强化学习 | 基于 Q-Learning 算法解决 Treasure on Right 游戏
Hi,大家好,我是半亩花海。在本篇技术博客中,我们将探讨如何使用 Q-Learning 算法来解决 Treasure on Right 游戏,实现一个简单的强化学习。
一、游戏背景
Treasure on Right 游戏——一个简单的命令行寻宝游戏,是一个经典的强化学习示例,它模拟了一个智能体在有限状态空间中寻找宝藏的过程。游戏环境由一个线性状态空间组成,智能体可以执行两个动作:向左移动或向右移动。目标是让智能体学会在状态空间中移动,找到宝藏,它位于状态空间的最右侧。
二、Q-Learning 算法简介
Q-Learning 是一种基于值函数的强化学习算法,用于解决智能体与环境交互的问题。它通过迭代更新状态-动作对的 Q 值来优化策略。Q 值表示在特定状态下采取特定动作的长期回报,智能体通过学习最优的 Q 值来选择最佳动作。
三、代码拆解
1. 导入必要的库
首先导入 pandas、numpy 和 time 库,以便进行数据处理、数组操作和控制程序运行时间。
import pandas as pd
import numpy as np
import time
2. 定义常量和参数
在这个部分,我们定义了游戏中所需的常量和参数,包括状态数量、动作集合、epsilon 贪婪度、学习率、奖励衰减因子等。
N_STATES = 6 # 状态数量
ACTIONS = ["left", "right"] # 动作集合
EPSILON = 0.9 # epsilon-greedy算法中的贪婪度
ALPHA = 0.1 # 学习率
GAMMA = 0.9 # 奖励衰减因子
MAX_EPISODES = 15 # 最大训练轮数
FRESH_TIME = 0.3 # 每一步的时间间隔
TerminalFlag = "terminal" # 终止状态标识
3. 创建Q表
我们定义了一个函数来创建 Q 表格,用于存储状态-动作对的 Q 值。初始时,所有的 Q 值都被初始化为 0。
def build_q_table(n_states, actions):return pd.DataFrame( np.zeros((n_states, len(actions))), columns=actions )
4. 选择动作
这个函数根据当前状态和 Q 表格选择动作。我们使用 ε-greedy 策略,以一定的概率随机选择动作,以便在探索和利用之间取得平衡。
def choose_action(state, q_table):state_table = q_table.loc[state, :]if (np.random.uniform() > EPSILON) or ((state_table == 0).all()):action_name = np.random.choice(ACTIONS)else:action_name = state_table.idxmax()return action_name
5. 获取环境反馈
这个函数模拟了智能体与环境的交互过程,根据智能体采取的动作返回下一个状态和相应的奖励。
def get_env_feedback(S, A):if A == "right":if S == N_STATES - 2:S_, R = TerminalFlag, 1else:S_, R = S + 1, 0else:S_, R = max(0, S - 1), 0return S_, R
6. 更新环境
这个函数用于更新环境的显示,以便智能体能够观察到当前状态。
def update_env(S, episode, step_counter):env_list = ["-"] * (N_STATES - 1) + ["T"] if S == TerminalFlag: interaction = 'Episode %s: total_steps = %s' % (episode + 1, step_counter) print(interaction) time.sleep(2) else: env_list[S] = '0' interaction = ''.join(env_list) print(interaction) time.sleep(FRESH_TIME)
7. Q-learning主循环
这个函数包含了整个Q-learning的主要逻辑,包括选择动作、获取环境反馈和更新Q值等步骤。
def rl():q_table = build_q_table(N_STATES, ACTIONS)for episode in range(MAX_EPISODES): step_counter = 0S = 0is_terminated = Falseupdate_env(S, episode, step_counter) while not is_terminated: A = choose_action(S, q_table) S_, R = get_env_feedback(S, A) q_predict = q_table.loc[S, A] if S_ != TerminalFlag: q_target = R + GAMMA * q_table.loc[S_, :].max() else: q_target = R is_terminated = True q_table.loc[S, A] += ALPHA * (q_target - q_predict) S = S_ update_env(S, episode, step_counter + 1) step_counter += 1 return q_table
8. 主程序入口
在这部分代码中,我们运行整个程序,执行Q-learning算法并输出最终的Q表格。
if __name__ == '__main__':q_table = rl() print(q_table)
四、项目意义和应用价值
Treasure on Right 游戏作为一个简单的强化学习示例,展示了 Q-Learning 算法在解决智能体与环境交互问题中的应用。通过实现这个项目,我们可以深入理解强化学习算法的工作原理,并了解如何利用这种算法解决实际问题。Q-Learning 算法及其变体在许多领域都有广泛的应用,如机器人控制、自动驾驶、游戏设计等。通过掌握这种算法,我们可以为各种应用场景开发智能决策系统,从而提高效率、优化资源利用,甚至解决复杂的实时决策问题。
在学术界和工业界,Q-Learning 算法已经被广泛应用,并且不断被改进和扩展,以解决更加复杂的问题。因此,掌握 Q-Learning 算法对于从事人工智能和机器学习领域的工程师和研究人员来说是非常重要的。
五、完整代码
# 使用Q-Learning算法来实现treasure on right游戏(宝藏在最右边的位置:训练一个智能体去获得这个宝藏)
import pandas as pd
import numpy as np
import timeN_STATES = 6 # 状态数量
ACTIONS = ["left", "right"] # 动作集合
EPSILON = 0.9 # epsilon-greedy算法中的贪婪度
ALPHA = 0.1 # 学习率
GAMMA = 0.9 # 奖励衰减因子
MAX_EPISODES = 15 # 最大训练轮数
FRESH_TIME = 0.3 # 每一步的时间间隔
TerminalFlag = "terminal" # 终止状态标识# 创建Q表
def build_q_table(n_states, actions):return pd.DataFrame( # 创建一个DataFrame对象np.zeros((n_states, len(actions))), # 用0初始化一个n_states行,len(actions)列的数组columns=actions # 设置DataFrame的列名为动作列表)# 根据当前状态选择动作
def choose_action(state, q_table):state_table = q_table.loc[state, :] # 获取Q表中对应状态行的值if (np.random.uniform() > EPSILON) or ((state_table == 0).all()): # 判断是否随机选择动作action_name = np.random.choice(ACTIONS) # 如果满足条件,随机选择一个动作else:action_name = state_table.idxmax() # 否则选择具有最大值的动作return action_name # 返回选择的动作# 获取环境的反馈,包括下一个状态和奖励
def get_env_feedback(S, A):if A == "right": # 如果动作是向右移动if S == N_STATES - 2: # 如果当前状态是倒数第二个状态S_, R = TerminalFlag, 1 # 下一个状态是终止状态,奖励为1else: # 否则S_, R = S + 1, 0 # 下一个状态向右移动一步,奖励为0else: # 如果动作不是向右移动S_, R = max(0, S - 1), 0 # 下一个状态向左移动一步,奖励为0return S_, R # 返回下一个状态和奖励# 更新环境
def update_env(S, episode, step_counter):env_list = ["-"] * (N_STATES - 1) + ["T"] # 创建一个环境列表,长度为N_STATES-1,最后一个元素为终止标志"T"if S == TerminalFlag: # 如果当前状态为终止状态interaction = 'Episode %s: total_steps = %s' % (episode + 1, step_counter) # 打印本次训练的步数print(interaction) # 打印信息time.sleep(2) # 等待2秒else: # 如果当前状态不是终止状态env_list[S] = '0' # 在环境列表中将当前状态位置标记为'0'interaction = ''.join(env_list) # 将环境列表转换为字符串print(interaction) # 打印环境状态time.sleep(FRESH_TIME) # 等待一段时间# Q-learning主循环
def rl():# 创建Q表: 存储的表记录的是, 在状态S下, 每个行为A的Q值q_table = build_q_table(N_STATES, ACTIONS)for episode in range(MAX_EPISODES): # 对于每一轮训练(episode)step_counter = 0 # 记录每个episode的步数S = 0 # 初始状态is_terminated = False # 用于判断是否到达终止状态update_env(S, episode, step_counter) # 更新环境显示# 在未到达终止状态的情况下进行循环while not is_terminated: # 如果未到达终止状态A = choose_action(S, q_table) # 选择动作S_, R = get_env_feedback(S, A) # 获取环境反馈(下一个状态和奖励)q_predict = q_table.loc[S, A] # 获取Q值的预测值# 根据下一个状态是否为终止状态更新Q值的目标值if S_ != TerminalFlag: # 如果下一个状态不是终止状态q_target = R + GAMMA * q_table.loc[S_, :].max() # 使用贝尔曼方程计算目标Q值else: # 如果下一个状态是终止状态q_target = R # 目标Q值为即时奖励is_terminated = True # 到达终止状态q_table.loc[S, A] += ALPHA * (q_target - q_predict) # 使用Q-learning更新Q表S = S_ # 更新当前状态update_env(S, episode, step_counter + 1) # 更新环境显示step_counter += 1 # 步数加1return q_tableif __name__ == '__main__':q_table = rl() # 运行Q-learning算法print(q_table) # 打印Q表相关文章:

强化学习 | 基于 Q-Learning 算法解决 Treasure on Right 游戏
Hi,大家好,我是半亩花海。在本篇技术博客中,我们将探讨如何使用 Q-Learning 算法来解决 Treasure on Right 游戏,实现一个简单的强化学习。 一、游戏背景 Treasure on Right 游戏——一个简单的命令行寻宝游戏,是一个…...
计算机网络-无线通信技术与原理
一般我们网络工程师接触比较多的是交换机、路由器,很少涉及到WiFi和无线设置,但是呢在实际工作中一般企业也是有这些需求的,这就需要我们对于无线的一些基本配置也要有独立部署能力,今天来简单了解一下。 一、无线网络基础 1.1 无…...
机器学习 | 揭示EM算法和马尔可夫链的实际应用
目录 初识EM算法 马尔可夫链 HMM模型基础 HMM模型使用 初识EM算法 EM算法是一种求解含有隐变量的概率模型参数的迭代算法。该算法通过交替进行两个步骤:E步骤和M步骤,从而不断逼近模型的最优参数值。EM算法也称期望最大化算法,它是一个基…...

回归预测 | Matlab实现POA-BP鹈鹕算法优化BP神经网络多变量回归预测
回归预测 | Matlab实现POA-BP鹈鹕算法优化BP神经网络多变量回归预测 目录 回归预测 | Matlab实现POA-BP鹈鹕算法优化BP神经网络多变量回归预测预测效果基本描述程序设计参考资料 预测效果 基本描述 1.Matlab实现POA-BP鹈鹕算法优化BP神经网络多变量回归预测(完整源码…...
基于java+springboot+vue实现的房屋租赁管理系统(文末源码+Lw)23-142
第1章 绪论 房屋租赁管理系统管理系统按照操作主体分为管理员和用户。管理员的功能包括报修管理、字典管理、租房房源管理、租房评价管理、房源租赁管理、租房预约管理、论坛管理、公告管理、投诉建议管理、用户管理、租房合同管理、管理员管理。用户的功能等。该系统采用了My…...
ubuntu20安装mongodb
方法一:直接安装(命令是直接从mongo官网Install MongoDB Community Edition on Ubuntu — MongoDB Manual复制的) cat /etc/lsb-release sudo apt-get install -y gnupg curl curl -fsSL https://www.mongodb.org/static/pgp/server-7.0.asc | \sudo gp…...

java面试题:MySQL中的各种JOIN的区别
表关联是频率非常高的一种数据库操作,在MySQL中,这种JOIN操作有很多类型,包括内联接、左外连接、右外连接等等,而每种连接的含义都不一样,如果死记硬背,不仅很难记住,而且也容易搞混淆ÿ…...
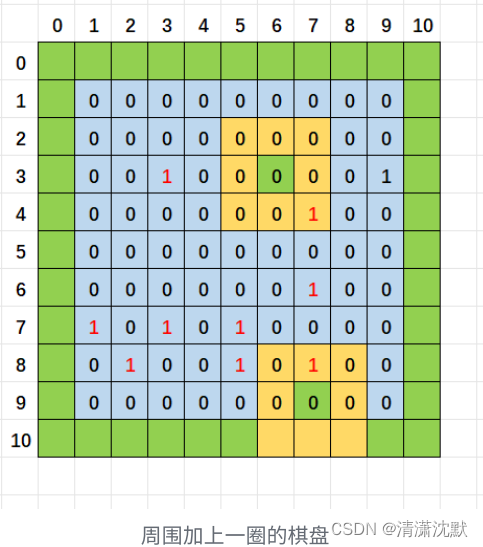
C语言数组与扫雷游戏实现(详解)
扫雷游戏的功能说明 使⽤控制台实现经典的扫雷游戏游戏可以通过菜单实现继续玩或者退出游戏扫雷的棋盘是9*9的格子默认随机布置10个雷可以排查雷 ◦ 如果位置不是雷,就显示周围有几个雷 ◦ 如果位置是雷,就炸死游戏结束 ◦ 把除10个雷之外的所有雷都找出来,排雷成功,游戏结…...

C#调用WechatOCR.exe实现本地OCR文字识别
最近遇到一个需求:有大量的扫描件需要还原为可编辑的文本,很显然需要用到图片OCR识别为文字技术。本来以为这个技术很普遍的,结果用了几个开源库,效果不理想。后来,用了取巧的方法,直接使用了WX的OCR识别模…...

ComfyUI 学习笔记
目录 ComfyUI 入门教程 什么是ComfyUI? windows安装教程: 组件技巧学习 ComfyUI 入门教程 老V带你学comfyUI-基础入门 - 知乎 什么是ComfyUI? ComfyUI 是一个基于节点的 GUI,用于Stable Diffusion。你可以通过将不同的no…...

基于Linux的HTTP代理服务器搭建与配置实战
在数字化世界中,HTTP代理服务器扮演着至关重要的角色,它们能够帮助我们管理网络请求、提高访问速度,甚至在某些情况下还能保护我们的隐私。而Linux系统,凭借其强大的功能和灵活性,成为了搭建HTTP代理服务器的理想选择。…...
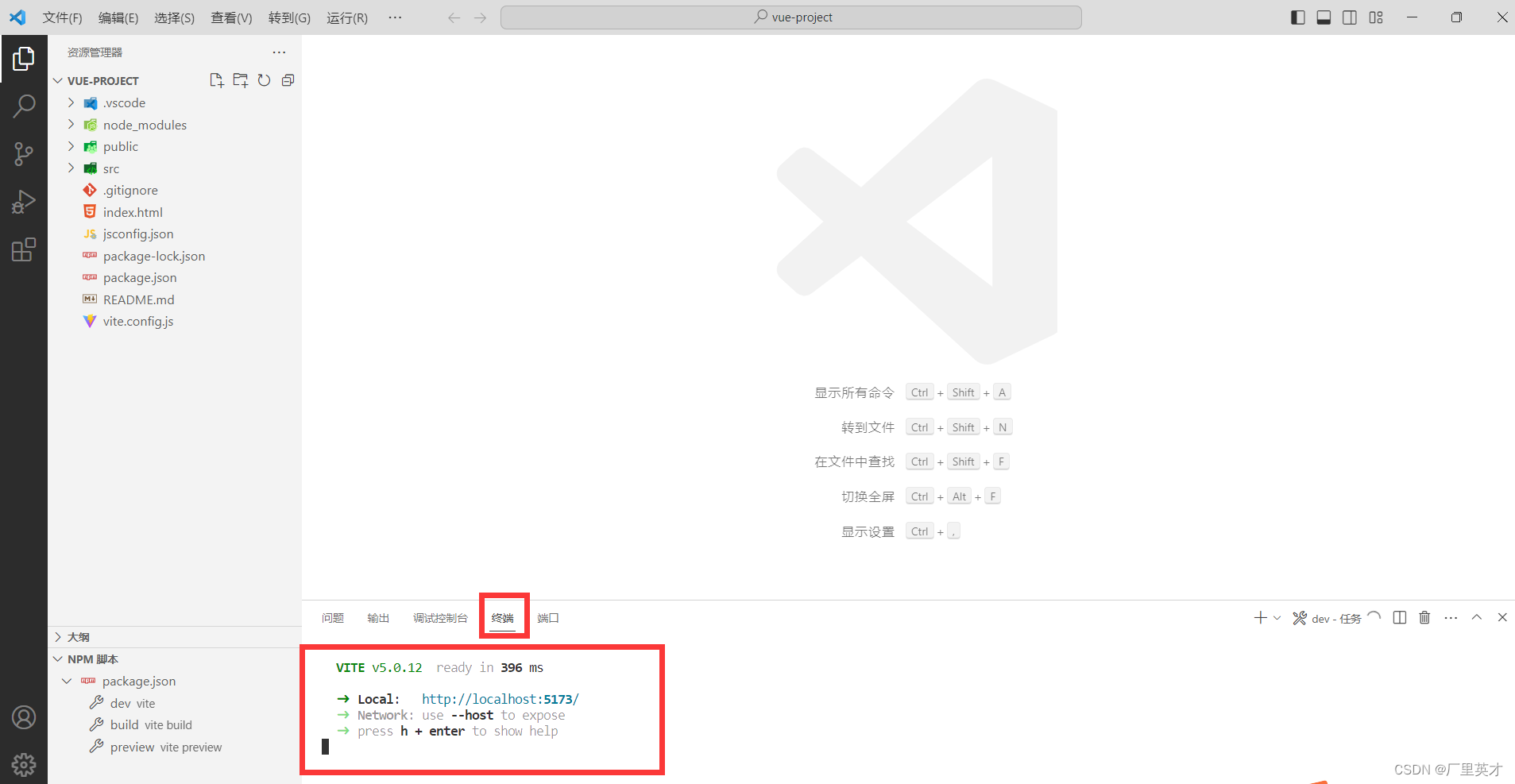
创建一个Vue项目(含npm install卡住不动的解决)
目录 1 安装Node.js 2 使用命令提示符窗口创建Vue 2.1 打开命令提示符窗口 2.2 初始Vue项目 2.2.1 npm init vuelatest 2.2.2 npm install 3 运行Vue项目 3.1 命令提示符窗口 3.2 VSCode运行项目 1 安装Node.js 可以看我的这篇文章《Node.js的安装》 2 使用命令提示…...

npm_config_xxx
// package.json{ "scripts": { "log": "node index.js", } }// index.js function logProcessEnv(key){ console.log(process.env[${key}], process.env[key]); } logProcessEnv(npm_config_foo); 问题: npm run log 和 yarn log…...

P8756 [蓝桥杯 2021 省 AB2] 国际象棋 状压dp统计情况数的一些小理解
目录 建议有状压基础再食用:本题的状态转移方程是 dp代码片:参考代码 建议有状压基础再食用: n行m列 等价 n列m行 ,因为n比较小,int是32位足够了,我们用比特位统计每一行的状态。 本题的状态转移方程是 dp[h][i][j]…...
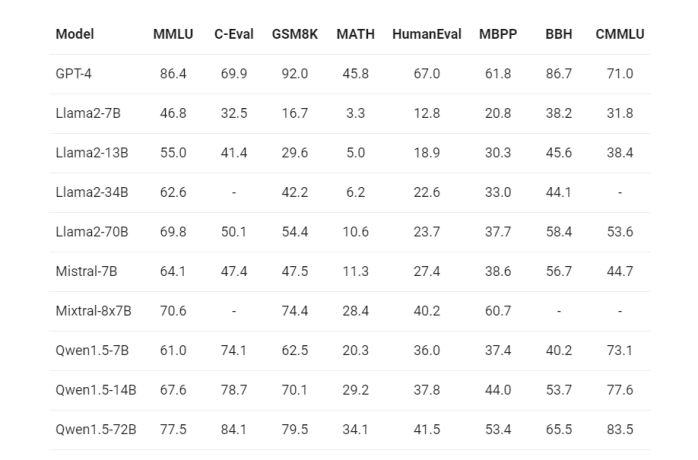
春节放大招,阿里通义千问Qwen1.5开源发布
2月6日阿里发布了通义千问1.5版本,包含6个大小的模型,“Qwen” 指的是基础语言模型,而 “Qwen-Chat” 则指的是通过后训练技术如SFT(有监督微调)和RLHF(强化学习人类反馈)训练的聊天模型。 模型…...
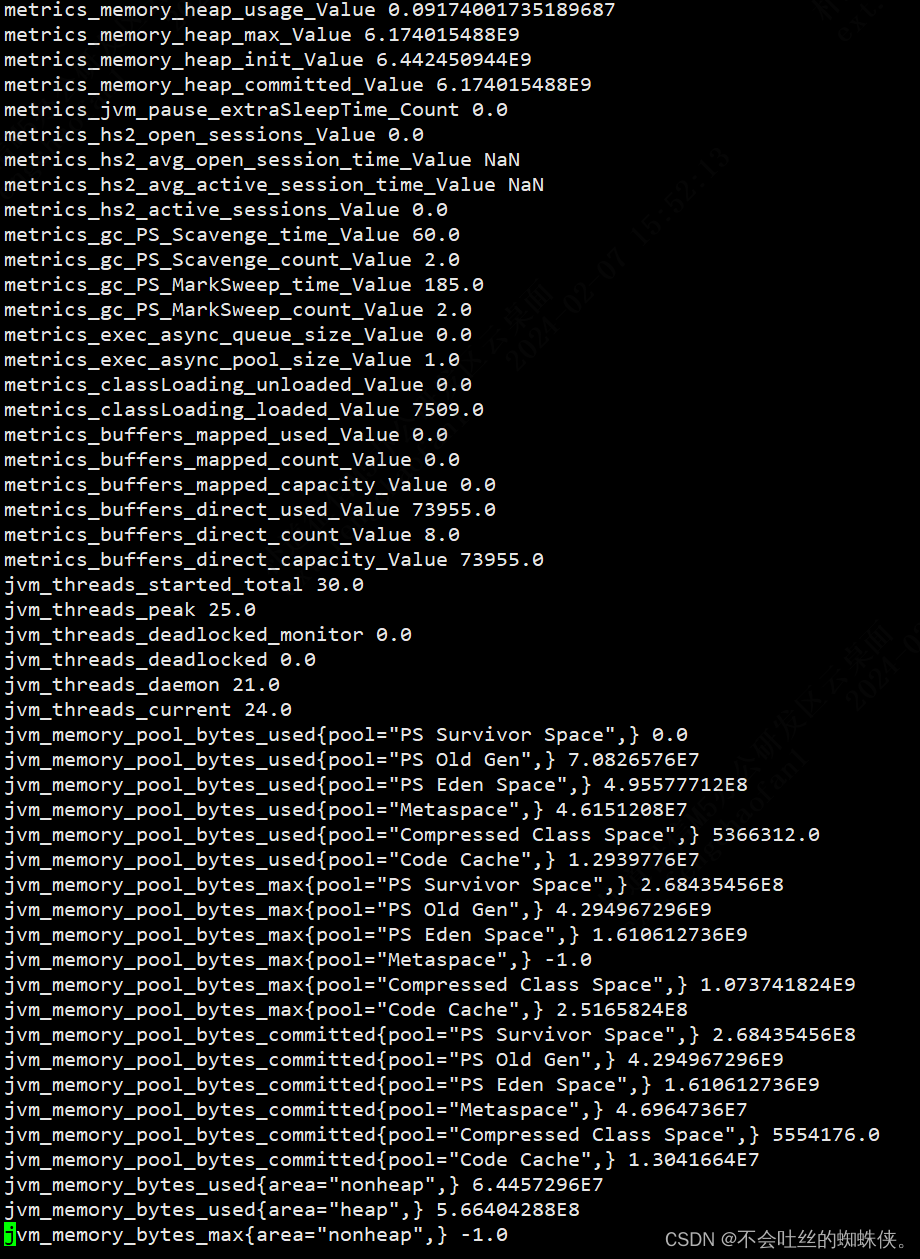
grafana+prometheus+hiveserver2(jmx_exporter+metrics)
一、hiveserver2开启metrics,并启动jmx_exporter 1、修改hive-site.xml文件开启metrics <property><name>hive.server2.metrics.enabled</name><value>true</value> </property> <property><name>hive.service.m…...

Redis系列——Lua脚本和redis事务的应用
介绍 Lua脚本 背景 Redis是一种抽象数据类型的特定领域语言,由各种命令组成。大多数命令专门用于操作不通的数据类型。每次发送命令均需要执行至此网络请求。所以Redis提供了一个编程接口,支持服务器执行用户自定义的任意脚本。有助于减少网络流量&am…...

rtt设备驱动框架面向对象学习-i2c总线
本来想着i2c和spi是一样的,标题都想抄袭成《rtt设备驱动框架学习-i2c总线和设备》,然后看过源码发现,i2c没有分开总线和设备,我想着正常它和spi一样有总线和设备,设备存在竞争。估计是因为i2c设备可以通过i2c地址区分&…...

Golang 基础 Go Modules包管理
Golang 基础 Go Modules包管理 在 Go 项目开发中,依赖包管理是一个非常重要的内容,依赖包处理不好,就会导致编译失败,本文将系统介绍下 Go 的依赖包管理工具。 我会首先介绍下 Go 依赖包管理工具的历史,并详细介绍下…...
)
图数据库 之 Neo4j - 背景介绍(1)
引言 Neo4j是一种高性能的图数据库,它专门设计用于存储、管理和查询大规模的图数据。与传统的关系型数据库不同,Neo4j以图的形式存储数据,其中节点表示实体,边表示实体之间的关系。这种图数据模型非常适合表示复杂的关系和连接。…...

从零到一:Windows环境下Oracle19c的完整部署与实战配置
1. 环境准备:搭建Oracle19c的Windows温床 第一次在Windows上装Oracle数据库就像给新房子铺水电——基础没打好,后面全是坑。我见过太多人因为忽略环境检查,导致安装到一半报错重来的惨剧。这里分享几个实测有效的准备工作: 硬件配…...

收藏!普通人零基础转行AI,3-5个月实现高薪就业的进阶指南
本文指出AI行业对非计算机专业人才的需求激增,半路转行者因具备行业经验而更具竞争力。文章澄清了转行AI的常见误区,强调“技术懂业务”是关键,并提供了普通人转行AI的3步走策略:选择AI算法、自然语言或应用工程师等低门槛岗位&am…...

如何在5分钟内配置鸣潮自动化助手,实现多账号高效管理?
如何在5分钟内配置鸣潮自动化助手,实现多账号高效管理? 【免费下载链接】better-wuthering-waves 🌊更好的鸣潮 - 后台自动剧情 项目地址: https://gitcode.com/gh_mirrors/be/better-wuthering-waves 厌倦了《鸣潮》中重复的剧情对话…...

机器学习在芯片电容提取中的应用与CapBench数据集
1. 电容提取与机器学习结合的背景与挑战在芯片设计流程中,电容提取是决定最终产品性能的关键环节。当设计进入物理实现阶段,工程师需要精确计算互连线之间的寄生电容,这些数据直接影响时序分析和功耗估算的准确性。传统基于场求解器的方法&am…...

如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧
如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经遇到过想要查看Godot游戏内部资源却无从下手的困境?那些神秘…...

跨设备代码同步工具cursor-sync:设计原理与工程实践指南
1. 项目概述:一个为开发者设计的代码同步工具如果你和我一样,经常在多个设备上切换着写代码——比如在公司用台式机,回家用笔记本,甚至偶尔在平板上改几行——那你一定对“代码同步”这个痛点深有体会。手动复制粘贴、用U盘倒腾、…...

模拟ASIC设计:核心技术与工程实践解析
1. 模拟ASIC设计概述模拟ASIC(专用集成电路)作为电子系统的重要组成部分,与数字ASIC相比有着独特的设计挑战和技术特点。在过去的45年里,从Hans Camenzind发明的NE555定时器开始,模拟ASIC已经发展成为现代电子设备不可…...

2026 年 TanStack npm 供应链遭入侵:42 个包 84 版本受影响,多方面待解决问题待明确
总结2026 年 5 月 11 日 19:20 至 19:26 UTC 期间,攻击者通过结合“Pwn Request”模式的 pull_request_target、跨越分叉↔主库信任边界的 GitHub Actions 缓存投毒,以及从 GitHub Actions 运行器进程中提取 OIDC 令牌,在 42 个 tanstack/* n…...

【统计推断实战】从置信区间到假设检验:如何用数据做出可靠决策
1. 从产品迭代案例看统计推断的价值 最近团队上线了一个新功能,产品经理信心满满地宣称能提升15%的用户留存率。但上线一周后数据波动很大,有人觉得效果明显,有人却说毫无变化。这时候该信谁的?其实这就是统计推断大显身手的时刻—…...

从零搭建机器人抓取系统:OpenClaw工作坊实践指南
1. 项目概述:一个为初学者打开机器人抓取大门的实践工作坊如果你对机器人技术,特别是让机械臂“学会”抓取物体这件事充满好奇,但又觉得它高深莫测、无从下手,那么jelmerdejong/openclaw-beginners-workshop这个项目就是为你量身打…...