CentOS7搭建Hadoop集群
准备工作
1、准备三台虚拟机,参考:CentOS7集群环境搭建(3台)-CSDN博客
2、配置虚拟机之间免密登录,参考:CentOS7集群配置免密登录-CSDN博客
3、虚拟机分别安装jdk,参考:CentOS7集群安装JDK1.8-CSDN博客
4、下载Hadoop安装包,下载地址:链接:https://pan.baidu.com/s/1f1DmqNNFBvBDKi5beYl3Jg?pwd=6666
搭建Hadoop集群
集群部署规划

一、上传并解压Hadoop安装包
1、将hadoop3.3.4.tar.gz使用XFTP上传到opt目录下面的software文件夹下面
2、进入到Hadoop安装包路径
cd /opt/software3、解压安装文件到/opt/moudle下面
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/moudle/![]()
4、查看是否解压成功
cd /opt/moudle
ll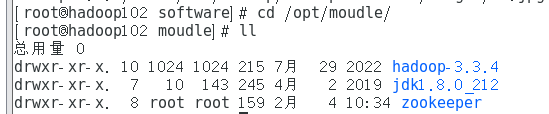
5、重命名
mv hadoop-3.3.4/ hadoop
6、将Hadoop添加到环境变量
1、获取Hadoop安装路径
进入Hadoop目录下输入
pwd
#输出
opt/moudle/hadoop![]()
2、打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在profile文件末尾添加hadoop路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/moudle/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3、保存后退出
esc键然后
:wq
4、分发环境变量文件
分发脚本之前配置的有可以去前面的文章看看
sudo /home/user/bin/xsync /etc/profile.d/my_env.sh5、source 使之生效(3台节点)
[user@hadoop102 module]$ source /etc/profile.d/my_env.sh
[user@hadoop103 module]$ source /etc/profile.d/my_env.sh
[user@hadoop104 module]$ source /etc/profile.d/my_env.sh
二、配置集群
1、核心配置文件
配置core-site.xml
cd $HADOOP_HOME/etc/hadoopvim core-site.xml文件内容如下(在<configuration><configuration>中间输入):
我这样配置不知道为啥用不了(直接用的root用户)加红的地方换成root
<!-- 把多个NameNode的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property><!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/moudle/hadoop/data</value>
</property>
<!-- 配置NN故障转移的 ZK集群-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property><!-- 配置HDFS网页登录使用的静态用户为user -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>user</value>
</property><!-- 配置该user(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.user.hosts</name>
<value>*</value>
</property>
<!-- 配置该user(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.user.groups</name>
<value>*</value>
</property>
<!-- 配置该user(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.user.users</name>
<value>*</value>
</property>

2、HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml文件内容如下在<configuration><configuration>中间输入:
<!-- NameNode数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/name</value></property><!-- DataNode数据存储目录 --><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/data</value></property><!-- JournalNode数据存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>${hadoop.tmp.dir}/jn</value></property><!-- 完全分布式集群名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 集群中NameNode节点都有哪些 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- NameNode的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>hadoop102:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>hadoop103:8020</value></property><!-- NameNode的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>hadoop102:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>hadoop103:9870</value></property><!-- 指定NameNode元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value></property><!-- 访问代理类:client用于确定哪个NameNode为Active --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要ssh秘钥登录--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/user/.ssh/id_rsa</value></property>
<!-- 启用nn故障自动转移 -->
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value>
</property> <!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name><value>3</value></property>3、YARN配置文件
配置yarn-site.xml
vim yarn-site.xml文件内容如下(在<configuration><configuration>中间输入):
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 启用resourcemanager ha --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 声明两台resourcemanager的地址 --><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-yarn1</value></property><!--指定resourcemanager的逻辑列表--><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property>
<!-- ========== rm1的配置 ========== --><!-- 指定rm1的主机名 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop102</value></property><!-- 指定rm1的web端地址 --><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>hadoop102:8088</value></property><!-- 指定rm1的内部通信地址 --><property><name>yarn.resourcemanager.address.rm1</name><value>hadoop102:8032</value></property><!-- 指定AM向rm1申请资源的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop102:8030</value></property><!-- 指定供NM连接的地址 --> <property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>hadoop102:8031</value></property><!-- ========== rm2的配置 ========== --><!-- 指定rm2的主机名 --><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop103</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>hadoop103:8088</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>hadoop103:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>hadoop103:8030</value></property><property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>hadoop103:8031</value></property><!-- 指定zookeeper集群的地址 --> <property><name>yarn.resourcemanager.zk-address</name><value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value></property><!-- 启用RM自动故障转移 --> <property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定resourcemanager的状态信息存储在zookeeper集群 --> <property><name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!--yarn单个容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>4、MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml文件内容如下(在<configuration><configuration>中间输入):
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>5、配置workers
vim /opt/moudle/hadoop/etc/hadoop/workers在该文件中增加如下内容(localhost删除):
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。

三、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1、配置mapred-site.xml
vim mapred-site.xml在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>
四、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1、配置yarn-site.xml
vim yarn-site.xml在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property><!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
五、分发Hadoop
xsync /opt/moudle/hadoop/六、启动Hadoop-HA
1、在3个JournalNode节点上,输入以下命令启动journalnode服务
进入/opt/moudle/hadoop
![]()
hdfs --daemon start journalnode2、在hadoop102[nn1]上,对其进行格式化,并启动
hdfs namenode -format
hdfs --daemon start namenode3、在hadoop103[nn2]上,同步nn1的元数据信息
hdfs namenode -bootstrapStandby4、启动hadoop103[nn2]
hdfs --daemon start namenode5、格式化zkfc(102)
zookeeper必须先启动
zk.sh start具体参考zookeeper集群安装
hdfs zkfc -formatZK6、在所有nn节点(102、103)启动zkfc
hdfs --daemon start zkfc7、在所有节点上(3台),启动datanode
hdfs --daemon start datanode8、第二次启动可以在NameNode所在节点执行start-dfs.sh启动HDFS所有进程
(这一步不用管)关闭之时,提示我权限不够,我直接用root用户操作,然后在hadoop-env.sh中加入以下几行
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_JOURNALNODE_USER="root"
export HDFS_ZKFC_USER="root"在yarn-env.sh中加入了以下几行 :然后分发给三台机器
export YARN_NODEMANAGER_USER="root"
export YARN_RESOURCEMANAGER_USER="root"start-dfs.sh
stop-dfs.sh9、在ResourceMamager所在节点执行start-yarn.sh 启动yarn所有进程
start-yarn.sh
stop-yarn.sh10、部署完成可以通过start-all.sh和stop-all.sh控制Hadoop-HA所有节点的启停
start-all.sh
stop-all.shHadoop群起脚本
1、在/home/user/bin目录下创建hdp.sh
2、写入以下内容
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs 和 yarn ---------------"ssh hadoop102 "/opt/moudle/hadoop/sbin/start-all.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/moudle/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/moudle/hadoop/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 hdfs 和 yarn ---------------"ssh hadoop102 "/opt/moudle/hadoop/sbin/stop-all.sh"
;;
*)echo "Input Args Error..."
;;
esac
3、增加(+x指的是增加可以运行权限)权限
chmod +x hdp.sh4、启动集群
hdp.sh start查看进程
xcall.sh jps5、关闭集群
hdp.sh stop查看进程
xcall.sh jps
UI
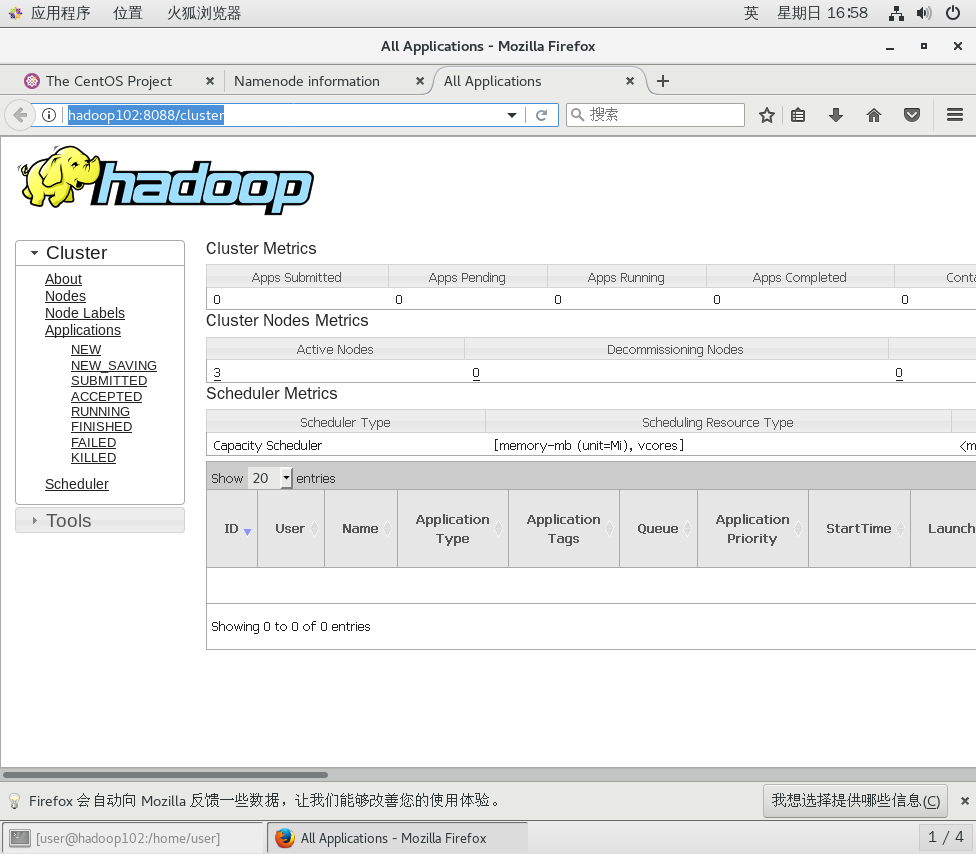
http://hadoop102:9870/dfshealth.html#tab-overview

http://hadoop102:8088/cluster![]() http://hadoop102:8088/cluster
http://hadoop102:8088/cluster
至此Hadoop集群就顺利搭建完成,遇见错误可以私我,共勉~
相关文章:
CentOS7搭建Hadoop集群
准备工作 1、准备三台虚拟机,参考:CentOS7集群环境搭建(3台)-CSDN博客 2、配置虚拟机之间免密登录,参考:CentOS7集群配置免密登录-CSDN博客 3、虚拟机分别安装jdk,参考:CentOS7集…...
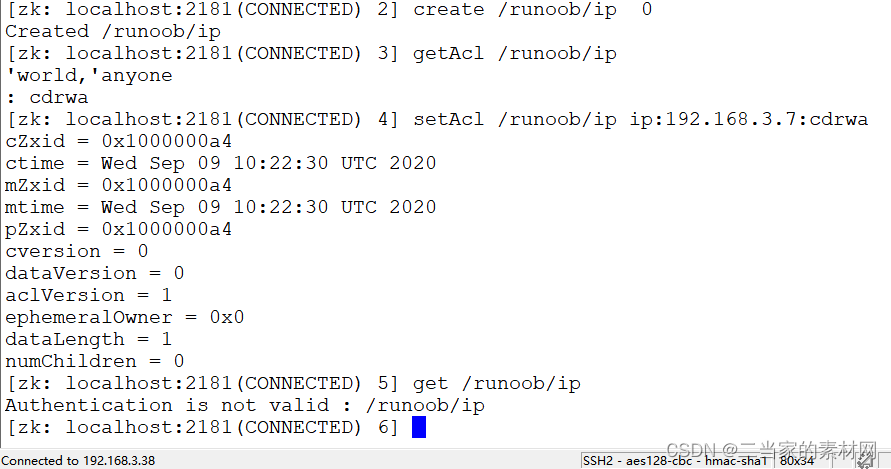
10.0 Zookeeper 权限控制 ACL
zookeeper 的 ACL(Access Control List,访问控制表)权限在生产环境是特别重要的,所以本章节特别介绍一下。 ACL 权限可以针对节点设置相关读写等权限,保障数据安全性。 permissions 可以指定不同的权限范围及角色。 …...

容器化技术基础概念:雪花服务器与凤凰服务器
雪花服务器与凤凰服务器:两种软件部署领域的基础设施对比 在软件部署领域,服务器管理在正常运行时间、效率和安全性方面发挥着关键作用。存在两种截然不同的方法:雪花服务器和凤凰服务器。了解它们之间的区别将帮助您选择最适合您需求的策略…...

解决maven 在IDEA 下载依赖包速度慢的问题
1.idea界面双击shift键 2.打开setting.xml文件 复制粘贴 <?xml version"1.0" encoding"UTF-8"?> <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:sc…...
用python编写爬虫,爬取二手车信息+实验报告
题目 报告要求 工程报告链接放在这里 https://download.csdn.net/download/Samature/88805518使用 1.安装jupyter notebook 2.用jupyter notebook打开工程里的ipynb文件,再run all就行 注意事项 可能遇到的bug 暂无,有的话私信我...

代码随想录算法训练营第二十九天|491.非递减子序列、46.全排列、47.全排列II
491.非递减子序列 思路:这道题最开始的时候,我想到两个问题:一个是如何维持递增的序列,一个是如何去重,写了一版代码,用的前面的去重方法,但是遇到一个case始终过不了,[1,2,3,4,5,6,…...
(2)(2.14) SPL Satellite Telemetry
文章目录 前言 1 本地 Wi-Fi(费用:30 美元以上,范围:室内) 2 蜂窝电话(费用:100 美元以上,范围:蜂窝电话覆盖区域) 3 手机卫星(费用ÿ…...
OTG -- STM32 OTG驱动代码下载及简述(三)
目录 前沿 1 STM32 OTG标准库的获取 2 设备模式代码匹配开发板 2.1 OTG FS全速代码修改 2.2 OTG HS代码修改 2.2.1 OTG HS外部高速PHY运行在高速模式代码修改 2.2.2 OTG HS外部高速PHY运行在全速模式代码修改 2.2.3 OTG HS内部全速PHY运行在全速模式代码修改 前沿 前面…...

STM32F407 CAN参数配置 500Kbps
本篇CAN参数适用 芯片型号:STM32F407xx系统时钟:168MHz,CAN挂载总线APB1为42M波 特 率 :500Kpbs引脚使用:TX_PB9,RX_PB8;修改为PA11PA12后,参数不变。 步骤一、打勾开启CAN…...

python常用的深度学习框架
目录 一:介绍 二:使用 Python中有几个非常受欢迎的深度学习框架,它们提供了构建和训练神经网络所需的各种工具和库。以下是一些最常用的Python深度学习框架: 一:介绍 TensorFlow:由Google开发的TensorF…...

将xyz格式的GRACE数据转成geotiff格式
我们需要将xyz格式的文件转成geotiff便于成图,或者geotiff转成xyz用于数据运算,下面介绍如何实现这一操作,采用GMT和matlab两种方法。 1.GMT转换 我们先准备一个xyz文件,这里是一个降水文件。在gmt中采用以下的语句实现xyz转grd…...

【机器学习】机器学习流程之收集数据
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...

IP风险画像在企业网络统计与安全防范中应用
随着企业在数字化时代的迅速发展,网络安全问题变得尤为突出。IP风险画像作为一种全面的网络安全工具,在企业网络统计与安全防范中展现出卓越的应用价值。本文将以一个实际案例为例,深入探讨IP风险画像在企业网络中的成功应用,以及…...

Unity类银河恶魔城学习记录3-6 Finalize BattleState源代码 P52
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Enemy.cs using System.Collections; using System.Collections.Generic; …...
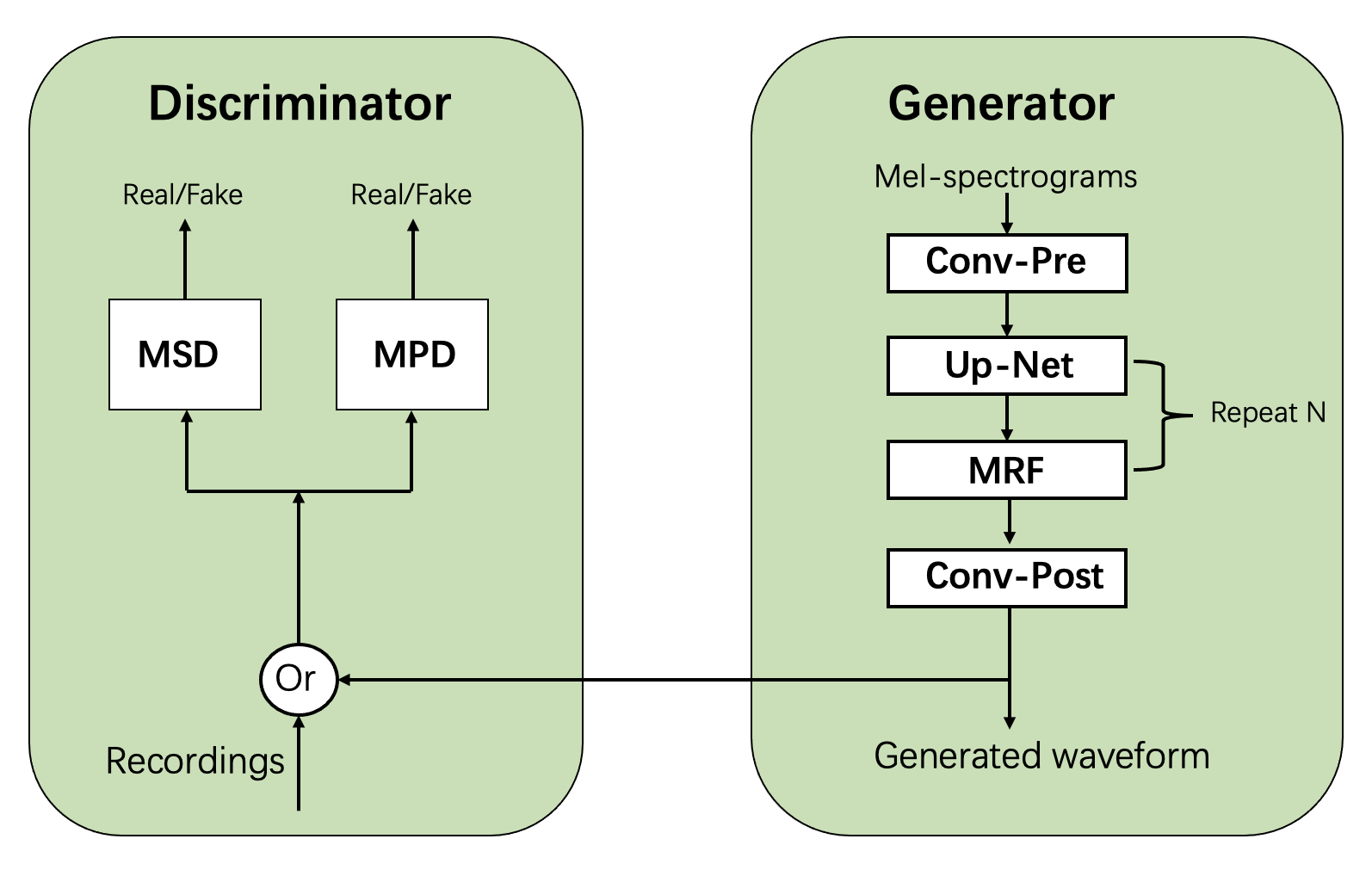
【语音合成】中文-多情感领域-16k-多发音人
模型介绍 语音合成-中文-多情感领域-16k-多发音人 框架描述 拼接法和参数法是两种Text-To-Speech(TTS)技术路线。近年来参数TTS系统获得了广泛的应用,故此处仅涉及参数法。 参数TTS系统可分为两大模块:前端和后端。 前端包含文本正则、分词、多音字预…...

07-使用Package、Crates、Modules管理项目
上一篇:06-枚举和模式匹配 当你编写大型程序时,组织代码将变得越来越重要。通过对相关功能进行分组并将具有不同功能的代码分开,您可以明确在哪里可以找到实现特定功能的代码,以及在哪里可以改变功能的工作方式。 到目前为止&…...

spring.jpa.hibernate 配置和源码解析
版本 spring-boot:3.2.2 hibernate:6.4.1.Final 配置项目 DDL模式 生成定义语句修改表结构 配置路径:spring.jpa.hibernate.ddl-auto配置值:org.hibernate.tool.schema.Action枚举类型值 可选值: 可选值说明none默认值。不操作create-…...
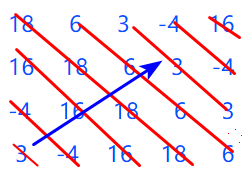
2019年江苏省职教高考计算机技能考试——一道程序改错题的分析
题目:函数将str字符串中的5个数字字符串转换为整数,并保存在二维数组m的最后一行,各元素为3、-4、16、18、6。并经函数move处理后,运行结果如下: 18 6 3 -4 16 16 18 6 3 -4 -4 16 …...

邦芒支招:职场白领必备的10条护身符
在职场生存除了小心驶得万年船,怎样躲过不长眼的办公室风暴,职场八卦及不成为上司利益的牺牲品呢?职场就是个小社会,人际关系说复杂也复杂,说简单也简单。现在送你10道有用的职场护身符,希望你能够通过利…...

python实现飞书群机器人消息通知(消息卡片)
python实现飞书群机器人消息通知 直接上代码 """ 飞书群机器人发送通知 """ import time import urllib3 import datetimeurllib3.disable_warnings()class FlybookRobotAlert():def __init__(self):self.webhook webhook_urlself.headers {…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...

PH热榜 | 2025-06-08
1. Thiings 标语:一套超过1900个免费AI生成的3D图标集合 介绍:Thiings是一个不断扩展的免费AI生成3D图标库,目前已有超过1900个图标。你可以按照主题浏览,生成自己的图标,或者下载整个图标集。所有图标都可以在个人或…...