impala与kudu进行集成
文章目录
- 概要
- Kudu与Impala整合配置
- Impala内部表
- Impala外部表
- Impala sql操作kudu
- Impala jdbc操作表
- 如果使用了Hadoop 使用了Kerberos认证,可使用如下方式进行连接。
概要
- Impala是一个开源的高效率的SQL查询引擎,用于查询存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。它提供了一个类似于传统关系型数据库的SQL接口,允许用户使用SQL语言查询存储在Hadoop集群中的数据。使用内存进行计算提供实时的SQL查询,impala强依赖于Hive 的MetaStore,直接使用hive的元数据,意味着impala元数据都存储在hive的MetaStore当中,并且impala兼容hive的绝大多数sql语法,具有实时,批处理,多并发等优点。
- Kudu提供了KuduClient api用于操作kudu数据库,但不支持标准SQL操作,可以将Kudu与Apache Impala紧密集成,impala天然就支持兼容kudu,允许开发人员使用Impala的SQL语法从Kudu的tablets 插入,查询,更新和删除数据,Kudu与Impala整合本质上就是为了可以使用Hive表来操作Kudu,主要支持SQL操作。
Kudu与Impala整合配置
先安装Impala后安装Kudu,Impala默认与Kudu没有形成依赖,这里需要首先在Impala中开启Kudu依赖支持,打开Impala->“配置”->“Kudu服务”:
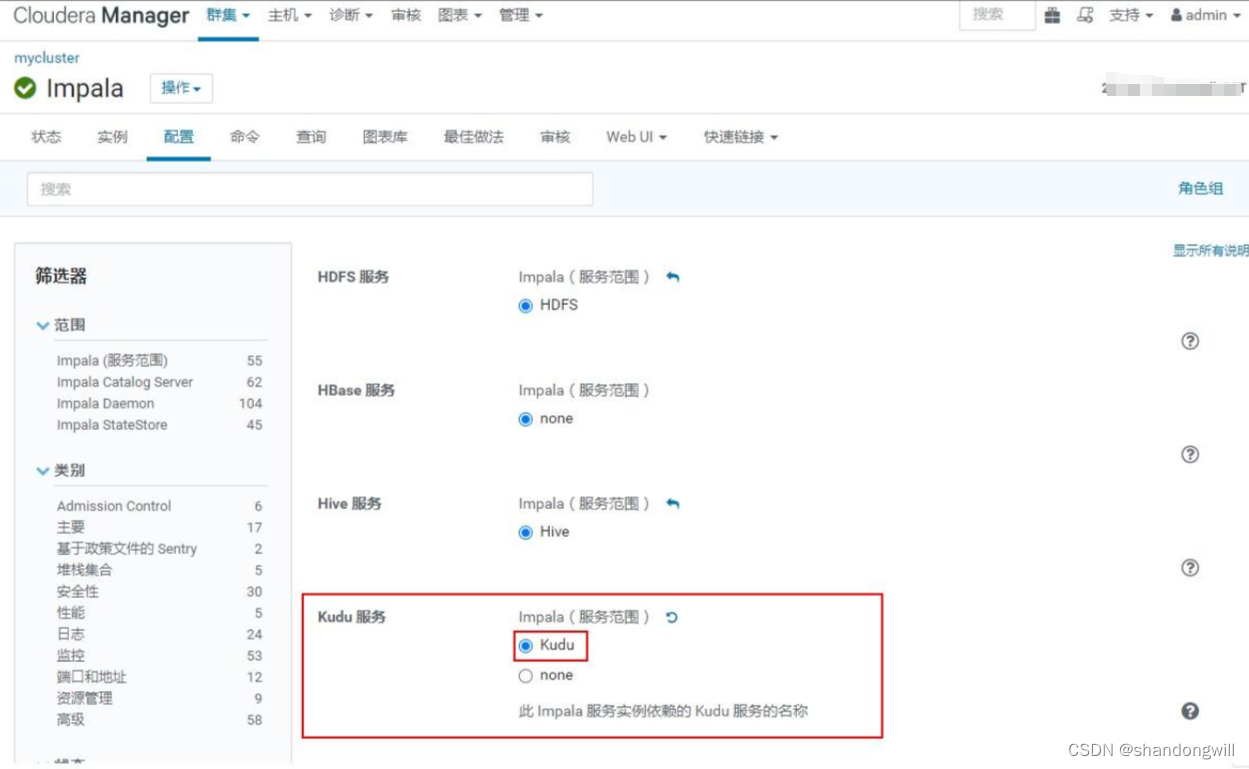
以上配置完成之后,重启Impala即可。
Impala内部表
内部表是由Impala自身管理的表,数据存储在Hive元数据库和Kudu中。当删除内部表时,存储在Hive元数据库中的元数据和存储在kudu中的数据都会被删除。
例如:
CREATE TABLE my_table1
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES(
‘kudu.master_addresses’ = ‘cm1:7051’,
‘kudu.table_name’ = ‘my_table1’
);
Impala外部表
外部表则是由KUDU管理的表,元数据存储在Hive元数据库中,但实际数据文件存储在kudu中。删除外部表时,只会删除元数据,实际的数据文件不会被删除。外部表也可以指定数据的存储位置,可以在建表时指定,也可以通过ALTER TABLE语句修改。
使用Kudu client api 在Kudu中创建表test_user,创建好之后。使用下面的sql语句创建外部表。
CREATE EXTERNAL TABLE test_user STORED AS KUDU
TBLPROPERTIES(
‘kudu.table_name’ = ‘test_user’,
‘kudu.master_addresses’ = ‘10.68.18.60:7051’);
Impala sql操作kudu
插入数据
insert into default_vals(id,name,address,age) values (10,“hello1”,‘山东’,22) ;
查询表数据
select * from default_vals;
更新表数据
upsert into default_vals(id,name,address,age) values(102,‘hello2’,‘山东’,22);
删除数据
delete from default_valswhere id = 20;
Impala jdbc操作表
maven 依赖
<!-- impala的驱动 --><dependency><groupId>com.cloudera.impala.jdbc</groupId><artifactId>ImpalaJDBC42</artifactId><version>2.5.42</version><scope>provided</scope></dependency>
代码示例
package com.example.demo.impala;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;public class ImpalaCrud {public static void main(String[] args) {System.out.println("begin");Connection conn =getConnection();queryTable(conn) ;
// insertTable2(conn) ;}public static void insertTable2(Connection conn) {String insertSql="insert into default_vals( name,age,create_time,update_time,id) values (?,?,?,now(),?)";PreparedStatement ps=null;try {ps=conn.prepareStatement(insertSql);ps.setString(1, "张三李四");ps.setString(2, "43");ps.setTimestamp(3, getCurrentTimestamp());ps.setString(4, "102");ps.execute();} catch (SQLException e) {e.printStackTrace();}finally {if(conn!=null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}public static java.sql.Timestamp getCurrentTimestamp() {java.util.Date date=new java.util.Date();java.sql.Timestamp timestamp = new java.sql.Timestamp(date.getTime()); System.out.println(timestamp);
// java.sql.Date sqlDate=new java.sql.Date(date.getTime());return timestamp;}public static void insertTable(Connection conn) {String insertSql="insert into default_vals( name,age,create_time,update_time,id) values (?,?,now(),now(),?)";PreparedStatement ps=null;try {ps=conn.prepareStatement(insertSql);ps.setString(1, "xxxxx1");ps.setInt(2, 43);ps.setInt(3, 101);
// ps.setInt(4, 33);ps.execute();} catch (SQLException e) {e.printStackTrace();}finally {if(conn!=null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}public static void queryTable(Connection conn) {String querySql="select * from test_user1";
// PreparedStatement ps=conn.prepareStatement(querySql);Statement st;try {st = conn.createStatement();ResultSet rs=st.executeQuery(querySql);while(rs.next()) {System.out.print (rs.getString(1));System.out.print (rs.getString(2));System.out.print (rs.getString(3));System.out.println (" ");}rs.close();} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(conn!=null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}public static Connection getConnection() {Connection conn =null;try {Class.forName("com.cloudera.impala.jdbc.Driver");//指定连接类型 String url="jdbc:impala://10.68.18.170:21050/db1;UseSasl=0;AuthMech=0;UID=impala";
// String url="jdbc:impala://10.3.4.31:21050/ccit_dl_ods";
// conn = DriverManager.getConnection(url);//获取连接conn = DriverManager.getConnection(url,"root","huawei@123");//获取连接}catch(Exception e) {e.printStackTrace();}return conn;}
}
如果使用了Hadoop 使用了Kerberos认证,可使用如下方式进行连接。
package com.example.demo.impala;import java.security.PrivilegedAction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;import org.apache.hadoop.security.UserGroupInformation;public class ImpalaKdc {private static String driver = "com.cloudera.impala.jdbc.Driver";public static void main(String[] args) throws Exception {String jdbcUrl="jdbc:impala://cm2:21050/db1;AuthMech=1;KrbRealm=EXAMPLE.COM;KrbHostFQDN=cm2.cdh;KrbServiceName=impala";String configPath="E:\\tmp\\krb5.conf";String keyTabPath="E:\\tmp\\impala.keytab";Connection conn=getImapalaAuthConnection(jdbcUrl,"impala/cm2.cdh",configPath,keyTabPath);System.out.println(conn);queryTable(conn);}private static Connection getImapalaAuthConnection(String jdbcUrl,String username,String configPath,String keyTabPath)throws Exception{
// System.setProperty("java.security.krb5.conf", configPath);Connection connection = null;try{org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration(); conf.set("hadoop.security.authentication", "Kerberos");UserGroupInformation.setConfiguration(conf); UserGroupInformation.loginUserFromKeytab(username, keyTabPath);connection = UserGroupInformation.getLoginUser().doAs(new PrivilegedAction<Connection>(){@Overridepublic Connection run(){Connection connection = null;try{Class.forName(driver);connection = DriverManager.getConnection(jdbcUrl);}catch (Exception e){e.printStackTrace();}return connection;}});}catch (Exception e){throw e;}return connection;}public static void queryTable(Connection conn) {String querySql="select * from test_user1";
// PreparedStatement ps=conn.prepareStatement(querySql);Statement st;try {st = conn.createStatement();ResultSet rs=st.executeQuery(querySql);while(rs.next()) {System.out.print (rs.getString(1));System.out.print (rs.getString(2));System.out.print (rs.getString(3));System.out.println (" ");}rs.close();} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(conn!=null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}
}相关文章:
impala与kudu进行集成
文章目录 概要Kudu与Impala整合配置Impala内部表Impala外部表Impala sql操作kuduImpala jdbc操作表如果使用了Hadoop 使用了Kerberos认证,可使用如下方式进行连接。 概要 Impala是一个开源的高效率的SQL查询引擎,用于查询存储在Hadoop分布式文件系统&am…...
链表经典算法(+OJ刷题)
文章目录 前言一、移除链表元素二、链表的中间节点三.反转链表四.合并两个有序链表五.分割链表六.环形链表的约瑟夫问题总结 创作不易,点赞收藏一下呗!!! 前言 在上一节,我们介绍了单链表的增,删ÿ…...
)
网络原理TCP/IP(4)
文章目录 面向字节流粘包问题异常情况TCP小结 面向字节流 创建⼀个TCP的socket,同时在内核中创建⼀个发送缓冲区和⼀个接收缓冲区; • 调⽤write时,数据会先写⼊发送缓冲区中; • 如果发送的字节数太⻓,会被拆分成多个TCP的数据包发出; • 如果发送的字节数太短,就会先在缓…...

【C/C++ 11】贪吃蛇游戏
一、题目 贪吃蛇游戏机制是通过控制蛇上下左右移动并吃到食物得分。 蛇头碰到墙壁或者碰到蛇身就游戏结束。 食物随机生成,蛇吃到食物之后蛇身变长,蛇速加快。 二、算法 1. 初始化游戏地图并打印,地图的边缘是墙,地图的每个坐…...
相互转换)
【日常总结 - java】list 与 字符串(用逗号隔开)相互转换
一、list 转 字符串 第一种:使用谷歌Joiner方法 (推荐) 第二种:循环插入逗号 第三种:stream流 (推荐) 第四种:lambda表达式遍历并加入逗号 二、字符串 转 list 方法一:使用split()方法 方法二:使用C…...
《幻兽帕鲁》好玩吗?幻兽帕鲁能在Mac上运行吗?
最近一款叫做《幻兽帕鲁》的新游戏走红,成为了Steam游戏平台上,连续3周的销量冠军,有不少Mac电脑用户,利用Crossover成功玩上了《幻兽帕鲁》,其实Crossover已经支持很多3A游戏,包括《赛博朋克2077》《博德之…...

【数据分享】1929-2023年全球站点的逐日平均能见度(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、湿度等指标,说到常用的降水数据,最详细的降水数据是具体到气象监测站点的降水数据! 有关气象指标的监测站点数据,之前我们分享过1929-2023年全…...

浅谈——开源软件的影响力
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 ✨特色专栏:…...
MySQL-事务(TRANSACTION)
文章目录 1. 事务概述2. 事务的四大特性(ACID)3. 控制事务4. 并发事务产生的问题5. 事务的隔离级别6. 拓展6.1 InnoDB如何解决幻读?6.2 MySQL实现事务的原理? 1. 事务概述 定义:数据库的事务( Transaction…...

Vue 实现动态路由
Vue 实现动态路由 Vue中实现动态路由主要涉及到两个方面:一是路由的动态添加,二是基于路由的参数变化来动态渲染组件。这通常在使用Vue Router时进行配置和实现。以下是实现动态路由的一些基本步骤和概念: 安装和设置Vue Router npm insta…...
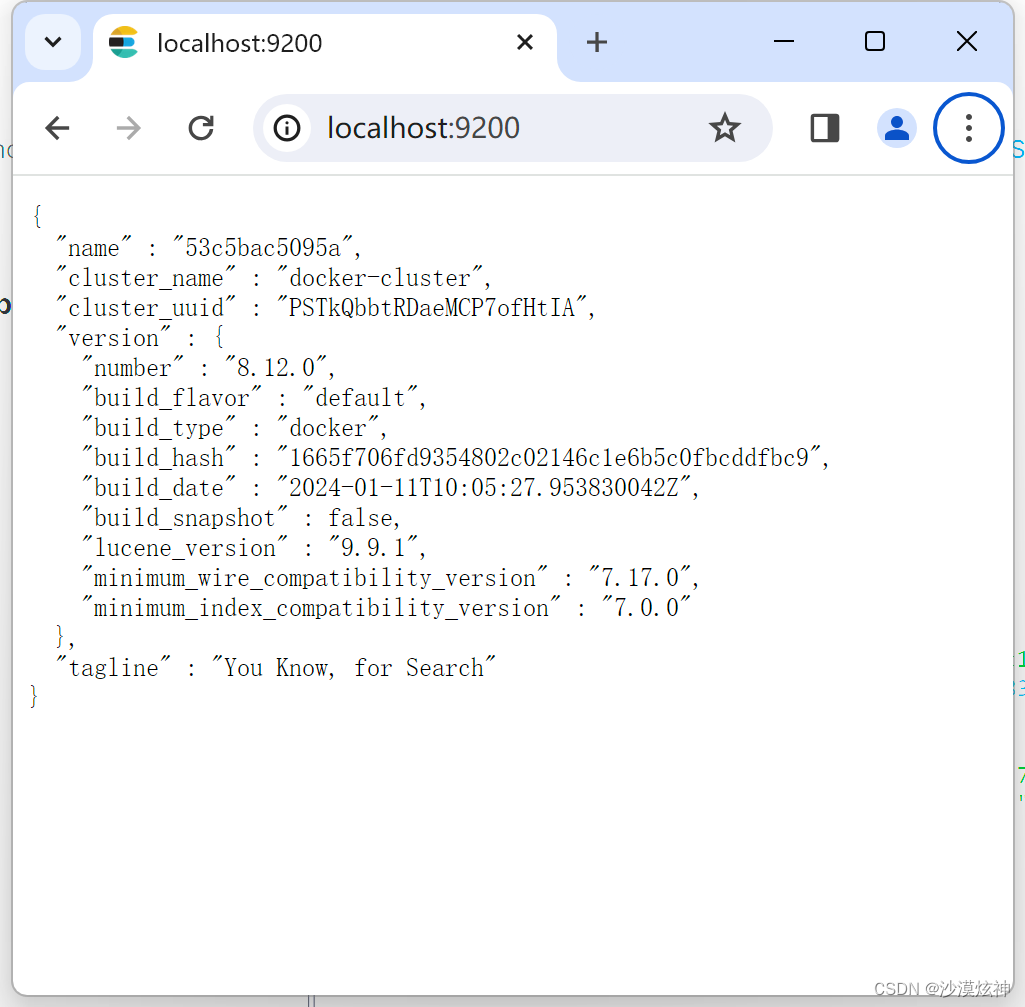
docker elasticsearch8启动失败
docker elasticsearch8.12.0启动后提示这个,并且始终无法访问localhost:9200 received plaintext http traffic on an https channel, closing connection Netty4HttpChannel 解决方案:重新创建 elasticsearch容器,加上 -e xpack.security.…...

《Python 网络爬虫简易速速上手小册》第1章:Python 网络爬虫基础(2024 最新版)
文章目录 1.1 网络爬虫简介1.1.1 重点基础知识讲解1.1.2 重点案例:社交媒体数据分析1.1.3 拓展案例1:电商网站价格监控1.1.4 拓展案例2:新闻聚合服务 1.2 网络爬虫的工作原理1.2.1 重点基础知识讲解1.2.2 重点案例:股票市场数据采…...
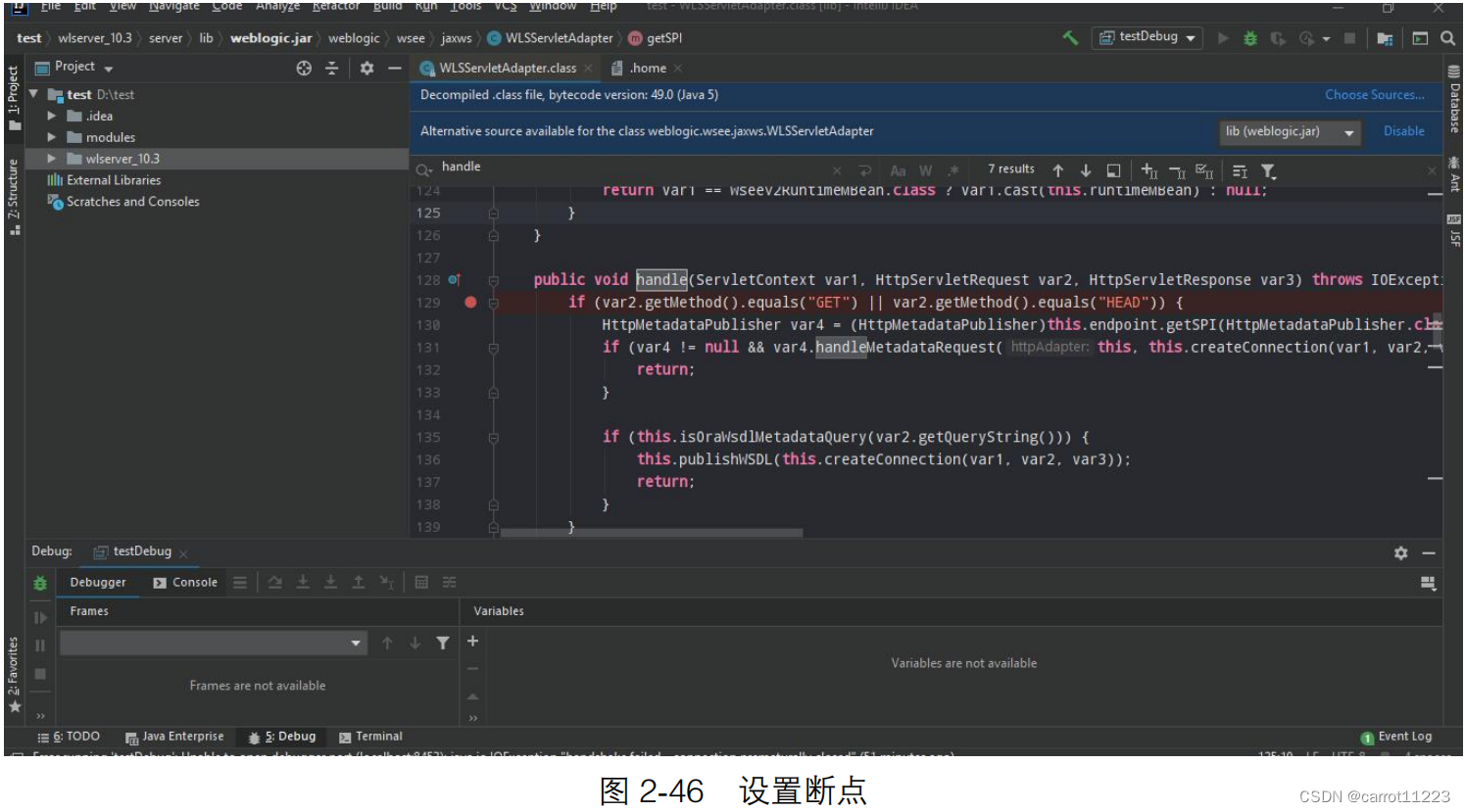
使用 IntelliJ IDEA 配合 Docker 对 Weblogic 中间件进行远程调试
使用idea对jar包远程调试: 打开一个springboot的项目进行远程调试设置: 运行: 其实我不太明白远程调试的意义,本地直接debug不好嘛。。。 点击debug的按钮,打断点测试: 跑到断点处: 远程de…...
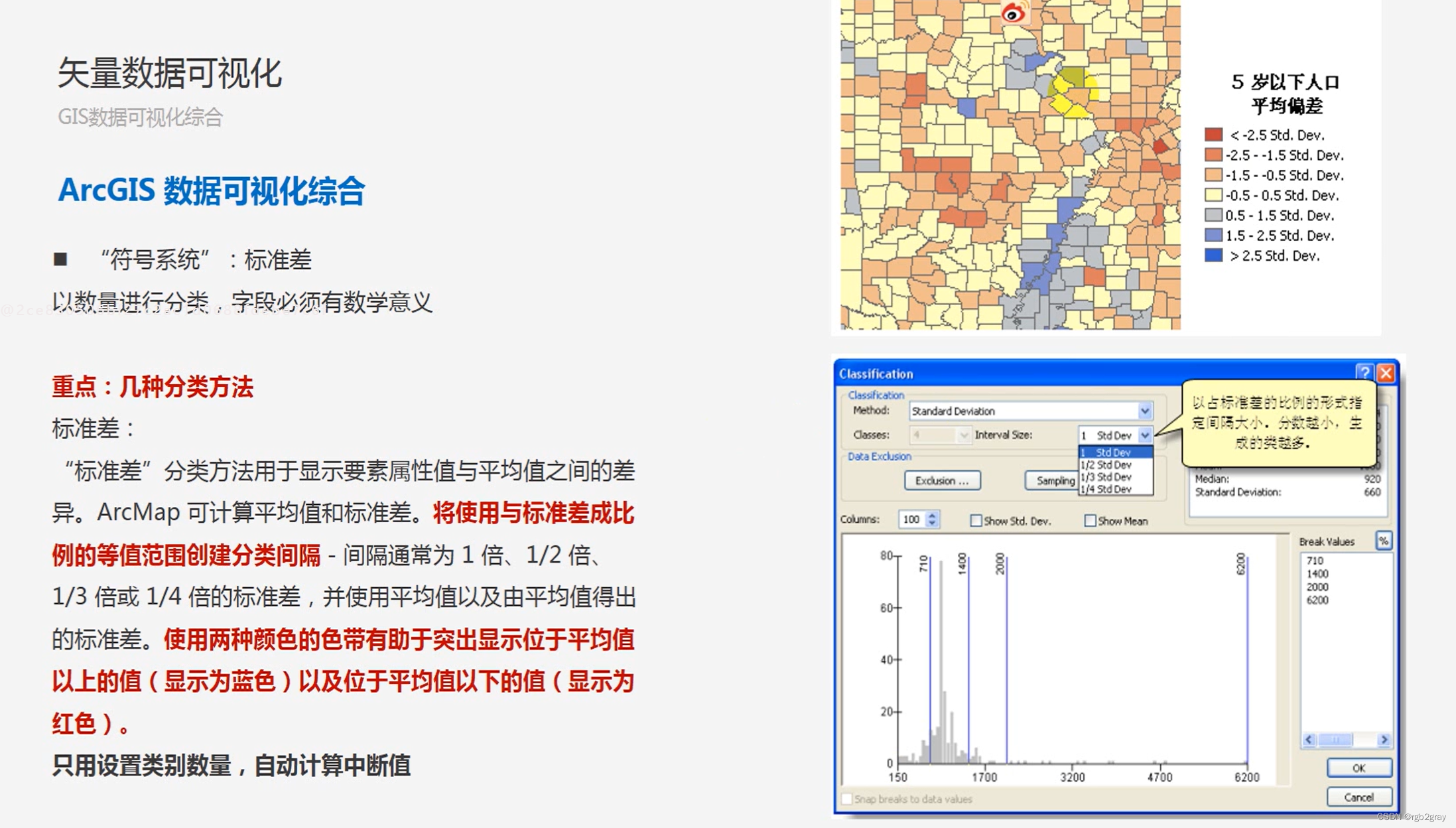
ArcGIS学习(三)数据可视化
ArcGIS学习(三)数据可视化 1.矢量数据可视化 需要提前说明的是,在ArcGIS中,所有的可视化选项设置都是在“图层属性”对话框里面的“符号系统”中实现的。 对于矢量数据的可视化,主要有四种可视化方式: 按“要素”可视化按“类别”可视化按“数量”可视化按“图表”可视…...

【使用 Python 进行 NLP】 第 2 部分 NLTK
一、说明 Python 有一些非常强大的 NLP 库,NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推理。…...
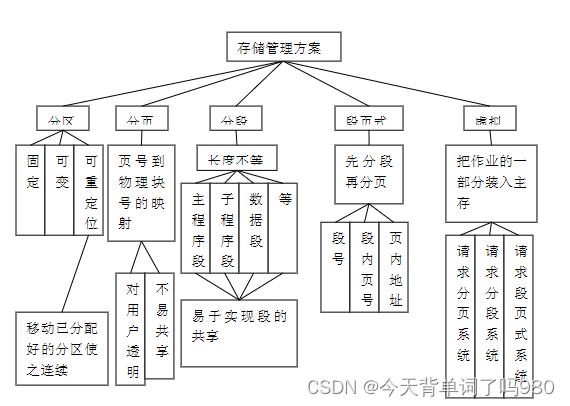
【软件设计师笔记】深入探究操作系统
【软件设计师笔记】计算机系统基础知识考点(传送门) 💖 【软件设计师笔记】程序语言设计考点(传送门) 💖 🐓 操作系统的作用 1.通过资源管理提高计算机系统的效率 2.改善人机界面向用户提供友好的工作环境 🐓 操作系统的特征 …...

python常用pandas函数nlargest / nsmallest及其手动实现
目录 pandas库 Series和DataFrame nlargest和nsmallest 用法示例 代替方法 手动实现 模拟代码 pandas库 是Python中一个非常强大的数据处理库,提供了高效的数据分析方法和数据结构。它特别适用于处理具有关系型数据或带标签数据的情况,同时在时间序列分析方面也有着出…...
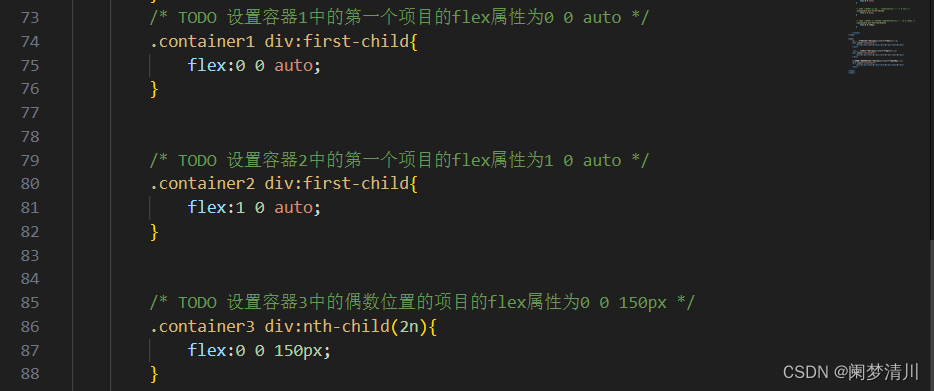
web前端-------弹性盒子(2)
上一讲我们谈的是盒子的容器实行,今天我们来聊一聊弹性盒子的项目属性; *******************(1)顺序属性 order属性,用于定义容器中项目的出现顺序。 顺序属性值,为整数,可以为负数ÿ…...
图论练习4
内容:染色划分,带权并查集,扩展并查集 Arpa’s overnight party and Mehrdad’s silent entering 题目链接 题目大意 个点围成一圈,分为对,对内两点不同染色同时,相邻3个点之间必须有两个点不同染色问构…...
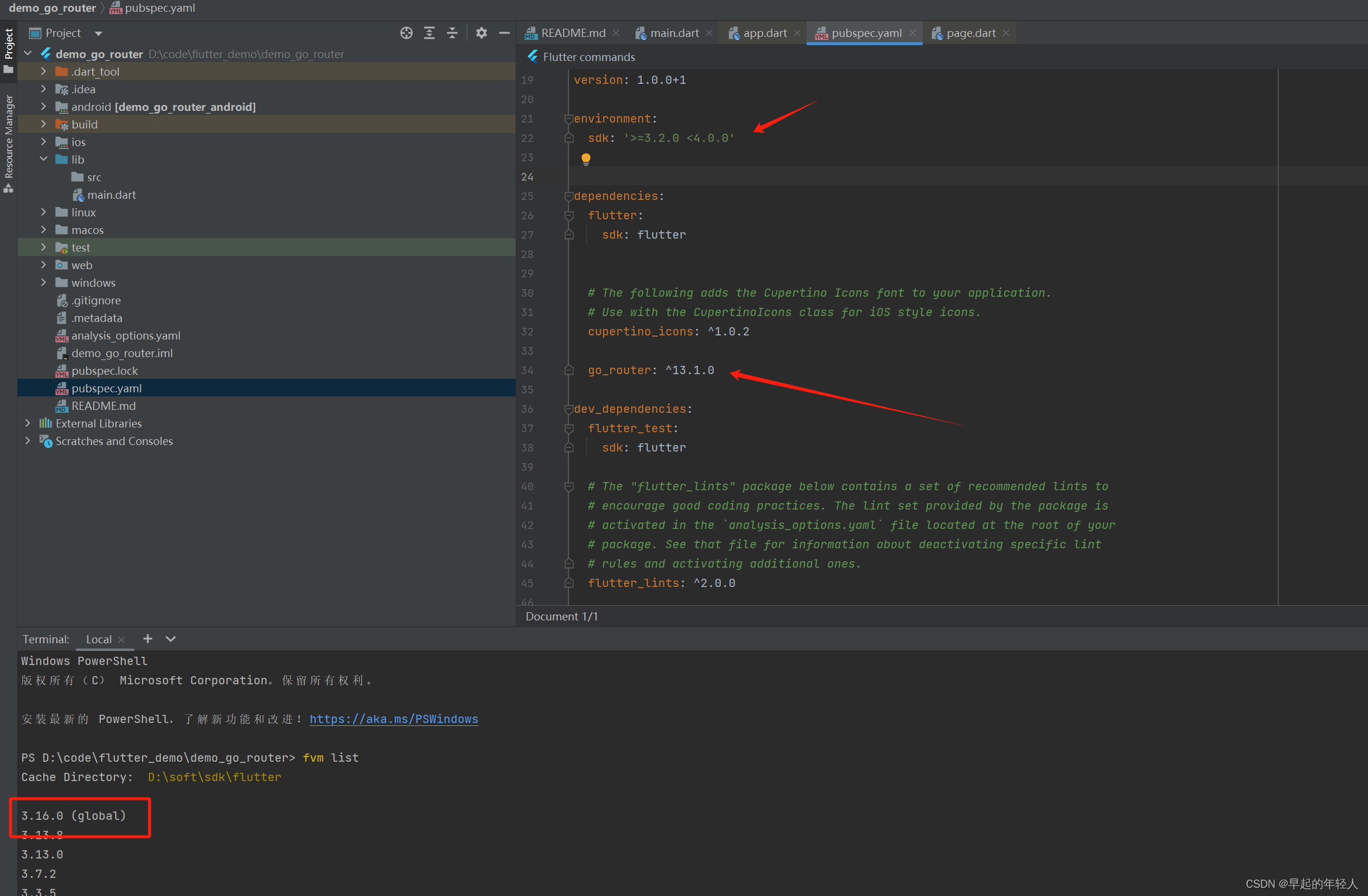
flutter go_router 官方路由(一)基本使用
1 项目中添加最新的依赖 go_router: ^13.1.0如下图所示,我当前使用的flutter版本为3.16.0 然后修改应用的入口函数如下: import package:flutter/material.dart; import package:go_router/go_router.dart;void main() {runApp(const MyApp()); }cla…...

sing-box性能调优:从内存占用到吞吐量的全面优化
sing-box性能调优:从内存占用到吞吐量的全面优化 引言 sing-box作为通用代理平台(The universal proxy platform),在高并发网络环境下的性能表现直接影响用户体验。本文将从内存管理、连接复用、吞吐量优化三个维度,…...

高效安装BetterNCM:零基础用户的插件管理指南
高效安装BetterNCM:零基础用户的插件管理指南 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否曾因网易云音乐插件安装步骤繁琐而放弃个性化体验?BetterNC…...

Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南
Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南 【免费下载链接】leptonai A Pythonic framework to simplify AI service building 项目地址: https://gitcode.com/gh_mirrors/le/leptonai Lepton AI是一个Pythonic框架,专门用于简化AI…...

医疗数据增强技巧:提升MedGemma在小数据集上的表现
医疗数据增强技巧:提升MedGemma在小数据集上的表现 1. 引言 当你手头只有几百张医疗影像数据,却要训练一个强大的MedGemma模型时,会不会觉得这是个不可能完成的任务?别担心,这恰恰是很多医疗AI开发者面临的真实困境。…...

apache-dolphinscheduler-3.4.1调度器配置虚拟机
1、下载文件3.4.1下载安装包https://mirrors.tuna.tsinghua.edu.cn/apache/dolphinscheduler/3.4.1/ 2、传到虚拟机/home/spark2下 3、解压并重命名 4、初始化 MySQL 数据库 (1)启动 MySQL 服务 (2)登录 MySQL(输入 r…...

BERT文本分割模型5分钟快速部署:零基础搭建智能分段工具
BERT文本分割模型5分钟快速部署:零基础搭建智能分段工具 1. 引言:告别文字“墙”,让长文本秒变清晰段落 你有没有过这样的经历?辛辛苦苦听完一场两小时的线上会议,语音转文字工具生成了一份上万字的逐字稿。你满怀期…...

REX-UniNLU在SpringBoot项目中的集成指南
REX-UniNLU在SpringBoot项目中的集成指南 1. 引言 如果你正在开发一个需要理解中文文本的SpringBoot应用,比如要做智能客服、内容分析或者自动分类,那么REX-UniNLU可能会是个不错的选择。这是一个专门为中文设计的自然语言理解模型,不需要训…...

计算机网络核心:OSI/RM七层模型与TCP/IP模型详解——软件设计师备考指南
目录 一、OSI/RM七层模型(开放式系统互联参考模型) 二、TCP/IP模型(传输控制协议/网际协议模型) 三、常用网络协议详解(含默认端口、功能及特殊说明) 四、总结 非 VIP 用户可前往公众号“前端基地”进行免费阅读,文章链接如下: 计算机网络核心:OSI/RM七层模型与T…...

忍者像素绘卷部署教程:Ubuntu 22.04+PyTorch 2.1环境完整搭建步骤
忍者像素绘卷部署教程:Ubuntu 22.04PyTorch 2.1环境完整搭建步骤 1. 环境准备与系统要求 在开始部署忍者像素绘卷之前,请确保您的系统满足以下最低要求: 操作系统:Ubuntu 22.04 LTS(推荐)或更高版本显卡…...

基于GTE模型的新闻推荐系统:个性化内容分发实践
基于GTE模型的新闻推荐系统:个性化内容分发实践 1. 引言 每天打开新闻应用,你是否经常看到一堆完全不感兴趣的内容?或者发现推荐的文章总是那几类,缺乏新鲜感?传统的新闻推荐系统往往基于简单的关键词匹配或热门排行…...