java SpringBoot2.7整合Elasticsearch(ES)7 进行文档增删查改
首先 我们在 ES中加一个 books 索引 且带有IK分词器的索引
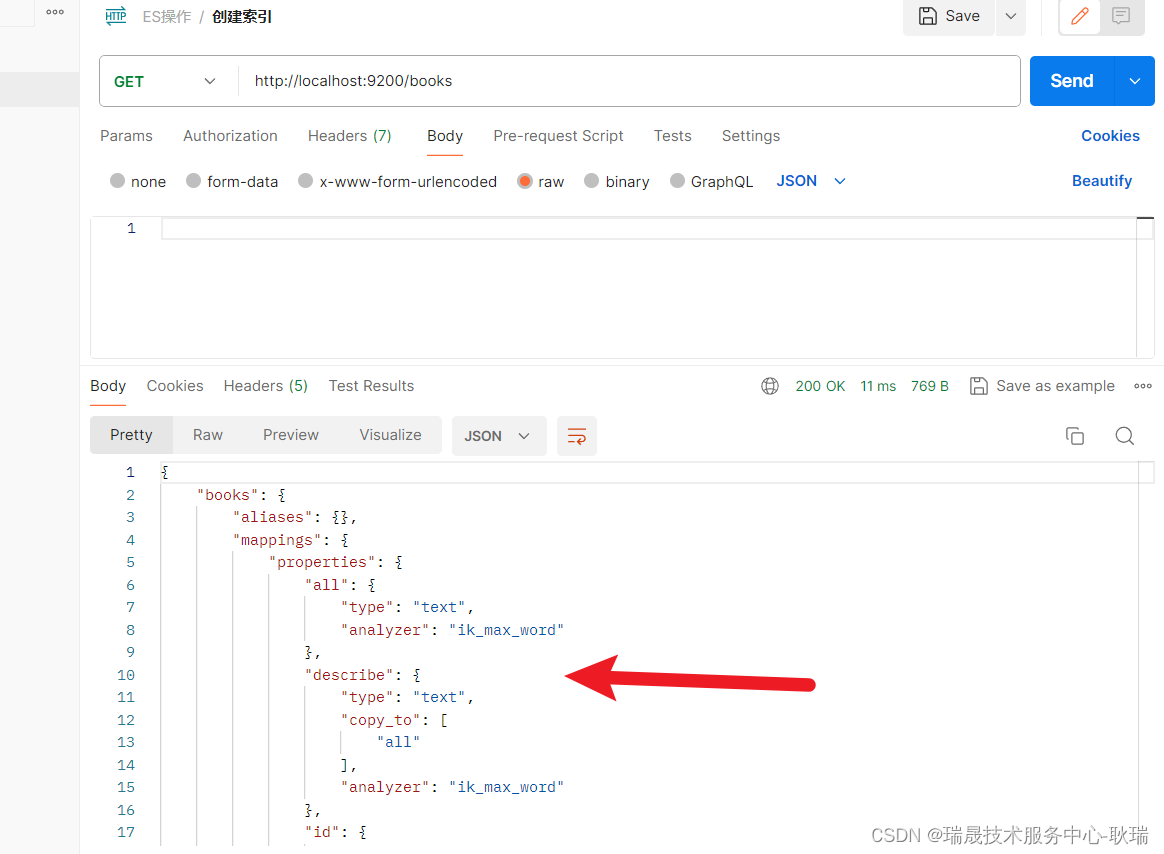
首先 pom.xml导入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
application配置文件中编写如下配置
spring.elasticsearch.hosts: 172.16.5.10:9200
我这里是用的yml格式的
spring:elasticsearch:hosts: http://localhost:9200
告诉它指向 我们本地的 9200服务
然后 我们在启动类同目录下 创建一个叫 domain的包 放属性类
然后在这个包下创建一个叫 books的类
参考代码如下
package com.example.webdom.domain;import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.stereotype.Component;@Component
@Document(indexName = "books")
public class books {private String id;private String type;private String name;private String describe;public String getId() {return id;}public String getName() {return name;}public String getType() {return type;}public String getDescribe() {return describe;}public void setId(String id) {this.id = id;}public void setType(String type) {this.type = type;}public void setName(String name) {this.name = name;}public void setDescribe(String describe) {this.describe = describe;}@Overridepublic String toString() {return "books{" +"id='" + id + '\'' +", type='" + type + '\'' +", name='" + name + '\'' +", description='" + describe + '\'' +'}';}
}
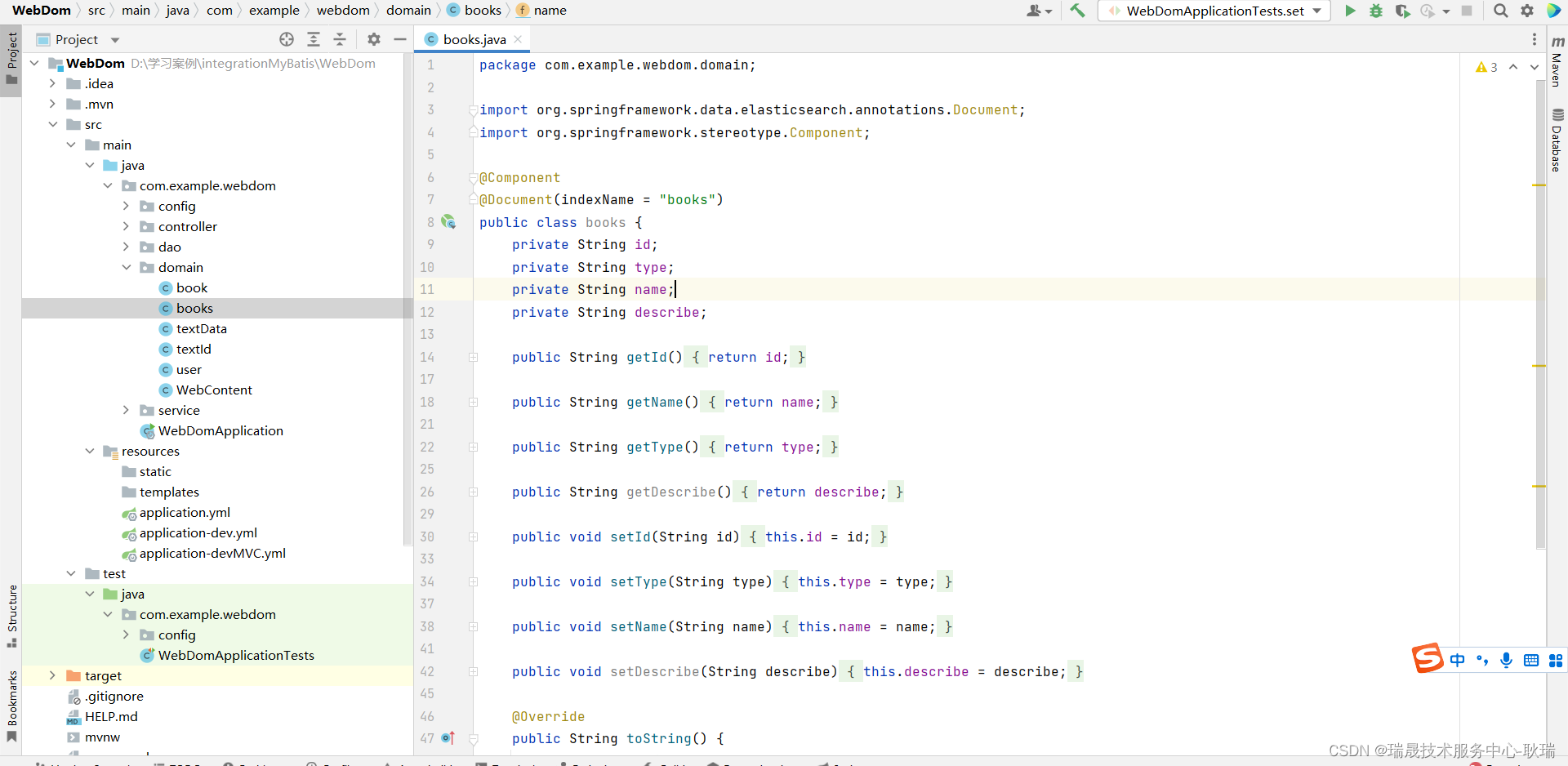
这里 我们就定义了几个属性 声明get set函数 然后 为了不免错误 我们id直接给了个字符串类型
重写了toString 让大家能够更直观的看到属性
然后 Document 的indexName 告诉程序 我们要用的是哪一个索引 这里我们给了个 books 表示操作books 索引
然后 我们创建一个Mapper接口 这里 我们直接就叫 BooksMapper
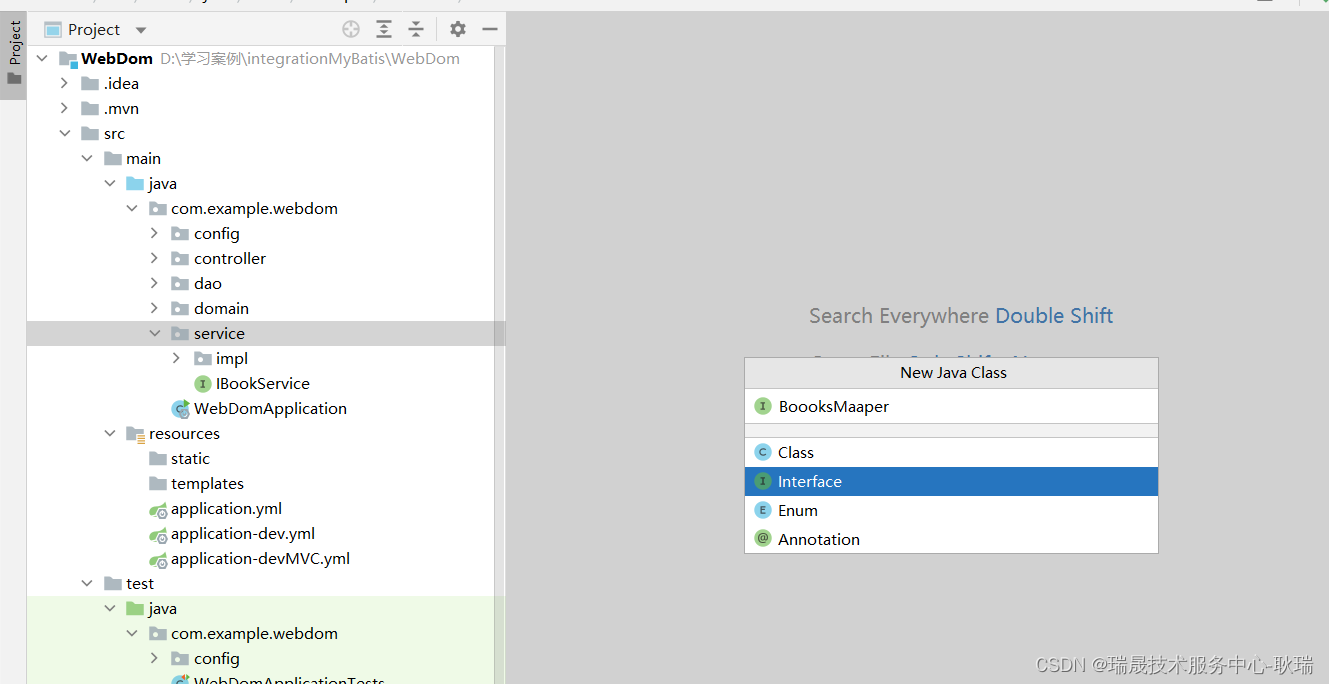
接口代码如下
package com.example.webdom.service;import com.example.webdom.domain.books;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;@Repository
public interface BoooksMaaper extends ElasticsearchRepository<books,String> {
}
它需要继承 ElasticsearchRepository 操作ES的一个接口 然后通过 Repository 将它加到spring容器中
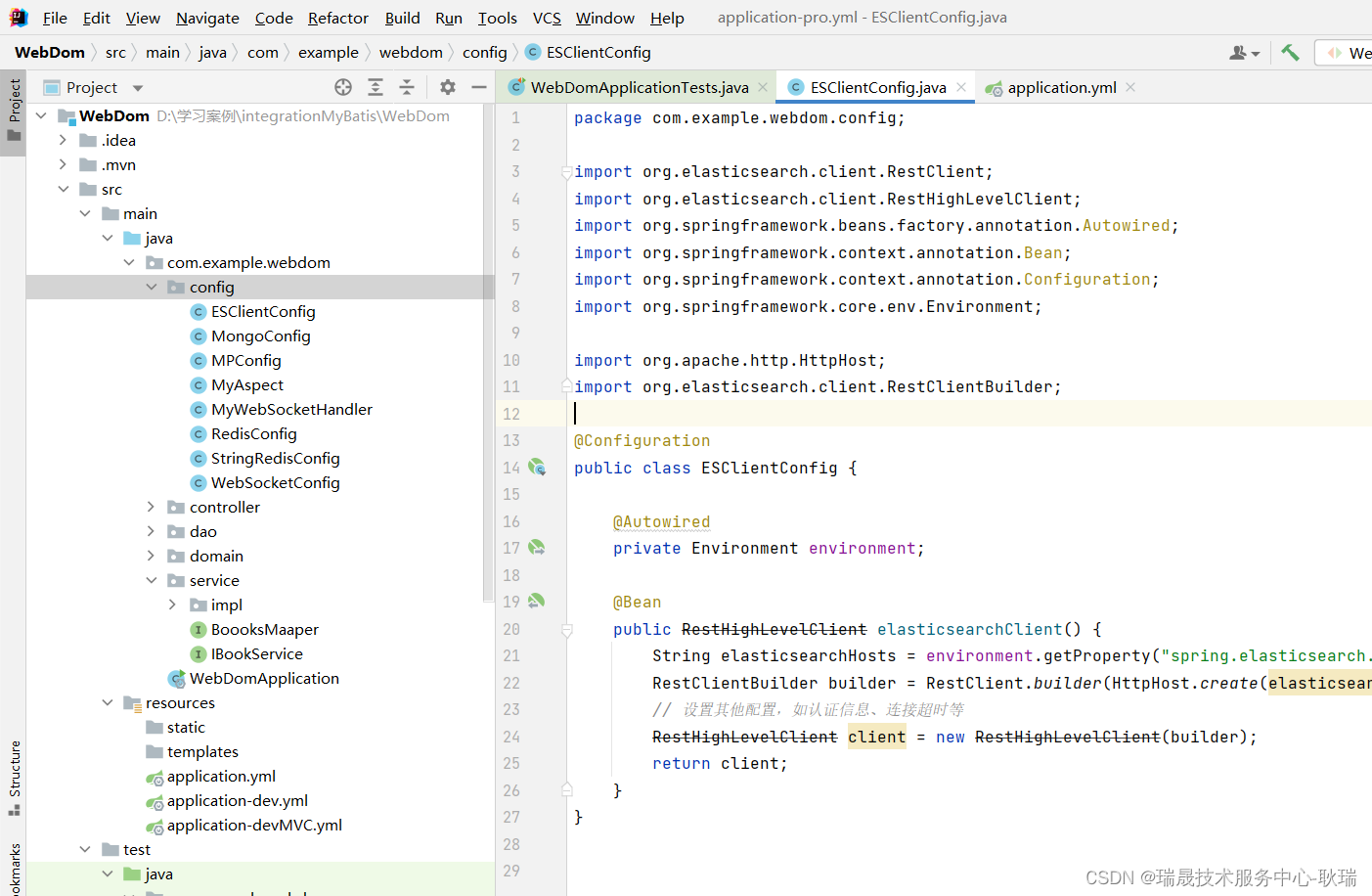
然后 我们在启动类同目录下的 config 包 没有就建一个 下面创建一个类 叫 ESClientConfig 名字无所谓
然后 编写代码如下
package com.example.webdom.config;import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClientBuilder;@Configuration
public class ESClientConfig {@Autowiredprivate Environment environment;@Beanpublic RestHighLevelClient elasticsearchClient() {String elasticsearchHosts = environment.getProperty("spring.elasticsearch.hosts");RestClientBuilder builder = RestClient.builder(HttpHost.create(elasticsearchHosts));// 设置其他配置,如认证信息、连接超时等RestHighLevelClient client = new RestHighLevelClient(builder);return client;}
}
然后 我们在测试类 中将这个接口条件装配进来
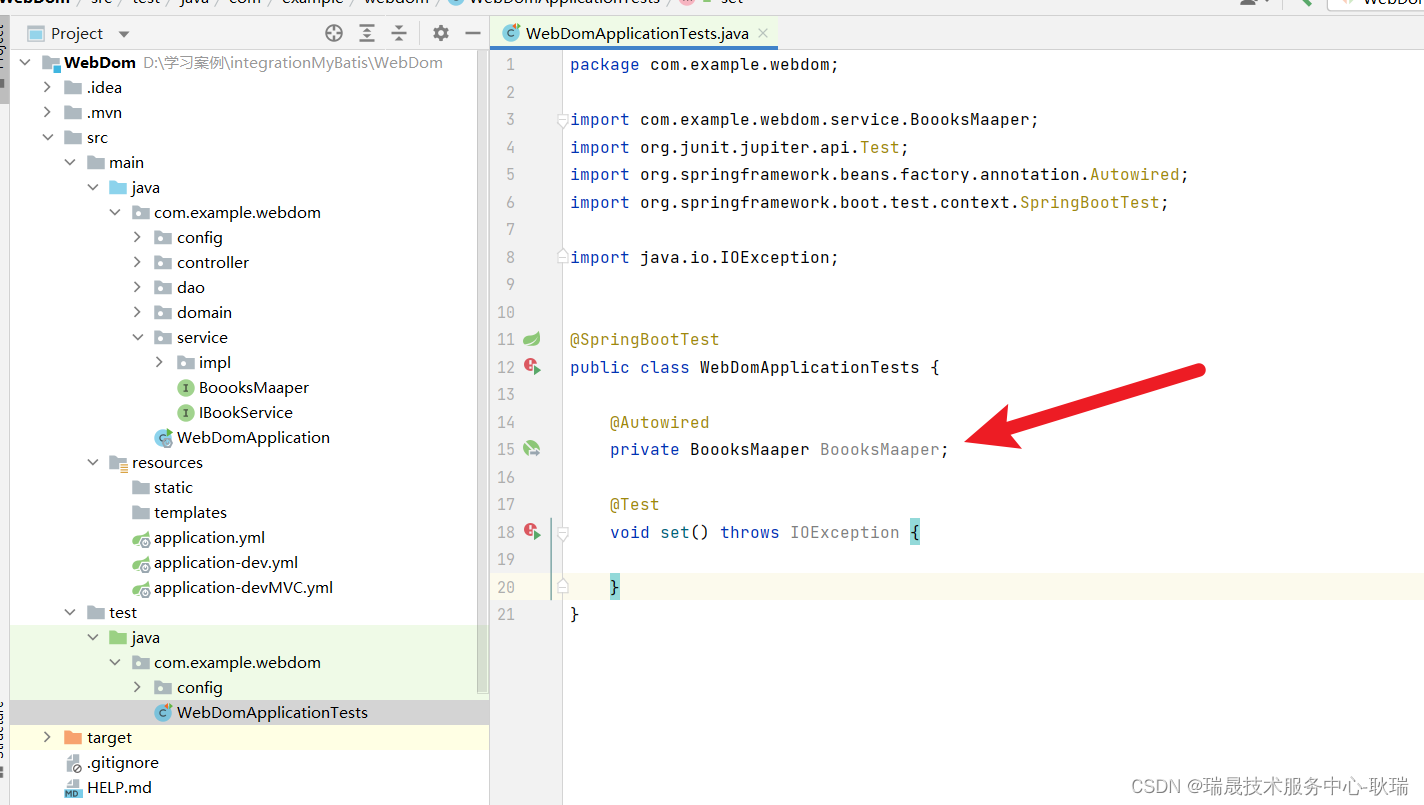
测试类代码编写如下
package com.example.webdom;import com.example.webdom.domain.books;
import com.example.webdom.service.BoooksMaaper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class WebDomApplicationTests {@Autowiredprivate BoooksMaaper BoooksMaaper;@Testvoid set() {books bookdai = new books();bookdai.setId("1");bookdai.setType("爱猫当的自我修改样");bookdai.setName("爱护猫猫");bookdai.setDescribe("帮助所有爱猫当快速了解猫猫");books book = BoooksMaaper.save(bookdai);System.out.println(book);}
}
这里 我们条件装配了自己写的接口 BoooksMaaper
然后 books实体类 new出来 然后 用set方法给每一个字段赋值
最后调用 save 添加方法 它有一个返回值 就是我们的属性类实体对象
我们右键运行
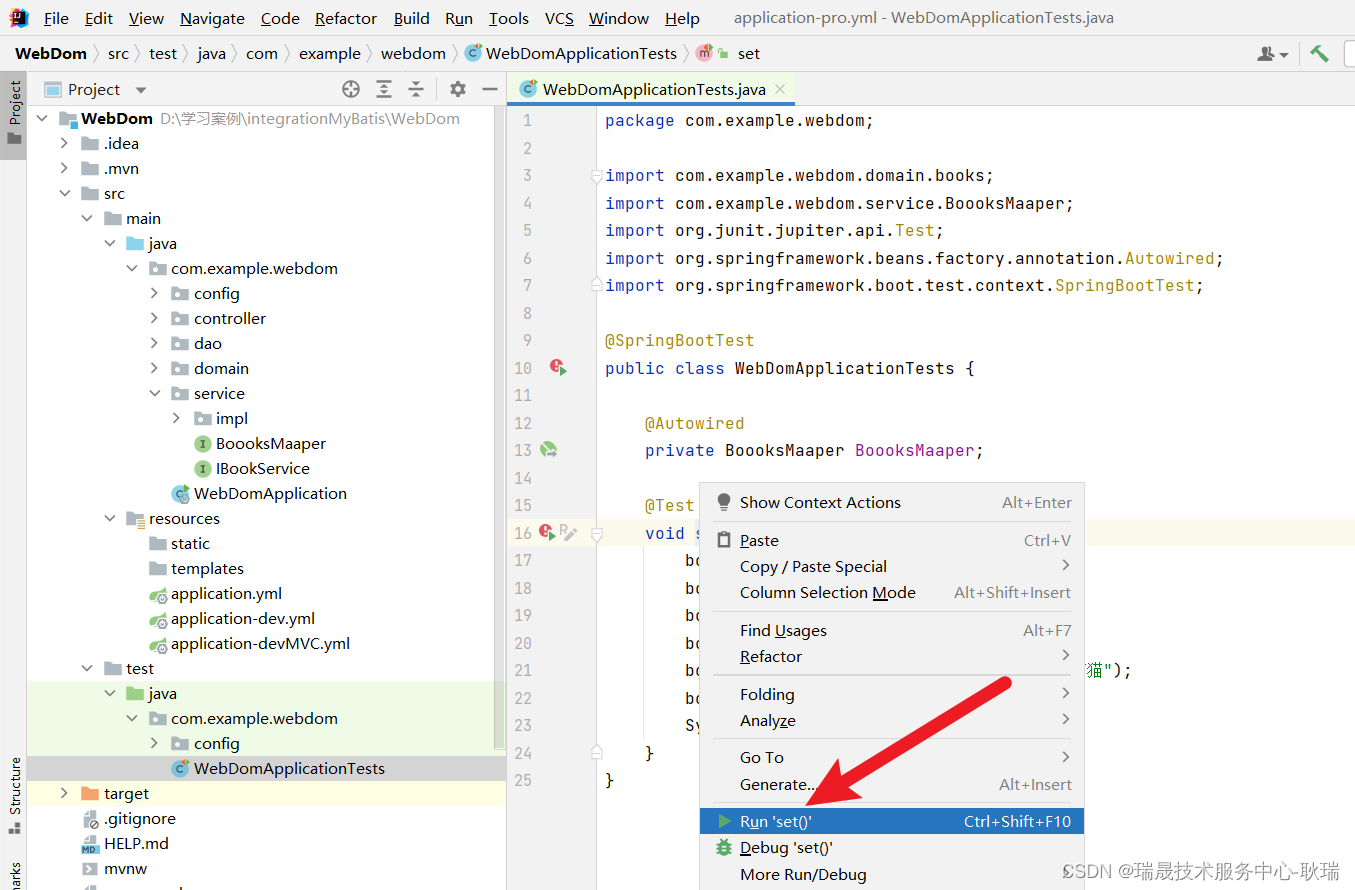
此时 我们就运行成功了 然后 可以看到 save 返回的这个对象 就是我们添加进去的东西了
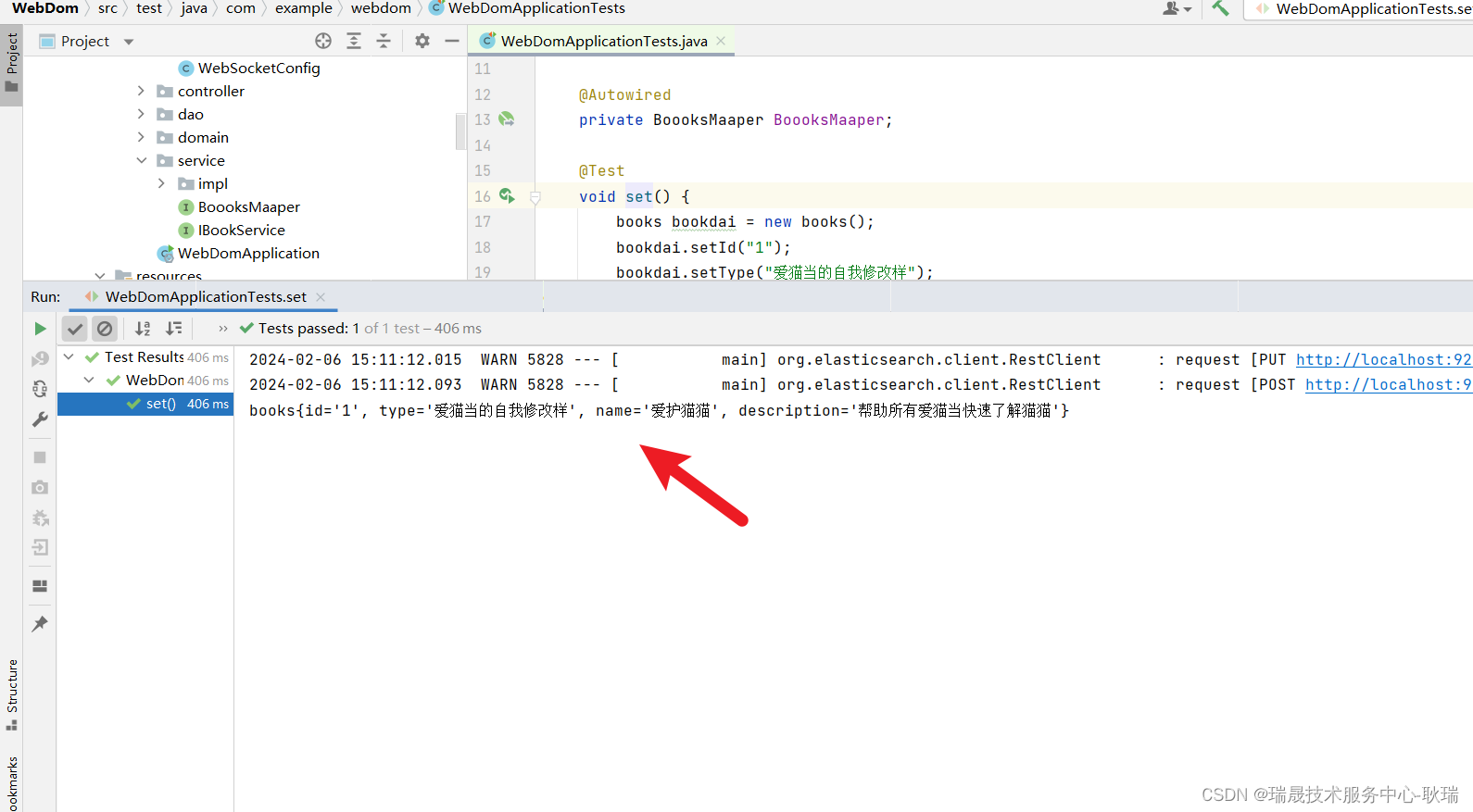
然后 我们通过请求查询一下 books索引下面的文档
http://localhost:9200/books/_search get
就会看到 这里确实是进来了
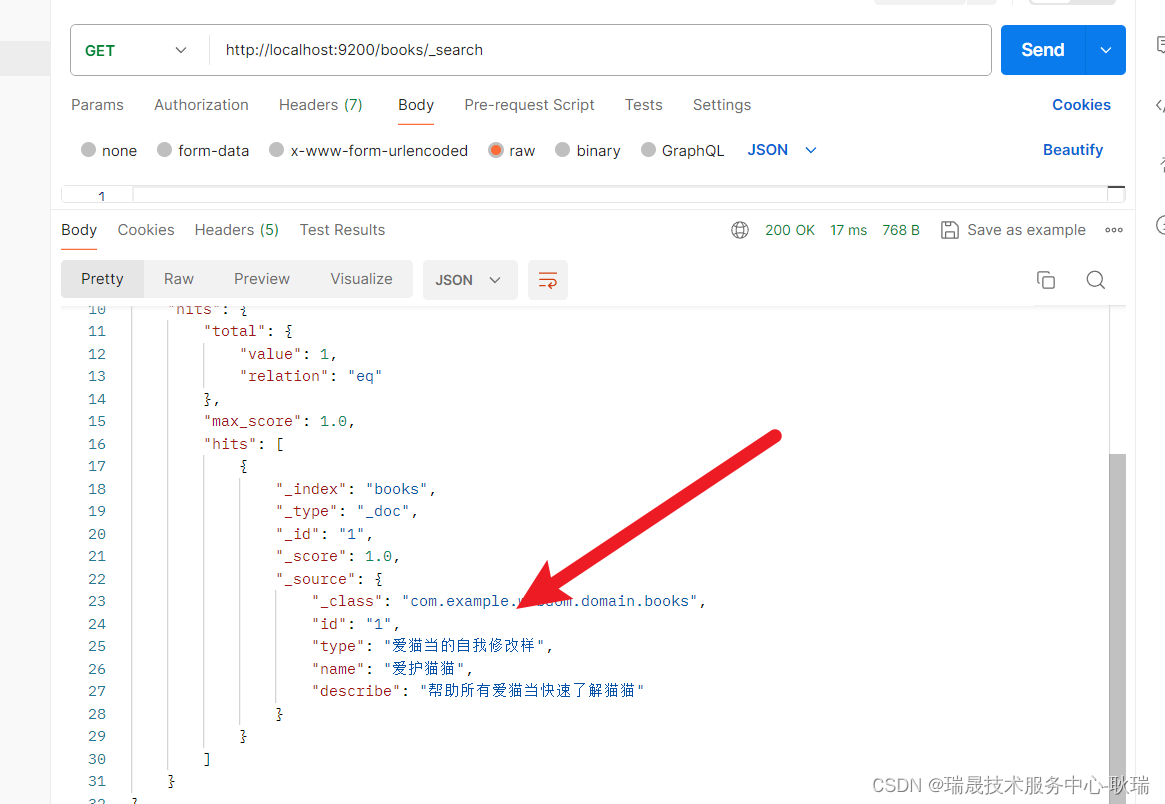
然后呢 这个东西的修改比较有意思
我们还是这样一段代码
books bookdai = new books();
bookdai.setId("1");
bookdai.setType("vue");
bookdai.setName("vue基础到进阶");
bookdai.setDescribe("测试vue内容修改");
books book = BoooksMaaper.save(bookdai);
System.out.println(book);
有些人可能已经蒙了 save不是添加吗?
这里的设定非常有趣呀 save 你的id如果有 它会覆盖 如果没有 就是添加
我们的id 1是已经存在的 所以 它会将我们前面添加那条id为1的数据覆盖掉 就是修改功能了
运行之后 控制台输出一切正常
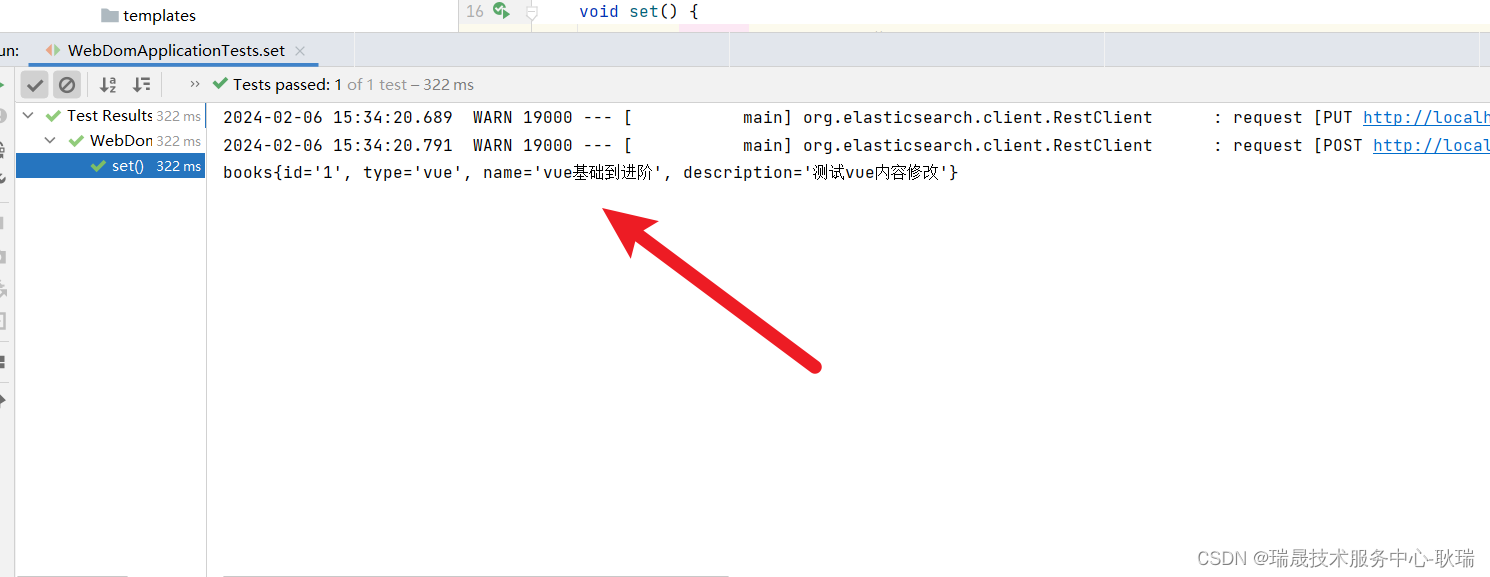
然后 我们来查一下
会发现 确实是实现了一个修改的效果
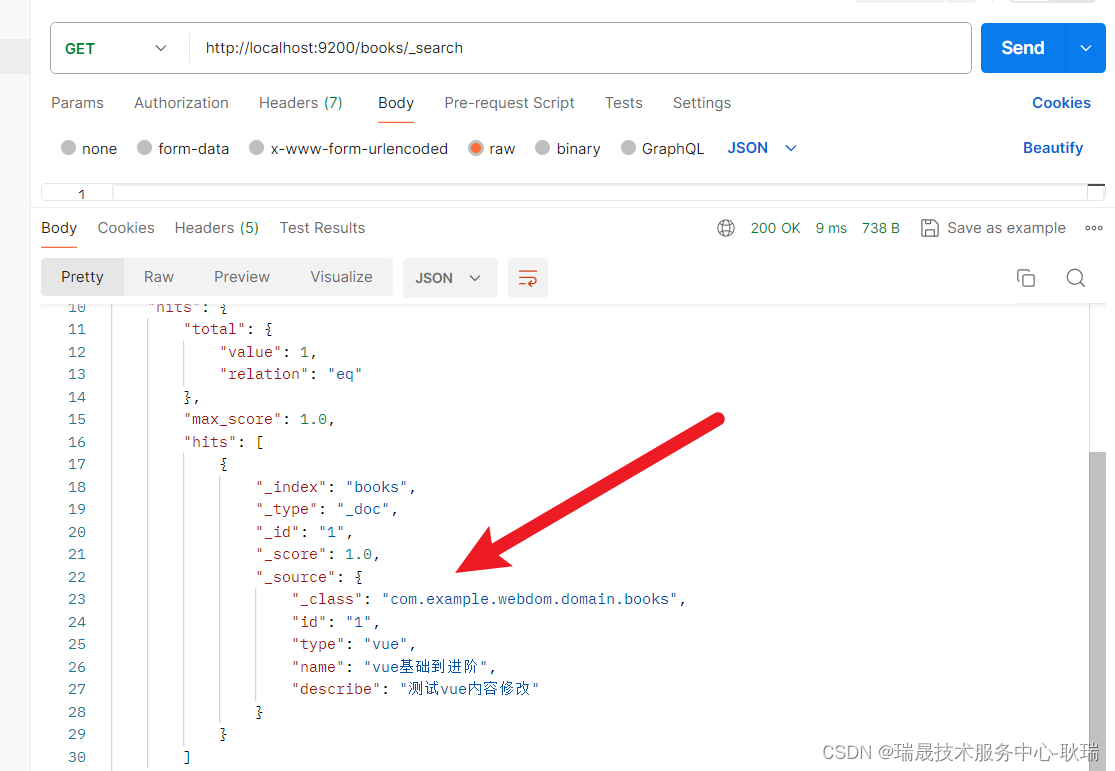
然后 我们来看 ES最有特殊的查询
其实ES主要的价值就在于分词的一个查询
首先是查询全部 findAll
我们这样写
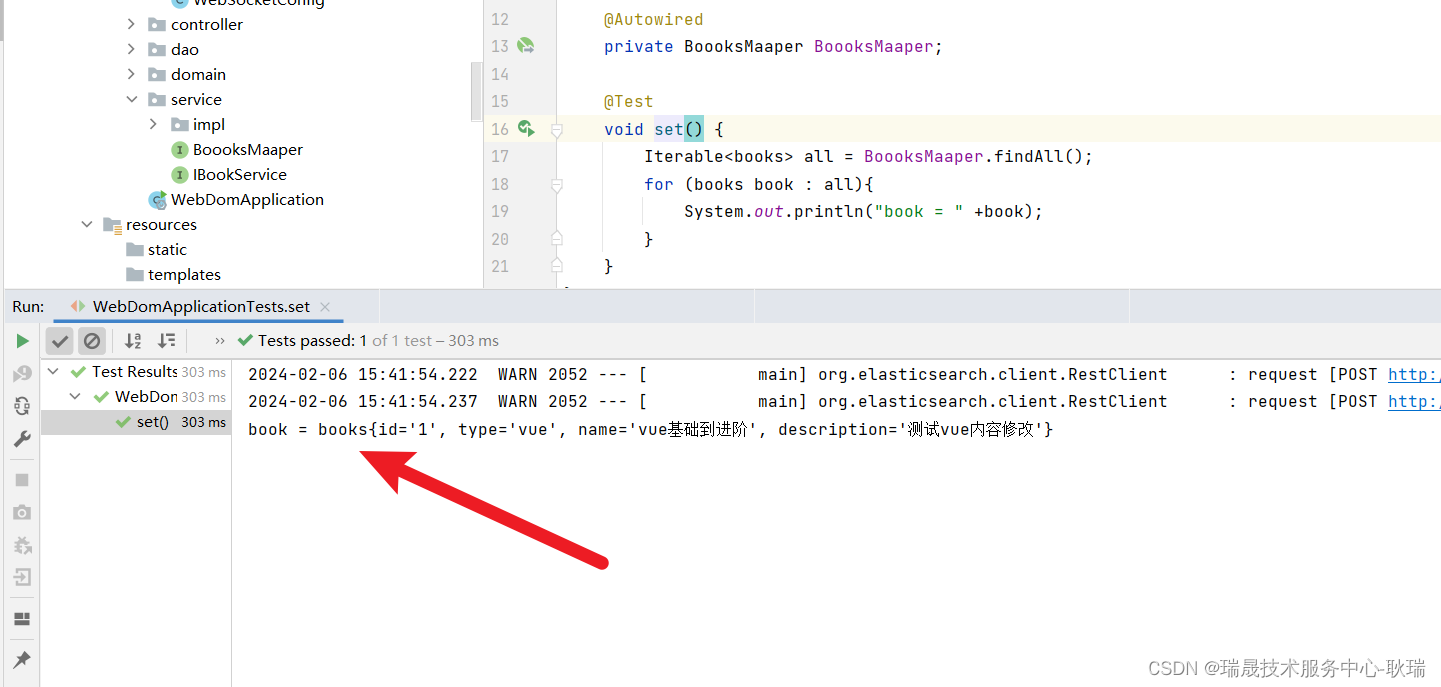
Iterable<books> all = BoooksMaaper.findAll();
for (books book : all){System.out.println("book = " +book);
}
调用 findAll 返回一个 泛型为我们实体类的Iterable接口集合
然后 for遍历这个集合 输出每一次结果
运行代码 因为我们总共就一条数据 所以输出的内容就一条 findAll就是查询全部
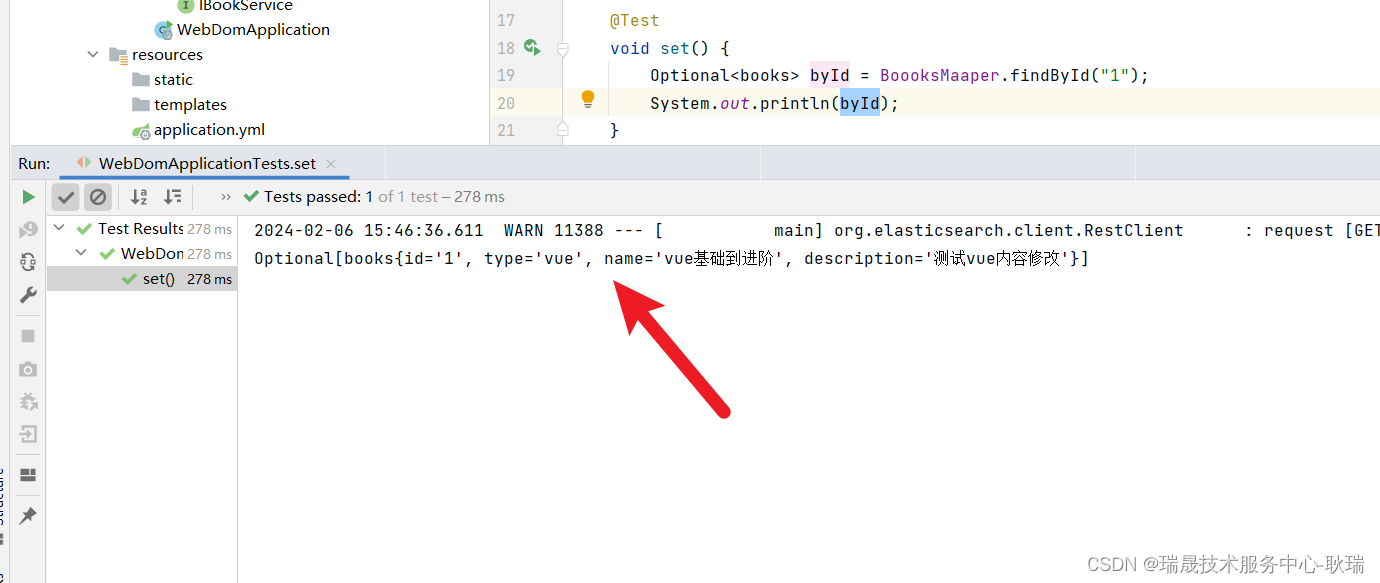
然后 按照id查询 findById
Optional<books> byId = BoooksMaaper.findById("1");
System.out.println(byId);
我们查询id为1的内容 并输出
右键运行代码
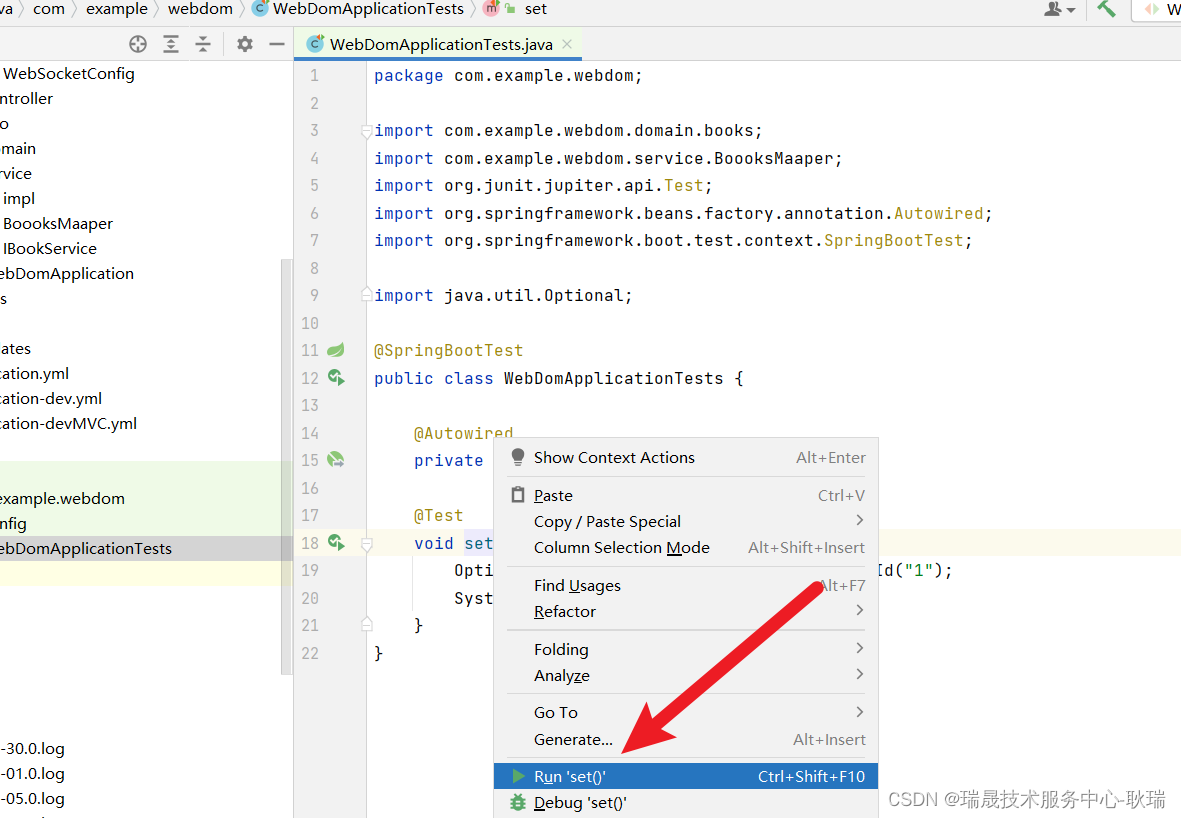
这里 也是顺利查出来了
然后 他有一个比较特殊函数 感觉不是很实用findAllById
它支持传入list数组
可以传给它多个id 然后带出多条数据
ArrayList<String> ids = new ArrayList<>();
ids.add("1");
ids.add("2");
ids.add("3");
ids.add("4");
Iterable<books> byId = BoooksMaaper.findAllById(ids);
查询 id 1 2 3 4的数据 然后形成一个 实体类泛型的 Iterable集合
然后 我们来说自定义的查询方法
我们 可以在自己写的 BoooksMaaper 接口中写一个这样的函数
//自定义 根据name查询
List<books> findByName(String name);
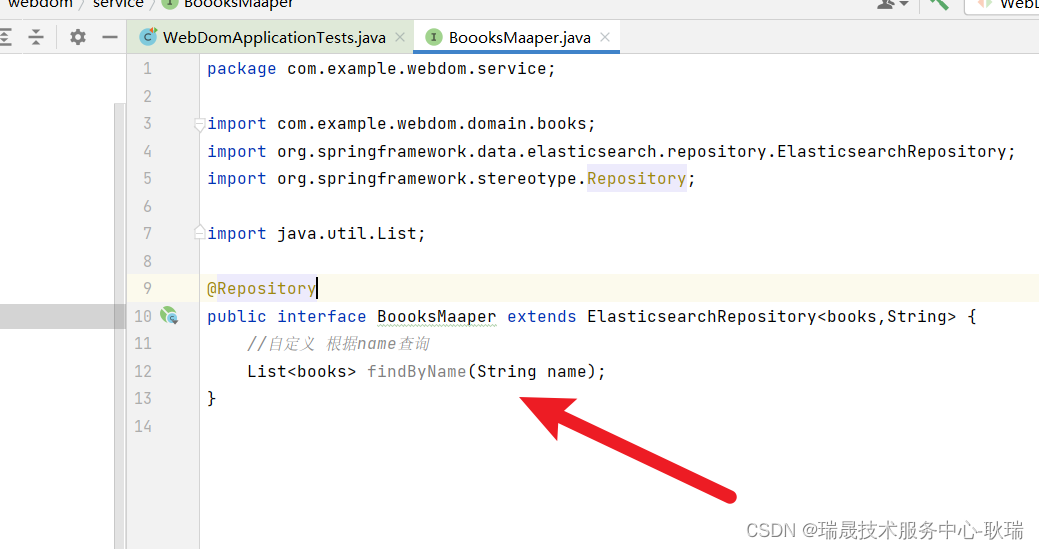
这里需要注意 findBy 后面 跟自己要条件查询的字段名 首字母大写 因为如果你不这样 它是找不到你要查哪个字段的
然后 我们测试类来调用这个函数
List<books> byId = BoooksMaaper.findByName("vue");
System.out.println(byId);
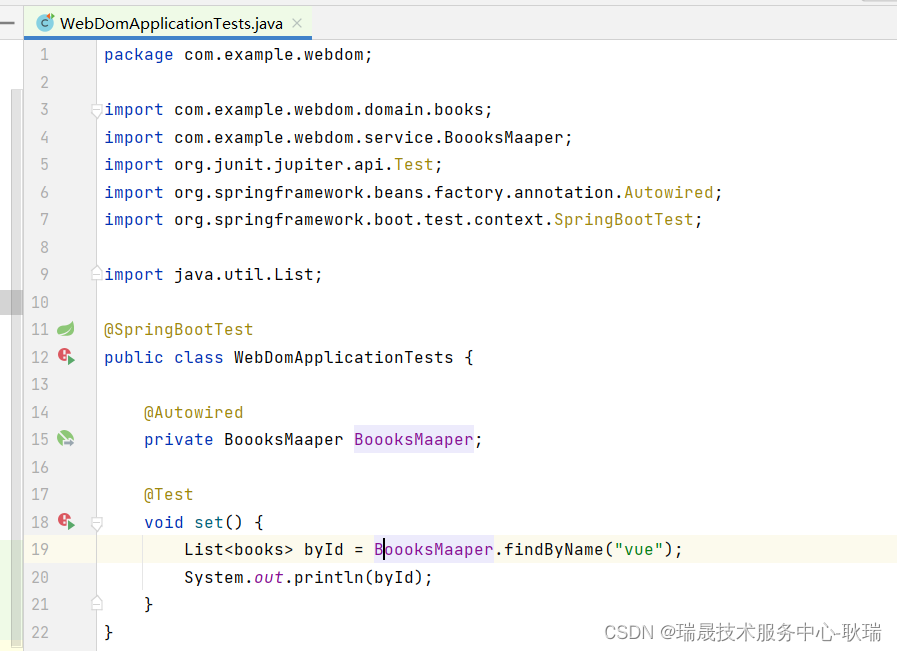
运行代码 这里也顺利通过 vue 模糊查询到了
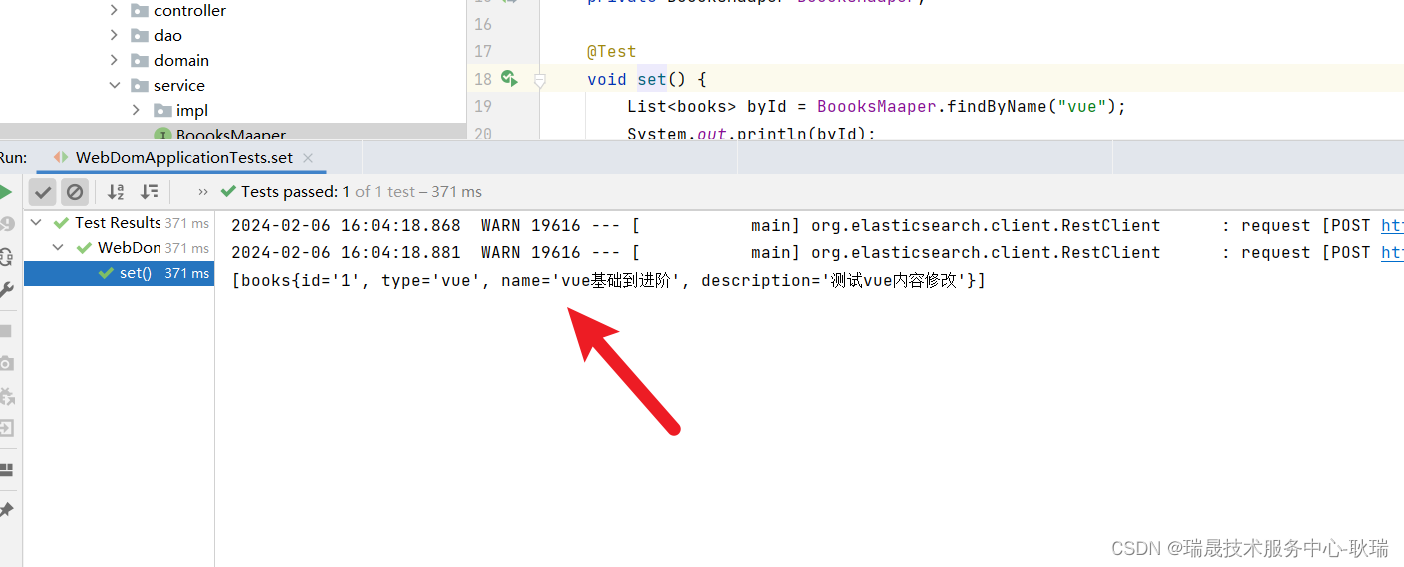
最后删除方法
我们就看个根据id删除吧 deleteById
没有返回值
我们直接写
BoooksMaaper.deleteById("1");
右键运行代码
运行状态是OK的 但是 看不出有没有成功
我们请求查询一下索引下的文档
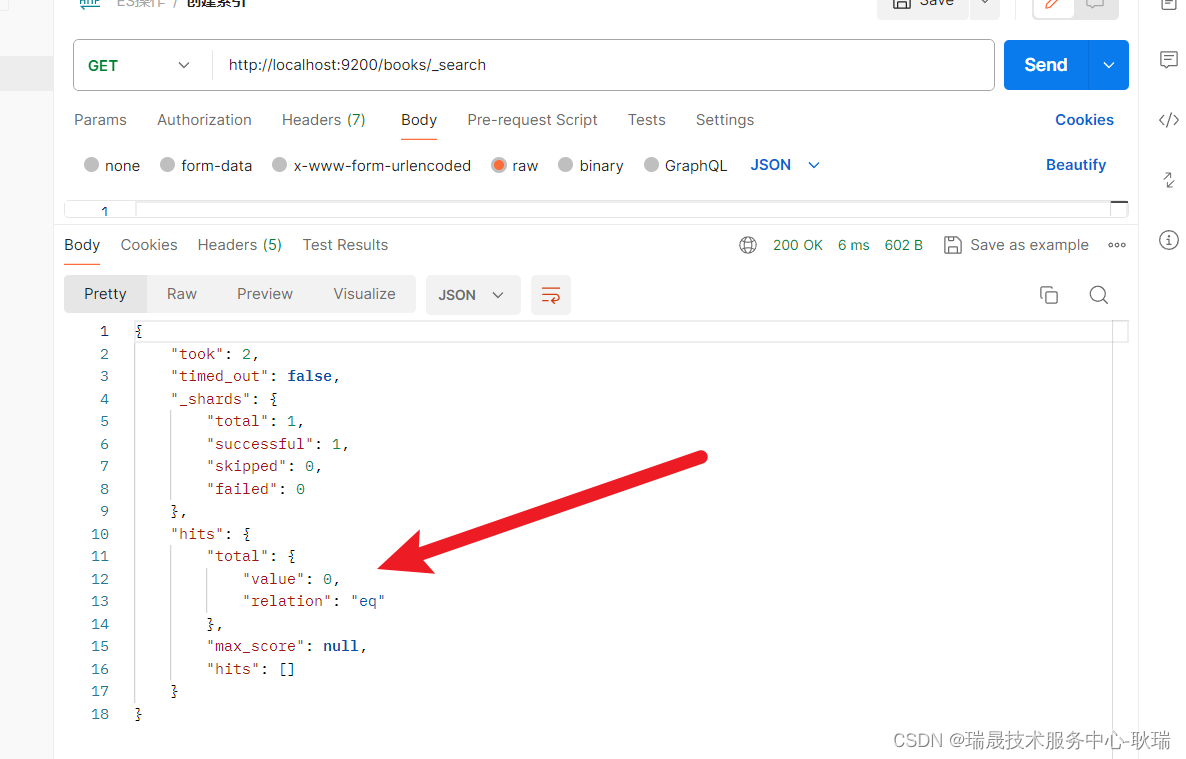
很明显 已经删掉了
相关文章:
java SpringBoot2.7整合Elasticsearch(ES)7 进行文档增删查改
首先 我们在 ES中加一个 books 索引 且带有IK分词器的索引 首先 pom.xml导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>applicatio…...
动态内存管理(2)
文章目录 4. 几个经典的笔试题4.1 题目14.2 题目24.3 题目34.4 题目4 5. C/C程序的内存开辟6. 动态通讯录7. 柔性数组7.1 柔性数组的特点7.2 柔性数组的使用7.3 柔性数组的优势 4. 几个经典的笔试题 4.1 题目1 #include <stdio.h> #include <stdlib.h> #include …...

使用 git 上传文件时,运行 命令 git pull origin 时未成功,出现报错信息
项目场景: 背景: 使用 git 上传文件时,运行 命令 git pull origin 时未成功,出现报错信息 问题描述 问题: $ git pull origin print --allow-unrelated-histories error: Pulling is not possible because you hav…...

Linux文件编译
目录 一、GCC编译 1.直接编译 2.分步编译 预处理: 编译: 汇编: 链接: 3.多文件编译 4.G 二、Make 1.概述 2.使用步骤 3.makefile创建规则 3.1一个基本规则 3.2两个常用函数 4.示例文件 三、GDB 示例:…...

homeword_day1
第一章 命名空间 一.选择题 1、编写C程序一般需经过的几个步骤依次是( B ) A. 编辑、调试、编译、连接 B. 编辑、编译、连接、运行 C. 编译、调试、编辑、连接 D. 编译、编辑、连接、运行 2、所谓数据封装就是将一组数据和与这组数据…...

ChatGPT论文指南|ChatGPT论文写作过程中6个润色与查重提示词
论文完成初稿之后,一般情况下,宝子们还需要找专家给我们提出评审意见。找专家评审其实并不容易,即使对老师来说,找人评审论文也是一件苦活。我们这个时候可以通过文字提示让 ChatGPT充当我们的评审专家,为论文提出问题…...

论文阅读:Learning Lens Blur Fields
这篇文章是对镜头模糊场进行表征学习的研究,镜头的模糊场也就是镜头的 PSF 分布,镜头的 PSF 与物距,焦距,光学系统本身的像差都有关系,实际的 PSF 分布是非常复杂而且数量也很多,这篇文章提出用一个神经网络…...
SpringBoot整合Knife4j接口文档生成工具
一个好的项目,接口文档是非常重要的,除了能帮助前端和后端开发人员更快地协作完成开发任务,接口文档还能用来生成资源权限,对权限访问控制的实现有很大的帮助。 这篇文章介绍一下企业中常用的接口文档工具Knife4j(基于…...
爬虫(三)
1.JS逆向实战破解X-Bogus值 X-Bogus:以DFS开头,总长28位 答案是X-Bogus,因为会把负载里面所有的值打包生成X-Boogus 1.1 找X-Bogus加密位置(请求堆栈) 1.1.1 绝招加高级断点(日志断点) 日志断点看有没有X-B值 日志…...
03 动力云客项目之登录功能后端实现
1 准备工作 1.1 创建项目 使用Spring initializr初始化项目 老师讲的是3.2.0, 但小版本之间问题应该不大. 1.2 项目结构 根据阿里巴巴Java开发手册确定项目结构 1.3 分层领域模型 【参考】分层领域模型规约: • DO(Data Object)&am…...

时光峰峦文物璀璨,预防性保护筑安全
在璀璨的历史长河中,珍贵文物如同时间的印记,承载着过往的辉煌。《人文山水时光峰峦——多彩贵州历史文化展》便是这样一场文化的盛宴,汇聚了众多首次露面的宝藏。然而,文物的保存对环境要求极为苛刻,温湿度波动都可能…...

Redis面试题43
人工智能在未来会有哪些可能的发展趋势? 答:人工智能在未来将继续迎来许多可能的发展趋势,以下是一些可能的方向: 更强大的算法和模型:人工智能算法和模型将不断改进和优化,为更复杂的数据和问题提供更强大…...
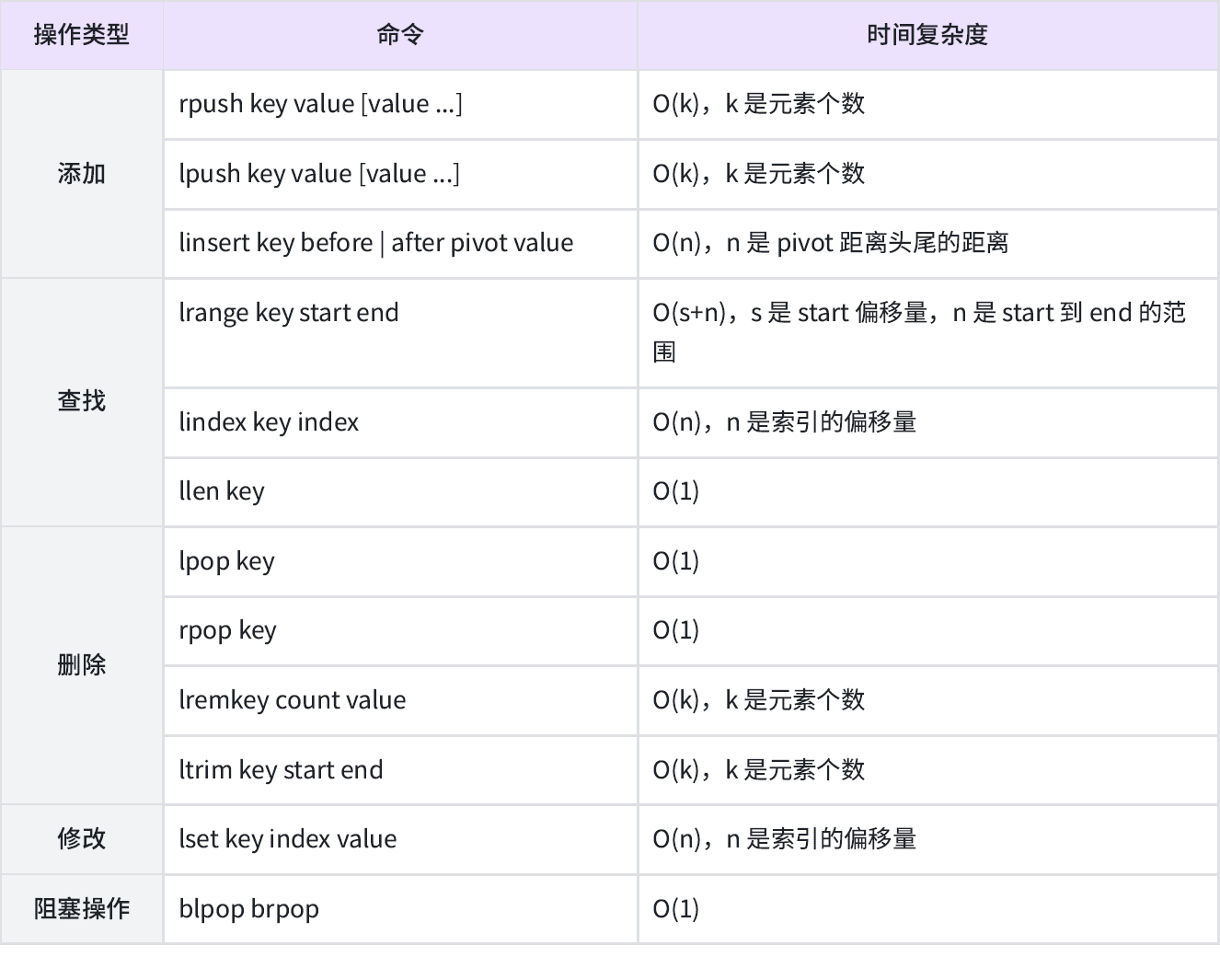
Redis -- list列表
只有克服了情感的波动,才能专心致志地追求事业的成功 目录 列表 list命令 lpush lpushx rpush rpushx lrange lpop rpop lindex linsert llen lrem ltrim 阻塞命令 小结 列表 列表相当于 数组或者顺序表。 列表类型是用来存储多个有序的字符串&…...

【MATLAB】使用梯度提升树在回归预测任务中进行特征选择(深度学习的数据集处理)
1.梯度提升树在神经网络的应用 使用梯度提升树进行特征选择的好处在于可以得到特征的重要性分数,从而识别出对目标变量预测最具影响力的特征。这有助于简化模型并提高其泛化能力,减少过拟合的风险,并且可以加快模型训练和推理速度。此外&…...
神经网络 | 基于多种神经网络模型的轴承故障检测
Hi,大家好,我是半亩花海。本文主要源自《第二届全国技能大赛智能制造工程技术项目比赛试题(样题) 模块 E 工业大数据与人工智能应用》,基于给出的已知轴承状态的振动信号样本,对数据进行分析,建…...
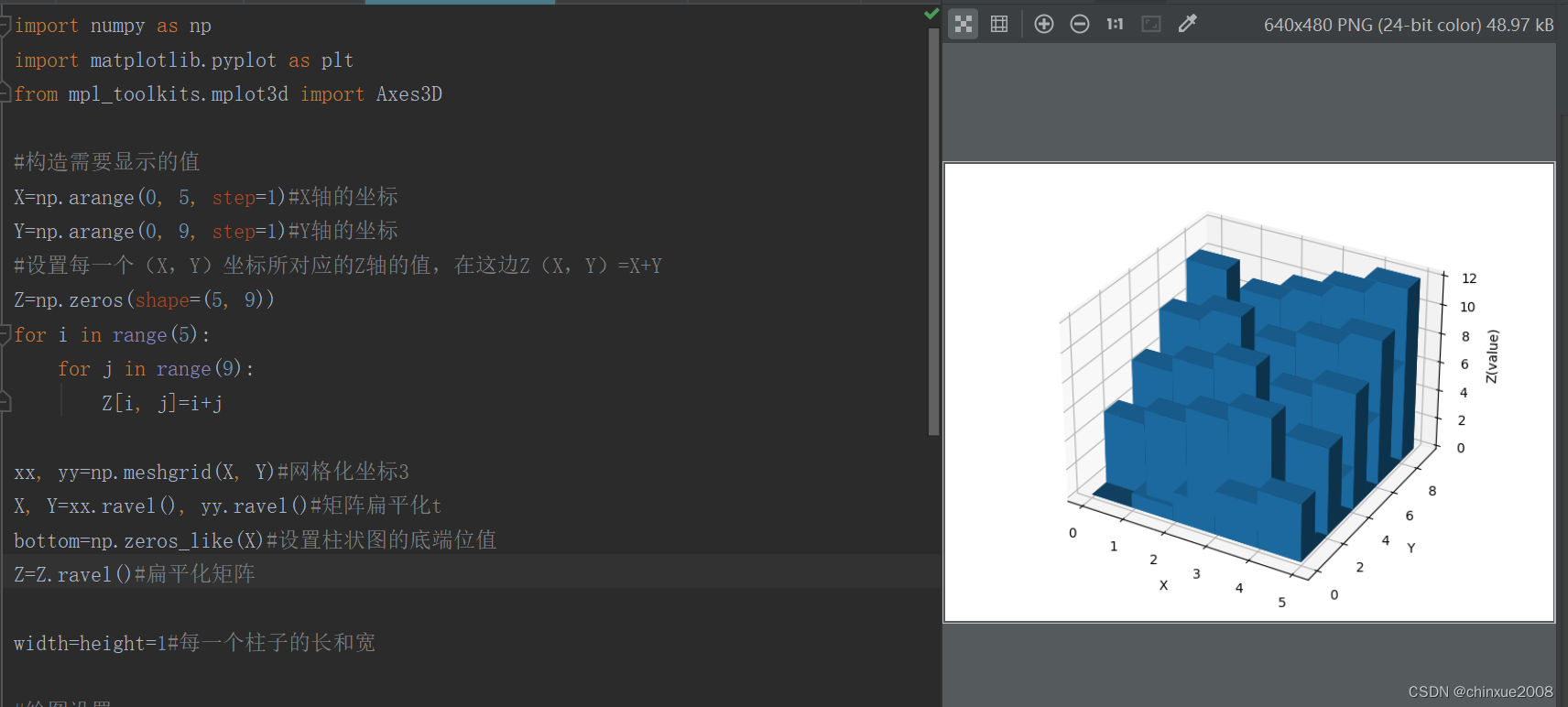
matplot画3D图的时候报错
使用matplot画3D图的时候,报这个错。 ERROR: Could not find a version that satisfies the requirement mpl_toolkits (from versions: none) ERROR: No matching distribution found for mpl_toolkits 要使用升级命令升级matplot而不是安装 pip install --upgr…...

如何使用LNMP让网站顺利工作?
如何使用LNMP让网站顺利工作? 1. Nginx的安装和部署 2. nginxphpmysql 3. nginx php-fpm安装配置 4. Nginx配置性能优化的方法 5. 如何使用Nginx实现限制各种恶意访问...
最新AI系统ChatGPT网站H5系统源码,支持Midjourney绘画局部编辑重绘,GPT语音对话+ChatFile文档对话总结+DALL-E3文生图
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPT…...
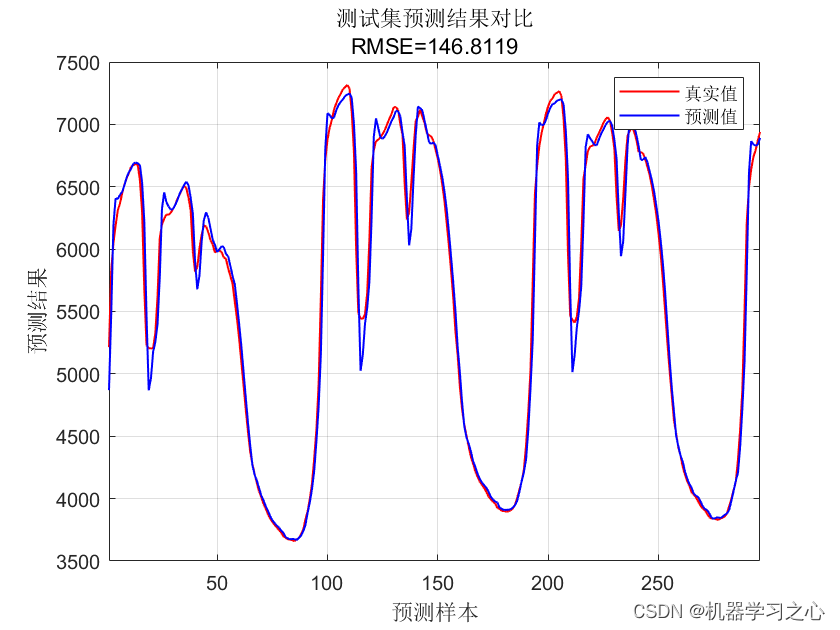
多维时序 | MATLAB实现基于CNN-LSSVM卷积神经网络-最小二乘支持向量机多变量时间序列预测
多维时序 | MATLAB实现基于CNN-LSSVM卷积神经网络-最小二乘支持向量机多变量时间序列预测 目录 多维时序 | MATLAB实现基于CNN-LSSVM卷积神经网络-最小二乘支持向量机多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于CNN-LSSVM卷积神经…...

使用NLTK进行自然语言处理:英文和中文示例
Natural Language Toolkit(NLTK)是一个强大的自然语言处理工具包,提供了许多有用的功能,可用于处理英文和中文文本数据。本文将介绍一些基本的NLTK用法,并提供代码示例,展示如何在英文和中文文本中应用这些…...

终极指南:10个必学Objective-C库助力iOS开发效率翻倍
终极指南:10个必学Objective-C库助力iOS开发效率翻倍 【免费下载链接】TimLiu-iOS iOS开发常用三方库、插件、知名博客等等 项目地址: https://gitcode.com/gh_mirrors/ti/TimLiu-iOS TimLiu-iOS是一个精心整理的iOS开发资源宝库,包含了Objective…...

在Windows系统中快速配置Taotoken的Python调用环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Windows系统中快速配置Taotoken的Python调用环境 对于Windows平台的开发者而言,快速搭建一个能够调用多种大模型的环…...

AI自动化不是接工具就行,得补缺点搭轨道
你有没有过这种经历? 点了一杯定制奶茶,本来想着 “全自动机器做,我啥也不用管,等着拿就行”。 结果呢? 机器煮茶到一半,弹出来问你:“我要开始煮茶了哦,确认一下?” 加珍…...

# 软考软件设计师每日精练 | 2026-04-25
📝 软考软件设计师每日精练 | 2026-04-25📅 距离2026年5月23日软考还有 28天! 今日重点:算法策略辨析 线性规划 知识产权深化 项目管理工具🎯 模块一:算法策略辨析(必考 ★★★★★ÿ…...

Halcon局部阈值分割避坑指南:dyn_threshold与var_threshold到底怎么选?
Halcon局部阈值分割避坑指南:dyn_threshold与var_threshold到底怎么选? 在工业视觉检测中,遇到反光金属表面的划痕识别或明暗不均背景下的轮廓定位时,全局阈值分割往往力不从心。Halcon提供的dyn_threshold和var_threshold两个局部…...

ARM生态产品创新评估:从芯片到系统的技术选型方法论
1. 从一次投票看ARM生态的演进与产品创新逻辑2015年秋天,EE Times上的一则投票通知,可能被很多人当作一次普通的行业活动而滑过。标题很简单——“Vote for Best ARM-Based Product”。但如果你恰好是一位嵌入式开发者、半导体行业的从业者,或…...

终极指南:如何快速掌握Clean Code PHP编码规范提升团队协作效率
终极指南:如何快速掌握Clean Code PHP编码规范提升团队协作效率 【免费下载链接】clean-code-php :bathtub: Clean Code concepts adapted for PHP 项目地址: https://gitcode.com/gh_mirrors/cl/clean-code-php 在PHP开发中,编写清晰、可维护的代…...
常见问题)
使用S32 Design Studio(S32DS)常见问题
S32DS常见问题如下:1. 编译器找不到ld文件工程路径不能有中文字符2. 编译器找不到make文件鼠标右键点击工程,在弹出菜单中点击 “Properties” 按钮,弹出属性对话框,点击 Tool Settings 选项卡,在左侧树状框中点击 C/C…...

控制面容灾实战:别让“不处理业务请求“的系统拖死全站
控制面容灾实战:别让"不处理业务请求"的系统拖死全站 前言 控制面是分布式系统里最隐蔽也最致命的单点故障源。 注册中心、配置中心、证书系统、观测后端,这些系统看似"不处理任何业务请求",但一旦不可用,…...

为什么83%的企业在2025年底紧急替换AI Agent?2026年必须升级的4个底层能力清单
更多请点击: https://intelliparadigm.com 第一章:为什么83%的企业在2025年底紧急替换AI Agent?2026年必须升级的4个底层能力清单 2025年Q3起,全球头部金融、制造与医疗企业集中触发AI Agent架构重构——Gartner最新调研显示&…...