使用NLTK进行自然语言处理:英文和中文示例
Natural Language Toolkit(NLTK)是一个强大的自然语言处理工具包,提供了许多有用的功能,可用于处理英文和中文文本数据。本文将介绍一些基本的NLTK用法,并提供代码示例,展示如何在英文和中文文本中应用这些功能。
1. 分词(Tokenization)
分词是将文本拆分为单词或子句的过程。NLTK提供了适用于英文和中文的分词工具。
英文分词示例:
import nltk
from nltk.tokenize import word_tokenizeenglish_sentence = "NLTK is a powerful library for natural language processing."
english_tokens = word_tokenize(english_sentence)
print(english_tokens)
结果:
['NLTK', 'is', 'a', 'powerful', 'library', 'for', 'natural', 'language', 'processing', '.']中文分词示例:
import jiebachinese_sentence = "自然语言处理是一门重要的研究领域。"
chinese_tokens = jieba.lcut(chinese_sentence)
print(chinese_tokens)
2. 句子分割(Sentence Tokenization)
句子分割是将文本拆分为句子的过程。
英文句子分割示例:
from nltk.tokenize import sent_tokenizeenglish_text = "NLTK is a powerful library for natural language processing. It provides various tools for text analysis."
english_sentences = sent_tokenize(english_text)
print(english_sentences)
结果:
['NLTK is a powerful library for natural language processing.', 'It provides various tools for text analysis.']中文句子分割示例:
import rechinese_text = "自然语言处理是一门重要的研究领域。NLTK 和 jieba 是常用的工具库。"
chinese_sentences = re.split('(?<!\\w\\.\\w.)(?<![A-Z][a-z]\\.)(?<=\\.|\\?)\\s', chinese_text)
print(chinese_sentences)
请注意,中文句子分割通常需要更复杂的规则,这里使用了正则表达式作为一个简单的例子。实际中,可能需要更复杂的算法或中文分句库
3. 停用词处理示例:
停用词是在文本分析中通常被忽略的常见词语。NLTK 提供了一些停用词列表,以及用于过滤它们的方法。
英文停用词处理示例:
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenizeenglish_sentence = "NLTK is a powerful library for natural language processing. It provides various tools for text analysis."
english_tokens = word_tokenize(english_sentence)# 移除停用词
english_stopwords = set(stopwords.words('english'))
filtered_tokens = [word for word in english_tokens if word.lower() not in english_stopwords]
print(filtered_tokens)
结果:
['NLTK', 'powerful', 'library', 'natural', 'language', 'processing', '.', 'provides', 'various', 'tools', 'text', 'analysis', '.']4. 词频分布示例:
词频分布是文本中单词出现频率的统计。NLTK 中的 FreqDist 类可用于实现这一功能。
英文词频分布示例:
from nltk import FreqDist
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwordsenglish_sentence = "NLTK is a powerful library for natural language processing. It provides various tools for text analysis."
english_tokens = word_tokenize(english_sentence)# 移除停用词
english_stopwords = set(stopwords.words('english'))
filtered_tokens = [word for word in english_tokens if word.lower() not in english_stopwords]# 计算词频分布
freq_dist = FreqDist(filtered_tokens)
print(freq_dist.most_common(5)) # 输出最常见的五个单词及其频率
结果:
[('.', 2), ('NLTK', 1), ('powerful', 1), ('library', 1), ('natural', 1)]中文词频分布示例:
import jieba
from nltk import FreqDistchinese_sentence = "自然语言处理是一门重要的研究领域。NLTK 和 jieba 是常用的工具库。"
chinese_tokens = jieba.lcut(chinese_sentence)# 计算词频分布
freq_dist = FreqDist(chinese_tokens)
print(freq_dist.most_common(5)) # 输出最常见的五个词及其频率
5. 词干提取(Stemming)
词干提取是将单词还原为其词干或词根的过程。
英文词干提取示例:
from nltk.stem import PorterStemmerenglish_words = ["running", "jumps", "quickly"]
stemmer = PorterStemmer()
english_stemmed_words = [stemmer.stem(word) for word in english_words]
print(english_stemmed_words)
结果:
['run', 'jump', 'quickli']中文词干提取示例:
中文文本的词干提取通常需要复杂的处理,这里以英文为例。
6. 词性标注(Part-of-Speech Tagging)
词性标注是为文本中的每个单词确定其词性的过程。
英文词性标注示例:
from nltk import pos_tag
from nltk.tokenize import word_tokenizeenglish_sentence = "NLTK is great for part-of-speech tagging."
english_tokens = word_tokenize(english_sentence)
english_pos_tags = pos_tag(english_tokens)
print(english_pos_tags)
结果:
[('NLTK', 'NNP'), ('is', 'VBZ'), ('great', 'JJ'), ('for', 'IN'), ('part-of-speech', 'JJ'), ('tagging', 'NN'), ('.', '.')]中文词性标注示例:
中文词性标注需要使用特定的中文语料库,这里以英文为例。
7. 情感分析(Sentiment Analysis)
情感分析是确定文本情感倾向的过程。
英文情感分析示例:
from nltk.sentiment import SentimentIntensityAnalyzerenglish_sentence = "NLTK makes natural language processing easy and fun."
sia = SentimentIntensityAnalyzer()
sentiment_score = sia.polarity_scores(english_sentence)if sentiment_score['compound'] >= 0.05:sentiment = 'Positive'
elif sentiment_score['compound'] <= -0.05:sentiment = 'Negative'
else:sentiment = 'Neutral'print(f"Sentiment: {sentiment}")
中文情感分析示例:
中文情感分析同样需要中文语料库和模型。这里以英文为例。
结论
NLTK是一个强大的工具包,可以应用于多种自然语言处理任务。通过本文提供的示例,您可以了解如何在英文和中文文本中使用NLTK的不同功能。
下载资源
手动下载地址
https://www.nltk.org/nltk_data/
import nltk
nltk.data.path.append("your donwloaded data path")代码下载
import nltk
nltk.download('punkt')附加资源
- NLTK官方文档
- jieba中文分词库
相关文章:

使用NLTK进行自然语言处理:英文和中文示例
Natural Language Toolkit(NLTK)是一个强大的自然语言处理工具包,提供了许多有用的功能,可用于处理英文和中文文本数据。本文将介绍一些基本的NLTK用法,并提供代码示例,展示如何在英文和中文文本中应用这些…...

学习Spring的第十六天
AOP底层两种生成Proxy的方式 我来解释这两种方式 1 目标类有接口 , 调用JDK的动态代理实现 2 目标类没有接口 , 用Cglib实现 , 即生成目标类的子类 , 来实现动态代理 , 所以要求目标类不能时final修饰的 . (若有接口 , 也可用Cglib方式实现 , 需要手动配置<aop: config pr…...

学习笔记-01
学习笔记记录了我在学习官方文档过程中记的要点,可以参考学习。 go build *.go 文件 编译 go run *.go 执行 go mod init 生成依赖管理文件 gofmt -w *.go 格式换名称的大小写用来控制方法的可见域主方法及包命名规范 package main //注意package的命名࿰…...
opensatck中windows虚拟机CPU核数显示异常问题处理
文章目录 一、问题描述二、元数据信息三、以32核的实例模版为例3.1 单槽位32核3.2 双槽位32核 总结 一、问题描述 openstack创建windows虚拟机的时候,使用普通的实例模版会出现CPU数量和实例模版不一致的问题。需要定制元数据才可以正常显示。 帖子:htt…...

Camunda流程引擎数据库架构
💖专栏简介 ✔️本专栏将从Camunda(卡蒙达) 7中的关键概念到实现中国式工作流相关功能。 ✔️文章中只包含演示核心代码及测试数据,完整代码可查看作者的开源项目snail-camunda ✔️请给snail-camunda 点颗星吧😘 💖数据库架构…...
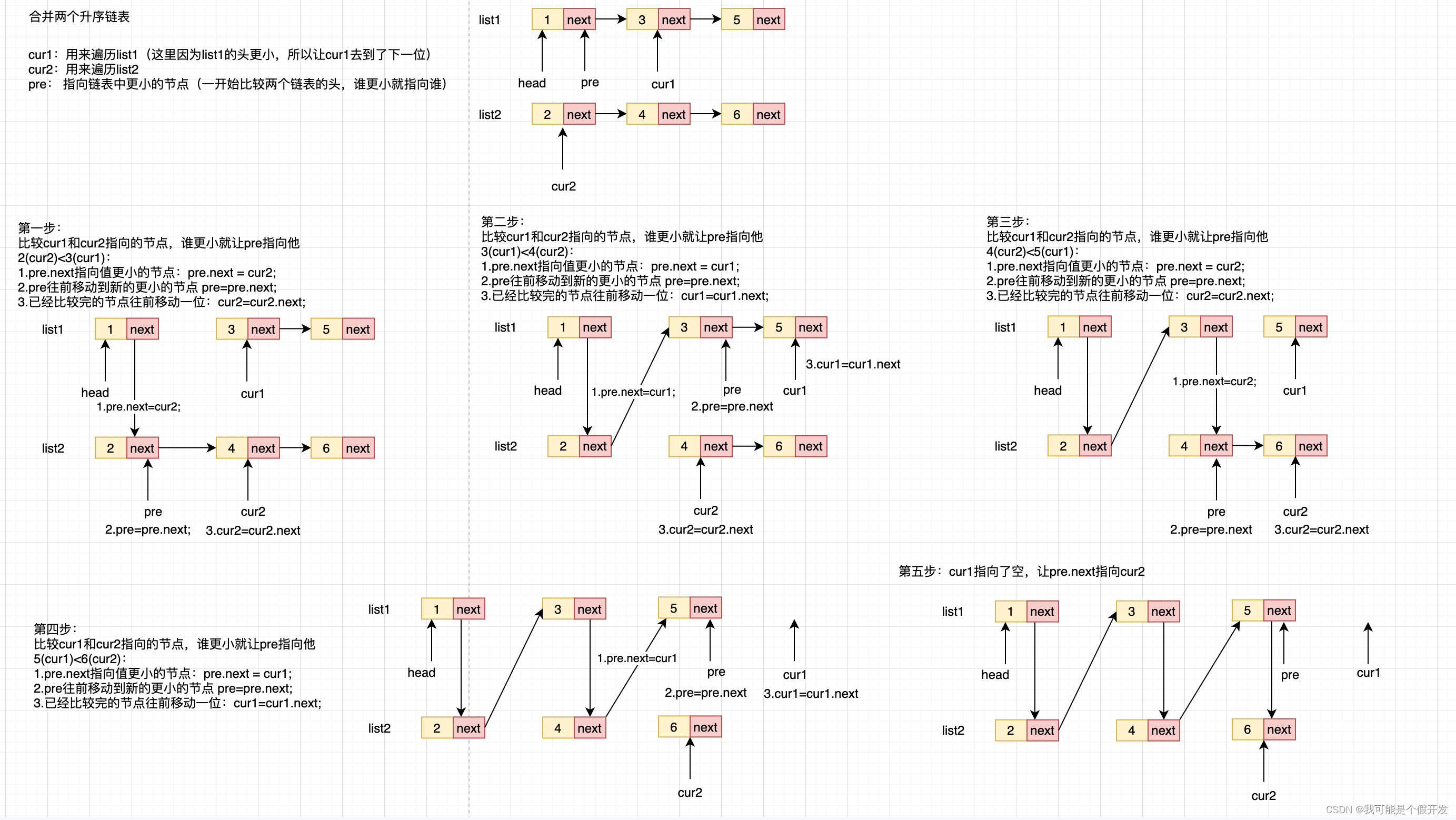
Leetcode21:合并两个有序链表
一、题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 示例: 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3,4,4]输入:l1 [], l2 [] 输出:[]输入&#…...

深度学习驱动下的自然语言处理进展及其应用前景
文章目录 每日一句正能量前言技术进步应用场景挑战与前景自然语言处理技术当前面临的挑战未来的发展趋势和前景 伦理和社会影响实践经验后记 每日一句正能量 一个人若想拥有聪明才智,便需要不断地学习积累。 前言 自然语言处理(NLP)是一项正…...
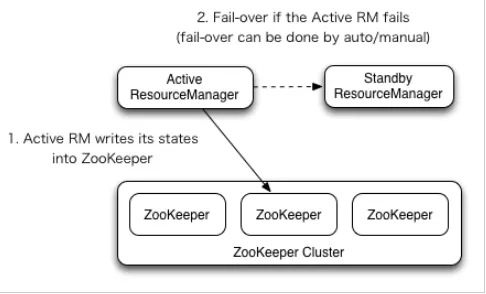
Zookeeper相关面试准备问题
Zookeeper介绍 Zookeeper从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生了变化,Zookeeper就负责通知已经在Zoo…...

SpringBoot整理-性能优化
Spring Boot性能优化通常涉及到多个方面,包括代码优化、数据库交互、资源使用和系统配置等。下面是一些常见的优化建议: 代码层面的优化:使用合适的数据结构和算法。减少不必要的对象创建,避免内存泄漏。对于重复使用的对象,考虑使用对象池。数据库优化:优化SQL查询,避免复…...
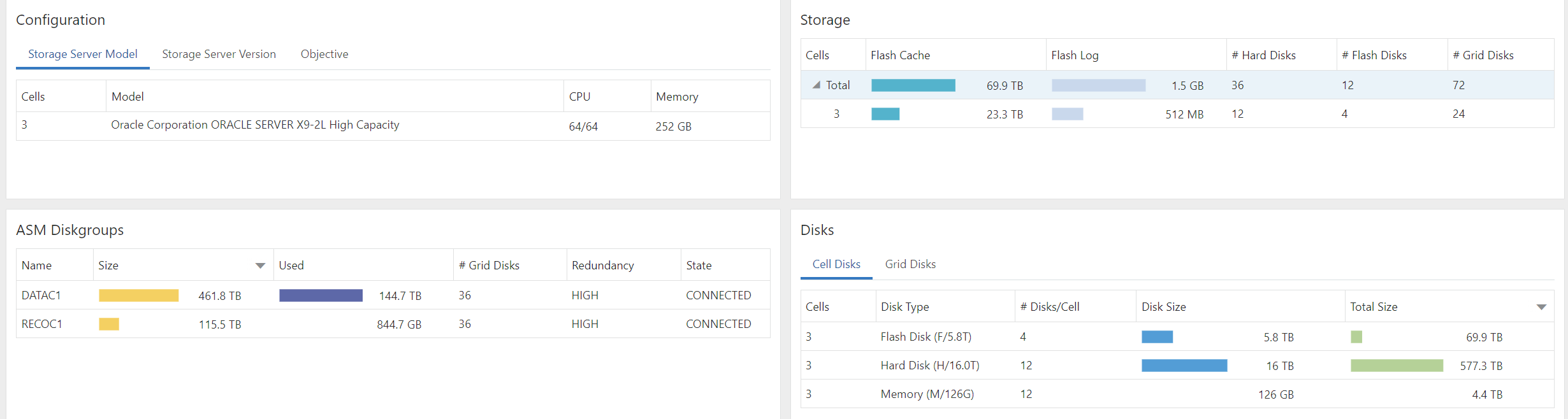
数据库管理-第146期 最强Oracle监控EMCC深入使用-03(20240206)
数据库管理145期 2024-02-06 数据库管理-第146期 最强Oracle监控EMCC深入使用-03(20240206)1 概览2 性能中心3 性能中心-Exadata总结 数据库管理-第146期 最强Oracle监控EMCC深入使用-03(20240206) 作者:胖头鱼的鱼缸&…...

QT上位机:串口调试助手
前言 上位机的简单编写可以帮我们测试并完善平台,QT作为一款跨平台的GUI开发框架,提供了非常丰富的常用串口api。本文先从最简单的串口调试助手开始,编写平台软件的串口控制界面 工程配置 QT 串口通信基于QT的QSerialPort类,先在…...
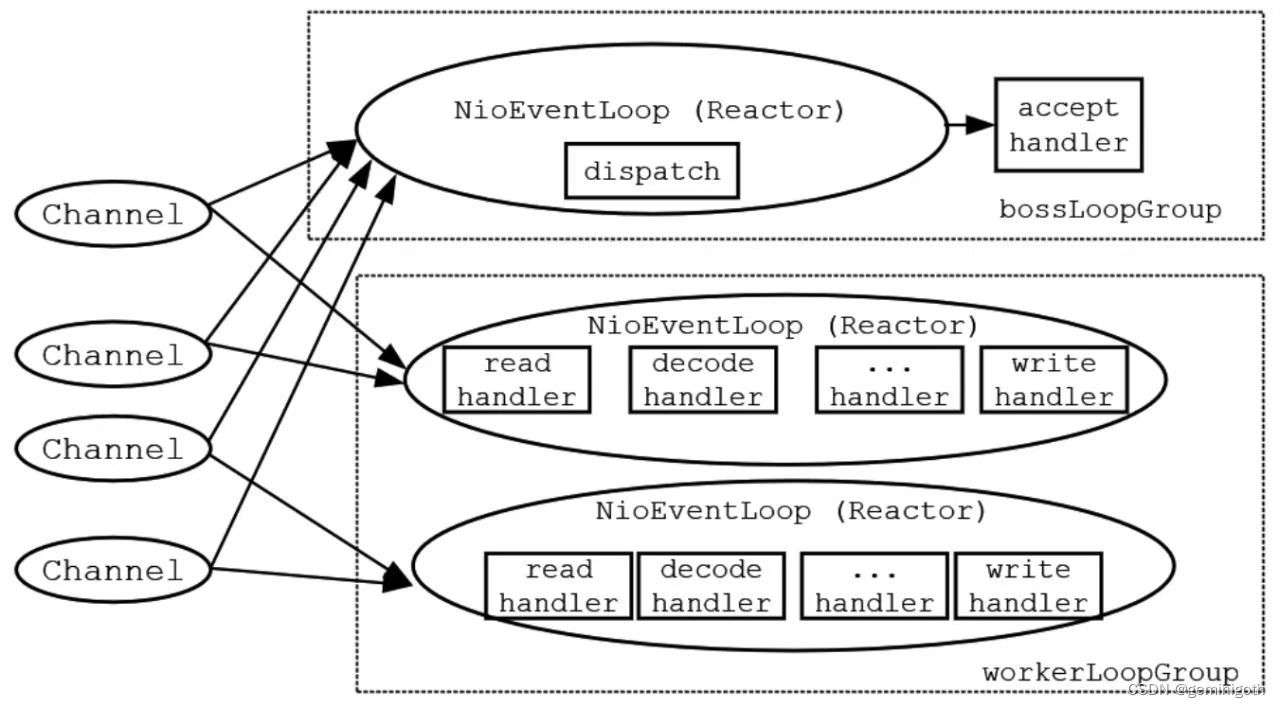
Netty核心原理与基础实战(二)——详解Bootstrap
接上篇:Netty核心原理与基础实战(一) 1 Bootstrap基础概念 Bootstrap类是Netty提供的一个便利的工厂类,可以通过它来完成Netty的客户端或服务端的Netty组件的组装,以及Netty程序的初始化和启动执行。Netty的官方解释是…...

C语言常见面试题:C语言中如何进行比较运算?
在C语言中,比较运算用于比较两个值的大小关系。比较运算符包括等于()、不等于(!)、大于(>)、小于(<)、大于等于(>)和小于等于࿰…...

学习总结14
# 【CSGRound1】天下第一 ## 题目背景 天下第一的 cbw 以主席的身份在 8102 年统治全宇宙后,开始了自己休闲的生活,并邀请自己的好友每天都来和他做游戏。由于 cbw 想要显出自己平易近人,所以 zhouwc 虽然是一个蒟蒻,也有能和 c…...
D盘不见了如何恢复?4个恢复方法(新版)!
“很奇怪!我的电脑d盘不知道为什么突然不见了,我还保存了很多重要的文件在里面呢,有什么恢复d盘的方法吗?” 在我们的日常生活中,电脑已经成为了我们工作、学习和娱乐的重要工具。然而,有时候我们会遇到一些…...

vector类的模拟实现
实现基本的vector框架 参考的是STL的一些源码,实现的vector也是看起来像是一个简略版的,但是看完能对vector这个类一些接口函数更好的认识。 我们写写成员变量,先来看看STL的成元变量是那些 namespace tjl {template<class T>class …...

Topaz Photo AI for Mac v2.3.1 补丁版人工智能降噪软件无损放大
想要将模糊的图片变得更加清晰?不妨试试Topaz Photo AI for Mac 这款人工智能、无损放大软件。Topaz Photo AI for Mac 一款强大的人工智能降噪软件,允许用户使用复杂的锐化算法来提高图像清晰度,还包括肖像编辑选项,如面部重塑、…...
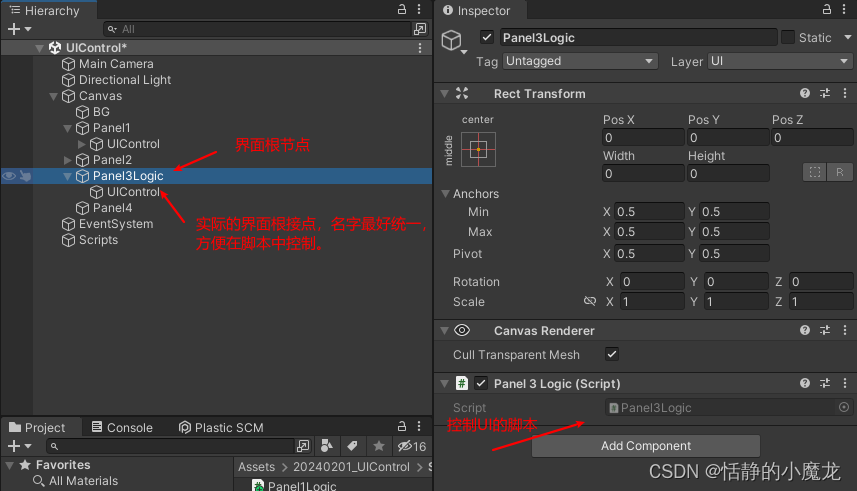
【Unity3D小技巧】Unity3D中UI控制解决方案
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 在开发中总是会控制UI界面,如何优雅的控制UI界面是…...
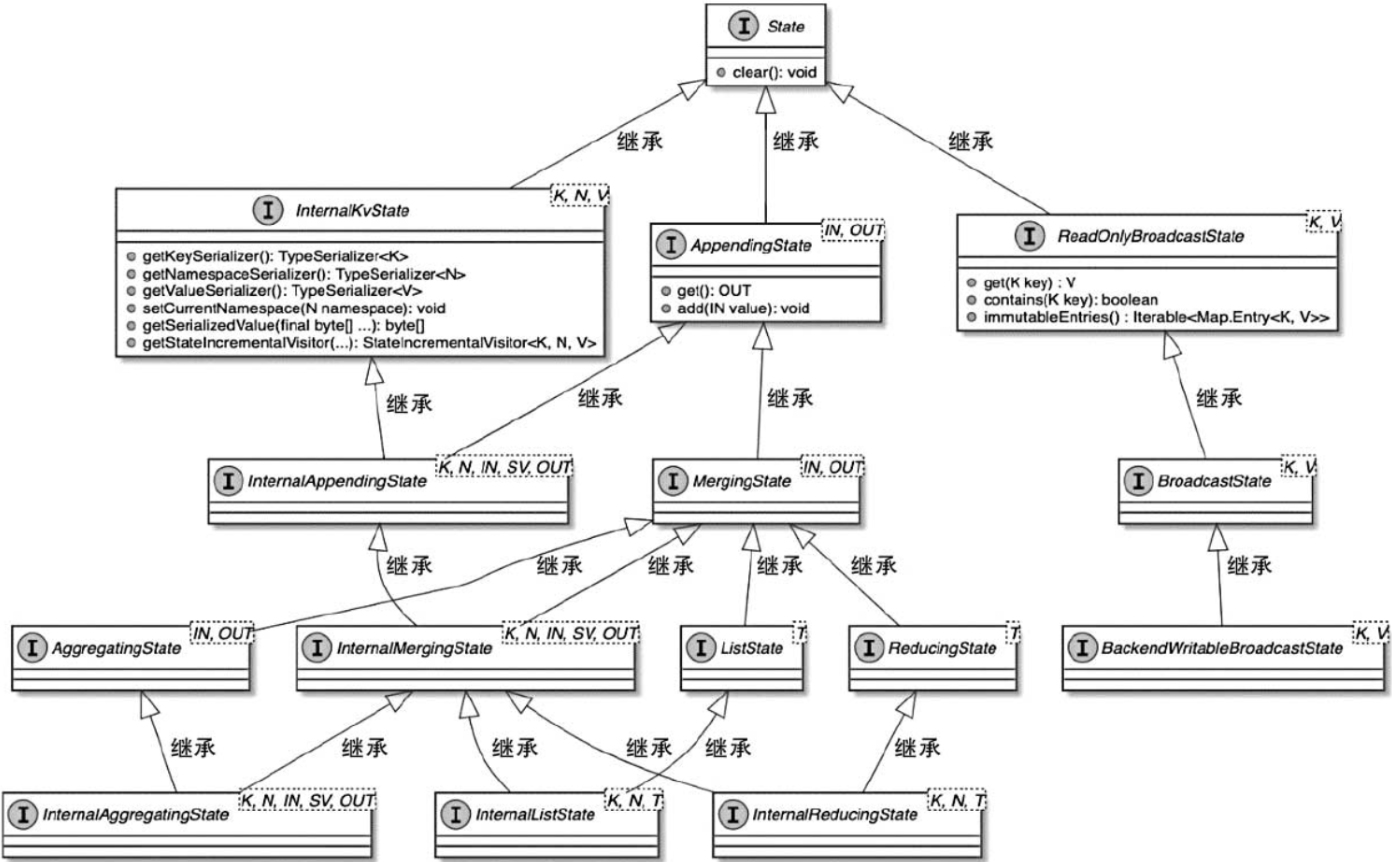
【状态管理一】概览:状态使用、状态分类、状态具体使用
文章目录 一. 状态使用概览二. 状态的数据类型1. 算子层面2. 接口层面2.1. UML与所有状态类型介绍2.2. 内部状态:InternalKvState 将知识与实际的应用场景、设计背景关联起来,这是学以致用、刨根问底知识的一种直接方式。 本文介绍 状态数据管理&#x…...
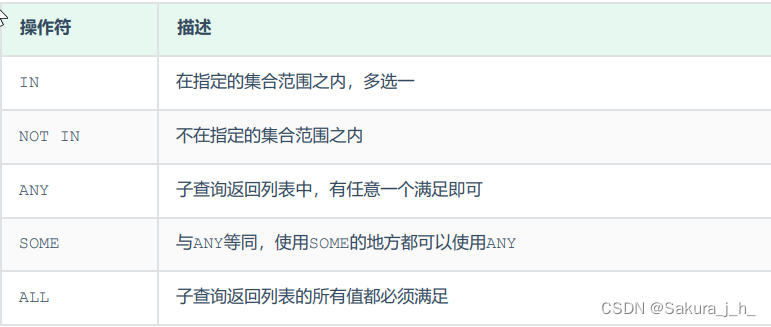
SQL--多表查询
我们之前在讲解SQL语句的时候,讲解了DQL语句,也就是数据查询语句,但是之前讲解的查询都是单 表查询,而本章节我们要学习的则是多表查询操作,主要从以下几个方面进行讲解。 多表关系 项目开发中,在进行数据…...

Kibana 7.3.0 导出CSV报告保姆级教程:从保存搜索到解决内存溢出
Kibana 7.3.0 高效数据导出实战:从基础配置到性能调优全攻略 当你面对TB级别的日志数据需要离线分析时,Kibana的CSV导出功能就像一把双刃剑——用得好能大幅提升工作效率,用不好则可能陷入内存溢出和性能瓶颈的泥潭。本文将带你深入Kibana 7…...

KrkrzExtract:新一代krkrz引擎XP3资源解包工具全攻略
KrkrzExtract:新一代krkrz引擎XP3资源解包工具全攻略 【免费下载链接】KrkrzExtract The next generation of KrkrExtract 项目地址: https://gitcode.com/gh_mirrors/kr/KrkrzExtract KrkrzExtract是一款专门为krkrz游戏引擎设计的下一代资源解包工具&#…...

终极解放!淘宝自动任务神器让你每天多出30分钟自由时间
终极解放!淘宝自动任务神器让你每天多出30分钟自由时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你知…...

为什么GanttProject是你最应该尝试的免费项目管理神器
为什么GanttProject是你最应该尝试的免费项目管理神器 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 在当今快节奏的项目管理环境中,你是否还在为高昂的软件费用和复杂的工具…...

暗黑破坏神2角色编辑器:5分钟打造完美角色的终极指南
暗黑破坏神2角色编辑器:5分钟打造完美角色的终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中漫长的练级过程而苦恼?想要快速测试不同职业的bui…...

pkrelay:轻量级端口转发工具的设计原理与生产实践
1. 项目概述:一个轻量级、高可用的端口转发与流量中继工具在分布式系统、微服务架构以及混合云部署的日常运维和开发调试中,我们经常会遇到一个经典问题:如何安全、便捷地将一个网络环境中的服务端口,暴露给另一个网络环境访问&am…...

Android开源生态重构:从中心化控制到社区驱动的技术路径与挑战
1. 从“相对开放”到“真正自由”:Android生态的十字路口作为一名在移动通信和嵌入式系统领域摸爬滚打了十几年的工程师,我亲眼见证了Android从初代HTC Dream上那个略显笨拙的“小绿人”,成长为如今驱动全球数十亿智能设备的庞然大物。最近重…...

开源提示词工程平台LynxPrompt:本地化部署与工程化实践指南
1. 项目概述:一个提示词工程的“瑞士军刀”如果你和我一样,长期在AI应用开发、内容创作或者自动化流程构建的一线工作,那么“提示词”这三个字对你来说,绝对不陌生。从简单的聊天对话,到复杂的代码生成、数据分析&…...

冠珠瓷砖×莫氏鸡煲×叠滘东胜东队,德叔有请,莫叔掌勺,“力撑”叠滘龙船传承
5月10日,2026叠滘龙船漂移大赛金牌合作伙伴冠珠瓷砖品牌代表、新明珠集团董事长叶德林“德叔”有请,莫氏鸡煲创始人“莫叔”掌勺,携火爆全网的莫氏祛湿鸡煲、紫洞黄皮酒,探班叠滘东胜东队训练场。当天下午,德叔、莫叔还…...

深度拆解GPT-Realtime-2:从“能听会说”到“听懂人话”,靠的是什么?
请你想象这个场景: 你打电话订酒店,中途改主意3次,还接了另一个电话。AI全程没让你重复一句话。——这就是GPT-Realtime-2做到的事。三大模型,三类场景的精准切割OpenAI此次发布的核心策略是专业化分工:GPT-Realtime-2…...