【PostgreSQL内核学习(二十六) —— (共享数据缓冲区)】
共享数据缓冲区
- 概述
- 共享数据缓冲区管理
- 共享缓冲区管理的核心功能包括:
- 共享数据缓冲区的组织结构
- 初始化共享缓冲池
- BufferDesc 结构体
- InitBufferPool 函数
- 如何确定请求的数据页面是否在缓冲区中?
- BufferTag 结构体
- RelFileNode 结构体
- ForkNumber 结构体
- ReadBuffer_common 函数
- 怎么查看缓冲区中每个缓冲块的状态?
- BufferDesc 结构体
- pg_atomic_uint32
- 怎么快速找到缓冲区的空页?
- StrategyGetBuffer 函数
- BufferStrategyControl 结构体
- 如果没有空闲页了,怎么办?
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-10.1 的开源代码和《OpenGauss数据库源码解析》和《PostgresSQL数据库内核分析》一书以及一些相关资料。
概述
PostgreSQL 的共享数据缓冲区(Shared Buffer Cache)是数据库系统中用于存储从磁盘读取的数据页的内存区域,以便快速重用这些数据,从而减少对磁盘的访问次数和提高查询性能。当数据库需要访问某个数据页时,它首先检查该页是否已在共享数据缓冲区中;如果是,直接从内存中读取数据,否则从磁盘加载数据页到缓冲区再进行访问。
共享数据缓冲区的大小是可配置的,通过调整 shared_buffers 参数来实现,这个参数定义了缓冲区分配的内存量。理想的缓冲区大小取决于系统的总内存、数据库的工作负载以及其他内存需求。正确配置共享数据缓冲区对于优化数据库性能至关重要,因为它直接影响到数据检索的速度。PostgreSQL 还实现了复杂的缓冲区管理策略,比如使用 LRU(最近最少使用)算法来决定哪些数据页应当保留在缓冲区中,哪些可以被替换出去,以确保最常访问的数据页尽可能地保留在内存中。
共享数据缓冲区管理
共享缓冲区管理是数据库管理系统(DBMS)中的一个关键组件,特别是在 PostgreSQL 这样的关系数据库系统中。它涉及到数据库系统如何在内存中有效管理、缓存和访问数据页的机制。共享缓冲区(Shared Buffers)是内存中的一个区域,用于存储最近访问的数据页(包括表和索引的数据),以便快速响应后续的数据查询和操作,从而减少直接磁盘 I/O 的需求,提升数据库的整体性能。
共享缓冲区管理的核心功能包括:
- 数据页缓存: 当数据库操作需要访问磁盘上的数据页时,这些页首先被加载到共享缓冲区中。如果后续操作再次请求相同的数据页,系统可以直接从内存中获取,避免了磁盘访问的延迟。
- 写入策略: 为了保证数据的持久性,对共享缓冲区中的数据页所做的更改最终需要写回磁盘。PostgreSQL 使用写前日志(WAL)来确保即使在系统崩溃的情况下,所有的事务更改也能被恢复。数据页的实际写回可以延迟执行,直到系统认为最合适的时机,比如在缓冲区空间不足或定期检查点(Checkpoint)发生时。
- 缓冲区替换策略: 共享缓冲区的大小是有限的,当缓冲区满时,数据库需要决定哪些数据页保留在内存中,哪些被替换出去。PostgreSQL 使用近似最近最少使用(LRU)算法进行页替换,以优先保留最频繁访问的数据页。
- 配置和调优: 数据库管理员可以通过调整 shared_buffers 参数来配置共享缓冲区的大小,这通常根据系统的总内存和数据库的工作负载进行优化。合理配置共享缓冲区对于提高数据库的性能至关重要。
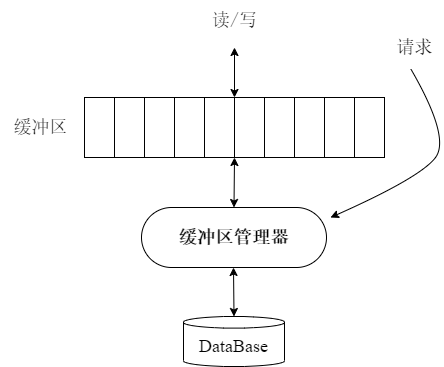
上图描绘的是数据库中共享数据缓冲区管理的概念模型,其中:
- 矩形块: 代表数据库的共享缓冲区中的多个缓冲槽(buffer slots),每个槽可以存储一个数据块的内容。这是内存中分配给数据库缓存数据块的区域。其中,一个缓存块的大小由参数 BLOCK_SIZE 定义,在系统初始化时定义。
- 椭圆形: “缓冲区管理器”(Buffer Manager)的象征,它负责管理共享缓冲区的操作,包括决定何时从磁盘读取数据块到缓冲区,何时将更改后的数据块写回磁盘,以及如何在内存中替换数据块。
- 圆柱形: “DataBase” 代表数据库的持久存储,如磁盘或其他形式的持久存储介质,其中实际存储所有数据块。
- 读/写操作: 箭头表示数据的读写操作。数据库操作(如查询和更新)首先查找共享缓冲区以确定所需的数据块是否已加载到内存中。如果找到,直接进行读写操作,提高性能;如果没有找到,从磁盘读取数据块到共享缓冲区再进行操作。
- 备份/恢复: 从共享缓冲区到数据库的双向箭头可能表示数据的备份和恢复流程。在备份时,数据从共享缓冲区写入到备份存储;在恢复时,备份数据可以重新加载到共享缓冲区,然后被恢复到数据库中。
这张数据库共享缓冲区与管理机制图展示了数据库内存中的共享缓冲区是如何被缓冲区管理器管理的,以及数据块是如何在内存和磁盘之间流动的。这种机制对于数据库的性能和数据的高效处理至关重要,因为它大大减少了对磁盘 I/O 操作的需求,而磁盘 I/O 通常是数据库操作中最耗时的部分。
共享数据缓冲区的组织结构
PostgreSQL 的共享数据缓冲区是由一组内存页组成的结构,这些页在物理上可以分散存储,但在缓冲区管理器的控制下逻辑上是连续的。每个内存页对应数据库磁盘上的一个数据块,当数据块被读取时,它们被载入这些内存页中。共享数据缓冲区的大小由 shared_buffers 配置参数确定,它定义了内存中用于缓存的页的总数。缓冲区管理器负责维护一个页表,记录哪些数据块当前在缓冲区中,以及它们的使用状态。通过精心设计的替换策略,如 LRU(最近最少使用)算法,管理器优先保留最活跃的数据块,以优化数据的访问速度和减少磁盘 I/O,从而提升数据库操作的效率。这个组织结构是实现 PostgreSQL 高性能数据处理的基础。
初始化共享缓冲池
共享缓冲池处于共享内存区域,在系统启动的时候需要对其进行初始化操作,负责这一工作的函数为 InitBufferPool。在共享缓冲池管理中,使用了一个全局数组 BufferDescriptor 来管理池中的缓冲区,其数组元素类型为 BufferDesc。数组元素个数为缓冲区的总数,用于管理所有缓冲区的描述符,可以认为 BufferDescriptors 就是共享缓冲池。另外还使用了一个全局指针变量 BufferBlocks 来存储缓冲池的起始地址。每个缓冲区对应一个描述符结构 BufferDesc,用于描述相应缓冲区的状态信息。
BufferDesc 结构体
在 PostgreSQL 的源码中,与共享数据缓冲区管理相关的主要结构体是 BufferDesc,它位于 src/include/storage/buf_internals.h 文件中。BufferDesc 结构体表示一个共享缓冲区内的单个缓冲页,其中包含了页的状态信息、锁信息、引用计数等。每个 BufferDesc 项与一个在共享内存中的数据块相对应,对应的结构体源码如下:
typedef struct BufferDesc
{BufferTag tag; /* 该缓冲页包含的页面的标识符,包含表空间、数据库、关系和块号信息 */int buf_id; /* 缓冲页的索引编号,从0开始计数 *//* 标签的状态,包含标志位、引用计数和使用计数 */pg_atomic_uint32 state; int wait_backend_pid; /* 如果有后台进程在等待该缓冲页的引用计数变为零,则这里记录该后台进程的PID */int freeNext; /* 在空闲链表中的下一个元素的链接 */LWLock content_lock; /* 用于锁定对缓冲页内容的访问的轻量级锁 */
} BufferDesc;

BufferDesc 结构体描述了 PostgreSQL 中的一个缓冲页(数据块)的元数据,这些元数据包括:
- 缓冲页的内容信息: 通过 BufferTag 结构体标识缓冲页包含的特定页面。
- 缓冲页的位置和状态信息: buf_id 用于标识缓冲页在共享缓冲区中的位置,state 用于存储缓冲页的状态,包括是否被修改(脏页)、引用计数等。
- 并发控制信息: wait_backend_pid 和 content_lock 用于在并发环境下控制对缓冲页的访问,确保数据的一致性和完整性。
- 缓冲页的链表信息: freeNext 用于将多个 BufferDesc 串联成一个链表,这通常用于维护空闲的缓冲页。
此外,管理共享数据缓冲区的核心函数和控制逻辑位于 src/backend/storage/buffer 目录下。特别是,bufmgr.c 文件包含了对缓冲区进行操作的函数,如读取、写入、分配和替换缓冲页的函数。
PostgreSQL 还使用了缓冲池的概念,通常是一个 BufferPool 结构,它是一个 BufferDesc 数组,表示整个共享缓冲区。缓冲池的管理还涉及锁定机制和引用计数,以确保对缓冲页的并发访问是安全的。
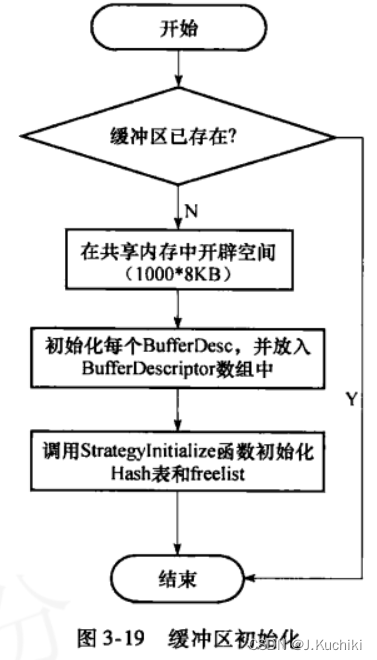
InitBufferPool 函数
其中,InitBufferPool 函数用于在数据库系统初始化期间设置共享缓冲区。这个函数首先为缓冲区描述符、缓冲区块、I/O 锁以及检查点用的缓冲区 ID 数组在共享内存中分配空间,并对它们进行初始化。这包括设置每个缓冲区描述符的状态、标识符、链接到空闲列表的下一个缓冲区、以及初始化相关的轻量级锁(LWLock)。如果这些结构在共享内存中已经存在(由 foundDescs 等变量标识),则验证它们全部存在(这是在后台进程模型中期望的情况)。若这些结构尚未存在,则初始化一个新的共享缓冲区,包括设置所有缓冲区描述符并将它们链接成空闲列表。此外,该函数还会初始化用于缓冲区管理策略的其他相关数据结构,以及为后台写回上下文设置文件刷新策略。这个函数是 PostgreSQL 启动时建立核心数据结构和内存管理基础的关键部分,对于数据库能够高效处理缓存和 I/O 操作至关重要。函数源码如下所示:(路径:src\backend\storage\buffer\buf_init.c)
/* 初始化共享缓冲池 */
void
InitBufferPool(void)
{/* 几个布尔变量,用于标记是否已经找到了共享内存中的相应结构 */bool foundBufs,foundDescs,foundIOLocks,foundBufCkpt;/* 将缓冲描述符对齐到缓存线界限 */BufferDescriptors = (BufferDescPadded *)ShmemInitStruct("Buffer Descriptors",NBuffers * sizeof(BufferDescPadded),&foundDescs);BufferBlocks = (char *)ShmemInitStruct("Buffer Blocks",NBuffers * (Size) BLCKSZ, &foundBufs);/* 将轻量级锁对齐到缓存线界限 */BufferIOLWLockArray = (LWLockMinimallyPadded *)ShmemInitStruct("Buffer IO Locks",NBuffers * (Size) sizeof(LWLockMinimallyPadded),&foundIOLocks);LWLockRegisterTranche(LWTRANCHE_BUFFER_IO_IN_PROGRESS, "buffer_io");LWLockRegisterTranche(LWTRANCHE_BUFFER_CONTENT, "buffer_content");/** 用于排序待检查点缓冲区ID的数组位于共享内存中,* 以避免在运行时分配大量内存。因为这将在检查点过程中进行,* 或者当检查点重启时,内存分配失败将是痛苦的。*/CkptBufferIds = (CkptSortItem *)ShmemInitStruct("Checkpoint BufferIds",NBuffers * sizeof(CkptSortItem), &foundBufCkpt);if (foundDescs || foundBufs || foundIOLocks || foundBufCkpt){/* 应该同时找到所有这些,或者一个都不找到 */Assert(foundDescs && foundBufs && foundIOLocks && foundBufCkpt);/* 注意:这条路径只在 EXEC_BACKEND 情况下执行 */}else{int i;/** 初始化所有缓冲头。*/for (i = 0; i < NBuffers; i++){BufferDesc *buf = GetBufferDescriptor(i);CLEAR_BUFFERTAG(buf->tag);pg_atomic_init_u32(&buf->state, 0);buf->wait_backend_pid = 0;buf->buf_id = i;/** 最初将所有缓冲区作为未使用的链接在一起。* 后续的这个列表的管理由 freelist.c 执行。*/buf->freeNext = i + 1;LWLockInitialize(BufferDescriptorGetContentLock(buf),LWTRANCHE_BUFFER_CONTENT);LWLockInitialize(BufferDescriptorGetIOLock(buf),LWTRANCHE_BUFFER_IO_IN_PROGRESS);}/* 纠正链接列表的最后一个条目 */GetBufferDescriptor(NBuffers - 1)->freeNext = FREENEXT_END_OF_LIST;}/* 初始化其他共享缓冲管理相关的东西 */StrategyInitialize(!foundDescs);/* 初始化每个后端文件刷新上下文 */WritebackContextInit(&BackendWritebackContext,&backend_flush_after);
}
其中,BufferBlocks[] 使用 buffer_id 标识每个缓冲块。
如何确定请求的数据页面是否在缓冲区中?
在 PostgreSQL 中,确定请求的数据页面是否在缓冲区中,主要涉及共享缓冲区(Shared Buffer Cache)的查找过程。这个过程大致如下:
- 缓冲区标识: 每个数据页面在缓冲区中的存在通过一个缓冲区标识符(BufferTag)来标识。这个标识符包括表空间 ID(Tablespace OID)、数据库 ID(Database OID)、关系 ID(Relation OID)、分叉号(Fork Number),以及块号(Block Number)。这些信息共同定义了数据页面的唯一性。
- 缓冲区哈希表: PostgreSQL 使用一个缓冲区哈希表(Buffer Mapping Hash Table)来快速查找缓冲区中是否存在指定的数据页面。这个哈希表将缓冲区标识符映射到缓冲区描述符(Buffer Descriptor)。
- 查找过程:
• 当数据库需要访问一个数据页面时,它首先构造该页面的缓冲区标识符。
• 然后,数据库通过缓冲区哈希表查找该标识符对应的缓冲区描述符。
• 如果找到了匹配的缓冲区描述符,这意味着请求的数据页面已经在共享缓冲区中。 - 缓冲区描述符: 缓冲区描述符包含了关于缓冲区状态的信息,如是否被锁定、是否被修改(脏页面),以及关联的数据页面等。如果数据页面在缓冲区中找到,数据库可以直接从内存中访问这个页面,避免了磁盘 I/O 操作。
- 未命中缓冲区: 如果请求的数据页面不在缓冲区中(即缓冲区哈希表中没有找到对应的缓冲区描述符),PostgreSQL 需要从磁盘读取该页面。读取后,数据库可能需要在共享缓冲区中为这个页面分配一个新的缓冲槽,并更新缓冲区哈希表,以便未来的访问可以直接从内存中获取。
通过这种机制,PostgreSQL 可以有效地管理内存中的数据页面,优化数据访问性能。这个过程是数据库缓冲区管理策略的一部分,对于减少数据库的响应时间和提高事务处理的吞吐量至关重要。
BufferTag 结构体
BufferTag 结构体,它在 PostgreSQL 中用于唯一标识共享缓冲区中的一个数据块。BufferTag 是缓冲区管理系统的核心部分,它允许数据库精确地追踪和访问内存中的数据页面。下面是对该结构体中每个字段的详细解释:(路径:src\include\storage\buf_internals.h)
typedef struct buftag
{RelFileNode rnode; /* 物理关系标识符,用于唯一标识一个数据库中的表或索引 */ForkNumber forkNum; /* 分叉号,指明数据块属于关系的哪个物理文件(如主数据文件、TOAST文件等)*/BlockNumber blockNum; /* 块号,相对于关系的开始位置,用于在其所属分叉中唯一标识一个数据块 */
} BufferTag;
BufferTag 结构体通过组合关系的物理标识符、分叉号和块号,BufferTag 能够精确地指向数据库中的一个具体数据块,这对于缓冲区管理、数据访问和数据一致性维护至关重要。BufferTag 可以用来查询对应于该文件块的缓冲区,查询流程如下:

RelFileNode 结构体
RelFileNode 结构体在 PostgreSQL 中用于表示一个数据库关系(如表或索引)的物理位置。结构体中的每个字段都是使用 Oid(对象标识符)类型表示的,用于唯一标识数据库中的对象。下面是对该结构体中每个字段的详细解释:(路径:D:\pg相关src\include\storage\relfilenode.h)
typedef struct RelFileNode
{Oid spcNode; /* 表空间的 OID,用于标识数据块所在的表空间 */Oid dbNode; /* 数据库的 OID,用于标识数据块所属的数据库 */Oid relNode; /* 关系的 OID,用于标识具体的表或索引 */
} RelFileNode;
RelFileNode 结构体通过组合表空间、数据库和关系的 OID 来完整地描述了一个数据库对象的物理存储位置。这使得 PostgreSQL 能够准确地定位到存储在磁盘上的数据块,是实现数据管理和访问的基础。在数据库系统中,表空间用于管理磁盘上的数据文件,数据库 OID 将数据块与特定的数据库实例关联起来,而关系 OID 则指定了数据块属于哪个具体的表或索引。这种层次化的标识方法为 PostgreSQL 的数据存储和访问提供了高度的灵活性和效率。
ForkNumber 结构体
ForkNumber 是枚举类型,它在 PostgreSQL 中用于标识关系(如表或索引)的不同物理存储分叉。每个分叉代表了关系的不同物理部分,主要用于存储数据、自由空间信息、可见性信息等。以下是对各个枚举成员的详细中文注释:(路径:src\include\common\relpath.h)
typedef enum ForkNumber
{InvalidForkNumber = -1, /* 无效的分叉编号,用于错误检查或初始化 */MAIN_FORKNUM = 0, /* 主分叉,用于存储表的实际数据 */FSM_FORKNUM, /* 自由空间地图(Free Space Map)分叉,用于跟踪表中未使用的空间 */VISIBILITYMAP_FORKNUM, /* 可见性地图分叉,用于跟踪哪些页面对哪些事务可见 */INIT_FORKNUM /* 初始分叉,用于存储关系的初始化分叉,仅在关系创建时使用 *//** 注意:如果添加了新的分叉,需要修改 MAX_FORKNUM 和可能的 FORKNAMECHARS,* 并在 src/common/relpath.c 中更新 forkNames 数组*/
} ForkNumber;
ReadBuffer_common 函数
ReadBuffer_common 函数是 PostgreSQL 缓冲区读取操作的核心逻辑。该函数负责从共享缓冲区中读取指定的数据块,如果数据块不在缓冲区中,则从磁盘加载。这个过程涵盖了检查缓冲区是否已存在所需数据块、处理缓冲区分配、读取数据块等多个步骤。以下是对代码的详细解释:(路径:src\backend\storage\buffer\bufmgr.c)
/* ReadBuffer_common -- 所有ReadBuffer变种的通用逻辑** 如果请求从共享缓冲区缓存中得到满足,则*hit被设置为true。*/
static Buffer
ReadBuffer_common(SMgrRelation smgr, char relpersistence, ForkNumber forkNum,BlockNumber blockNum, ReadBufferMode mode,BufferAccessStrategy strategy, bool *hit)
{BufferDesc *bufHdr;Block bufBlock;bool found;bool isExtend;bool isLocalBuf = SmgrIsTemp(smgr);*hit = false;/* 确保我们有足够的空间来记住缓冲区锁 */ResourceOwnerEnlargeBuffers(CurrentResourceOwner);isExtend = (blockNum == P_NEW); // 是否扩展操作TRACE_POSTGRESQL_BUFFER_READ_START(forkNum, blockNum,smgr->smgr_rnode.node.spcNode,smgr->smgr_rnode.node.dbNode,smgr->smgr_rnode.node.relNode,smgr->smgr_rnode.backend,isExtend);/* 如果调用者请求了P_NEW,替换为适当的块号 */if (isExtend)blockNum = smgrnblocks(smgr, forkNum);if (isLocalBuf) // 如果是本地缓冲区{bufHdr = LocalBufferAlloc(smgr, forkNum, blockNum, &found);if (found)pgBufferUsage.local_blks_hit++;elsepgBufferUsage.local_blks_read++;}else // 如果是共享缓冲区{/** 查找缓冲区。如果请求的块当前不在内存中,则设置IO_IN_PROGRESS。*/bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum,strategy, &found);if (found)pgBufferUsage.shared_blks_hit++;elsepgBufferUsage.shared_blks_read++;}/* 在这一点上我们不持有任何锁。 *//* 如果缓冲池中已经存在所请求的数据块,则完成处理 */if (found){if (!isExtend){/* 如果不是扩展操作,只需更新统计信息即可 */*hit = true; // 标记命中缓冲池VacuumPageHit++; // 更新真空清理命中的页面数if (VacuumCostActive) // 如果真空清理成本模型激活VacuumCostBalance += VacuumCostPageHit; // 更新真空清理成本TRACE_POSTGRESQL_BUFFER_READ_DONE(forkNum, blockNum,smgr->smgr_rnode.node.spcNode,smgr->smgr_rnode.node.dbNode,smgr->smgr_rnode.node.relNode,smgr->smgr_rnode.backend,isExtend,found);/* 如果是 RBM_ZERO_AND_LOCK 模式,调用者期望在返回时页面被锁定 */if (!isLocalBuf) // 如果不是本地缓冲区{if (mode == RBM_ZERO_AND_LOCK) // 如果模式为零并锁定LWLockAcquire(BufferDescriptorGetContentLock(bufHdr),LW_EXCLUSIVE); // 获取内容锁else if (mode == RBM_ZERO_AND_CLEANUP_LOCK) // 如果模式为零并进行清理锁定LockBufferForCleanup(BufferDescriptorGetBuffer(bufHdr)); // 获取清理锁}return BufferDescriptorGetBuffer(bufHdr); // 返回缓冲区描述符对应的缓冲区}/* 处理试图扩展关系但发现已存在标记为 BM_VALID 的缓冲区的特殊情况 */bufBlock = isLocalBuf ? LocalBufHdrGetBlock(bufHdr) : BufHdrGetBlock(bufHdr); // 获取缓冲区块if (!PageIsNew((Page) bufBlock)) // 如果页面不是新的ereport(ERROR,(errmsg("unexpected data beyond EOF in block %u of relation %s",blockNum, relpath(smgr->smgr_rnode, forkNum)),errhint("This has been seen to occur with buggy kernels; consider updating your system.")));/* 在成功之前,我们必须执行 smgrextend,否则内核不会保留该页 */if (isLocalBuf){/* 只需要调整标志 */uint32 buf_state = pg_atomic_read_u32(&bufHdr->state);Assert(buf_state & BM_VALID); // 断言缓冲区状态为有效buf_state &= ~BM_VALID; // 清除有效位pg_atomic_unlocked_write_u32(&bufHdr->state, buf_state); // 更新缓冲区状态}else{/* 处理可能有人在我们清除 BM_VALID 和 StartBufferIO 检查它之间重新设置 BM_VALID 的小概率事件 */do{uint32 buf_state = LockBufHdr(bufHdr); // 锁定缓冲区头Assert(buf_state & BM_VALID); // 断言缓冲区状态为有效buf_state &= ~BM_VALID; // 清除有效位UnlockBufHdr(bufHdr, buf_state); // 解锁缓冲区头} while (!StartBufferIO(bufHdr, true)); // 开始缓冲区 IO}}/* 在这一点上,我们已为页面分配了缓冲区,但其内容尚未有效。如果是共享缓冲区,IO_IN_PROGRESS 已设置。*/Assert(!(pg_atomic_read_u32(&bufHdr->state) & BM_VALID)); // 断言缓冲区状态不为有效(不需要自旋锁)bufBlock = isLocalBuf ? LocalBufHdrGetBlock(bufHdr) : BufHdrGetBlock(bufHdr); // 获取缓冲区块if (isExtend){/* 新缓冲区被零填充 */MemSet((char *) bufBlock, 0, BLCKSZ); // 零填充新缓冲区smgrextend(smgr, forkNum, blockNum, (char *) bufBlock, false); // 扩展存储管理器中的文件}else{/* 读取页面,除非调用者打算覆盖它,只是希望我们分配一个缓冲区。*/// 省略了读取数据块并进行错误处理的代码}/* 如果模式为 RBM_ZERO_AND_LOCK 或 RBM_ZERO_AND_CLEANUP_LOCK,在标记页面有效之前获取缓冲区内容锁 */if ((mode == RBM_ZERO_AND_LOCK || mode == RBM_ZERO_AND_CLEANUP_LOCK) && !isLocalBuf){LWLockAcquire(BufferDescriptorGetContentLock(bufHdr), LW_EXCLUSIVE); // 获取独占内容锁}if (isLocalBuf){/* 只需要调整标志 */uint32 buf_state = pg_atomic_read_u32(&bufHdr->state);buf_state |= BM_VALID; // 设置缓冲区状态为有效pg_atomic_unlocked_write_u32(&bufHdr->state, buf_state); // 更新缓冲区状态}else{/* 设置 BM_VALID,终止 IO,并唤醒任何等待者 */TerminateBufferIO(bufHdr, false, BM_VALID); // 终止缓冲区 IO}VacuumPageMiss++; // 更新真空清理未命中页面数if (VacuumCostActive) // 如果真空清理成本模型激活VacuumCostBalance += VacuumCostPageMiss; // 更新真空清理成本TRACE_POSTGRESQL_BUFFER_READ_DONE(forkNum, blockNum,smgr->smgr_rnode.node.spcNode,smgr->smgr_rnode.node.dbNode,smgr->smgr_rnode.node.relNode,smgr->smgr_rnode.backend,isExtend,found); // 跟踪日志return BufferDescriptorGetBuffer(bufHdr); // 返回缓冲区描述符对应的缓冲区
}
函数首先检查是否为扩展操作(请求新的块 P_NEW),然后根据是本地缓冲区还是共享缓冲区采取不同的处理策略。对于共享缓冲区,BufferAlloc 函数用于尝试找到缓冲区,如果找到,则更新命中或读取的统计信息;如果未找到,则进行进一步的处理,包括可能的磁盘读取。
如果请求的数据块已经存在于缓冲区中(found == true),则根据是否是扩展操作和读取模式(如 RBM_ZERO_AND_LOCK)进行适当的处理,包括锁定页面以供调用者使用。
如果数据块不在缓冲区中,ReadBuffer_common 会进行磁盘读取或为新的数据块分配缓冲区。这涉及到处理缓冲区的有效性标记、执行实际的磁盘读取操作,以及在必要时进行错误处理。
怎么查看缓冲区中每个缓冲块的状态?
在 PostgreSQL 中,要查看缓冲区中每个缓冲块的状态,你需要访问共享缓冲区中的缓冲区描述符(Buffer Descriptor),这是因为缓冲区描述符包含了关于缓冲块状态的详细信息。此外,某些扩展和贡献模块,如 pg_buffercache,提供了查看缓冲区状态的功能。
其中,BufferDescriptors[] 是一个数组,提供缓冲区页面的描述信息。
BufferDescPadded *BufferDescriptors;typedef union BufferDescPadded
{BufferDesc bufferdesc;char pad[BUFFERDESC_PAD_TO_SIZE];
} BufferDescPadded;
BufferDesc 结构体
BufferDesc 结构体,它是 PostgreSQL 中用于描述共享缓冲区中一个缓冲块(buffer block)的状态和属性的数据结构。共享缓冲区是 PostgreSQL 用于缓存磁盘上数据页的内存区域,以减少对磁盘的访问次数和提高数据库性能。以下是对 BufferDesc 结构体中每个字段的详细解释:(路径:src\include\storage\buf_internals.h)
typedef struct BufferDesc
{BufferTag tag; /* 缓冲块中包含的页面的ID,用于唯一标识一个数据库页面 */int buf_id; /* 缓冲块的索引号,从0开始计数 *//* 标签的状态,包含标志位、引用计数和使用计数 */pg_atomic_uint32 state; int wait_backend_pid; /* 等待该缓冲块引用计数变为0的后台进程PID */int freeNext; /* 在空闲链表中的下一个缓冲块的链接 */LWLock content_lock; /* 用于锁定对缓冲块内容的访问的轻量级锁 */
} BufferDesc;
其中,pg_atomic_uint32 state 是一个原子变量,存储了缓冲块的状态,包括但不限于是否被修改(脏页)、是否被固定(引用计数)以及访问频率(使用计数)。pg_atomic_uint32 结构体是 PostgreSQL 中用于实现跨平台原子操作的数据结构。原子操作是指在多线程环境下,能够保证被执行的操作在开始到结束期间不会被其他线程中断的操作。在数据库系统中,这种操作对于维护数据的一致性和完整性至关重要。
typedef struct pg_atomic_uint32
{/* 根据 pg_atomic_flag 的定义,这里的注释说明了为何需要这样的定义 */
#if defined(__hppa) || defined(__hppa__) /* 针对 HP PA-RISC 架构,适用于 GCC 和 HP 编译器 */int sema[4]; /* 使用数组提供足够的空间来实现原子操作的信号量 */
#elseint sema; /* 在其他平台上,一个 int 类型足以作为原子操作的信号量 */
#endifvolatile uint32 value; /* 实际存储的无符号32位整数值,声明为 volatile 以防止编译器优化导致的问题 */
} pg_atomic_uint32;
pg_atomic_uint32
BufferDesc 结构体中的 state 字段是一个非常关键的部分,用于存储缓冲块(Buffer Block)的当前状态信息。这个字段是 pg_atomic_uint32 类型,表示它是一个原子的无符号 32 位整数。在 PostgreSQL 的多线程环境中,原子操作确保了在读写这个字段时的线程安全。
state 字段中包含的信息非常丰富,它通过位掩码的方式存储了多个状态标志(flags),如下表所示:
| 状态 | 描述 |
|---|---|
| BM_LOCKED | 表明缓冲区当前被锁定,防止其他进程访问,以确保数据的一致性。 |
| BM_DIRTY | 表示缓冲区中的数据已被修改(脏数据),需要在某个时刻写回(同步)到磁盘上。 |
| BM_VALID | 指示缓冲区中的数据是最新的,并且可以被数据库进程安全地读取。 |
| BM_TAG_VALID | 表示缓冲区的标签(BufferTag,包含表空间、数据库、关系和块号等信息)是有效的,说明缓冲区已经被分配给特定的数据页。 |
| BM_IO_IN_PROGRESS | 标记当前缓冲区正在进行 I/O 操作,如读取或写入磁盘。 |
| BM_IO_ERROR | 表示最近一次对该缓冲区的 I/O 操作发生了错误。 |
| BM_JUST_DIRTIED | 表示缓冲区在最近的写操作开始后被修改过。 |
| BM_PIN_COUNT_WAITER | 存在进程正在等待缓冲区的固定计数(pin count)变为 0,以便它们可以对缓冲区进行操作。 |
| BM_CHECKPOINT_NEEDED | 缓冲区需要在下一个检查点(Checkpoint)被写回磁盘,以确保数据的持久性。 |
| BM_PERMANENT | 表示缓冲区包含的是持久化存储的数据,不是临时或未记录日志的数据。 |
结论:通过 BufferDesc 结构体中的 state 字段来查看缓冲区中每个缓冲块的状态。
怎么快速找到缓冲区的空页?
在 PostgreSQL 中,快速找到缓冲区的空页(即未被使用的缓冲槽)依赖于缓冲区管理策略,特别是空闲缓冲槽的管理机制。PostgreSQL 使用几种策略来跟踪和回收空闲的缓冲槽,以便它们可以被重新利用来存储新的数据页。以下是一些关键的机制:
- 缓冲区替换策略
PostgreSQL 使用的一种常见缓冲区替换策略是时钟算法(一种近似的 LRU 算法)。在这种策略中,每个缓冲槽都关联一个使用标记,当缓冲槽被访问时,该标记被设置。时钟算法周期性地扫描缓冲槽,并根据使用标记来选择被替换的缓冲槽。未被使用(即空页)的缓冲槽会优先被选中用于存储新的数据页。 - 空闲列表
PostgreSQL 维护一个空闲列表,用于快速查找可用的缓冲槽。当缓冲槽中的数据被写回磁盘并且不再被任何事务引用时,这个缓冲槽就会被添加到空闲列表中。需要新的缓冲槽来存储数据页时,系统会首先检查空闲列表。 - 缓冲区描述符
每个缓冲槽都有一个对应的 BufferDesc 结构体,其中包含了缓冲槽的状态信息。通过检查这些描述符的状态字段,系统可以确定哪些缓冲槽当前未被使用。 - 后台写回进程(Checkpointer 和 Background Writer)
PostgreSQL 的后台写回进程定期将脏页(修改过的缓冲槽)写回磁盘。一旦数据被写回,相关的缓冲槽就可以被标记为可用,从而增加了空闲缓冲槽的数量。
StrategyGetBuffer 函数
StrategyGetBuffer 函数在 PostgreSQL 的缓冲管理策略中选择一个用于 BufferAlloc() 的候选缓冲区。函数首先尝试使用给定的缓冲访问策略(如果有)来选择缓冲区。如果没有策略或策略没有选中任何缓冲区,它会尝试从空闲列表中获取一个缓冲区。如果空闲列表中没有可用的缓冲区,函数将使用时钟扫描算法来找到一个未被锁定的缓冲区。该函数确保返回的缓冲区在返回时保持锁定状态,以防止在缓冲区被锁定之前其他进程锁定它。这个过程是 PostgreSQL 管理其共享缓冲区,特别是在高并发环境下,确保数据的一致性和访问效率的关键部分。函数源码如下所示:(路径:src\backend\storage\buffer\freelist.c)
/** StrategyGetBuffer** 由缓冲管理器调用,以获取用于BufferAlloc()的下一个候选缓冲区。* BufferAlloc()的唯一硬性要求是所选的缓冲区当前不能被任何人锁定。** strategy 是一个 BufferAccessStrategy 对象,或者为 NULL 表示默认策略。** 为了确保在我们锁定缓冲区之前没有其他人能够锁定它,我们必须* 在返回缓冲区时保持缓冲区头部的自旋锁(spinlock)。*/
BufferDesc *
StrategyGetBuffer(BufferAccessStrategy strategy, uint32 *buf_state)
{BufferDesc *buf;int bgwprocno;int trycounter;uint32 local_buf_state; /* 避免重复引用和解引用 *//** 如果提供了策略对象,看它是否能选择一个缓冲区。我们* 假设策略对象不需要 buffer_strategy_lock。*/if (strategy != NULL){buf = GetBufferFromRing(strategy, buf_state);if (buf != NULL)return buf;}/** 如果需要,我们需要唤醒后台写入器(bgwriter)。因为我们不想依赖* 自旋锁来完成这个工作,所以我们强制先从共享内存中读取一次,然后* 基于该值设置闩锁(latch)。我们需要这样做是因为否则 bgprocno 在我们* 检查时可能会被重置,因为编译器可能会重新从内存中读取。*/bgwprocno = INT_ACCESS_ONCE(StrategyControl->bgwprocno);if (bgwprocno != -1){/* 首先重置 bgwprocno,然后再设置闩锁 */StrategyControl->bgwprocno = -1;/** 这里没有获取 ProcArrayLock,这稍微有点问题。实际上这是安全的,* 因为 procLatch 永远不会被释放,所以我们只是可能设置了错误进程的* 闩锁(或没有设置任何进程的闩锁)。*/SetLatch(&ProcGlobal->allProcs[bgwprocno].procLatch);}/** 我们计算缓冲区分配请求的次数,以便后台写入器可以估计缓冲区消耗的速率。* 注意,通过策略对象回收的缓冲区在这里故意不被计数。*/pg_atomic_fetch_add_u32(&StrategyControl->numBufferAllocs, 1);/** 首先在不获取锁的情况下检查是否有缓冲区在空闲列表中。因为我们在大多数* StrategyGetBuffer()调用中不需要自旋锁,所以如果在这里无用地获取它会很遗憾 -* 在大多数情况下是不必要的。这显然留下了一个竞争条件,即一个缓冲区被放入空闲列表* 但我们还没看到存储 - 但这是相当无害的,它将在下一次缓冲区获取时被使用。** 如果空闲列表中有缓冲区,获取自旋锁以从空闲列表中弹出一个缓冲区。* 然后检查该缓冲区是否可用,如果不可用则重试。** 注意 freeNext 字段被认为是由 buffer_strategy_lock 而不是* 个别缓冲区自旋锁保护的,所以在不持有自旋锁的情况下操作它们是可以的。*/if (StrategyControl->firstFreeBuffer >= 0){while (true){/* 获取自旋锁以从空闲列表中移除元素 */SpinLockAcquire(&StrategyControl->buffer_strategy_lock);if (StrategyControl->firstFreeBuffer < 0){SpinLockRelease(&StrategyControl->buffer_strategy_lock);break;}buf = GetBufferDescriptor(StrategyControl->firstFreeBuffer);Assert(buf->freeNext != FREENEXT_NOT_IN_LIST);/* 无条件地从空闲列表中移除缓冲区 */StrategyControl->firstFreeBuffer = buf->freeNext;buf->freeNext = FREENEXT_NOT_IN_LIST;/** 释放锁,以便其他人可以在我们检查这个缓冲区时访问空闲列表。*/SpinLockRelease(&StrategyControl->buffer_strategy_lock);/** 如果缓冲区被锁定或有非零的使用计数,我们不能使用它;* 丢弃它并重试。(如果VACUUM将一个有效的缓冲区放入空闲列表,* 然后其他人在我们到达之前使用它,这种情况可能发生。自 8.3 版本以来,* 这种情况可能完全不会发生,但我们还是应该检查。)*/local_buf_state = LockBufHdr(buf);if (BUF_STATE_GET_REFCOUNT(local_buf_state) == 0&& BUF_STATE_GET_USAGECOUNT(local_buf_state) == 0){if (strategy != NULL)AddBufferToRing(strategy, buf);*buf_state = local_buf_state;return buf;}UnlockBufHdr(buf, local_buf_state);}}/* 如果空闲列表为空,运行“时钟扫描”算法 */trycounter = NBuffers;for (;;){/* 使用时钟扫描的当前位置获取缓冲区描述符 */buf = GetBufferDescriptor(ClockSweepTick());/** 如果缓冲区被固定(pinned)或有非零的使用计数,我们不能使用它;* 减少使用计数(除非被固定)并继续扫描。*/local_buf_state = LockBufHdr(buf);if (BUF_STATE_GET_REFCOUNT(local_buf_state) == 0){if (BUF_STATE_GET_USAGECOUNT(local_buf_state) != 0){/* 减少缓冲区的使用计数并重置尝试计数器 */local_buf_state -= BUF_USAGECOUNT_ONE;trycounter = NBuffers;}else{/* 找到了一个可用的缓冲区 */if (strategy != NULL)AddBufferToRing(strategy, buf);*buf_state = local_buf_state;return buf;}}else if (--trycounter == 0){/** 我们已经扫描了所有的缓冲区而没有做任何状态改变,* 所以所有的缓冲区都被固定了(或在我们查看它们时是这样)。* 我们可以希望有人最终会释放一个缓冲区,但失败可能比陷入* 无限循环更好。*/UnlockBufHdr(buf, local_buf_state);elog(ERROR, "no unpinned buffers available");}UnlockBufHdr(buf, local_buf_state);}
}
其中,GetBufferDescriptor(StrategyControl->firstFreeBuffer) 根据缓冲区 ID(StrategyControl->firstFreeBuffer)获取对应的缓冲区描述符 (BufferDesc)。这个函数根据缓冲区的索引号(在这个上下文中是 StrategyControl->firstFreeBuffer,表示空闲列表中第一个空闲缓冲区的索引)来检索对应的 BufferDesc 结构体。BufferDesc 结构体包含了缓冲区的元数据,如缓冲区的状态、锁信息、所持数据页的标识等信息。
BufferStrategyControl 结构体
BufferStrategyControl 结构体是 PostgreSQL 中用于控制共享缓冲区空闲列表的关键数据结构。这个结构体包含了管理缓冲区分配策略所需的控制信息和统计数据。它在 PostgreSQL 的缓冲区管理系统中扮演着至关重要的角色。此结构体封装了控制和监视共享缓冲区空闲列表的各种元素和统计信息,使得 PostgreSQL 能够有效地管理其缓冲区资源,优化数据的读写操作,并提高整体数据库性能。函数源码如下所示:(路径:src\backend\storage\buffer\freelist.c)
/** 共享的空闲列表控制信息。*/
typedef struct
{/* 自旋锁:保护下面列出的值 */slock_t buffer_strategy_lock;/** 时钟扫描的指针:下一个考虑用于替换的缓冲区的索引。注意这不是一个具体的缓冲区 -* 我们只是不断增加这个值。因此,要得到一个实际的缓冲区,需要对其使用 NBuffers 取模。*/pg_atomic_uint32 nextVictimBuffer;/* 空闲列表的头部索引,指向未使用的缓冲区列表的开始 */int firstFreeBuffer;/* 空闲列表的尾部索引,指向未使用的缓冲区列表的结束 *//** 注意:当 firstFreeBuffer 为 -1 时(即列表为空),lastFreeBuffer 是未定义的*//** 统计数据。这些计数器的宽度应该足够宽,以确保它们不会在一个后台写入器周期内溢出。*/uint32 completePasses; /* 时钟扫描的完整循环次数 */pg_atomic_uint32 numBufferAllocs; /* 自上次重置以来分配的缓冲区数量 *//** 在发生活动时需要通知的后台工作进程号,或者如果没有则为 -1。参见 StrategyNotifyBgWriter。*/int bgwprocno;
} BufferStrategyControl;/* 指向共享状态的指针 */
static BufferStrategyControl *StrategyControl = NULL;
如果没有空闲页了,怎么办?
- 使用时钟扫描算法寻找替换候选
当没有空闲页时,PostgreSQL 会运行时钟扫描(Clock Sweep)算法来寻找一个替换候选。这个算法会遍历缓冲区,寻找引用计数为零(即没有被任何查询或事务锁定)的缓冲页。时钟算法还考虑了缓冲页的使用计数(一个衡量页面活跃程度的指标),尽可能地选择最不活跃的页进行替换。(后面有机会再做详细的学习) - 写回脏页
如果选中的替换候选是脏页(即自上次写入以来已被修改),PostgreSQL 需要先将这些更改写回磁盘。这确保了数据的持久性,并释放了缓冲页以供重新使用。 - 强制检查点
在极端情况下,如果缓冲区压力过大,PostgreSQL 可能会提前触发一个检查点(Checkpoint)。检查点的过程会将所有脏页写回磁盘,并更新事务日志,从而减少了在故障恢复时需要重放的日志量。通过这种方式,检查点可以间接释放更多的缓冲页。 - 调整缓冲区大小和配置
如果频繁遇到没有空闲页的情况,可能表明共享缓冲区大小配置(shared_buffers 参数)不足以满足当前的工作负载需求。在这种情况下,数据库管理员可能需要考虑增加共享缓冲区的大小或者优化查询以减少对缓冲区的需求。 - 后台写入器和检查点进程
PostgreSQL 的后台写入器(Background Writer)进程和检查点(Checkpoint)进程也会定期将脏页写回磁盘。这有助于确保有足够的空闲页可用于即将到来的数据库操作。 - 错误处理
如果经过上述所有步骤后,仍然无法找到可用的缓冲页,PostgreSQL 将无法分配新的缓冲页。在极端情况下,这可能导致数据库操作失败,PostgreSQL 会抛出错误。这种情况下,通常需要数据库管理员介入进行进一步的诊断和配置调整。
相关文章:
【PostgreSQL内核学习(二十六) —— (共享数据缓冲区)】
共享数据缓冲区 概述共享数据缓冲区管理共享缓冲区管理的核心功能包括: 共享数据缓冲区的组织结构初始化共享缓冲池BufferDesc 结构体InitBufferPool 函数 如何确定请求的数据页面是否在缓冲区中?BufferTag 结构体RelFileNode 结构体ForkNumber 结构体Re…...
word调整论文格式的记录
页眉的分章显示内容 效果: 步骤: 确保“显示/隐藏的标记”符号打开点亮 前提是章节前面有“分节符(下一页)”,没有则添加,在菜单栏“布局”——》“下一页” 添加页眉,双击页眉,选…...

android.MediaMuxer时间裁剪
使用MediaMuxer裁剪视频_安卓muxer 裁剪视频画布-CSDN博客 关键步骤 mediaExtractor.seekTo(beginTime, MediaExtractor.SEEK_TO_PREVIOUS_SYNC);long presentTimeUs mediaExtractor.getSampleTime(); if (presentTimeUs > endTime)break; 功能代码 VideoView videoVie…...

【蓝桥杯选拔赛真题91】Scratch筛选数据 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch筛选数据 一、题目要求 编程实现 二、案例分析 1、角色分析...

英语学习——16组英语常用短语
第1组:look look at 看 look for 寻找 look up 查阅,向上看 look out 向外看,小心 look after 照顾 look like 看起来像 look through 浏览 look into 向里看 look around 环顾四周 look forward to 期盼 look ahead 向前看 Look…...
unity 增加系统时间显示、FPS帧率、ms延迟
代码 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;using UnityEngine;public class Frame : MonoBehaviour {// 记录帧数private int _frame;// 上一次计算帧率的时间private float _lastTime;// 平…...
【Python基础】文件详解(文件基础、csv文件、时间处理、目录处理、excel文件、jsonpicke、ini配置文件)
文章目录 (一)文件详解1 快速入门文件操作1.1 快速实现文件读取1.2 快速实现文件写入 2 文件打开方式详解2.1 open方法2.2 打开方式2.3 文件读写操作2.3.1 基本读写2.3.2 读写方式打开2.3.3 实现重复读取 3 文件编码问题4 文件读写方法4.1 文件读取方式4…...
[UI5 常用控件] 05.FlexBox, VBox,HBox,HorizontalLayout,VerticalLayout
文章目录 前言1. FlexBox布局控件1.1 alignItems 对齐模式1.2 justifyContent 对齐模式1.3 Direction1.4 Sort1.5 Render Type1.6 嵌套使用1.7 组件等高显示 2. HBox,VBox3. HorizontalLayout,VerticalLayout 前言 本章节记录常用控件FlexBox,VBox,HBox,Horizontal…...

Unity类银河恶魔城学习记录1-14 AttackDirection源代码 P41
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili PlayerPrimaryAttackState.cs using System.Collections; using System.Co…...
DataX详解和架构介绍
系列文章目录 一、 DataX详解和架构介绍 二、 DataX源码分析 JobContainer 三、DataX源码分析 TaskGroupContainer 四、DataX源码分析 TaskExecutor 五、DataX源码分析 reader 六、DataX源码分析 writer 七、DataX源码分析 Channel 文章目录 系列文章目录DataX是什么ÿ…...
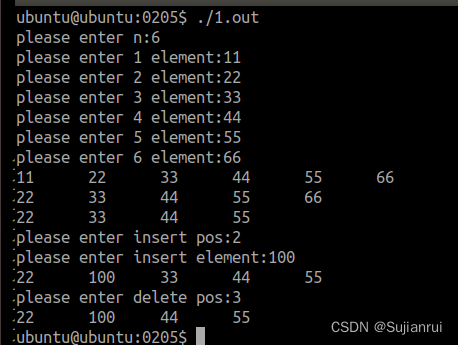
02.05
1.单链表 main #include "1list_head.h" int main(int argc, const char *argv[]) { //创建链表之前链表为空Linklist headNULL;int n;datatype element;printf("please enter n:");scanf("%d",&n);for(int i0;i<n;i){printf("ple…...
【C语言】贪吃蛇 详解
该项目需要的技术要点 C语言函数、枚举、结构体、动态内存管理、预处理指令、链表、Win32API等。 由于篇幅限制 和 使知识模块化, 若想了解 使用到的 Win32API 的知识:请点击跳转:【Win32API】贪吃蛇会使用到的 Win32API 目录 1. 贪吃蛇游…...

Mysql MGR搭建
一、架构说明 1.1 架构概述 MGR(单主)VIP架构是一种分布式数据库架构,其中数据库系统采用单主复制模式, 同时引入虚拟IP(VIP)来提高可用性和可扩展性。 这种架构结合了传统主从复制和虚拟IP技术的优势,为数据库系统提供了高可用、 高性能和…...

新火种AI|寒武纪跌落神坛!七年连亏50亿,AI芯片第一股不行了吗?
作者:文子 编辑:小迪 连年亏损,烧钱不止,寒武纪终是走到悬崖边缘。 寒武纪市值腰斩,连续七年累亏50亿 继连续六年亏损之后,寒武纪又迎来第七年亏损。 1月30日晚,寒武纪正式对外发布2023年年…...

three.js CSS3DObject、CSS2DObject、CSS3DSprite、Sprite的作为标签的区别
CSS3DObject、CSS2DObject、CSS3DSprite、Sprite的作为标签的区别 是否面向相机场景缩放时,是否会跟随是否会被模型遮挡CSS2DObject是否否CSS3DObject否是否CSS3DSprite是是是Sprite是是是 CSS3DObject 和 CSS3DRenderer 搭配来渲染标签; CSS2DObject …...

第7节、双电机直线运动【51单片机+L298N步进电机系列教程】
↑↑↑点击上方【目录】,查看本系列全部文章 摘要:前面章节主要介绍单个电机控制,本节内容介绍两个电机完成Bresenham直线运动 一、Bresenham直线算法介绍 Bresenham直线算法由Jack Elton Bresenham于1962年在IBM开发,最初用于计…...

【C语言 - 哈希表 - 力扣 - 相交链表】
相交链表题目描述 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意࿰…...

C++参悟:内存管理-unique_ptr
内存管理-unique_ptr 一、概述二、成员函数1. 构造、析构函数函数1. 构造函数2. 析构函数3. 赋值号 2. 修改器1. release()2. reset()3. swap() 3. 观察器1. get()2. get_deleter3. bool 运算 一、概述 std::unique_ptr 是通过指针占有并管理另一对象&a…...

【征稿已开启】第五大数据、人工智能与软件工程国际研讨会(ICBASE 2024)
第五大数据、人工智能与软件工程国际研讨会(ICBASE 2024) 2024 5th International Conference on Big Data & Artificial Intelligence & Software Engineering 2024年09月20-22日 | 中国温州 第五届大数据、人工智能与软件工程国际研讨会&…...

Vue3父子组件传参
一,父子组件传参: 应用场景:父子组件传参 Vue3碎片:defineEmits,defineProps,ref,reactive,onMounted 1.父组件传子组件 a.父组件传参子组件 import { ref} from vue import OnChi…...

新手入门:在快马平台动手实现你的第一个ui-ux-pro-max设计页面
作为一个刚接触前端设计的新手,最近在InsCode(快马)平台尝试做了一个UI-UX-Pro-Max级别的登录注册页面,整个过程意外地顺利。这里记录下我的实践过程,希望能帮到同样想入门的朋友。 从零搭建页面框架 先用HTML搭建基础结构,包含表…...

3大核心优势!猫抓视频捕获工具让流媒体解析效率提升100%
3大核心优势!猫抓视频捕获工具让流媒体解析效率提升100% 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓浏览器扩展是一款专业的网…...

从模电理论到商用落地,应届生必做的无线充项目,H 桥 / LC 谐振 + QI 协议全栈详解
很多初学嵌入式的同学、正在准备秋招的电子信息类应届生,都会遇到两个核心困境:一是模电学了 H 桥、LC 谐振,只会背公式做题,根本不知道怎么在真实产品里落地;二是学完单片机只会点灯,写的都是流水账代码&a…...

comsol电磁超声压电接收EMAT 在1mm厚铝板中激励250kHz的电磁超声在200mm位...
comsol电磁超声压电接收EMAT 在1mm厚铝板中激励250kHz的电磁超声在200mm位置处设置一个深0.8mm的裂纹缺陷,左端面设为低反射边界 在85mm位置处放置一个压电片接收信号,信号如图3所示,三个波分别为始波,裂纹反射波(S0模态)和右端面…...
)
告别预烘焙!在UE材质编辑器中实时生成FlowMap和法线贴图(附节点图)
实时材质魔法:UE引擎中FlowMap与法线贴图的动态生成技术 在游戏开发与动态视觉创作领域,材质表现的真实感与动态效果一直是技术美术师们追求的核心目标。传统工作流中,FlowMap(流场图)和法线贴图的生成往往依赖于外部软…...

一步步教你:星图平台部署Qwen3-VL:30B完整流程,Clawdbot飞书集成实战
一步步教你:星图平台部署Qwen3-VL:30B完整流程,Clawdbot飞书集成实战 想象一下这个场景:你的团队在飞书群里讨论产品设计,有人发了一张UI截图问“这个按钮位置是不是太靠下了?”;财务同事上传了一张发票照…...

当00后测试员给CEO系统提了487个缺陷后
在软件测试领域,一个年轻测试员的行动往往能引发行业深思。故事始于一家科技公司新上线的“CEO决策支持系统”——一个旨在为高管提供实时数据分析和战略建议的核心平台。项目团队信心满满地推进上线,却未料到一位00后测试员小陈的介入,彻底改…...
)
超导电路阵列实验方案 V1.0桌面量子引力实验(自指动力学与类时空关联涌现)
超导电路阵列实验方案 V1.0 桌面量子引力实验(自指动力学与类时空关联涌现) 方案编号:SR-EXP-QG-001 版本:V1.0 一、核心科学目标 1. 科学目标 在一维/二维超导量子比特阵列中,引入全局量子态测量 实时反馈构建强自指…...

10个C语言开源项目解析与学习指南
1. 10个值得学习的C语言开源项目解析 作为一名在嵌入式领域摸爬滚打多年的开发者,我深知阅读优秀开源代码对提升编程能力的重要性。今天要分享的这10个C语言项目,每一个都是精炼而实用的典范,特别适合想要深入理解系统编程、网络协议和底层实…...

深圳小学数学期末试卷创新题型引热议,数学与文学跨界融合成焦点
1. 当数学题遇上古诗词:深圳试卷创新设计背后的教育逻辑 深圳某区五年级数学期末卷上的一道"跨界题"最近在家长群炸开了锅。题目要求学生分析函数单调性后,将其与《琵琶行》中琵琶女的情感变化对应起来。这种"数学古诗文"的混搭模式…...