Vision Transfomer系列第一节---从0到1的源码实现
本专栏主要是深度学习/自动驾驶相关的源码实现,获取全套代码请参考
这里写目录标题
- 准备
- 逐步源码实现
- 数据集读取
- VIt模型搭建
- hand
- 类别和位置编码
- 类别编码
- 位置编码
- blocks
- head
- VIT整体
- Runner(参考mmlab)
- 可视化
- 总结
准备

本博客完成Vision Transfomer(VIT)模型的搭建和flowers数据集的训练测试.整个源码包括如下几个任务:
1.读取flowers数据集的dataset类,对应文件dataset.py
2.VIT模型搭建,主要依赖于上几篇博客,对应model.py
1.transfomer中Multi-Head Attention的源码实现的MultiheadAttention类,用于搭建BaseTransformerLayer类,实现encoder和decoder功能
2.transfomer中Decoder和Encoder的base_layer的源码实现的BaseTransformerLayer类,帮助我们丝滑地搭建各类transformer网络
3.transfomer中正余弦位置编码的源码实现[可选]
3.设置优化器学习率和训练/验证模型,对应runner.py和train.py
4.可视化测试单个图片的预测结果,对应demo.py
逐步源码实现
源码结构如下

数据集读取
主要原理:根据dataset的路径,存储各个图片对应的路径,label隐藏在路径中.
在getitem函数中完成指定index图片和label的读取和数据增强功能
class Flowers(Dataset):# 用于读取flower数据集def __init__(self, dataset_path: str, transforms=None):'''存储所有数据 data路径和label:param dataset_path:'''super(Dataset, self).__init__()flowers = os.listdir(dataset_path)flowers = sorted(flowers) # 必须排序,否在每一次顺序不一样训练测试类别就会乱self.flower_paths = []self.class2label = {} # 类别str 转 labellabel = 0for _, flower in enumerate(flowers):flowers_path = os.path.join(dataset_path, flower)if os.path.isdir(flowers_path):self.class2label[flower] = labellabel +=1sub_flowers = os.listdir(flowers_path)for sub_flower in sub_flowers:self.flower_paths.append(os.path.join(flowers_path, sub_flower))self.label2class = label2class(self.class2label) # label 转 类别strself.transforms = transforms''''''def __getitem__(self, item):# 读取数据和labelimg = Image.open(self.flower_paths[item])label = self.class2label[self.flower_paths[item].split('/')[-2]]if self.transforms is not None:img = self.transforms(img) # 数据增强return img, label
VIt模型搭建
将整个深度学习模型按照人体分为hand+backbone+neck+head 4个部分,Vit模型不同CNN模型,它的backbone+neck为多个MultiHeadAttention堆叠组成,称之为blocks.
hand
hand主用完成预处理,将数据用"手"揉捏成想要的类型.本处主要完成图片的patch操作,将图片分割成一个个小块,使用大核的卷积完成.然后把w和h拉平后shape就和NLP(b,n,d)一样了.
class PatchLayer(nn.Module):def __init__(self, img_size, patch_size=20, embeding_dim=64):super(PatchLayer, self).__init__()self.grid_size = (img_size[0] // patch_size, img_size[1] // patch_size)self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_channels=3,out_channels=embeding_dim,kernel_size=(patch_size, patch_size),stride=patch_size,padding=0)self.norm = nn.LayerNorm(normalized_shape=embeding_dim)def forward(self, img):img = self.proj(img) # 图片分割img = img.flatten(start_dim=2) # wh拉平img = img.permute(0, 2, 1) # [b wh c]img = self.norm(img)return img
类别和位置编码
类别编码
直接cat到input上面,那么最后也取出对应的那一列作为类别输出.这是transformer类型网络的常用手段.
个人解释:训练出类别的访问者,这个访问者可以从特征信息(原input)中提取类别信息.训练访问者方法就是类别loss回归,训练时候先果推出因,推理时因推出果
位置编码
add到input上,可以使用可学习式的位置编码也可以使用正余弦位置编码.这是transformer类型网络的常用手段,还要特征层编码等
个人解释:训练出位置的标记者
# 类别编码self.cls_token = nn.Parameter(torch.zeros(size=[1, 1, embed_dim]))# 固定位置编码和可学习位置编码# self.pos_embed = posemb_sincos_1d(len=num_patches + 1, dim=embed_dim,temperature=1000).unsqueeze(0)self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
blocks
blocks使用注意力机制完成特征提取,
个人解释:
input线性映射为[query,key,value],需求侧(query)从供给侧(value)中取值,取值的根据是qurey@key转置生成的注意力矩阵(需求侧和供给侧每个像素之间的相似度),最后输出与输入shape相同.所以我们重复depth次,多次特征提取.
源码直接调用:transfomer中Decoder和Encoder的base_layer的源码实现的BaseTransformerLayer类
head
主要对transfomer输出的类别特征进行映射,embed维度映射为num_class维度
self.head = nn.Linear(embed_dim, num_classes)
VIT整体
主要是上述几个模块的集合及其正向传播过程:
完成二维图片变一维特征,一维特征transfomer特征提取,分类头输出.
class Vit(nn.Module):def __init__(self, img_size=[224, 224], patch_size=16, num_classes=1000,embed_dim=768, depth=12, num_heads=12):super(Vit, self).__init__()self.patch_embed = PatchLayer(img_size, patch_size, embed_dim)num_patches = self.patch_embed.num_patchesself.blocks = nn.Sequential(*[BaseTransformerLayer(attn_cfgs=[dict(embed_dim=embed_dim, num_heads=num_heads)],fnn_cfg=dict(embed_dim=embed_dim, feedforward_channels=4 * embed_dim, act_cfg='ReLU',ffn_drop=0.),operation_order=('self_attn', 'norm', 'ffn', 'norm'))for _ in range(depth)])# 类别编码self.cls_token = nn.Parameter(torch.zeros(size=[1, 1, embed_dim]))# 固定位置编码和可学习位置编码# self.pos_embed = posemb_sincos_1d(len=num_patches + 1, dim=embed_dim,temperature=1000).unsqueeze(0)self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))# 分类头self.head = nn.Linear(embed_dim, num_classes)self.loss_class = nn.CrossEntropyLoss() # 内置softmaxself.init_weights()''''''def forward(self, img):query = self.hand(img)query = self.extract_feature(query)cls_fea = query[:, -1, :] # 刚刚class_token被cat到了dim1的最后一个数x = self.head(cls_fea)return x
Runner(参考mmlab)
建立优化前,设置学习率,根据指定的work_flow顺序进行训练的测试,并保留最优权重
class Runner:def __init__(self, arg, model, device):self.arg = arg# 建立优化器params = [p for p in model.parameters() if p.requires_grad]self.optimizer = torch.optim.SGD(params=params, lr=arg.lr, momentum=0.9, weight_decay=5E-5)lf = lambda x: ((1 + math.cos(x * math.pi / arg.epochs)) / 2) * (1 - arg.lrf) + arg.lrf # cosineself.scheduler = torch.optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=lf)self.model = model.to(device)self.device = deviceif arg.load_from is not None and arg.load_from != '':weight_dict = torch.load(arg.load_from, map_location=device)model.load_state_dict(weight_dict)def run(self, dataloaders: dict):# 开始训练和验证assert 'train' in self.arg.work_flow.keys(), '必须要用训练任务'epoch_start = 0best_accuracy = 0.0while epoch_start < self.arg.epochs:for task, times in self.arg.work_flow.items():if task == 'train': # 开始训练for _ in range(times):epoch_start += 1 # epoch只记录训练轮self.model.train()loss_sum = 0.0data_loader = tqdm(dataloaders['train'], file=sys.stdout)for step, data_dict in enumerate(data_loader):img, label = data_dictinstance = {'data': img.to(self.device),'label': label.to(self.device)}loss = self.model.loss(**instance)loss_sum += loss.detach() # 要十分注意 避免往计算图中引入新的东西loss.backward()self.optimizer.step()self.optimizer.zero_grad()data_loader.desc = "[train epoch {}] loss: {:.3f}".\format(epoch_start,loss_sum.item() / (step + 1))self.scheduler.step()print('train: epoch={}, loss={}'.format(epoch_start, loss_sum / (step + 1.0)))elif task == 'val': # 开始验证''''''else:raise ValueError('task must be in [train, val, test]')可视化
读取单张图片,转换格式输入模型,输出的label,转化为class名和置信度,显示图像,class名和置信度.
if __name__ == '__main__':# 建立数据集data_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])img = Image.open('*****daisy/21652746_cc379e0eea_m.jpg')input = data_transform(img).unsqueeze(0)label2class = Flowers(dataset_path='../datasets/flower_photos-mini').label2classdevice = torch.device('cuda:0')# 建立模型model = Vit(img_size=[224, 224],patch_size=16,embed_dim=768,depth=12,num_heads=12,num_classes=5).to(device)weight_dict = torch.load('weights/vit.pth', map_location=device)model.load_state_dict(weight_dict)model.eval()with torch.no_grad():output = model(input.to(device))output = output.detach().cpu()label = output[0].numpy().argmax()cnf = torch.softmax(output[0],dim=0).numpy().max()*100.0cnf = np.around(cnf, decimals=2) #保留2位小数plt.imshow(img)plt.title('{} : {}%'.format(label2class[label],cnf))plt.show()
总结
vit是视觉transfomer最经典的模型,复现一次代码十分有必要,中间会产生很多思考和问题.
后面章节将会更有价值,我将会:
1.利用本次的代码进行很多思考和trick的验证
2.总结本次代码的BUG们,及其产生的原理和解决方法
如需获取全套代码请参考
相关文章:
Vision Transfomer系列第一节---从0到1的源码实现
本专栏主要是深度学习/自动驾驶相关的源码实现,获取全套代码请参考 这里写目录标题 准备逐步源码实现数据集读取VIt模型搭建hand类别和位置编码类别编码位置编码 blocksheadVIT整体 Runner(参考mmlab)可视化 总结 准备 本博客完成Vision Transfomer(VIT)模型的搭建和flowers数…...
【CSS + ElementUI】更改 el-carousel 指示器样式且隐藏左右箭头
需求 前三条数据以走马灯形式展现,指示器 hover 时可以切换到对应内容 实现 <template><div v-loading"latestLoading"><div class"upload-first" v-show"latestThreeList.length > 0"><el-carousel ind…...

Ubuntu 22.04 上安装和使用 Go
1.下载 All releases - The Go Programming Language //https://golang.google.cn/dl/wget https://golang.google.cn/dl/go1.21.6.linux-amd64.tar.gz 2.在下载目录下执行,现在,使用以下命令将文件提取到 “/usr/local ” 位置 sudo tar -C /usr/…...

ES6-const
一、基本用法 - 语法:const 标识符初始值;注意:const一旦声明变量,就必须立即初始化,不能留到以后赋值 - 规则:1.const 声明一个只读的常量,一旦声明,常量的值就不能改变2.const 其实保证的不是变量的值不…...

Android消息通知Notification
Notification 发送消息接收消息 #前言 最近在做消息通知类Notification的相关业务,利用闲暇时间总结一下。主要分为两部分来记录:发送消息和接收消息。 发送消息 发送消息利用NotificationManager类的notify方法来实现,现用最普通的方式发…...
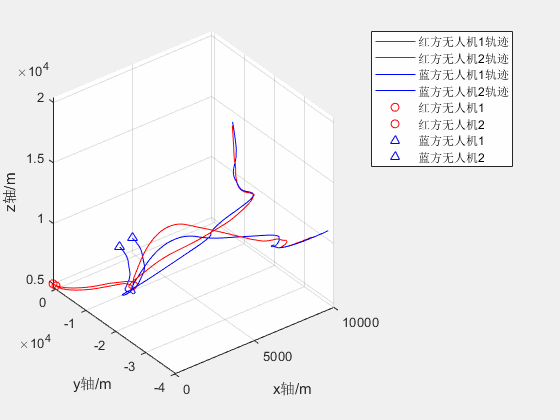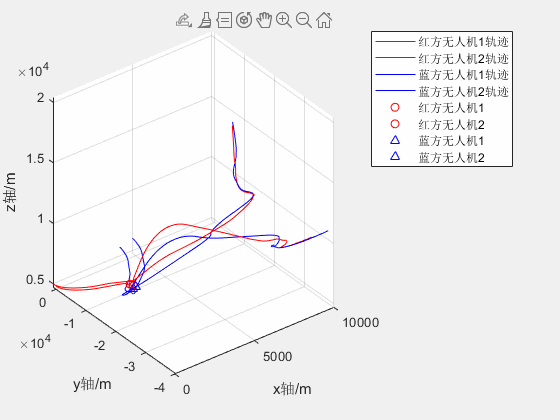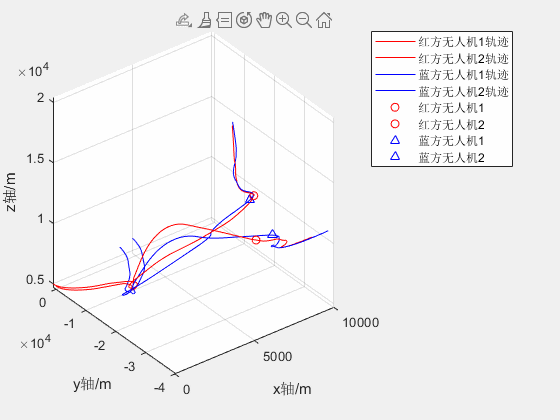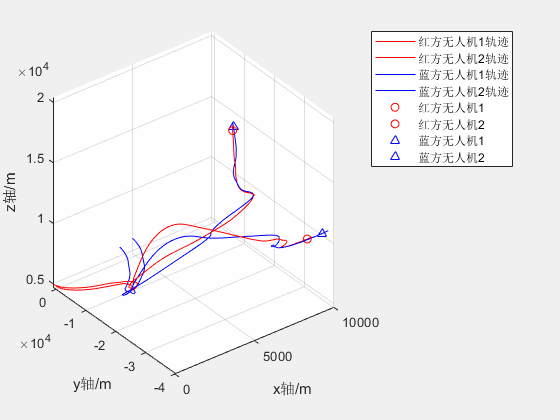
2V2无人机红蓝对抗仿真
两架红方和蓝方无人机分别从不同位置起飞,蓝方无人机跟踪及击毁红方无人机 2020a可正常运行 2V2无人机红蓝对抗仿真资源-CSDN文库...

VUE3语法--computed计算属性中get和set使用案例
1、功能概述 计算属性computed是Vue3中一个响应式的属性,最大的用处是基于多依赖时的监听。也就是属性A的值可以根据其他数据的变化而响应式的变化。 在Vue3中,你可以使用computed函数来定义计算属性。computed函数接收两个参数:一个包含getter和setter函数的对象和可选的…...

Linux cd 和 df 命令执行异常
这篇记录一些奇奇怪怪的命令执行异常的情况,后续有新的发现也会补录进来 情况一 /tmp 目录权限导致 按 tab 补充报错 情况描述 cd 按 tab 自动补充文件报错(普通用户) bash: cannot create temp file for here-document: Permission denie…...
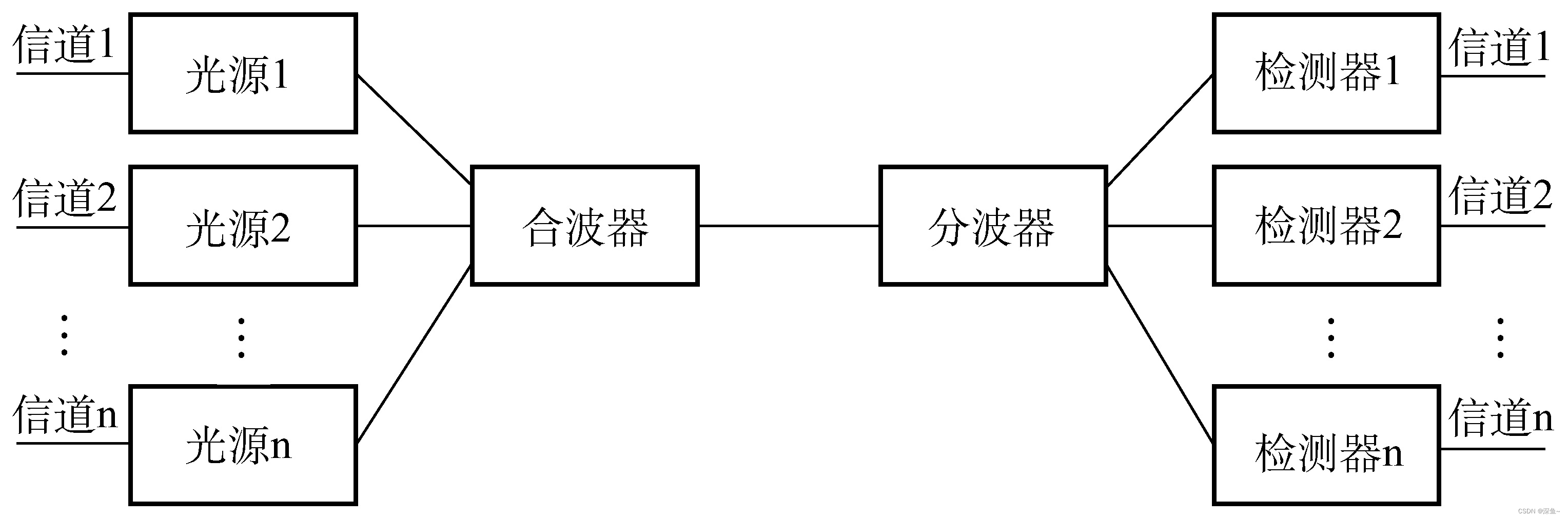
【计算机网络】物理层概述|通信基础|奈氏准则|香农定理|信道复用技术
目录 一、思维导图 二、 物理层概述 1.物理层概述 2.四大特性(巧记"械气功程") 三、通信基础 1.数据通信基础 2.趁热打铁☞习题训练 3.信号の变身:编码与调制 4.极限数据传输率 5.趁热打铁☞习题训练 6.信道复用技术 推荐 前些天发…...
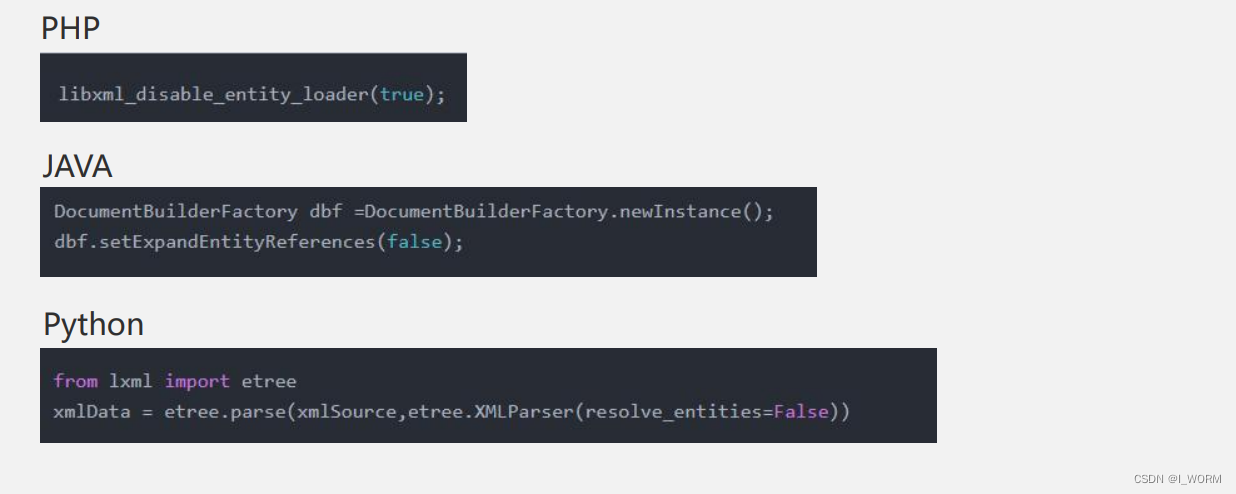
XXE基础知识整理(附加xml基础整理)
全称:XML External Entity 外部实体注入攻击 原理 利用xml进行读取数据时过滤不严导致嵌入了恶意的xml代码;和xss原理雷同 危害 外界攻击者可读取商户服务器上的任意文件; 执行系统命令; 探测内网端口; 攻击内网网站…...

【pytorch】anaconda使用及安装pytorch
https://zhuanlan.zhihu.com/p/348120084 https://blog.csdn.net/weixin_44110563/article/details/123324304 介绍 Conda创建环境相当于创建一个虚拟的空间将这些包都装在这个位置,不需要了可以直接打包放入垃圾箱,同时也可以针对不同程序的运行环境选…...

SpringBoot过滤器获取响应的参数
一、背景 在项目开发过程中,需要对于某些接口统一处理。 这时候就需要获取响应的报文,再对获取的报文进行统一处理。 二、了解过滤器 首先了解一下过滤器拦截器的区别: JAVA中的拦截器、过滤器:https://blog.csdn.net/qq_38254…...
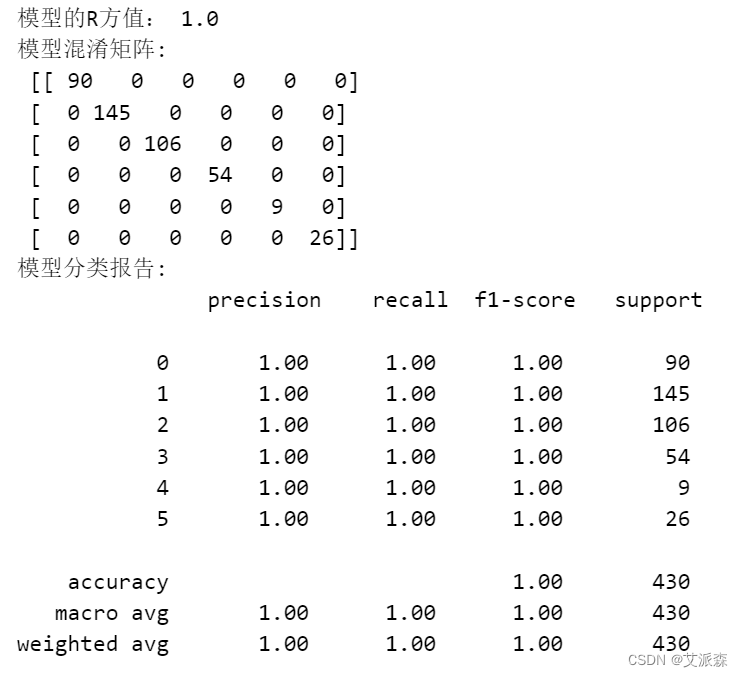
数据挖掘实战-基于决策树算法构建北京市空气质量预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

SOLID原理:用Golang的例子来解释
随着软件系统变得越来越复杂,编写模块化、灵活和易于理解的代码非常重要。实现这一目标的方法之一是遵循SOLID原则。这些原则是由罗伯特-C-马丁(Robert C. Martin)提出的,以帮助开发人员创建更容易维护、测试和扩展的代码。 本文将…...

mysql是如何使用索引的?
摘自官网 MySQL使用索引进行以下操作: WHERE条件中,快速查找匹配的行。(快速查询数据) 从准备查询的数据中消除多余行。如果可以在多个索引之间进行选择,则MySQL通常会使用查找最少行数的索引。 如果表具有多列索引,那么优化器可以使用索引的任何最左前缀来查找行。 举例来…...
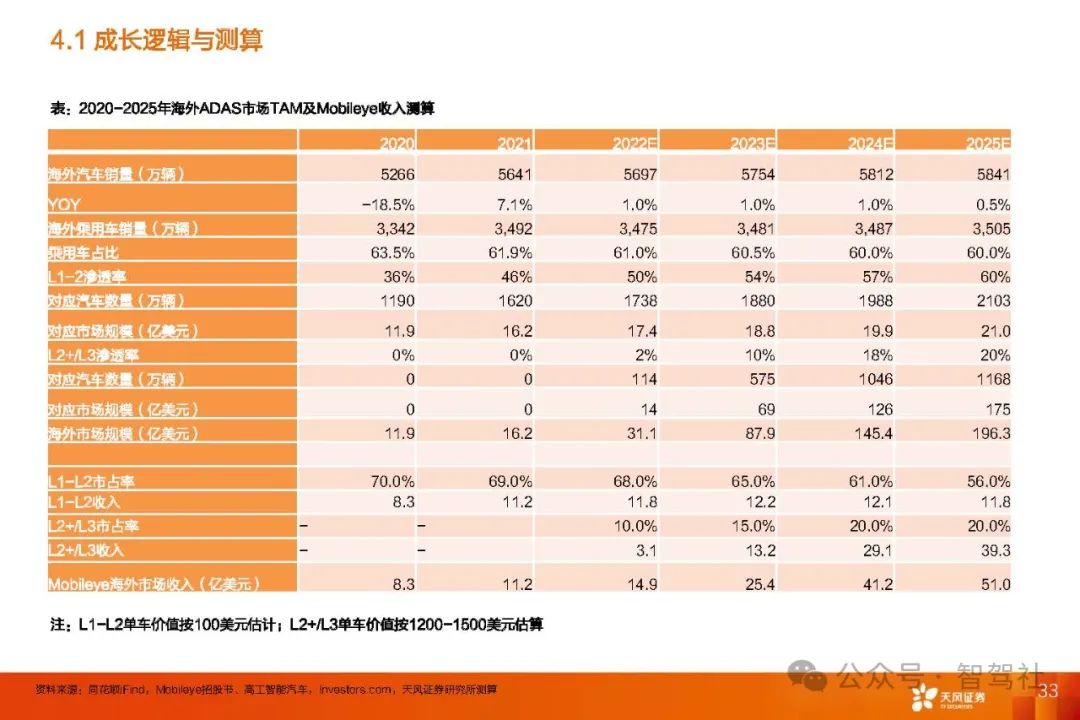
自动驾驶IPO第一股及商业化行业标杆 Mobileye
一、Mobileye 简介 Mobileye 是全球领先的自动驾驶技术公司,成立于 1999 年,总部位于以色列耶路撒冷。公司专注于开发视觉感知技术和辅助驾驶系统 (ADAS),并在自动驾驶领域处于领先地位。Mobileye 是高级驾驶辅助系统(ADAS&#…...

Linux前后端程序部署
1.总述 首先安装包类型分为 二进制发布包安装:找到对应自己的linux平台版本(CentOS还是redhat等),的具体压缩文件,解压修改配置 源码编译安装:需要自己进行编译 对于redhat安装包,可以使用rpm命令进行安装,但是rpm命令安装不能够解决依赖库的问题,常用的rpm命令,只用于卸载…...
手把手 S32K344移植FreeRTOS
版本信息 RTD:2.0.0.2022 S32DS:3.4.0.2020 下载 从S32K3参考软件下载FreeTROS FreeRTOS安装链接:https://www.nxp.com/webapp/swlicensing/sso/downloadSoftware.sp?catidSW32K3-REFSW-D 根据S32DS版本和S32K3 RTD 2.0.0 Package找到对应的FreeRTOS的zip安装…...

《云原生安全攻防》-- 云原生安全概述
从本节课程开始,我们将正式踏上云原生安全的学习之旅。在深入探讨云原生安全的相关概念之前,让我们先对云原生有一个全面的认识。 什么是云原生呢? 云原生(Cloud Native)是一个组合词,我们把它拆分为云和原生两个词来…...

综合分享1
VM及安装配置windows server 2008 1)安装配置VM 确保是否正确安装: 1)检查本地“网络与internal设置”中的虚拟网卡是否创建成功(vmnet1和vmnet8) 2)必须通过services.msc查看vmware的所有是否已经…...

OpenClaw健康检查:百川2-13B量化模型任务看板搭建
OpenClaw健康检查:百川2-13B量化模型任务看板搭建 1. 为什么需要健康检查系统 上周三凌晨两点,我被手机警报声惊醒——OpenClaw正在执行的自动化日报生成任务连续失败了7次。登录服务器查看日志时,发现根本原因是模型响应超时导致的操作链断…...
)
HTML 开发 - HTML 描述列表标签(<dl>、<dt>、<dd>)
HTML 描述列表标签 1、基本介绍在 HTML 中,<dl>、<dt>、<dd> 标签用于创建描述列表(Description List)描述列表是一种专门用于展示 术语 - 描述 或 名称 - 值 对结构的语义化标签标签说明<dl>Description List&#…...
绿色软件制作:TranslucentTB便携版开发全攻略
绿色软件制作:TranslucentTB便携版开发全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 在Windows个性化定制领域&#…...

交付前批量人脸脱敏自动模糊的一点记录
客户给了一批线下沙龙现场图,两百三十张上下,要用于对外案例页,合同里写了人脸需做不可辨认处理。手工框选不现实,我这次用【批量图片面部识别自动模糊工具】走完整交付链,只记和排期、验收相关的点。输入支持拖文件夹…...

Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践
Godot资源解压器godotdec:从游戏资源保护到开发分析的技术实践 【免费下载链接】godotdec An unpacker for Godot Engine package files (.pck) 项目地址: https://gitcode.com/gh_mirrors/go/godotdec 在游戏开发与资源管理领域,Godot引擎的.pck…...

告别系统卡顿:RyTuneX全方位性能优化指南
告别系统卡顿:RyTuneX全方位性能优化指南 【免费下载链接】RyTuneX RyTuneX is a cutting-edge optimizer built with the WinUI 3 framework, designed to amplify the performance of Windows devices. Crafted for both Windows 10 and 11. 项目地址: https://…...

新时达电脑调试软件上位机:支持256种全协议,便捷实现系统参数导入导出与备份
新时达软件上位机,256全协议 新时达电脑调试软件多协议,方便用电脑调试系统,可以从电脑导入 和导出参数到电脑保存控制柜前蹲半小时协议选错的痛,你懂不懂?U盘插了拔拔了插还是提示版本格式不匹配的烦躁,你…...
)
TDEngine-OSS-3.3.7.5开源版高可用部署实战(单节点快速入门与三副本集群搭建详解)
1. TDEngine开源版入门:为什么选择它? 如果你正在寻找一个高性能、开源的时序数据库,TDEngine绝对值得考虑。这个由涛思数据推出的产品,专门为物联网、工业互联网等场景设计,能够轻松处理海量时间序列数据。我最近在实…...

树莓派4B部署YOLOv5-Lite实战:从ONNX模型优化到实时检测性能调优
树莓派4B部署YOLOv5-Lite实战:从ONNX模型优化到实时检测性能调优 当目标检测遇上边缘计算,如何在仅有1.5GHz Cortex-A72处理器的树莓派4B上实现15FPS的实时推理?本文将揭示从模型压缩到硬件调优的全链路实战方案。不同于常规的部署教程&…...

1.6.2 掌握Scala数据结构 - 列表
本次实战深入讲解了Scala中不可变列表与可变列表的核心操作。首先,详细演示了不可变列表的创建与元素添加,重点强调了其不可变特性——任何添加或合并操作(如::、)都会生成新列表而不改变原列表。接着,介绍了可变列表L…...