PySpark(二)RDD基础、RDD常见算子
目录
RDD
RDD五大特性
RDD创建
RDD算子
常见的Transformation算子
map
flatMap
mapValues
reduceByKey
groupBy
filter
distinct
union
join
intersection
glom
groupByKey
groupByKey和reduceByKey的区别 ?
sortBy
sortByKey
常见的action算子
countByKey
collect
reduce
fold
first、take、top、count
takeSample
takeOrdered
foreach
saveAsTextFile
分区操作算子
mapPartitions
foreachPartition
partitionBy
repartition、coalesce
RDD
RDD定义 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
RDD五大特性
1、 RDD是有分区的
RDD分区是RDD存储数据的最小单位,一份RDD数据实际上是被分成了很多分区
RDD是逻辑的抽象概念,而分区是真实存在的物理概念
代码演示:
print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3).glom().collect())print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 6).glom().collect())
# [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# [[1], [2, 3], [4], [5, 6], [7], [8, 9]]2、RDD方法会作用在所有分区之上
例如map算子会作用在所有的分区上面
print(sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 6).map(lambda x:x*10).glom().collect())
# [[10], [20, 30], [40], [50, 60], [70], [80, 90]]3、RDD之间有依赖关系
以下面的例子为例,rdd是相互依赖的,例如rdd2依赖于rdd1,会行成一个依赖链条
rdd1 -> rdd2 -> rdd3 -> rdd4 -> rdd5
rdd1 = sc.textFile("hdfs://node1:8020/test.txt")rdd2 = rdd1.flatMap(lambda line: line.split(" "))rdd3 = rdd2.map(lambda x: (x,1))rdd4 = rdd3.reduceByKey(lambda a,b:a+b)rdd5 = rdd4.collect()4、Key-Value型的RDD可以有分区器
5、RDD的分区规划会尽量靠近数据所在的服务器
在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到 存储数据所在的服务器上因为这样可以走本地读取,避免网络读取
本地读取: Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可 无需走网络传输网络读取:读取数据需要经过网络的传输才能读取到
本地读取性能>>>网络读取的
总结,Spark会在确保并行计算能力的前提下,尽量确保本地读取,这里是尽量确保而不是100%确保
RDD创建
有两种创建方式:
• 通过并行化集合创建( 本地对象转分布式RDD )
rdd = sc.parallelize(参数1,参数2)
参数1:可迭代对象,例如list
参数2:分区数量,int ,这个参数可以不设置,会根据CPU设置分区数量,可以通过下面这个语句查看此RDD的分区数量
print(rdd.getNumPartitions())
• 读取外部数据源( 读取文件)
sparkcontext.textFile(参数1,参数2)#参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如S3协议
#参数2,可选,表示最小分区数量
# 注意: 参数2 话语权不足,spark有自己的判断,在它允许的范围内,参数2有效果,超出spark允许的范围,:参数2失效
wholeTextFile是另外一种读取文件的APl,适合读取一堆小文件
sparkcontext.wholeTextFies(参数1,参数2)# 参数1,必填,文件路径 支持本地文件 支持HDFS 也支持一些比如如S3协议
# 参数2,可选,表示最小分区数量
注意: 参数2 话语权不足,这个API 分区数量最多也只能开到文件数量#
这个API偏向于少量分区读取数据,因为,这个API表明了自己是小文件读取专用,那么文件的数据很小分区很多,导致shuffle的几率更高 所以尽量少分区读取数据
RDD算子
RDD的算子分成2类:Transformation:转换算子、Action:动作(行动)算子
Transformation算子
定义:RDD的算子返回值仍旧是一个RDD的称之为转换算子特性:
这类算子是lazy 懒加载的.如果没有action算子,Transformation算子是不工作的
Action算子
定义:返回值 不是rdd 的就是action算子
对于这两类算子来说Transformation算子,相当于在构建执行计划,action是一个指令让这个执行计划开始工作
说白了,如果没有action算子,则Transformation算子不执行
常见的Transformation算子
map
对每个元素进行一个映射转换,生成新的rdd
可以使用匿名函数或函数名参数的方式调用
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]).map(lambda x:x+10)print(rdd.collect())# [11, 12, 13, 14, 15, 16, 17, 18, 19]def change(data):return (data+10)*3rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]).map(change)print(rdd.collect())# [33, 36, 39, 42, 45, 48, 51, 54, 57]flatMap
transformation类算子,map之后将新的rdd中的元素解除嵌套
rdd = sc.parallelize(['one two three','a b c','1 2 3']).map(lambda x:x.split(' '))
print(rdd.collect())
rdd2 = sc.parallelize(['one two three','a b c','1 2 3']).flatMap(lambda x:x.split(' '))
print(rdd2.collect())
# [['one', 'two', 'three'], ['a', 'b', 'c'], ['1', '2', '3']]
# ['one', 'two', 'three', 'a', 'b', 'c', '1', '2', '3']mapValues
针对二元元祖的value进行map操作:
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])rdd2 = rdd.mapValues(lambda x:x+10)print(rdd2.collect())# [('a', 11), ('b', 12), ('c', 13), ('b', 12), ('b', 12), ('a', 11)]reduceByKey
功能: 针对KV型 RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value) 的聚合操作。
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])rdd2 = rdd.reduceByKey(lambda a,b :a+b)print(rdd2.collect())# [('a', 2), ('b', 6), ('c', 3)]内部逻辑是累加方式实现的,首先其先按照key进行分组,即分成了a , b, c三组,以b组为例,有三个(b,2),则采用累加,先两个相加得到4,再4+2得到6
同理,使用别的逻辑也是累次的形式,也可以使用函数:
def change(a,b):return (a+b)*3rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])rdd2 = rdd.reduceByKey(change)print(rdd2.collect())# [('a', 6), ('b', 42), ('c', 3)]groupBy
将rdd数据按照提供的依据分组
例如,对元祖的第一个元素进行分组
rdd = sc.parallelize([('a',1),('b',2),('c',3),('b',2),('b',2),('a',1)])rdd2 = rdd.groupBy(lambda x:x[0])print(rdd2.collect())# [('a', < pyspark.resultiterable.ResultIterable object at 0x7fb2f21219d0 >),# ('b', < pyspark.resultiterable.ResultIterable object at 0x7fb2f2121be0 >),# ('c', < pyspark.resultiterable.ResultIterable object at 0x7fb2f2121ca0 >)]可以看到按照第一个元素分成了a,b,c三组,但是其value值变成了一个对象
可以强制转换出value:
print(rdd2.map(lambda x: (x[0], list(x[1]))).collect())# [('a', [('a', 1), ('a', 1)]), ('b', [('b', 2), ('b', 2), ('b', 2)]), ('c', [('c', 3)])]filter
将数据进行过滤,传入一个函数,其返回值必须为 true 或 false
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])rdd2 = rdd.filter(lambda x:x<6)print(rdd2.collect())# [1, 2, 3, 4, 5]distinct
去除
rdd = sc.parallelize([1,1,2,4,5,1,3,8,2])rdd2 = rdd.distinct()print(rdd2.collect()) # [1, 2, 4, 5, 3, 8]union
RDD数据合并,但是不去重
rdd = sc.parallelize([1,2,3,3,8,2])rdd2 = sc.parallelize(['a','v','b'])rdd3 = rdd.union(rdd2)print(rdd3.collect())# [1, 2, 3, 3, 8, 2, 'a', 'v', 'b']join
rdd数据关联,这跟sql语句中的join的原理一样
rdd = sc.parallelize([(1,'a'),(2,'b'),(3,'c'),(4,'d')])rdd2 = sc.parallelize([(1,100),(2,300)])rdd3 = rdd.join(rdd2)print(rdd3.collect())rdd4 = rdd.leftOuterJoin(rdd2)print(rdd4.collect())# [(2, ('b', 300)), (1, ('a', 100))]# [(2, ('b', 300)), (4, ('d', None)), (1, ('a', 100)), (3, ('c', None))]intersection
取数据的交集
rdd = sc.parallelize([(1,'a'),(2,'b'),(3,'c'),(4,'d')])rdd2 = sc.parallelize([(1,'a'),(2,'b')])rdd3 = rdd.intersection(rdd2)print(rdd3.collect())# [(1, 'a'), (2, 'b')]glom
将RDD数据按照 分区 进行嵌套
rdd = sc.parallelize([1,2,3,4,5,6,7,8],3)rdd2 = rdd.glom()print(rdd2.collect())# [[1, 2], [3, 4], [5, 6, 7, 8]]groupByKey
对于KV型数据自动对KEY进行分组
rdd = sc.parallelize([('a', 1), ('b', 2), ('c', 3), ('b', 2), ('b', 2), ('a', 1)])rdd2 = rdd.groupByKey()print(rdd2.collect())# [('a', < pyspark.resultiterable.ResultIterable object at 0x7f27564fc7c0 >),# ('b', < pyspark.resultiterable.ResultIterable object at 0x7f27564fc9d0 >),# ('c', < pyspark.resultiterable.ResultIterable object at 0x7f27564fca90 >)]rdd3 = rdd2.map(lambda x:(x[0],list(x[1])))print(rdd3.collect())# [('a', [1, 1]), ('b', [2, 2, 2]), ('c', [3])]groupByKey和reduceByKey的区别 ?
在功能上的区别:
groupByKey仅仅有分组功能而已
reduceByKey除了有ByKey的分组功能外,还有reduce聚合功能.所以是一个分组+聚合一体化的算子.
当面临一个 分组加聚合 的操作时,有两种选择,一是使用 groupByKey后在使用别的算子计算,二是直接使用reduceByKey,其性能上有很大差别。
第一种方法是先分组,然后再计算,那么每个数据都要单独的进行io传输计算,例如下面这个例子,a数据需要传6次到下面,再计算(a,6)
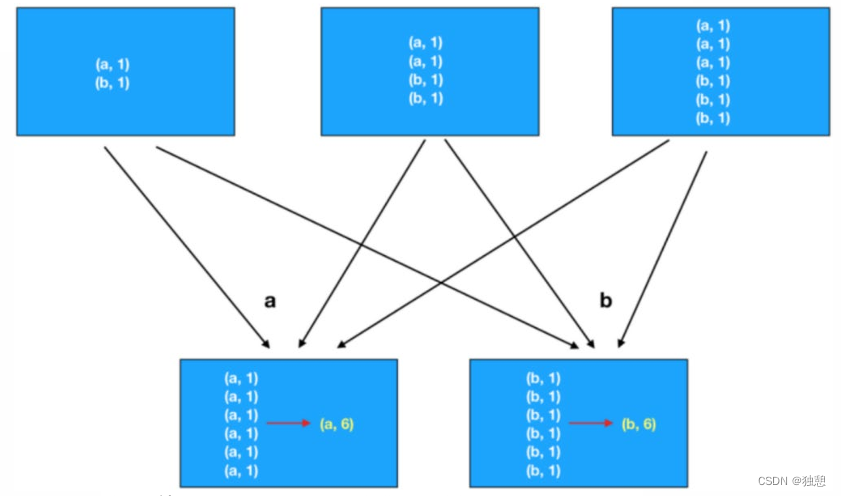
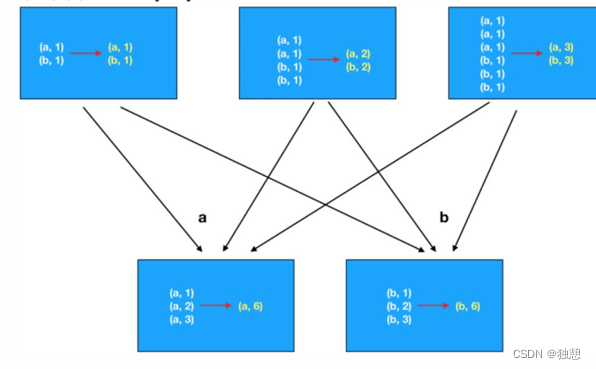
而第二种方式先在分区内做预聚合,然后再走分组流程(shuffle),分组后再做最终聚合,大大提升了性能
sortBy
按照规定的值排序,第一个参数为排序的根据,第二个值表示升序或降序,第三个值表示排序分区值
如果想要全局排序,最好将第三个值设定为1,否则可能会出现分区内排序,但是组合在一起乱序的可能
rdd = sc.parallelize([('a', 1), ('b',5), ('c', 7), ('b', 2), ('b',9), ('a', 1)])rdd2 = rdd.sortBy(lambda x:x[1],ascending=True,numPartitions=1)print(rdd2.collect())# [('a', 1), ('a', 1), ('b', 2), ('b', 5), ('c', 7), ('b', 9)]sortByKey
针对二元元祖排序,根据为key
有三个参数,前面两个跟上面一样,keyfunc表示对key的处理函数
rdd = sc.parallelize([('a', 1), ('b',5), ('A', 7), ('C', 2), ('b',9), ('a', 1)])rdd2 = rdd.sortByKey(ascending=True,numPartitions=1, keyfunc=lambda key:str(key).lower())print(rdd2.collect())# [('a', 1), ('A', 7), ('a', 1), ('b', 5), ('b', 9), ('C', 2)]常见的action算子
action算子的返回值不是rdd
countByKey
按照key进行计数
rdd = sc.parallelize([('a',1),('a',1),('a',1),('b',1)])result = rdd.countByKey()print(result)print(type(result))# defaultdict( <class 'int'>, {'a': 3, 'b': 1})# <class 'collections.defaultdict'>collect
这个算子是将RDD各个分区数据都拉取到Driver
注意的是,RDD是分布式对象,其数据量可以很大,所以用这个算子之前要心知肚明的了解结果数据集不会太大,不然会把Driver内存撑爆
reduce
类似于reduceByKey的逻辑操作,也是以累次的方式实现
rdd = sc.parallelize([1,2,3,4,5,6,7,9])result = rdd.reduce(lambda a,b :a+b)print(result)# 37fold
和reduce一样也是累次的逻辑实现,区别是这个方法带有初始值,且在分区的情况下会多次作用
以下面这个例子为例,分成三个组
那么组内的计算为:1+2+3+10 = 16,4+5+6+10=25,7+9+10+10=36
组件的计算为:16+25+36+10 = 87
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10],3)print(rdd.glom().collect())result = rdd.fold(10,lambda a,b :a+b)print(result)# [[1, 2, 3], [4, 5, 6], [7, 9, 10]]# 87first、take、top、count
first:取出rdd的第一个元素
take:取出rdd的前n个元素
top:将rdd降序排列然后取出前n个元素
count:计算rdd有多少个元素
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])print(rdd.first())print(rdd.take(5))print(rdd.top(4))print(rdd.count())
# 1
# [1, 2, 3, 4, 5]
# [10, 9, 7, 6]
# 9takeSample
takeSample(参数1:True or False,参数2:采样数,参数3:随机数种子)
-参数1:True表示运行取同一个数据,False表示不允许取同一个数据.和数据内容无关,是否重复表示的是同一个位置的数-参数2:抽样数量
-参数3︰随机数种子
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])print(rdd.takeSample(True, 13))print(rdd.takeSample(False, 13))# [7, 2, 7, 4, 6, 4, 1, 6, 6, 7, 7, 7, 3]# [9, 1, 10, 4, 7, 5, 3, 2, 6]takeOrdered
rdd.take0rdered(参数1,参数2)
-参数1要几个数据
-参数2对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法使用按照元素自然顺序升序排序,如果想玩倒叙,需要用参数2来对排序的数据进行处理
rdd = sc.parallelize([1,2,3,4,5,6,7,9,10])print(rdd.takeOrdered(3))print(rdd.takeOrdered(3, lambda x:-x))# [1, 2, 3]# [10, 9, 7]foreach
跟map类似,对每一个元素做处理,但是没有返回值
值得注意的是,大部分算子都需要将结果返回到driver再输出,而foreach则是直接由executor输出的
rdd = sc.parallelize([1,2,3,4,5])rdd.foreach(lambda x:print(x+10))# 11# 12# 13# 14# 15saveAsTextFile
保存文件为text,n个分区就会生成n个文件
这个也是executor直接生成文件
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)rdd.saveAsTextFile('data/output/out1')分区操作算子
mapPartitions
功能和map一样,但是map是对每一个元素都进行计算和IO,但是mapPartitions是对一个分区计算完之后再整体IO
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)def process(iter):result = []for i in iter:result.append(i+10)return resultprint(rdd.mapPartitions(process).collect())# [11, 12, 13, 14, 15, 16, 17, 18, 19]foreachPartition
跟foreach类似,区别是整体处理
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)def process(iter):result = []for i in iter:result.append(i+10)print(result)rdd.foreachPartition(process)# [11, 12, 13]# [14, 15, 16]# [17, 18, 19]partitionBy
默认的分区方式是根据HASH算子决定的,而这个算子能对分区进行人为规定
例如下面这个例子,我希望key为a的分一组,其他分一组
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)])def process(k):if k=='a':return 0else:return 1print(rdd.partitionBy(2, process).glom().collect())# [[('a', 1), ('a', 3), ('a', 6)], [('b', 1), ('b', 2), ('c', 1)]]repartition、coalesce
repartition对RDD数据重新分区,仅仅针对分区数量
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)print(rdd.glom().collect())print(rdd.repartition(2).glom().collect())# [[('a', 1), ('a', 3)], [('a', 6), ('b', 1)], [('b', 2), ('c', 1)]]# [[('b', 2), ('c', 1)], [('a', 1), ('a', 3), ('a', 6), ('b', 1)]]注意:对分区的数量进行操作,一定要慎重
一般情况下,我们写Spark代码除了要求全局排序设置为1个分区外多数时候,所有API中关于分区相关的代码我们都不太理会.
因为,如果你改分区了会影响并行计算(内存迭代的并行管道数量),分区如果增加,极大可能导致shuffle
初次之外,coalesce也可以完成这个功能,但是其多了一个安全机制,如果要增加分区,则必须设置 shuffle= True
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)print(rdd.coalesce(2).getNumPartitions())print(rdd.coalesce(4).getNumPartitions())print(rdd.coalesce(4,shuffle=True).getNumPartitions())# 2# 3# 4相关文章:
PySpark(二)RDD基础、RDD常见算子
目录 RDD RDD五大特性 RDD创建 RDD算子 常见的Transformation算子 map flatMap mapValues reduceByKey groupBy filter distinct union join intersection glom groupByKey groupByKey和reduceByKey的区别 ? sortBy sortByKey 常见的action算子 countByKey…...
修改MFC图标
摘要:本文主要讲解了MFC程序窗口图标的添加、任务栏、底部托盘的图标添加,以及所生成的exe文件图标的添加。 1、在资源视图添加Icon资源 透明图标怎么制作? 1)点击图片》右键:使用画图3D进行编辑 2&a…...
springboot158基于springboot的医院资源管理系统
简介 【毕设源码推荐 javaweb 项目】基于springbootvue 的 适用于计算机类毕业设计,课程设计参考与学习用途。仅供学习参考, 不得用于商业或者非法用途,否则,一切后果请用户自负。 看运行截图看 第五章 第四章 获取资料方式 **项…...

【算法】枚举——蓝桥杯、日期统计、特殊日期(位数之和)、2023、特殊日期(倍数)、跑步锻炼
文章目录 蓝桥杯日期统计特殊日期(位数之和)2023特殊日期(倍数)跑步锻炼 蓝桥杯 日期统计 日期统计 如果暴力枚举100个数的八次循环那就是1016次运算,时间复杂度太高了,好在前四次的2023是确定的…...
基于flask的个人博客项目从0到1
项目展示(持续完善中…) 首页 文章时间线页面 笔记页面 留言页面 关于页面 后台页面-文章管理 后台页面-笔记页面 后台页面-分类 后台管理-新增标签 后台管理-标签页面 后台管理-新增标签 后台管理-关于页面 2.项目详述 该博客开源地址点击跳转,该项目已部署上…...

基于OpenCV灰度图像转GCode的单向扫描实现
基于OpenCV灰度图像转GCode的单向扫描实现 引言单向扫描存在的问题灰度图像单向扫描代码示例结论 系列文章 ⭐深入理解G0和G1指令:C中的实现与激光雕刻应用⭐基于二值化图像转GCode的单向扫描实现⭐基于二值化图像转GCode的双向扫描实现⭐基于二值化图像转GCode的…...

JAVA生成Word文档
第一步:导入依赖 <!--生成word文档--> <dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.10.3</version> </dependency> <!--数字转为汉字大写--> <depend…...

python将.db数据库文件转成Excel文档
python实现.db数据库转Excel 程序实现 上一篇文章程序实现以下功能: 1.读取一个Excel文件,文件名通过函数传参数传入 2.将文件读取的内容保存到一个数据库文件中 3.数据库的文件名以传入的Excel文件的文件名命名 4.将excel文件的工作簿的名字作为数据库的表单名 5…...

[opencvsharp]C#基于Fast算法实现角点检测
角点检测算法有很多,比如Harris角点检测、Shi-Tomas算法、sift算法、SURF算法、ORB算法、BRIEF算法、Fast算法等,今天我们使用C#的opencvsharp库实现Fast角点检测 【算法介绍】 fast算法 Fast(全称Features from accelerated segment test)是一种用于角…...
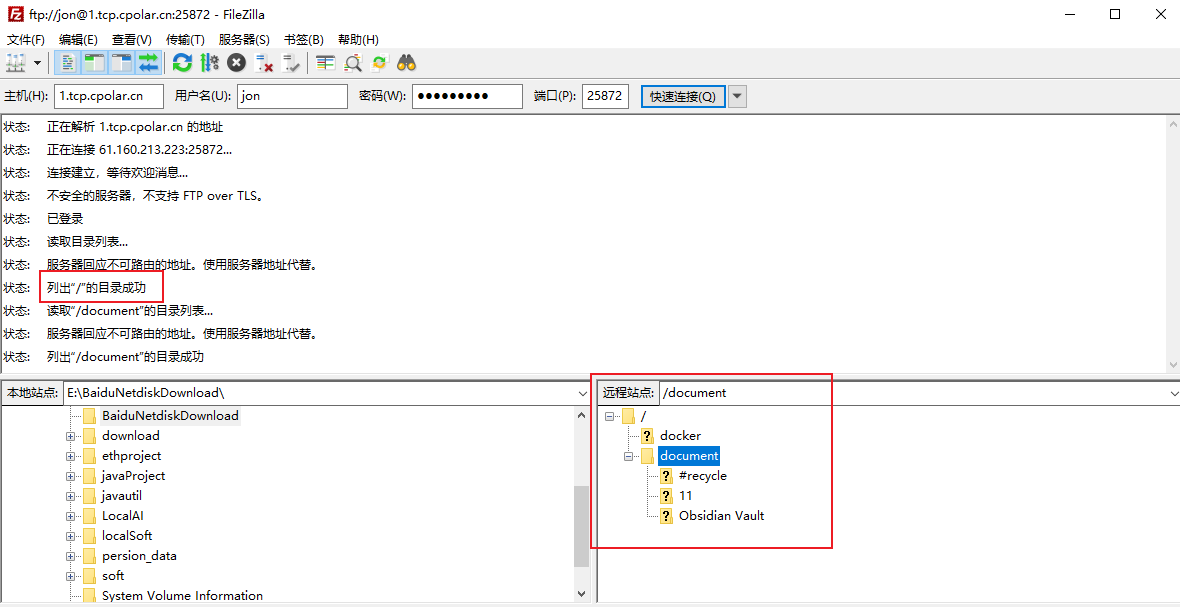
群晖NAS开启FTP服务结合内网穿透实现公网远程访问本地服务
⛳️ 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 文章目录 ⛳️ 推荐1. 群晖安装Cpolar2. 创建FTP公网地址3. 开启群晖FTP服务4. 群晖FTP远程连接5. 固定FTP公网地址6. 固定FTP…...

ReactNative实现弧形拖动条
我们直接看效果 先看下面的使用代码 <CircularSlider5step{2}min{0}max{100}radius{100}value{30}onComplete{(changeValue: number) > this.handleEmailSbp(changeValue)}onChange{(changeValue: number) > this.handleEmailDpd(changeValue)}contentContainerStyle{…...
STM32F407移植OpenHarmony笔记9
继上一篇笔记,已经完成liteos内核的基本功能适配。 今天尝试启动OHOS和XTS兼容性测试。 如何启动OHOS? OHOS系统初始化接口是OHOS_SystemInit(void),在内核初始化完成后,就能调用。 extern void OHOS_SystemInit(void); OHOS_Sys…...
telnet笔记
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、场景二、介绍1.测试端口2.访问百度3. 简单的爬虫 前言 最近telnet命令用的比较多,所以记录一下。 一、场景 ping应该是大家最常用的命令&…...

【考研408】操作系统笔记
文章目录 [toc] 计算机系统概述操作系统的基本概念操作系统的概念和特征操作系统的目标和功能(**处理器管理、存储器管理、设备管理、文件管理、向用户提供接口、扩充机器**) 操作系统的发展与分类操作系统的运行环境操作系统的运行机制 操作系统的体系结…...
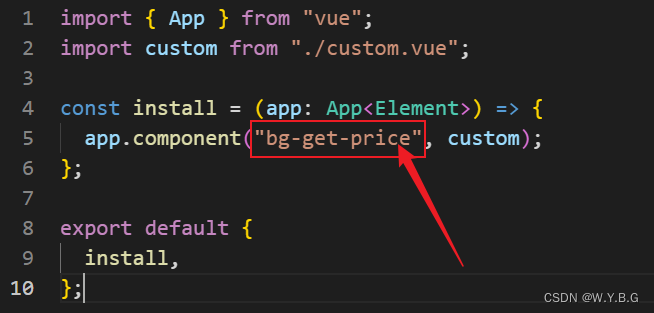
从0开始搭建、上传npm包
从0开始搭建、上传npm包 1、上传一个简单获取水果价格的包创建 vite 项目在项目根目录 src 文件夹中创建 index.ts 文件,文件内容如下:在 main.ts 文件中导入、导出上面创建的方法创建 vite.config.ts 配置文件,文件内容如下配置 package.jso…...

【Go】在 JSON 中解析 time.Duration
当解析 JSON 时,使用time.Duration可能是一个繁琐的过程,因为它需要在一秒的后面添加 9 个零(即 1000000000)。为了简化这个过程,我创建了一个名为 Duration 的新类型: type Duration time.Duration为了将…...
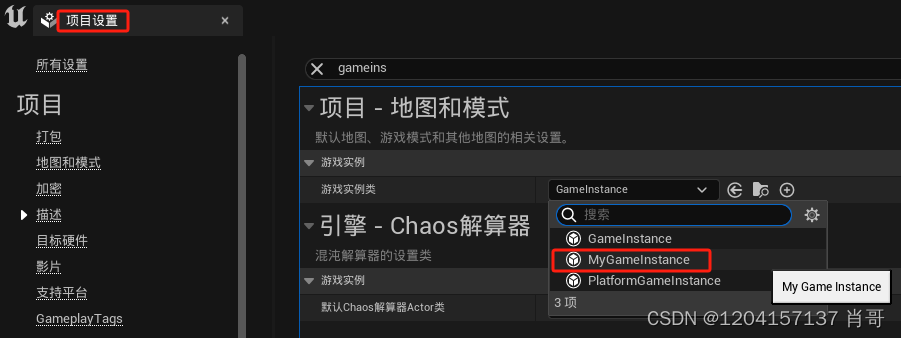
UE4 C++ UGameInstance实例化
1.创建GameInstance C类 2.在.h添加变量 class 工程名称_API UMyGameInstance : public UGameInstance {GENERATED_BODY()public: //定义了三个公开的变量UMyGameInstance();UPROPERTY(EditAnywhere, BlueprintReadWrite, Category "MyGameInstance")FString Name…...

在工业制造方面,如何更好地实现数字化转型?
实现工业制造的数字化转型涉及利用数字技术来增强流程、提高效率并推动创新。以下是工业制造领域更好实现数字化转型的几个关键步骤: 1.定义明确的目标: 清楚地概述您的数字化转型目标。确定需要改进的领域,例如运营效率、产品质量或供应链…...

【MySQL】-10 MySQL 存储过程
MySQL 存储过程 优点缺点一、存储过程的创建和调用创建存储过程实例1、in 输入参数2、out输出参数3、inout输入参数 三、变量1. 变量定义2. 变量赋值3. 用户变量 四、注释MySQL存储过程的调用MySQL存储过程的查询MySQL存储过程的修改MySQL存储过程的删除MySQL存储过程的控制语句…...

3.闭包 - JS
作用域 一般认为 JS 中作用域有三种: 全局作用域:一个脚本运行代码的默认作用域;模块作用域:一个模块运行代码的默认作用域;函数作用域:一个函数运行代码的默认作用域。 而由于 let/const 声明变量的作用…...

想找界面清爽操作直观的个人记账app?不妨看看这些实用分享
前阵子跟几个朋友聊起记录日常开支的事儿,一圈聊下来发现:10个人里有8个都试过整理日常收支,最后都放弃了。要么是打开app一堆乱七八糟的内容,找个记账按钮都要翻半天;要么是操作繁琐,买瓶水还要填一堆信息…...
,带你直击PyObject_NEW与PyMem_RawMalloc底层决策逻辑)
Python内存管理不再黑箱:手绘12张源码流程图(含PyMalloc arena分配/回收路径),带你直击PyObject_NEW与PyMem_RawMalloc底层决策逻辑
第一章:Python智能体内存管理策略源码分析Python智能体(如基于LangChain或LlamaIndex构建的Agent)在运行过程中常面临对象生命周期混乱、缓存冗余、引用泄漏等问题。其内存管理并非完全依赖CPython默认的引用计数与循环垃圾回收(G…...

革命性游戏模组管理平台:XXMI启动器带你告别繁琐配置,一键畅玩所有二次元游戏
革命性游戏模组管理平台:XXMI启动器带你告别繁琐配置,一键畅玩所有二次元游戏 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否曾经为了玩不同的二次…...

Hunyuan-MT-7B多场景实践:像素语言传送门在独立游戏开发、字幕生成、文档本地化中的三重应用
Hunyuan-MT-7B多场景实践:像素语言传送门在独立游戏开发、字幕生成、文档本地化中的三重应用 1. 像素语言传送门:当翻译遇见16-bit冒险 在独立游戏开发者的工作台上,一款名为"像素语言传送门"的工具正在改变传统翻译体验。这款基…...
对图片摘要质量影响分析)
Qwen3.5-9B-AWQ-4bit效果对比:不同温度值(0.0/0.7/1.2)对图片摘要质量影响分析
Qwen3.5-9B-AWQ-4bit效果对比:不同温度值(0.0/0.7/1.2)对图片摘要质量影响分析 1. 引言 在视觉理解任务中,温度参数(temperature)是影响模型输出质量的关键因素之一。本文将通过实际测试,展示…...
到镜像运行全链路)
Wan2.2-I2V-A14B保姆级教程:从云服务器选购(CPU/内存/磁盘)到镜像运行全链路
Wan2.2-I2V-A14B保姆级教程:从云服务器选购到镜像运行全链路 1. 前言:为什么选择私有部署 在当今视频内容需求爆炸式增长的时代,能够快速生成高质量视频内容的能力变得尤为重要。Wan2.2-I2V-A14B作为一款先进的文生视频模型,可以…...

终极SyntaxHighlighter CDATA处理指南:如何实现完美的XML兼容性
终极SyntaxHighlighter CDATA处理指南:如何实现完美的XML兼容性 【免费下载链接】syntaxhighlighter SyntaxHighlighter is a fully functional self-contained code syntax highlighter developed in JavaScript. 项目地址: https://gitcode.com/gh_mirrors/sy/s…...

AI绘画新体验:图图的嗨丝造相快速上手,轻松生成时尚渔网袜风格图片
AI绘画新体验:图图的嗨丝造相快速上手,轻松生成时尚渔网袜风格图片 1. 认识图图的嗨丝造相-Z-Image-Turbo 1.1 什么是嗨丝造相模型 图图的嗨丝造相-Z-Image-Turbo是一款专注于生成时尚渔网袜风格图片的AI绘画模型。它基于先进的图像生成技术ÿ…...

【QuantDev必藏】:为什么92%的C++交易系统仍在用malloc——深度剖析jemalloc/tcmalloc/mimalloc在L3缓存穿透场景下的失效临界点
第一章:金融高频交易系统内存分配的底层挑战与现实困境在纳秒级竞争的金融高频交易(HFT)场景中,内存分配不再是语言运行时的“黑盒服务”,而是决定订单延迟、吞吐一致性与系统可预测性的关键路径。传统堆分配器&#x…...

Token 成本暴跌 280 倍,为什么用 AI 替代初级开发,依然算不拢账?
从董事会的 PPT 翻车,看 AI 降本神话背后的全成本真相上周我旁听了一场 C-suite 高管会议,亲眼看着一位副总裁被自己的 PPT 逼入绝境。会议的主题是 AI 项目的成本收益,他准备了一套无懈可击的逻辑:大模型 Token 价格 3 年暴跌 28…...