SQL--多表查询
我们之前在讲解SQL语句的时候,讲解了DQL语句,也就是数据查询语句,但是之前讲解的查询都是单 表查询,而本章节我们要学习的则是多表查询操作,主要从以下几个方面进行讲解。
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结 构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
一对多(多对一)
多对多
一对一
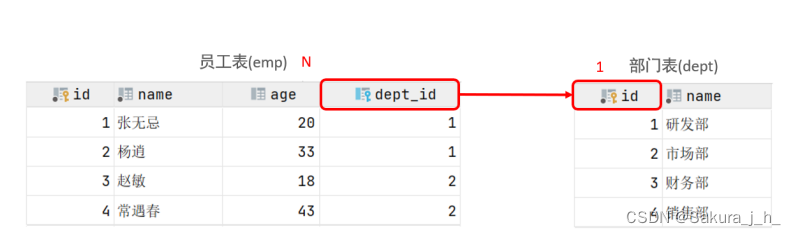
一对多
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 在多的一方建立外键,指向一的一方的主键
多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

对应的SQL脚本:
create table student
(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',no varchar(10) comment '学号'
) comment '学生表';
insert into student
values (null, '黛绮丝', '2000100101'),(null, '谢逊','2000100102'),(null, '殷天正', '2000100103'),(null, '韦一笑', '2000100104');
create table course
(id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';
insert into course
values (null, 'Java'),(null, 'PHP'),(null, 'MySQL'),(null, 'Hadoop');
create table student_course
(id int auto_increment comment '主键' primary key,studentid int not null comment '学生ID',courseid int not null comment '课程ID',constraint fk_courseid foreign key (courseid) references course (id),constraint fk_studentid foreign key (studentid) references student (id)
) comment '学生课程中间表';
insert into student_course
values (null, 1, 1),(null, 1, 2),(null, 1, 3),(null, 2, 2),(null, 2, 3),(null, 3, 4);一对一
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另 一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)

对应的SQL脚本:
create table tb_user
(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '1: 男 , 2: 女',phone char(11) comment '手机号'
) comment '用户基本信息表';
create table tb_user_edu
(id int auto_increment primary key comment '主键ID',degree varchar(20) comment '学历',major varchar(50) comment '专业',primaryschool varchar(50) comment '小学',middleschool varchar(50) comment '中学',university varchar(50) comment '大学',userid int unique comment '用户ID',constraint fk_userid foreign key (userid) references tb_user (id)
) comment '用户教育信息表';
insert into tb_user(id, name, age, gender, phone)
values (null, '黄渤', 45, '1', '18800001111'),(null, '冰冰', 35, '2', '18800002222'),(null, '码云', 55, '1', '18800008888'),(null, '李彦宏', 50, '1', '18800009999');
insert into tb_user_edu(id, degree, major, primaryschool, middleschool,university, userid)
values (null, '本科', '舞蹈', '静安区第一小学', '静安区第一中学', '北京舞蹈学院', 1),(null, '硕士', '表演', '朝阳区第一小学', '朝阳区第一中学', '北京电影学院', 2),(null, '本科', '英语', '杭州市第一小学', '杭州市第一中学', '杭州师范大学', 3),(null, '本科', '应用数学', '阳泉第一小学', '阳泉区第一中学', '清华大学', 4);多表查询概述
数据准备
1). 删除之前 emp, dept表的测试数据
2). 执行如下脚本,创建emp表与dept表并插入测试数据
-- 创建dept表,并插入数据
create table dept
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '部门名称'
) comment '部门表';
INSERT INTO dept (id, name)
VALUES (1, '研发部'),(2, '市场部'),(3, '财务部'),(4,'销售部'),(5, '总经办'),(6, '人事部');
-- 创建emp表,并插入数据
create table emp
(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '姓名',age int comment '年龄',job varchar(20) comment '职位',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment '直属领导ID',dept_id int comment '部门ID'
) comment '员工表';
-- 添加外键
alter table empadd constraint fk_emp_dept_id foreign key (dept_id) referencesdept (id);
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES (1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5),(2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1),(3, '杨逍', 33, '开发', 8400, '2000-11-03', 2, 1),(4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1),(5, '常遇春', 43, '开发', 10500, '2004-09-07', 3, 1),(6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1),(7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3),(8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3),(9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3),(10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2),(11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2),(12, '鹤笔翁', 19, '职员', 3750, '2007-05-09', 10, 2),(13, '方东白', 19, '职员', 5500, '2009-02-12', 10, 2),(14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4),(15, '俞莲舟', 38, '销售', 4600, '2004-10-12', 14, 4),(16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4),(17, '陈友谅', 42, null, 2000, '2011-10-12', 1, null);dept表共6条记录,emp表共17条记录。
概述
多表查询就是指从多张表中查询数据。
原来查询单表数据,执行的SQL形式为:select * from emp;
那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,如: select * from emp , dept ; 具体的执行结果如下:
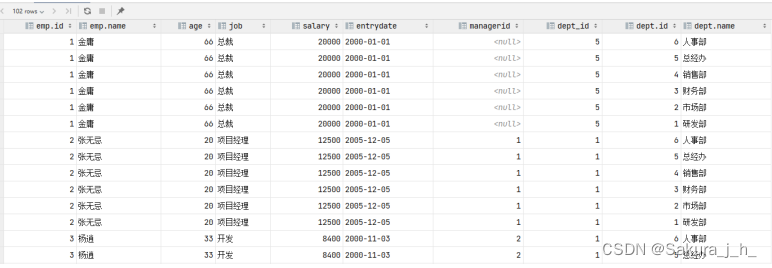
此时,我们看到查询结果中包含了大量的结果集,总共102条记录,而这其实就是员工表emp所有的记录 (17) 与 部门表dept所有记录(6) 的所有组合情况,这种现象称之为笛卡尔积。
接下来,就来简单 介绍下笛卡尔积。 笛卡尔积: 笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。
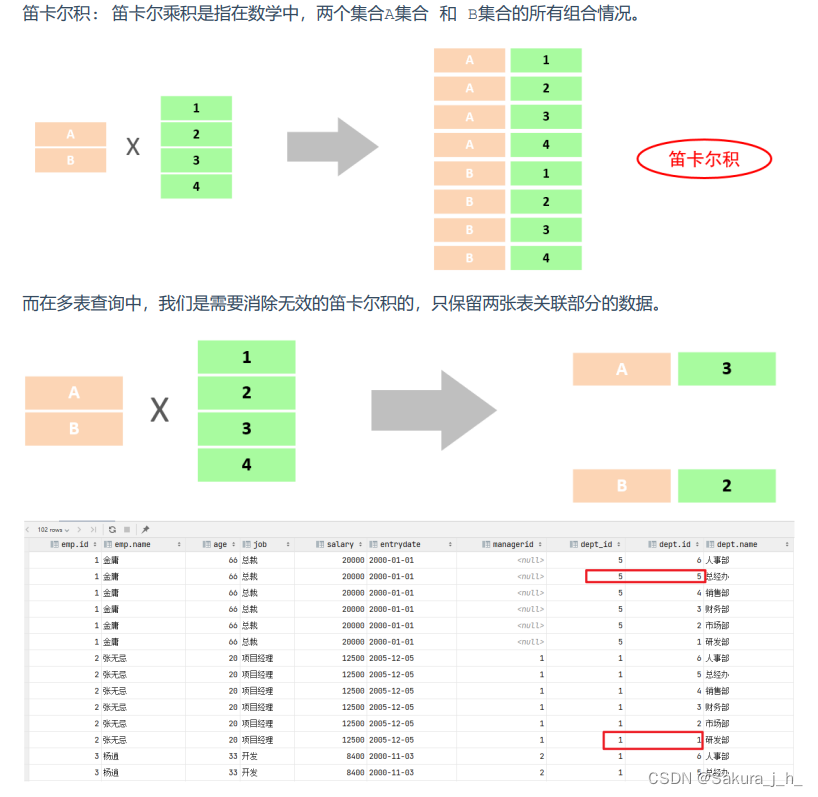 在SQL语句中,如何来去除无效的笛卡尔积呢? 我们可以给多表查询加上连接查询的条件即可
在SQL语句中,如何来去除无效的笛卡尔积呢? 我们可以给多表查询加上连接查询的条件即可
分类
连接查询
内连接:相当于查询A、B交集部分数据
外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据
右外连接:查询右表所有数据,以及两张表交集部分数据
自连接:当前表与自身的连接查询,自连接必须使用表别名
子查询
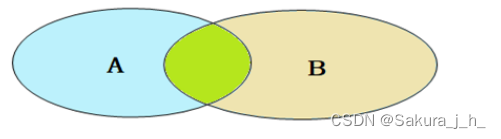
内连接

1). 隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;2). 显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;案例:
A. 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: emp , dept
连接条件: emp.dept_id = dept.id
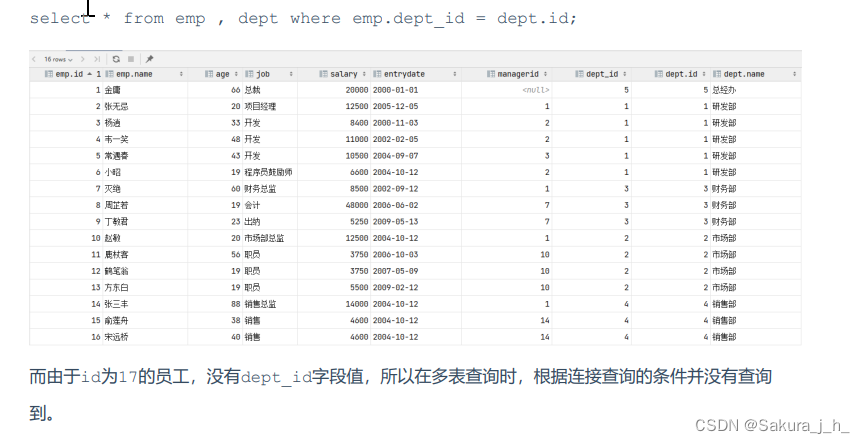
select emp.name , dept.name from emp , dept where emp.dept_id = dept.id ;-- 为每一张表起别名,简化SQL编写
select e.name,d.name from emp e , dept d where e.dept_id = d.id;B. 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) --- INNER JOIN ... ON ...
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id;-- 为每一张表起别名,简化SQL编写
select e.name, d.name from emp e join dept d on e.dept_id = d.id;表的别名:
①. tablea as 别名1 , tableb as 别名2 ;
②. tablea 别名1 , tableb 别名2 ;
注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字 段。
外连接
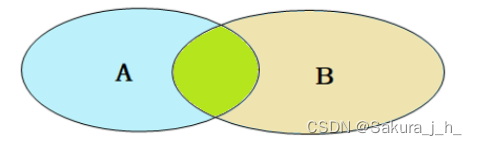
外连接分为两种,分别是:左外连接 和 右外连接。具体的语法结构为:
1). 左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
2). 右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
案例:
A. 查询emp表的所有数据, 和对应的部门信息
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id;select e.*, d.name from emp e left join dept d on e.dept_id = d.id;B. 查询dept表的所有数据, 和对应的员工信息(右外连接
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查 询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id;select d.*, e.* from dept d left outer join emp e on e.dept_id = d.id;注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺 序就可以了。而我们在日常开发使用时,更偏向于左外连接。
自连接
自连接查询
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。我们先来学习一下自连接 的查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;而对于自连接查询,可以是内连接查询,也可以是外连接查询。
案例:
A. 查询员工 及其 所属领导的名字
表结构: emp
select a.name , b.name from emp a , emp b where a.managerid = b.id;
B. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来 表结构: emp a , emp b
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid =
b.id;注意事项: 在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。
联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集.
SELECT 字段列表 FROM 表A ...
UNION [ ALL ]
SELECT 字段列表 FROM 表B ....;对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
案例:
A. 将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
当前对于这个需求,我们可以直接使用多条件查询,使用逻辑运算符 or 连接即可。 那这里呢,我们 也可以通过union/union all来联合查询.
select * from emp where salary < 5000
union all
select * from emp where age > 50;
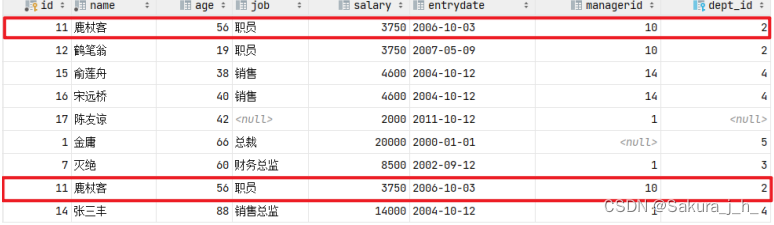
union all查询出来的结果,仅仅进行简单的合并,并未去重。
select * from emp where salary < 5000
union
select * from emp where age > 50; 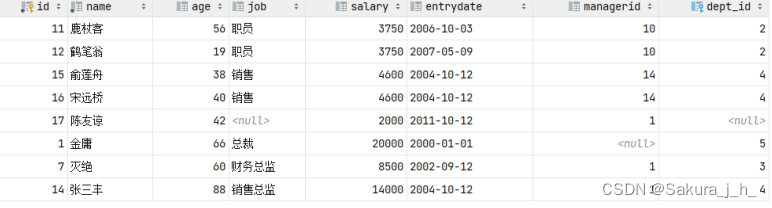
union 联合查询,会对查询出来的结果进行去重处理。
注意:
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报 错。如:

子查询
概述
1). 概念
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
2). 分类
根据子查询结果不同,
分为: A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符:= <> > >= < <=
案例:
A. 查询 "销售部" 的所有员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 "销售部" 部门ID
select id from dept where name = '销售部';
②. 根据 "销售部" 部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');
B. 查询在 "方东白" 入职之后的员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 方东白 的入职日期
select entrydate from emp where name = '方东白';②. 查询指定入职日期之后入职的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东
白');
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
案例:
A. 查询 "销售部" 和 "市场部" 的所有员工信息
分解为以下两步:
①. 查询 "销售部" 和 "市场部" 的部门ID
select id from dept where name = '销售部' or name = '市场部';②. 根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or
name = '市场部');B. 查询比 财务部 所有人工资都高的员工信息
分解为以下两步:
①. 查询所有 财务部 人员工资
select id from dept where name = '财务部';select salary from emp where dept_id = (select id from dept where name = '财务部');
②. 比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id =
(select id from dept where name = '财务部') );C. 查询比研发部其中任意一人工资高的员工信息
分解为以下两步:
①. 查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');②. 比研发部其中任意一人工资高的员工信息
select * from emp where salary > any ( select salary from emp where dept_id =
(select id from dept where name = '研发部') );行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
A. 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
这个需求同样可以拆解为两步进行:
①. 查询 "张无忌" 的薪资及直属领导
select salary, managerid from emp where name = '张无忌'②. 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp
where name = '张无忌');表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
A. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
分解为两步执行:
①查询 "鹿杖客" , "宋远桥" 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';②. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name =
'鹿杖客' or name = '宋远桥' );
B. 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分解为两步执行:
①. 入职日期是 "2006-01-01" 之后的员工信息
select * from emp where entrydate > '2006-01-01';②. 查询这部分员工, 对应的部门信息;
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left
join dept d on e.dept_id = d.id ;多表查询案例
数据环境准备:
create table salgrade(grade int,losal int,hisal int
) comment '薪资等级表';insert into salgrade values (1,0,3000);
insert into salgrade values (2,3001,5000);
insert into salgrade values (3,5001,8000);
insert into salgrade values (4,8001,10000);
insert into salgrade values (5,10001,15000);
insert into salgrade values (6,15001,20000);
insert into salgrade values (7,20001,25000);
insert into salgrade values (8,25001,30000);在这个案例中,我们主要运用上面所讲解的多表查询的语法,完成以下的12个需求即可,
而这里主要涉 及到的表就三张:emp员工表、dept部门表、salgrade薪资等级表 。
1). 查询员工的姓名、年龄、职位、部门信息 (隐式内连接)
表: emp , dept
连接条件: emp.dept_id = dept.id
select e.name , e.age , e.job , d.name from emp e , dept d where e.dept_id = d.id;2). 查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
表: emp , dept
连接条件: emp.dept_id = dept.id
select e.name , e.age , e.job , d.name from emp e inner join dept d on e.dept_id =
d.id where e.age < 30;3). 查询拥有员工的部门ID、部门名称
表: emp , dept
连接条件: emp.dept_id = dept.id
select distinct d.id , d.name from emp e , dept d where e.dept_id = d.id;4). 查询所有年龄大于40岁的员工, 及其归属的部门名称; 如果员工没有分配部门, 也需要展示出 来(外连接)
表: emp , dept
连接条件: emp.dept_id = dept.id
select e.*, d.name from emp e left join dept d on e.dept_id = d.id where e.age >
40 ;5). 查询所有员工的工资等级
表: emp , salgrade
连接条件 : emp.salary >= salgrade.losal and emp.salary <= salgrade.hisal
-- 方式一
select e.* , s.grade , s.losal, s.hisal from emp e , salgrade s where e.salary >=
s.losal and e.salary <= s.hisal;
-- 方式二
select e.* , s.grade , s.losal, s.hisal from emp e , salgrade s where e.salary
between s.losal and s.hisal;6). 查询 "研发部" 所有员工的信息及 工资等级
表: emp , salgrade , dept
连接条件 : emp.salary between salgrade.losal and salgrade.hisal , emp.dept_id = dept.id 查询条件 : dept.name = '研发部'
select e.* , s.grade from emp e , dept d , salgrade s where e.dept_id = d.id and (
e.salary between s.losal and s.hisal ) and d.name = '研发部';7). 查询 "研发部" 员工的平均工资
表: emp , dept
连接条件 : emp.dept_id = dept.id
select avg(e.salary) from emp e, dept d where e.dept_id = d.id and d.name = '研发
部';8). 查询工资比 "灭绝" 高的员工信息。
①. 查询 "灭绝" 的薪资
select salary from emp where name = '灭绝';
②. 查询比她工资高的员工数据
select * from emp where salary > ( select salary from emp where name = '灭绝' );9). 查询比平均薪资高的员工信息
①. 查询员工的平均薪资
select avg(salary) from emp;②. 查询比平均薪资高的员工信息
select * from emp where salary > ( select avg(salary) from emp );10). 查询低于本部门平均工资的员工信息
①. 查询指定部门平均薪资
select avg(e1.salary) from emp e1 where e1.dept_id = 1;
select avg(e1.salary) from emp e1 where e1.dept_id = 2;②. 查询低于本部门平均工资的员工信息
select * from emp e2 where e2.salary < ( select avg(e1.salary) from emp e1 where
e1.dept_id = e2.dept_id );11). 查询所有的部门信息, 并统计部门的员工人数
select d.id, d.name , ( select count(*) from emp e where e.dept_id = d.id ) '人数'
from dept d;12). 查询所有学生的选课情况, 展示出学生名称, 学号, 课程名称
表: student , course , student_course
连接条件: student.id = student_course.studentid , course.id = student_course.courseid
select s.name , s.no , c.name from student s , student_course sc ,
course c where s.id = sc.studentid and sc.courseid = c.id ;备注: 以上需求的实现方式可能会很多, SQL写法也有很多,只要能满足我们的需求,查询出符合条 件的记录即可。
相关文章:
SQL--多表查询
我们之前在讲解SQL语句的时候,讲解了DQL语句,也就是数据查询语句,但是之前讲解的查询都是单 表查询,而本章节我们要学习的则是多表查询操作,主要从以下几个方面进行讲解。 多表关系 项目开发中,在进行数据…...
多维时序 | Matlab实现CNN-RVM卷积神经网络结合相关向量机多变量时间序列预测
多维时序 | Matlab实现CNN-RVM卷积神经网络结合相关向量机多变量时间序列预测 目录 多维时序 | Matlab实现CNN-RVM卷积神经网络结合相关向量机多变量时间序列预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现CNN-RVM卷积神经网络结合相关向量机多变量时间序…...

RK3568平台 安卓hal3适配usb camera
一.RK安卓hal3 camera框架 Camera hal3 在 android 框架中所处的位置如上图, 对上,主要实现 Framework 一整套 API 接口,响应其 控制命令,返回数据与控制参数结果。 对下, 主要是通 V4l2 框架实现与 kernel 的交互。3a…...
使用 Visual Studio Code 在远程计算机上调试 PostgreSQL
使用 Visual Studio Code 在远程计算机上调试 PostgreSQL 1. 概述 PostgreSQL 是一个功能强大的开源关系数据库管理系统,适用于各种应用程序。在开发过程中,调试 PostgreSQL 对于识别和解决问题至关重要。在本博客中,我们将手把手教你使用客…...

javascript设计模式之建造者
工厂模式不关心过程,只关心结果,这与建造者相反,建造者更关心的是过程, 这里我们创建一个基类,其拥有技能跟爱好两个属性,还有两个实例方法用来获取技能跟爱好 // 基类 let Human function (param {}) …...

安擎科技携手华为云区块链共同打造安全天空
当前,低空经济崛起,无人机多并发、混合运行时引发的网络信息安全、空域安全问题已成行业首要课题。 在2024年1月正式实施的《民用无人驾驶航空器运行安全管理规则》(CCAR-92)第549条中规定,“无人驾驶航空器航行服务提…...

学习数据结构的第一天
结构体 如何定义结构体 1、先定义结构体类型,再定义结构体类型变量 struct student/定义学生结构体类型/ { long number; char name[20]; char sex; int age; float score[3];/三科考试成绩/ }2、定义结构体类型同时定义结构体类型变量 struct student/定义学生结…...

5.electron之主进程起一个本地服务
如果可以实现记得点赞分享,谢谢老铁~ Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 Electron 将 Chromium 和 Node.js 嵌入到了一个二进制文件中,因此它允许你仅需一个代码仓库,就可以撰写支持 Windows、…...
爬取58二手房并用SVR模型拟合
目录 一、前言 二、爬虫与数据处理 三、模型 一、前言 爬取数据仅用于练习和学习。本文运用二手房规格sepc(如3室2厅1卫)和二手房面积area预测二手房价格price,只是练习和学习,不代表任何实际意义。 二、爬虫与数据处理 import requests import cha…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之RichText组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之RichText组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、RichText组件 鸿蒙(HarmonyOS)富文本组件,…...

7.electron之渲染线程发送事件,主进程监听事件
如果可以实现记得点赞分享,谢谢老铁~ Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 Electron 将 Chromium 和 Node.js 嵌入到了一个二进制文件中,因此它允许你仅需一个代码仓库,就可以撰写支持 Windows、…...
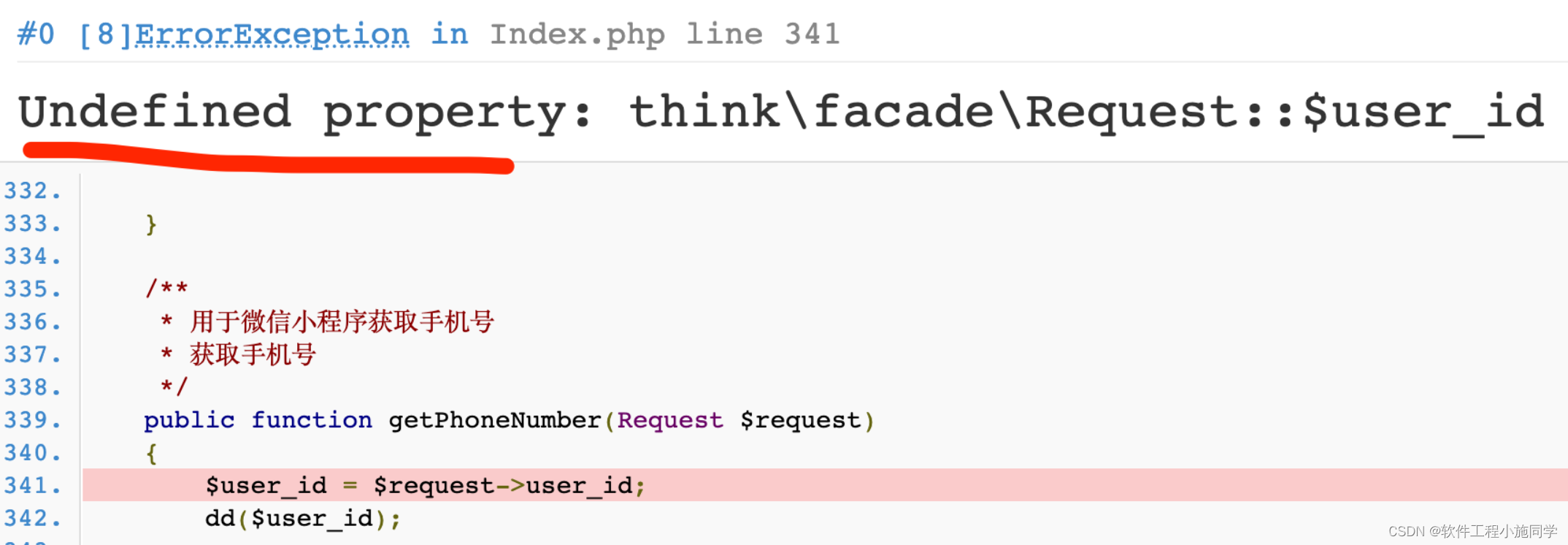
thinkphp6入门(19)-- 中间件向控制器传参
可以通过给请求对象赋值的方式传参给控制器(或者其它地方),例如 <?phpnamespace app\middleware;class Hello {public function handle($request, \Closure $next){$request->hello ThinkPHP;return $next($request);} } 然后在控制…...

Flink Format系列(2)-CSV
Flink的csv格式支持读和写csv格式的数据,只需要指定 format csv,下面以kafka为例。 CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3) ) WITH (connector kafka,topic user_behavior…...

Spring Data Envers 数据审计实战2 - 自定义监听程序扩展审计字段及字段值
上篇讲述了如何在Spring项目中集成Spring Data Envers做数据审计和历史版本查看功能。 之前演示的是业务表中已有的字段进行审计,那么如果我们想扩展审计字段呢? 比如目前对员工表加入了Audited审计,员工表有个字段为dept_id,为…...
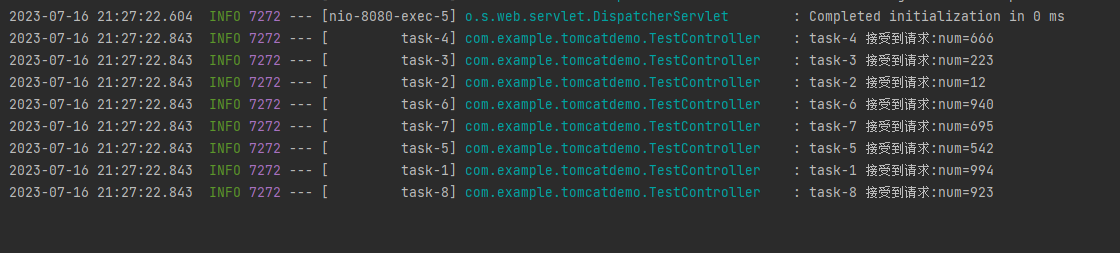
一个 SpringBoot 项目能同时处理多少请求?
目录 1 问题分析 2 Demo 3 答案 4 怎么来的? 5 标准答案及影响参数一Tomcat配置 6 影响参数二 Web容器 7 影响参数三 Async 1 问题分析 一个 SpringBoot 项目能同时处理多少请求? 不知道你听到这个问题之后的第一反应是什么? 我大概…...

计算机网络——网络
计算机网络——网络 小程一言专栏链接: [link](http://t.csdnimg.cn/ZUTXU)前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家, [跳转到网站](https://www.captainbed.cn/qianqiu) 无线网络和移动网…...

C语言探索:选择排序的实现与解读
当我们需要对一组数据进行排序时,选择排序(Selection Sort)是一种简单但效率较低的排序算法。它的基本思想是每次从未排序的数据中选择最小(或最大)的元素,然后将其放置在已排序序列的末尾。通过重复这个过…...
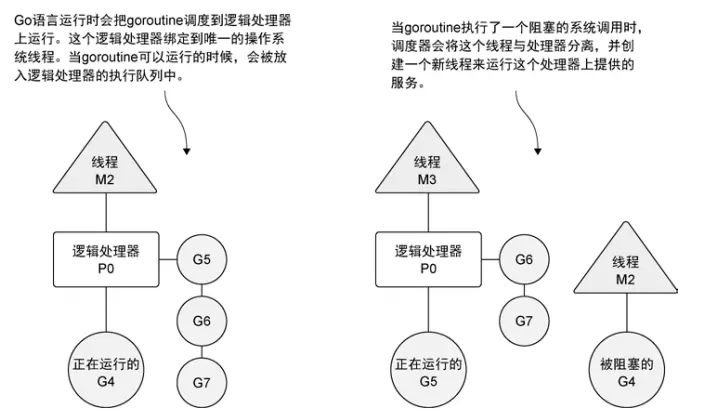
Golang 学习(二)进阶使用
二、进阶使用 性能提升——协程 GoRoutine go f();一个 Go 线程上,可以起多个协程(有独立的栈空间、共享程序堆空间、调度由用户控制)主线程是一个物理线程,直接作用在 cpu 上的。是重量级的,非常耗费 cpu 资源。协…...

ubuntu22.04@laptop OpenCV定制化安装
ubuntu22.04laptop OpenCV定制化安装 1. 源由2. 默认配置3. 定制配置4. 定制安装5. 定制OpenCV-4.9.05.1 修改opencv.conf5.2 加载so文件5.3 修改bash环境变量5.4 增加pkgconfig5.5 检查OpenCV-4.9.0安装 6. 总结7. 参考资料 1. 源由 目前,能Google到的代码层次不齐…...

linux系统非关系型数据库redis
redis 介绍redis的特点:缓存 安装安装单机版redisredis的相关工具 介绍 redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库 redis的官网:redis.ioredis的特点: 丰富的数据结构 支持持久化 支持事务 支持主从缓存 类型 …...

优化算法中的‘0.618’魔法:黄金分割法为何是工程优化的首选入门工具?
黄金分割法:从古希腊美学到现代工程优化的优雅解决方案 在工程优化领域,算法选择往往让初学者感到困惑。面对梯度下降、牛顿法等复杂方法,有一种源自公元前300年的数学比例——黄金分割比(0.618),却成为了…...
)
避坑指南:用高德DistrictSearch获取精准行政边界时遇到的5个典型问题(含最新GeoJson处理技巧)
高德DistrictSearch深度避坑:5个实战难题与GeoJson优化方案 当你在深夜调试地图边界数据时,突然发现某个街道的轮廓出现了诡异的锯齿状变形——这不是恐怖片情节,而是使用高德DistrictSearch时可能遇到的真实场景。作为经历过数十个地图项目…...

技术揭秘:QtScrcpy如何实现跨平台Android投屏与低延迟控制
技术揭秘:QtScrcpy如何实现跨平台Android投屏与低延迟控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScr…...
)
告别复制粘贴!用Qwen Code在终端里直接重构500行烂代码(附真实项目截图)
告别复制粘贴!用Qwen Code在终端里直接重构500行烂代码(附真实项目截图) 接手一个满是技术债的项目,就像走进一间多年无人打扫的仓库——到处是随意堆放的代码、重复的逻辑、难以理解的函数命名。更糟的是,传统的AI辅助…...

Qwen3-0.6B-FP8应用场景:开发者测试LLM应用前端UI兼容性的沙盒环境
Qwen3-0.6B-FP8应用场景:开发者测试LLM应用前端UI兼容性的沙盒环境 1. 引言:为什么需要一个轻量级的“测试沙盒”? 如果你正在开发一个基于大语言模型的应用,比如一个智能客服系统、一个文档助手,或者一个创意写作工…...
Pixel Dream Workshop惊艳效果展示:像素化视频帧序列生成与动画合成
Pixel Dream Workshop惊艳效果展示:像素化视频帧序列生成与动画合成 1. 像素艺术的数字复兴 在数字艺术领域,像素风格正经历着令人振奋的复兴。Pixel Dream Workshop作为这一浪潮中的佼佼者,将传统像素艺术与现代AI技术完美融合,…...

Phi-4-mini-reasoning企业落地案例:集成至内部知识库的逻辑问答模块
Phi-4-mini-reasoning企业落地案例:集成至内部知识库的逻辑问答模块 1. 项目背景与需求 企业内部知识库系统通常面临一个共同挑战:员工在查找专业问题时,往往需要花费大量时间筛选信息,特别是涉及数学计算、逻辑推理等需要多步分…...
)
用Python搞定雷达海杂波建模:从瑞利、威布尔到K分布的仿真对比(附完整代码)
用Python搞定雷达海杂波建模:从瑞利、威布尔到K分布的仿真对比(附完整代码) 雷达海杂波建模是雷达信号处理中的核心挑战之一。想象一下,当雷达波束扫过海面时,回波信号中不仅包含目标信息,还混杂着海面反射…...

RS232 vs RS485 vs TTL:如何为你的嵌入式项目选择正确的电平标准?
RS232 vs RS485 vs TTL:嵌入式工程师的电平标准选型指南 在嵌入式系统开发中,选择合适的电平标准往往决定了整个通信系统的可靠性和成本效益。就像建筑师需要根据不同的地质条件选择合适的地基方案一样,工程师也需要根据传输距离、环境干扰和…...

Port-Hamiltonian建模在ROS2中的实战:用Python实现双机器人能量交换仿真
Port-Hamiltonian建模在ROS2中的实战:用Python实现双机器人能量交换仿真 当两个机器人在协作搬运物体时,它们的能量如何通过接触点传递?当一群无人机编队飞行时,如何数学描述它们之间无形的能量交互?这正是Port-Hamilt…...