spring boot 使用 Kafka
一、Kafka作为消息队列的好处

-
高吞吐量:Kafka能够处理大规模的数据流,并支持高吞吐量的消息传输。
-
持久性:Kafka将消息持久化到磁盘上,保证了消息不会因为系统故障而丢失。
-
分布式:Kafka是一个分布式系统,可以在多个节点上运行,具有良好的可扩展性和容错性。
-
支持多种协议:Kafka支持多种协议,如TCP、HTTP、UDP等,可以与不同的系统进行集成。
-
灵活的消费模式:Kafka支持多种消费模式,如拉取和推送,可以根据需要选择合适的消费模式。
-
可配置性强:Kafka的配置参数非常丰富,可以根据需要进行灵活配置。
-
社区支持:Kafka作为Apache旗下的开源项目,拥有庞大的用户基础和活跃的社区支持,方便用户得到及时的技术支持。
二、springboot中使用Kafka
-
添加依赖:在pom.xml文件中添加Kafka的依赖,包括spring-kafka和kafka-clients。确保版本与你的项目兼容。
-
创建生产者:创建一个Kafka生产者类,实现Producer接口,并使用KafkaTemplate发送消息。
-
配置生产者:在Spring Boot的配置文件中配置Kafka生产者的相关参数,例如bootstrap服务器地址、Kafka主题等。
-
发送消息:在需要发送消息的地方,注入Kafka生产者,并使用其发送消息到指定的Kafka主题。
-
创建消费者:创建一个Kafka消费者类,实现Consumer接口,并使用KafkaTemplate订阅指定的Kafka主题。
-
配置消费者:在Spring Boot的配置文件中配置Kafka消费者的相关参数,例如group id、auto offset reset等。
-
接收消息:在需要接收消息的地方,注入Kafka消费者,并使用其接收消息。
-
处理消息:对接收到的消息进行处理,例如保存到数据库或进行其他业务逻辑处理。
三、使用Kafka
pom中填了依赖
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.8.1</version>
</dependency>
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.8.1</version>
</dependency>-
创建生产者:创建一个Kafka生产者类,实现Producer接口,并使用KafkaTemplate发送消息。
import org.apache.kafka.clients.producer.*;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component; @Component
public class KafkaProducer { @Value("${kafka.bootstrap}") private String bootstrapServers; @Value("${kafka.topic}") private String topic; private KafkaTemplate<String, String> kafkaTemplate; public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public void sendMessage(String message) { Producer<String, String> producer = new KafkaProducer<>(bootstrapServers, new StringSerializer(), new StringSerializer()); try { producer.send(new ProducerRecord<>(topic, message)); } catch (Exception e) { e.printStackTrace(); } finally { producer.close(); } }
}-
配置生产者:在Spring Boot的配置文件中配置Kafka生产者的相关参数,例如bootstrap服务器地址、Kafka主题等。
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.ConsumerConfig;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.MessageListener;
import org.springframework.context.annotation.PropertySource;
import java.util.*;
import org.springframework.beans.factory.*;
import org.springframework.*;
import org.springframework.*;expression.*;value; @Value("${kafka}") Properties kafkaProps = new Properties(); @Bean public KafkaTemplate<String, String> kafkaTemplate(ProducerFactory<String, String> pf){ KafkaTemplate<String, String> template = new KafkaTemplate<>(pf); template .setMessageConverter(new StringJsonMessageConverter()); template .setSendTimeout(Duration .ofSeconds(30)); return template ; } @Bean public ProducerFactory<String, String> producerFactory(){ DefaultKafkaProducerFactory<String, String> factory = new DefaultKafkaProducerFactory<>(kafkaProps); factory .setBootstrapServers(bootstrapServers); factory .setKeySerializer(new StringSerializer()); factory .setValueSerializer(new StringSerializer()); return factory ; } @Bean public ConsumerFactory<String, String> consumerFactory(){ DefaultKafkaConsumerFactory<String, String> factory = new DefaultKafkaConsumerFactory<>(consumerConfigProps); factory .setBootstrapServers(bootstrapServers); factory .setKeyDeserializer(new StringDeserializer()); factory .setValueDeserializer(new StringDeserializer()); return factory ; } @Bean public ConcurrentMessageListenerContainer<String, String> container(ConsumerFactory<String, String> consumerFactory, MessageListener listener){ ConcurrentMessageListenerContainer<String, String> container = new ConcurrentMessageListenerContainer<>(consumerFactory); container .setMessageListener(listener); container .setConcurrency(3); return container ; } @Bean public MessageListener消费者
import org.apache.kafka.clients.consumer.*;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component; @Component
public class KafkaConsumer { @Value("${kafka.bootstrap}") private String bootstrapServers; @Value("${kafka.group}") private String groupId; @Value("${kafka.topic}") private String topic; private KafkaTemplate<String, String> kafkaTemplate; public KafkaConsumer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public void consume() { Consumer<String, String> consumer = new KafkaConsumer<>(consumerConfigs()); consumer.subscribe(Collections.singletonList(topic)); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } } } private Properties consumerConfigs() { Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); return props; }
}四、kafka与rocketMQ比较
Kafka和RocketMQ都是开源的消息队列系统,它们具有许多相似之处,但在一些关键方面也存在差异。以下是它们在数据可靠性、性能、消息传递方式等方面的比较:
- 数据可靠性:
- Kafka使用异步刷盘方式,而RocketMQ支持异步实时刷盘、同步刷盘、同步复制和异步复制。这使得RocketMQ在单机可靠性上比Kafka更高,因为它不会因为操作系统崩溃而导致数据丢失。此外,RocketMQ新增的同步刷盘机制也进一步保证了数据的可靠性。
- 性能:
- Kafka和RocketMQ在性能方面各有千秋。由于Kafka的数据以partition为单位,一个Kafka实例上可能有多达上百个partition,而一个RocketMQ实例上只有一个partition。这使得RocketMQ可以充分利用IO组的commit机制,批量传输数据,从而在replication时具有更好的性能。然而,Kafka的异步replication性能理论上低于RocketMQ的replication,因为同步replication与异步replication相比,性能上会有约20%-30%的损耗。
- 消息传递方式:
- Kafka和RocketMQ在消息传递方式上也有所不同。Kafka采用Producer发送消息后,broker马上把消息投递给consumer,这种方式实时性较高,但会增加broker的负载。而RocketMQ基于Pull模式和Push模式的长轮询机制,来平衡Push和Pull模式各自的优缺点。RocketMQ的消息及时性较好,严格的消息顺序得到了保证。
- 其他特性:
- Kafka在单机支持的队列数超过64个队列,而RocketMQ最高支持5万个队列。队列越多,可以支持的业务就越多。
五、kafka使用场景
- 实时数据流处理:Kafka可以处理大量的实时数据流,这些数据流可以来自不同的源,如用户行为、传感器数据、日志文件等。通过Kafka,可以将这些数据流进行实时的处理和分析,例如进行实时数据分析和告警。
- 消息队列:Kafka可以作为一个消息队列使用,用于在分布式系统中传递消息。它能够处理高吞吐量的消息,并保证消息的有序性和可靠性。
- 事件驱动架构:Kafka可以作为事件驱动架构的核心组件,将事件数据发布到不同的消费者,以便进行实时处理。这种架构可以简化应用程序的设计和开发,提高系统的可扩展性和灵活性。
- 数据管道:Kafka可以用于数据管道,将数据从一个系统传输到另一个系统。例如,可以将数据从数据库或日志文件传输到大数据平台或数据仓库。
- 业务事件通知:Kafka可以用于通知业务事件,例如订单状态变化、库存更新等。通过订阅Kafka主题,相关的应用程序和服务可以实时地接收到这些事件通知,并进行相应的处理。
- 流数据处理框架集成:Kafka可以与流处理框架集成,如Apache Flink、Apache Spark等。通过集成,可以将流数据从Kafka中实时导入到流处理框架中进行处理,实现流式计算和实时分析。
相关文章:
spring boot 使用 Kafka
一、Kafka作为消息队列的好处 高吞吐量:Kafka能够处理大规模的数据流,并支持高吞吐量的消息传输。 持久性:Kafka将消息持久化到磁盘上,保证了消息不会因为系统故障而丢失。 分布式:Kafka是一个分布式系统,…...
LFU缓存(Leetcode460)
例题: 分析: 这道题可以用两个哈希表来实现,一个hash表(kvMap)用来存储节点,另一个hash表(freqMap)用来存储双向链表,链表的头节点代表最近使用的元素,离头节…...

Vue学习笔记:计算属性
计算属性 入门进阶二次进阶三次进阶四次进阶结界五次进阶六次进阶七次进阶八次进阶九次进阶终章彩蛋 入门 Vue.js中,计算属性示例: export default {data() {return {firstName: John,lastName: Doe};},computed: {// 计算属性:全名fullNam…...

深度学习本科课程 实验2 前馈神经网络
任务 3.3 课程实验要求 (1)手动实现前馈神经网络解决上述回归、二分类、多分类任务 l 从训练时间、预测精度、Loss变化等角度分析实验结果(最好使用图表展示) (2)利用torch.nn实现前馈神经网络解决上述回归…...
【python】python爱心代码【附源码】
一、实现效果: 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 二、完整代码: import math import random import threading import time from math import sin, cos, pi, log from tkinter import * import re# 烟花相关设置 Fireworks [] m…...
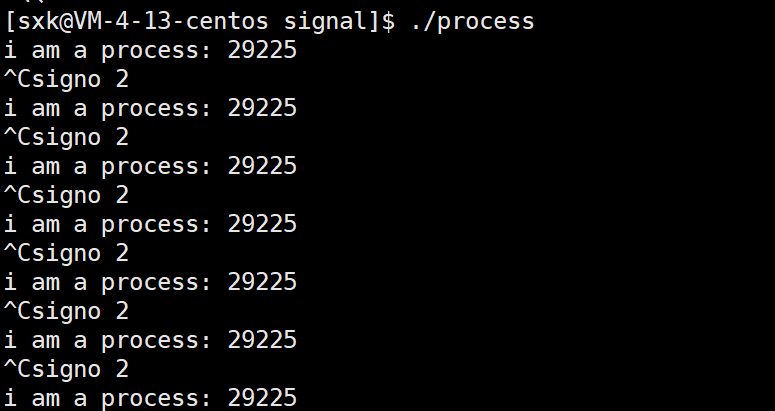
Linux---信号
前言 到饭点了,我点了一份外卖,然后又开了一把网游,这个时候,我在打游戏的过程中,我始终记得外卖小哥会随时给我打电话,通知我我去取外卖,这个时候游戏还没有结束。我在打游戏的过程中需要把外…...
-Java版)
24种设计模式之行为型模式(下)-Java版
软件设计模式是前辈们代码设计经验的总结,可以反复使用。设计模式共分为3大类,创建者模式(6种)、结构型模式(7种)、行为型模式(11种),一共24种设计模式,软件设计一般需要满足7大基本原则。下面通过5章的学习一起来看看设计模式的魅…...
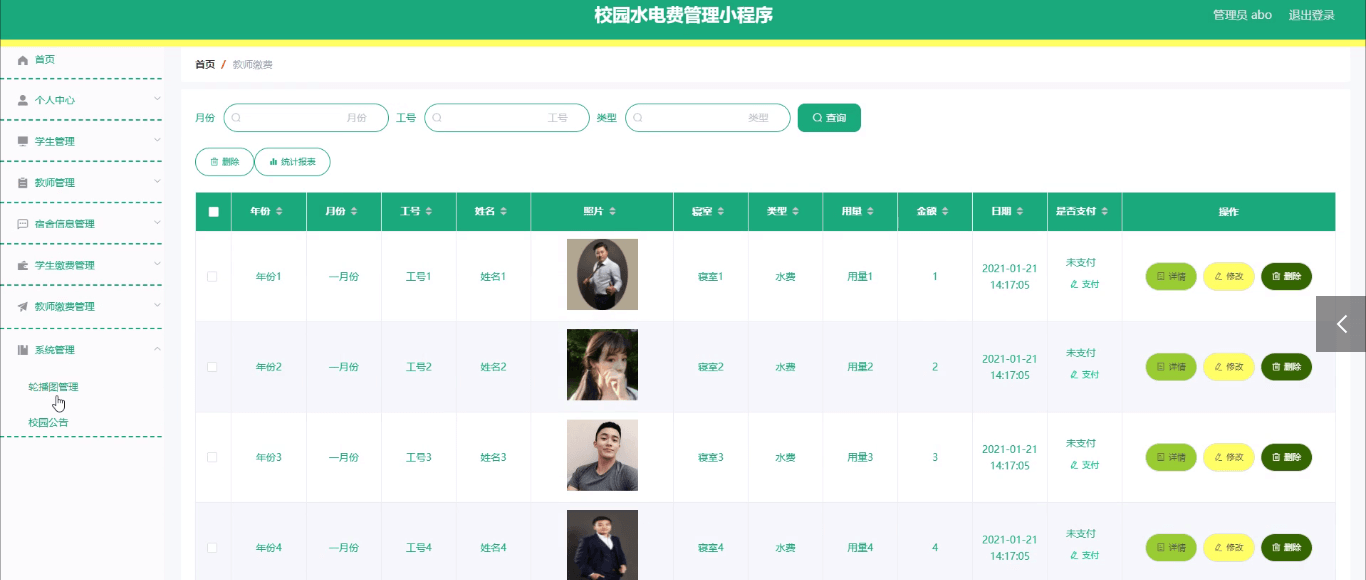
基于微信小程序的校园水电费管理小程序的研究与实现
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
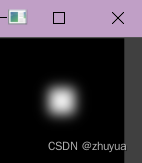
python二维高斯热力图绘制简单的思路代码
import numpy as np import matplotlib.pyplot as plt from scipy.ndimage import gaussian_filter import cv2# 生成一个示例图像 image_size 100 image np.zeros((image_size, image_size))# 在图像中心创建一个高亮区域 center_x, center_y image_size // 2, image_size …...

k8s 部署 nocas 同时部署mysql
使用 ygqygq2 的 helm 模板部署 官方地址:https://artifacthub.io/packages/helm/ygqygq2/nacos 添加 helm 仓库 helm repo add ygqygq2 https://ygqygq2.github.io/charts/下载 helm 安装文件 helm pull ygqygq2/nacos解压 tar -zxvf nacos-2.1.6.tgz执行 hel…...

GolangCI-Lint配置变更实践
GolangCI-Lint配置变更实践 Golang编程中,为了便于调试和代码质量和安全性检查。利用该方法可以在开发周期的早期捕获错误,并且检查团队编程风格,提高一致性。这对团队协作开发特别有用,可以提高开发的效率,保持代码质…...
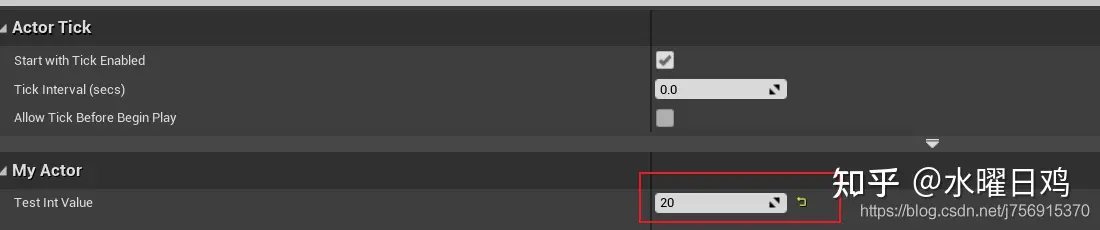
UE中对象创建方法示例和类的理解
对象创建方法示例集 创建Actor示例 //创建一个护甲道具 AProp* armor GetWorld()->SpawnActor<AProp>(pos, rotator); 创建Component示例 UCapsuleComponent* CapsuleComponent CreateDefaultSubobject<UCapsuleComponent>(TEXT("CapsuleComponent&qu…...
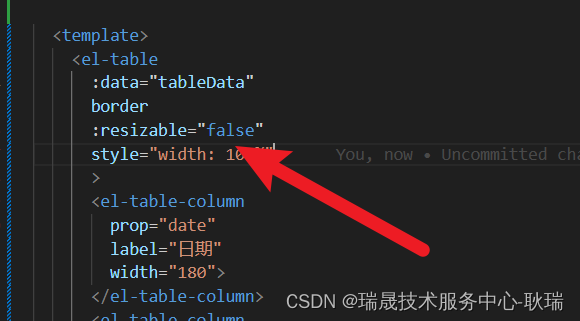
ElementUI鼠标拖动没列宽度
其实 element ui 表格Table有提供给我们一个resizable属性 按官方文档上描述 它就是控制是否允许拖拽表格列大小的属性 而且 它的默认值就是 true 但是依旧很多人会反应拖拽不了 首先 表格要有边框 如果没有变宽 确实是拖拽不了 给 el-table加上 border属性 运行结果如下 但…...
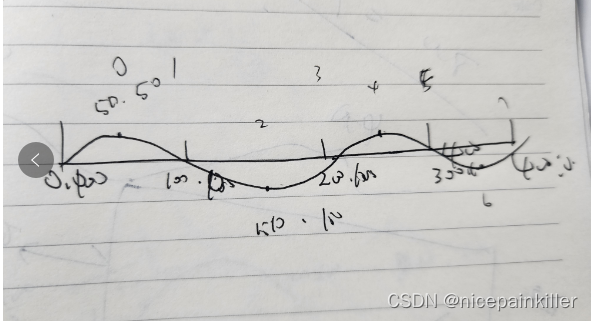
Flutter canvas 画一条会动的波浪线 进度条
之前用 Flutter Canvas 画过一个三角三角形,html 的 Canvas 也画过一次类似的, 今天用 Flutter Canvas 试了下 感觉差不多: html 版本 大致效果如下: 思路和 html 实现的类似: 也就是找出点的位置,使用二阶…...

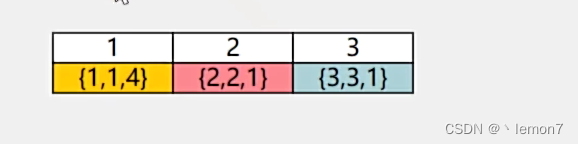
算法训练营day22, 回溯2
216. 组合总和 III func combinationSum3(k int, n int) [][]int { //存储全部集合 result : make([][]int, 0) //存储单次集合 path : make([]int, 0) var backtrace func(k int, n int, sum int, startIndex int) backtrace func(k int, n int, sum int, startIndex int) {…...

undefined symbol: avio_protocol_get_class, version LIBAVFORMAT_58
rv1126上进行编译和在虚拟机里面进行交叉编译ffmpeg都不行 解决办法查看 查看安装的ffmpeg链接的文件 ldd ./ffmpeg rootEASY-EAI-NANO:/home/nano/ffmpeg-4.3.6# ldd ffmpeg linux-vdso.so.1 (0xaeebd000)libavdevice.so.58 > /lib/arm-linux-gnueabihf/libavde…...

Android简单支持项目符号的EditText
一、背景及样式效果 因项目需要,需要文本编辑时,支持项目符号(无序列表)尝试了BulletSpan,但不是很理想,并且考虑到影响老版本回显等因素,最终决定自定义一个BulletEditText。 先看效果&…...
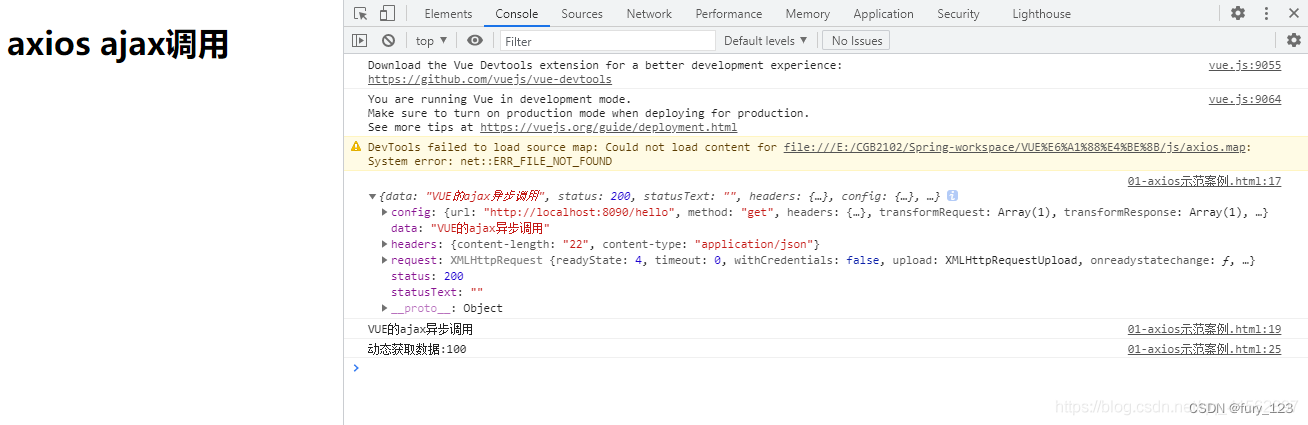
【axios报错异常】: Uncaught ReferenceError: axios is not defined
问题描述: 当前代码在vivo手机和小米手机运行是正常的,点击分享按钮调出相关弹框,发送接口进行分享,但是现在oppo手机出现了问题: 点击分享按钮没有反应. 问题解析: 安卓同事经过查询后,发现打印了错误: 但是不清楚这个问题是安卓端造成的还是前端造成的,大家都不清楚. 问题…...
Docker基础与持续集成
docker 基础知识: docker与虚拟机 !左边为虚拟机,右边为docker环境 – Server :物理机服务器Host OS :构建的操作系统Hypervisor :一种虚拟机软件,装了之后才能虚拟化操作系统Guest OS :虚拟化的操作系统…...

flutter开发实战-ijkplayer视频播放器功能
flutter开发实战-ijkplayer视频播放器功能 使用better_player播放器进行播放视频时候,在Android上会出现解码失败的问题,better_player使用的是video_player,video_player很多视频无法解码。最终采用ijkplayer播放器插件,在flutt…...

SmolVLA企业应用:轻量级VLA模型赋能AGV分拣与桌面机械臂
SmolVLA企业应用:轻量级VLA模型赋能AGV分拣与桌面机械臂 1. 引言:当机器人开始“看懂”世界 想象一下,你对着一个机械臂说:“把那个红色的方块拿起来,放到蓝色的盒子里。”然后它真的照做了。这不是科幻电影…...
构建的详细和依赖项的处理过程(个人总结))
Make:目标(Target)构建的详细和依赖项的处理过程(个人总结)
相关文章 Make专栏https://blog.csdn.net/weixin_45791458/category_12383799.html 这段时间在用makefile,所以自己探究了一下make的工作过程,并经过实验总结了一些规律。 对于一个规则的处理如下,首先make会检查规则中的目标文件是否存在和…...

yaml-cpp低延迟优化终极指南:实时系统中的高性能解析技巧
yaml-cpp低延迟优化终极指南:实时系统中的高性能解析技巧 【免费下载链接】yaml-cpp A YAML parser and emitter in C 项目地址: https://gitcode.com/gh_mirrors/ya/yaml-cpp yaml-cpp是一个功能强大的C YAML解析器和发射器,完全符合YAML 1.2规范…...

ECAPA-TDNN:通道注意力驱动的说话人验证技术革新
ECAPA-TDNN:通道注意力驱动的说话人验证技术革新 【免费下载链接】ECAPA-TDNN Unofficial reimplementation of ECAPA-TDNN for speaker recognition (EER0.86 for Vox1_O when train only in Vox2) 项目地址: https://gitcode.com/gh_mirrors/ec/ECAPA-TDNN …...

STM32单片机NRST管脚异常复位问题解析与EMC设计优化
1. STM32单片机NRST管脚异常复位问题解析最近在客户现场遇到一个棘手的STM32G474单片机异常复位问题,发生在EMS浪涌测试过程中。作为嵌入式开发者,复位问题往往是最让人头疼的故障之一。今天我就把这个案例的完整排查过程和解决方案分享给大家࿰…...

外贸站点SEO优化中如何处理站点的内容优化
外贸站点SEO优化中如何处理站点的内容优化 在当今全球化的商业环境中,外贸站点的SEO优化显得尤为重要。一个成功的外贸站点不仅要吸引国际客户,还需要在搜索引擎结果中获得高排名,以最大限度地提高曝光率和转化率。内容优化是外贸站点SEO优化…...

实战指南:RegRipper3.0 Windows注册表深度取证分析完整方案
实战指南:RegRipper3.0 Windows注册表深度取证分析完整方案 【免费下载链接】RegRipper3.0 RegRipper3.0 项目地址: https://gitcode.com/gh_mirrors/re/RegRipper3.0 RegRipper3.0 是一个专业的 Windows 注册表分析工具,专为数字取证和事件响应设…...

Memento-Skills 深度解析:当 AI 学会自己“造” AI,大模型的进化被彻底改写
Memento-Skills 深度解析:当 AI 学会自己“造” AI,大模型的进化被彻底改写当其他大模型还在云端苦苦等待下一次耗资千万的“重新训练”时,Memento-Skills 已经在你的系统里默默写代码,给自己“招聘”并设计了100个精通各个领域的…...

子代理拆分任务:为什么要用上下文隔离保护 Agent 的思路清晰
子代理拆分任务:为什么要用上下文隔离保护 Agent 的思路清晰 很多人第一次看到子代理,注意力会先落在“一个 Agent 还能再叫出另一个 Agent”这件事上。这个现象当然有意思,但如果只停在这里,很容易错过 s04 真正想解决的问题。 …...

当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩
当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩 【免费下载链接】flac Free Lossless Audio Codec 项目地址: https://gitcode.com/gh_mirrors/fl/flac 你是否曾为音乐收藏占用过多硬盘空间而烦恼?是否在音质与存储效率之间难以抉择…...