PyTorch中tensor.backward()函数的详细介绍
backward() 函数是PyTorch框架中自动求梯度功能的一部分,它负责执行反向传播算法以计算模型参数的梯度。由于PyTorch的源代码相当复杂且深度嵌入在C++底层实现中,这里将提供一个高层次的概念性解释,并说明其使用方式而非详细的源代码实现。
在PyTorch中,backward() 是自动梯度计算的核心方法之一。当调用一个张量的 .backward() 方法时,系统会执行反向传播算法以计算该张量以及它依赖的所有可导张量的梯度。
具体来说,这行代码 tensor.backward() 的含义和作用是:
-
前提条件:
- 需要确保
tensor是在一个包含至少一个需要梯度(requires_grad=True)的张量的计算图中的结果。 - 如果
tensor不是一个标量张量,通常需要先对它进行求和或者其他运算将其转换为标量,以便于得到有效的梯度。
- 需要确保
-
操作过程:
- 当调用
.backward()时,PyTorch会从当前张量开始沿着计算图回溯,根据链式法则计算每个叶子节点(即最初具有 requires_grad=True 属性的输入张量)对当前目标张量(这里是tensor)的梯度。
- 当调用
-
内存管理与优化:
- PyTorch内部实现了缓存机制来保存中间计算结果,并且能够处理稀疏梯度、只计算需要更新参数的梯度等情况,以提高效率和减少内存使用。
-
实际应用: 在深度学习训练中,我们通常会在前向传播后计算损失函数的值,然后对这个损失值调用
.backward()计算网络中所有可训练参数的梯度,接着利用这些梯度通过优化器更新参数,从而迭代地优化模型性能。
例如,在一个简单的神经网络训练场景中:
1# 假设model是一个定义好的神经网络,inputs和targets是训练数据
2outputs = model(inputs)
3loss = loss_function(outputs, targets)
4
5# 调用 .backward() 计算梯度
6loss.backward()
7
8# 使用优化器更新参数
9optimizer.step()
10optimizer.zero_grad() # 清零梯度,准备下一轮迭代 总结起来,tensor.backward() 是实现自动微分的关键步骤,它允许我们在无需手动编写梯度计算代码的情况下,自动完成整个计算图上所有需要梯度的张量的梯度计算。
1. 概念介绍:
当你在PyTorch中创建一个张量并设置 requires_grad=True 时,这个张量会跟踪在其上执行的所有操作形成一个计算图。当你对包含这些张量的表达式求值(如损失函数)并调用 .backward() 方法时,系统会沿着这个计算图反向传播来计算每个可训练变量相对于当前目标变量(通常是损失函数)的梯度。
1import torch
2
3# 创建一个可求导的张量
4x = torch.tensor([1.0, 2.0], requires_grad=True)
5
6# 对张量进行操作
7y = x ** 2
8z = y.sum()
9
10# 计算损失并调用 .backward()
11loss = z
12loss.backward()在这个例子中,调用 loss.backward() 后,x.grad 将会被更新为相对于 loss 的梯度。
2. 实现原理概要:
虽然我们不深入到具体的源代码细节,但可以概述一下.backward()函数背后的工作原理:
- PyTorch维护了一个动态构建的计算图,记录了从叶子节点(即那些
requires_grad=True的张量开始)到当前输出张量的所有运算。 - 当调用
.backward()时,它首先检查是否有任何关于如何计算梯度的缓存(如果之前已经调用过.backward()并且retain_graph=True)。如果没有,则开始新的反向传播过程。 - 反向传播过程中,PyTorch按照计算图中的操作顺序反向遍历,对于每一个前向传播中的操作,调用其对应的反向传播函数来计算梯度,并将梯度累积到相关的叶子节点上。
- 如果目标张量是一个标量,则不需要指定gradient参数;如果不是标量,需要传入一个与目标张量形状相匹配的gradient张量作为反向传播的起始梯度。
实际的 .backward() 函数的具体实现涉及复杂的C++代码和大量的优化逻辑,包括利用CUDA对GPU加速的支持、内存管理以及针对各种数学操作的高效微分规则实现等。
3. backward() 函数内部介绍
backward() 函数的实际内部实现非常复杂,并且大部分代码是用C++编写的。它主要包括以下几个关键部分:
-
动态计算图构建与反向传播算法: 在PyTorch中,每次执行一个涉及可导张量的操作时,都会在背后构建一个动态的计算图。当调用
.backward()时,系统会沿着这个计算图反向遍历,应用链式法则(或自动微分规则)来逐层计算梯度。 -
CUDA支持与GPU加速: 对于使用GPU进行计算的情况,
.backward()函数内部会利用CUDA API进行并行化计算以加速梯度的求解过程。这包括了将数据从CPU移动到GPU、在GPU上执行反向传播操作以及最后将结果梯度回传至CPU等步骤。 -
内存管理: 反向传播过程中涉及到大量的临时变量和中间结果,为了高效地利用内存资源,
.backward()需要有效地管理这些临时对象的生命周期,例如通过适当的内存分配和释放策略,以及梯度累加等技术避免不必要的内存拷贝。 -
优化逻辑:
- 稀疏梯度:对于大型网络和稀疏输入场景,
.backward()能够处理稀疏梯度以减少计算和存储开销。 - 自动微分:针对各种数学运算实现了高效的微分规则,确保能够快速准确地计算出所有参数的梯度。
- 梯度累积:在训练深度学习模型时,可能需要多次前向传播后才做一次更新,这时可以累计多个批次的梯度后再调用优化器更新权重,
.backward()也支持这种模式下的梯度累积。 - 防止梯度爆炸/消失:提供一些机制如梯度裁剪(gradient clipping)来防止训练过程中梯度的过大或过小问题。
- 稀疏梯度:对于大型网络和稀疏输入场景,
由于源代码实现的具体细节较为复杂和技术性强,以上仅为 .backward() 实现原理的大致概述,具体实现则包含了大量底层的C++代码逻辑。
4. backward() 实现原理和其中底层的C++代码逻辑
backward() 函数在PyTorch中实现自动梯度计算的核心原理是利用动态图(Dynamic Computational Graph)和反向模式自动微分(Reverse-Mode Automatic Differentiation)。由于底层C++代码的具体实现相当复杂且深入,以下是对其实现原理的高级概述:
-
动态图构建: 当对一个带有
requires_grad=True的张量进行操作时,PyTorch会记录这些操作以形成一个动态计算图。每个操作节点都包含了一个关于如何执行前向传播的函数以及一个关于如何执行反向传播(即求梯度)的函数。 -
反向传播: 调用
.backward()时,它会从当前张量开始沿着这个动态计算图逆向遍历,对于每一个操作节点调用其对应的反向传播函数。在这个过程中,通过链式法则递归地计算出所有叶子节点(即原始输入张量)相对于目标张量(通常为损失函数值)的梯度。 -
内存管理与优化:
- PyTorch内部有复杂的内存管理机制来处理中间结果和梯度的存储。例如,在某些情况下,梯度可能被累积(累加到现有的梯度上),而不是每次都重新计算。
- 对于GPU加速,
.backward()利用CUDA API并行计算各个节点的梯度,从而极大地提高效率。
-
底层C++实现: 实际的C++源代码逻辑涉及到torch/csrc/autograd目录下的多个文件,包括Function、Variable、AccumulateGrad等核心类,它们共同构成了自动梯度计算的基础设施。其中,
Function类及其派生类定义了不同运算符在正向传播和反向传播中的行为;Variable类则代表了带有梯度信息的数据结构。 -
缓存与优化: PyTorch还会尝试利用缓存技术减少不必要的重复计算,并采用了一些优化策略,比如只对需要更新的参数计算梯度、避免冗余计算、支持稀疏梯度等。
总之,虽然这里没有给出详细的C++源码分析,但可以理解的是,.backward() 的实现是一个结合了深度学习、自动微分理论和高性能计算编程技术的综合成果。
5. 底层C++实现
PyTorch的自动梯度计算系统主要依赖于C++实现的核心组件。以下是这些关键类和文件的简要概述:
-
Function 类: 在
torch/csrc/autograd/function.h等文件中定义了Function类及其派生类。每个Function实例代表了一个在计算图中的节点,它包含了前向传播(forward)操作的实现以及反向传播(backward)时所需的梯度计算逻辑。当对张量进行运算时,会创建对应的Function对象,并将其加入到动态图中。 -
Variable 类:
Variable类(现在在新版本的PyTorch中被Tensor合并)是带有梯度信息的数据结构,它封装了实际的数据存储(即张量),并关联了一个指向其创建它的Function的指针。通过这种方式,Variable能够追踪其参与的所有计算历史,从而在调用.backward()时执行正确的反向传播过程。 -
AccumulateGrad: 这个类通常用于处理梯度累加的情况,当多次调用
.backward()而没有清零梯度时,确保梯度会被正确地累积而不是覆盖。这个类的实例也会作为特定情况下的一个Function节点存在于计算图中。 -
其他相关类和机制:
- AutogradEngine:负责调度正向传播和反向传播的实际执行流程。
- GradFn(或AutogradMeta):与Variable相关联,存储关于如何执行反向传播的具体信息。
- Function_hook:用户可以注册自定义函数,在前向传播或反向传播过程中特定位置插入额外的操作。
以上描述仅提供了一种高层次的理解,具体的实现细节涉及到更复杂的C++代码和内存管理策略,以确保高效的计算性能和资源利用率。
6. 多种优化策略来提高效率和减少资源消耗
PyTorch在自动梯度计算过程中采用了多种优化策略来提高效率和减少资源消耗:
-
梯度累加(Gradient Accumulation): 在深度学习训练中,尤其是当显存有限时,可以通过多次前向传播后累积梯度再一次性更新参数,而不是每次前向传播后都立即进行反向传播和参数更新。这样可以使用更小的批量大小进行训练,同时保持较大的“有效”批量大小。
-
只计算需要更新的参数的梯度: 当模型中的某些参数不需要更新时(例如权重被冻结或者模型部分结构为不可训练的),PyTorch不会为这些参数计算梯度,从而节省了计算资源。
-
避免冗余计算:
- PyTorch通过动态图机制允许重用已计算结果,在同一计算图上下文中重复执行相同的运算会直接返回缓存的结果,而非重新计算。
.grad属性默认情况下会累加多个.backward()调用产生的梯度,只有在进行参数更新之前才会清零。这有助于在分布式训练或梯度累积等场景下避免重复计算梯度。
-
稀疏梯度支持: 对于大规模数据集中的稀疏输入或者输出层具有高维度稀疏性的情况,PyTorch能够高效地处理和存储稀疏梯度,避免对全零或近似全零区域进行不必要的内存占用和计算。
-
CUDA并行化与优化: 利用CUDA提供的并行计算能力,PyTorch可以在GPU上高效地并行执行大量的计算任务,并针对GPU特性进行了大量底层优化以加速自动微分过程。
-
检查点技术: 在处理大型模型时,可以通过torch.utils.checkpoint库实现计算图分割和临时结果的保存/恢复,只保留必要的中间结果,从而节省内存。
以上都是PyTorch在实际运行过程中用来提升性能、降低资源消耗的一些策略和技术。
相关文章:
函数的详细介绍)
PyTorch中tensor.backward()函数的详细介绍
backward() 函数是PyTorch框架中自动求梯度功能的一部分,它负责执行反向传播算法以计算模型参数的梯度。由于PyTorch的源代码相当复杂且深度嵌入在C底层实现中,这里将提供一个高层次的概念性解释,并说明其使用方式而非详细的源代码实现。 在P…...

Linux 驱动开发基础知识——内核对设备树的处理与使用(十)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...

编程笔记 html5cssjs 077 Javascript 关键字
编程笔记 html5&css&js 077 Javascript 关键字 一、关键字二、Javascript关键字注意 在计算机编程语言中,关键字(Keyword)是指那些被编程语言赋予特殊含义、具有预定义用途的保留字。这些词汇不能用作变量名、函数名或其他标识符&…...
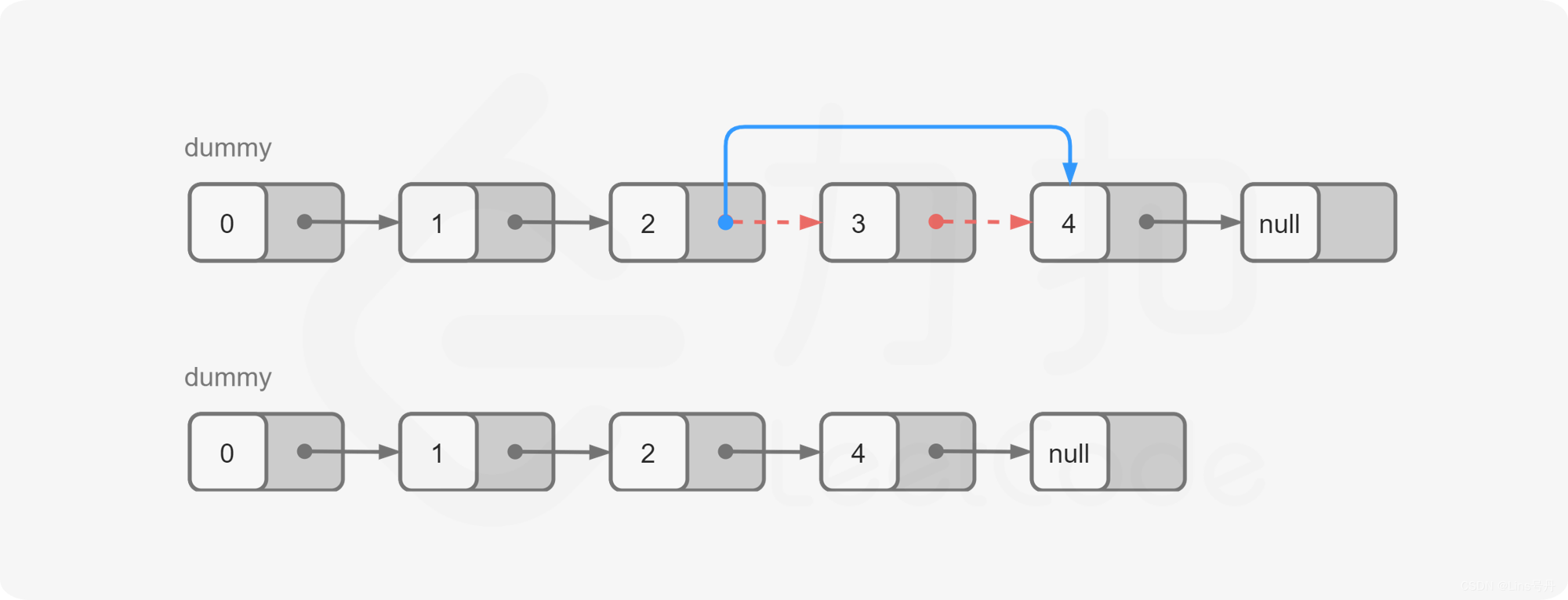
LeetCode_19_中等_删除链表的倒数第N个结点
文章目录 1. 题目2. 思路及代码实现(Python)2.1 计算链表长度2.2 栈 1. 题目 给你一个链表,删除链表的倒数第 n n n 个结点,并且返回链表的头结点。 示例 1: 输入: h e a d [ 1 , 2 , 3 , 4 , 5 ] , n…...

C++泛编程(3)
类模板基础 1.类模板的基本概念2.类模板的分文件编写3.类模板的嵌套 (未完待续...) 在往节内容中,我们详细介绍了函数模板,这节开始我们就来聊一聊类模板。C中,类的细节远比函数多,所以这个专题也会更复杂。…...
python基于django的公交线路查询系统mf383
1.个人信息的管理:对用户名,密码的增加、删除等 2.线路信息的管理:对线路的增加、修改、删除等 3.站点信息的管理:对站点的增加、修改、删除等 4.车次信息的管理:对车次的增加、修改、删除等 5.线路查询、站点查询 …...

ElementUI 组件:Container 布局容器实例
ElementUI安装与使用指南 Container 布局容器 点击下载learnelementuispringboot项目源码 效果图 el-container-example.vue(Container 布局容器实例)页面效果图 项目里el-container-example.vue代码 <script> export default {name: el_cont…...
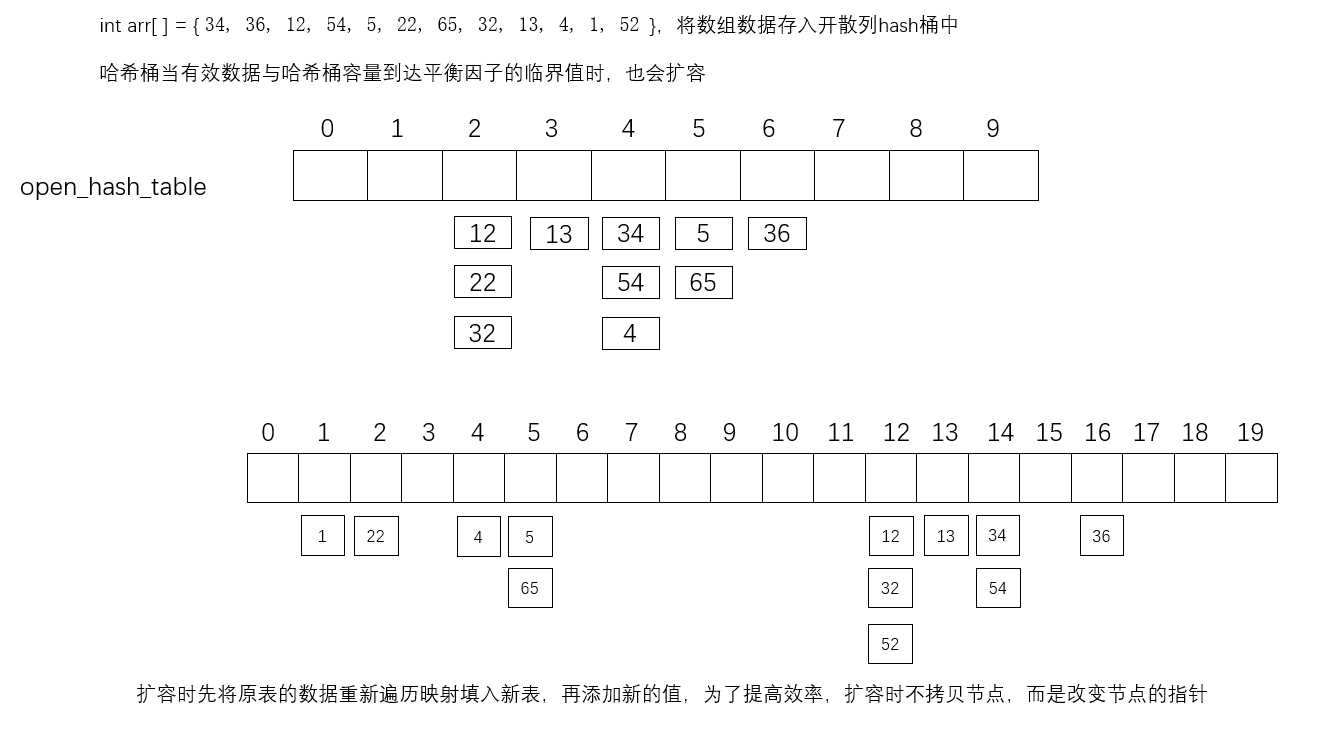
【数据结构 09】哈希
哈希算法:哈希也叫散列、映射,将任意长度的输入通过散列运算转化为固定长度的输出,该输出就是哈希值(散列值)。 哈希映射是一种压缩映射,通常情况下,散列值的空间远小于输入值的空间。 哈希运…...

理解和管理Linux文件权限
理解和管理Linux文件权限 文件权限的基本概念和表示方式 文件权限管理在Linux系统中是非常重要的,它决定了谁可以访问、读取、写入或执行文件。文件权限以及所有者、所属组等属性可以通过 ls -l 命令查看。 在 ls -l 命令的输出中,文件的权限通常表示…...

爬虫(二)
1.同步获取短视频 1.只要播放地址对Json数据解析,先把列表找出: 2.只想要所有的播放地址,通过列表表达式循环遍历这个列表拿到每个对象,再从一个个对象里面找到Video,再从Video里面找到播放地址(play_addr),再从播放地址找到播放…...
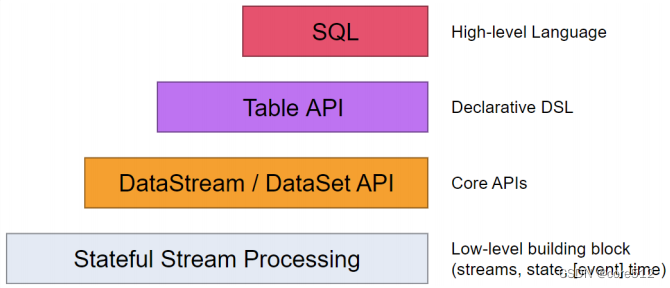
Flink实战四_TableAPISQL
接上文:Flink实战三_时间语义 1、Table API和SQL是什么? 接下来理解下Flink的整个客户端API体系,Flink为流式/批量处理应用程序提供了不同级别的抽象: 这四层API是一个依次向上支撑的关系。 Flink API 最底层的抽象就是有状态实…...

海外云手机开辟企业跨境电商新道路
近几年,海外云手机为跨境电商、海外媒体引流、游戏行业等互联网领域注入了蓬勃活力。对于国内跨境电商而言,在亚马逊及其他平台上,短视频引流和社交电商营销成为最为有效的流量来源。如何通过海外云手机的助力,在新兴社交平台为企…...
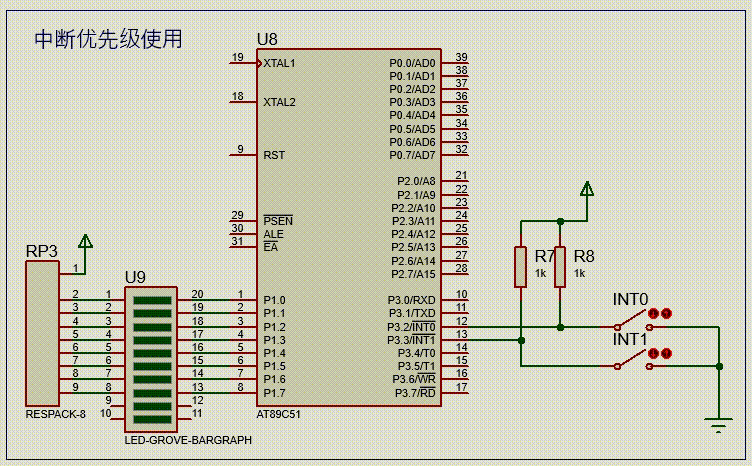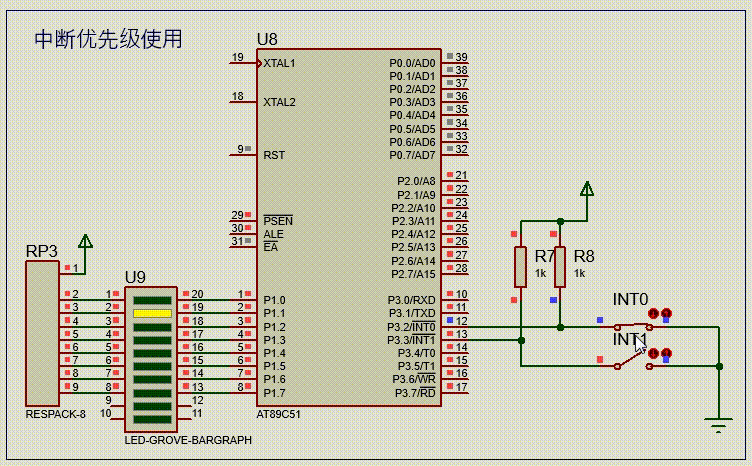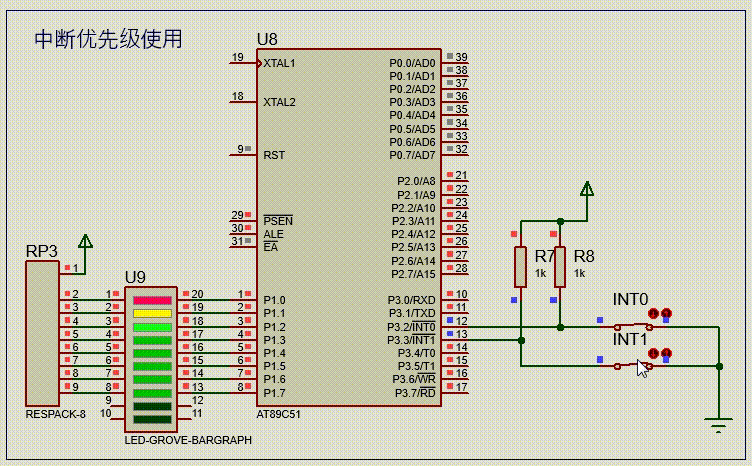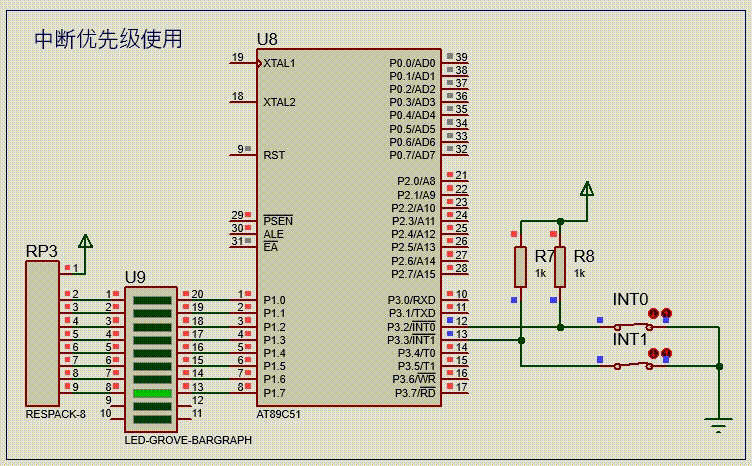
【51单片机系列】中断优先级介绍及使用
文章来源:《51单片机原理及应用(第3版)》5.4节。 51单片机采用了自然优先级和人工设置高、低优先级的策略。 当CPU处理低优先级中断,又发生更高级中断时,此时中断处理过程如下图所示。 一个正在执行的低优先级中断服…...
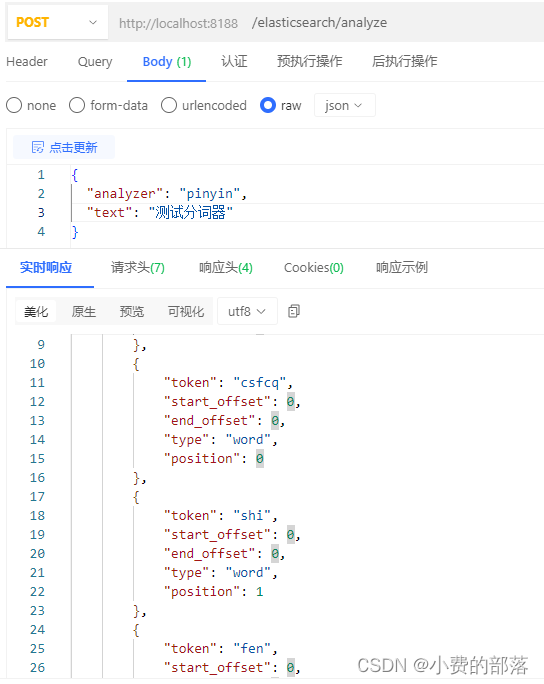
.net core 6 集成 elasticsearch 并 使用分词器
1、nuget包安装NEST、安装elasticsearch、kibana、ik分词器、拼音分词器 2、创建操作对象 //索引库 static string indexName "testparticper"; //es 操作对象 ElasticClient elasticClient new ElasticClient(new ConnectionSettings(new Uri("http://192.…...

Unity项目从built-in升级到URP(包含早期版本和2023版本)
unity不同版本的升级URP的方式不一样,但是大体流程是相似的 首先是加载URP包 Windows -> package manager,在unity registry中找到Universal RP 2023版本: 更早的版本: 创建URP资源和渲染器 有些版本在加载时会自动创建&#…...
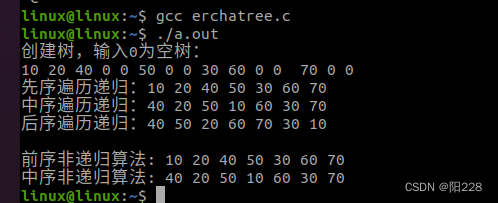
2月4号作业
编写程序实现二叉树的创建,三种遍历自己销毁 #include <myhead.h>#define TRUE 1 #define FALSE 0 #define OVERFLOW -2 #define OK 1 #define ERROR 0#define INIT_SIZE 20 #define INCREMENT_SIZE 5typedef int Status; typedef int TElemType; //存储结构…...

瑞_23种设计模式_建造者模式
文章目录 1 建造者模式(Builder Pattern)1.1 介绍1.2 概述1.3 创作者模式的结构 2 案例一2.1 需求2.2 代码实现 3 案例二3.1 需求3.2 代码实现 4 模式拓展 ★★★4.1 重构前4.2 重构后 5 总结5.1 建造者模式优缺点5.2 建造者模式使用场景5.3 建造者模式 …...

GA/T 1707-2019 防爆安全门检测
防爆安全门是指能抵抗爆炸冲击波作用的特种防护门,根据防爆门的防爆性能的不同,分为非接触爆炸防爆门和防接触爆炸防爆门,根据防爆能力的不同,分为不同等级。 GA/T 1707-2019 防爆安全门检测项目 测试项目 测试标准 外观质量 …...

k8s学习-数据管理
在Docker中我们知道,要想实现数据的持久化(所谓Docker的数据持久化即数据不随着Container的结束而结束),需要将数据从宿主机挂载到容器中,常用的手段就是Volume数据卷。在K8S中,也提供了存储模型Volume&…...
java hutool工具类实现将数据下载到excel
通过hutool工具类,对于excel的操作变得非常简单,上篇介绍的是excel的上传,对excel的操作,核心代码只有一行。本篇的excel的下载,核心数据也不超过两行,简洁方便,特别适合当下的低代码操作。 下载…...

Matlab仿真研究:三机并联风光混合储能并网系统的建模与控制策略实现
Matlab仿真三机并联风光混合储能并网系统,风光储并网,微电网系统,光伏电池模型,永磁同步风机,电压电流控制,PQ控制 波形正确,结构完整有参考文献,详情见图片 三机并联风光混合储能并…...
)
告别OBS!用JavaCV+FFmpeg在Windows上搭建个人直播推流服务器(含Nginx配置)
用JavaCVFFmpeg构建Windows直播推流服务器的全栈指南 直播技术正在从专业领域向个人开发者渗透,但传统方案如OBS往往过于笨重且缺乏定制性。本文将带你用JavaCVFFmpegNginx搭建一套轻量级直播推流服务器,实现从视频采集、编码推流到服务端分发的完整链路…...

2026届毕业生推荐的AI学术工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于毕业论文写作进程里,人工智能工具可充作辅助方式用以提高效率。学生能借AI开展…...
注解基础(Annotation))
JAVA重点基础、进阶知识及易错点总结(34)注解基础(Annotation)
🚀 Java 巩固进阶 第 34 天 主题:注解基础(Annotation)—— 代码的"元数据"标签📅 进度概览:继设计模式之后,今天学习 Java 注解体系。注解是"代码的标签",是 …...

预算有限AI率还有80%,性价比最高的降AI方案
AI率80%,但预算只有100-200元,怎么处理? 这是一个真实存在的困境。不同工具的定价差异很大,预算不够时怎么取舍,怎么用最少的钱解决问题? 这篇文章给出不同预算下的最优方案。 先了解各工具定价 工具定…...

Unity WebGL小游戏上抖音,从踩坑到上线:一份避坑指南与性能优化清单
Unity WebGL小游戏上抖音:性能优化与避坑实战手册 当你第一次将Unity WebGL小游戏发布到抖音平台时,可能会遇到各种意想不到的性能瓶颈和兼容性问题。iOS设备上的内存限制、WebGL与Native的性能差距、包体大小控制等挑战,都可能让原本流畅的游…...
)
ESP32自动登录校园网实战:绕过网页认证,实现设备永久在线(附完整Arduino代码)
ESP32校园网自动登录全攻略:从逆向分析到模块化封装 校园网环境下的IoT设备部署常面临一个棘手问题——每次断电重启后都需要手动登录网页认证系统。想象一下凌晨三点实验室的温湿度监测系统突然掉线,而你不得不顶着寒风跑去教学楼重新登录的场景。本文将…...
板卡Remote-SSH运行Antigravity AI崩溃(SIGILL):Samba网络盘本地挂载方案)
解决RDK X5(ARM64架构)板卡Remote-SSH运行Antigravity AI崩溃(SIGILL):Samba网络盘本地挂载方案
一、前言最近在折腾 D-Robotics 的 RDK X5 板卡(搭载 Sunrise X5 芯片,ARM Cortex-A55 架构)。在尝试使用强大的 Antigravity IDE 通过 Remote-SSH 远程连接板卡进行开发时,遇到了一个极其头疼的问题:AI 侧边栏完全不可…...

如何用QtScrcpy突破手机操控局限?三大创新方案让多场景效率提升300%
如何用QtScrcpy突破手机操控局限?三大创新方案让多场景效率提升300% 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 手机屏幕太小导致操作失误?多设备管理切…...

ai辅助开发新体验:在快马平台生成复杂算法代码,赋能idea社区版项目
今天想和大家分享一个特别实用的开发体验:如何用AI辅助快速生成复杂算法代码,再无缝导入IDEA社区版进行调试优化。整个过程就像有个编程助手在身边,效率提升非常明显。 需求背景 最近在做一个需要动态计算数学表达式的项目,要求…...