS)u"\U00002702-\U000027B0"u"\U000024C2-\U0001F251""]+", flags=re.UNICODE)return pat.sub(r'', tweet)train_data['OriginalTweet'] =train_data['OriginalTweet'].apply(remove_emojis)
train_data.head()2.8 删除非 ASCII 字符
#https://docs.python.org/2/library/unicodedata.html#unicodedata.normalize
import unicodedata
def remove_nonascii(text):text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore')# apply compatibility decompositionreturn text
train_data['OriginalTweet'] = train_data['OriginalTweet'].apply(remove_nonascii)
train_data.head()2.9 删除空字符串
import string
def remove_empty_strings1(tweet):tweet = re.sub(r"^\s+|\s+$", 'NaN', tweet)return tweet
train_data['OriginalTweet'] =train_data['OriginalTweet'].apply(remove_empty_strings1)2.10 删除主题标签、URL 后删除所有包含 NaN 的行
train_data = train_data[train_data['OriginalTweet'] != 'NaN']# Now resetting index of Data frame
train_data = train_data.reset_index(drop = True)三、文本内容预处理
3.1 使用 TextBlob 进行拼写更正
# Spelling correction
import warnings
warnings.filterwarnings("ignore")
from textblob import TextBlob
train_data['SpellCorrectedTweet'] = train_data['OriginalTweet'].apply(lambda x : str(TextBlob(x).correct()))
train_data.head()3.2 使用 NLTK 的内置 Tokenizer 进行标记化
# Now we will perform tokenization
import nltk
from nltk import word_tokenize
tokenizer = nltk.tokenize.WhitespaceTokenizer()
def tokenize(text):return tokenizer.tokenize(text)train_data['OriginalTweet'] = train_data['OriginalTweet'].apply(tokenize)
train_data['OriginalTweet'].head()3.3 使用 NLTK 的 WordNetLemmatizer 进行词形还原
import nltk
tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()def lemmatize(text):return [lemmatizer.lemmatize(w) for w in text]train_data['OriginalTweet'] = train_data['OriginalTweet'].apply(lemmatize)
train_data.head()3.4 使用 NLTK 的 PorterStemmer 进行词干提取
# Stemming
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()def stemming(text):return [stemmer.stem(w) for w in text]train_data['OriginalTweet'] = train_data['OriginalTweet'].apply(stemming)
train_data.head()3.5 计算推文中最常见的单词
# Counting most frequent words in tweets
#https://docs.python.org/3/library/itertools.html#itertools.chain
import itertools
import collections
all_tweets = list(train_data["OriginalTweet"])
all_tokens = list(itertools.chain(*all_tweets))
token_counts = collections.Counter(all_tokens)# Print 10 most common words with their frequency
print(token_counts.most_common(10))# Convert above words and frequencies to a dataframe
df = pd.DataFrame(token_counts.most_common(20), columns=['Token','Count'])
df.head()# Plotting frequencies using Matplotlib barplot
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (12,8)
df.sort_values(by = 'Count').plot.bar(x='Token', y='Count')
plt.title('Most Used Words')
plt.show()四、总结
本文总结出关于文本预处理的大多数处理方法。对于文本处理的实际过程,可以抽取某些过程进行整合处理。对于更加特殊的处理也可以特别处理。
下一篇文章介绍文本表示技术:
使用 Python 进行自然语言处理第 4 部分:文本表示
相关文章:
使用 Python 进行自然语言处理第 3 部分:使用 Python 进行文本预处理
一、说明 文本预处理涉及许多将文本转换为干净格式的任务,以供进一步处理或与机器学习模型一起使用。预处理文本所需的具体步骤取决于具体数据和您手头的自然语言处理任务。 常见的预处理任务包括: 文本规范化——将文本转换为标准表示形式,…...

Python新春烟花盛宴
写在前面 哈喽小伙伴们,博主在这里提前祝大家新春快乐呀!我用Python绽放了一场新春烟花盛宴,一起来看看吧! 环境需求 python3.11.4及以上PyCharm Community Edition 2023.2.5pyinstaller6.2.0(可选,这个库…...
)
【QT+QGIS跨平台编译】之二十:【xerces+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、xerces介绍二、文件下载三、文件分析四、pro文件五、编译实践一、xerces介绍 Xerces是一个开源的XML解析器,由Apache软件基金会维护。它是用Java语言编写的,提供了对XML文档进行解析、验证和操作的功能。Xerces具有高性能和广泛的兼容性,可用于各种Java应用程…...

18.通过telepresence调试部署在Kubernetes上的微服务
Telepresence简介 在微服务架构中,本地开发和调试往往是一项具有挑战性的任务。Telepresence 是一种强大的工具,使得开发者本地机器上开发微服务时能够与运行在 Kubernetes 集群中的其他服务无缝交互。本文将深入探讨 Telepresence 的架构、运行原理,并通过实际的案例演示其…...
QT 范例阅读:系统托盘 The System Tray Icon example
main.cpp QApplication app(argc, argv);//判断系统是否支持 系统托盘功能if (!QSystemTrayIcon::isSystemTrayAvailable()) {QMessageBox::critical(0, QObject::tr("Systray"),QObject::tr("I couldnt detect any system tray ""on this system.&qu…...

OpenAI Gym 高级教程——深度强化学习库的高级用法
Python OpenAI Gym 高级教程:深度强化学习库的高级用法 在本篇博客中,我们将深入探讨 OpenAI Gym 高级教程,重点介绍深度强化学习库的高级用法。我们将使用 TensorFlow 和 Stable Baselines3 这两个流行的库来实现深度强化学习算法ÿ…...

K8sGPT 会彻底改变你对 Kubernetes 的认知
在不断发展的 Kubernetes (K8s) 环境中,AI 驱动技术的引入继续重塑我们管理和优化容器化应用程序的方式。K8sGPT 是一个由人工智能驱动的尖端平台,在这场变革中占据了中心位置。本文探讨了 K8sGPT 在 Kubernetes 编排领域的主要特…...

计组学习笔记2024/2/4
1.计算机的发展历程 2.计算机硬件的基本组成 存储器 -> 就是内存. 3.各个硬件的部件 寄存器 -> 用来存放二进制数据. 各个硬件的工作原理视频留白,听完后边课程之后再来理解理解. 冯诺依曼计算机的特点: 1.计算机由五大部件组成 2.指令和数据以同等地位存于存储器,…...
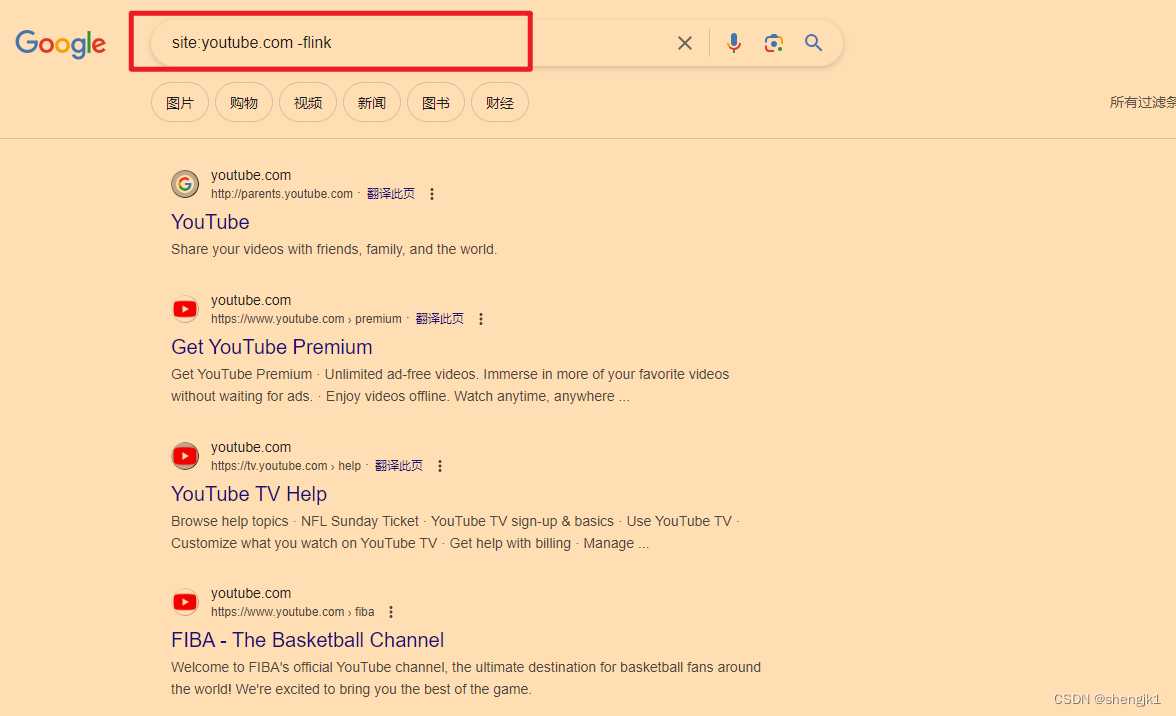
25种Google的搜索技巧
背景 目前浏览器、搜索引擎,想必各位已经很熟悉了,但不代表想要知道的事情就一定可以通过搜索引擎搜索出来。大部分人的搜索技巧都在小学。所以本文就会系统总结一个 GOOGLE 搜索的一些技巧,来提高搜索效率。 首先呢,本文只保证 GOOGLE 有效,其他搜索引擎自己尝试,因为我…...
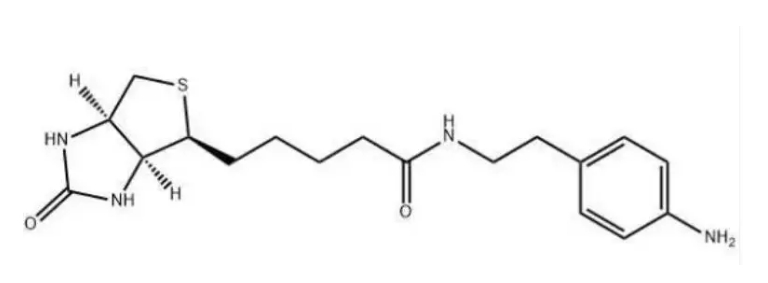
769933-15-5,Biotin aniline,可以合成多种有机化合物和聚合物
您好,欢迎来到新研之家 文章关键词:769933-15-5,Biotin aniline,生物素苯胺,生物素-苯胺 一、基本信息 产品简介:Biotin Aniline,一种具有重要生物学功能的化合物,不仅参与了维生…...

回归预测 | Matlab实现POA-CNN-LSTM-Attention鹈鹕算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制)
回归预测 | Matlab实现POA-CNN-LSTM-Attention鹈鹕算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制) 目录 回归预测 | Matlab实现POA-CNN-LSTM-Attention鹈鹕算法优化卷积长短期记忆网络注意力多变量回归预测(SE注意力机制&…...

B站视频在电商中的应用:如何利用item_get_video API提高转化率
在数字媒体时代,视频已成为电商领域中不可或缺的营销工具。B站作为中国最大的弹幕视频网站之一,拥有庞大的用户群体和活跃的社区。将B站与电商结合,利用其独特的视频API(如item_get_video)可以带来诸多商业机会。本文将…...
【Linux】统信服务器操作系统V20 1060a-AMD64 Vmware安装
目录 编辑 一、概述 1.1 简介 1.2 产品特性 1.3 镜像下载 二、虚拟机安装 一、概述 1.1 简介 官网:统信软件 – 打造操作系统创新生态 统信服务器操作系统V20是统信操作系统(UOS)产品家族中面向服务器端运行环境的,是一款…...

c++类继承
一、继承的规则 (1)基类成员在派生类中的访问权限不得高于继承方式中指定的权限。例如,当继承方式为protected时,那么基类成员在派生类中的访问权限最高也为protected,高于protected会降级为protected,但低…...
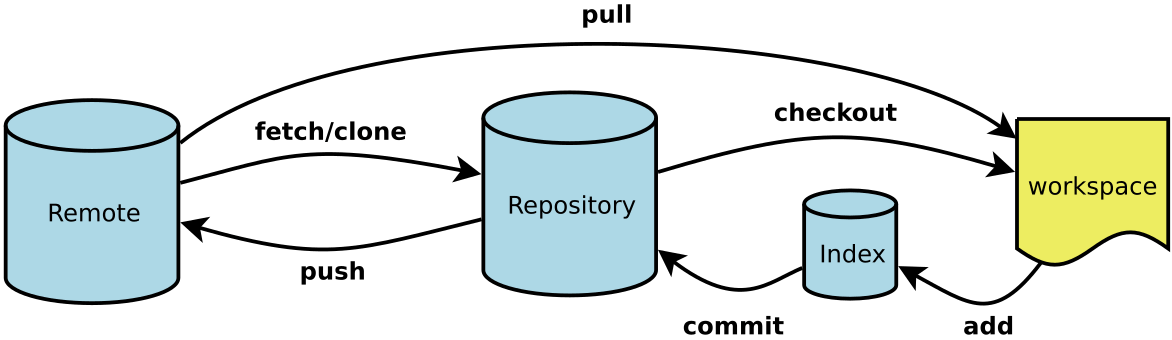
Git 指令
Git 安装 操作 命令行 简介: Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。 Git 与常用的版本控制工具 CVS, Subversion …...

JAVA中的多态参数
1.方法定义的参数类型为父类类型,实参类型允许为子类类型 public class Ploy_parameter {public static void main(String[] args) {Manage jack new Manage("jack",12000,3000);Staff tom new Staff("tom",10000);Ploy_parameter ploy_para…...
Ubuntu Linux 下安装和卸载cmake 3.28.2版本
一、安装cmake 1.首先,先从cmake官网下载cmake-3.28.2-linux-x86_64.tar.gz 2.用FinalShell 等文件上传工具,将这个压缩包上传到 虚拟机的某个路径去(自选) 3. cd /usr/local/bin/,然后创建cmake文件夹,…...

【C++】类和对象3:默认成员函数之析构函数
前言 这篇文章我们来学习默认成员函数中的析构函数 概念 析构函数:与构造函数功能相反,析构函数不是完成对对象本身的销毁,局部对象销毁工作是由编译器完成的。而对象在销毁时会自动调用析构函数,完成对象中资源的清理工作。 …...

2024美赛C题完整解题教程及代码 网球运动的势头
2024 MCM Problem C: Momentum in Tennis (网球运动的势头) 注:在网球运动中,"势头"通常指的是比赛中因一系列事件(如连续得分)而形成的动力或趋势,这可能对比赛结果产生重要影响。球…...
二、人工智能之提示工程(Prompt Engineering)
黑8说 岁月如流水匆匆过,哭一哭笑一笑不用说。 黑8自那次和主任谈话后,对这个“妖怪”继续研究,开始学习OpenAI API!关注到了提示工程(Prompt Engineering)的重要性,它包括明确的角色定义、自然语言理解(…...

YOLOv8鹰眼快速入门:三步完成图像上传、检测与结果查看
YOLOv8鹰眼快速入门:三步完成图像上传、检测与结果查看 1. 引言:为什么选择YOLOv8鹰眼目标检测 在计算机视觉领域,目标检测技术正变得越来越重要。无论是安防监控、自动驾驶还是工业质检,快速准确地识别图像中的物体都是核心需求…...

Docker与cpolar强强联合:打造私有化RSSHub内容聚合的远程访问方案
1. 为什么需要私有化RSSHub内容聚合 在这个信息爆炸的时代,我们每天都被各种资讯轰炸。你可能已经厌倦了商业平台的算法推荐,或者担心个人阅读数据被收集利用。这时候,拥有一个完全属于自己的内容聚合系统就显得尤为重要。 RSSHub作为一款开源…...

剧本杀创作指南2025,解析,从零开始打造沉浸式推理体验
剧本杀创作指南2025,解析,从零开始打造沉浸式推理体验剧本杀作为一种新兴的娱乐方式,近年来在国内迅速崛起。随着市场需求的不断增长,越来越多的创作者开始尝试编写剧本杀剧本。本文将为你提供一份详尽的剧本杀创作指南࿰…...

unknown
unknown...

零代码实战:用OpenClaw和Qwen3.5-9B-AWQ-4bit制作表情包生成器
零代码实战:用OpenClaw和Qwen3.5-9B-AWQ-4bit制作表情包生成器 1. 为什么需要本地化表情包生成工具 作为一个长期混迹技术社区的老鸟,我经常需要在群聊中快速制作贴合讨论主题的表情包。传统方式要么依赖在线生成器(存在隐私风险࿰…...

文心一言搜索优化,做好这件事就赢了一半
如果你在文心一言上铺了几百篇内容,但品牌词一问,AI还是引用别人——你缺的不是数量,是质量锚点。文心一言的算法有一套对“优质可信内容”的隐形成交系统,没通过质检的内容,发再多也是无效库存。去年我们实测过一个案…...

SpringBoot源码企业公司ERP进销存管理系统JavaWeb项目前后端分离Vue实现方案
SpringBoot源码企业公司ERP进销存管理系统JavaWeb项目前后端分离Vue一、项目背景与目标SpringBoot源码企业公司ERP进销存管理系统JavaWeb项目前后端分离Vue随着企业信息化管理的需求日益增长,ERP(企业资源计划)系统成为企业提升管理效率、优化…...

**发散创新:基于Go语言实现的Raft共识算法实战解析**在分布式系统中,**一
发散创新:基于Go语言实现的Raft共识算法实战解析 在分布式系统中,一致性是核心挑战之一。而Raft共识算法因其简洁性和可理解性,已成为当前主流的分布式一致性协议(如etcd、Consul均采用Raft)。本文将带你深入用Go语言从…...
)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧) 在AI模型部署领域,量化技术正成为突破硬件限制的关键手段。当我们面对Atlas 800I A2这样的高性能服务器时,如何充分发挥其64GB显存优势&#…...

解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案
解决Windows 11 LTSC应用商店缺失难题:从根源修复到生态重建的完整方案 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 在企业环境和专业工…...