大数据 - Spark系列《四》- Spark分布式运行原理
Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
目录
🍠Spark分布式运行原理
1)🧀编程抽象类 RDD
2)🧀分区数据处理
3)🧀统一的数据处理逻辑
4) 🧀统一的结果类型
🍠延申:关于Spark默认并行度spark.default.parallelism的理解
1. 🧀设置方式: 可以通过Spark配置项进行设置
2. 🧀影响因素
🍠Spark面试题总结:
1. Spark是什么,用于什么场景?
2. Spark的优点
3. Spark为什么比MR效率高?
4. Spark编程核心步骤
5. Spark运行模式有哪些?(.setMaster方法)
6. RDD是什么?
7. 创建RDD的方式有哪些?
🍠Spark分布式运行原理
Spark作为一种分布式计算引擎,能够高效地处理大规模数据,其分布式运行的原理主要基于以下几个方面:
1)🧀编程抽象类 RDD
Spark中的核心概念之一是弹性分布式数据集(RDD),它是一种抽象的数据结构,代表分布在集群中的数据集。RDD具备分区的特性,每个分区可以看作是并行处理的单元,Spark会以分区为单位创建任务实例,从而实现分布式运行计算。目前可以理解RDD为带有分区信息和算子计算逻辑的迭代器
创建一个RDD 到底有几个分区(并行)?
1. 加载文件源头RDD
当通过加载文件等方式创建RDD时,RDD的初始分区数由Spark根据输入数据的大小和集群配置自动确定。通常情况下,如果没有特别指定,Spark会尽可能地将数据分成多个分区,以提高并行度和性能。对于文件加载的源头RDD,默认情况下至少会有2个分区。
2. 调用算子返回的RDD
当对一个RDD调用转换算子(transformation)时,返回的新RDD的分区数通常与父RDD的分区数保持一致。
2)🧀分区数据处理
在Spark分布式运行中,各个分区处理属于自己的数据任务。每个任务会被分配到不同的节点上执行,并且各个分区的计算逻辑是一致的,这样就可以保证在不同节点上的并行计算结果是一致的。
3)🧀统一的数据处理逻辑
在处理数据的过程中,Spark提供了丰富的方法和算子来对RDD进行各种操作,例如map、flatMap、reduce等。这些操作符能够灵活地应用于各个分区的数据上,并且具有统一的数据处理逻辑,从而保证了整个作业的一致性。
4) 🧀统一的结果类型
最终,在分布式运行完成后,各个分区处理的结果会被合并成一个统一的RDD。这样就保证了返回的结果类型是一致的,可以进一步进行后续的操作和分析。

🍠延申:关于Spark默认并行度spark.default.parallelism的理解
spark.default.parallelism是指RDD任务的默认并行度,即RDD中的分区数。它对Spark作业的并行执行有着重要影响。
1. 🧀设置方式: 可以通过Spark配置项进行设置
val conf = new SparkConf().set("spark.default.parallelism", "500")2. 🧀影响因素
-
父RDD分区数: 当初始RDD没有设置分区数(
numPartition或numSlice)时,默认并行度取决于spark.default.parallelism的值。 -
分布式shuffle操作: 在使用
reduceByKey、join等分布式shuffle算子操作时,reduce端的stage默认取spark.default.parallelism配置项的值作为分区数。 -
没有shuffle的算子: 对于没有shuffle的算子,在创建RDD又没有设置分区数时,默认并行度依赖Spark运行的模式:
-
本地模式: 默认并行度取决于本地机器的核数。
--local: 没有指定CPU核数,则所有计算都运行在一个线程当中,没有任何并行计算--local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
--local[*]: 自动帮你按照CPU的核数来设置线程数。比如CPU有32个逻辑处理器,Spark帮你自动设置32个线程计算。
-
集群模式: 默认并行度为8。
-
目前Spark系列文章已经更新到第四篇,Spark第一阶段学习也已经完成。对此,特对知识点做了一个汇总如下
🍠Spark面试题总结:
1. Spark是什么,用于什么场景?
Spark是一站式分布式计算引擎,主要用于离线处理
2. Spark的优点
1)比MR效率高
2)API丰富,可以实现复杂度处理逻辑
3)功能组件丰富,满足各种处理需求场景
4)支持多语言编程
3. Spark为什么比MR效率高?
1)减少了与HDFS的交互的次数
2)减少了作业初始化的流程
3)开发高效
4. Spark编程核心步骤
1)编程环境
2)加载各种数据源
3)使用算子处理数据
4)保存结果
5. Spark运行模式有哪些?(.setMaster方法)
1)本地测试
2)yarn集群
3)自带的集群模式
6. RDD是什么?
RDD是弹性分布式数据集,它是一种抽象的数据结构,可以理解为带有分区信息和算子计算逻辑的迭代器。
7. 创建RDD的方式有哪些?
1)读文件
2)本地集合用makerdd方法转换成rdd
3) 读数据库
相关文章:
大数据 - Spark系列《四》- Spark分布式运行原理
Spark系列文章: 大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客 大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客 大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客 目录 🍠…...

Java使用规范
1.关键字 定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词) 特点:关键字中的所有字母都是小写 2.保留字 java保留字:现有Java版本尚未使用,但以后的版本可能会作为关键字使用。命名标识符时要避免使用这些…...

Debian 11 安装并开启SSH服务实现允许root用户使用SecureCRT远程登录
Debian11系统默认没有安装SSH服务,如需要开启远程登录则需要安装相应的服务。 确保你已经登录到Debian系统,并具有root用户或sudo特权。 打开终端,并使用以下命令安装OpenSSH服务器软件包: sudo apt update sudo apt install ope…...
)
Linux下对线程的理解(上)
1、线程的概念 要理解线程首先要理解页表和进程地址空间,我是这样子理解的,1、进程地址空间是进程访问资源的窗口。2、页表是规定进程地址空间中哪些属于进程。3、合理的使用进程地址空间页表可以对资源进行划分。而如何理解进程呢?进程是接受…...

【蓝桥杯】环形链表的约瑟夫问题
目录 题目描述: 输入描述: 输出描述: 示例1 解法一(C): 解法二(Cpp): 正文开始: 题目描述: 据说著名犹太历史学家 Josephus 有过以下故事&a…...

深度学习本科课程 实验1 Pytorch基本操作
一、Pytorch基本操作考察 1.1 任务内容 使用 𝐓𝐞𝐧𝐬𝐨𝐫 初始化一个 𝟏𝟑 的矩阵 𝑴 和一个 𝟐𝟏 的矩阵 𝑵,对两矩阵…...
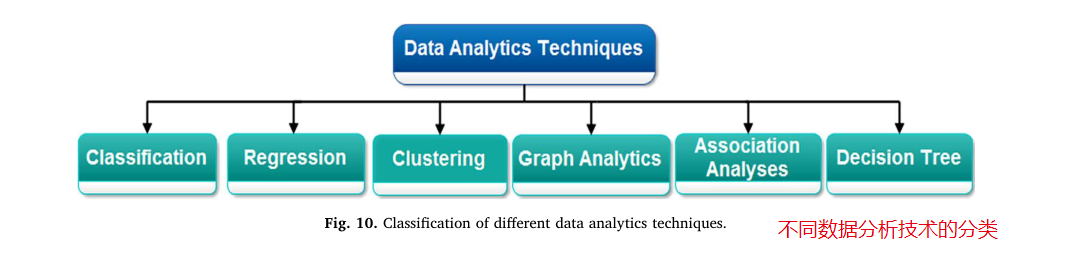
大数据分析|设计大数据分析的三个阶段
文献来源:Saggi M K, Jain S. A survey towards an integration of big data analytics to big insights for value-creation[J]. Information Processing & Management, 2018, 54(5): 758-790. 下载链接:链接:https://pan.baidu.com/s/1…...
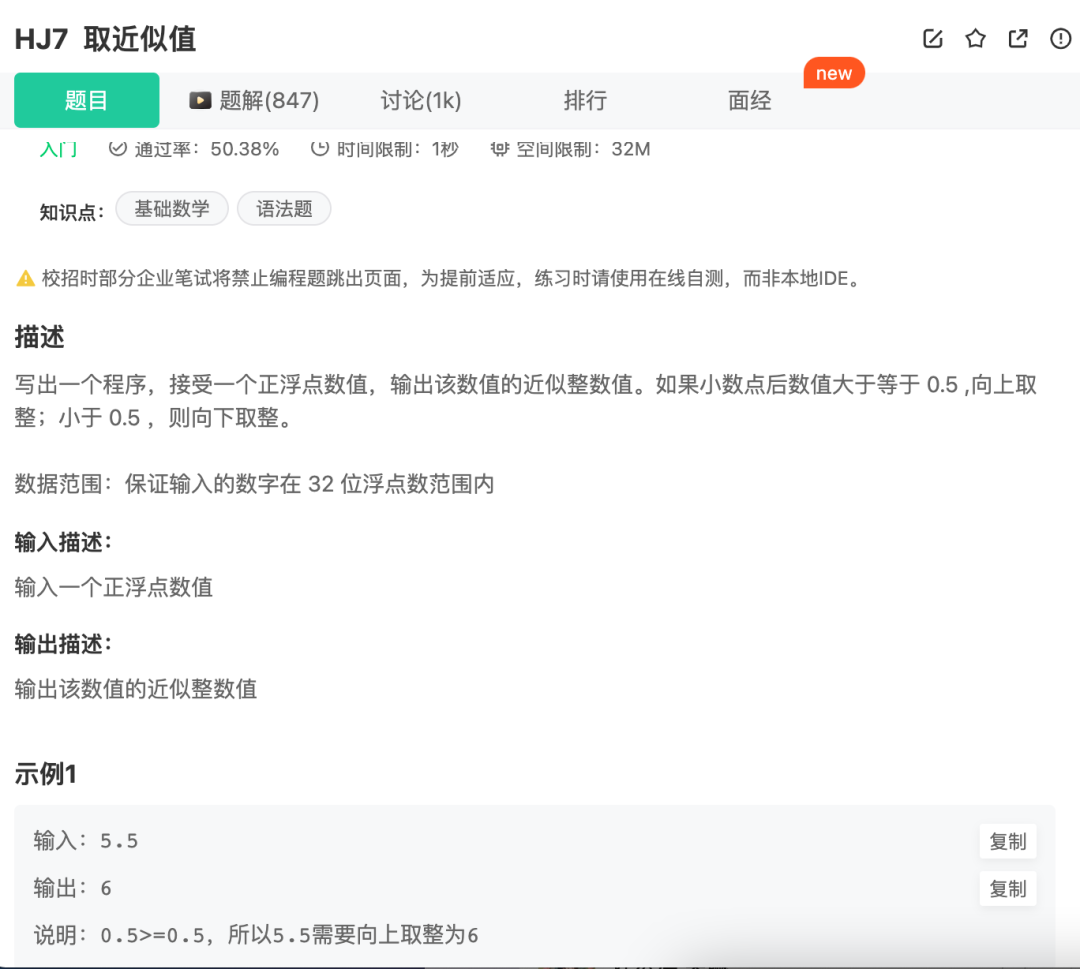
华为机考入门python3--(7)牛客7-取近似值
分类:数字 知识点: str转float float(str) 向上取整 math.ceil(float_num) 向下取整 math.floor(float_num) 题目来自【牛客】 import math def round_to_int(float_num): # 如果小数点后的数值大于等于0.5,则向上取整…...

C# Avalonia 11.0.6 绘图
在 Avalonia 11.0.6 中,Render 方法是被标记为 sealed 的,意味着不能直接在子类中重写这个方法。这样的设计可能是为了确保一致性和避免误用。 如果你需要在 Avalonia 中进行自定义的绘图操作,可以使用 DrawingContext,但是需要通…...
使用java -jar命令运行jar包提示“错误:找不到或无法加载主类“的问题分析
用maven把普通java项目打包成可运行的jar后,打开cmd用java -jar运行此jar包时报错: 用idea运行该项目则没有问题 。 其实原因很简单,我们忽略了2个细节。 java指令默认在寻找class文件的地址是通过CLASSPATH环境变量中指定的目录中寻找的。我…...
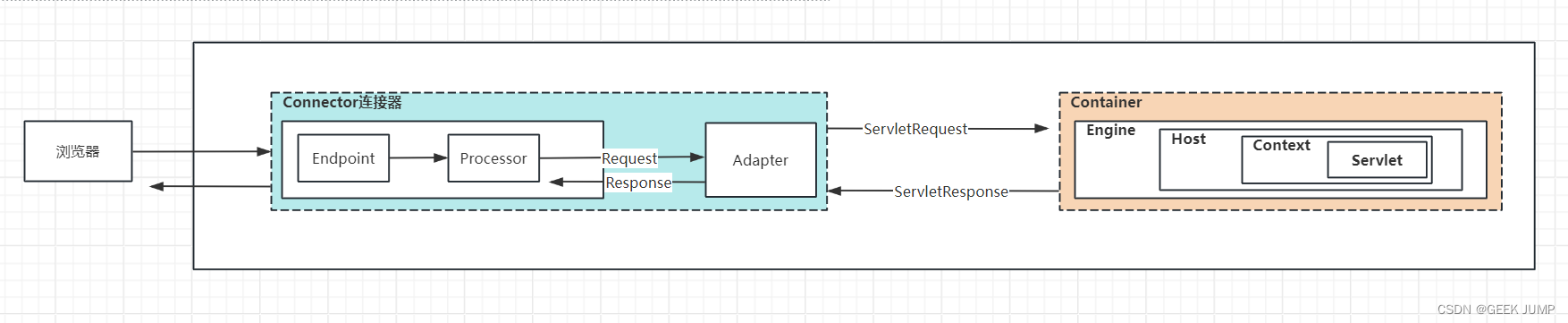
Tomcat组件架构与数据流
一、背景与简介 Tomcat我们都知道是一个开源的、实现了大部分Java EE、Servlet、JSP规范的Servlet容器, 允许我们将实现了Serlvet接口的Web程序war包进行部署运行。 但是你有对Tomcat做过细致的学习么? 我相信大部分同学和我一样,之前也是只会进行简单使用&#x…...

AES算法:数据传输的安全保障
在当今数字化时代,数据安全成为了一个非常重要的问题。随着互联网的普及和信息技术的发展,我们需要一种可靠的加密算法来保护我们的敏感数据。Advanced Encryption Standard(AES)算法应运而生。本文将介绍AES算法的优缺点、解决了…...

前端小案例——动态导航栏文字(HTML + CSS, 附源码)
一、前言 实现功能: 这案例是一个具有动态效果的导航栏。导航栏的样式设置了一个灰色的背景,并使用flex布局在水平方向上平均分配了四个选项。每个选项都是一个li元素,包含一个文本和一个横向的下划线。 当鼠标悬停在选项上时,选项的文本颜色…...
【2024-02-04】)
前置机、堡垒机(跳板机)【2024-02-04】
文章目录 0、前言1、前置机1.1、概念1.2、功能1.3、使用场景1.4、总结 2、堡垒机2.1、概念2.2、功能2.3、使用场景2.4、总结 3、前置机和堡垒机3.1、设计理念与目的3.2、功能3.3、使用场景 0、前言 文章借鉴: https://blog.csdn.net/weixin_45565886/article/detai…...

从编程中理解:大脑的短期记忆和长期记忆
在编程中,我们可以将大脑的短期记忆和长期记忆类比为程序中的变量作用域和持久化存储。在Unity C#编程环境下,可以这样解释: 假设金庸武侠世界中的人物张无忌正在修炼九阳真经。我们用C#代码来模拟他学习武功的过程,其中涉及的“…...
Rust 本地文档的使用:rustup doc
Rust 是一种系统级编程语言,以其安全性、速度和内存控制能力而闻名。为了方便开发者更好地了解并利用 Rust 标准库和工具链中的功能,Rust 提供了一种内置的文档浏览方式——通过 rustup doc 命令。 安装 rustup 在查阅 Rust 文档之前,确保你…...
)
uni-app切换页面刷新,返回上一页刷新(onShow钩子函数的使用)
切换页面刷新:通过onShow()便可实现 返回上一页通过uni.navigateBack({delta: 1});实现 以返回上一页刷新为例 从B页面返回上一页到A页面,在A页面写入方法refreshHandler() //a.vue methods: { // 执行刷新逻辑refreshHandler() {uni.request({ur…...
adb 无线连接 操作Android设备
最近集五福活动比较热门 可以用这个工具 用自己擅长的语言写一个循环程序 运行起来就可以 自动帮我们 看视频得福卡了 很方便 while (true) {sleep(mt_rand(15, 25));system(adb shell input swipe 500 2000 500 1000 100); } 1. 首先下载 安卓开发工具 adb adb网盘链接 链接…...

春节运维不打烊:一体化运维高效保障企业IT与机房环境
随着技术的不断发展和企业数字化转型的深入,IT运维已经成为企业运营不可或缺的一部分。尤其在春节期间,一体化运维管理系统以其独特的技术特性和卓越的功能,为企业的稳定运行提供了坚实保障,确保了节日的祥和与工作的连续高效。 一…...

类银河恶魔城学习记录1-5 CollisionCheck源代码 P32
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Player.cs using System.Collections; using System.Collections.Generic; using Unity.VisualScripting; u…...

torchaudio报错没安装torchcodec
安装torchcodec后仍然报错,原因是torchcodec需要cuda13.x的配置解决办法:重装torchaudio,版本回退到2.4,在保存音频时无需依赖torchcodec同时需要注意匹配torch和torchvision的版本pip install torch2.4.0 torchvision0.19.0 torc…...

从 Vectorless 到 SAIF 再到板级实测:HLS Kernel 功耗估计全流程实战
从 Vectorless 到 SAIF 再到板级实测:HLS Kernel 功耗估计全流程实战 很多人在做 FPGA 或 SoC 上的 HLS kernel 时,第一次接触功耗分析,往往是从 Vivado 里的 report_power 开始的。点一下按钮,工具很快就会给出一个总功耗数字&am…...

终极指南:activate-linux项目如何实现WebAssembly移植与浏览器环境运行
终极指南:activate-linux项目如何实现WebAssembly移植与浏览器环境运行 【免费下载链接】activate-linux The "Activate Windows" watermark ported to Linux 项目地址: https://gitcode.com/gh_mirrors/ac/activate-linux activate-linux是一个有…...

GitHub Desktop中文汉化工具:轻松将官方客户端变成中文界面
GitHub Desktop中文汉化工具:轻松将官方客户端变成中文界面 【免费下载链接】GitHubDesktop2Chinese GithubDesktop语言本地化(汉化)工具 【GitHub桌面客户端中文汉化】 项目地址: https://gitcode.com/gh_mirrors/gi/GitHubDesktop2Chinese 还在为GitHub De…...

openEuler 24.03 LTS SP3 跨版本升级安装源设置全指南
一、背景认知 1.1 版本与升级基础 openEuler 24.03 LTS SP3:2025 年 12 月 30 日正式发布,基于 Linux 6.6 内核,提供 4 年社区长期支持,修复了前期版本的已知问题,大幅优化了 AI、数据库和异构计算性能,是…...

微信网页授权redirect_uri配置全解析:从错误码10003到完美避坑指南
1. 微信网页授权redirect_uri配置全解析 最近在开发一个需要微信登录的项目时,遇到了经典的错误码10003问题。当时调试了大半天才发现是redirect_uri配置出了问题。相信很多开发者都踩过这个坑,今天我就把完整的解决方案和避坑经验分享给大家。 微信网页…...

魔兽争霸3帧率优化完全指南:从技术原理到实战调优
魔兽争霸3帧率优化完全指南:从技术原理到实战调优 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 一、性能瓶颈诊断:定位魔兽争…...

UABEA:Unity游戏资源编辑与分析的终极解决方案
UABEA:Unity游戏资源编辑与分析的终极解决方案 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和模组制作领域,处理Asset Bundle资源文件是每个开发者都会面临的…...

PaddleOCR模型选型避坑指南:从‘轻量级模型缺失文件’到‘通用模型实战’
PaddleOCR模型选型避坑指南:从轻量级到通用模型的实战解析 第一次接触PaddleOCR时,面对琳琅满目的模型选择,很多开发者都会陷入困惑:轻量级模型和通用模型到底有什么区别?为什么下载的轻量级模型总是提示缺少文件&…...
)
CPS实战:如何用树莓派+传感器搭建你的第一个信息物理系统(附代码)
CPS实战:如何用树莓派传感器搭建你的第一个信息物理系统(附代码) 信息物理系统(CPS)听起来像是高科技实验室里的复杂装置,但实际上,你完全可以用手边的树莓派和几十元的传感器搭建一个功能完整的…...