Kafka运维相关知识
目录
一、基本概念
二、技术特性
三、设计思想
四、运维建议
一、基本概念
Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/spark流式处理引擎。
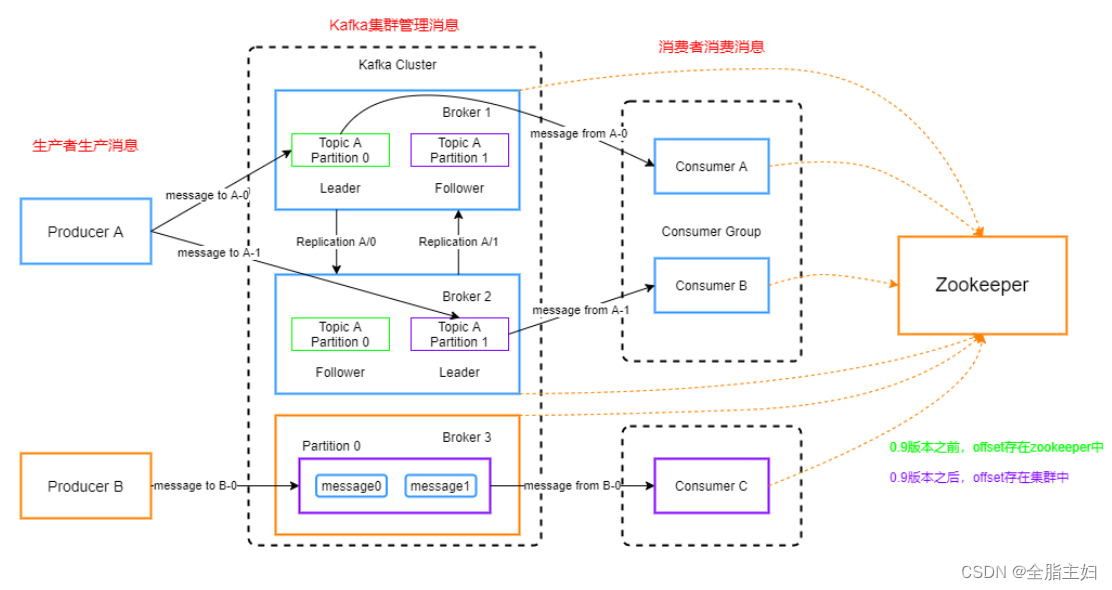
Producer:Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如broker-0、broker-1等。
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
二、技术特性
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
Consumergroup:各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
消息状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
消息持久化:Kafka中会把消息持久化到本地文件系统中,并且保持极高的效率。
消息有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
push-and-pull : Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
分区机制partition:Kafka的broker端支持消息分区,Producer可以决定把消息发到哪个分区,在一个分区中消息的顺序就是Producer发送消息的顺序,一个主题中可以有多个分区,具体分区的数量是可配置的。分区的意义很重大,后面的内容会逐渐体现。
三、设计思想
整体架构如下:
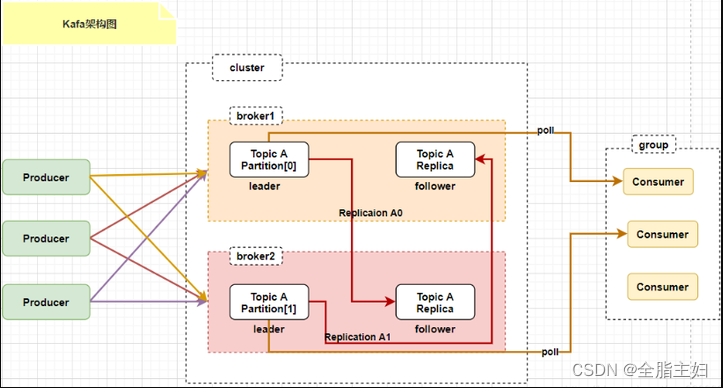
Kafka 集群包含多个 broker。一个 topic 下通常有多个 partition,partition 分布在不同的 Broker 上,用于存储 topic 的消息,这使 Kafka 可以在多台机器上处理、存储消息,给 kafka 提供给了并行的消息处理能力和横向扩容能力。
消费者架构如下:
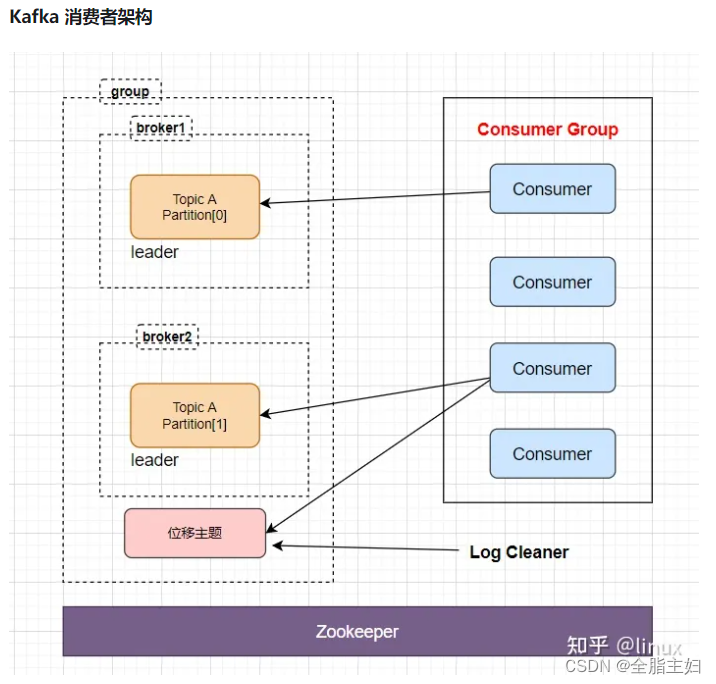
基本流程:
Consumer Group中的Consumer向各自注册的分区上进行消费消息
Consumer消费消息后会将当前标注的消费位移信息以消息的方式提交到位移主题中记录,一个Consumer Group中多个Consumer会做负载均衡,如果一个Consumer宕机,会自动切换到组内别的Consumer进行消费
关键的点:
Consumer Group:组内多个的Consumer可以公用一个Consumer Id,组内所有的Consumer只能注册到一个分区上去消费,一个Consumer Group只能到一个Topic上去消费
位移主题:
位移主题的主要作用是保存Kafka消费者的位移信息
Kafka最新版本中位移主题的处理方式:
Consumer的位移信息offset会当作一条条普通消息提交到位移主题(_consumer_offsets)中。
四、运维建议
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。所以可以估算消费这条消息后,处理的时间,设置max.poll.interval.ms大于等于这个时长多1min。
如果这些都设置好,还是出现rebalance,可以排查一下Consumer 端的 GC 表现,比如是否出现了频繁的 Full GC 导致的长时间停顿,从而引发了 Rebalance。
将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer。
- 当生产者往主题写入消息的速度超过了应用程序验证数据的速度或者消息的数量较大,可采取横向伸缩的策略提高消费效率,分为两种:1.群组内增加消费者 2.增加消费者群组
- 消费者组订阅某一主题时需要注意,建议:该消费组内消费者数量不要超过该主题的分区数,否则将可能产生闲置的消费者,不会接收到任何消息。
- 消费者组订阅一个主题,主题下的每个分区只对应组中一个消费者,不会出现对应多个消费者的情况。如果分区数大于或者等于组中的消费者实例数,一个消费者会负责多个分区,建议:分区数和消费者数量相等,一个消费者负责一个分区。
- 避免重平衡
在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance 完成。
Rebalance 的弊端:
1.Rebalance 影响 Consumer 端 TPS。(因为rebalance过程中,kafka会停止消费)
2.Rebalance 要完成需要比较久的时间。
3.Rebalance 效率不高,每次都要全部consumer参加。
Rebalance 的触发条件有 3 个。
- 组成员数发生变更。比如有新的 Consumer 实例加入组或者离开组,抑或是有 Consumer 实例崩溃被“踢出”组。99% 都是这个原因
- 订阅主题数发生变更。Consumer Group 可以使用正则表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile(“t.*c”)) 就表明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主题。在 Consumer Group 的运行过程中,你新创建了一个满足这样条件的主题,那么该 Group 就会发生 Rebalance。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
如何避免这99%的情况发生的rebalance?
可以从consumer组员变化的原因分析起:
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被“踢出”Group 而引发的。
当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经“死”了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。
这个发送心跳的间隔在Consumer 端有个参数,叫 session.timeout.ms,默认值是 10 秒,即如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。session.timout.ms 决定了 Consumer 存活性的时间间隔。
除了这个参数,Consumer 还提供了一个允许你控制发送心跳请求频率的参数,就是 heartbeat.interval.ms。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启 Rebalance,因为,目前 Coordinator 通知各个 Consumer 实例开启 Rebalance 的方法,就是将 REBALANCE_NEEDED 标志封装进心跳请求的响应体中。
Consumer 端还有一个参数,用于控制 Consumer 实际消费能力对 Rebalance 的影响,即 max.poll.interval.ms 参数,默认5min,Consumer 端应用程序两次调用 poll 方法的最大时间间隔,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,Coordinator 也会开启新一轮 Rebalance。
所以可以修改为以下经验推荐值:
- 设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
相关文章:
Kafka运维相关知识
目录 一、基本概念 二、技术特性 三、设计思想 四、运维建议 一、基本概念 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速、可扩展、可持久化的特点。它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于h…...
 和静态库(.a))
鸿蒙Native项目生产动态库(.so) 和静态库(.a)
通过 DevEco Studio 创建Native项目,我的版本为:Build Version: 3.1.0.501, built on June 20, 2023 CMakeLists.txt 文件中默认生成的是动态库,该命令为:add_library(entry SHARED hello.cpp) 通过Sutdio的操作 Build -> Bu…...

B站课程评分
Spring6 https://www.bilibili.com/video/BV1Ft4y1g7Fb/ 评价: 推荐一看 配套文档优秀, 老师口齿清晰, 条理不错. mybatis https://www.bilibili.com/video/BV1JP4y1Z73S/?spm_id_from333.337.search-card.all.click 评价: 推荐一看 配套文档优秀, 老师口齿清晰, 条理不错…...
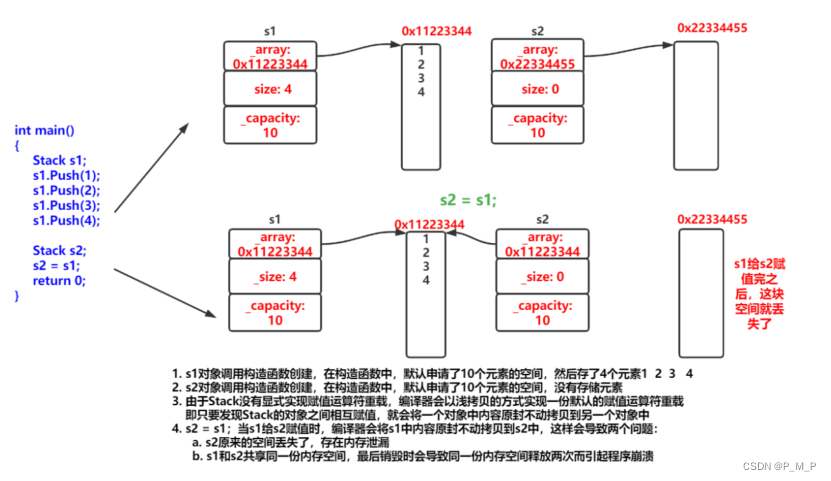
【C++】拷贝构造函数和赋值运算符重载详解
目录 拷贝构造函数 概念 特征 赋值运算符重载 运算符重载 赋值运算符重载 编辑前置和后置重载 ⭐拷贝构造函数 ⭐概念 拷贝构造函数:只有单个形参,该形参是对本类类型对象的引用(一般常用const修饰),在用已存 在的类类型对象创建新…...
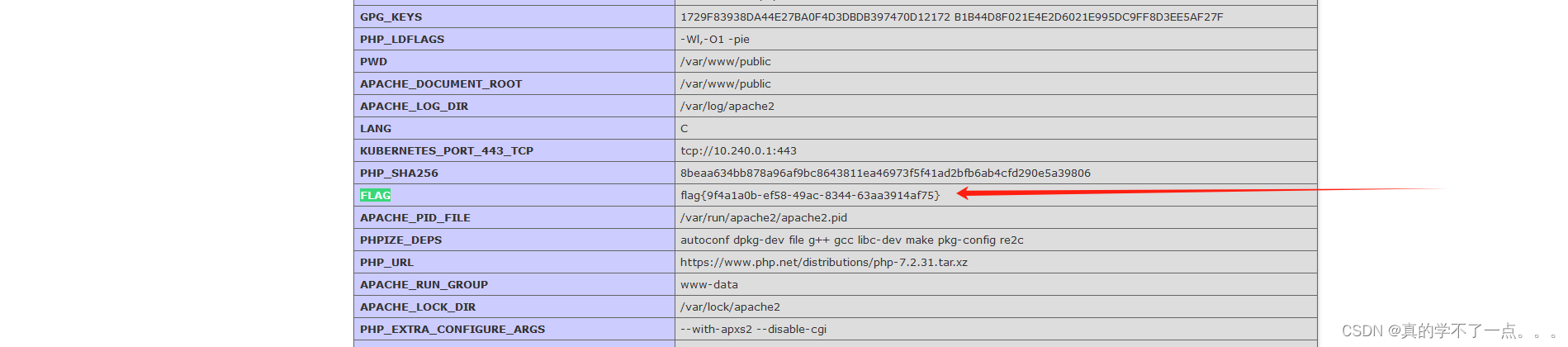
BUUCTF-Real-[ThinkPHP]5-Rce
1、ThinkPHP检测工具 https://github.com/anx0ing/thinkphp_scan 漏洞检测 通过漏洞检测,我们发现存在rce漏洞! 2、漏洞利用 ---- [!] Name: Thinkphp5 5.0.22/5.1.29 Remote Code Execution VulnerabilityScript: thinkphp5022_5129.pyUrl: http://n…...

物联网中基于WIFI的室内温度检测系统设计
标题:物联网中基于WIFI的室内温度检测系统设计 摘要 随着物联网技术的快速发展,智能家居环境监测系统成为研究热点之一。本论文旨在设计并实现一个基于Wi-Fi的室内温度检测系统,用于实时监控和调节家庭或办公环境中的温度条件。该系统利用Wi-Fi信号的特性进行温度感知,不…...
驱动开发-系统移植
一、Linux系统移植概念 需要移植三部分东西,Uboot ,内核 ,根文件系统 (rootfs) ,这三个构成了一个完整的Linux系统。 把这三部分学明白,系统移植就懂点了。 二、Uboot 1、啥是Uboot uboot就是引导程…...

MySQL数据存储
MySQL数据存储 Innodb存储引擎的数据存储,可以使用两种方式进行存储:系统表空间和独立表空间 -- ON表示使用的是独立表空间-- OFF表示使用的是系统表空间show variables like %innodb_file_per_table% 系统表空间(共享表空间) 在MySQL5.5之前默认使用的是…...
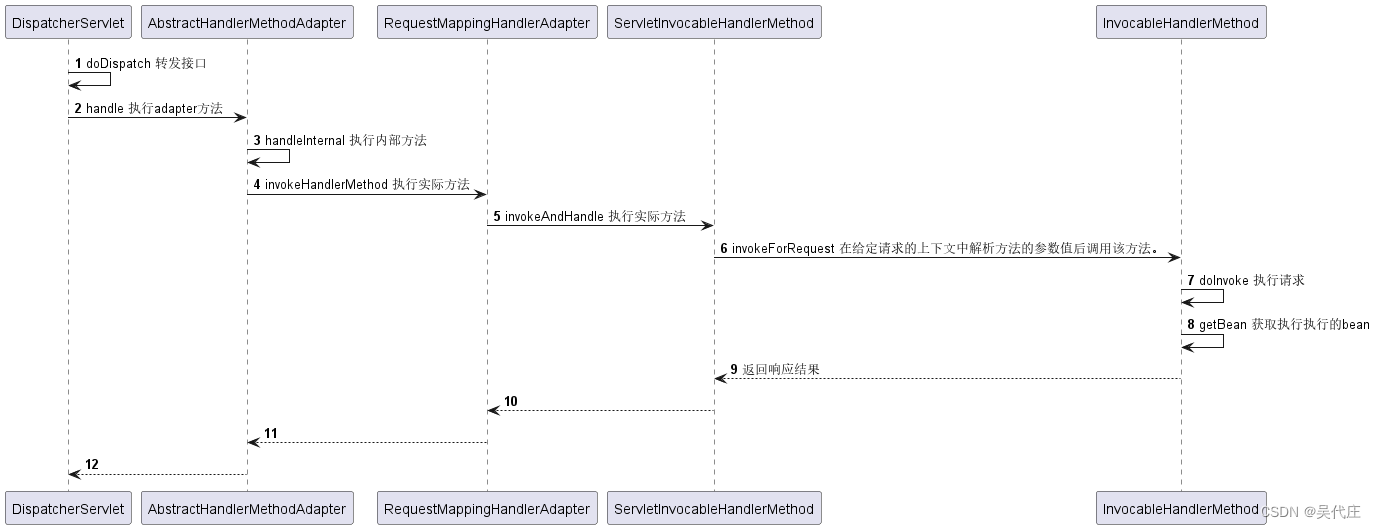
带着问题读源码——Spring MVC是怎么找到接口实现类的?
引言 我们的产品主打金融服务领域,以B端客户为我们的核心合作伙伴,然而,我们的服务最终将惠及C端消费者。在技术实现上,我们采用了公司自主研发的微服务框架,该框架基于SpringBoot,旨在提供高效、可靠的服…...

[NAND Flash 7.1] 闪存系统性能优化方向集锦?AC timing? Cache? 多路并发?
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解NAND Flash》 <<<< 返回总目录 <<<< 传送门 >>> 总目录 主页: 元存储的博客_CSDN博客 依公开知识及经验整理,如有误请留言。 个人辛苦整理,付费内容,禁止转载。 内容摘要 优…...
【数据结构】分治策略
现场保护和现场恢复 文章目录 分治策略分治法解决问题有以下四个特征:分治法步骤: 递归:解决以下问题:倒序输出整数求最大公约数(递归和非递归)菲波那切数列 不要尝试间接 要使用直接递归(自己调用自己&am…...
【PLC一体机】PLC一体机中如何实现触摸屏和PC电脑的通讯
博主今天准备把之前买的PLC一体机拿出来玩一下,翻看以前的博文,发现没有记录分享PLC一体机中如何实现触摸屏程序下载的内容。 如之前博文介绍的那样,PLC一体机由PLC和触摸屏两部分集成的设备,因此设备内部已经做好了PLC和触摸屏之…...

如何保证订单异步回调的幂等性
保证订单异步回调的幂等性是非常重要的,因为异步通知可能会由于网络问题、支付系统重试或其他原因导致多次发送同一个支付结果通知。以下是一些保证订单异步回调幂等性的常用方法: 接口设计幂等性: 在设计异步通知的接口时,考虑让…...
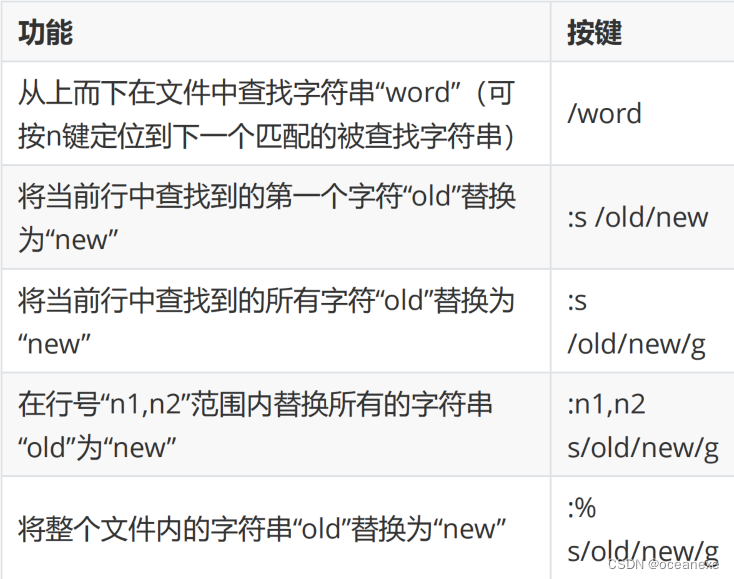
Linux下vim命令详解
vim #创建或编辑新的文件 #这将在当前目录下创建一个名为fi.txt的新文本文件。如果文件已经存在,将会编辑现有文件。 [rootsever ~]#vim fi.txt #对于普通的文本编辑操作,可以使用以下键盘命令: - i:进入插入模式ÿ…...
机器学习6-逻辑回归
逻辑回归是机器学习中一种常用于二分类问题的监督学习算法。虽然名字中包含“回归”,但实际上它用于分类任务,特别是对于输出为两个类别的情况。逻辑回归通过使用 logistic 函数将输入映射到一个在0,1范围内的概率值,然后根据这个概率值进行分类。 以下是逻辑回归的基本概念…...

关于Clone
关于Clone 一般情况下,如果使用clone()方法,则需满足以下条件。 1、对任何对象o,都有o.clone() ! o。换言之,克隆对象与原型对象不是同一个对象。 2、对任何对象o,都有o.clone().getClass() o.getClass()。换言之&a…...

【C++入门学习指南】:函数重载提升代码清晰度与灵活性
🎥 屿小夏 : 个人主页 🔥个人专栏 : C入门到进阶 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑前言一、函数重载1.1 函数重载的概念1.2 函数重载的作用1.3 C支持函数重载的原理1.4 扩展 &…...
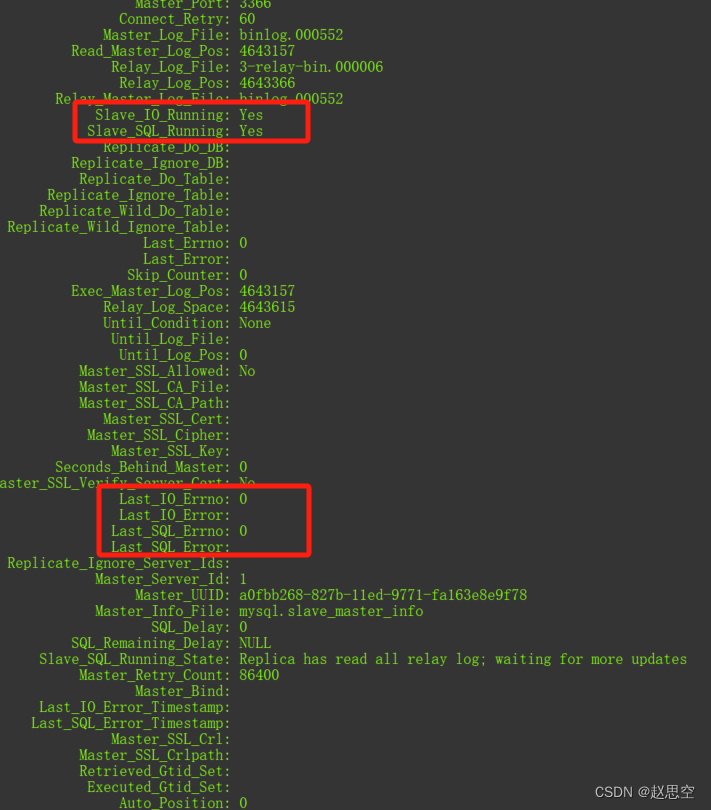
MySql主从同步,同步SQL_ERROR 1032解决办法
1.登录从库 mysql -u root -p 2.输入命令查看状态 SHOW SLAVE STATUS\G; 3.找到对应的错误数据位置 Slave_IO_Running: YesSlave_SQL_Running: NoReplicate_Do_DB: app_push_centerReplicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Tabl…...

Webpack的性能优化
减少构建时间:使用webpack的缓存功能,通过配置cache: true来利用缓存,减少重复构建时间。 使用多线程或并行构建,可以利用webpack的parallel-webpack或HappyPack插件来实现。 充分利用硬件资源,例如利用多核CPU或者SSD…...
函数的详细介绍)
PyTorch中tensor.backward()函数的详细介绍
backward() 函数是PyTorch框架中自动求梯度功能的一部分,它负责执行反向传播算法以计算模型参数的梯度。由于PyTorch的源代码相当复杂且深度嵌入在C底层实现中,这里将提供一个高层次的概念性解释,并说明其使用方式而非详细的源代码实现。 在P…...

如何运用AI技术有效破解企业视觉检测难题
「本文已用流量券推广,欢迎收藏 关注」AI智能体视觉检测系统(TVA)的核心突破,在于实现了从“被动识别”到“主动决策”的历史性跨越。以汽车零部件制造车间的经典场景为例,螺母焊接点的质检曾是长期困扰各个企业多年的…...

python zipfile
# Python 的 zipfile:不只是打包文件那么简单 如果你用过压缩软件,大概知道 ZIP 格式是用来把多个文件打包成一个,顺便还能压缩节省空间。Python 里的 zipfile 模块就是干这个的,但它的能力远不止“打包”这么简单。 它到底是什么…...

2026大模型训练全景,从底座到上线,决定AI体验的完整链路
在人工智能飞速发展的2026年,大众对大模型的认知早已不再停留在“参数越大越强”的简单层面。我们日常使用AI助手时感受到的流畅对话、精准指令响应、高效工具调用,甚至稳定可靠的输出风格,背后都不是单一的预训练环节在支撑,而是…...

明日方舟基建自动化:从手动操作到智能管理的进阶指南
明日方舟基建自动化:从手动操作到智能管理的进阶指南 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 作为《明日方舟》玩家,你是否也曾面临这样的困境:每天花费…...

2025届学术党必备的十大降AI率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 对于知网AI检测系统来讲,要降低生成文本的可识别性,得从词汇层面施展…...

MyKeymap应用专属键盘映射配置指南
MyKeymap应用专属键盘映射配置指南 【免费下载链接】MyKeymap 一款基于 AutoHotkey 的键盘映射工具 项目地址: https://gitcode.com/gh_mirrors/my/MyKeymap 还在为不同软件快捷键冲突烦恼?当你在Photoshop中习惯使用CtrlS保存,却在Excel中误触导…...

music-api:快速获取四大音乐平台播放地址的终极指南
music-api:快速获取四大音乐平台播放地址的终极指南 【免费下载链接】music-api 各大音乐平台的歌曲播放地址获取接口,包含网易云音乐,qq音乐,酷狗音乐等平台 项目地址: https://gitcode.com/gh_mirrors/mu/music-api 还在…...

开源SCADA系统FUXA的SVG编辑器列表过滤功能:从线性列表到智能管理的技术演进
开源SCADA系统FUXA的SVG编辑器列表过滤功能:从线性列表到智能管理的技术演进 【免费下载链接】FUXA Web-based Process Visualization (SCADA/HMI/Dashboard) software 项目地址: https://gitcode.com/gh_mirrors/fu/FUXA 在工业自动化领域,SCADA…...

实战案例:基于快马平台开发copaw本地部署的智能文档摘要应用
今天想和大家分享一个最近用InsCode(快马)平台做的实战项目——基于copaw本地部署的智能文档摘要工具。这个工具特别适合需要处理大量文档的团队或个人,能快速提取核心内容,提高工作效率。 项目背景与需求 在日常工作中,我们经常需要阅读大量…...

加密压缩包密码恢复全攻略:从原理到实战的ArchivePasswordTestTool应用指南
加密压缩包密码恢复全攻略:从原理到实战的ArchivePasswordTestTool应用指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 在数…...