Flink实战四_TableAPISQL
接上文:Flink实战三_时间语义
1、Table API和SQL是什么?
接下来理解下Flink的整个客户端API体系,Flink为流式/批量处理应用程序提供了不同级别的抽象:
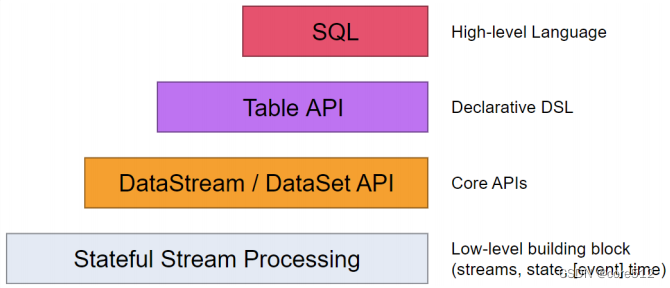
这四层API是一个依次向上支撑的关系。
- Flink API 最底层的抽象就是有状态实时流处理 Stateful Stream Processing,是最底层的Low-Level API。实际上就是基于ProcessFunction提供的一整套API。在上面侧输出流部分,已经接触到了一个示例。这是最灵活,功能最全面的一层客户端API,允许应用程序可以定制复杂的计算过程。但是这一层大部分的常用的功能都已经封装在了上层的Core API当中,大部分的应用都不会需要使用到这一层API。
- Core APIs主要是DataStream API以及针对批处理的DataSet API。这是最为常用的一套API。其中,又以DataStream API为主。他们其实就是基于一系列ProcessFunction做的一些高层次的封装,可以极大的简化客户端应用程序的开发。
- Table API主要是表(Table)为中心的声明式编程API。他允许应用程序像操作关系型数据库一样对数据进行一些select\join\groupby等典型的逻辑操作,并且也可以通过用户自定义函数进行功能扩展,而不用确切地指定程序指定的代码。当然,Table API的表达能力还是不如Core API灵活。大部分情况下,用户程序应该将Table API和DataStream API混合使用。
- SQL是Flink API中最顶层的抽象。功能类似于Table API,只是程序实现的是直接的SQL语句支持。本质上还是基于Table API的一层抽象。
Table API和Flink SQL是一套给Java和Scalal语言提供的快速查询数据的API,在Python语言客户端中也可以使用。他们是集成在一起的一整套API。通过TableAPI,用户可以像操作数据库中的表一样查询流式数据。 这里注意Table API主要是针对数据查询操作,而"表"中数据的本质还是对流式数据的抽象。而SQL则是直接在"表"上提供SQL语句支持。
其实这种思路在流式计算中是非常常见的,像kafka Streams中提供了KTable封装,Spark中也提供了SparkSQL进行表操作。
2、如何使用Table API
使用Table API和SQL,需要引入maven依赖。
首先需要引入一个语言包
<!-- java客户端 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>1.12.3</version><scope>provided</scope>
</dependency>
另外也提供了scala语言的依赖版本
<!-- scala客户端 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.11</artifactId><version>1.12.3</version><scope>provided</scope>
</dependency>
然后需要引入一个Planner
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>1.12.3</version><scope>provided</scope>
</dependency>
接下来如果要使用一些自定义函数的话,还需要引入一个扩展依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>1.12.3</version><scope>provided</scope>
</dependency>
注意下,为什么这些依赖都使用了provided的scope呢?因为这些maven依赖的jara包,在flink的部署环境中都有。如果需要添加一些新的jar包,那就需要手动把jar包复制进去。
3、基础编程框架
Flink中对批处理和流处理的Table API 和SQL 程序都遵循一个相同的模式,都像下面示例中的这种结构。
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...;// create an input Table
tableEnv.executeSql("CREATE TEMPORARY TABLE table1 ... WITH ( 'connector' =
... )");// register an output Table
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH (
'connector' = ... )");// create a Table object from a Table API query
Table table2 = tableEnv.from("table1").select(...);// create a Table object from a SQL query
Table table3 = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");// emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = table2.executeInsert("outputTable");
tableResult...
基本的步骤都是这么几个:
- 创建TableEnvironment
- 将流数据转换成动态表 Table
- 在动态表上计算一个连续查询,生成一个新的动态表
- 生成的动态表再次转换回流数据
3.1 创建TableEnvironment
TableEnvironment是Table API 和SQL 的核心概念。未来的所有重要操作,例如窗口注册,自定义函数(UDF)注册等,都需要用到这个环境。
对于流式数据,直接通过StreamExecutionEnvironment就可以创建。
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
在构建Table运行环境时,还可以指定一个配置对象。
final EnvironmentSettings environmentSettings =EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env, environmentSettings);
示例中这个配置对象,设置了三个属性,都是取的默认值。
首先关于Planner,Flink从1.11版本开始,就已经将默认的Planner改为了Blink。
然后在配置中指定了Catalog和Database的名字。在Flink中,表对象的层次结构是Catalog -> Database -> Table。这就相当于是MySQL中的schema。示例中指定的两个值就是Flink提供的默认值,也可以自行进行指定。
3.2 将流数据转换成动态表 Table
Flink中的表Table与关系型数据库中的表Table是有区别的。Flink中的表是随时间不短变化的,流中的每条记录都被解释为对结果表的insert操作。而Flink的TableAPI是让应用程序可以像查询静态表一样查询这些动态表。但是基于动态表的查询,其结果也是动态的,这个查询永远不会停止。所以,也需要用一个动态表来接收动态的查询结果。
final URL resource = FileRead.class.getResource("/stock.txt");final String filePath = resource.getFile();// final DataStreamSource<String> stream =env.readTextFile(filePath);final DataStreamSource<String> dataStream = env.readFile(newTextInputFormat(new Path(filePath)), filePath);final SingleOutputStreamOperator<Stock> stockStream = dataStream.map((MapFunction<String, Stock>) value -> {final String[] split = value.split(",");return new Stock(split[0],Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));
});final Table stockTable = tableEnv.fromDataStream(stockStream);
其实关键的就是最后这一行。将一个DataStream转换成了一个stockTable。接下来,就可以使用Table API来对stockTable进行类似关系型数据库的操作了。
final Table table = stockTable.groupBy($("id"), $("stockName")).select($("id"), $("stockName"),$("price").avg().as("priceavg")).where($("stockName").isEqual("UDFStock"));
整个操作过程跟操作一个关系型数据库非常类似。例如示例中的代码,应该一看就能明白。这里需要注意下,对于groupBy,select,where这些操作算子,老版本支持传入字符串,但是在1.12版本中已经标注为过时了。当前版本需要传入一个由$转换成的Expression对象。这个$不是一个特殊的符号,而是Flink中提供的一个静态API。
另外,Flink提供了SQL方式来简化上面的查询过程。
tableEnv.createTemporaryView("stock",stockTable);String sql = "select id,stockName,avg(price) as priceavg from stock where stockName='UDFStock' group by id,stockName";final Table sqlTable = tableEnv.sqlQuery(sql);
使用SQL需要先注册一个表,然后才能针对表进行SQL查询。注册时,createTemporaryView表示注册一个只与当前任务相关联的临时表。这些临时表在多个Flink会话和集群中都是可见的。
3.3 将Table重新转换为DataStream
通过SQL查询到对应的数据后,通常有两种处理方式:一种是将查询结果转换回DataStream,进行后续的操作。
//转换成流
final DataStream<Tuple2<Boolean, Tuple3<String, String, Double>>>
sqlTableDataStream = tableEnv.toRetractStream(sqlTable,
TypeInformation.of(new TypeHint<Tuple3<String, String, Double>>() {
}));sqlTableDataStream.print("sql");
另一种是将查询结果插入到另一个表中,并通过另一张表对应Sink将结果输出到目标Sink中。
完整demo:
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogBaseTable;
import org.apache.flink.table.catalog.CatalogTableImpl;
import org.apache.flink.table.catalog.GenericInMemoryCatalog;
import org.apache.flink.table.catalog.ObjectPath;import java.net.URL;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import static org.apache.flink.table.api.Expressions.$;/*** @author roy* @date 2021/9/12* @desc*/
public class FileTableDemo {public static void main(String[] args) throws Exception {//1、读取数据final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();final URL resource = FileRead.class.getResource("/stock.txt");final String filePath = resource.getFile();final DataStreamSource<String> dataStream = env.readFile(new TextInputFormat(new Path(filePath)), filePath);final SingleOutputStreamOperator<Stock> stockStream = dataStream.map((MapFunction<String, Stock>) value -> {final String[] split = value.split(",");return new Stock(split[0], Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));});//2、创建StreamTableEnvironment catalog -> database -> tablenamefinal EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);//3、基于流创建表final Table stockTable = tableEnv.fromDataStream(stockStream);final Table table = stockTable.groupBy($("id"), $("stockName")).select($("id"), $("stockName"), $("price").avg().as("priceavg")).where($("stockName").isEqual("UDFStock"));//转换成流final DataStream<Tuple2<Boolean, Tuple3<String, String, Double>>> tableDataStream =tableEnv.toRetractStream(table, TypeInformation.of(new TypeHint<Tuple3<String, String, Double>>() {}));tableDataStream.print("table");env.execute("FileTableDemo");}
}
stock.txt内容:
stock_277,70.3760055422398,SYSStock,1631002964777
stock_578,22.141256900167285,UDFStock,1631002965778
stock_578,1.238164914104345,UDFStock,1631002966779
stock_578,92.19084433119833,UDFStock,1631002967779
stock_483,20.029404720792922,SYSStock,1631002968779
stock_578,15.347261600178431,SYSStock,1631002969780
4、扩展编程框架
4.1 临时表与永久表
在3.2章节注册动态表时,可以选择注册为临时表或者是永久表。临时表只能在当前任务中访问。任务相关的所有Flink的会话Session和集群Cluster都能够访问表中的数据。但是任务结束后,这个表就会删除。
而永久表则是在Flink集群的整个运行过程中都存在的表。所有任务都可以像访问数据库一样访问这些永久表,直到这个表被显示的删除。
表注册完成之后,可以将Table对象中的数据直接插入到表中。
//创建临时表
tableEnv.createTemporatyView("Order",orders)//创建永久表
Table orders = tableEnv.from("Orders");
orders.executeInsert("OutOrders");
如下com.flink.table.FileTableDemo,演示了一个基于文件的永久表:
import com.roy.flink.beans.Stock;
import com.roy.flink.streaming.FileRead;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.net.URL;public class PermanentFileTableDemo {public static void main(String[] args) throws Exception {//1、读取数据final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();final URL resource = FileRead.class.getResource("/stock.txt");final String filePath = resource.getFile();
// final DataStreamSource<String> stream = env.readTextFile(filePath);final DataStreamSource<String> dataStream = env.readFile(new TextInputFormat(new Path(filePath)), filePath);final SingleOutputStreamOperator<Stock> stockStream = dataStream.map((MapFunction<String, Stock>) value -> {final String[] split = value.split(",");return new Stock(split[0], Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));});//2、创建StreamTableEnvironment catalog -> database -> tablenamefinal EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);String sql = "create table stock(" +" id varchar," +" price double," +" stockName varchar," +" `timestamp` bigint" +" ) with (" +" 'connector.type' = 'filesystem'," +" 'format.type' = 'csv'," +" 'connector.path' = 'D://flinktable'" +" )";tableEnv.executeSql(sql);//创建临时表。计算任务结束时,表就会回收。
// tableEnv.createTemporaryView("stock",stockStream);//创建永久表。表在显示删除之前一直可以查询。final Table table = tableEnv.fromDataStream(stockStream);table.executeInsert("stock");// String sql = "select id,stockName,avg(price) as priceavg from stock where stockName='UDFStock' group by id,stockName";sql = "select id,stockName,avg(price) as priceavg from stock where stockName='UDFStock' group by id,stockName";final Table sqlTable = tableEnv.sqlQuery(sql);//转换成流final DataStream<Tuple2<Boolean, Tuple3<String, String, Double>>> sqlTableDataStream = tableEnv.toRetractStream(sqlTable, TypeInformation.of(new TypeHint<Tuple3<String, String, Double>>() {}));sqlTableDataStream.print("sql");env.execute("FileConnectorDemo");}
}
Flink的永久表需要一个catalog来维护表的元数据。一旦永久表被创建,任何连接到这个catalog的Flink会话都可见并且持续存在。直到这个表被明确删除。也就是说,永久表是在Flink的会话之间共享的。
而临时表则通常保存于内存中,并且只在创建他的Flink会话中存在。这些表对于其他会话是不可见的。他们也不需要与catalog绑定。临时表是不共享的。
在Table对象中也能对表做一些结构化管理的工作,例如对表中的列进行增加、修改、删除、重命名等操作,但是通常都不建议这样做。原因还是因为Flink针对的是流式数据计算,他的表保存的应该只是计算过程中的临时数据,频繁的表结构变动只是增加计算过程的复杂性。
最后,当一个会话里有两个重名的临时表和永久表时,将会只有临时表生效。如果临时表没有删除,那么永久表就无法访问。这个特性在做开发测试时是非常好用的。可以很容易的做Shadowing影子库测试。
4.2 AppendStream和RetractStream
在3.3章节将Table转换成为DataStream时,我们用的是tableEnv.toRetractStream方法。另外还有一个方法是tableEnv.toAppendStream方法。这两个方法都是将Table转换成为DataStream。但是在我们这个示例com.flink.table.FileTableDemo中如果使用toAppendStream方法,则会报错:
//代码
final DataStream<Tuple3<String, String, Double>> tuple3DataStream
= tableEnv.toAppendStream(sqlTable, TypeInformation.of(new
TypeHint<Tuple3<String, String, Double>>() {}));//异常
Exception in thread "main" org.apache.flink.table.api.TableException:
toAppendStream doesn't support consuming update changes which is produced by
node GroupAggregate(groupBy=[id, stockName], select=[id, stockName,
AVG(price) AS priceavg])
异常信息很明显,groupby语句不支持toAppendStream。这是为什么呢?要理解这个异常,就要从这两种结果流模式说起。
我们现在的代码虽然看起来是在用SQL处理批量数据,但是本质上,数据依然是流式的,是一条一条不断进来的。这时,当处理增量数据时,将表的查询结果转换成DataStream时,就有两种不同的方式。
一种是将新来的数据作为新数据,不断的追加到Flink的表中。这种方式就是
toApppendStream。
另一种方式是用新来的数据覆盖Flink表中原始的数据。这种方式就是toRestractStream。在他的返回类型中可以看到,他会将boolean与原始结果类型拼装成一个Tuple2组合。前面的这个boolean结果就表示这条数据是覆盖还是插入。true表示插入,false表示覆盖。
很显然,经过groupby这种统计方式后,我们需要的处理结果是分组计算后的一个统计值。这个统计值只能覆盖,不能追加,所以才会有上面的错误。
4.3 内置函数与自定义函数
在SQL操作时,我们经常会调用一些函数,像count()、max()等等。 Flink也提供了非常丰富的内置函数。这些函数即可以在Table API中调用,也可以在SQL中直接调用。调用的方式跟平常在关系型数据库中调用方式差不多。
具体内置函数就不再一一梳理了,可以参见官方文档 https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/functions/systemFunctions.html
我们这里重点介绍下自定义函数,UDF。这些自定义函数显著扩展了查询的表达能力。使用自定义函数时需要注意以下两点:
1、大多数情况下,用户自定义的函数需要先注册,然后才能在查询中使用。 注册的方法有两种
//注册一个临时函数
tableEnv.createTemporaryFunction(String path, Class<? extends
UserDefinedFunction> functionClass);//注册一个临时的系统函数
tableEnv.createTemporarySystemFunction(String name, Class<? extends
UserDefinedFunction> functionClass);
这两者的区别在于,用户函数只在当前Catalog和Database中生效。而系统函数能由独立于Catalog和Database的全局名称进行标识。所以使用系统函数可以继承Flink的一些内置函数,比如trim,max等
**2、自定义函数需要按照函数类型继承一个Flink中指定的函数基类。**Flink中有有以
下几种函数基类:
- 标量函数 org.apache.flink.table.functions.ScalarFunction。标量函数可以将0个或者多个标量值,映射成一个新的标量值。例如常见的获取当前时间、字符串转大写、加减法、多个字符串拼接,都是属于标量函数。例如下面定义一个hash方法
public static class HashCode extends ScalarFunction {private int factor = 13;public HashCode(int factor) {this.factor = factor;}public int eval(String s) {return s.hashCode() * factor;}
}
完整示例代码:
import com.roy.flink.beans.Stock;
import com.roy.flink.streaming.FileRead;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;import java.net.URL;public class ScalarUDFDemo {public static void main(String[] args) throws Exception {//1、读取数据final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();final URL resource = FileRead.class.getResource("/stock.txt");final String filePath = resource.getFile();
// final DataStreamSource<String> stream = env.readTextFile(filePath);final DataStreamSource<String> dataStream = env.readFile(new TextInputFormat(new Path(filePath)), filePath);final SingleOutputStreamOperator<Stock> stockStream = dataStream.map((MapFunction<String, Stock>) value -> {final String[] split = value.split(",");return new Stock(split[0], Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));});//2、创建StreamTableEnvironment catalog -> database -> tablenamefinal EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);
// final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//3、基于流创建表final Table stockTable = tableEnv.fromDataStream(stockStream);tableEnv.createTemporaryView("stock",stockTable);// 注册UDF函数tableEnv.createTemporaryFunction("myConcate",new MyConcate());String sql = "select id,stockName,myConcate(stockName,price) as stockinfo from stock where stockName='UDFStock'";final Table sqlTable = tableEnv.sqlQuery(sql);//转换成流final DataStream<Tuple2<Boolean, Tuple3<String, String, String>>> sqlTableDataStream =tableEnv.toRetractStream(sqlTable, TypeInformation.of(new TypeHint<Tuple3<String, String, String>>() {}));sqlTableDataStream.print("sql");env.execute("ScalarUDFDemo");}public static class MyConcate extends ScalarFunction{//必须实现一个public的eval函数,参数不能是Object,返回类型和参数类型不确定,根据实际情况定。// 这是目前版本完全没有道理的实现方式。public String eval(String a,Double b){return a.toString()+"_"+b.toString();}}
}
- 表函数 org.apache.flink.table.functions.TableFunction表函数同样以0个或者多个标量作为输入,但是他可以返回任意数量的行作为输出,而不是单个值。例如下面这个简单的字符串拆分函数
public class Split extends TableFunction<String> {private String separator = ",";public Split(String separator) {this.separator = separator;}public void eval(String str) {for (String s : str.split(" ")) {collect(s); // use collect(...) to emit an output row}}
}
完整示例:
import com.roy.flink.beans.Stock;
import com.roy.flink.streaming.FileRead;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;import java.net.URL;import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;public class TableUDFDemo {public static void main(String[] args) throws Exception {//1、读取数据final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();final URL resource = FileRead.class.getResource("/stock.txt");final String filePath = resource.getFile();
// final DataStreamSource<String> stream = env.readTextFile(filePath);final DataStreamSource<String> dataStream = env.readFile(new TextInputFormat(new Path(filePath)), filePath);final SingleOutputStreamOperator<Stock> stockStream = dataStream.map((MapFunction<String, Stock>) value -> {final String[] split = value.split(",");return new Stock(split[0], Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));});//2、创建StreamTableEnvironment catalog -> database -> tablenamefinal EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);
// final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//3、基于流创建表final Table stockTable = tableEnv.fromDataStream(stockStream);tableEnv.createTemporaryView("stock",stockTable);//注册TableFunctiontableEnv.createTemporaryFunction("splitId",new SplitFunction());//table方式调用final Table tableRes= tableEnv.from("stock").joinLateral(call(SplitFunction.class, $("id"))).select($("id"), $("word"), $("length"), $("price"));tableEnv.toAppendStream(tableRes,TypeInformation.of(new TypeHint<Tuple4<String, String, Integer , Double>>(){})).print("tableres");//sql中调用
// String sql = "select id,word,length from stock LEFT JOIN LATERAL TABLE(splitId(id))";String sql = "select id,word,length,price from stock ,LATERAL TABLE(splitId(id))";final Table sqlTable = tableEnv.sqlQuery(sql);//转换成流final DataStream<Tuple2<Boolean, Tuple4<String, String, Integer,Double>>> sqlTableDataStream =tableEnv.toRetractStream(sqlTable, TypeInformation.of(new TypeHint<Tuple4<String, String, Integer, Double>>() {}));sqlTableDataStream.print("sql");env.execute("TableUDFDemo");}@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))public static class SplitFunction extends TableFunction<Row> {public void eval(String str){for (String s : str.split("_")) {// use collect(...) to emit a rowcollect(Row.of(s, s.length()));}}}/*将一条stock_578,22.141256900167285,UDFStock,1631002965778数据拆分成两条数据stock_578,stock,5,22.141256900167285,UDFStock,1631002965778stock_578,578,3,22.141256900167285,UDFStock,1631002965778*/
}
- 聚合函数 org.apache.flink.table.functions.AggregateFunction聚合函数可以把一个表中一列的数据,聚合成一个标量值。例如常用的max、min、count这些都是聚合函数。定义聚合函数时,首先需要定义个累加器Accumulator,用来保存聚合中间结果的数据结构,可以通过
createAccumulator()方法构建空累加器。然后通过accumulate()方法来对每一个输入行进行累加值更新。最后调用getValue()方法来计算并返回最终结果。例如下面是一个计算字符串出现次数的count方法。
public static class CountFunction extends AggregateFunction<String,
CountFunction.MyAccumulator> {public static class MyAccumulator {public long count = 0L;}public MyAccumulator createAccumulator() {return new MyAccumulator();}public void accumulate(MyAccumulator accumulator, Integer i) {if (i != null) {accumulator.count += i;}}public String getValue(MyAccumulator accumulator) {return "Result: " + accumulator.count;}
}
常用的自定义函数这些,Flink中也还提供了其他一些函数基类,有兴趣可以再深入了解。另外,这些函数基类都是实现了UserDefinedFunction这个接口,也就是说,应用程序完全可以基于UserDefinedFunction接口进行更深入的函数定制。这里就不再多做介绍了。
另外也可以通过aggregate()函数进行一些聚合操作,例如sum 、max等等。这样将获得一个AggregatedTable。例如
tab.aggregate(call(MyAggregateFunction.class, $("a"), $("b")).as("f0", "f1",
"f2")).select($("f0"), $("f1"));
4.4 基于Connector进行数据流转
由于Flink中的流数据,大部分情况下,都是映射的一个外部的数据源,所以,通常创建表时,也需要通过connector映射外部的数据源。关于Connector,之前已经介绍过。基于Connector来注册表的通用方式是这样:
tableEnv
.connect(...) // 定义表的数据来源,和外部系统建立连接
.withFormat(...) // 定义数据格式化方法
.withSchema(...) // 定义表结构
.createTemporaryTable("MyTable"); // 创建临时表
例如,针对文本数据
tableEnv
.connect(
new FileSystem().path(“YOUR_Path/sensor.txt”)
) // 定义到文件系统的连接
.withFormat(new Csv()) // 定义以csv格式进行数据格式化
.withSchema( new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
) // 定义表结构
.createTemporaryTable("sensorTable"); // 创建临时表
针对kafka数据
tableEnv.connect(
new Kafka()
.version("0.11")
.topic("sinkTest")
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
)
.withFormat( new Csv() )
.withSchema( new Schema()
.field("id", DataTypes.STRING())
.field("temp", DataTypes.DOUBLE())
)
.createTemporaryTable("kafkaOutputTable");
针对ES数据: 需要引入相应的connector依赖
tableEnv.connect(new Elasticsearch().version("6").host("localhost", 9200, "http").index("stock").documentType("temp"))
.inUpsertMode()
.withFormat(new Json())
.withSchema( new Schema().field("id", DataTypes.STRING()).field("count", DataTypes.BIGINT()))
.createTemporaryTable("esOutputTable");
aggResultTable.insertInto("esOutputTable");
或者针对MySQL,可以直接用SQL语句来管理
String sinkDDL=
"create table jdbcOutputTable (" +
" id varchar(20) not null, " +
" cnt bigint not null " +
") with (" +
" 'connector.type' = 'jdbc', " +
" 'connector.url' = 'jdbc:mysql://localhost:3306/test', " +
" 'connector.table' = 'sensor_count', " +
" 'connector.driver' = 'com.mysql.jdbc.Driver', " +
" 'connector.username' = 'root', " +
" 'connector.password' = '123456' )";
tableEnv.executeSql(sinkDDL) // 执行 DDL创建表
//操作表。
aggResultSqlTable.executeInsert("jdbcOutputTable");
另外,也可以直接将DataStream转换成表
DataStream<Tuple2<String, Long>> stream = ...
//直接创建一个与stream结构相同的表。
Table table = fsTableEnv.from("stream");
//或者进行一些列名转换
Table table = tableEnv.fromDataStream(stream,$("f1"), // 使用原有的列名 (f1是tuple中的第二列)$("rowtime").rowtime(), // 增加一个rowtime列,列的值是当前事件的EventTime$("f0").as("name") // 转换一个列名 (f0是tuple中的第一列)
);
将结果输出到另一张动态表的操作也在上面的文档中有介绍。可以直接使用insertinto方法。例如
Table orders = tableEnv.from("Orders");
orders.executeInsert("OutOrders");
//老版本的insertInto方法已经过期,不建议使用。
4.5 Flink Table API&SQL的时间语义
Flink对于时间语义的定义和处理是非常惊艳的,整个时间语义机制对于乱序数据流的处理非常有力。但是在Table API和SQL这一部分,时间语义似乎没有什么太大的作用。通常并不会对一个表进行开窗处理。所以在Flink的Table API&SQL这一部分,对于时间语义的处理思想就比较简单。就是将时间语义作为Table中的一个字段引入进来,由应用程序去决定要怎么使用时间。关于这一部分的时间语义,就不再去做过多深入的分析,只关注最常用的情况,使用EventTime事件时间机制,将Watermark添加到Table中。
在DataStream转换成为Table时,可以用.rowtime后缀在定义Schema时定义。这种方式一定需要在DataStream上已经定义好时间戳和watermark。使用.rowtime修饰的,可以是一个已有的字段,也可以是一个不存在的字段。如果不存在,会在schema的结尾追加一个新的字段。然后就可以像使用一个普通的Timestamp类型的字段一样使用这个字段。不管在哪种情况下,事件时间字段的值都是DataStream中定义的事件时间。
// Option 1:
// 基于 stream 中的事件产生时间戳和watermark
DataStream<Tuple2<String, String>> stream =
inputStream.assignTimestampsAndWatermarks(...);// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"),
$("user_action_time").rowtime());// Option 2:
// 从第一个字段获取事件时间,并且产生watermark
DataStream<Tuple3<Long, String, String>> stream =
inputStream.assignTimestampsAndWatermarks(...);// 第一个字段已经用作事件时间抽取了,不用再用一个新的字段表示事件时间了
Table table = tEnv.fromDataStream(stream, $("user_action_time").rowtime(),
$("user_name"), $("data"));完整demo:
import com.roy.flink.beans.Stock;
import com.roy.flink.window.WindowAssignerDemo;
import javafx.scene.control.Tab;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import java.sql.Timestamp;
import java.time.Duration;import static org.apache.flink.table.api.Expressions.$;/*** @desc 在DataStream转为Table时定义事件时间。*/
public class TableWatermarkDemo2 {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();final EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().withBuiltInCatalogName("default_catalog").withBuiltInDatabaseName("default_database").build();final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);//如果从文件读取,数据一次就处理完了。String filePath = WindowAssignerDemo.class.getResource("/stock.txt").getFile();final DataStreamSource<String> dataStream = env.readTextFile(filePath, "UTF-8");final SingleOutputStreamOperator<Stock> stockStream = dataStream.map(new MapFunction<String, Stock>() {@Overridepublic Stock map(String value) throws Exception {final String[] split = value.split(",");return new Stock(split[0], Double.parseDouble(split[1]), split[2], Long.parseLong(split[3]));}});//KEY1:定义一个WatermarkStrategy。Watermark延迟2秒WatermarkStrategy<Stock> watermarkStrategy= WatermarkStrategy.<Stock>forBoundedOutOfOrderness(Duration.ofMillis(2)).withTimestampAssigner(((element, recordTimestamp) -> element.getTimestamp()));final SingleOutputStreamOperator<Stock> etStream = stockStream.assignTimestampsAndWatermarks(watermarkStrategy);//将事件时间定义成一个新的字段 eventtimefinal Table table = tableEnv.fromDataStream(etStream, $("id"), $("price"),$("stockName"), $("eventtime").rowtime());
// final Table selectedTable = table.groupBy($("stockName"))
// .select($("stockName"), $("price").max().as("maxPrice"));
//
// tableEnv.toRetractStream(selectedTable, TypeInformation.of(new TypeHint<Tuple2<String, Double>>(){}))
// .print("selectedTable");//查找eventtime字段。final Table selectedTable = table.select($("id"), $("price"),$("eventtime"));
//
// tableEnv.toRetractStream(selectedTable, TypeInformation.of(new TypeHint<Tuple3<String, Double, Timestamp>>(){}))
// .print("selectedTable");tableEnv.toAppendStream(selectedTable,TypeInformation.of(new TypeHint<Tuple3<String, Double, Timestamp>>(){})).print("selectedTable");env.execute("TableWatermarkDemo2");}
}
4.6 查看SQL执行计划
最后补充一个查看SQL执行计划的API
final String explaination = tableEnv.explainSql(sql);
System.out.println(explaination);
在explainSql方法中,还可以传入一组可选的ExplainDetail参数,以展示更多的执行计划的细节。这是一个枚举值
/** ExplainDetail defines the types of details for explain result. */
@PublicEvolving
public enum ExplainDetail {
/**
* The cost information on physical rel node estimated by optimizer.
e.g. TableSourceScan(...,
* cumulative cost = {1.0E8 rows, 1.0E8 cpu, 2.4E9 io, 0.0 network, 0.0
memory}
*/
ESTIMATED_COST,
/**
* The changelog mode produced by a physical rel node. e.g.
GroupAggregate(...,
* changelogMode=[I,UA,D])
*/
CHANGELOG_MODE
总结:
Flink的Table API&SQL这一部分是提供了一组高级的抽象API,最常用的场景还是用在简化对流式数据的检索过程。但是,在示例用的1.12版本以及最新的1.13版本中,这一组抽象API还都处在活跃开发期,很多高级特性以及API都会经常发生变动。很多在1.11版本还非常实用的API,到当前1.12版本就被移除或者标记为过时,不建议使用。所以在学习这一章节时,即要理解这一组API的实现思路,也要学会如何查看API。至少要学会如何去尝试客户端API的使用方式。而他的功能,都可以DataStream/DataSet API来实现,并且在大部分的场景下,这种功能转换并不会太难。因此,在生产环境中,还不建议进行深度的使用。
相关文章:
Flink实战四_TableAPISQL
接上文:Flink实战三_时间语义 1、Table API和SQL是什么? 接下来理解下Flink的整个客户端API体系,Flink为流式/批量处理应用程序提供了不同级别的抽象: 这四层API是一个依次向上支撑的关系。 Flink API 最底层的抽象就是有状态实…...

海外云手机开辟企业跨境电商新道路
近几年,海外云手机为跨境电商、海外媒体引流、游戏行业等互联网领域注入了蓬勃活力。对于国内跨境电商而言,在亚马逊及其他平台上,短视频引流和社交电商营销成为最为有效的流量来源。如何通过海外云手机的助力,在新兴社交平台为企…...
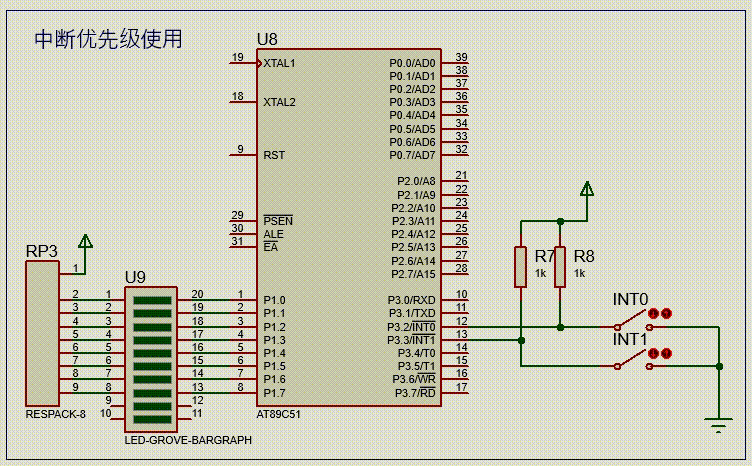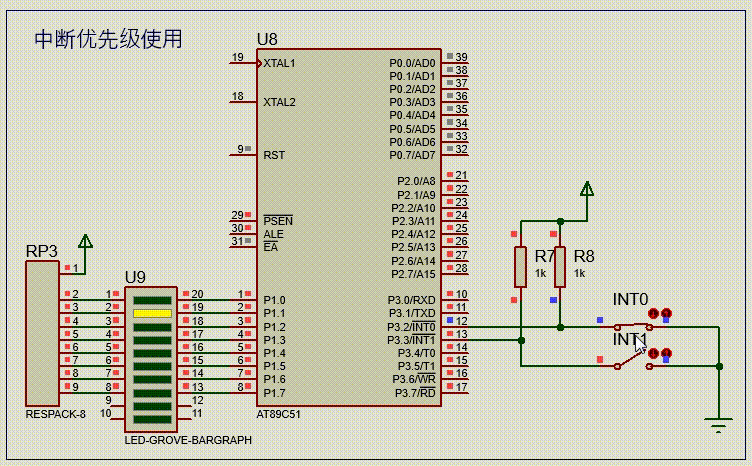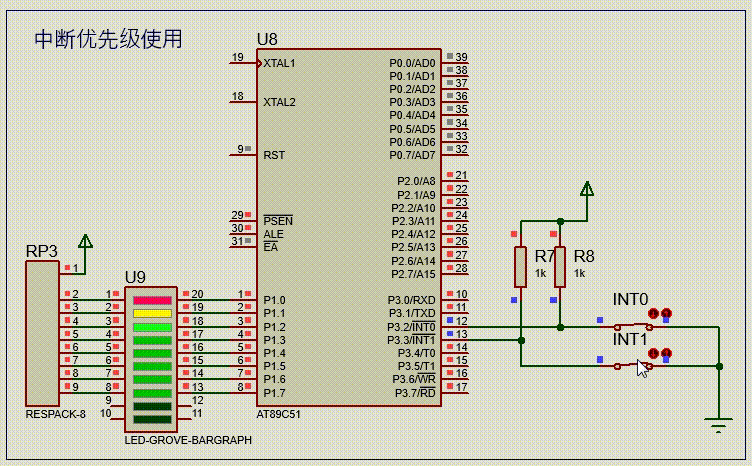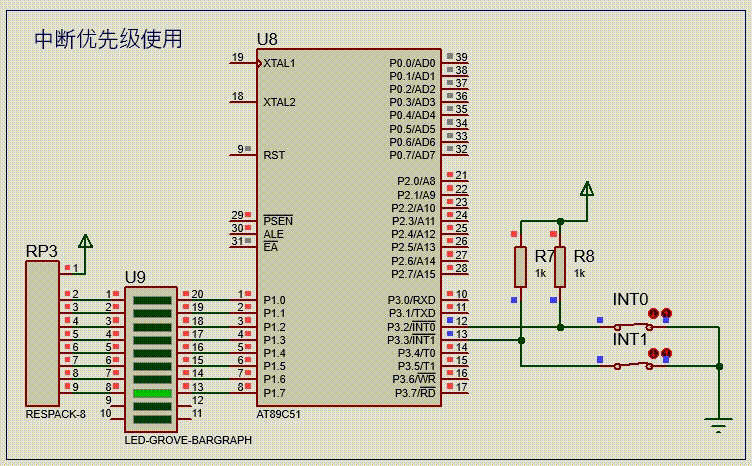
【51单片机系列】中断优先级介绍及使用
文章来源:《51单片机原理及应用(第3版)》5.4节。 51单片机采用了自然优先级和人工设置高、低优先级的策略。 当CPU处理低优先级中断,又发生更高级中断时,此时中断处理过程如下图所示。 一个正在执行的低优先级中断服…...
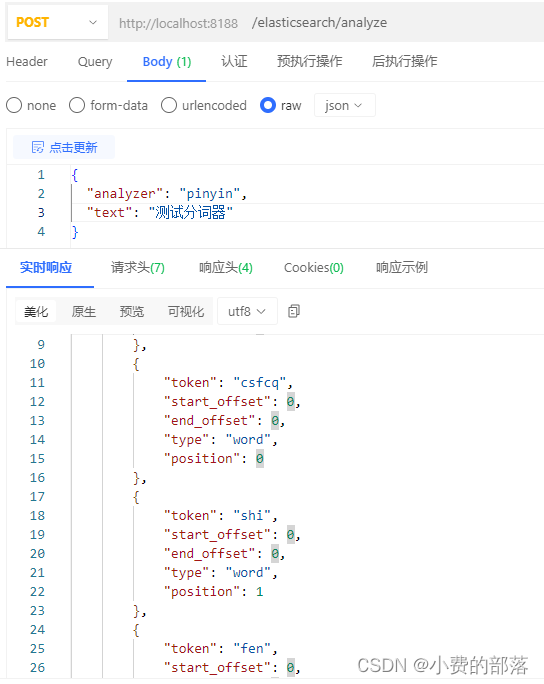
.net core 6 集成 elasticsearch 并 使用分词器
1、nuget包安装NEST、安装elasticsearch、kibana、ik分词器、拼音分词器 2、创建操作对象 //索引库 static string indexName "testparticper"; //es 操作对象 ElasticClient elasticClient new ElasticClient(new ConnectionSettings(new Uri("http://192.…...

Unity项目从built-in升级到URP(包含早期版本和2023版本)
unity不同版本的升级URP的方式不一样,但是大体流程是相似的 首先是加载URP包 Windows -> package manager,在unity registry中找到Universal RP 2023版本: 更早的版本: 创建URP资源和渲染器 有些版本在加载时会自动创建&#…...
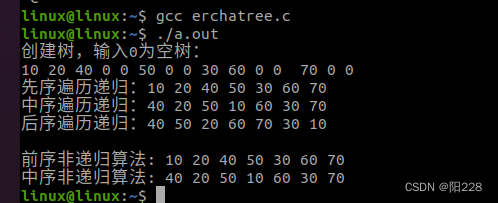
2月4号作业
编写程序实现二叉树的创建,三种遍历自己销毁 #include <myhead.h>#define TRUE 1 #define FALSE 0 #define OVERFLOW -2 #define OK 1 #define ERROR 0#define INIT_SIZE 20 #define INCREMENT_SIZE 5typedef int Status; typedef int TElemType; //存储结构…...

瑞_23种设计模式_建造者模式
文章目录 1 建造者模式(Builder Pattern)1.1 介绍1.2 概述1.3 创作者模式的结构 2 案例一2.1 需求2.2 代码实现 3 案例二3.1 需求3.2 代码实现 4 模式拓展 ★★★4.1 重构前4.2 重构后 5 总结5.1 建造者模式优缺点5.2 建造者模式使用场景5.3 建造者模式 …...

GA/T 1707-2019 防爆安全门检测
防爆安全门是指能抵抗爆炸冲击波作用的特种防护门,根据防爆门的防爆性能的不同,分为非接触爆炸防爆门和防接触爆炸防爆门,根据防爆能力的不同,分为不同等级。 GA/T 1707-2019 防爆安全门检测项目 测试项目 测试标准 外观质量 …...

k8s学习-数据管理
在Docker中我们知道,要想实现数据的持久化(所谓Docker的数据持久化即数据不随着Container的结束而结束),需要将数据从宿主机挂载到容器中,常用的手段就是Volume数据卷。在K8S中,也提供了存储模型Volume&…...
java hutool工具类实现将数据下载到excel
通过hutool工具类,对于excel的操作变得非常简单,上篇介绍的是excel的上传,对excel的操作,核心代码只有一行。本篇的excel的下载,核心数据也不超过两行,简洁方便,特别适合当下的低代码操作。 下载…...

【C/Python】Gtk部件ListStore的使用
一、C语言 在GTK中,Gtk.ListStore是一个实现了Gtk.TreeModel接口的存储模型,用于在如Gtk.TreeView这样的控件中存储数据。以下是一个简单的使用Gtk.ListStore的C语言示例,该示例创建了一个列表,并在图形界面中显示: …...

Swift 入门之自定义类型的模式匹配(Pattern Matching)
概览 小伙伴们都知道 Swift 是一门简洁、类型安全、极富表现力以及“性感迷人”的编程语言。 和大多数语言一样,在 Swift 中也有一些隐藏着的、不为人知的宝藏特性。利用它们我们可以极大增加撸码的愉悦和成就感。 其中,模式匹配(Pattern …...
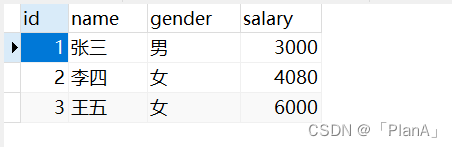
MySQL-----DML基础操作
DML语句 DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增删改操作。 ▶ 添加数据(INSERT) 【语法】 1. 给指定字段添加数据 INSERTO 表名 (字段名1,字段名2,...) VALUES (值1,值2,...); 2.给全…...

提前祝大家新年好!来看看社区 2023 都得了哪些奖吧
大噶好!转眼马上就是“龙”历新年啦,不知道大家这周的工作热情怎么样呢?小陈的心已经在殷切期盼回家过年了~ RTE 开发者社区预祝诸位: 2024 年 🐲龙年添财气,万事皆胜意! 回顾过去…...
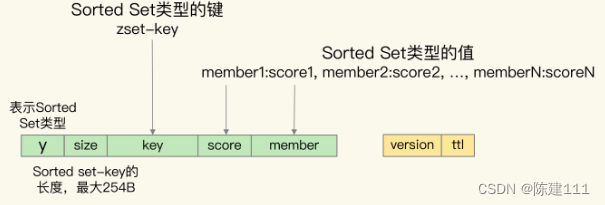
Redis核心技术与实战【学习笔记】 - 19.Pika:基于SSD实现大容量“Redis”
前言 随着业务数据的增加(比如电商业务中,随着用户规模和商品数量的增加),就需要 Redis 能保存更多的数据。你可能会想到使用 Redis 切片集群,把数据分散保存到不同的实例上。但是这样做的话,如果要保存的…...
qt-C++笔记之contains()和isEmpty()函数、以及部分其他函数列举
qt-C笔记之contains()和isEmpty()函数、以及部分其他函数列举 code review! 文章目录 qt-C笔记之contains()和isEmpty()函数、以及部分其他函数列举contains()isEmpty() 类似的其他函数列举通用容器类函数字符串特有函数 在Qt C开发中, contains() 和 isEmpty()…...
极速搭建幻兽帕鲁私服,叫上好友春节假期一起联机畅玩帕鲁
文章目录 前言幻兽帕鲁私服详细部署教程查看服务器开始游戏自定义游戏参数配置 前言 行业资讯 《幻兽帕鲁》的火爆对开发商 Pocketpair 来说,代价是巨大的。该游戏的成功让首席执行官沟部拓郎最近在推特上表示,他可能因服务器运营费用而面临破产。据他透…...

MagicVideo-V2:多阶段高保真视频生成框架
本项工作介绍了MagicVideo-V2,将文本到图像模型、视频运动生成器、参考图像embedding模块和帧内插模块集成到端到端的视频生成流程中。由于这些架构设计的好处,MagicVideo-V2能够生成具有极高保真度和流畅度的美观高分辨率视频。通过大规模用户评估&…...
【三】【C++】类与对象(二)
类的六个默认成员函数 在C中,有六个默认成员函数,它们是编译器在需要的情况下自动生成的成员函数,如果你不显式地定义它们,编译器会自动提供默认实现。这些默认成员函数包括: 默认构造函数 (Default Constructor)&…...

ffmpeg 输入文件,输入出udp-ts 指定pid
要使用FFmpeg将输入文件转换为UDP传输流(TS)并指定特定的PID,您可以使用以下命令: ffmpeg -i input_file -c:v libx264 -preset ultrafast -tune zerolatency -f mpegts -map 0:v:0 -map 0:a:0 -pid 0x12345678 udp://output_addr…...
)
UE5地牢生成实战:从零搭建程序化地下城(附完整蓝图逻辑)
UE5地牢生成实战:从零搭建程序化地下城(附完整蓝图逻辑) 在游戏开发中,程序化内容生成(PCG)技术正变得越来越重要。想象一下,你正在开发一款Roguelike游戏,每次玩家进入地牢都能获得全新的探索体验——这正…...

从 LLM 到 OpenClaw:七步看懂 Prompt、Memory、MCP、Skills、Agent
从 LLM 到 OpenClaw:七步看懂 Prompt、Memory、MCP、Skills、Agent 这两年 AI 术语越来越多:LLM、MCP、Agent、Skills、OpenClaw。 如果你不是技术背景,第一次看到这串词,基本都会懵。下面我用一个统一场景来讲:把 AI…...

OpenClaw+千问3.5-9B:个性化新闻摘要与推送系统
OpenClaw千问3.5-9B:个性化新闻摘要与推送系统 1. 为什么需要个人新闻助手? 每天早上打开新闻App,总会被各种无关信息轰炸——明星八卦、标题党、重复推送...作为一个技术从业者,我真正需要的是垂直领域的高质量内容。尝试过RSS…...

**发散创新:基于Python的本体推理与知识表示实战解析**在人工智能和语义网技术飞速发展的今天,**知识表
发散创新:基于Python的本体推理与知识表示实战解析 在人工智能和语义网技术飞速发展的今天,知识表示(Knowledge Representation) 已成为构建智能系统的底层核心能力之一。它不仅决定了系统对现实世界的理解深度,还直接…...

电赛赛题深度解析:从五大类别到实战备赛策略
1. 电赛赛题五大类别全解析 全国大学生电子设计竞赛(简称电赛)作为电子类专业最具影响力的赛事,其赛题设置直接反映了行业技术发展趋势。经过对近十年赛题的统计分析,所有题目可明确划分为五大类别,每类都有独特的考察…...

Python 中的正则表达式:从基础到高级应用
Python 中的正则表达式:从基础到高级应用 1. 背景介绍 正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于匹配字符串中字符组合的模式。在 Python 中,正则表达式是处理文本的强大工具,它可以…...
深度学习中的 Transformer 架构:从原理到实践
深度学习中的 Transformer 架构:从原理到实践 1. 背景介绍 Transformer 架构是深度学习领域的重大突破,它彻底改变了自然语言处理(NLP)的格局,并逐渐扩展到计算机视觉、语音识别等领域。Transformer 由 Google 团队在 …...

2025届毕业生推荐的降重复率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术写作以及论文发表进程里,查重之后的降重处置是关键一环,当下市面…...
 第一章:AWS IAM 配置详解)
对接亚马逊 SP-API(Amazon Selling Partner API) 第一章:AWS IAM 配置详解
1. AWS IAM 基础概念扫盲 第一次接触亚马逊SP-API的开发者,往往会在IAM配置环节卡壳。我见过不少团队在这个阶段浪费两三周时间反复调试,其实只要理解几个核心概念就能事半功倍。IAM(Identity and Access Management)就像亚马逊AW…...

Scratch二次开发实战:如何按需“阉割”菜单栏功能?从关闭语言切换、主题到隐藏教程按钮
Scratch教学环境定制指南:精准控制菜单栏功能的艺术 1. 为什么需要定制Scratch界面? 在少儿编程教育领域,Scratch作为全球最受欢迎的图形化编程工具之一,其默认界面设计面向的是广泛年龄段的国际用户。然而在实际教学场景中&#…...