【前端收藏】前端小作文-前端八股文知识总结(超万字超详细)持续更新
有了这个八股文不仅对你基础知识的巩固,不管你是几年老前端程序员,还是要去面试的,文章覆盖了前端常用及不常用的方方面面,都是前端日后能用上的,对你的前端知识有总结意义,看完后,懂的不懂的都感觉茅塞顿开,会有前端知识有质的提高。知识整理不易,请【收藏-点赞】
直接开始前端知识总结,从浅到深,包括了HTML,css总结,HTTP基础,javascript深入问题,Vue2 / Vue3,React知识点,ES6新功能特性。
HTML前端基础
1.1 html标签的类型(head, body,!Doctype) 他们的作用是什么
!DOCTYPE 标签
它是指示 web 浏览器关于页面使用哪个 HTML 版本进行编写的指令
head:
- 是所有头部元素的容器, 绝大多数头部标签的内容不会显示给读者
- 该标签下所包含的部分可加入的标签有 base, link, meta, script, style和title
body:
- 用于定义文档的主体, 包含了文档的所有内容
- 该标签支持 html 的全局属性和事件属性
1.2 h5新特性
- 新增选择器 document.querySelector、document.querySelectorAll
- 拖拽释放(Drag and drop) API
- 媒体播放的 video 和 audio
- 本地存储 localStorage 和 sessionStorage
- 离线应用 manifest
- 桌面通知 Notififications
- 语意化标签 article、footer、header、nav、section
- 增强表单控件 calendar、date、time、email、url、search
- 地理位置 Geolocation
- 多任务 webworker
- 全双工通信协议 websocket
- 历史管理 history
- 跨域资源共享(CORS) Access-Control-Allow-Origin
- 页面可见性改变事件 visibilitychange
- 跨窗口通信 PostMessage
- Form Data 对象
- 绘画 canvas
1.3 伪类和伪元素
伪类:用于已有元素处于某种状态时为其添加对应的样式,这个状态是根据用户行为而动态变化的
例如:当用户悬停在指定元素时,可以通过:hover来描述这个元素的状态,虽然它和一般css相似,可以为 已有元素添加样式,但是它只有处于DOM树无法描述的状态下才能为元素添加样式,所以称为伪类
伪元素:用于创建一些不在DOM树中的元素,并为其添加样式
1.4 html语义化132613673
| 标签名 | 页面主体内容 |
|---|---|
| h1~h6 | h1~h6,分级标题,<h1> 和 <title> 协调有利于搜索引擎优化 |
| ul li | 无序列表 |
| ol li | 有序列表 |
| header | 页眉通常包括网站标志、主导航、全站链接以及搜索框 |
| nav | 标记导航,仅对文档中重要的链接群使用 |
| main | 页面主要内容,一个页面只能使用一次。如果是web应用,则包围其主要功能 |
| article | 定义外部的内容,其中的内容独立于文档的其余部分 |
| section | 定义文档中的节(section、区段)。比如章节、页眉、页脚或文档中的其他部分 |
| aside | 定义其所处内容之外的内容。如侧栏、文章的一组链接、广告、友情链接、相关产品列表等 |
| footer | 页脚,只有当父级是body时,才是整个页面的页脚 |
| small | 呈现小号字体效果,指定细则,输入免责声明、注解、署名、版权 |
| strong | 和 em 标签一样,用于强调文本,但它强调的程度更强一些 |
| em | 将其中的文本表示为强调的内容,表现为斜体 |
| mark | 使用黄色突出显示部分文本 |
| figure | 规定独立的流内容(图像、图表、照片、代码等等)(默认有40px左右margin) |
| figcaption | 定义 figure 元素的标题,应该被置于 figure 元素的第一个或最后一个子元素的位置 |
| cite | 表示所包含的文本对某个参考文献的引用,比如书籍或者杂志的标题 |
| progress | 定义运行中的进度(进程) |
| address | 作者、相关人士或组织的联系信息(电子邮件地址、指向联系信息页的链接) |
| blockquoto | 定义块引用,块引用拥有它们自己的空间 |
| del、ins、code | 移除的内容、添加的内容、标记代码 |
语义化优点
- 易于用户阅读,样式丢失的时候能让页面呈现清晰的结构
- 有利于SEO,搜索引擎根据标签来确定上下文和各个关键字的权重
- 方便屏幕阅读器解析,如盲人阅读器根据语义渲染网页
- 有利于开发和维护,语义化更具可读性,代码更好维护,与CSS3关系更和谐
1.5 引入样式时,link和@import的区别?
- 链接样式时,link只能在HTML页面中引入外部样式
- 导入样式表时,@import 既可以在HTML页面中导入外部样式,也可以在css样式文件中导入外部css样式
1.6 介绍一下你对浏览器内核的理解
主要分成两部分:渲染引擎(Layout Engine或Rendering Engine)和js引擎
- 渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。
- js引擎:解析和执行JavaScript来实现网页的动态效果
1.7 常见的浏览器内核有哪些
- Trident( MSHTML ):IE MaxThon TT The World 360 搜狗浏览器
- Geckos:Netscape6及以上版本 FireFox Mozilla Suite/SeaMonkey
- Presto:Opera7及以上(Opera内核原为:Presto,现为:Blink)
- Webkit:Safari Chrome
1.8 label标签的作用是什么? 是怎么用的?
- label标签用来定义表单控件间的关系
- 当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件上
- label 中有两个属性是非常有用的, FOR和ACCESSKEY
- FOR属性功能:表示label标签要绑定的HTML元素,你点击这个标签的时候,所绑定的元素将获取焦点
1.9 title与h1的区别、b与strong的区别、i与em的区别?
- title属性没有明确意义,只表示标题;h1表示层次明确的标题,对页面信息的抓取也有很大的影响
- strong标明重点内容,语气加强含义;b是无意义的视觉表示
- em表示强调文本;i是斜体,是无意义的视觉表示
- 视觉样式标签:bius
- 语义样式标签:strong em ins del code
1.10 元素的alt和title有什么不同?
在alt和title同时设置的时候,alt作为图片的替代文字出现,title是图片的解释文字
1.11 浏览器页面有哪三层构成,分别是什么,作用是什么?
- 浏览器页面构成:结构层、表示层、行为层
- 分别是:HTML、CSS、JavaScript
- 作用:HTML实现页面结构,CSS完成页面的表现与风格,JavaScript实现一些客户端的功能与业务。
1.12 网页制作会用到的图片格式有哪些?
- Webp:WebP格式,谷歌(google)开发的一种旨在加快图片加载速度的图片格式。并能节省大量的服务器带宽资源和数据空间。Facebook Ebay等知名网站已经开始测试并使用WebP格式。
- Apng:是PNG的位图动画扩展,可以实现png格式的动态图片效果,有望代替GIF成为下一代动态图标准
1.13 viewport 所有属性?
- width :设置layout viewport的宽度,为一个正整数,或字符串’device-width’
- initial-scale:设置页面的初始缩放值,为一个数字,可以带小数
- minimum-scale:允许用户的最小缩放值,为一个数字,可以带小数
- maximum-scale:允许用户的最大缩放值,为一个数字,可以带小数
- height:设置layout viewport的高度,这个属性对我们并不重要,很少使用
- user-scalable:是否允许用户进行缩放,值为‘no’或者‘yes’
- 安卓中还支持:target-densitydpi,表示目标设备的密度等级,作用是决定css中的1px 代表多少物理像素
1.14 meta标签的name属性值?
name 属性主要用于描述网页,与之对应的属性值为content,content中的内容主要是便于搜索引擎机器人查找信息和分类信息用的
- Keywords(关键字)说明:keywords用来告诉搜索引擎你网页的关键字是什么。
- description(网站内容描述) 说明:description用来告诉搜索引擎你的网站主要内容。
- robots(机器人向导)说明:robots用来告诉搜索机器人哪些页面需要索引,哪些页面不需要索引。
1.15 a标签中 如何禁用href 跳转页面 或 定位链接?
- e.preventDefault();
- href="javascript:void(0);
1.16 video标签的几个属性方法
- src:视频的URL
- poster:视频封面,没有播放时显示的图片
- preload:预加载
- autoplay:自动播放
- loop:循环播放
- controls:浏览器自带的控制条
- width:视频宽度
- height:视频高度
1.17 块级元素、行内元素、行内块元素
块级元素:
特点:可设置宽高边距,占满整行,会自动换行
示例:div、 p、 h1 、h6、ol、ul、dl、table、address、blockquote、form
行内元素:
特点:无法设置宽高边距,不会占满整行,不会自动换行
示例:a、strong、b、em、i、del、s、ins、u、span
行内块元素:
特点:可设置宽高,占满整行,但不会自动换行
示例:img、input
1.18 web标准和w3c标准
web标准:分为结构、表现和行为
W3C标准:提出了更规范的要求
1、结构方面:标签字母要小写,标签要闭合,标签要正确嵌套
2、css和js方面:尽量使用外链写法,少用行内样式,属性名要见名知意
1.19 前端需要注意哪些SEO
1、合理的title、description、keywords:搜素时对这三项的权重逐个减少,title强调重点,重要关键词不要超过两次,而且要靠前,不同页面title要有所不同,description高度概括页面内容,长度合适,不过分堆砌关键词,不同页面description有所不同,keywords列出重要关键词即可
2、语义化的html代码,符合W3C标准
3、提高网站速度
4、重要HTML代码放前面
5、重要内容不要用js输出:爬虫不会执行js获取内容
6、少用 iframe:搜索引擎不会抓取 iframe 中的内容
7、非装饰性图片必须加 alt
1.20 canvas和svg的区别
| canvas | svg |
|---|---|
| 通过js绘制2D图形,按像素进行渲染,当位置发生改变会重新进行绘制 | 使用XML绘制的2D图形,可以为元素添加js处理器 |
| 依赖分辨率 | 不依赖分辨率 |
| 不支持事件处理器 | 支持事件处理器 |
| 弱的文本渲染能力 | 最适合带有哦大型渲染区域的应用程序(如谷歌地图) |
| 能以.png或.jpg格式保存结果图像 | 复杂度高会减慢渲染速度 |
| 最适合图像密集型游戏,其中的许多对象会被频繁重绘 | 不适合游戏应用 |
+++++++++++++++++性感的分隔线++++++++++++++++++++++++++
CSS知识
1.1 标准盒模型和IE盒模型两者的区别是什么?
概念
CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括: 外边距(margin) 、 边框(border) 、 内边距(padding) 、实际内容(content) 四个属性
设置盒子模型
box-sizing:content-box;(标准)
box-sizing:border-box;(IE)
区别
标准的(W3C)盒模型:元素的实际宽度等于设置的宽高 + border + padding (默认方式)
IE盒模型: 元素的实际宽度就等于设置的宽高,即使定义有 border 和 padding 也不会改变元素的实际宽度,即 ( Element width = width )
1.2 盒子塌陷是什么?
盒子塌陷
本应该在父盒子内部的元素跑到了外部。为什么会出现盒子塌陷?
当父元素没设置足够大小的时候,而子元素设置了浮动的属性,子元素就会跳出父元素的边界(脱离文档流),尤其是当父元素的高度为auto时,而父元素中又没有其它非浮动的可见元素时,父盒子的高度就会直接塌陷为零, 我们称这是CSS高度塌陷
解决塌陷的方法
- 设置宽高
- 设置BFC
- 清楚浮动
- 给父盒子添加border
- 给父盒子设置padding-top
1.3 继承相关
css的继承:就是给父级设置一些属性,子级继承了父级的该属性,这就是我们的css中的继承
常用无继承性的属性
display:规定元素应该生成的框的类型
常用无继承性的文本属性:
- vertical-align:垂直文本对齐
- text-decoration:规定添加到文本的装饰
- text-shadow:文本阴影效果
- white-space:空白符的处理
- unicode-bidi:设置文本的方向
- 盒子模型的属性:width、height、margin、padding、border
- 背景属性:background
- 定位属性:float、clear、position、top、right、bottom、left、min-width、min-height、max、width、max-height、overflow、clip、z-index
有继承性的属性
- font:字体系列属性
有继承性文本系列属性:
-
text-indent:文本缩进
-
text-align:文本水平对齐
-
line-height:行高
-
word-spacing:增加或减少单词间的空白(即字间隔)
-
letter-spacing:增加或减少字符间的空白(字符间距)
-
text-transform:控制文本大小写
-
direction:规定文本的书写方向
-
color:文本颜色 a元素除外
-
元素可见性:visibility
表格布局属性:caption-side、border-collapse、border-spacing、empty-cells、table-layout -
列表布局属性:list-style-type、list-style-image、list-style-position、list-style
-
生成内容属性:quotes
-
光标属性:cursor
1.4 行内元素可以设置padding,margin吗?
行内元素的margin左右有效,上下无效
行内元素的padding左右有效 ,但是由于设置padding上下不占页面空间,无法显示效果,所以无效
1.5 什么是边距重叠?什么情况下会发生边距重叠?如何解决边距重叠?
边距重叠:两个box如果都设置了边距,那么在垂直方向上,两个box的边距会发生重叠,以绝对值大的那个为最终结果显示在页面上
边距重叠分为两种:
- 同级关系的重叠:同级元素在垂直方向上外边距会出现重叠情况,最后外边距的大小取两者绝对值大的那个
- 父子关系的边距重叠:嵌套崩塌
父子关系,如果子元素设置了外边距,在没有把父元素变成BFC的情况下,父元素也会产生外边距。
给父元素添加overflow:hidden 这样父元素就变为 BFC,不会随子元素产生外边距。
1.6 BFC是什么?
文档有几种流
-
定位流
- 绝对定位方案,盒从常规流中被移除,不影响常规流的布局;
- 它的定位相对于它的包含块,相关CSS属性:top、bottom、left、right;
- 如果元素的属性position为absolute或fixed,它是绝对定位元素;
- 对于position: absolute,元素定位将相对于上级元素中最近的一个relative、fixed、
absolute,如果没有则相对于body;
-
浮动流
- 左浮动元素尽量靠左、靠上,右浮动同理
- 这导致常规流环绕在它的周边,除非设置 clear 属性
- 浮动元素不会影响块级元素的布局
- 但浮动元素会影响行内元素的布局,让其围绕在自己周围,撑大父级元素,从而间接影响块级元素布局
- 最高点不会超过当前行的最高点、它前面的浮动元素的最高点
- 不超过它的包含块,除非元素本身已经比包含块更宽
- 行内元素出现在左浮动元素的右边和右浮动元素的左边,左浮动元素的左边和右浮动元素的
- 右边是不会摆放浮动元素的
-
普通流
- 在常规流中,盒一个接着一个排列;
- 在块级格式化上下文里面, 它们竖着排列;
- 在行内格式化上下文里面, 它们横着排列;
- 当position为static或relative,并且float为none时会触发常规流;
- 对于静态定位(static positioning),position: static,盒的位置是常规流布局里的位置;
- 对于相对定位(relative positioning),position: relative,盒偏移位置由top、bottom、
left、right属性定义。即使有偏移,仍然保留原有的位置,其它常规流不能占用这个位置。
定义
BFC的基本概念–BFC就是“块级格式化上下文”的意思,也有译作“块级格式化范围”。
通俗的讲,就是一个特殊的块,内部有自己的布局方式,不受外边元素的影响。
布局规则
- 内部的 Box 会在垂直方向,一个接一个地放置
- 垂直方向上的距离由margin决定。(完整的说法是:属于同一个BFC的两个相邻Box的margin会发生重叠(塌陷),与方向无关。)
- 每个元素的左外边距与包含块的左边界相接触(从左向右),即使浮动元素也是如此。(这说明BFC中子元素不会超出他的包含块,而position为absolute的元素可以超出他的包含块边界)
- BFC的区域不会与float的元素区域重叠
- 计算BFC的高度时,浮动子元素也参与计算
- BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面元素,反之亦然
哪些元素会创建 BFC
- 根元素
- float 属性不为 none
- position 为 absolute 或 fixed
- display 为 inline-block, table-cell, table-caption, flex, inline-flex
- overflow 不为 visible
场景
-
清除元素内部浮动:只要把父元素设为BFC就可以清理子元素的浮动了,最常见的用法就是在父元素上设置overflow: hidden样式,对于IE6加上zoom:1就可以了。 计算BFC的高度时,自然也会检测浮动或者定位的盒子高度。
-
解决外边距合并问题(嵌套崩塌)
外边距合并的问题。
盒子垂直方向的距离由margin决定。属于同一个BFC的两个相邻盒子的margin会发生重叠
属于同一个BFC的两个相邻盒子的margin会发生重叠,那么我们创建不属于同一个BFC,就不会发生margin重叠了。 -
制作右侧自适应的盒子问题
普通流体元素BFC后,为了和浮动元素不产生任何交集,顺着浮动边缘形成自己的封闭上下文
1.7 块元素居中
- 我们可以利用margin:0 auto来实现元素的水平居中。
- 利用绝对定位,设置四个方向的值都为0,并将margin设置为auto,由于宽高固定,因此对应方向实现平分,可以实现水平和垂直方向上的居中。
- 利用绝对定位,先将元素的左上角通过top:50%和left:50%定位到页面的中心,然后再通过margin负值来调整元素的中心点到页面的中心。
- 利用绝对定位,先将元素的左上角通过top:50%和left:50%定位到页面的中心,然后再通过translate来调整元素的中心点到页面的中心。
- 使用flex布局,通过align-items:center和justify-content:center设置容器的垂直和水平方向上为居中对齐,然后它的子元素也可以实现垂直和水平的居中。
- 对于宽高不定的元素,后面两种方法,可以实现元素的垂直和水平的居中。
##1.8 CSS 优化、提高性能的方法有哪些?
加载性能:
- css压缩:将写好的css进行打包压缩,可以减小文件体积
- css单一样式:当需要下边距和左边距的时候,很多时候会选择使用margin-left:20px;margin-bottom:30px
- 减少使用@import,建议使用link,因为后者在页面加载时一起加载,前者是等待页面加载完成之后再进行加载
选择器性能:
-
关键选择器(key selector)。选择器的最后面的部分为关键选择器(即用来匹配目标元素的部分)。CSS选择符是从右到左进行匹配的。
-
当使用后代选择器的时候,浏览器会遍历所有子元素来确定是否是指定的元素等等
-
如果规则拥有ID选择器作为其关键选择器,则不要为规则增加标签。
-
过滤掉无关的规则(这样样式系统就不会浪费时间去匹配它们了)。
-
尽量少的去对标签进行选择,而是用class。
-
尽量少的去使用后代选择器,降低选择器的权重值。后
-
代选择器的开销是最高的,尽量将选择器的深度降到最低,最高不要超过三层,更多的使用类来关联每一个标签元素。
-
了解哪些属性是可以通过继承而来的,然后避免对这些属性重复指定规则。
渲染性能:
-
属性值为0时,不加单位。
-
可以省略小数点之前的0。
-
标准化各种浏览器前缀:带浏览器前缀的在前。标准属性在后。
-
选择器优化嵌套,尽量避免层级过深。
-
css雪碧图,同一页面相近部分的小图标,方便使用,减少页面的请求次数,但是同时图片本身会变大,使用时,优劣考虑清楚,再使用。
-
不滥用web字体。对于中文网站来说WebFonts可能很陌生,国外却很流行。web fonts通常体积庞大,而且一些浏览器在下载web fonts时会阻塞页面渲染损伤性能。
可维护性、健壮性:
-
将具有相同属性的样式抽离出来,整合并通过class在页面中进行使用,提高css的可维护性。
-
样式与内容分离:将css代码定义到外部css中
1.9 行内元素和块级元素什么区别,然后怎么相互转换
块级元素
-
总是从新的一行开始,即各个块级元素独占一行,默认垂直向下排列
-
高度、宽度、margin及padding都是可控的,设置有效,有边距效果
-
宽度没有设置时,默认为100%
-
块级元素中可以包含块级元素和行内元素
行内元素
-
和其他元素都在一行,即行内元素和其他行内元素都会在一条水平线上排列
-
高度、宽度是不可控的,设置无效,由内容决定
-
根据标签语义化的理念,行内元素最好只包含行内元素,不包含块级元素
转换
-
display:inline;转换为行内元素
-
display:block;转换为块状元素
-
display:inline-block;转换为行内块状元素
1.10 min-width/max-width 和 min-height/max-height 属性间的覆盖规则?
-
max-width 会覆盖 width,即使 width 是行内样式或者设置了 !important。
-
min-width 会覆盖 max-width,此规则发生在 min-width 和 max-width 冲突的时候;
1.11 浏览器是怎样解析CSS选择器的?
CSS选择器的解析是从右向左解析的
原因:
从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点),而从左向右的匹配规则的性能都浪
费在了失败的查找上面
1.12 width:auto 和 width:100%的区别
-
width:100%会使元素box的宽度等于父元素的contentbox的宽度
-
width:auto会使元素撑满整个父元素,margin、border、padding、content区域会自动分配水平空间。
1.13 display、position和float的相互关系?
-
首先我们判断display属性是否为none,如果为none,则position和float属性的值不影响元素最后的表现
-
然后判断position的值是否为absolute或者fixed,如果是,则float属性失效,并且display的值应该被 设置为table或者block,具体转换需要看初始转换值
-
如果position的值不为absolute或者fixed,则判断float属性的值是否为none,如果不是,则display 的值则按上面的规则转换。注意,如果position的值为relative并且float属性的值存在,则relative相对 于浮动后的最终位置定位
-
如果float的值为none,则判断元素是否为根元素,如果是根元素则display属性按照上面的规则转换,如果不是, 则保持指定的display属性值不变
总的来说,可以把它看作是一个类似优先级的机制,"position:absolute"和"position:fixed"优先级最高,有它存在 的时候,浮动不起作用,'display’的值也需要调整;其次,元素的’float’特性的值不是"none"的时候或者它是根元素 的时候,调整’display’的值;最后,非根元素,并且非浮动元素,并且非绝对定位的元素,'display’特性值同设置值。
1.14 IFC 是什么?
IFC指的是行级格式化上下文,它有这样的一些布局规则:
-
行级上下文内部的盒子会在水平方向,一个接一个地放置。
-
当一行不够的时候会自动切换到下一行。
-
行级上下文的高度由内部最高的内联盒子的高度决定
1.15 为什么不建议使用统配符初始化 css 样式
采用*{pading:0;margin:0;}这样的写法好处是写起来很简单,但是是通配符,需要把所有的标签都遍历一遍,当网站较大时, 样式比较多,这样写就大大的加强了网站运行的负载,会使网站加载的时候需要很长一段时间,因此一般大型的网站都有分层次的一 套初始化样式
出于性能的考虑,并不是所有标签都会有padding和margin,因此对常见的具有默认padding和margin的元素初始化即 可,并不需使用通配符*来初始化
1.16 CSS3 新特新
-
新增各种 CSS 选择器 :not§ 选择每个非p的元素; p:empty 选择每个没有任何子级的p元素(包括文本节点)
-
边框(Borders)
-
背景 background-clip(规定背景图的绘制区域),background-origin,background-size
-
线性渐变 (Linear Gradients) 向下/向上/向左/向右/对角方向
-
文本效果 阴影text-shadow,textwrap,word-break,word-wrap
-
2D 转换 transform:scale(0.85,0.90) | translate(0px,-30px) | skew(-9deg,0deg) |rotate() - 3D转换 perspective();transform是向元素应用 2D 或者 3D 转换
-
过渡 transition
-
动画
-
多列布局 (multi-column layout)
-
盒模型
-
flex 布局
-
多媒体查询 **定义两套css,当浏览器的尺寸变化时会采用不同的属性
1.17 position 跟 display、float 这些特性相互叠加后会怎么样?
-
display 属性规定元素应该生成的框的类型;position属性规定元素的定位类型;float属性是一种布局方式,定义元素在哪个方向浮动。
-
类似于优先级机制:position:absolute/fixed优先级最高,有他们在时,float不起作用,display值需要调整。float 或者absolute定位的元素,只能是块元素或表格。
1.18 什么是CSS 预处理器?为什么使用?
Less、Sass、Stylus,用来预编译Sass或less,增强了css代码的复用性,还有层级、mixin、变量、循环、函数等,具有很方便的UI组件模块化开发能力,极大的提高工作效率
为什么要使用?
-
可嵌套性
-
变量
-
Mixins(混合@mixin):可重用性高,可以注入任何东西
-
@extend:允许一个选择器继承另一个选择器
@function:函数功能,用户使用@function 可以去编写自己的函数
-
引用父元素&:在编译时,&将被替换成父选择符
-
计算功能
-
组合连接: #{} :变量连接字符串
-
循环语句:(很少用到)
-
if 语句:(很少用到)
1.19 浏览器是怎样解析的?
-
HTML 被 HTML 解析器解析成 DOM 树;2. CSS 被 CSS 解析器解析成 CSSOM 树;
-
结合 DOM 树和 CSSOM 树,生成一棵渲染树(Render Tree),这一过程称为 Attachment;
-
生成布局(flow),浏览器在屏幕上“画”出渲染树中的所有节点;
-
将布局绘制(paint)在屏幕上,显示出整个页面。
1.20 在网页中的应该使用奇数还是偶数的字体?为什么呢?
-
使用偶数字体
-
Windows 自带的点阵宋体(中易宋体)从 Vista 开始只提供 12、14、16 px 这三个大小的点阵,而 13、15、17 px时用的是小一号的点。(即每个字占的空间大了 1 px,但点阵没变),于是略显稀疏
1.21 元素竖向的百分比设定是相对于容器的高度吗?
当按百分比设定一个元素的宽度时,它是相对于父容器的宽度计算的,但是,对于一些表示竖向距离的属性,例如 padding-top , padding-bottom , margin-top , margin-bottom 等,当按百分比设定它们时,依据的也是父容器的宽度,而不是高度
1.22 怎么让谷歌支持小于12px的文字?
使用 scale
1.23 li 与 li 之间有看不见的空白间隔是什么原因引起的?有什么解决办法?
行框的排列会受到中间空白(回车空格)等的影响,因为空格也属于字符,这些空白也会被应用样式,占据空间,所以会有间隔,把字符大小设为0,就没有空格了
解决方法:
-
可以将代码全部写在一排
-
浮动li中float:left
-
在ul中用font-size:0(谷歌不支持);
-
可以将 ul{letter-spacing: -4px;};li{letter-spacing: normal;}
1.24 display:inline-block 什么时候会显示间隙?
-
有空格时候会有间隙 解决:除空格
-
margin正值的时候 解决:margin使用负值
-
使用font-size时候 解决:font-size:0、letter-spacing、word-spacing
1.25 png、jpg、gif 这些图片格式解释一下,分别什么时候用。有没有了解过webp?
-
png是便携式网络图片(Portable Network Graphics)是一种无损数据压缩位图文件格式.优点是:压缩比高,色彩好。 大多数地方都可以用。
-
jpg是一种针对相片使用的一种失真压缩方法,是一种破坏性的压缩,在色调及颜色平滑变化做的不错。在www上,被用来储存和传输照片的格式。
-
gif是一种位图文件格式,以8位色重现真色彩的图像。可以实现动画效果.
-
webp格式是谷歌在2010年推出的图片格式,压缩率只有jpg的2/3,大小比png小了45%。缺点是压缩的时间更久了,兼容性不好,目前谷歌和opera支持。
1.26 style 标签写在 body 后与 body前有什么区别?
页面加载自上而下 当然是先加载样式。 写在 body 标签后由于浏览器以逐行方式对HTML文档进行解析,当解析到写在尾部的样式表(外联或写在 style 标签)会导致浏览器停止之前的渲染,等待加载且解析样式表完成之后重新渲染,在windows的IE下可能会出现 FOUC 现象(即样式失效导致的页面闪烁问题)
1.27 ::before 和::after 中双冒号和单冒号有什么区别、作用?
区别
在css中伪类一直用:表示,如 :hover,:active等
伪元素在CSS1中已存在,当时语法使用 : 表示 ,如::before和:after
后来在CSS3中修订,伪元素用 ::表示,如 ::before 和 ::after,以此区分伪元素和伪类
由于低版本 IE 对双冒号不兼容,开发者为了兼容性各浏览器,继续使使用 :after 这种老语法表示伪元素
单冒号: CSS3表示伪类;双冒号::CSS3伪元素
作用:
::before 和::after 的主要作用是在元素内容前后加上指定内容
伪类与伪元素都是用于向选择器加特殊效果
伪类与伪元素的本质区别就是是否抽象创造了新元素
伪类只要不是互斥可以叠加使用
伪元素在一个选择器中只能出现一次,并且只能出现在末尾
伪类与伪元素优先级分别与类、标签优先级相同
1.28 CSS3新增伪类,以及伪元素?
CSS3 新增伪类
p:first-of-type 选择属于其父元素的首个
元素的每个
元素
p:last-of-type 选择属于其父元素的最后
元素的每个
元素
p:nth-child(n) 选择属于其父元素的第 n 个子元素的每个
元素
p:nth-last-child(n) 选择属于其父元素的倒数第 n 个子元素的每个
元素
p:nth-of-type(n) 选择属于其父元素第 n 个
元素的每个
元素
p:nth-last-of-type(n)
选择属于其父元素倒数第 n 个
元素的每个
元素
p:last-child 选择属于其父元素最后一个子元素的每个
元素
p:target
选择当前活动的
元素
:not§ 选择非
元素的每个元素
:enabled 控制表单控件的可用状态
:disabled 控制表单控件的禁用状态
:checked 单选框或复选框被选中
伪元素
-
::first-letter 将样式添加到文本的首字母
-
::first-line 将样式添加到文本的首行
:- :before 在某元素之前插入某些内容
- ::after 在某元素之后插入某些内容
1.29 未知高度元素垂直居中、垂直居中的实现方式有哪些?
- 绝对定位+css3 transform:translate(-50%,-50%)
.wrap{position:relative;
}
.child{position: absolute;top:50%;left:50%;-webkit-transform:translate(-50%,-50%);
}
css3 的flex布局.wrap{display:flex;justify-content:center;
}
.child{align-self:center;
}- table布局
<div class="wrap">
<div class="child">
<div>sadgsdgasgd</div>
</div>
</div>
<style>
.wrap{display:table;text-align:center;
}
.child{background:#ccc;display:table-cell;vertical-align:middle;
}
.child div{width:300px;height:150px;background:red;margin:0 auto;
}
</style>
1.30 图片垂直居中
- 使用flex实现图片垂直居中
<div class="flexbox"><img src="1.jpg" alt="">
</div>
<style>
.flexbox{width: 300px;height: 250px;background:#fff;display: flex;align-items:center}
.flexbox img{width: 100px;height: 100px;align-items: center;}
</style>
- 利用Display: table;实现img图片垂直居中
<div class="tablebox">
<div id="imgbox">
<img src="1.jpg" alt="">
</div></div>
<style>
.tablebox{width: 300px;height: 250px;background: #fff;display: table}
#imgbox{display: table-cell;vertical-align: middle;}
#imgbox img{width: 100px}
</style>
- 用绝对定位实现垂直居中
<div class="posdiv">
<img src="1.jpg" alt=""></div>
<style>
.posdiv{width: 300px;height: 250px;background: #fff;position: relative;
margin:0 auto}
.posdiv img{width: 100px;position: absolute;top: 50%;margin-top: -50px;}
</style>
1.31 文本元素居中
- 水平居中:text-align
- 垂直居中:line-height 和height设置一样
- 多行文本垂直居中
- 父级元素高度不固定(padding-top和padding-bottom)
- 父级元素高度固定 (vertical-align:middle +display:table-cell )
1.32 CSS实现一个等腰三角形
主要是通过把宽高设置成0,边框宽度设置宽一些,设置其中三个边透明,只留一个边显示
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>测试</title>
<style type="text/css">div {width:0px;height:0px;margin:100px auto;border-left:80px solid transparent;border-right:80px solid transparent;border-bottom:138.56px solid #A962CE; /*--三角形的高--*/}
</style>
</head>
<body>
<div>
</div>
</body>
</html>
1.33 画 0.5px 的直线
- 使用scale缩放
<style>
.hr.scale-half {height: 1px;transform: scaleY(0.5);
}
</style>
<p>1px + scaleY(0.5)</p>
<div class="hr scale-half"></div>
<!--
Chrome/Safari都变虚了,只有Firefox比较完美看起来是实的而且还很细,效果和直接设置0.5px一
样。所以通过transform: scale会导致Chrome变虚了,而粗细几乎没有变化。但是如果加上transformorigin: 50% 100%:
-->
.hr.scale-half {height: 1px;transform: scaleY(0.5);transform-origin: 50% 100%;
}
- 线性渐变linear-gradient
<style>
.hr.gradient {
height: 1px;
background: linear-gradient(0deg, #fff, #000);
}
</style>
<p>linear-gradient(0deg, #fff, #000)</p>
<div class="hr gradient"></div>
- boxshadow
<style>
.hr.boxshadow {height: 1px;background: none;box-shadow: 0 0.5px 0 #000;
}
</style>
<p>box-shadow: 0 0.5px 0 #000</p>
<div class="hr boxshadow"></div>
- viewport
<meta name="viewport" content="width=device-width,initial-sacle=0.5">
<!--
width=device-width表示将viewport视窗的宽度调整为设备的宽度,这个宽度通常是指物理上宽度
initial-sacle=0.5 缩放0.5
-->
1.34 移动端适配方案
- viewport 适配 :
缺点:边线问题,不同尺寸下,边线的粗细是不一样的(等比缩放后),全部元素都是等比缩放,实际显示效果可能不太好
<meta name="viewport" content="width=750,initial-scale=0.5">
<!--
initial-scale = 屏幕的宽度 / 设计稿的宽度
为了适配其他屏幕,需要动态的设置 initial-scale 的值
-->
<head>
<script>
const WIDTH = 750
const mobileAdapter = () => {
let scale = screen.width / WIDTH
let content = `width=${WIDTH}, initial-scale=${scale}, maximumscale=${scale}, minimum-scale=${scale}`
let meta = document.querySelector('meta[name=viewport]')
if (!meta) {
meta = document.createElement('meta')
meta.setAttribute('name', 'viewport')
document.head.appendChild(meta)
}
meta.setAttribute('content',content)
}
mobileAdapter()
window.onorientationchange = mobileAdapter //屏幕翻转时再次执行
</script>
</head>
vw 适配(部分等比缩放)
- 开发者拿到设计稿(假设设计稿尺寸为750px,设计稿的元素标注是基于此宽度标注)
- 开始开发,对设计稿的标注进行转换,把px换成vw。比如页面元素字体标注的大小是32px,换成vw为 (100/750)*32 vw
- 对于需要等比缩放的元素,CSS使用转换后的单位
- 对于不需要缩放的元素,比如边框阴影,使用固定单位px
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, maximumscale=1, minimum-scale=1">
<script>const WIDTH = 750//:root { --width: 0.133333 } 1像素等于多少 vwdocument.documentElement.style.setProperty('--width', (100 / WIDTH))
</script>
</head>
rem适配
弹性盒适配(合理布局)
1.35 link 和 @import 的区别
-
引入的内容不同
link 除了引用样式文件,还可以引用图片等资源文件,而 @import 只引用样式文件 -
加载顺序不同
link 引用 CSS 时,在页面载入时同时加载;@import 需要页面网页完全载入以后加载 -
兼容性不同
link 是 XHTML 标签,无兼容问题;@import 是在 CSS2.1 提出的,低版本的浏览器不支持 -
对 JS 的支持不同
link 支持使用 Javascript 控制 DOM 去改变样式;而 @import 不支持
1.36 iframe有什么优点、缺点?
优点:
- iframe能够原封不动的把嵌入的网页展现出来。
- 如果有多个网页引用iframe,那么你只需要修改iframe的内容,就可以实现调用的每一个页面内 容的更改,方便快捷。
- 网页如果为了统一风格,头部和版本都是一样的,就可以写成一个页面,用iframe来嵌套,可以 增加代码的可重用。
- 如果遇到加载缓慢的第三方内容如图标和广告,这些问题可以由iframe来解决。
缺点:
- iframe会阻塞主页面的onload事件;
- iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。会 产生很多页面,不容易管理。
- iframe框架结构有时会让人感到迷惑,如果框架个数多的话,可能会出现上下、左右滚动条,会 分散访问者的注意力,用户体验度差。
- 代码复杂,无法被一些搜索引擎索引到,这一点很关键,现在的搜索引擎爬虫还不能很好的处理 iframe中的内容,所以使用iframe会不利于搜索引擎优化(SEO)。
- 很多的移动设备无法完全显示框架,设备兼容性差。
- iframe框架页面会增加服务器的http请求,对于大型网站是不可取的。
+++++++++++++++++性感的分隔线++++++++++++++++++++++++++
JavaScript知识
1. Promise 的理解
Promise 是一种为了避免回调地狱的异步解决方案 2. Promise 是一种状态机: pending(进行中)、fulfilled(已成功)和rejected(已失败) 只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。
回调函数中嵌套回调函数的情况就叫做回调。
回调地狱就是为是实现代码顺序执行而出现的一种操作,它会造成我们的代码可读性非常差,后期不好维护。
Promise是什么?**
Promise是最早由社区提出和实现的一种解决异步编程的方案,比其他传统的解决方案(回调函数和事件)更合理和更强大。
ES6 将其写进了语言标准,统一了用法,原生提供了Promise对象。
ES6 规定,Promise对象是一个构造函数,用来生成Promise实例。
Promise是为解决什么问题而产生的?**
promise是为解决异步处理回调金字塔问题而产生的
Promise的两个特点**
1、Promise对象的状态不受外界影响
1)pending 初始状态
2)fulfilled 成功状态
3)rejected 失败状态
Promise 有以上三种状态,只有异步操作的结果可以决定当前是哪一种状态,其他任何操作都无法改变这个状态
2、Promise的状态一旦改变,就不会再变,任何时候都可以得到这个结果,状态不可以逆,只能由 pending变成fulfilled或者由pending变成rejected
Promise的三个缺点
- 无法取消Promise,一旦新建它就会立即执行,无法中途取消
- 如果不设置回调函数,Promise内部抛出的错误,不会反映到外部
- 当处于pending状态时,无法得知目前进展到哪一个阶段,是刚刚开始还是即将完成
Promise在哪存放成功回调序列和失败回调序列?
- onResolvedCallbacks 成功后要执行的回调序列 是一个数组
- onRejectedCallbacks 失败后要执行的回调序列 是一个数组
以上两个数组存放在Promise 创建实例时给Promise这个类传的函数中,默认都是空数组。
每次实例then的时候 传入 onFulfilled 成功回调 onRejected 失败回调,如果此时的状态是pending 则将onFulfilled和onRejected push到对应的成功回调序列数组和失败回调序列数组中,如果此时的状态是fulfilled 则onFulfilled立即执行,如果此时的状态是rejected则onRejected立即执行
上述序列中的回调函数执行的时候 是有顺序的,即按照顺序依次执行
2. 箭头函数和普通函数的区别
箭头函数与普通函数的区别在于: 1、箭头函数没有this,所以需要通过查找作用域链来确定this的值,这就意味着如果箭头函数被非箭头函数包含,this绑定的就是最近一层非箭头函数的this, 2、箭头函数没有自己的arguments对象,但是可以访问外围函数的arguments对象 3、不能通过new关键字调用,同样也没有new.target值和原型
- 语法更加简洁、清晰
- 箭头函数不会创建自己的this,它只会从自己的作用域链的上一层继承this。
- 箭头函数继承而来的this指向永远不变
- .call()/.apply()/.bind()无法改变箭头函数中this的指向
- 箭头函数不能作为构造函数使用
- 箭头函数没有自己的arguments,可以在箭头函数中使用rest参数代替arguments对象,来访问箭头函数的参数列表
- 箭头函数没有原型prototype
- 箭头函数不能用作Generator函数,不能使用yeild关键字
- 箭头函数不具有super,不具有new.target
3. ES6新特性
1、let( let 允许创建块级作用域(最靠近的一个花括号内有效),不具备变量提升,不允许重复声明: )、const( const 允许创建块级作用域(最靠近的一个花括号内有效)、变量声明不提升、const 在声明时必须被赋值、声明时大写变量(默认规则): )、block作用域
2、箭头函数 ES6 中,箭头函数就是函数的一种简写形式,使用括号包裹参数,跟随一个 =>,紧接着是函数体:
3、函数默认参数值
ES6 中允许你对函数参数设置默认值:
4、对象超类
ES6 允许在对象中使用 super 方法:
5、Map VS WeakMap
ES6 中两种新的数据结构集:Map 和 WeakMap。事实上每个对象都可以看作是一个 Map。
一个对象由多个 key-val 对构成,在 Map 中,任何类型都可以作为对象的 key,如:
6、类
ES6 中有 class 语法。值得注意是,这里的 class 不是新的对象继承模型,它只是原型链的语法糖表现形式。
函数中使用 static 关键词定义构造函数的的方法和属性:
4. var let const 的区别
共同点:都能声明变量
不同点:var 在ECMAScript 的所有版本中都可以使用,而const和let只能在ECMAScript6【ES2015】及更晚中使用
| 特点 | var | let | const |
|---|---|---|---|
| 作用域 | 函数作用域 | 块作用域 | 块作用域 |
| 声明提升 | 能 | 不能 | 不能 |
| 重复声明 | 能 | 不能 | 不能 |
| 全局声明时为window对象的属性 | 是 | 不是 | 不是 |
- ECMAScript6 增加了
let和const之后要尽可能少使用var。因为let和const申明的变量有了更加明确的作用域、声明位置以及不变的值。 - 优先使用const来声明变量,只在提前知道未来会修改时,再使用let。
- 因为let作用域为块作用域!!!!【得要时刻记住这一点】
不能进行条件式声明 - 声明时得直接初始化变量,且不能修改const声明的变量的值
- 该限制只适用于它指向的变量的引用,如果它一个对象的,则可以修改这个对象的内部的属性。
Null 和 undefined 的区别
undefined和null的区别:.
undefined表示一个变量没有被声明,或者被声明了但没有被赋值(未初始化),一个没有传入实参的形参变量的值为undefined,如果一个函数什么都不返回,则该函数默认返回undefined。null则表示"什么都没有",即"空值"。.- Javascript将未赋值的变量默认值设为
undefined; - Javascript从来不会将变量设为
null。它是用来让程序员表明某个用var声明的变量时没有值的
Call、bind、apply方法的区别
-
apply方法- apply接受两个参数,第一个参数是this的指向,第二个参数是函数接受的参数,以数组的形式传入,且当第一个参数为null、undefined的时候,默认指向window(在浏览器中),使用apply方法改变this指向后原函数会立即执行,且此方法只是临时改变this指向一次。
-
call方法 - call方法的第一个参数也是this的指向,后面传入的是一个参数列表(注意和apply传参的区别)。当一个参数为null或undefined的时候,表示指向window(在浏览器中),和apply一样,call也只是临时改变一次this指向,并立即执行。
-
bind方法 - bind方法和call很相似,第一参数也是this的指向,后面传入的也是一个参数列表(但是这个参数列表可以分多次传入,call则必须一次性传入所有参数),但是它改变this指向后不会立即执行,而是返回一个永久改变this指向的函数。
防抖和节流
防抖(debounce)
所谓防抖,就是指触发事件后在 n 秒内函数只能执行一次,如果在 n 秒内又触发了事件,则会重新计算函数执行时间。
非立即执行版的意思是触发事件后函数不会立即执行,而是在 n 秒后执行,如果在 n 秒内又触发了事件,则会重新计算函数执行时间。
立即执行版的意思是触发事件后函数会立即执行,然后 n 秒内不触发事件才能继续执行函数的效果。
节流(throttle)
**所谓节流,就是指连续触发事件但是在 n 秒中只执行一次函数。**节流会稀释函数的执行频率。
对于节流,一般有两种方式可以实现,分别是时间戳版和定时器版
数组方法
数组原型方法主要有以下这些:
- join():用指定的分隔符将数组每一项拼接为字符串
- push():向数组的末尾添加新元素
- pop():删除数组的最后一项
- unshift():向数组首位添加新元素
- shift():删除数组的第一项
- slice():按照条件查找出其中的部分元素
- splice():对数组进行增删改
- filter():过滤功能
- concat():用于连接两个或多个数组
- indexOf():检测当前值在数组中第一次出现的位置索引
- lastIndexOf():检测当前值在数组中最后一次出现的位置索引
- every():判断数组中每一项都是否满足条件
- some():判断数组中是否存在满足条件的项
- includes():判断一个数组是否包含一个指定的值
- sort():对数组的元素进行排序
- reverse():对数组进行倒序
- forEach():es5及以下循环遍历数组每一项
- map():es6循环遍历数组每一项
- find():返回匹配的项
- findIndex():返回匹配位置的索引
- reduce():从数组的第一项开始遍历到最后一项,返回一个最终的值
- reduceRight():从数组的最后一项开始遍历到第一项,返回一个最终的值
- toLocaleString()、toString():将数组转换为字符串
- entries()、keys()、values():遍历数组
各个方法的基本功能详解
1、join()
join()方法用于把数组中的所有元素转换一个字符串,默认使用逗号作为分隔符
var arr1 = [1,2,3];
console.log(arr1.join()); // 1,2,3
console.log(arr.join('-')); // 1-2-3
console.log(arr); // [1,2,3](原数组不变)
2、push()和pop()
push()方法从数组末尾向数组添加元素,可以添加一个或多个元素,并返回新的长度
pop()方法用于删除数组的最后一个元素并返回删除的元素
var arr1 = ['lily','lucy','Tom'];
var count = arr1.push('Jack','Sean');
console.log(count); // 5
console.log(arr1); // ['lily','lucy','Tom','Jack','Sean']var item = arr1.pop();
console.log(item); // Sean
console.log(arr1); // ['lily','lucy','Tom','Jack']
3、unshift()和shift()
unshift()方法可向数组的开头添加一个或更多元素,并返回新的长度
shift()方法用于把数组的第一个元素从其中删除,并返回第一个元素的值
var arr1 = ['lily','lucy','Tom'];
var count = arr1.unshift('Jack','Sean');
console.log(count); // 5
console.log(arr1); // ['Jack','Sean','lily','lucy','Tom']var item = arr1.shift();
console.log(item); // Jack
console.log(arr1); // [''Sean','lily','lucy','Tom']
4、sort()
用于对数组的元素进行排序。
默认情况下是将数组元素转换成字符串,然后按照ASC码进行排序
排序顺序可以是字母或数字,并按升序或降序,默认排序顺序为按字母升序
arrayObject.sort(sortby);参数sortby可选。规定排序顺序,必须是函数。
var arr1 = ['a','d','c','b'];
console.log(arr1.sort()); // ['a','b','c','d'] 排序了let arr = [23,12,1,34,116,8,18,37,56,50]
a.sort()
console.log(a) // [1, 116, 12, 18, 23, 34, 37, 50, 56, 8] 没有排序function compare(value1,value2){if(value1 < value2){return -1;}else if(value1 > value2){return 1;}else{return 0;}
}var arr2 = [13,24,51,3];
console.log(arr2.sort(compare)); // [3,13,24,51]// 如果需要通过比较函数产生降序排序的结果,只要交后比较函数返回的值即可// arr2的可以简化
var arr2 = [13,24,51,3];
console.log(arr2.sort((a, b) => (a - b))); // [3,13,24,51]
5、reverse()
用于颠倒数组中元素的顺序,原数组改变
var arr1 = [13,24,51,3];
console.log(arr1.reverse()); // [3,51,24,13]
console.log(arr1); // [3,51,24,13](原数组改变)
6、concat()
用于连接两个或多个数组,该方法不会改变现有的数组,而仅仅会返回被连接数组的一个副本
var arr1 = [1,3,5,7];
var arrCopy = arr1.concat(9,[11,13]);
console.log(arrCopy); // [1,3,5,7,9,11,13]
console.log(arr1); // [1,3,5,7](原数组未被修改)
7、slice()
返回从原数组中指定开始下标到结束下标之间的项组成的新数组,可以接受一或两个参数,即要返回项的起始和结束位置(不包括结束位置的项)
用法:array.slice(start,end)
解释:该方法是对数组进行部分截取,并返回一个数组副本;参数start是截取的开始数组索引,end参数等于你要取的最后一个字符的位置值加上1(可选)
var arr1 = [1,3,5,7,9,11];
var arrCopy = arr1.slice(1);
var arrCopy2 = arr1.slice(1,4);
var arrCopy3 = arr1.slice(1,-2); // 相当于arr1.slice(1,4);
var arrCopy4 = arr1.slice(-4,-1); // 相当于arr1.slice(2,5);
console.log(arr1); // [1,3,5,7,9,11](原数组没变)
console.log(arrCopy); // [3,5,7,9,11]
console.log(arrCopy2); // [3,5,7]
console.log(arrCopy3); // [3,5,7]
console.log(arrCopy4); // [5,7,9]//如果不传入参数二,那么将从参数一的索引位置开始截取,一直到数组尾
var a=[1,2,3,4,5,6];
var b=a.slice(0,3); //[1,2,3]
var c=a.slice(3); //[4,5,6]//如果两个参数中的任何一个是负数,array.length会和它们相加,试图让它们成为非负数,举例说明:
//当只传入一个参数,且是负数时,length会与参数相加,然后再截取
var a=[1,2,3,4,5,6];
var b=a.slice(-1); //[6]//当只传入一个参数,是负数时,并且参数的绝对值大于数组length时,会截取整个数组
var a=[1,2,3,4,5,6];
var b=a.slice(-6); //[1,2,3,4,5,6]
var c=a.slice(-8); //[1,2,3,4,5,6]//当传入两个参数一正一负时,length也会先于负数相加后,再截取
var a=[1,2,3,4,5,6];
var b=a.slice(2,-3); //[3]//当传入一个参数,大于length时,将返回一个空数组
var a=[1,2,3,4,5,6];
var b=a.slice(6); //[]
8、splice()
可以实现删除、插入和替换
用法:array.splice(start,deleteCount,item…)
解释:splice方法从array中移除一个或多个数组,并用新的item替换它们。参数start是从数组array中移除元素的开始位置。参数deleteCount是要移除的元素的个数。
如果有额外的参数,那么item会插入到被移除元素的位置上。它返回一个包含被移除元素的数组。
//替换
var a=['a','b','c'];
var b=a.splice(1,1,'e','f'); //a=['a','e','f','c'],b=['b']//删除
var arr1 = [1,3,5,7,9,11];
var arrRemoved = arr1.splice(0,2);
console.log(arr1); // [5,7,9,11]
console.log(arrRemoved); // [1,3]// 添加元素
var arr1 = [22,3,31,12];
arr1.splice(1,0,12,35);
console.log(arr1); // [22,12,35,3,31,12]9、forEach()
forEach方法中的function回调有三个参数:第一个参数是遍历的数组内容,第二个参数是对应的数组索引,第三个参数是数组本身
var arr = [1,2,3,4];
var sum =0;
arr.forEach(function(value,index,array){array[index] == value; //结果为truesum+=value; });
console.log(sum); //结果为 10
10、map()
返回一个新数组,会按照原始数组元素顺序依次处理元素
let array = [1, 2, 3, 4, 5];
let newArray = array.map((item) => {return item * item;
})
console.log(newArray) // [1, 4, 9, 16, 25]
11、every()
判断数组中每一项都是否满足条件,只有所有项都满足条件,才会返回true
var arr1 = [1,2,3,4,5];
var arr2 = arr1.every(x => {return x < 10;
});
console.log(arr2); // truevar arr3 = arr1.every(x => {return x < 3;
});
console.log(arr3); // false
12、some()
判断数组中是否存在满足条件的项,只要有一项满足条件,就会返回true
var arr1 = [1,2,3,4,5];
var arr2 = arr1.some(x => {return x < 3;
});
console.log(arr2); // true
var arr3 = arr1.some(x => {return x < 1;
});
console.log(arr3); // false
13、reduce()和reduceRight()
都会实现迭代数组的所有项(即累加器),然后构建一个最终返回的值,reduce()方法从数组的第一项开始,逐个遍历到最后,reduceRight()方法从数组的最后一项开始。向前遍历到第一项 4个参数:前一个值、当前值、项的索引和数组对象
var arr1 = [1,2,3,4,5];
var sum = arr1.reduce((prev,cur,index,array) => {return prev + cur;
},10); // 数组一开始加了一个初始值10,可以不设默认0
console.log(sum); // 25
14、toLocaleString()和toString()
都是将数组转换为字符串
var arr1 = [22,3,31,12];
let str = arr1.toLocaleString();
var str2 = arr1.toString();console.log(str); // 22,3,31,12
console.log(str2); // 22,3,31,12
15、find()和findIndex()
都接受两个参数:一个回调函数,一个可选值用于指定回调函数内部的this
该回调函数可接受3个参数:数组的某个元素、该元素对应的索引位置、数组本身,在回调函数第一次返回true时停止查找。
二者的区别是:find()方法返回匹配的值,而findIndex()方法返回匹配位置的索引
let arr = [1,2,3,4,5];
let num = arr.find(item => item > 1);
console.log(num) // 2let arr = [1,2,3,4,5];
let num = arr.findIndex(item => item > 1);
console.log(num) // 1
16、entries()、keys()和values()
es6新增entries()、keys()和values()–用于遍历数组。它们都返回一个遍历器对象,可以用for…of循环进行遍历
区别是keys()是对键名的遍历、values()是对键值的遍历、entries()是对键值对的遍历
for(let index of [a,b].keys()){console.log(index);
}
// 0
// 1for(let elem of [a,b].values()){console.log(elem);
}
// a
// bfor(let [index,elem] of [a,b].entries()){console.log(index,elem);
}
// 0 'a'
// 1 'b'
17、indexOf()
indexof方法可以在字符串和数组上使用。
indexOf() 方法可返回某个指定的字符串值(基本数据类型)在字符串、数组中首次出现的位置。
arr = ['mfg', '2017', '2016'];console.log(arr.indexOf('mfg')); // 0console.log(arr.indexOf('m')); // -1console.log(arr.indexOf('2017'));// 1console.log(arr.indexOf(2017)); // -1,这里不会做隐式类型转换const arr = ['111', '222', '333', 'NaN']console.log(arr.indexOf(NaN)) // -1
18、includes()
es7新增,用来判断一个数组、字符串是否包含一个指定的值(基本数据类型),使用===运算符来进行值比较,如果是返回true,否则false,参数有两个,第一个是(必填)需要查找的元素值,第二个是(可选)开始查找元素的位置
var arr1 = [22,3,31,12,58];
var includes = arr1.includes(31);
console.log(includes); // truevar includes2 = arr1.includes(31,3); // 从索引3开始查找31是否存在
console.log(includes2); // falsevar includes3 = arr1.includes(31,-1); // 从最后一个开始向后查找31是否存在
console.log(includes3); // falseconst arr = ['111', '222', '333', 'NaN']
console.log(arr.includes(NaN)) // true
console.log(arr.includes(111)) // false 不做隐式转换
Vue知识总结
##1.1 怎样理解 Vue 的单向数据流?
-
数据从父级组件传递给子组件,只能单向绑定
-
子组件内部不能直接修改从父级传递过来的数据
-
所有的 prop 都使得其父子 prop 之间形成了一个单向下行绑定:父级 prop 的更新会向下流动到子组件中,但是反过来则不行,这样会防止从子组件意外改变父级组件的状态, 从而导致你的应用的数据流向难以理解。
-
每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值,这意味着你不应该在一个子组件内部改变 prop。如果你这样做了,Vue 会在浏览器的控制台中发出警 告
-
子组件想修改时,只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件 修改
1.2 谈谈你对 Vue 生命周期的理解?
(1)生命周期是什么?
Vue 实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模版、挂载 Dom -> 渲染、更新 -> 渲染、卸载等一系列过程,我们称这是 Vue 的生命周期
(2)各个生命周期的作用
| beforeCreate | 组件实例被创建之初,组件的属性生效之前 |
|---|---|
| created | 组件实例已经完全创建,属性也绑定,但真实 dom 还没有生成,$el 还不可用 |
| beforeMount | 在挂载开始之前被调用:相关的 render 函数首次被调用 |
| mounted | el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子 |
| beforeUpdate | 组件数据更新之前调用,发生在虚拟 DOM 打补丁之前 |
| update | 组件数据更新之后 |
| activited | keep-alive 专属,组件被激活时调用 |
| deadctivated | keep-alive 专属,组件被销毁时调用 |
| beforeDestory | 组件销毁前调用 |
| destoryed | 组件销毁后调用 |
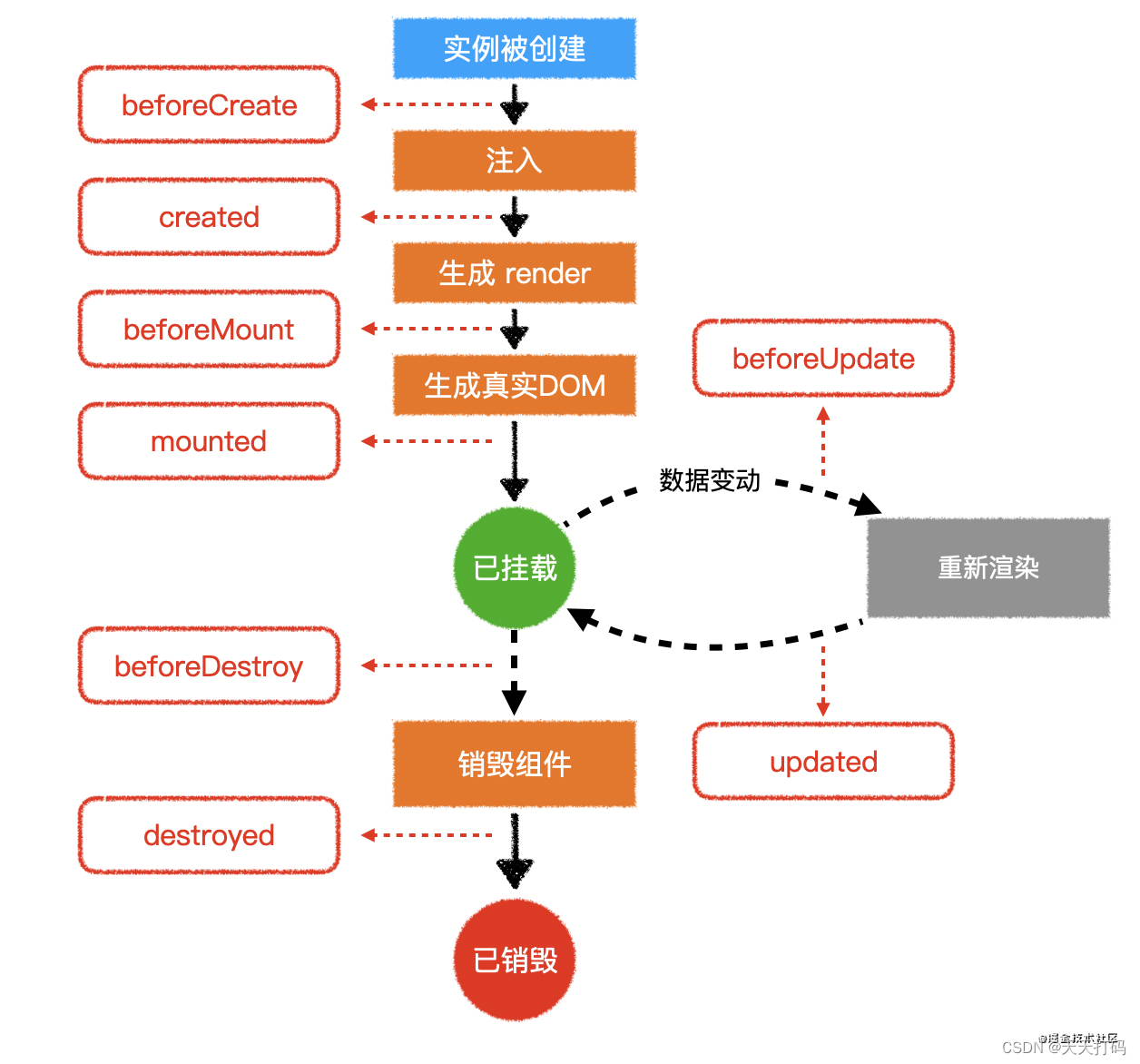
1.3 谈谈你对 keep-alive 的了解?
keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,避免重新渲染 ,其有以下特性:
一般结合路由和动态组件一起使用,用于缓存组件
提供 include 和 exclude 属性,两者都支持字符串或正则表达式, include 表示只有名称匹配的组件会被缓存,exclude 表示任何名称匹配的组件都不会被缓存 ,其中 exclude 的优先级比 include 高
对应两个钩子函数 activated 和 deactivated ,当组件被激活时,触发钩子函数 activated,当组件被移除时,触发钩子函数 deactivated
1.4 组件中 data 为什么是一个函数?
因为组件是用来复用的,且 JS 里对象是引用关系,如果组件中 data 是一个对象,那么这样作用域没有隔离,子组件中的 data 属性值会相互影响
如果组件中 data 选项是一个函数,那么每个实例可以维护一份被返回对象的独立的拷贝,组件实例之间的 data 属性值不会互相影响;而 new Vue 的实例,是不会被复用的,因此不存在引用对象的问题
1.5 你对vue项目哪些优化?
(1)代码层面的优化
-
v-if 和 v-show 区分使用场景
-
computed 和 watch 区分使用场景
-
v-for 遍历必须为 item 添加 key,且避免同时使用 v-if
-
长列表性能优化
-
事件的销毁
-
图片资源懒加载
-
路由懒加载
-
第三方插件的按需引入
-
优化无限列表性能
-
服务端渲染 SSR or 预渲染
(2)Webpack 层面的优化
-
Webpack 对图片进行压缩
-
减少 ES6 转为 ES5 的冗余代码
-
提取公共代码
-
模板预编译
-
提取组件的 CSS
-
优化 SourceMap
-
构建结果输出分析
-
Vue 项目的编译优化
(3)基础的 Web 技术的优化
-
开启 gzip 压缩
-
浏览器缓存
-
CDN 的使用
-
使用 Chrome Performance 查找性能瓶颈
1.6 vue中的key有什么作用?
key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
Vue 的 diff 过程可以概括为:oldCh 和 newCh 各有两个头尾的变量 oldStartIndex、oldEndIndex 和 newStartIndex、newEndIndex,它们会新节点和旧节点会进行两两对比,即一共有4种比较方式:newStartIndex 和oldStartIndex 、newEndIndex 和 oldEndIndex 、newStartIndex 和 oldEndIndex 、newEndIndex 和 oldStartIndex,如果以上 4 种比较都没匹配,如果设置了key,就会用 key 再进行比较,在比较的过程中,遍历会往中间靠,一旦 StartIdx > EndIdx 表明 oldCh 和 newCh 至少有一个已经遍历完了,就会结束比较
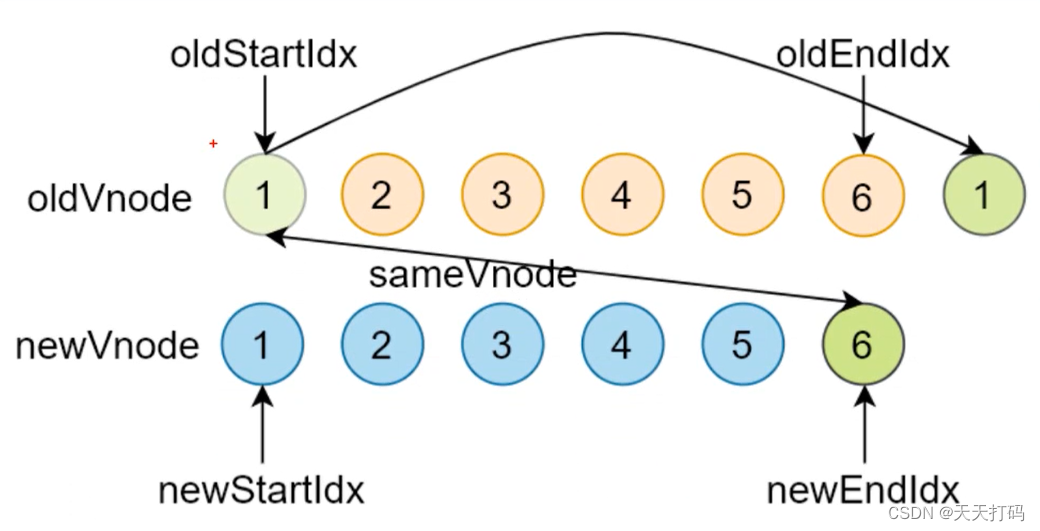
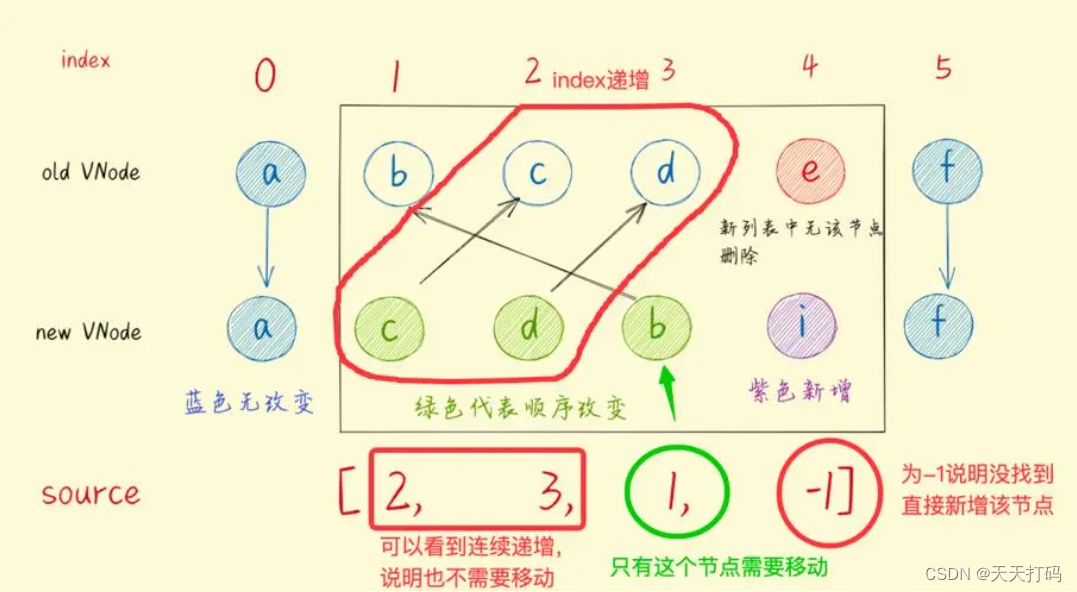
所以 Vue 中 key 的作用是:key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
1.7 虚拟dom的优缺点
优点:
-
保证性能下限: 框架的虚拟 DOM 需要适配任何上层 API 可能产生的操作,它的一些 DOM 操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的 DOM 操作性能要好很多,因此框架的虚拟 DOM 至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限;
-
无需手动操作 DOM: 我们不再需要手动去操作 DOM,只需要写好 View-Model 的代码逻辑,框架会根据虚拟 DOM 和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率;
-
跨平台: 虚拟 DOM 本质上是 JavaScript 对象,而 DOM 与平台强相关,相比之下虚拟 DOM 可以进行更方便地跨平台操作,例如服务器渲染、weex 开发等等
缺点:
无法进行极致优化: 虽然虚拟 DOM + 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化:比如动画等等
1.8 vue虚拟dom实现原理?
虚拟 DOM 的实现原理主要包括以下 3 部分:
-
用 JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象;
-
diff 算法 — 比较两棵虚拟 DOM 树的差异;
-
pach 算法 — 将两个虚拟 DOM 对象的差异应用到真正的 DOM 树

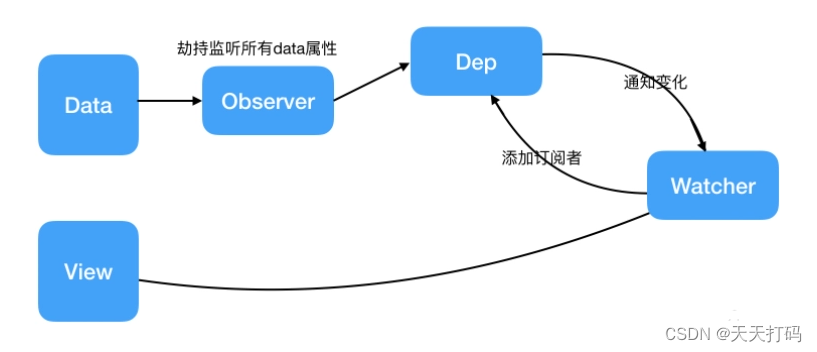
1.9 Vue 是如何实现数据双向绑定的?
Vue 数据双向绑定主要是指:数据变化更新视图
-
输入框内容变化时,Data 中的数据同步变化。即 View => Data 的变化。
-
Data 中的数据变化时,文本节点的内容同步变化。即 Data => View 的变化
Vue 主要通过以下 4 个步骤来实现数据双向绑定的:
-
实现一个监听器 Observer:对数据对象进行遍历,包括子属性对象的属性,利用 Object.defineProperty() 对属性都加上 setter 和 getter。这样的话,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了数据变化
-
实现一个解析器 Compile:解析 Vue 模板指令,将模板中的变量都替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,调用更新函数进行数据更新
-
实现一个订阅者 Watcher:Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁 ,主要的任务是订阅 Observer 中的属性值变化的消息,当收到属性值变化的消息时,触发解析器 Compile 中对应的更新函
-
实现一个订阅器 Dep:订阅器采用 发布-订阅 设计模式,用来收集订阅者 Watcher,对监听器 Observer 和 订阅者 Watcher 进行统一管理
1.20 Vue-router 有哪几种路由守卫?
-
全局守卫:beforeEach
-
后置守卫:afterEach
-
全局解析守卫:beforeResolve
-
路由独享守卫:beforeEnter
1.21 Vue-router 的钩子函数都有哪些?
关于 vue-router 中的钩子函数主要分为 3 类
-
全局钩子函数要beforeEach 函数有三个参数,分别是
1.to:router 即将进入的路由对象
2.from:当前导航即将离开的路由
3.next:function,进行管道中的一个钩子,如果执行完了,则导航的状态就是 confirmed (确认的)否则为 false,终止导航
-
单独路由独享组件 beforeEnter
-
组件内钩子
1.beforeRouterEnter
2.beforeRouterUpdate
3.beforeRouterLeave
1.22 vue-router 路由模式有几种?
vue-router 有 3 种路由模式:hash、history、abstract
-
hash: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
-
history : 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式;
-
abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式.
1.23 说下 vue-router 中常用的 hash 和 history 路由模式实现原理吗?
(1)hash 模式的实现原理 -
URL 中 hash 值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash 部分不会被发送;
-
hash 值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制hash 的切换;
-
可以通过 a 标签,并设置 href 属性,当用户点击这个标签后,URL 的 hash 值会发生改变;或者使用 JavaScript 来对 loaction.hash 进行赋值,改变 URL 的 hash 值;
-
我们可以使用 hashchange 事件来监听 hash 值的变化,从而对页面进行跳转(渲染)
(2)history 模式的实现原理
-
pushState 和 repalceState 两个 API 来操作实现 URL 的变化 ;
-
我们可以使用 popstate 事件来监听 url 的变化,从而对页面进行跳转(渲染);
-
history.pushState() 或 history.replaceState() 不会触发 popstate 事件,这时我们需要手动触发页面跳转(渲染)
1.27 vue 中如何重置 data?
要初始化 data 中的数据,可以使用 Object.assign()方法,实现重置 data 中的数据,以下就是对该方法的详细介绍,以及如何使用该方法,重置 data 中的数据
-
**Object.assign()**方法基本定义
-
Object.assign() 方法用于将所有可枚举属性的值从一个或多个源对象复制到目 标对象。它将返回目标对象。
-
用法: Object.assign(target, …sources),第一个参数是目标对象,第二个参数 是源对象,就是将源对象属性复制到目标对象,返回目标对象
1.28 vue3 新特性有哪些?
1、性能提升
-
响应式性能提升,由原来的 Object.defineProperty 改为基于ES6的 Proxy ,使其速度更快,消除警告。
-
重写了 Vdom ,突破了 Vdom 的性能瓶颈。
-
进行模板编译优化。
-
更加高效的组件初始化
2、更好的支持 typeScript
- 有更好的类型推断,使得 Vue3 把 typeScript 支持得非常好
3、新增Composition API
Composition API 是 vue3 新增的功能,比 mixin 更强大。它可以把各个功能模块独立开来,提高代码逻辑的可复用性,同时代码压缩性更强
4、新增组件
-
Fragment 不再限制 template 只有一个根几点。
-
Teleport 传送门,允许我们将控制的内容传送到任意的 DOM 中。
-
Supense 等待异步组件时渲染一些额外的内容,让应用有更好的用户体验。
5、Tree-shaking:支持摇树优化
摇树优化后会将不需要的模块修剪掉,真正需要的模块打到包内。优化后的项目体积只有原来的一半,加载速度更快
6、Custom Renderer API: 自定义渲染器
实现 DOM 的方式进行 WebGL 编程
1.29 vue3 组合式API生命周期钩子函数有变化吗?
setup 是围绕 beforeCreate 和 created 生命周期钩子运行的,所以不需要显示的定义它们。其他的钩子都可以编写到 setup 内
1.30 watch 和 watchEffect 的区别?
watch 和 watchEffect 都是监听器,watchEffect 是一个副作用函数。它们之间的区别有:
-
watch 需要传入监听的数据源,而 watchEffect 可以自动手机数据源作为依赖。
-
watch 可以访问倒改变之前和之后的值,watchEffect 只能获取改变后的值。
-
watch 运行的时候不会立即执行,值改变后才会执行,而 watchEffect 运行后可立即执行。这一点可以通过 watch 的配置项 immediate 改变。
1.31 vue中v-if和v-for优先级在vue2和vue3中的区别
实践中不管是vue2或者vue3都不应该把v-if和v-for放在一起使用。
-
在 vue 2.x 中,在一个元素上同时使用 v-if 和 v-for 时, v-for 会优先作用。
-
在 vue 3.x 中, v-if 总是优先于 v-for 生效。
-
vue2中v-for的优先级是高于v-if的,放在一起,会先执行循环在判断条件,并且如果值渲染列表中一小部分元素,也得再每次重渲染的时候遍历整个列表,比较浪费资源。
-
vue3中v-if的优先级是高于v-for的,所以v-if执行时,它调用相应的变量如果不存在,就会导致异常
1.32 script setup 有什么用?
scrtpt setup 是 vue3 的语法糖,简化了组合式 API 的写法,并且运行性能更好。使用 script setup 语法糖的特点:
-
属性和方法无需返回,可以直接使用。
-
引入组件的时候,会自动注册,无需通过 components 手动注册。
-
使用 defineProps 接收父组件传递的值。
-
useAttrs 获取属性,useSlots 获取插槽,defineEmits 获取自定义事件。
-
默认不会对外暴露任何属性,如果有需要可使用 defineExpose 。
1.33 vue常用的修饰符
.stop:等同于 JavaScript 中的 event.stopPropagation() ,防止事件冒泡;
.prevent :等同于 JavaScript 中的 event.preventDefault() ,防止执行预设的行为(如果事件可取消,则取消该事件,而不停止事件的进一步传播);作用是阻止默认事件(例如a标签的跳转
.capture :与事件冒泡的方向相反,事件捕获由外到内;
.self :只会触发自己范围内的事件,不包含子元素;
.once :只会触发一次。
.trim修饰符的作用是把v-model绑定的值的首尾空格给去掉。在实际开发中我们一般用于搜索框的内容修饰,过滤掉用户多输入前后空格导致内容查不出来的情况。
.left,.right,.middle这三个修饰符是鼠标的左中右按键触发的事件.
1.36 $route 和 $router 的区别?
$route 是“路由信息对象”,包括 path,params,hash,query,fullPath,matched,name 等路由信息参数
$router 是“路由实例”想要导航到不同URL 对象包括了路由的跳转方法,钩子函数等。
1.37 vue路由跳转传参的方式有哪些?
params传参(显示参数)
在url中会显示出传参的值,刷新页面不会失去拿到的参数,使用该方式传值的时候,需要子路由提前配置好参数
params传参(不显示参数)
在url中不会显示出传参的值,但刷新页面会失去拿到的参数,使用该方式 传值 的时候,需要子路由提前配置好name参数
query 传参
query 传过去的参数会拼接在地址栏中(?name=xx),刷新页面数据不会丢失,使用path和name都可以
VUE几种路由跳转几种方式的区别
-
this.$router.push:跳转到指定url路径,并想history栈中添加一个记录,点击后退会返回到上一个页面
-
this.$router.replace:跳转到指定url路径,但是history栈中不会有记录,点击返回会跳转到上上个页面 (就是直接替换了当前页面)
-
this.$router.go(n):向前或者向后跳转n个页面,n可为正整数或负整数
1.38 单页面应用和多页面应用区别及优缺点?
单页面:顾名思义,只有一个页面。一般是一个主页和多个路由页面组成。
优点:
-
公共资源不重新加载,局部加载,服务器压力小
-
切换速度快,用户体验好
-
前后端分离
缺点:
-
不利于SEO(可以优化:比如路由懒加载等)
-
初次加载时耗时多
开发难度较大(相对多页面)
多页面(Multi Page Application——MPA):有多个HTML页面,跳转的时候是从一个html页面跳到另一个页面。
优点:
-
利于SEO。
-
更容易扩展。
-
更易数据分析。
缺点:
-
开发成本高。
-
服务器压力大。
-
用户体验相对较差。
相关文章:
【前端收藏】前端小作文-前端八股文知识总结(超万字超详细)持续更新
有了这个八股文不仅对你基础知识的巩固,不管你是几年老前端程序员,还是要去面试的,文章覆盖了前端常用及不常用的方方面面,都是前端日后能用上的,对你的前端知识有总结意义,看完后,懂的不懂的都…...
GNSS模块的惯导技术:引领定位科技的前沿
全球导航卫星系统(GNSS)模块的惯导技术是一项颇具前瞻性的科技,它结合了全球定位系统和惯性导航技术,为各个领域的定位需求提供了更为精准和可靠的解决方案。本文将深入探讨GNSS模块的惯导技术,以及它如何在多个领域中…...
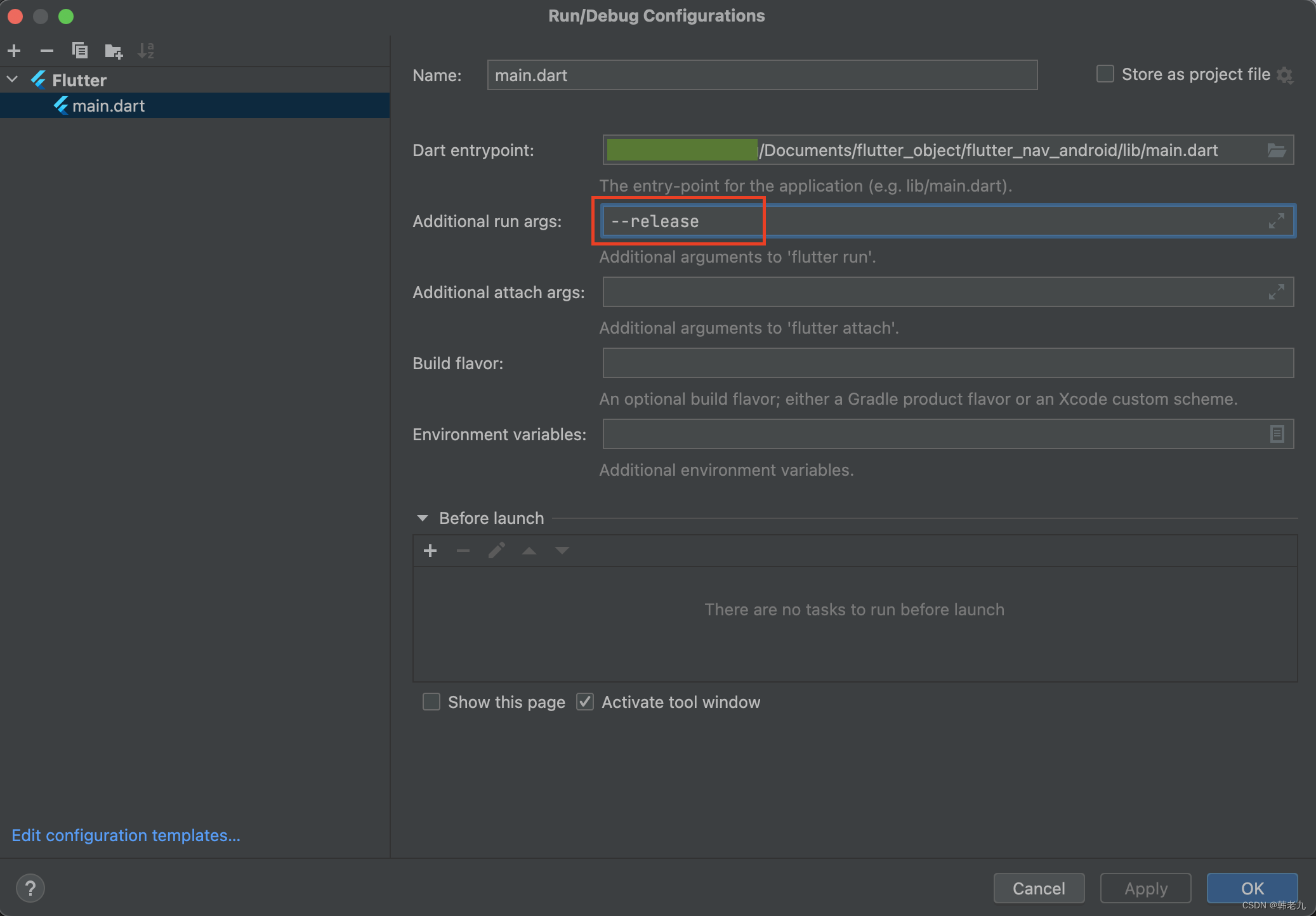
Flutter 和 Android原生(Activity、Fragment)相互跳转、传参
前言 本文主要讲解 Flutter 和 Android原生之间,页面相互跳转、传参, 但其中用到了两端相互通信的知识,非常建议先看完这篇 讲解通信的文章: Flutter 与 Android原生 相互通信:BasicMessageChannel、MethodChannel、…...
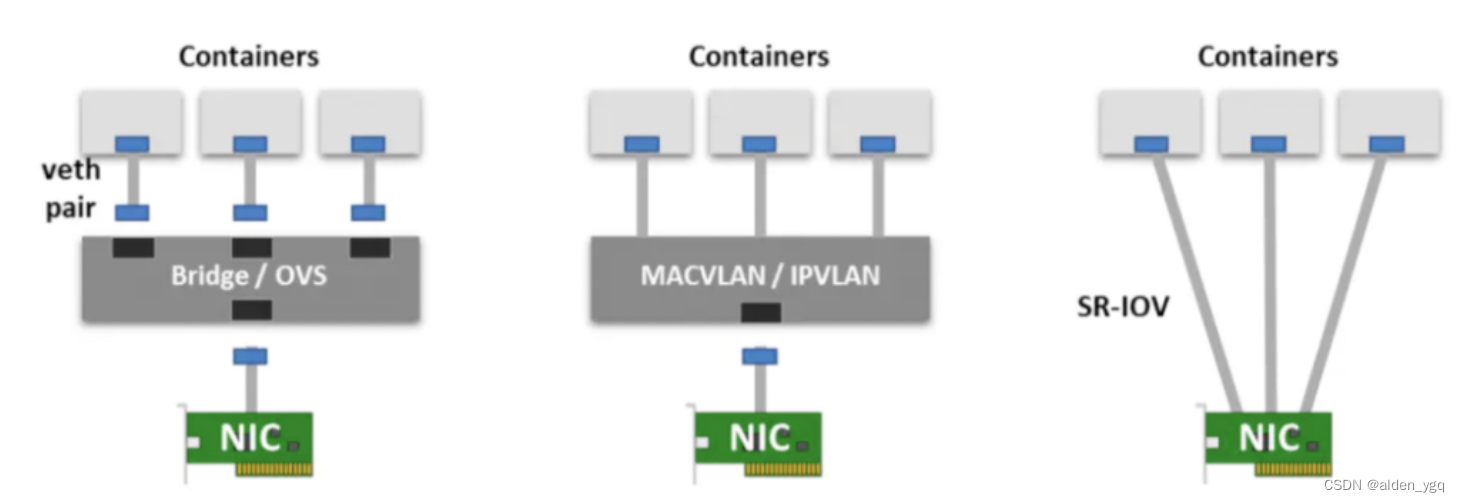
Kubernetes基础(十一)-CNI网络插件用法和对比
1 CNI概述 1.1 什么是CNI? Kubernetes 本身并没有实现自己的容器网络,而是借助 CNI 标准,通过插件化的方式来集成各种网络插件,实现集群内部网络相互通信。 CNI(Container Network Interface,容器网络的…...
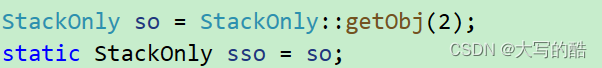
yo!这里是单例模式相关介绍
目录 前言 特殊类设计 只能在堆上创建对象的类 1.方法一(构造函数下手) 2.方法二(析构函数下手) 只能在栈上创建对象的类 单例模式 饿汉模式实现 懒汉模式实现 后记 前言 在面向找工作学习c的过程中,除了基本…...
2023年上-未来几年我要做什么
1月份,离职。 2月份,春节休假回来,中旬去参加了一个月的瑜伽培训,学会了倒立、鹤蝉。。。。 3月份,瑜伽培训结束,开始收拾房子,并调研各类项目。 4月份,参与了朋友的区块链项目 …...
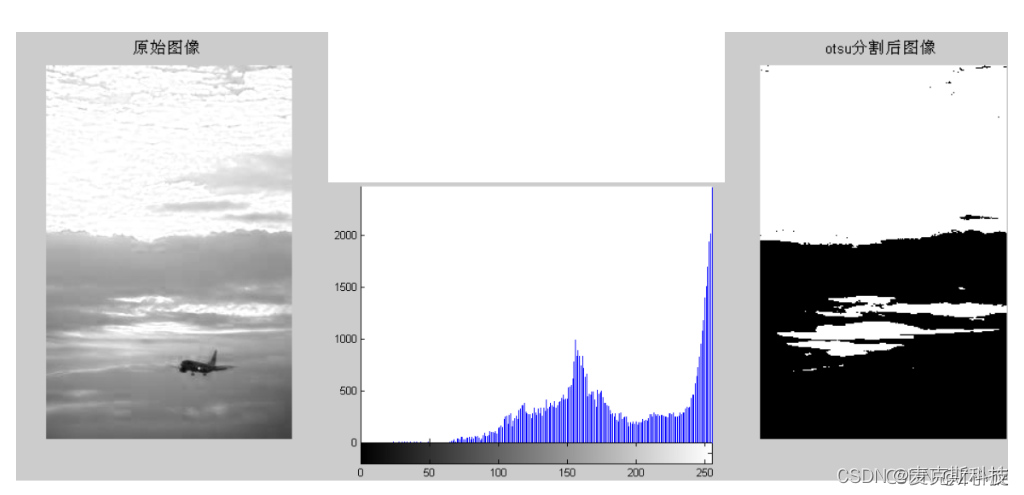
智能汽车竞赛摄像头处理(3)——动态阈值二值化(大津法)
前言 (1)在上一节中,我们学习了对图像的固定二值化处理,可以将原始图像处理成二值化的黑白图像,这里面的本质就是将原来的二维数组进行了处理,处理后的二维数组里的元素都是0和255两个值。 (2…...

BGP协议
1.BGP相关概念 1.1 BGP的起源 不同自治系统(路由域)间路由交换与管理的需求推动了EGP的发展,但是EGP的算法简单,无法选路,从而被BGP取代。 自治系统:(AS) IGP:自治系统…...
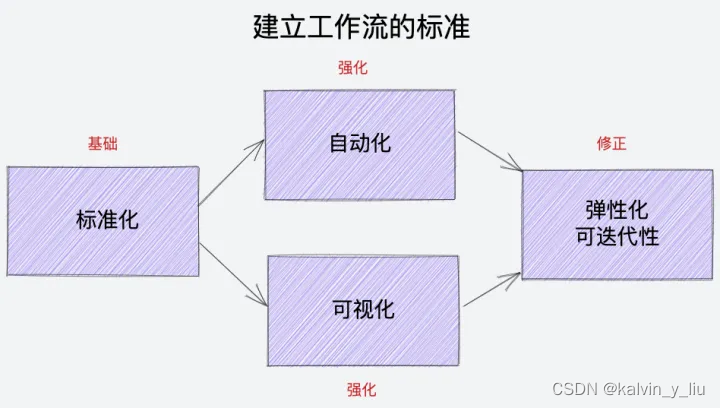
一个完整工作流管理系统的组成部分
一个完整工作流管理系统的组成部分 一个完整的工作流管理系统通常由工作流引擎、工作流设计器、流程操作、工作流客户端程序、流程监控、表单设计器、与表单的集成以及与应用程序的集成八个部分组成。 一、工作流组成 1. 工作流引擎 工作流引擎作为工作流管理系统的核心部分&…...
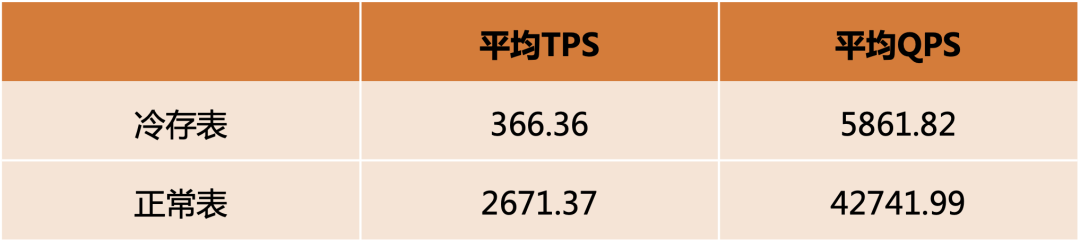
鱼和熊掌如何兼得?一文解析RDS数据库存储架构升级
在2023年云栖大会上,阿里云数据库产品事业部负责人李飞飞在主题演讲中提到,瑶池数据库推出“DB存储”一体化能力,结合人工智能、机器学习、存储等方法和创新能力,实现Buffer Pool Extension能力和智能冷温热数据分层能力。在大会的…...
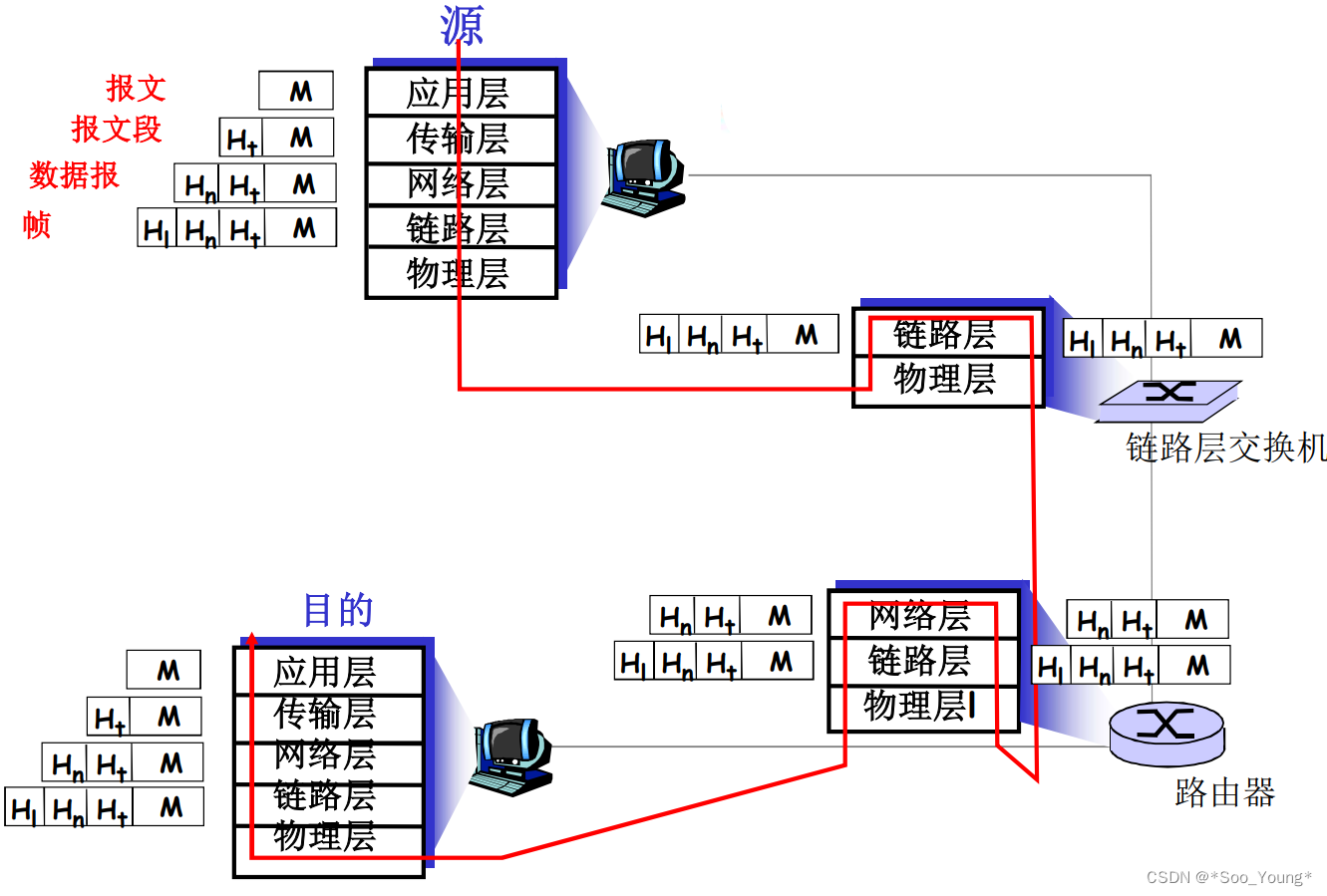
中科大计网学习记录笔记(五):协议层次和服务模型
前言: 学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程 该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信…...

同构异机迁移方案2_目标服务器仅安装数据库软件scp物理文件
源端和目标端的数据库版本需要保持一致,补丁版本可以不一致,目标端磁盘空间不能小于源端空间,目标端只需要安装 Oracle 软件即可。 特别说明:本文档案例Oracle的安装路径不同,数据目录一致,采用scp的方式实…...
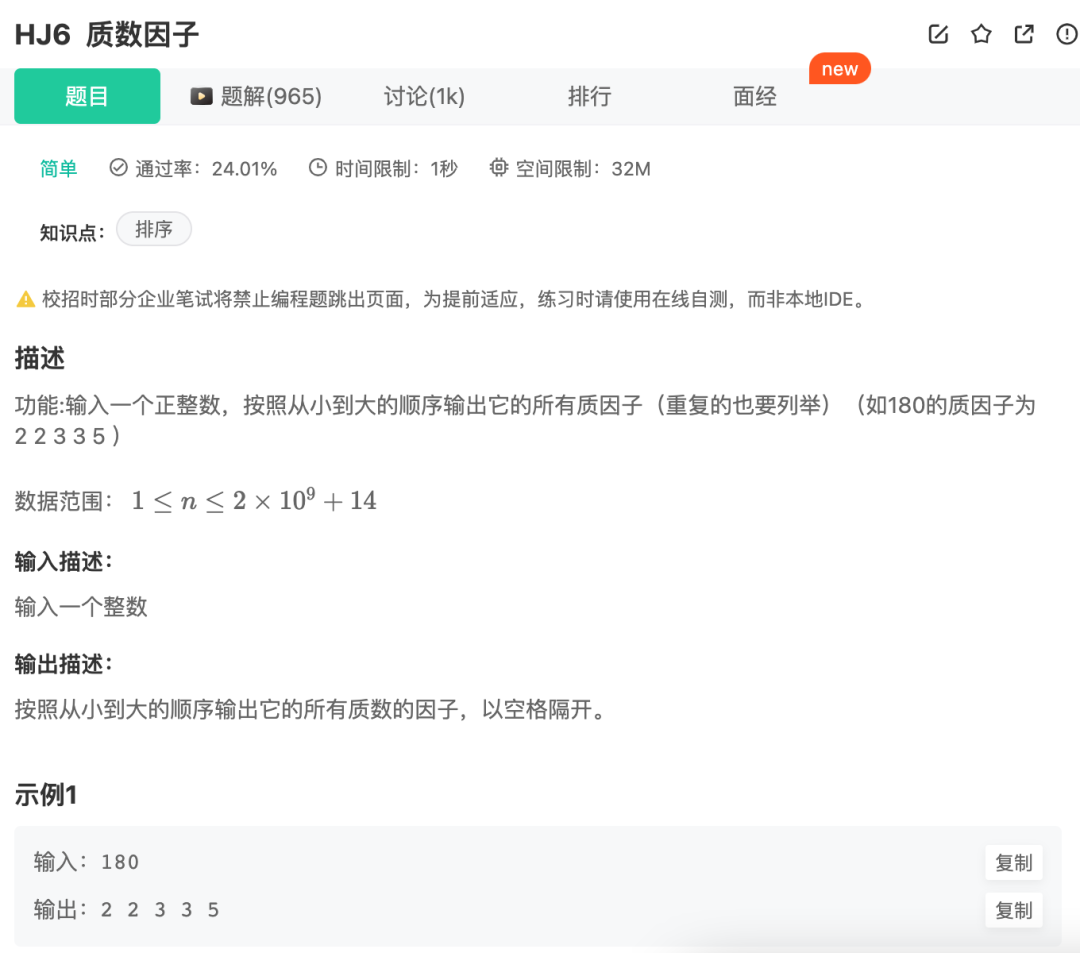
华为机考入门python3--(6)牛客6-质数因子
分类:质数、素数 知识点: 取余符号% 5%3 2 取整符号// 5//3 1 list中int元素转str map(str, list) 题目来自【牛客】 def prime_factors(n): """ 输入一个正整数n,输出它的所有质因子(重复的也…...
11月最新版付费进群源码自动定位+开源
Nginx 1.22.1 php5.6 mysql5.6 数据库配置:/config/database.php 配置后台域名:config/extra/ip.php 设置伪静态thinkphp 后台账号88886666 密码12345 代码结构 关键代码剖析 <?php // ----------------------------------------------------…...

Python算法题集_旋转图像
Python算法题集_旋转图像 题目48:旋转图像1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【矩阵复本】2) 改进版一【矩阵转置矩阵反转】3) 改进版二【四值旋转】 4. 最优算法 题目48:旋转图像 本文为Python算法题集之一…...

[ChatGPT们】ChatGPT 如何辅助编程初探
主页:元存储的博客 全文 9000 字, 原创请勿转载。 我没有写过诗,但有人说我的代码像诗一样优雅 -- 雷军 图片来源:https://www.bilibili.com/video/BV1zL411X7oS/ 1. 引言 作为一个程序员,我们不仅要熟悉各种编程语…...

深入Spring MVC的工作流程
深入Spring MVC的工作流程 在Spring MVC的面试问题中,常常被询问到的一个问题。Spring MVC的程序中,HTTP请求是如何从开始到结束被处理的。为了研究这个问题,我们将需要深入学习一下Spring MVC框架的核心过程和工作流程。 1. 启动请求生命周…...
)
我的数据结构c(给自己用的)
目录 顺序表: 链表: 栈: 队列: 我想在之后的大学数据结构课上需要自己写来做题,但每次都自己写,那太麻烦了,所以我就将这个博客来把所有的C语言的数据结构弄上去, 问我为什么不…...
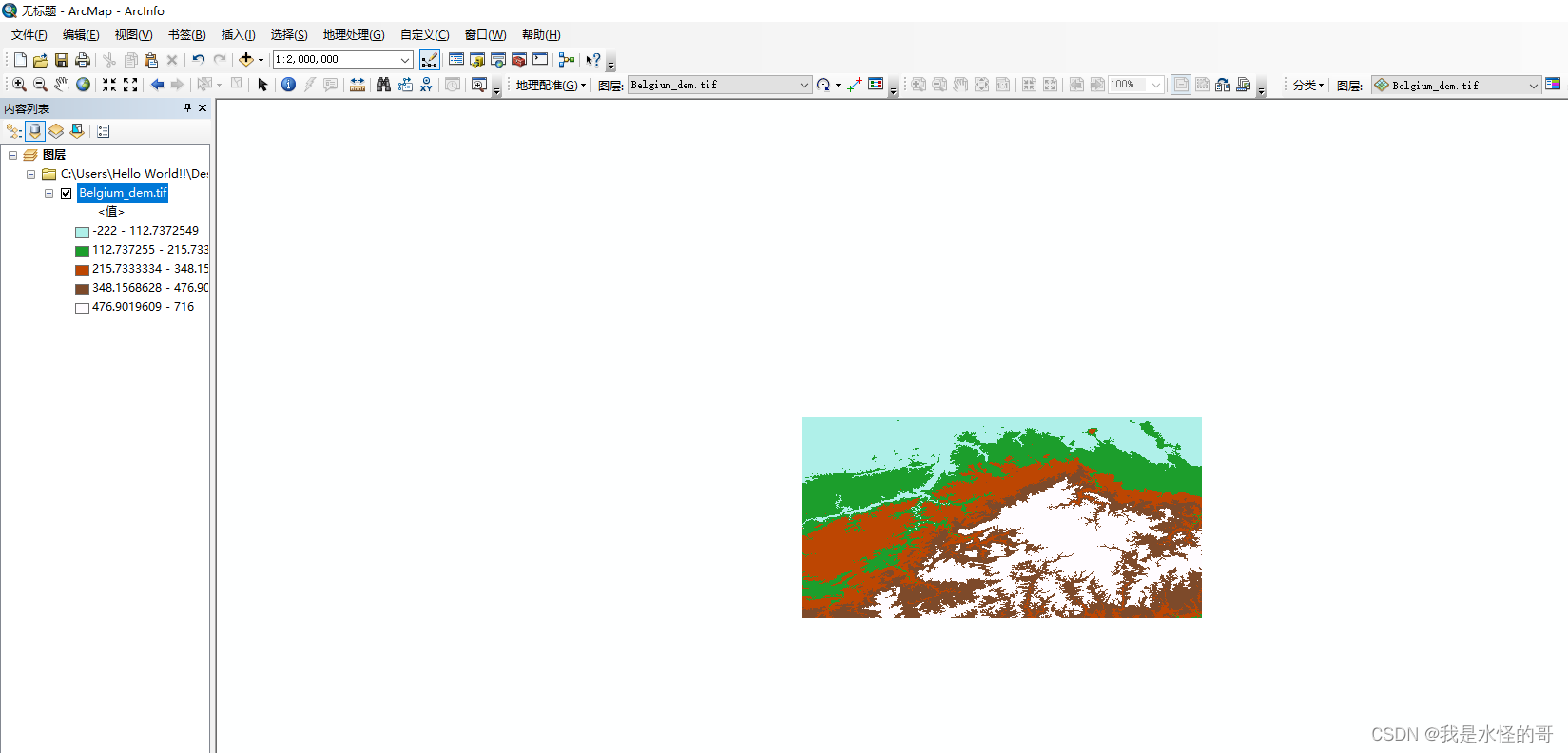
使用Arcgis对欧洲雷达高分辨率降水数据重投影
当前需要使用欧洲高分辨雷达降水数据,但是这个数据的投影问题非常头疼。实际的投影应该长这样(https://gist.github.com/kmuehlbauer/645e42a53b30752230c08c20a9c964f9?permalink_comment_id2954366https://gist.github.com/kmuehlbauer/645e42a53b307…...
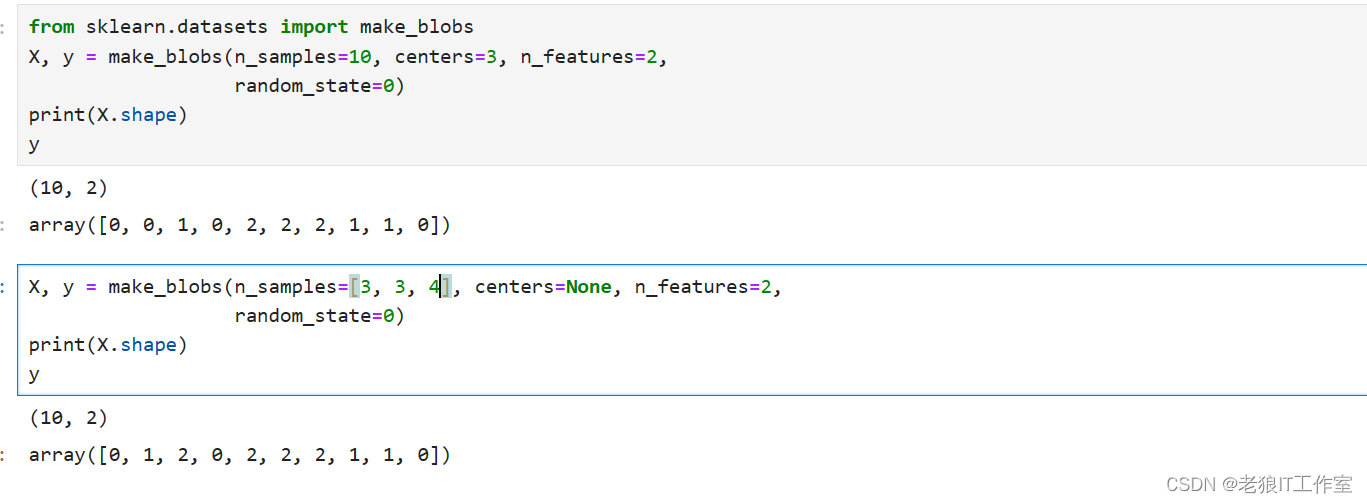
[Python] scikit-learn中数据集模块介绍和使用案例
sklearn.datasets模块介绍 在scikit-learn中,可以使用sklearn.datasets模块中的函数来构建数据集。这个模块提供了用于加载和生成数据集的函数。 API Reference — scikit-learn 1.4.0 documentation 以下是一些常用的sklearn.datasets模块中的函数 load_iris() …...

Ray框架实战:分布式AI训练中的动态资源调度与性能优化
1. Ray框架与分布式AI训练基础 第一次接触Ray框架是在处理一个图像分类项目时,当时我们的ResNet模型在单台8卡服务器上训练需要整整一周。同事建议试试Ray,结果同样的任务在16台机器上只用了6小时——这种效率提升让我彻底成为了Ray的拥趸。Ray本质上是…...
)
【从零开始学Java | 第二十六篇】双列集合(Map)
目录 前言 一、双列集合的特点 1. 键值对(Key-Value)存储 2. 键(Key)的唯一性 3. 值(Value)的可重复性 4. 单向的映射关系 5. 顺序的差异化(根据具体实现类而定) 二、双列集…...

【Git】TortoiseGit无法push远程仓库
问题 无法使用TortoiseGit push远程仓库,但是使用Git Bash命令正常,提示如下错误。 TortoiseGitPlink Fatal Error No supported authentication methods available(server sent: publickey) 原因 这个问题的核心原因在于:TortoiseGit 默认…...

技术方案:deepseek对话怎么导出PDF
在日常使用 DeepSeek 的过程中,一个让人又爱又恨的问题反复出现:回答质量很高,但想把它存下来却非常麻烦。 无论是做技术调研、写方案、做知识沉淀,还是整理学习笔记,DeepSeek 给出的答案往往信息密度大、结构清晰&am…...

3个维度解锁抖音内容采集:从个人创作到企业运营的效率革命
3个维度解锁抖音内容采集:从个人创作到企业运营的效率革命 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

微信聊天记录永久保存终极指南:如何用WeChatMsg掌控你的数字记忆
微信聊天记录永久保存终极指南:如何用WeChatMsg掌控你的数字记忆 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trendin…...

MAVROS无人机Offboard模式实战:从代码解析到自主飞行
1. 从零理解MAVROS与Offboard模式 第一次接触无人机编程时,我被各种专业术语搞得晕头转向。直到亲手用MAVROS控制无人机完成第一个Offboard飞行,才真正理解这套系统的精妙之处。简单来说,MAVROS就像无人机世界的"翻译官"——它把RO…...

技术深度解析:如何通过Turbo Boost动态控制优化Mac系统性能与散热管理
技术深度解析:如何通过Turbo Boost动态控制优化Mac系统性能与散热管理 【免费下载链接】Turbo-Boost-Switcher Turbo Boost disabler / enable app for Mac OS X 项目地址: https://gitcode.com/gh_mirrors/tu/Turbo-Boost-Switcher Turbo Boost Switcher是一…...

应收账款管理:从“被动应对”到“主动管理”的思维转变
“应收账款管理真的太难了!”这是许多企业管理者的心声。中小型企业尤其容易陷入资金回笼慢、坏账风险高的困境,甚至因此影响现金流健康,拖累企业发展。传统管理模式中,信息孤岛、流程繁琐和决策滞后等问题屡见不鲜,让…...

3大维度解锁YimMenu:GTA5安全增强工具全方位使用指南
3大维度解锁YimMenu:GTA5安全增强工具全方位使用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...