爬取58二手房并用SVR模型拟合
目录
一、前言
二、爬虫与数据处理
三、模型
一、前言
爬取数据仅用于练习和学习。本文运用二手房规格sepc(如3室2厅1卫)和二手房面积area预测二手房价格price,只是练习和学习,不代表任何实际意义。
二、爬虫与数据处理
import requests
import chardet
import pandas as pd
import time
from lxml import etree
from fake_useragent import UserAgentua = UserAgent()
user_agent = ua.random
print(user_agent)url = 'https://gy.58.com/ershoufang/'
headers = {'User-Agent':user_agent
}resp = requests.get(url=url, headers=headers)
encoding = chardet.detect(resp.content)['encoding']
resp.encoding = encoding
page_text = resp.texttree = etree.HTML(page_text)
page_num_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/ul/li/a/text()')
page_num = [item.strip() for item in page_num_data if item.strip().isdigit()]
last_page = int(page_num[-1])total_address_title = []
total_BR_LR_B = []
total_area = []
total_price = []
empty_title = 0
empty_address_data = 0
empty_BR_LR_B_data = 0
empty_area_data = 0
empty_price_data = 0for i in range(1, last_page+1):url = 'https://gy.58.com/ershoufang/p{}/?PGTID=0d100000-007d-f5b6-2cca-9cae0bcabf83&ClickID=1'.format(i)headers = {'User-Agent':user_agent}resp = requests.get(url=url, headers=headers)encoding = chardet.detect(resp.content)['encoding']resp.encoding = encodingpage_text = resp.texttree = etree.HTML(page_text)title = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/div/h3[@class="property-content-title-name"]/text()')time.sleep(3)address_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-comm-address"]/span/text()')address = [''.join(address_data[i:i+3]) for i in range(0, len(address_data), 3)]time.sleep(3)title_address = [str(address[i]) + '||' + str(title[i]) for i in range(min(len(address), len(title)))]total_address_title.extend(title_address)BR_LR_B_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-text property-content-info-attribute"]/span/text()')BR_LR_B = [''.join(BR_LR_B_data[i:i+6]) for i in range(0, len(BR_LR_B_data), 6)]total_BR_LR_B.extend(BR_LR_B)time.sleep(3)area_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/section/div/p[@class="property-content-info-text"]/text()')area = [item.strip() for item in area_data if '㎡' in item.strip()]total_area.extend(area)time.sleep(3)price_data = tree.xpath('//*[@id="esfMain"]/section/section/section/section/div/a/div/div/p/span[@class="property-price-total-num"]/text()')price = [price + '万' for price in price_data]total_price.extend(price)time.sleep(3)if len(title) == 0:empty_title += 1if len(address_data) == 0:empty_address_data += 1if len(BR_LR_B_data) == 0:empty_BR_LR_B_data += 1if len(area_data) == 0:empty_area_data += 1if len(price_data) == 0:empty_price_data += 1print('Page{} 爬取成功'.format(i))df = pd.DataFrame({'地址': total_address_title,'规格': total_BR_LR_B,'面积': total_area,'价格': total_price
})print(empty_title, empty_address_data, empty_BR_LR_B_data, empty_area_data, empty_price_data)df.to_excel('58二手房信息表.xlsx', index=False, engine='openpyxl')
print('58二手房信息表保存成功!')# 处理表格
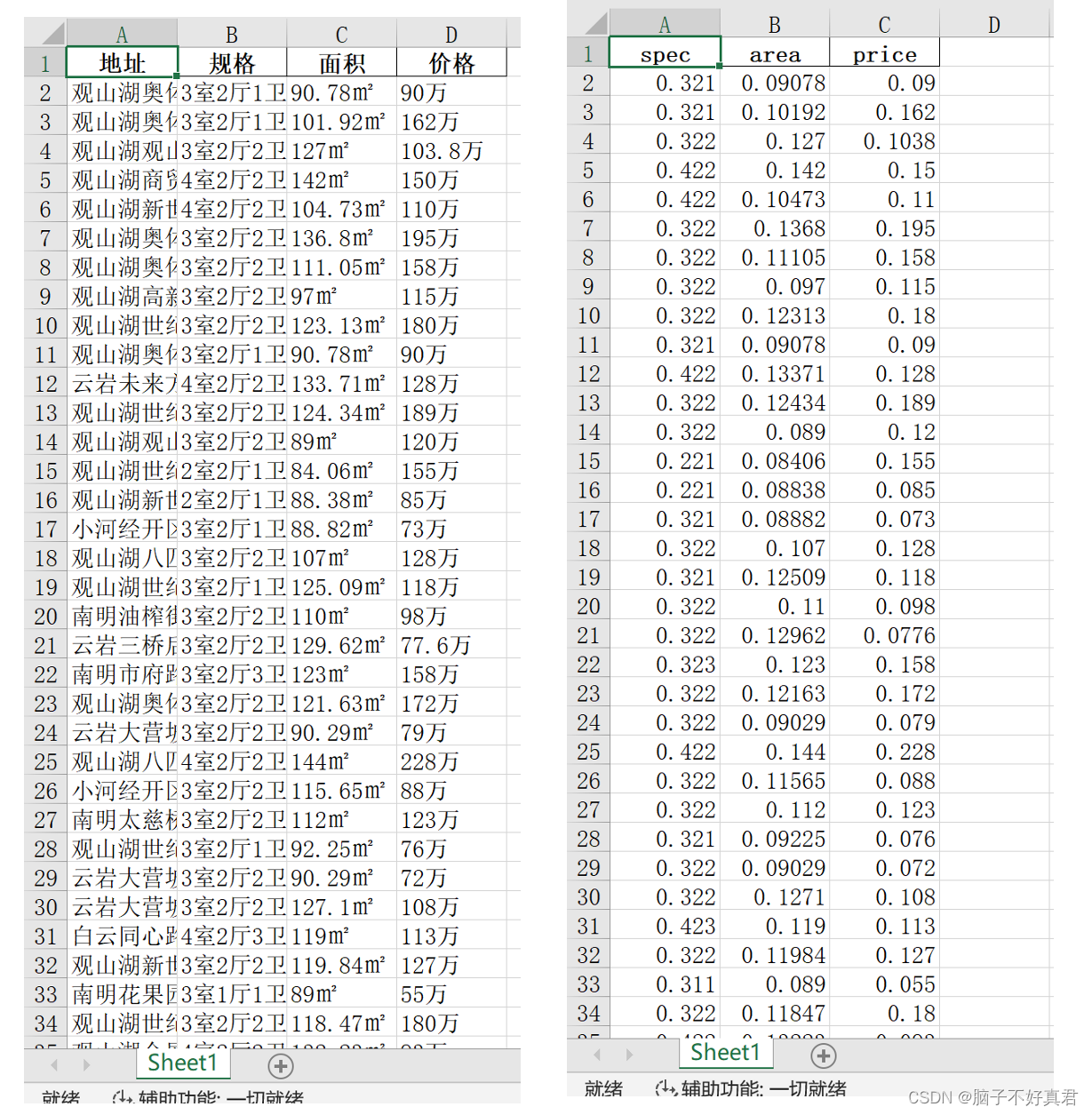
df = pd.read_excel('C:\\Users\\sjl\\Desktop\\58Second-hand-house\\58二手房信息表.xlsx')delete_column = '地址'
df = df.drop(delete_column, axis=1) # 删除地址一列df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '') # 删除文字和字符,保留数值df = df.rename(columns={'规格': 'spec', '面积': 'area', '价格': 'price'}) # 重命名列df = df * 0.001 # 缩小数值, 减少计算量df.to_excel('58Second-hand-house.xlsx', index=False, engine='openpyxl')
print('数据处理成功!')1. 运用chardet库自动获取网页编码
import chardet
resp = requests.get(url=url, headers=headers)encoding = chardet.detect(resp.content)['encoding']
resp.encoding = encoding
2. 运用fake_useragent库,生成随机的用户代理字符串,获取一个随机的用户代理来使用
from fake_useragent import UserAgent
ua = UserAgent()
user_agent = ua.random
print(user_agent)
3. 使用列表推导,去除每个元素的空白字符,并保留那些只包含数字的元素,以获取网站页数
page_num = [item.strip() for item in page_num_data if item.strip().isdigit()]
首先使用strip()方法去除其两端的空白字符(包括换行符\n、空格等),接着使用isdigit()方法检查处理后的字符串是否只包含数字。如果条件成立,即字符串只包含数字,那么这个处理后的字符串就会被包含在page_num列表中。
4. 使用列表推导来遍历列表,并将每三个元素组合成一个元素,获取大致地址
address = [''.join(address_data[i:i+3]) for i in range(0, len(address_data), 3)]
首先通过range(0, len(address_data) 3)生成一个从0开始,address_data最后一位长度结束,步长为3的序列。然后,对于序列中的每个i,使用''.join(address_data[i, i+3])连接从i到i+3(不包括i+3)的元素。这样,每三个元素就被拼接成了一个元素,并存储在address中。
5. 考虑到大致地址会有重复,在地址后附加上标题,作为每个二手房独一无二的标志
title_address = [str(address[i]) + '||' + str(title[i]) for i in range(min(len(address), len(title)))]
6. 同样合并'3','室','2','厅','1','卫'
BR_LR_B = [''.join(BR_LR_B_data[i:i+6]) for i in range(0, len(BR_LR_B_data), 6)]
7. 使用列表推导结合字符串处理方法获得只包含面积部分
area = [item.strip() for item in area_data if '㎡' in item.strip()]
遍历列表,对于每个元素,使用strip()方法去除前后的空格和换行符。检查处理过的字符串是否包含 "㎡" 字符,如果包含,则认为这个字符串表示面积信息。将这些面积信息添加到一个area列表中。
8. 在价格后加上 "万"
price = [price + '万' for price in price_data]
9. 监控得到有9页数据爬取失败
if len(title) == 0:
empty_title += 1
if len(address_data) == 0:
empty_address_data += 1
if len(BR_LR_B_data) == 0:
empty_BR_LR_B_data += 1
if len(area_data) == 0:
empty_area_data += 1
if len(price_data) == 0:
empty_price_data += 1

10. 删除表中的文字
df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '')
11.部分数据展示(处理前后)
delete_column = '地址'
df = df.drop(delete_column, axis=1) # 删除地址一列
df['规格'] = df['规格'].str.replace('室', '')
df['规格'] = df['规格'].str.replace('厅', '')
df['规格'] = df['规格'].str.replace('卫', '')
df['面积'] = df['面积'].str.replace('㎡', '')
df['价格'] = df['价格'].str.replace('万', '') # 删除文字和字符,保留数值
df = df.rename(columns={'规格': 'spec', '面积': 'area', '价格': 'price'}) # 重命名列
df = df * 0.001 # 缩小数值, 减少计算量
三、模型
模型官网:Ml regression in PythonOver 13 examples of ML Regression including changing color, size, log axes, and more in Python.![]() https://plotly.com/python/ml-regression/
https://plotly.com/python/ml-regression/
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from sklearn.svm import SVRmesh_size = .02
margin = 0df = pd.read_excel('C:\\Users\\sjl\\Desktop\\58Second-hand-house\\58Second-hand-house.xlsx')X = df[['spec', 'area']]
y = df['price']# Condition the model on sepal width and length, predict the petal width
model = SVR(C=1.)
model.fit(X, y)# Create a mesh grid on which we will run our model
x_min, x_max = X.spec.min() - margin, X.spec.max() + margin
y_min, y_max = X.area.min() - margin, X.area.max() + margin
xrange = np.arange(x_min, x_max, mesh_size)
yrange = np.arange(y_min, y_max, mesh_size)
xx, yy = np.meshgrid(xrange, yrange)# Run model
pred = model.predict(np.c_[xx.ravel(), yy.ravel()])
pred = pred.reshape(xx.shape)# Generate the plot
fig = px.scatter_3d(df, x='spec', y='area', z='price')
fig.update_traces(marker=dict(size=5))
fig.add_traces(go.Surface(x=xrange, y=yrange, z=pred, name='pred_surface'))
fig.show() 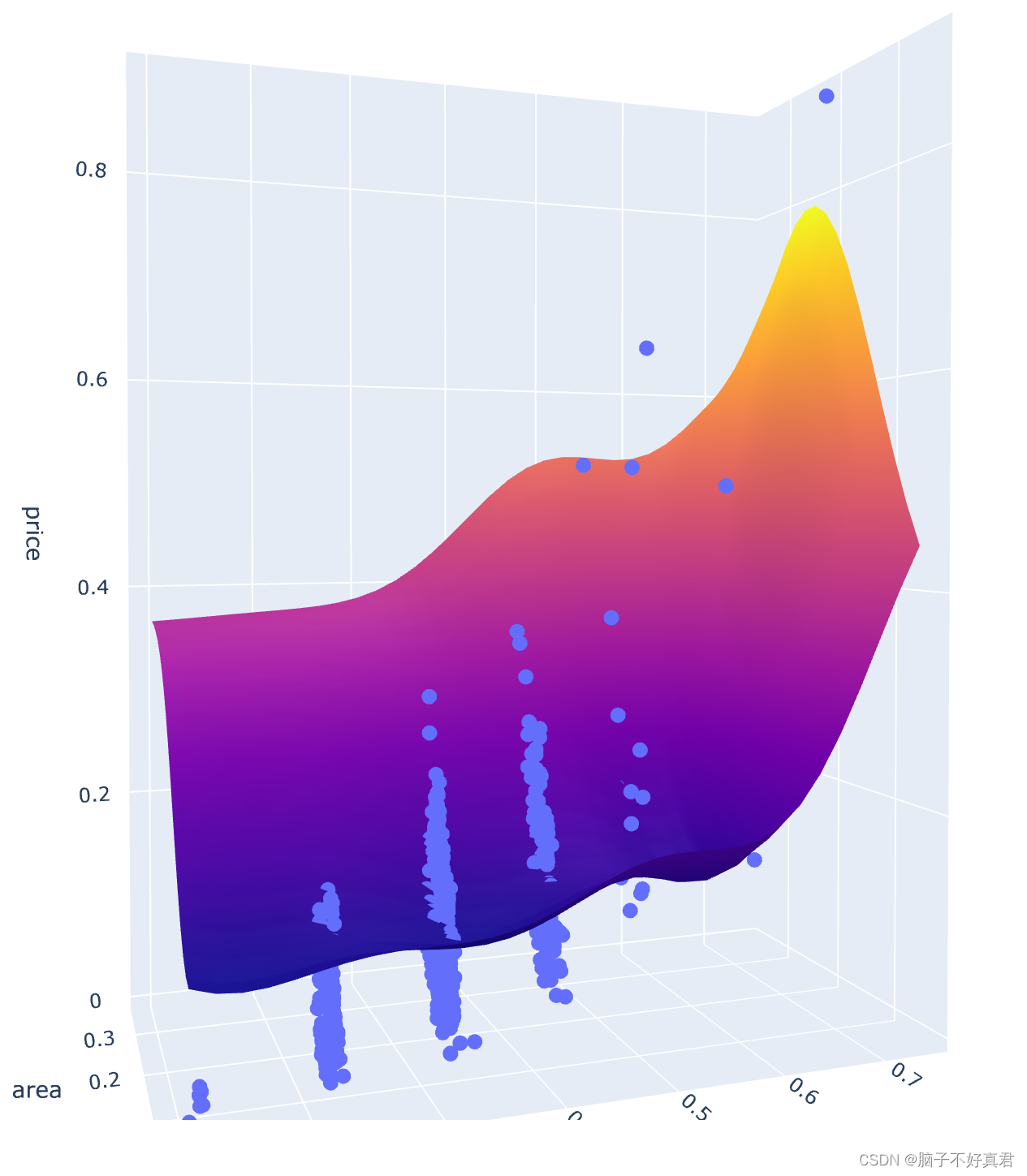
相关文章:
爬取58二手房并用SVR模型拟合
目录 一、前言 二、爬虫与数据处理 三、模型 一、前言 爬取数据仅用于练习和学习。本文运用二手房规格sepc(如3室2厅1卫)和二手房面积area预测二手房价格price,只是练习和学习,不代表任何实际意义。 二、爬虫与数据处理 import requests import cha…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之RichText组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之RichText组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、RichText组件 鸿蒙(HarmonyOS)富文本组件,…...

7.electron之渲染线程发送事件,主进程监听事件
如果可以实现记得点赞分享,谢谢老铁~ Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 Electron 将 Chromium 和 Node.js 嵌入到了一个二进制文件中,因此它允许你仅需一个代码仓库,就可以撰写支持 Windows、…...
thinkphp6入门(19)-- 中间件向控制器传参
可以通过给请求对象赋值的方式传参给控制器(或者其它地方),例如 <?phpnamespace app\middleware;class Hello {public function handle($request, \Closure $next){$request->hello ThinkPHP;return $next($request);} } 然后在控制…...

Flink Format系列(2)-CSV
Flink的csv格式支持读和写csv格式的数据,只需要指定 format csv,下面以kafka为例。 CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3) ) WITH (connector kafka,topic user_behavior…...

Spring Data Envers 数据审计实战2 - 自定义监听程序扩展审计字段及字段值
上篇讲述了如何在Spring项目中集成Spring Data Envers做数据审计和历史版本查看功能。 之前演示的是业务表中已有的字段进行审计,那么如果我们想扩展审计字段呢? 比如目前对员工表加入了Audited审计,员工表有个字段为dept_id,为…...
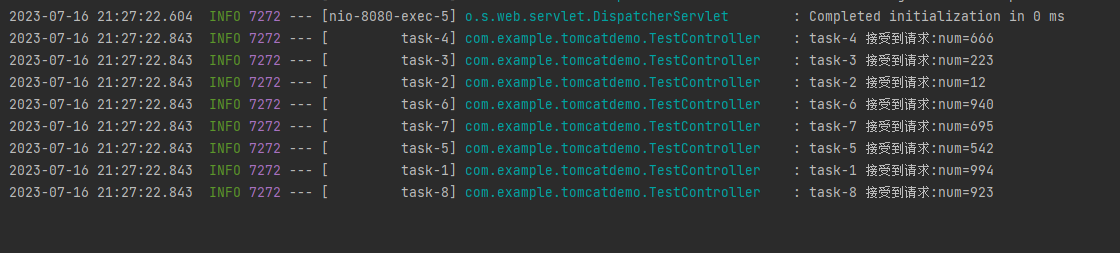
一个 SpringBoot 项目能同时处理多少请求?
目录 1 问题分析 2 Demo 3 答案 4 怎么来的? 5 标准答案及影响参数一Tomcat配置 6 影响参数二 Web容器 7 影响参数三 Async 1 问题分析 一个 SpringBoot 项目能同时处理多少请求? 不知道你听到这个问题之后的第一反应是什么? 我大概…...

计算机网络——网络
计算机网络——网络 小程一言专栏链接: [link](http://t.csdnimg.cn/ZUTXU)前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家, [跳转到网站](https://www.captainbed.cn/qianqiu) 无线网络和移动网…...

C语言探索:选择排序的实现与解读
当我们需要对一组数据进行排序时,选择排序(Selection Sort)是一种简单但效率较低的排序算法。它的基本思想是每次从未排序的数据中选择最小(或最大)的元素,然后将其放置在已排序序列的末尾。通过重复这个过…...
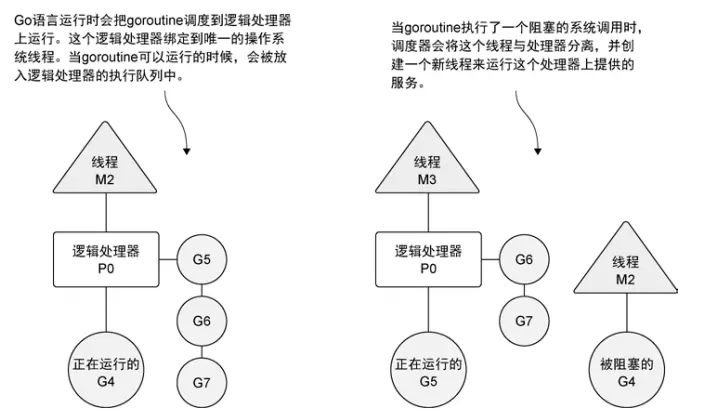
Golang 学习(二)进阶使用
二、进阶使用 性能提升——协程 GoRoutine go f();一个 Go 线程上,可以起多个协程(有独立的栈空间、共享程序堆空间、调度由用户控制)主线程是一个物理线程,直接作用在 cpu 上的。是重量级的,非常耗费 cpu 资源。协…...

ubuntu22.04@laptop OpenCV定制化安装
ubuntu22.04laptop OpenCV定制化安装 1. 源由2. 默认配置3. 定制配置4. 定制安装5. 定制OpenCV-4.9.05.1 修改opencv.conf5.2 加载so文件5.3 修改bash环境变量5.4 增加pkgconfig5.5 检查OpenCV-4.9.0安装 6. 总结7. 参考资料 1. 源由 目前,能Google到的代码层次不齐…...

linux系统非关系型数据库redis
redis 介绍redis的特点:缓存 安装安装单机版redisredis的相关工具 介绍 redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库 redis的官网:redis.ioredis的特点: 丰富的数据结构 支持持久化 支持事务 支持主从缓存 类型 …...

【LeetCode: 292. Nim 游戏+ 博弈问题】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

Android 9.0 禁用adb reboot recovery命令实现正常重启功能
1.前言 在9.0的系统rom定制化开发中,在定制recovery模块的时候,由于产品开发需要要求禁用recovery的相关功能,比如在通过adb命令的 adb reboot recovery的方式进入recovery也需要实现禁用,所以就需要了解相关进入recovery流程来禁用该功能 2.禁用adb reboot recovery命…...

分析网站架构:浏览器插件
一、Wappalyzer 1.1 介绍 Wappalyzer 是一款用于识别网站所使用技术栈的浏览器插件。它能够分析正在浏览的网页,检测出网站所使用的各种技术和框架,如内容管理系统(CMS)、JavaScript库、Web服务器等。用户只需安装 Wappalyzer 插…...
CentOS7搭建Hadoop集群
准备工作 1、准备三台虚拟机,参考:CentOS7集群环境搭建(3台)-CSDN博客 2、配置虚拟机之间免密登录,参考:CentOS7集群配置免密登录-CSDN博客 3、虚拟机分别安装jdk,参考:CentOS7集…...
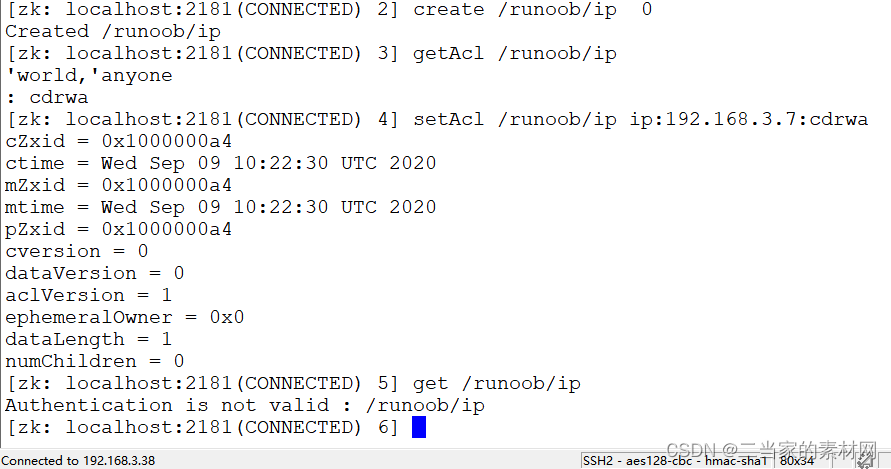
10.0 Zookeeper 权限控制 ACL
zookeeper 的 ACL(Access Control List,访问控制表)权限在生产环境是特别重要的,所以本章节特别介绍一下。 ACL 权限可以针对节点设置相关读写等权限,保障数据安全性。 permissions 可以指定不同的权限范围及角色。 …...

容器化技术基础概念:雪花服务器与凤凰服务器
雪花服务器与凤凰服务器:两种软件部署领域的基础设施对比 在软件部署领域,服务器管理在正常运行时间、效率和安全性方面发挥着关键作用。存在两种截然不同的方法:雪花服务器和凤凰服务器。了解它们之间的区别将帮助您选择最适合您需求的策略…...

解决maven 在IDEA 下载依赖包速度慢的问题
1.idea界面双击shift键 2.打开setting.xml文件 复制粘贴 <?xml version"1.0" encoding"UTF-8"?> <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:sc…...
用python编写爬虫,爬取二手车信息+实验报告
题目 报告要求 工程报告链接放在这里 https://download.csdn.net/download/Samature/88805518使用 1.安装jupyter notebook 2.用jupyter notebook打开工程里的ipynb文件,再run all就行 注意事项 可能遇到的bug 暂无,有的话私信我...

中国科协发布声明:停止受理学者参加NeurIPS 2026会议资助申请
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

Arduino轻量级XXH32哈希库:高吞吐低内存嵌入式校验方案
1. XxHash_arduino 库概述 XxHash_arduino 是一个专为 Arduino 平台优化的轻量级哈希算法库,基于 Yann Collet 开发的 xxHash 算法实现。该库于 2022 年 4 月由嵌入式爱好者 atesin 完成移植,采用 GPLv3 许可协议,同时兼容原始 xxHash 的算法…...

Harmonyos应用实例228:数学文化与数学史
10. 数学文化与数学史 功能简介:展示数学发展史上的重要事件、数学家及其贡献,通过时间轴和互动展示,介绍数学文化的发展历程。支持按时期、地区筛选,帮助学生了解数学的历史背景和文化价值。 ArkTS代码: // 定义类型接口 interface Mathematician {name: stringperiod…...
,从入门到精通,建议收藏!)
刚刚!美团开源LongCat-Next,全模态模型保姆级教程(非常详细),从入门到精通,建议收藏!
昨天下午刷到了美团龙猫团队又开源了一个新模型-LongCat-Next。 这次有所不同,是一个原生全模态模型,可以接受文本、语音、图像的输入,生成文本、语音、图像,激活参数3B。 在训练上,通过分词器-反分词器对࿰…...

微信小程序-live-player-实时视频-截图与文件流转换实战
1. 微信小程序live-player组件基础使用 微信小程序的live-player组件是专门用于播放实时视频流的核心组件。我在多个实际项目中使用过这个组件,发现它比普通的video组件更适合直播场景。live-player支持RTMP、FLV等常见直播协议,延迟可以控制在3秒以内&…...

TMI8260SP的替代品7889直流双向电机驱动芯片详解
在直流电机驱动领域,TMI8260SP作为一款经典的双向马达驱动芯片,曾广泛应用于各类中低功率电机控制场景,其稳定的性能积累了良好的市场口碑。但随着市场对电机驱动芯片的性能、功耗及性价比要求不断提升,7889直流双向电机驱动芯片凭…...

微内核架构与事件驱动架构的区别与联系详细对比
1. 微内核架构 (Microkernel Architecture)1.1 核心概念微内核架构将系统核心功能最小化,将大部分服务(文件系统、设备驱动、网络协议等)移出内核,作为独立的用户态进程运行。内核仅保留最基本的功能:进程间通信&#…...

变压器匝间短路这玩意儿仿真起来是真刺激。今儿拿COMSOL折腾了个5%短路模型,从电磁场到噪声一条龙全流程,咱们边撸代码边唠嗑
comsol仿真,变压器匝间短路5%的电磁振动噪声模型 包括电磁场分布,磁密分布,振动形变,噪声分布等结果建模第一步得先让线圈支棱起来。在组件里用参数化曲线画线圈特别实用: # 参数化螺旋线 r 0.5 # 半径(m) pitch 0.…...

为什么92%的FastAPI AI项目卡在流式响应?揭秘async generator阻塞根源与3种非阻塞调度模式
第一章:FastAPI 2.0 异步 AI 流式响应 如何实现快速接入FastAPI 2.0 原生强化了对异步流式响应(StreamingResponse)的支持,结合 async generator 可无缝对接大语言模型(LLM)的逐 token 输出场景,…...

Qwen2.5-VL半监督学习效果展示:有限标注下的性能提升
Qwen2.5-VL半监督学习效果展示:有限标注下的性能提升 1. 引言 在AI视觉领域,标注数据一直是制约模型性能的关键因素。传统监督学习需要大量人工标注,成本高、周期长,让很多企业和研究者望而却步。但今天,随着半监督学…...