【推荐算法】userid是否需要建模
看到一个din的源码,将userid也构建了emb table。
于是调研了一下。即推荐算法需要建模userid吗?
深度学习推荐算法中user-id和item-id是否需要放入模型中作为特征进行训练呢?
深度学习推荐算法中user-id和item-id是否需要放入模型中作为特征进行训练呢? - 知乎
回答1:
- 大厂会将user id / item id作为特征加入推荐模型,因为他们的数据足够多,算力足够强。
- 大厂的APP的资深用户的行为足够将他们的user id embedding训练出来。
- 大厂APP的热门物料会曝光十几万、甚至几十万次,这么多日志足够将这些item id embedding充分训练出来。
- 如果小厂的推荐模型就不建议使用这些id当embedding了,数据不够,你加进去也学习不出来。
另外这些特征加入模型的位置也非常重要,否则也会被淹没在其他特征中,泯然众人矣。
回答2:
user_id和item_id作为强记忆型特征,是否要放入模型中作为特征进行训练是不能一概而论的。至少需要考虑业务场景的特点、如何放到模型中两个因素。
一般情况下在真实的业务场景中,无论是用户行为还是物品受欢迎程度都呈现长尾分布,少数头部的user和item占据了样本中的绝大多数,他们的id embedding能够得到充分的学习;另一方面,大量的尾部user和item的在样本中出现的频率很低,因而他们的id embedding在模型训练结束后也没有经过几次参数更新,基本上比随机初始化的状态好不了多少。默认情况下,推荐算法都是对中长尾的user和item(比如冷启动用户、新加入的物品)不友好的。
user_id和item_id作为特征直接加入到模型中,基于长尾分布的用户行为日志训练的推荐模型会越来越偏好头部物品,在导致“富者越富”的同时伤害中长尾物品的曝光机会和用户满意度。
通过分析精排模型的特征重要度,我们发现重要度较高的特征主要集中在少量的“记忆性”特征上,而大量的中长尾特征的重要度都很低。“记忆性”特征指的是没有泛化能力的特征,如用户ID、物品ID、用户对物品ID在过去一段时间上的行为统计,在这些特征上无法学到能够迁移到其他物品的知识。常规的模型结构会产生特征重要度的长尾分布,最终带来了模型偏好物品的长尾分布。
总的来说长尾分布越严重的场景越不建议直接加入user_id和item_id作为特征(也不是绝对的,可以加到特殊的模型结构中,参考下文)。当然这里的长尾分布是按照user和item分开看的,确实存在一些业务场景在user这个维度长尾分布很严重,但在item这个维度长尾分布并不突出,这种情况下是可以把item_id作为特征直接丢给模型学习的。
具体来说:
- 物品池大小适中且基本保持稳定的场景建议加item_id特征;
- 物品池频繁汰换的场景不建议加item_id特征;
- 新用户占比很高的场景不建议加user_id特征;
- 小流量场景不建议加user_id特征;
- 其他场景大家根据user和item的分布情况自己评估;
- 搞不清楚的时候可以考虑加item_id,不加user_id。
如何添加user_id、item_id特征?添加在模型结构的什么位置也是有讲究的。
- 物品池大小适中且基本保持稳定的场景item_id可以和其他特征放在一起训练
- user_id等强区分性特征可以放在单独的塔中学习user bias;不和其他常规特征放在一起。
- user bias是有些用户天然喜欢给物品打高分,浏览很广泛,有些用户天然很挑剔
- 在长尾分布较严重的场景,user_id、item_id等强区分性特征embedding可以做特征粒度的dropout后再与其他特征embedding拼接。注意这里说的是“特征粒度的dropout”,不是常规的神经元粒度的dropout,也就是说特征embedding整体有一定的概率被丢弃(mask)或保留。
- 也可以考虑使用@石塔西提到的“补水塔”结构。
- 记忆型特征放在一个单独的塔中,泛化性特征放在另外的独立塔中;引入一个基于物品分布的门控机制,让头部的物品主要拟合“记忆特征”,中长尾物品主要拟合“泛化特征”。通过加权求和的方式在各个特征上学习到的表征特征,再去拟合最终的业务目标。参考谷歌的Cross Decoupling Network (CDN) 。
推荐算法user_id在train和serving时应该怎么用?
推荐算法user_id在train和serving时应该怎么用? - 知乎
第一次做推荐,看了几篇论文发现都会用到id类特征,比如在电商推荐领域,可能会用到user_id和item_id,随机初始化该类特征的向量表进行模型训练,那么在线服务时怎么对未出现的user_id进行预测呢?
回答1:
1、比较简单的做法,直接将那些新userid的embedding全部设置0,同样对那些出现次数少的userid也设置0,次数少说明该用户训练不够充分,可以直接设置0。
2、训练的时候对样本中的userid随机采样,将他们的userid都设置成同一个id,让其在模型中训练,serving的时候新用户以及出现次数少的用户的embedding就可以用该id的embedding。
回答2:
对于新id(新用户或新物料的id),一般作法是:
- 训练时,随机初始化
- 预测时,以全零向量代替。
多说一句,以上作法不是new user id或new item id的专利,而是Parameter Server的通常作法。比如遇到一个new tag, parameter server也是这样处理这个new tag在train & predict时的embedding的。
这样做是出于简单易行,但并非没有缺点。
为了解决这一问题,业界提出使用meta-learning的方式学习出new user/item id的最优初值。在《互联网大厂推荐算法实战》的8.2.3节对meta-learning在推荐冷启动中的应用有专门的论述。书中提出将meta-learning应用于推荐算法,不能简单照搬,而需要在应用范围、优化目标、生成方式三个方面进行改造。
回答3:
1.把这个user id丢掉,或者0向量填充
2.训练的时候对所有长尾的id共享一个向量作训练,预测出现新的id用这个表示
另外,既然是第一次出现的user id,必然是新用户了,可以对新用户单独做个冷启动模型。
参考:
推荐算法user_id在train和serving时应该怎么用? - 知乎
深度学习推荐算法中user-id和item-id是否需要放入模型中作为特征进行训练呢? - 知乎
电商推荐算法中,用户id和商品id是否需要作为模型特征? - 知乎
相关文章:

【推荐算法】userid是否需要建模
看到一个din的源码,将userid也构建了emb table。 于是调研了一下。即推荐算法需要建模userid吗? 深度学习推荐算法中user-id和item-id是否需要放入模型中作为特征进行训练呢? 深度学习推荐算法中user-id和item-id是否需要放入模型中作为特…...
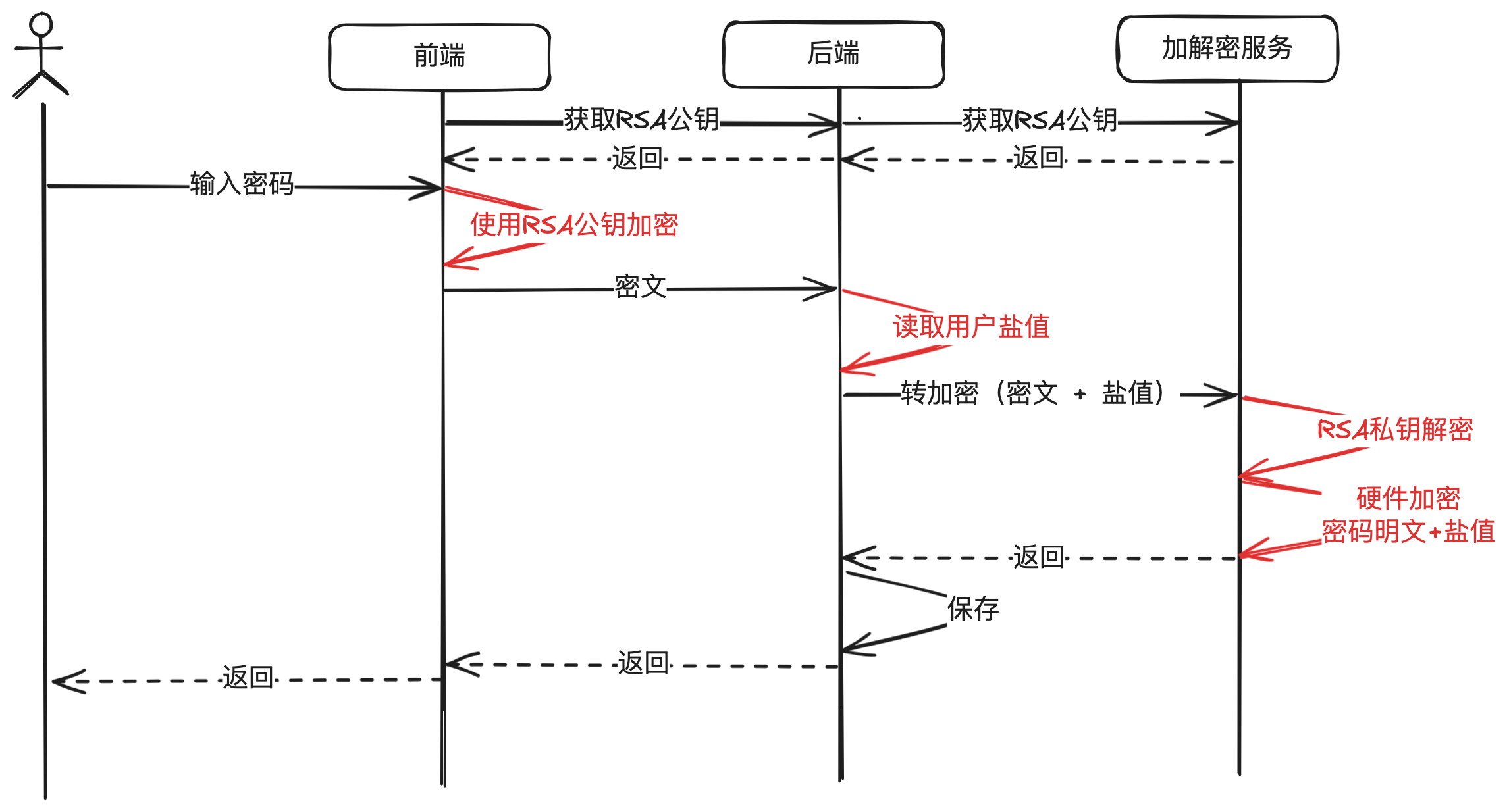
图解支付-金融级密钥管理系统:构建支付系统的安全基石
经常在网上看到某某公司几千万的个人敏感信息被泄露,这要是放在持牌的支付公司,可能就是一个非常大的麻烦,不但会失去用户的信任,而且可能会被吊销牌照。而现实情况是很多公司的技术研发人员并没有足够深的安全架构经验来设计一套…...
)
新概念英语第二册(58)
【New words and expressions】生词和短语(16) blessing n. 福分,福气 disguise n. 伪装 tiny adj. 极小的 possess v. 拥有 cursed …...

java和javascript的区别和联系
Java和JavaScript是两种非常流行的编程语言,尽管它们的名称相似,但实际上它们在设计、用途和运行环境等方面有很大的不同。以下是Java和JavaScript之间的主要区别和联系: 区别 设计目的和用途: Java 是一种通用的、面向对象的编程…...

uniapp中配置开发环境和生产环境
uniapp在开发的时候,可以配置多种环境,用于自动切换IP地址,用HBuilder X直接运行的就是开发环境,用HBuilder X发布出来的,就是生产环境。 1.使用HBuilder X创建原生的uniapp程序 选择vue3 2.什么都不改,就…...

prometheus之mysqld_exporter部署
mysql_exporter部署 下载解压压缩包 mkdir /opt/mysqld_exporter/ cd /opt/mysqld_exporter/ # 修改为自己的软件下载地址 wget http://soft.download/soft/linux/prometheus/mysqld_exporter/mysqld_exporter-0.14.0.linux-amd64.tar.gz tar -zxvf mysqld_exporter-0.14.0.…...

<网络安全>《19 安全态势感知与管理平台》
1 概念 安全态势感知与管理平台融合大数据和机器学习技术,提供可落地的安全保障能力,集安全可视化、监测、预警和响应处置于一体。它集中收集并存储客户I环境的资产、运行状态、漏洞、安全配置、日志、流量等安全相关数据,内置大数据存储和多…...

sqli靶场完结篇!!!!
靶场,靶场,一个靶场打一天,又是和waf斗智斗勇的一天,waf我和你拼啦!! 31.多个)号 先是一套基本的判断 ,发现是字符型,然后发现好像他什么都不过滤?于是开始poc 3213131…...

堆结构的解读
对于数据结构堆来说,堆事一种特定的数据结构,其与二叉树非常类似,但是又与二叉树有所不同,其不同点在于堆不需要左右指针指向孩子节点,而给定一个数组,将数组中的元素进行特定排序之后,就可以得…...
)
7、Qt5开发及实列(笔记)
文章目录 第二章 Qt5模板库、工具类及控件2.2 容器类2.2.1 QList类 # 2.3 QVariant类 #2.4 算法及正则表达式2.5控件 第二章 Qt5模板库、工具类及控件 2.2 容器类 2.2.1 QList类 //2.2容器类 - QList类QList<QString> list;//声明了一个QList<QString>栈对象{QSt…...
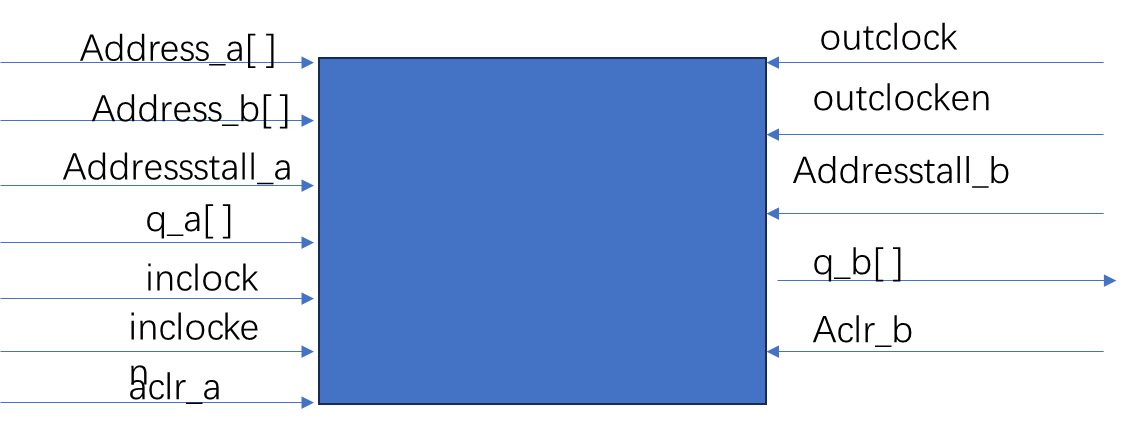
FPGA_ip_Rom
一 理论 Rom存储类ip核,Rom是只读存储器的简称,是一种只能读出事先存储数据的固态半导体存储器。 特性: 一旦储存资料,就无法再将之改变或者删除,且资料不会因为电源关闭而消失。 单端口Rom: 双端口rom: 二 Rom ip核…...
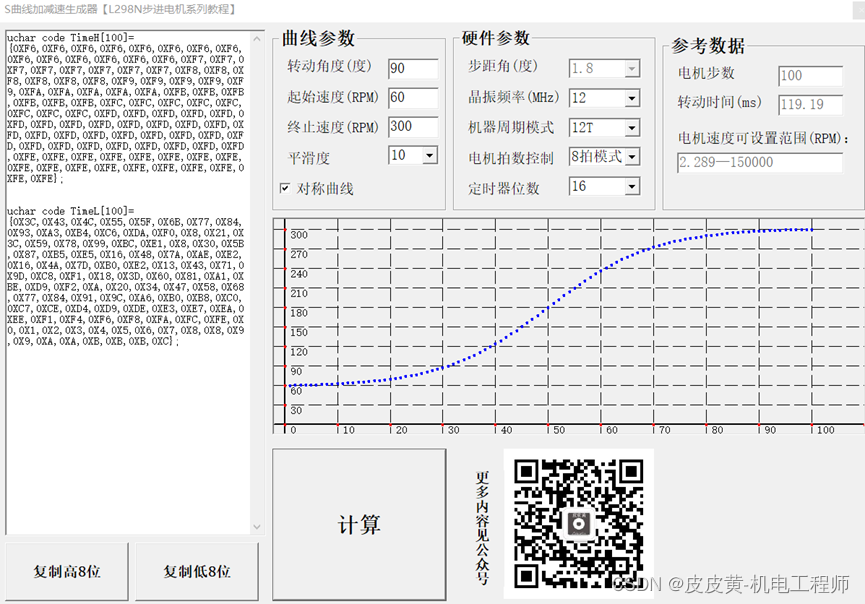
5-3、S曲线生成器【51单片机+L298N步进电机系列教程】
↑↑↑点击上方【目录】,查看本系列全部文章 摘要:本节介绍步进电机S曲线生成器的计算以及使用 一.计算原理 根据上一节内容,已经计算了一条任意S曲线的函数。在步进电机S曲线加减速的控制中,需要的S曲线如图1所示,横…...

Google开源项目风格指南——Java
Google Java Style Guide 谷歌 Java 风格指南 谷歌 Java 风格指南1 简介1.1 术语说明1.2 指导说明 2 源文件基础知识2.1 文件名2.2 文件编码:UTF-82.3 特殊字符2.3.1 空白字符2.3.2 特殊转义序列2.3.3 非ASCII字符 3 源文件结构3.1 许可或版权信息(如果存…...
)
数字图像处理与Python语言实现-常见图像特效(二)
文章目录 9、Splash滤镜10、双色调(Duo-Tone)滤镜11、日光(Daylight)滤镜12、60sTVs效果13、高对比度14、棕褐色/复古滤镜15、晕影效果16、模糊滤镜17、浮雕边缘9、Splash滤镜 在Splash滤镜中,仅某些颜色保持原样,其余颜色转换为灰度。 为了执行此操作,我们将在 HSV 颜…...

学习方法分享
工作上的代码实现,不要过度设计,不要想着炫技,要简单务实,“大道至简”。 学习一个方向(模块化)的知识,不经意间就会涉及到另一个领域,比如从消息队列存储的顺序读/写,延…...

Python学习路线 - Python高阶技巧 - 拓展
Python学习路线 - Python高阶技巧 - 拓展 闭包闭包注意事项 装饰器装饰器的一般写法(闭包写法)装饰器的语法糖写法 设计模式单例模式工厂模式 多线程进程、线程并行执行多线程编程threading模块 网络编程Socket客户端和服务端Socket服务端编程实现服务端并结合客户端进行测试 S…...

qt在pro文件中设置utf-8编码
在 Qt 的 .pro 文件中设置使用 UTF-8 编码,可以通过在 .pro 文件中添加以下内容来实现: QMAKE_CXXFLAGS -source-charset UTF-8 QMAKE_CXXFLAGS -execution-charset UTF-8这样设置后,Qt 会将源代码和执行时的字符集都设置为 UTF-8 编码。这…...
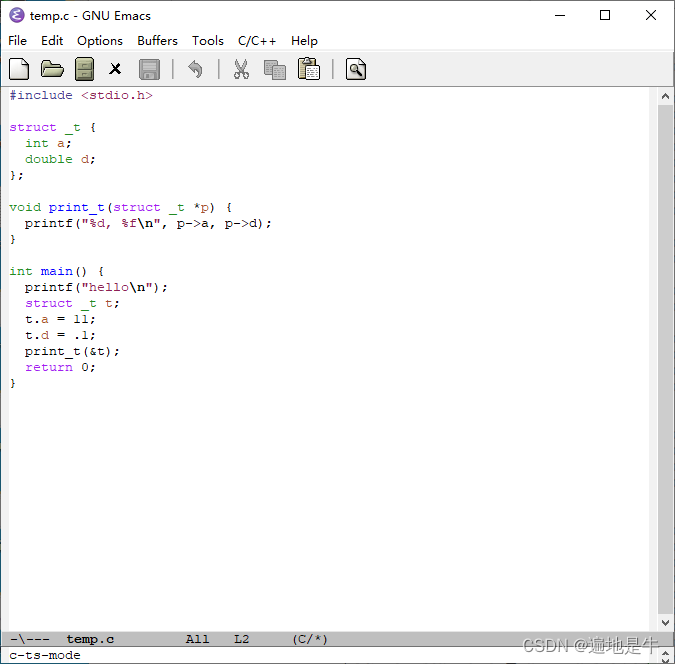
如何在 emacs 上开始使用 Tree-Sitter(windows)
文章目录 如何在emacs上开始使用Tree-Sitter(windows) 如何在emacs上开始使用Tree-Sitter(windows) 参考:“How to Get Started with Tree-Sitter”。 首先要有一个可运行的emacs,并且它支持Tree-Sitter&…...

Qt 数据库操作V1.0
1、pro文件 QT sql2、h文件 #ifndef DATABASEOPERATION_H #define DATABASEOPERATION_H#include <QSqlDatabase> #include <QSqlQuery> #include <QSqlError> #include <QSqlRecord> #include <QDebug> #include <QVariant>clas…...

【Eclipse插件开发】3工作台workbench探索【上篇】
3工作台workbench探索 文章目录 3工作台workbench探索前言视图编辑器一、工作台Workbench入门工作台页透视图视图和编辑器二、使用命令的基本工作台扩展点2.1 org.eclipse.ui.views2.2 org.eclipse.ui.editors编辑器和内容大纲2.3 org.eclipse.ui.comm...

百度网盘提取码智能获取工具:让资源下载效率提升100倍的秘密武器
百度网盘提取码智能获取工具:让资源下载效率提升100倍的秘密武器 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为获取百度网盘分享链接的提取码而浪费宝贵时间吗?面对"请输入提取码"的…...

5大突破!漫画阅读工具Venera重构跨平台阅读体验
5大突破!漫画阅读工具Venera重构跨平台阅读体验 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 副标题:如何在Windows、macOS和移动设备间无缝切换你的漫画库? 开篇痛点引入 不同设备间漫…...

Abp要落地DDD重要的一步
要用到实体之间的依赖关系,也就是聚合根,否则每个实体一个仓储,光一个服务注入就十几个仓储,玩锤子...
—— 原理详解、代码实现与性能验证)
超越极限:YOLOv8融合Dynamic Head(统一尺度-空间-任务感知注意力)—— 原理详解、代码实现与性能验证
引言 在目标检测领域,YOLO系列模型凭借其出色的速度与精度平衡,始终占据着举足轻重的地位。YOLOv8作为Ultralytics团队的最新力作,在架构设计、训练策略和部署便捷性上均达到了新的高度。然而,随着应用场景的日益复杂,如何让模型在多尺度变化、空间遮挡、任务干扰等挑战下…...

Python 3.13 + CUDA 13.0编译轮子
核心工具链安装 1、安装 Visual Studio 2022 (勾选 “使用 C 的桌面开发”) 2、安装 CUDA Toolkit 13.0环境变量注入 在终端执行,确保编译器能精准定位 CUDA 路径:set CUDA_PATHD:\Program Files\NVIDIA_GPU_Computing_Toolkit\v13 set PATH%CUDA_PATH%\…...

PT工具效率革命:一站式解决PT站点种子管理难题
PT工具效率革命:一站式解决PT站点种子管理难题 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项目地址: h…...

Spring Boot 集成云快充协议:充电桩接入平台完整Demo
云快充协议云快充1.5协议云快充1.6云快充协议开源代码云快充底层协议云快充桩直连桩直连协议充电桩协议云快充源码介绍云快充协议云快充1.5协议云快充1.6云快充协议开源代码云快充底层协议云快充桩直连桩直连协议充电桩协议云快充源码软件架构1、提供云快充底层桩直连协议&…...
)
第 11 章 追踪与性能分析(OpenOCD)
第 11 章 追踪与性能分析 导读:现代 ARM 处理器内置了丰富的 CoreSight 追踪基础设施,包括 ETM 指令追踪、ITM/DWT 数据追踪、SWO/TPIU 追踪输出以及 SEGGER RTT 高速日志。本章将系统介绍如何在 OpenOCD 中配置和使用这些追踪功能,帮助开发者在不侵入目标程序的前提下,完成…...

AI原生推荐:如何实现端到端的训练?
AI原生推荐:如何实现端到端的训练?关键词:AI原生推荐、端到端训练、深度学习推荐系统、推荐模型架构、多模态融合摘要:本文将从“AI原生推荐”的核心需求出发,用“快递物流”“餐厅点菜”等生活化类比,逐步…...

5步征服显存难题:多语言MiniLM模型量化优化实战指南
5步征服显存难题:多语言MiniLM模型量化优化实战指南 【免费下载链接】paraphrase-multilingual-MiniLM-L12-v2 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/paraphrase-multilingual-MiniLM-L12-v2 1. 诊断显存瓶颈 在部署paraphrase-multili…...