大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
文章目录
- 大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
- 一、项目概述
- 二、系统实现基本流程
- 三、项目工具所用的版本号
- 四、所需要软件的安装和使用
- 五、开发技术简介
- Django技术介绍
- Neo4j数据库
- Bootstrap4框架
- Echarts简介
- Navicat Premium 15简介
- Layui简介
- Python语言介绍
- MySQL数据库
- 深度学习
- 六、核心理论
- 贪心算法
- Aho-Corasick算法
- BERT(Bidirectional Encoder Representations from Transformers)
- 长短时记忆网络(Long Short-Term Memory,LSTM)
- 条件随机场(Conditional Random Field,CRF)
- 命名实体识别
- 实体对齐
- 语义知识库问答
- 七、系统实现
- 八、结语
大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
一、项目概述
知识图谱是将知识连接起来形成的一个网络。由节点和边组成,节点是实体,边是两个实体的关系,节点和边都可以有属性。知识图谱除了可以查询实体的属性外,还可以很方便的从一个实体通过遍历关系的方式找到相关的实体及属性信息。
BERT是一种基于Transformer 架构的预训练语言模型,能够捕捉双向上下文信息。BERT 模型在大规模语料上进行预训练,然后可以通过微调来适应特定任务,BERT 可用于处理输入文本,提取丰富的语义信息。它可以用于文本的编码和表征学习,以便更好地理解医学问答中的问题和回答。LSTM 是一种递归神经网络(RNN)的变体,专门设计用于处理序列数据。它通过使用门控机制来捕捉长期依赖关系,适用于处理时间序列和自然语言等序列数据。 LSTM 可以用于处理医学文本中的序列信息,例如病历、症状描述等。它有助于保留文本中的上下文信息,提高模型对长文本的理解能力。CRF 是一种用于标注序列数据的统计建模方法。在序列标注任务中,CRF 能够考虑标签之间的依赖关系,从而更好地捕捉序列结构。 在医学文本中,CRF 可以用于命名实体识别(NER)任务,例如识别疾病、药物、实验室结果等实体。通过引入CRF层,可以提高标签之间的一致性和整体序列标注的准确性。
基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统通过构建医疗领域的知识图谱来实现计算机的深度学习,并且能够实现自动问答的功能。本次的内容研究主要是通过以Python技术来对医疗相关内容进行数据的爬取,通过爬取足量的数据来进行知识图谱的的搭建,基于Python语言通过echarts、Neo4j来实现知识图谱的可视化。通过智慧问答的方式构建出以BERT+LSTM+CRF的深度学习识别模型,从而完成对医疗问句主体的识别,构建出数据集以及实现文本的训练。通过Django来进行web网页的开发,通过面向用户的网页端开发使用来满足用户医疗问答的需要。
二、系统实现基本流程
- 配置好所需要的环境(jdk1.8,neo4j,pycharm,python等)
- 爬取所需要的医学数据,获取所需基本的医疗数据。
- 对医疗数据进行数据清洗处理。
- 关系抽取定义与实体识别等。
- 基于BERT+LSTM+CRF深度学习知识图谱建模。
- 数据可视化、深度学习问答、问句分析可视化、知识图谱可视化等。
- 知识问句分析管理、系统用户管理等功能完善做出一个完整的基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统。
三、项目工具所用的版本号
Neo4j版本:Neo4j Desktop1.5.6或者neo4j-community-3.1.0都可以;
neo4j里面医疗系统数据库版本:3.1.0;
Pycharm版本:2021.2.1;
JDK版本:jdk1.8.0_211;
MongoDB版本:MongoDB-windows-x86_64-5.0.14;
Django版本:3.2.8
四、所需要软件的安装和使用
(一)安装JAVA
1.下载java安装包:
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html
配置的话这里不再过多描述,之前写过详细的JDK配置,可以看一下
附链接:
JDK的环境配置(超级详细教程)
neo4j数据库所用的是neo4j-community-3.1.0版本,目录参数信息如下:
五、开发技术简介
Django技术介绍
Django是一个开放源代码的Web应用框架,由Python写成。采用了MVC的软件设计模式,即模型M,视图V和控制器C。Django 框架的核心组件有:
-
用于创建模型的对象关系映射
-
为最终用户设计的完美管理界面
-
一流的 URL 设计
-
设计者友好的模板语言
-
缓存系统。
在Django中,控制器接受用户输入的部分由框架自行处理,所以 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),称为 MTV模式。它们各自的职责如下:
| 层次 |
|---|
| 模型(Model),即数据存取层 |
| 模板(Template),即表现层 |
| 视图(View),即业务逻辑层 |
模型(Model),即数据存取层 处理与数据相关的所有事务: 如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。
模板(Template),即表现层 处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。
视图(View),即业务逻辑层 存取模型及调取恰当模板的相关逻辑。模型与模板之间的桥梁。
Django 视图不处理用户输入,而仅仅决定要展现哪些数据给用户,而Django 模板 仅仅决定如何展现Django视图指定的数据。或者说, Django将MVC中的视图进一步分解为 Django视图 和 Django模板两个部分,分别决定 “展现哪些数据” 和 “如何展现”,使得Django的模板可以根据需要随时替换,而不仅仅限制于内置的模板。
Django的主要目的是简便、快速的开发数据库驱动的网站。它强调代码复用,多个组件可以很方便的以“插件”形式服务于整个框架,Django有许多功能强大的第三方插件,你甚至可以很方便的开发出自己的工具包。这使得Django具有很强的可扩展性。它还强调快速开发和DRY(Do Not Repeat Yourself)原则。
1.对象关系映射 (ORM,object-relational mapping):以Python类形式定义你的数据模型,ORM将模型与关系数据库连接起来,你将得到一个非常容易使用的数据库API,同时你也可以在Django中使用原始的SQL语句。
2.URL 分派:使用正则表达式匹配URL,你可以设计任意的URL,没有框架的特定限定。像你喜欢的一样灵活
3.模版系统:使用Django强大而可扩展的模板语言,可以分隔设计、内容和Python代码。并且具有可继承性。
4.表单处理:你可以方便的生成各种表单模型,实现表单的有效性检验。可以方便的从你定义的模型实例生成相应的表单。
5.Cache系统:可以挂在内存缓冲或其它的框架实现超级缓冲 -- 实现你所需要的粒度。
6.会话(session),用户登录与权限检查,快速开发用户会话功能。
7.国际化:内置国际化系统,方便开发出多种语言的网站。
8.自动化的管理界面:不需要你花大量的工作来创建人员管理和更新内容。Django自带一个ADMIN site,类似于内容管理系统。
Neo4j数据库
Neo4j数据库是一个轻量级的、高性能的图形数据库,该数据库也被称之为是图片引擎,能够同面向对象的方式来进行数据的处理。该技术能够通过嵌入式的开发实现java持久化引擎的应用。该技术也是开源的技术,截止目前已经有一亿多个节点,其可以满足绝大多数的用户需求。作为一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Bootstrap4框架
Bootstrap是一个流行的开源前端框架,用于快速开发响应式和移动优先的网站。Bootstrap 4是Bootstrap框架的第四个主要版本,它引入了许多新的特性和改进。Bootstrap 4框架的详细介绍及优势:
响应式设计: Bootstrap 4是一个响应式设计的框架,可以确保网站在各种设备上都能够良好显示,包括桌面、平板和手机。
网格系统: Bootstrap的网格系统是其核心组件之一,它允许开发人员创建灵活的布局。网格系统基于12列,可以轻松地创建多列布局,适应不同屏幕大小。
移动优先: Bootstrap 4采用移动优先的设计理念,使得在设计和开发时首先考虑移动设备的体验。这有助于确保网站在小屏幕上的良好表现。
CSS预处理器支持: Bootstrap 4使用Sass(Syntactically Awesome Stylesheets)作为其默认的CSS预处理器,使得定制样式变得更加灵活和方便。
组件: Bootstrap 4提供了许多内置的UI组件,如导航栏、表单、按钮、模态框、轮播等,可以在项目中轻松使用这些组件,减少开发时间。
升级的表格和表单: Bootstrap 4引入了一些改进,使得表格和表单的样式更加现代化和易于定制。
新的插件系统: Bootstrap 4引入了一种称为Popper.js的新的插件系统,用于处理弹出框和工具提示等交互式组件。
重新设计的文档: Bootstrap 4的文档经过重新设计,更加清晰易读,提供了丰富的示例和文档说明,方便开发人员使用和学习。
定制主题: Bootstrap 4允许开发人员通过使用Sass变量和mixin来轻松定制主题,以满足项目的特定需求。
浏览器支持: Bootstrap 4支持所有主流的现代浏览器,并提供了对Flexbox布局的良好支持。
总体而言,Bootstrap 4是一个功能强大且灵活的前端框架,适用于各种Web开发项目。它的广泛应用和强大的社区支持使得开发人员能够快速构建美观、响应式的网站。
Echarts简介
ECharts是一款基于JavaScript的开源可视化库,专注于提供直观、交互丰富的图表展示效果。它由百度前端开发团队开发和维护,具有灵活的配置项和丰富的图表类型,适用于各种数据可视化场景。
在本系统中,ECharts在可视化分析方面发挥着重要作用。首先,ECharts提供了丰富多样的图表类型,包括折线图、柱状图、饼图、地图等,可以满足系统对不同类型的数据进行展示的需求。通过使用ECharts,系统能够以直观、易懂的方式展示数据、历史数据。用户可以通过交互式的图表进行数据的探索和分析,从中获取有价值的信息。其次,ECharts提供了丰富的配置项和交互功能,使得系统能够灵活地定制图表展示效果和用户交互体验。此外,ECharts还提供了丰富的扩展能力和插件支持,使得系统能够根据需要定制和扩展特定的功能。例如,ECharts提供了地图可视化的支持,可以将数据以地理位置为基础展示在地图上,使用户能够直观地了解不同地区的情况。同时,ECharts还支持数据的动画效果、数据的渐变展示等,增加了图表的可视化效果和吸引力。
总之,ECharts作为一款功能强大的可视化库,在本系统中扮演着重要的角色。它通过丰富的图表类型和配置项,使系统能够以直观、交互丰富的方式展示数据。同时,ECharts的扩展能力和插件支持为系统的定制和功能扩展提供了便利。通过ECharts的应用,本系统能够提供直观、灵活的数据可视化分析功能,帮助用户更好地理解和利用数据。
Navicat Premium 15简介
Navicat Premium 15是一款功能强大且广泛使用的数据库管理工具。它提供了一个集成的开发环境,适用于不同类型的数据库,如MySQL、Oracle、SQL Server、PostgreSQL等。Navicat Premium 15具有直观的用户界面和丰富的功能,使数据库管理变得更加高效和便捷。
Navicat Premium 15作为一款强大的数据库管理工具,在本系统中发挥着重要的作用。它提供了直观的界面和丰富的功能,使用户能够方便地管理和操作MYSQL数据库。同时,它还为系统开发人员提供了便捷的开发和调试环境,加快了系统的开发进程。通过Navicat Premium 15的支持,本系统能够更好地实现天气数据的自动获取与可视化分析。
Layui简介
Layui 是一套开源免费的 Web UI 组件库,采用自身轻量级模块化规范,遵循原生态的 HTML/CSS/JavaScript 开发模式,非常适合网页界面的快速构建。Layui 区别于一众主流的前端框架,它更多是面向于后端开发者,即无需涉足各类构建工具,只需面向浏览器本身,便可将页面所需呈现的元素与交互信手拈来。Layui采用模块化的设计理念,将各个功能划分为独立的模块,每个模块都有清晰的责任和接口。这种设计使得开发者可以根据需要选择性地引入和使用不同的模块,从而减小项目体积,提高加载速度。此外,提供了大量常用的界面组件,包括但不限于按钮、表单、表格、导航、弹层、进度条等。这些组件风格简洁、统一,可以方便地进行定制和扩展,满足不同项目的需求。Layui的API设计简单易用,使得开发者无需深入研究复杂的前端技术,即可快速上手。它提供了丰富的文档和示例,方便开发者查阅和学习。在扩展性方面, Layui具有良好的扩展性,开发者可以根据项目需要编写自定义的模块或插件,并集成到Layui框架中,实现特定功能的定制化开发。
Python语言介绍
Python语言是现在最为常用的一款脚本语言技术,该语言的特点在于编程过程简单,语法平易近人。该语言的编程过程如同在进行一项语言的学习,通过符合人们日常生活使用语言的习惯来进行编程开发可以有效的提升系统编程的效率,并且在整个系统的开发过程中,该技术也能有着非常多的框架和类库可提供使用,包括django框架、flask框架等,都是Python在web端开发所经常使用的开发框架。该语言继承了C语言的编程特点,并且有着很好的跨平台使用特点,实现了一次编译,多处运行的效果。
MySQL数据库
本次的数据库选择了MySQL,该数据库是当下最为常用的一款标准SQL语言下的数据库管理工具。该数据库能够通过SQL layer以及storage engine layer来快速的对数据信息进行完整的解析与存储,通过多线程的数据服务来加快数据传输的效率,并且该数据库也支持多种开发语言,能够在不同的操作平台中均实现凯苏运行。该数据库对于硬盘内存的占用非常低,可以实现安全的数据存储,整个数据库具备了开源的特点,可以为用户的数据存储服务提供个性化的图表编辑,通过数据库表格的方式来进一步的提高数据存储的逻辑性,确保数据关系准确。
深度学习
深度学习是一种机器学习的方法,其中模型通过多层神经网络学习从输入数据中提取高层次抽象特征。深度学习模型通常包含多个层次,这些层次构成了深层结构,这也是“深度”学习一词的由来。深度学习是针对机器训练和学习的一个全新的研究方向,希望能够通过该学习方式来实现人工智能的目标。深度学习是对样本数据的学习,在对样本数据中所存在的逻辑关系、数据实体等进行解释和记录,让计算机可以通过广泛的内容学习来具备一定的分析能力、判断和识别能力,深度学习在搜索引擎、机器学习、自然语言等多个方面都形成非常好的应用效果,能够通过该学习方式来解决人工智能领域遇到的一些困难。
BERT是一种基于Transformer 架构的预训练语言模型,能够捕捉双向上下文信息。BERT 模型在大规模语料上进行预训练,然后可以通过微调来适应特定任务,BERT 可用于处理输入文本,提取丰富的语义信息。它可以用于文本的编码和表征学习,以便更好地理解医学问答中的问题和回答。LSTM 是一种递归神经网络(RNN)的变体,专门设计用于处理序列数据。它通过使用门控机制来捕捉长期依赖关系,适用于处理时间序列和自然语言等序列数据。 LSTM 可以用于处理医学文本中的序列信息,例如病历、症状描述等。它有助于保留文本中的上下文信息,提高模型对长文本的理解能力。CRF 是一种用于标注序列数据的统计建模方法。在序列标注任务中,CRF 能够考虑标签之间的依赖关系,从而更好地捕捉序列结构。 在医学文本中,CRF 可以用于命名实体识别(NER)任务,例如识别疾病、药物、实验室结果等实体。通过引入CRF层,可以提高标签之间的一致性和整体序列标注的准确性。
在医疗数据中,CRF可以用于命名实体识别(NER)任务,例如识别疾病、药物、实验室结果等实体。通过引入CRF层,可以提高标签之间的一致性和整体序列标注的准确性。意图识别可以看做是一个分类问题,针对于垂直产品的特点,定义不同的查询意图类别。通过该系统设计一个强大的问答模块,能够接受用户输入的自然语言问题,并基于BERT、LSTM、CRF等算法模型生成准确的、语义一致的回答。
六、核心理论
贪心算法
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。贪心算法不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题他能产生整体最优解或者是整体最优解的近似解。
贪婪算法(Greedy algorithm)是一种对某些求最优解问题的更简单、更迅速的设计技术。用贪婪法设计算法的特点是一步一步地进行,常以当前情况为基础根据某个优化测度作最优选择,而不考虑各种可能的整体情况,它省去了为找最优解要穷尽所有可能而必须耗费的大量时间,它采用自顶向下,以迭代的方法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题,通过每一步贪心选择,可得到问题的一个最优解,虽然每一步上都要保证能获得局部最优解,但由此产生的全局解有时不一定是最优的,所以贪婪法不要回溯。
贪婪算法是一种改进了的分级处理方法。其核心是根据题意选取一种量度标准。然后将这多个输入排成这种量度标准所要求的顺序,按这种顺序一次输入一个量。如果这个输入和当前已构成在这种量度意义下的部分最佳解加在一起不能产生一个可行解,则不把此输入加到这部分解中。这种能够得到某种量度意义下最优解的分级处理方法称为贪婪算法。
对于一个给定的问题,往往可能有好几种量度标准。初看起来,这些量度标准似乎都是可取的,但实际上,用其中的大多数量度标准作贪婪处理所得到该量度意义下的最优解并不是问题的最优解,而是次优解。因此,选择能产生问题最优解的最优量度标准是使用贪婪算法的核心。
Aho-Corasick算法
Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多。Aho-Corasick算法对应的数据结构是Aho-Corasick自动机,简称AC自动机Automaton。该算法能够识别出一个给定的语句中包含了哪些词典库中特定的词语,具有很有的模式匹配作用。
算法主要分为以下三个部分:
- 构造Goto表:成功转移到另一个状态
- 构造Failture指针:如果某状态发生匹配失败,需要跳转到一个特定的节点
- 匹配:匹配成功某一字符串
我们构建一个基于Aho-Corasick算法的trie树,用于加速过滤敏感词汇或关键词。
'''构造actree,加速过滤'''
def build_actree(self, wordlist):actree = ahocorasick.Automaton() # 初始化trie树,ahocorasick 库 ac自动化 自动过滤违禁数据for index, word in enumerate(wordlist):actree.add_word(word, (index, word)) # 向trie树中添加单词actree.make_automaton() # 将trie树转化为Aho-Corasick自动机return actree
使用Aho-Corasick自动机的目的是在输入文本中高效地检测和过滤多个关键词。这种数据结构的优势在于,它能够同时匹配多个关键词而无需多次扫描输入文本,因此在过滤大量文本时性能较高。
BERT(Bidirectional Encoder Representations from Transformers)
BERT(Bidirectional Encoder Representations from Transformers)属于深度学习模型。它是一种基于变压器(Transformer)架构的预训练模型,通过在大规模文本数据上进行无监督的预训练来学习语言表示。BERT在处理自然语言处理(NLP)任务时取得了很大的成功,包括文本分类、命名实体识别、语义角色标注等。BERT 模型在大规模语料上进行预训练,然后可以通过微调来适应特定任务,BERT 可用于处理输入文本,提取丰富的语义信息。它可以用于文本的编码和表征学习,以便更好地理解医学问答中的问题和回答。BERT的关键创新之一是使用了双向(bidirectional)的注意力机制,使模型能够同时考虑一个词的上下文信息,而传统的语言模型通常是从左到右或从右到左单向考虑上下文。
BERT建立在Transformer架构上,这是一种基于自注意力机制的深度学习模型。Transformer被广泛应用于自然语言处理任务,取得了显著的成功。它允许模型在并行计算的基础上有效地捕捉长距离依赖关系。总的来说,BERT代表了深度学习在自然语言处理领域的巨大进展,为多种NLP任务提供了先进的性能。
长短时记忆网络(Long Short-Term Memory,LSTM)
长短时记忆网络(Long Short-Term Memory,LSTM)是一种深度学习模型中的一种特殊类型的循环神经网络(Recurrent Neural Network,RNN)。LSTM专门设计用来解决传统RNN中遇到的梯度消失和梯度爆炸的问题,使得网络能够更好地捕捉和记忆长距离依赖关系。
LSTM 是一种递归神经网络(RNN)的变体,专门设计用于处理序列数据。它通过使用门控机制来捕捉长期依赖关系,适用于处理时间序列和自然语言等序列数据。 LSTM 可以用于处理医学文本中的序列信息,例如病历、症状描述等。它有助于保留文本中的上下文信息,提高模型对长文本的理解能力。
条件随机场(Conditional Random Field,CRF)
CRF是一种判别式概率图模型,用于建模标签序列的联合概率分布。在序列标注任务中,CRF可以捕捉标签之间的依赖关系,特别是相邻标签之间的依赖。这对于诸如命名实体识别、词性标注等序列标注任务非常重要。为了更好地捕捉标签之间的关系,CRF经常被用作深度学习模型的输出层。具体来说,深度学习模型可以学习输入序列的表示,然后使用CRF层对这些表示进行解码,考虑标签之间的依赖关系,从而生成最终的标签序列。
这种结合CRF和深度学习的方法在自然语言处理任务中广泛应用,包括命名实体识别、词性标注、分块等。通过结合深度学习的表示学习和CRF的序列建模能力,模型在序列标注任务上取得了更好的性能。在医学文本中,CRF 可以用于命名实体识别(NER)任务,例如识别疾病、药物、实验室结果等实体。通过引入CRF层,可以提高标签之间的一致性和整体序列标注的准确性。
命名实体识别
命名实体识别是一种可以在非结构化的文本中,通过特定的实体来进行文本的识别,是一种专名的识别。该识别方式是在特定的领域中,通过对领域中的实体类型进行精准的定义,例如在医疗领域中,针对与医疗相关的疾病、症状、药物、问诊等内容进行系统性的内容定义,也能够通过命名实体识别来对药剂、价格、收款等内容进行定义,这种定义的方式可以通过精准匹配的方式来进行实体边界的识别,并且可以实现对边界的正确标记。命名实体识别的方法主要有三种方式,第一种是通过利用规则法来进行规则的人工编写;第二种是通过HMM、CRF等模型来进行机器学习模板订制;第三种是通过神经网络的方式以LSTM、RNN等算法来进行特征的提取。
实体对齐
知识图谱与问答系统的应用结合已经非常的广泛,将不同的知识图谱进行对接可以实现有效的数据互补,形成一个更大的知识图谱。而知识图谱越大,其中包含的实体内容就越多,就越需要解决实体对齐的问题。实体对其主要包括了成对的实体对齐、集体实体对其等,通过不同的算法使用能够很好的完成不同知识图谱之间的相同数据对象表示的对齐问题解决。
语义知识库问答
语义解析是一种应用在知识库中非常常见的语言解析方式,可以将自然语言进行逻辑的转换,从而让自然语言被转换为可执行的查询语言。而语义知识库是先通过语义的解析,再通过搜索引擎的处理来进行逻辑判断并最终实现查询结果的获取。语义知识库可通过可解释性的方式来提升知识问答的精准度,最终实现面向知识图谱的自然语言问答环境的生成。
七、系统实现
数据爬取与清洗不再过多描述,具体看
大数据知识图谱——基于知识图谱+深度学习的大数据(KBQA)NLP医疗知识问答系统(全网最详细讲解及源码/建议收藏)
部分核心代码:
一小部分截图展示,其它内容这里不再过多描述。
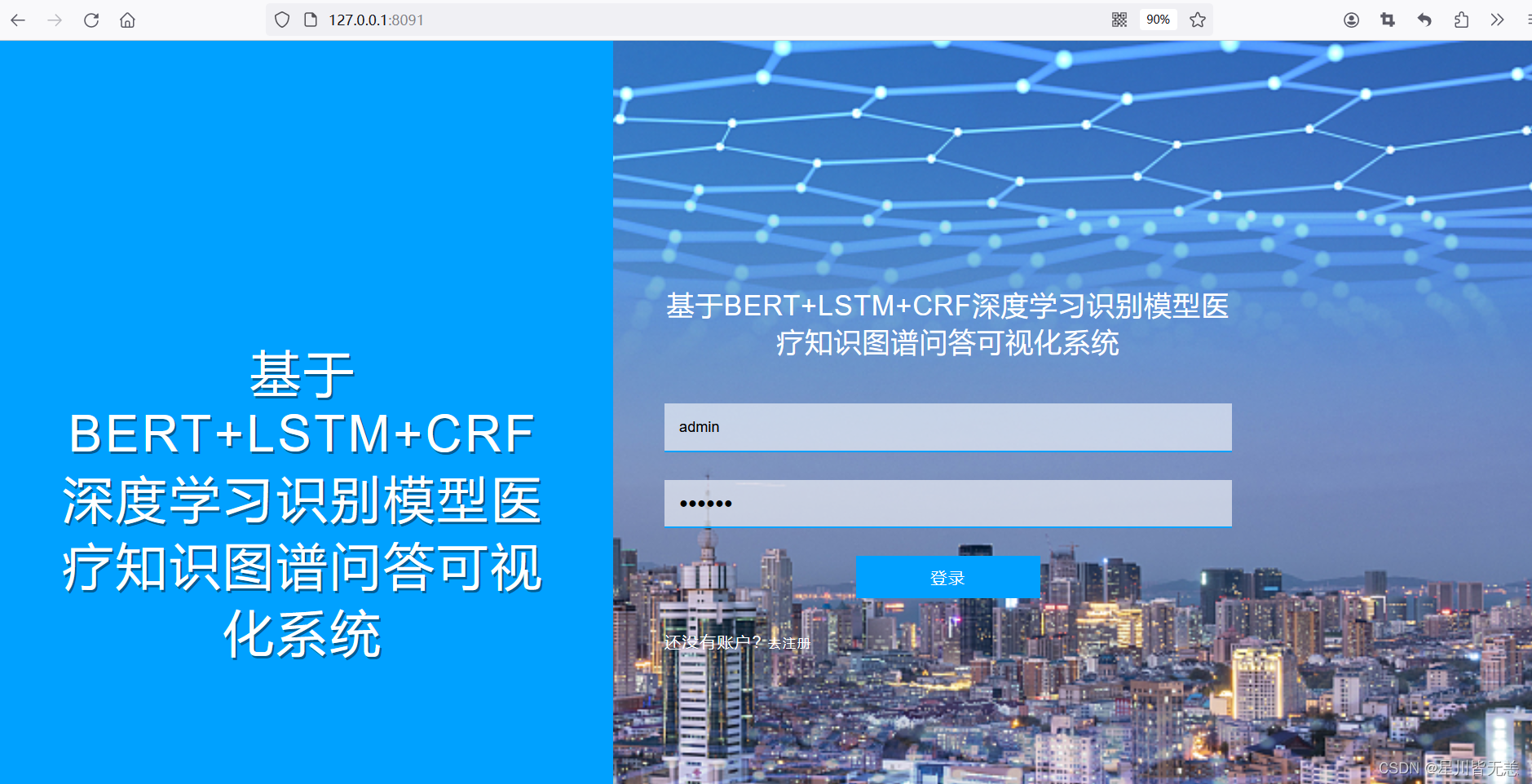
系统登录界面
通过首页登录名及密码信息的录入实现系统平台的登录使用,对于没有系统账号的用户可以通过注册页面实现在线的用户注册,系统界面的内容呈现相对简洁,具体界面呈现内容如下:
系统首页
进入到识别系统后台,系统首页界面主要介绍了知识图谱的概述,同时通过首页导航意图识别、问句管理以及问句分析功能模块的内容实现在线问答,结合医疗领域的问句管理及问句分析可以对系统端的问句内容进行整理和数据统计,系统用户可以通过修改密码以及用户管理实现识别系统登录及个人信息的维护,具体系统首页内容呈现如下图所示:

深度学习问答界面
基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统的主要功能模块为深度学习问答模块,用户可以通过该功能模块实现在线问答,通过界面下方的输入栏实现医疗领域相关问题的录入,通过点击发送实现在线提问,系统会结合用户端的问题进行意图分析并反馈问题答复内容,具体意图识别界面的主要功能栏内容呈现如下:
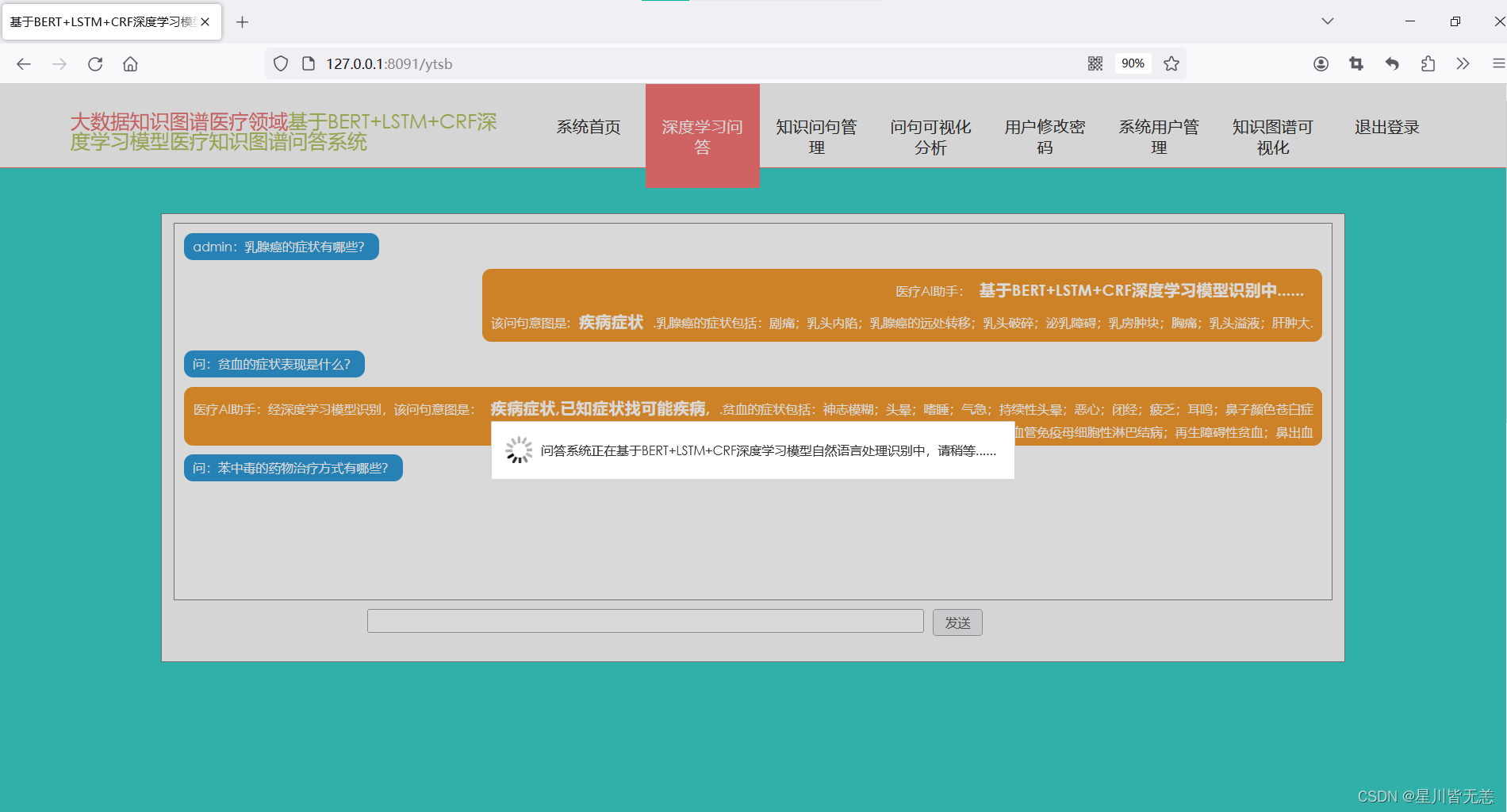
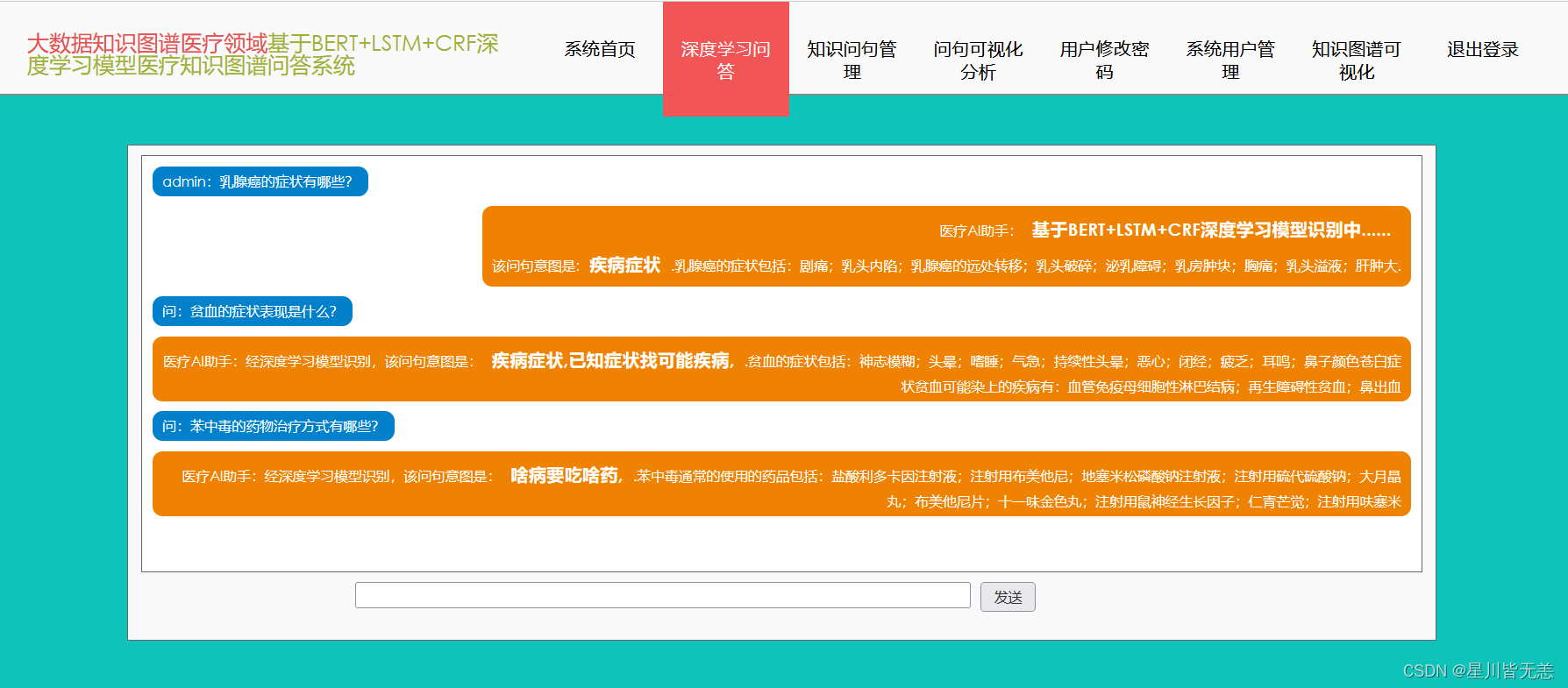
知识问句管理
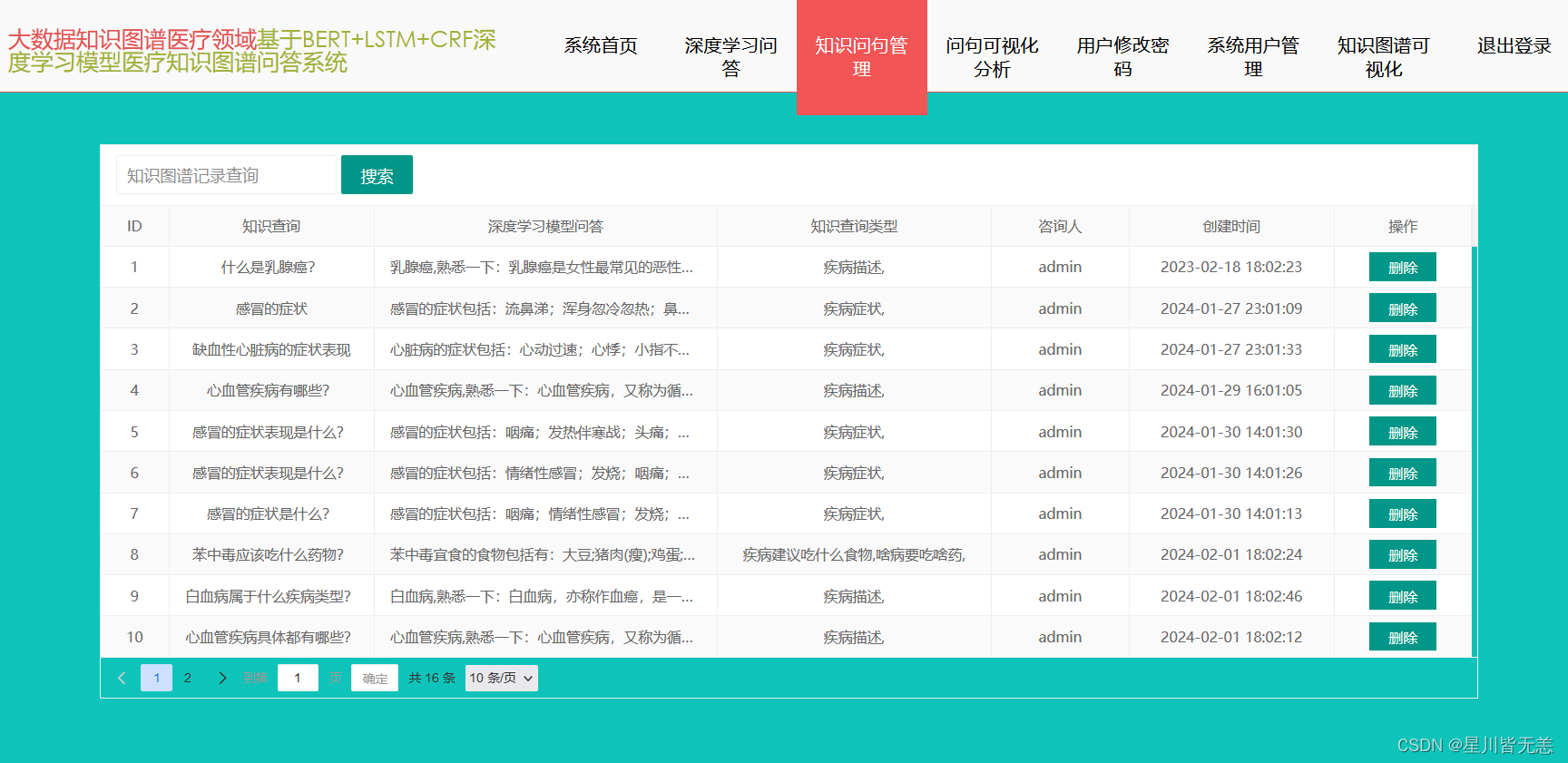
知识问句管理是对系统用户提出的问题信息进行统一的管理和查询,主要呈现了系统用户提出的问题信息、答案信息以及提出问题用户的个人信息及提问时间等内容,可以对于重复的问题内容进行在线的删除操作,同时也可以结合问题内容进行搜索和查找,具体知识问句管理界面内容呈现如下图所示:
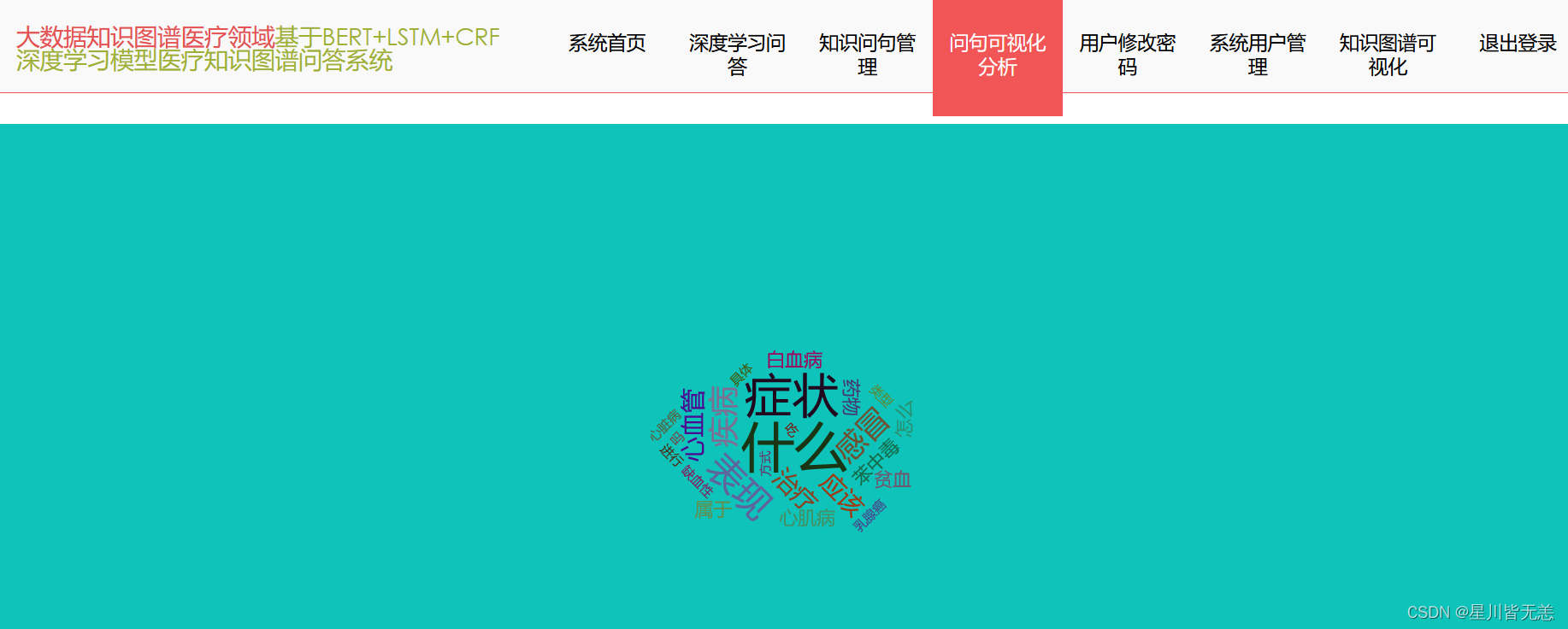
问句分析可视化界面
问句分析可视化主要是对于系统平台的问题内容进行关键字及查询次数内容的统计,通过该界面进行可视化呈现了医疗领域问题的内容以及提出问题的次数,结合问句分析对高频词的问题内容进行分析和统计,具体问句分析界面呈现如下:
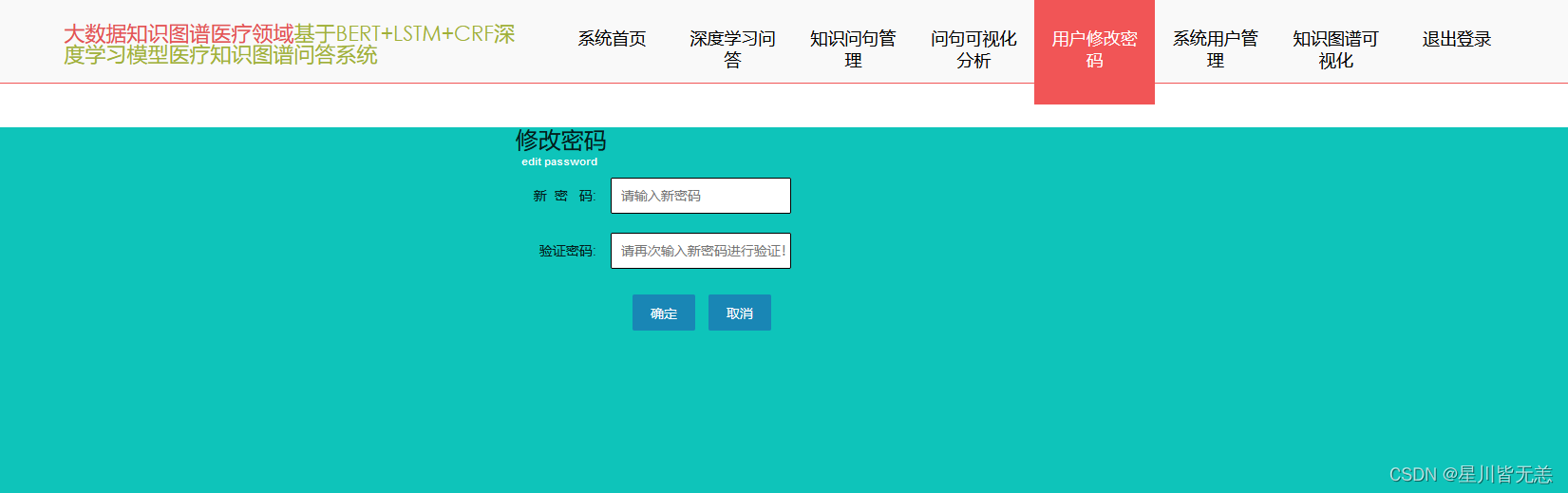
用户修改密码界面
用户可以通过修改密码模块实现登录密码的修改,通过录入新密码和复核录入来实现密码的修改,具体密码修改页面内容如下:
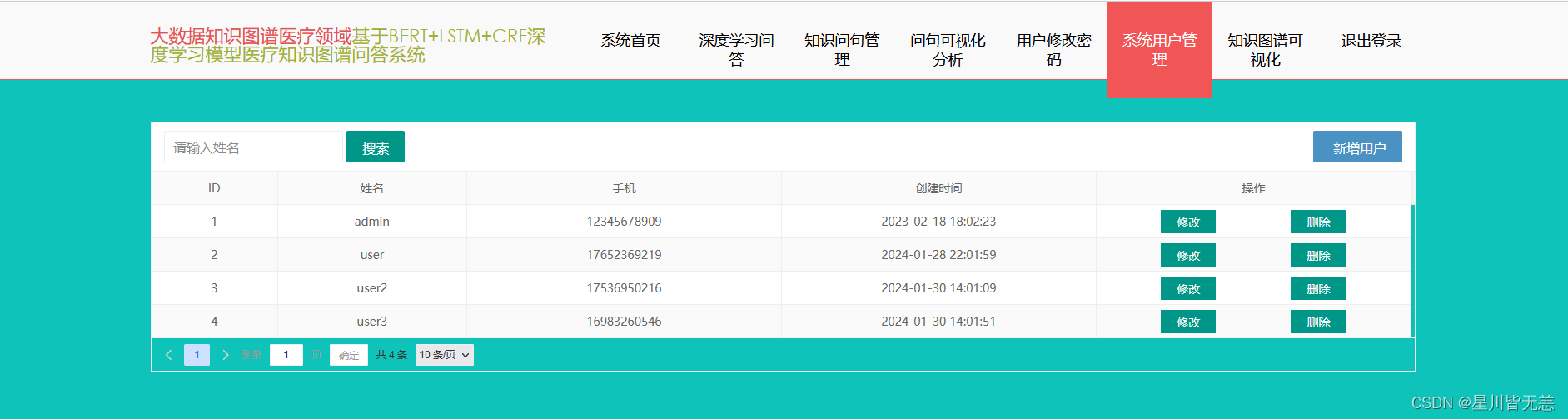
系统用户管理界面
通过系统用户管理界面可以实现用户的新增以及用户基本信息的修改,只需要录入用户姓名、密码以及手机号就可以实现在线用户新增,这里手机号必须为11位数字,具体用户新增界面信息内容录入如下图所示:
知识图谱可视化界面
通过系统知识图谱可视化界面通常一种图形化的表示方式,用于展示知识图谱中的实体(节点)以及它们之间的关系(边)。这样的界面有助于用户更直观地理解和探索复杂的知识结构。具体知识图谱可视化界面界面信息如下图所示:

八、结语
通过该系统设计一个强大的问答模块,能够接受用户输入的自然语言问题,并基于Aho-Corasick算法、贪心算法及深度学习模型BERT、LSTM、CRF等算法模型生成准确的、语义一致的回答。同时结合系统的问句分析和管理来帮助统计系统的问句管理信息,实现便捷的信息查询与管理。基于此次医疗领域深度学习用户问答系统的研究,在系统开发和结构搭建上还存在一定的改进和优化空间,因当前对中文临床医疗领域的知识图谱数据信息相对缺乏,在构建医疗知识图谱的基础上还需要各方资源的整合,还需要对知识库进行不断的信息扩充和维护,同时对单实体多关系复杂情况的问题反馈,未来仍需要在知识的抽取上还需要不断完善,在数据库语料构建以及知识库的扩充上做更加深入的研究。
所有项目非开源,需项目源码资料/商业合作/交流探讨等可以评论留言并添加文末下面个人名片,后面有时间和精力也会分享更多关于大数据领域方面的优质内容,喜欢的小伙伴可以点赞关注收藏,感谢各位的喜欢与支持!
相关文章:
大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统
文章目录 大数据知识图谱之深度学习——基于BERTLSTMCRF深度学习识别模型医疗知识图谱问答可视化系统一、项目概述二、系统实现基本流程三、项目工具所用的版本号四、所需要软件的安装和使用五、开发技术简介Django技术介绍Neo4j数据库Bootstrap4框架Echarts简介Navicat Premiu…...

年底个人总结
年底个人总结 前言:又到了年底,在游戏行业工作了接近10年,想想也应该把自己做过的东西做一个总结。 从14年在北京毕业,懵懂的我在机缘巧合下遇到了陈g,我行业的领路人,在他的带领下我进入到了游戏行业。 当…...
jsp教材管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP 教材管理系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5.0&…...
SpringBoot:配置相关知识点
SpringBoot:多环境配置 配置知识点demo:点击查看LearnSpringBoot02 点击查看更多的SpringBoot教程 一、SpringBootApplication SpringBootApplication 来标注一个主程序类,说明这是一个Spring Boot应用,运行这个类的main方法来…...
在线JSON转SQL工具
在线JSON转SQL - BTool在线工具软件,为开发者提供方便。在线JSON转SQL工具可以将JSON文件中的数据或者JSON对象转换为SQL插入语句,方便用户将数据导入到数据库中。用户可以通过简单的界面上传JSON文件,或者文本框输入,点击JSON转S…...
网络安全大赛
网络安全大赛 网络安全大赛的类型有很多,比赛类型也参差不齐,这里以国内的CTF网络安全大赛里面著名的的XCTF和强国杯来介绍,国外的话用DenCon CTF和Pwn2Own来举例 CTF CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相…...
phpMyAdmin 未授权Getshell
前言 做渗透测试的时候偶然发现,phpmyadmin少见的打法,以下就用靶场进行演示了。 0x01漏洞发现 环境搭建使用metasploitable2,可在网上搜索下载,搭建很简单这里不多说了。 发现phpmyadmin,如果这个时候无法登陆,且也…...

PHP实现DESede/ECB/PKCS5Padding加密算法兼容Java SHA1PRNG
这里写自定义目录标题 背景JAVA代码解决思路PHP解密 背景 公司PHP开发对接一个Java项目接口,接口返回数据有用DESede/ECB/PKCS5Padding加密,并且key也使用了SHA1PRNG加密了,网上找了各种办法都不能解密,耗了一两天的时间…...

亚马逊认证考试系列 - 知识点 - 安全组介绍
第一部分:AWS简介 Amazon Web Services(AWS)是全球领先的云计算服务提供商,为个人、企业和政府机构提供广泛的云服务解决方案。AWS的服务包括计算、存储、数据库、分析、机器学习、人工智能、物联网、安全和企业应用等领域。AW…...

【Golang】exec.command命令日志输出示例
背景 为了输出执行命令的日志,主要是执行时间很长,而且分批输出日志的命令。 代码 func Execute(){command : exec.Command("执行命令")// 隐藏黑色窗口command.SysProcAttr &syscall.SysProcAttr{CreationFlags: 0x08000000}// 输出日…...
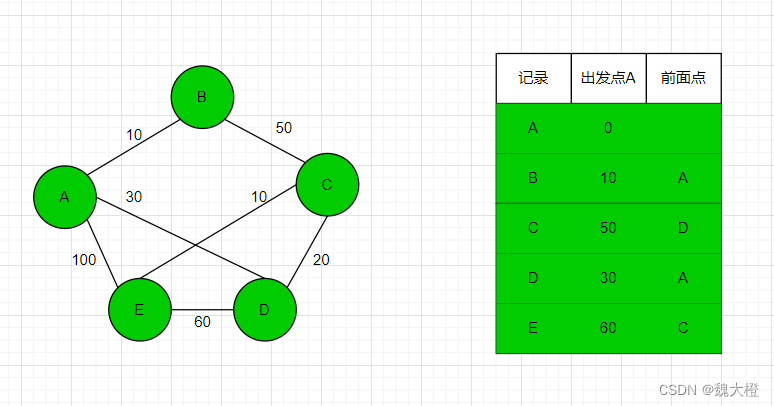
Dijkstra算法(求最短路)
简介: 迪杰斯特拉算法(Dijkstra)是由荷兰计算机科学家狄克斯特拉于1959年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。 特点: 迪杰斯特拉算法采用的是一种贪心策略&a…...

ipcf 核间通讯
S32G2汽车网关开发(四):IPCF通信_s32g 车载网关 精典-CSDN博客 Linux ARM平台开发系列讲解(IPCF异核通信) 2.11.3 IPCF异核通信驱动编译及其测试-CSDN博客...
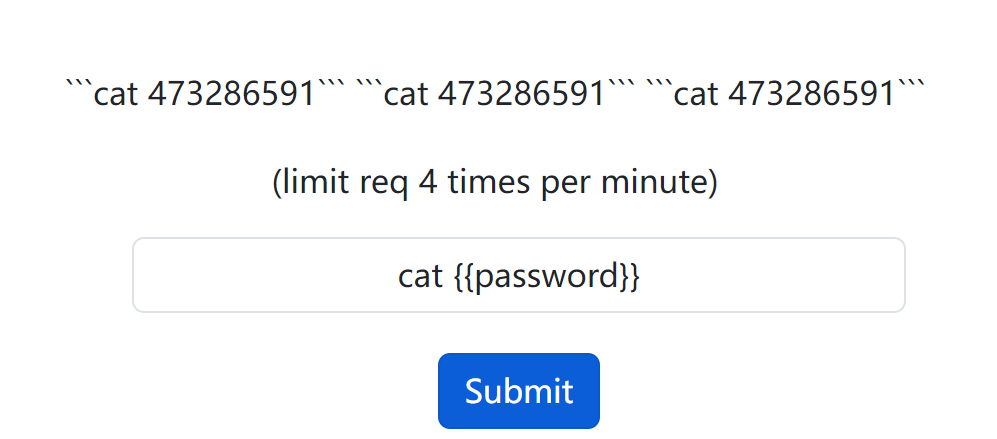
第七届西湖论剑·中国杭州网络安全技能大赛 AI 回声海螺 WP
第七届西湖论剑中国杭州网络安全技能大赛-AI-回声海螺 开题,提示输入密码给FLAG。 这个回声海螺应该是个AI,就是复读机,应该是想办法从中骗出密码。 感觉这题不像是AI,也没用啥模型,应该是WEB。或者是说类似于AI的提示…...

SpringBoot 拦截器Intercepto的创建与基本使用
介绍 拦截器和过滤器的功能都差不多,拦截器是SpringBoot的,而且过滤器是Servlet的 SpringBoot过滤器 拦截器-过滤器 执行顺序 发起请求-》过滤器-》拦截器-》接口 创建拦截器 实现HandlerInterceptor 的接口,并且实现他都三个方法 preHan…...

爬虫工作量由小到大的思维转变---<第四十五章 Scrapyd 关于gerapy遇到问题>
前言: 本章主要是解决一些gerapy遇到的问题,会持续更新这篇! 正文: 问题1: 1400 - build.py - gerapy.server.core.build - 78 - build - error occurred (1, [E:\\项目文件名\\venv\\Scripts\\python.exe, setup.py, clean, -a, bdist_uberegg, -d, C:\\Users\\Administrat…...
2024.2.4 awd总结
防御阶段 感觉打了几次awd,前面阶段还算比较熟练 1.ssh连接 靶机登录 修改密码 [root8 ~]# passwd Changing password for user root. New password: Retype new password: 2.xftp连接 备份网站源码 我觉得这步还是非常重要的,万一后面被删站。。…...

仰暮计划|“用心感悟使我获取了艺术真谛,自律如始让我获得了人生成功,我将继续在艺术道路上走下去”
口述人:郭敬东(男) 整理人:马静 口述人与整理人关系:姥爷与外孙女 口述人基本信息:现60岁,1963年出生于湖北省大悟县刘集镇金鼓村,1987年移居到河南省焦作市,现居河南省焦作市高新区。 引言:在得知要讲述自己的经历…...

网络原理——网络层
网络层重要涉及到的协议是IP协议。 IP协议主要完成的工作是: 地址管理路由选择 1. IP协议的组成 版本(Version):占4位,表示IP协议的版本号。目前广泛使用的版本是IPv4和IPv6。 头部长度(Header Length&…...

ideaIU-2023.2.1安装教程
ideaIU-2023.2.1安装教程 一、ideaIU-2023.2.1安装1.1 下载IdeaIU-2023.2.1安装包1.2 安装ideaIU-2023.2.1 二、ideaIU-2023.2.1激活 💖The Begin💖点点关注,收藏不迷路💖 一、ideaIU-2023.2.1安装 1.1 下载IdeaIU-2023.2.1安装包…...

JAVA面试题之三分布式和微服务的区别是什么?
面试题之三 分布式和微服务的区别是什么? 难度指数:3星 考察频率:50% 开发年限:3年左右 二者是隶属于不同的概念。 一.概念 微服务是系统架构的设计方式,是将复杂的业务拆分成多个微型的服务,让这些…...

3个核心功能让Windows优化变得如此简单:Winhance中文版深度体验
3个核心功能让Windows优化变得如此简单:Winhance中文版深度体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Wi…...

.NET源码生成器使用SyntaxTree生成代码及简化语法
一、SyntaxTree是什么SyntaxTree是语法树,是源代码的树形结构表示由Roslyn编译器生成在SourceGenerator中会自动生成整个源代码结构是1个SyntaxTreeSyntaxTree有一个根节点(SyntaxNode)每个SyntaxNode也包含一个SyntaxTree这样看整个源代码结构就是片“森林”public abstract p…...

用Python的igraph和leidenalg搞定知识图谱布局:一个科研领域的可视化实战
科研知识图谱实战:用PythonLeiden算法揭示学科交叉规律 当你在文献海洋中寻找研究方向时,是否曾被复杂的学科交叉关系困扰?传统的关键词共现分析已经不能满足现代科研的需求。本文将带你用Python的igraph和leidenalg构建一个能自动识别学科社…...

在GCP上运行autoresearch
Andrej Karpathy最近开源了autoresearch,这是一个将真实LLM训练环境交给AI代理并让它自主实验的项目。代理修改模型代码,训练恰好5分钟,检查验证损失是否改善,保留或丢弃更改,然后重复。你去睡觉;醒来时会看…...
)
Swiper动画进阶:手把手教你用Swiper Animate制作节日主题动画(2023最新版)
Swiper动画进阶:手把手教你用Swiper Animate制作节日主题动画(2023最新版) 当节日氛围遇上交互设计,如何让静态页面"活"起来?Swiper Animate作为Swiper生态中的动画引擎,能通过简单的类名配置实现…...

AI浪潮冲击下,前端该何去何从
🌊 初级前端工程师:向“深水区”扎根技能树与学习路径定位:面向初级前端开发工程师,聚焦底层原理、工程化思维与可验证的实战输出,构建 AI 时代不可替代的技术护城河。📐 核心原则(避坑指南&…...
)
Java AI推理服务上线即崩?JVM GC日志暴露真相:Metaspace暴涨470%、Direct Memory泄漏12.6GB——5行代码精准修复方案(含Arthas实时监控脚本)
第一章:Java AI推理服务集成概述在现代企业级AI应用架构中,Java凭借其稳定性、丰富的生态和成熟的微服务支持能力,正成为部署AI推理服务的重要后端语言。与Python主导的模型训练场景不同,Java更常用于高并发、低延迟、强事务保障的…...

AIVideo效果对比展示:不同参数下的视频生成质量评测
AIVideo效果对比展示:不同参数下的视频生成质量评测 1. 开场白:参数设置对视频效果的影响 你有没有遇到过这样的情况:用AI生成视频时,明明输入的内容一样,但出来的效果却天差地别?有时候画面模糊不清&…...

程序员做量化交易详解
程序员做量化交易详解 量化交易是程序员将编程能力与金融市场相结合的典型应用场景。作为系统分析师,理解量化交易的全貌有助于在金融IT系统设计中把握关键要素。下面为你全面解析。 📌 一、什么是量化交易? 量化交易是指利用数学模型、统计方法和计算机技术,通过程序化…...

卷积计算常见误区解析:为什么你的结果和理论值对不上?
卷积计算常见误区解析:为什么你的结果和理论值对不上? 在图像处理和深度学习领域,卷积操作是基础中的基础。但令人惊讶的是,即使是经验丰富的开发者,在实际编码时也常常遇到计算结果与预期不符的情况。这就像做菜时严格…...