我的PyTorch模型比内存还大,怎么训练呀?
原文:我的PyTorch模型比内存还大,怎么训练呀? - 知乎
看了一篇比较老(21年4月文章)的不大可能训练优化方案,保存起来以后研究一下。
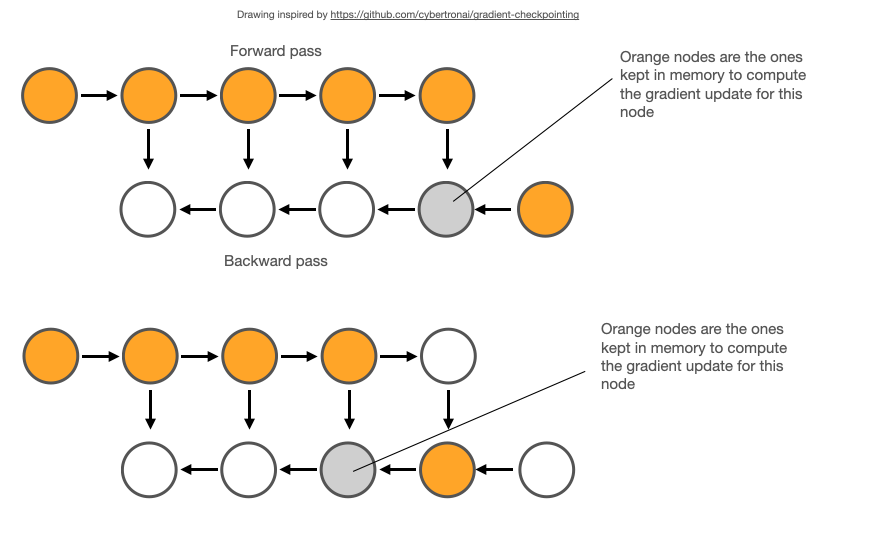
随着深度学习的飞速发展,模型越来越臃肿,哦不,先进,运行SOTA模型的主要困难之一就是怎么把它塞到 GPU 上,毕竟,你无法训练一个设备装不下的模型。改善这个问题的技术有很多种,例如,分布式训练和混合精度训练。
本文将介绍另一种技术: 梯度检查点(gradient checkpointing)。简单的说,梯度检查点的工作原理是在反向时重新计算深层神经网络的中间值(而通常情况是在前向时存储的)。这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
文末有一个示例基准测试,它显示了梯度检查点减少了模型 60% 的内存开销(以增加 25% 的训练时间为代价)。
详细代码请查看我的 GitHub 库: https://github.com/spellml/tweet-sentiment-extraction/blob/master/notebooks/5-checkpointing.ipynb
>>> 神经网络如何使用内存
为了理解梯度检查点是如何起作用的,我们首先需要了解一下模型内存分配是如何工作的。
神经网络使用的总内存基本上是两个部分的和。
第一部分是模型使用的静态内存。尽管 PyTorch 模型中内置了一些固定开销,但总的来说几乎完全由模型权重决定。当今生产中使用的现代深度学习模型的总参数在100万到10亿之间。作为参考,一个带 16GB GPU 内存的 NVIDIA T4 的实际限制大约在1-1.5亿个参数之间。
第二部分是模型的计算图所占用的动态内存。在训练模式下,每次通过神经网络的前向传播都为网络中的每个神经元计算一个激活值,这个值随后被存储在所谓的计算图中。必须为批中的每个单个训练样本存储一个值,因此数量会迅速的累积起来。总开销由模型大小和批次大小决定,一般设置最大批次大小限制来适配你的 GPU 内存。
要了解更多关于 PyTorch autograd 的信息,请查看我的 Kaggle 笔记本《PyTorch autograd 解释》: https://www.kaggle.com/residentmario/pytorch-autograd-explained
>>> 梯度检查点是如何起作用的
大型模型在静态和动态方面都很耗资源。首先,它们很难适配 GPU,而且哪怕你把它们放到了设备上,也很难训练,因为批次大小被迫限制的太小而无法收敛。
现有的各种技术可以改善这些问题中的一个或两个。梯度检查点就是这样一种技术; 分布式训练,是另一种技术。
梯度检查点(gradient checkpointing) 的工作原理是从计算图中省略一些激活值。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
但是,一开始存储激活的原因是,在反向传播期间计算梯度时需要用到激活。在计算图中忽略它们将迫使 PyTorch 在任何出现这些值的地方重新计算,从而降低了整体计算速度。
因此,梯度检查点是计算机科学中折衷的一个经典例子,即在内存和计算之间的权衡。
PyTorch 通过 torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 提供梯度检查点,根据官方文档的 notes,它实现了如下功能,在前向传播时,PyTorch 将保存模型中的每个函数的输入元组。在反向传播过程中,对于每个函数,输入元组和函数的组合以实时的方式重新计算,插入到每个需要它的函数的梯度公式中,然后丢弃。网络计算开销大致相当于每个样本通过模型前向传播开销的两倍。
梯度检查点首次发表在2016年的论文 《Training Deep Nets With Sublinear Memory Cost》 中。论文声称提出的梯度检查点算法将模型的动态内存开销从 O(n)(n 为模型中的层数)降低到 O(sqrt(n)),并通过实验展示了将 ImageNet 的一个变种从 48GB 压缩到了 7GB 内存占用。
>>> 测试 API
PyTorch API 中有两个不同的梯度检查点方法,都在 torch.utils.checkpoint 命名空间中。两者中比较简单的一个是 checkpoint_sequential,它被限制用于顺序模型(例如使用 torch.nn.Sequential wrapper 的模型)。另一个是更灵活的 checkpoint,可以用于任何模块。
下面是一个完整的代码示例,显示了 checkpoint_sequential 的实际用法:
import torch
import torch.nn as nnfrom torch.utils.checkpoint import checkpoint_sequential# a trivial model
model = nn.Sequential(nn.Linear(100, 50),nn.ReLU(),nn.Linear(50, 20),nn.ReLU(),nn.Linear(20, 5),nn.ReLU()
)# model input
input_var = torch.randn(1, 100, requires_grad=True)# the number of segments to divide the model into
segments = 2# finally, apply checkpointing to the model
# note the code that this replaces:
# out = model(input_var)
out = checkpoint_sequential(modules, segments, input_var)# backpropagate
out.sum().backwards()如你所见,checkpoint_sequential 替换了 module 对象上的 forward 或 __call__ 方法。out 几乎和我们调用 model(input_var) 时得到的张量一样; 关键的区别在于它缺少了累积值,并且附加了一些额外的元数据,指示 PyTorch 在 out.backward() 期间需要这些值时重新计算。
值得注意的是,checkpoint_sequential 接受整数值的片段数作为输入。checkpoint_sequential 将模型分割成 n 个纵向片段,并对除了最后一个的每个片段应用检查点。
这工作很容易,但有一些主要的限制。你无法控制片段的边界在哪里,也无法对整个模块应用检查点(而是其中的一部分)。
替代方法是使用更灵活的 checkpoint API. 下面展示了一个简单的卷积模型:
class CIFAR10Model(nn.Module):def __init__(self):super().__init__()self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.flatten = lambda inp: torch.flatten(inp, 1)self.head = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 10)])def forward(self, X):X = self.cnn_block_1(X)X = self.cnn_block_2(X)X = self.flatten(X)X = self.head(X)return X这种模型有两个卷积块,一些 dropout,和一个线性头(10个输出对应 CIFAR10 的10类)。
下面是这个模型使用梯度检查点的更新版本:
class CIFAR10Model(nn.Module):def __init__(self):super().__init__()self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2)])self.dropout_1 = nn.Dropout(0.25)self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2)])self.dropout_2 = nn.Dropout(0.25)self.flatten = lambda inp: torch.flatten(inp, 1)self.linearize = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512),nn.ReLU()])self.dropout_3 = nn.Dropout(0.5)self.out = nn.Linear(512, 10)def forward(self, X):X = self.cnn_block_1(X)X = self.dropout_1(X)X = checkpoint(self.cnn_block_2, X)X = self.dropout_2(X)X = self.flatten(X)X = self.linearize(X)X = self.dropout_3(X)X = self.out(X)return X在 forward 中显示的 checkpoint 接受一个模块(或任何可调用的模块,如函数)及其参数作为输入。参数将在前向时被保存,然后用于在反向时重新计算其输出值。
为了使其能够工作,我们必须对模型定义进行一些额外的更改。
首先,你会注意到我们从卷积块里删除了 nn.Dropout 层; 这是因为检查点与 dropout 不兼容(回想一下,样本有效地通过模型两次 —— dropout 会在每次通过时任意丢失不同的值,从而产生不同的输出)。基本上,任何在重新运行时表现出非幂等(non-idempotent )行为的层都不应该应用检查点(nn.BatchNorm 是另一个例子)。解决方案是重构模块,这样问题层就不会被排除在检查点片段之外,这正是我们在这里所做的。
其次,你会注意到我们在模型中的第二卷积块上使用了检查点,但是第一个卷积块上没有使用检查点。这是因为检查点简单地通过检查输入张量的 requires_grad 行为来决定它的输入函数是否需要梯度下降(例如,它是否处于 requires_grad=True 或 requires_grad=False模式)。模型的输入张量几乎总是处于 requires_grad=False 模式,因为我们感兴趣的是计算相对于网络权重而不是输入样本本身的梯度。因此,模型中的第一个子模块应用检查点没多少意义: 它反而会冻结现有的权重,阻止它们进行任何训练。更多细节请参考这个 PyTorch 论坛帖子:https://discuss.pytorch.org/t/use-of-torch-utils-checkpoint-checkpoint-causes-simple-model-to-diverge/116271。
在 PyTorch 文档(https://pytorch.org/docs/stable/checkpoint.html#)中还讨论了 RNG 状态以及与分离张量不兼容的一些其他细节。
完整的训练代码示例可以看这里: https://gist.github.com/ResidentMario/e3254172b4706191089bb63ecd610e21
和这里: https://gist.github.com/ResidentMario/9c3a90504d1a027aab926fd65ae08139
>>> 基准测试
作为一个快速的基准测试,我在 tweet-sentiment-extraction 上启用了模型检查点,这是一个基于 Twitter 数据的带有 BERT 主干的情感分类器模型。你可以在这里看到代码:https://github.com/spellml/tweet-sentiment-extraction。transformers 已经将模型检查点作为 API 的一个可选部分来实现; 为我们的模型启用它就像翻转一个布尔值标记一样简单:
# code from model_5.pycfg = transformers.PretrainedConfig.get_config_dict("bert-base-uncased")[0]
cfg["output_hidden_states"] = True
cfg["gradient_checkpointing"] = True # NEW!
cfg = transformers.BertConfig.from_dict(cfg)
self.bert = transformers.BertModel.from_pretrained("bert-base-uncased", config=cfg
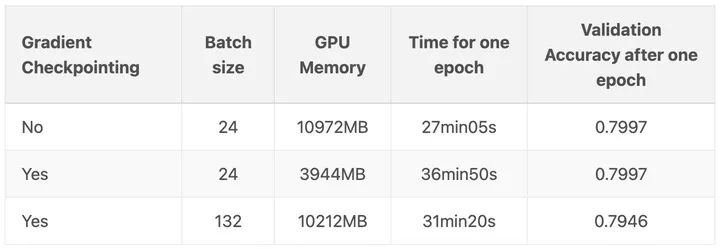
)我对这个模型进行了四次训练: 分别在 NVIDIA T4和 NVIDIA V100 GPU 上,包括检查点和无检查点模式。所有运行的批次大小为 64。以下是结果:

第一行是在模型检查点关闭的情况下进行的训练,第二行是在模型检查点开启的情况下进行的训练。
模型检查点降低了峰值模型内存使用量 60% ,同时增加了模型训练时间 25% 。
当然,你想要使用检查点的主要原因可能是,这样你就可以在 GPU 上使用更大的批次大小。在另一篇博文:https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html 中演示了这个很好的例子: 在他们的例子中,每批次样本从 24 个提高到惊人的 132 个!
要处理大型神经网络,模型检查点显然是一个非常强大和有用的工具。
原文: https://spell.ml/blog/gradient-checkpointing-pytorch-YGypLBAAACEAefHs
发布于 2021-04-27 22:39
相关文章:
我的PyTorch模型比内存还大,怎么训练呀?
原文:我的PyTorch模型比内存还大,怎么训练呀? - 知乎 看了一篇比较老(21年4月文章)的不大可能训练优化方案,保存起来以后研究一下。 随着深度学习的飞速发展,模型越来越臃肿,哦不&a…...
HTTP协议笔记
HTTP协议笔记 参考: (建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系 《透视 HTTP 协议》——chrono 目录: 1、说说你对HTTP的了解吧。 1. HTTP状态码。 2. HTTP请求头和响应头,其中包括cookie、跨域响…...

零基础学Python之网络编程
1.什么是socket 官方定义: 套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用…...
09 AB 10串口通信发送原理
通用异步收发传输器( Universal Asynchronous Receiver/Transmitter, UART)是一种异步收发传输器,其在数据发送时将并行数据转换成串行数据来传输, 在数据接收时将接收到的串行数据转换成并行数据, 可以实现…...

[145] 二叉树的后序遍历 js
题目描述:给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 解题思路: 迭代法: 后序(左右根) 先序是根左右 后序是左右根 后序翻转一下就是 根右左 所以后序的结果实际就是 先序的方法࿰…...
)
开源模型应用落地-业务优化篇(四)
一、前言 经过线程池优化、请求排队和服务实例水平扩容等措施,整个AI服务链路的性能得到了显著地提升。但是,作为追求卓越的大家,绝不会止步于此。我们的目标是在降低成本和提高效率方面不断努力,追求最佳结果。如果你们在实施AI项目方面有经验,那一定会对GPU服务器的高昂…...

MySQL的MVCC机制
MVCC机制 使用MVCC(Multi-Version Concurrency Control,多版本的并发控制协议)机制来实现可重复读(REPEATABLE READ)的隔离级别 MVCC最大的优点是读不加锁,因此读写不冲突,并发性能好。InnoDB实现MVCC,是通过保存数据在某个时间点…...
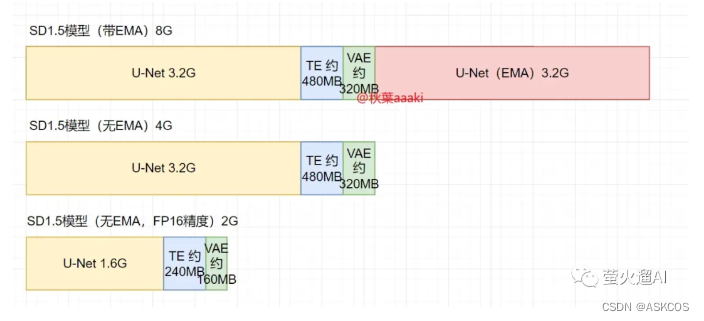
stable-diffusion | v1-5-pruned.ckpt和v1-5-pruned-emaonly.ckpt的区别
https://github.com/runwayml/stable-diffusion?tabreadme-ov-file#reference-sampling-script 对于 1.5 模型,其中可能包括四部分:标准模型、文本编码器、VAE模型、EMA模型。 标准模型:生成图片的核心模块,潜空间中的前向扩散和…...

基于Springboot的足球社区管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的足球社区管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构…...
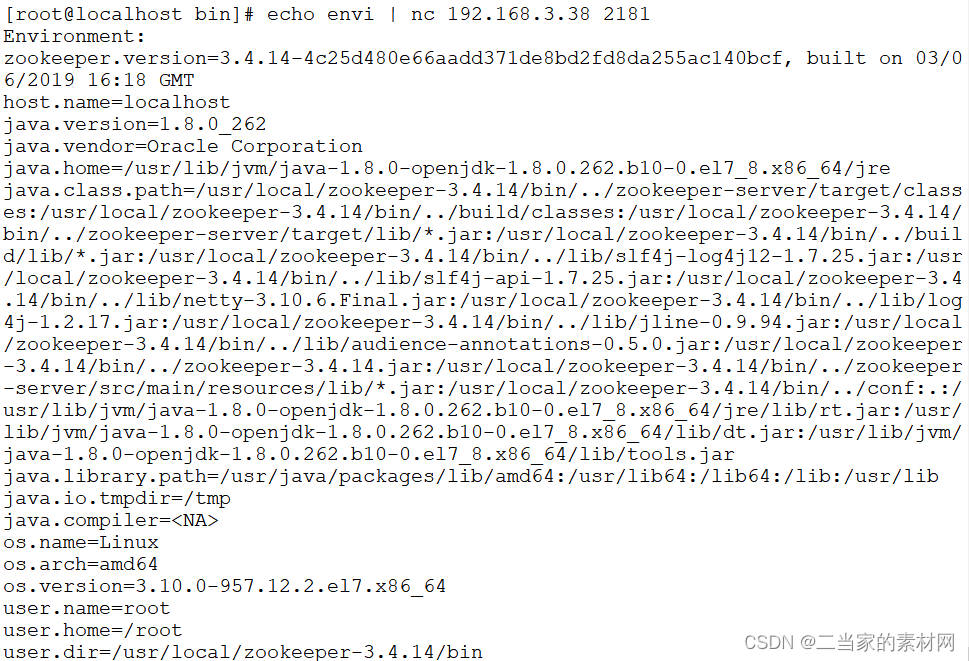
8.0 Zookeeper 四字命令教程详解
zookeeper 支持某些特定的四字命令与其交互,用户获取 zookeeper 服务的当前状态及相关信息,用户在客户端可以通过 telenet 或者 nc(netcat) 向 zookeeper 提交相应的命令。 安装 nc 命令: $ yum install nc …...

【MySQL】学习和总结DCL的权限控制
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-Bl9kYeLf8GfpdQgL {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...
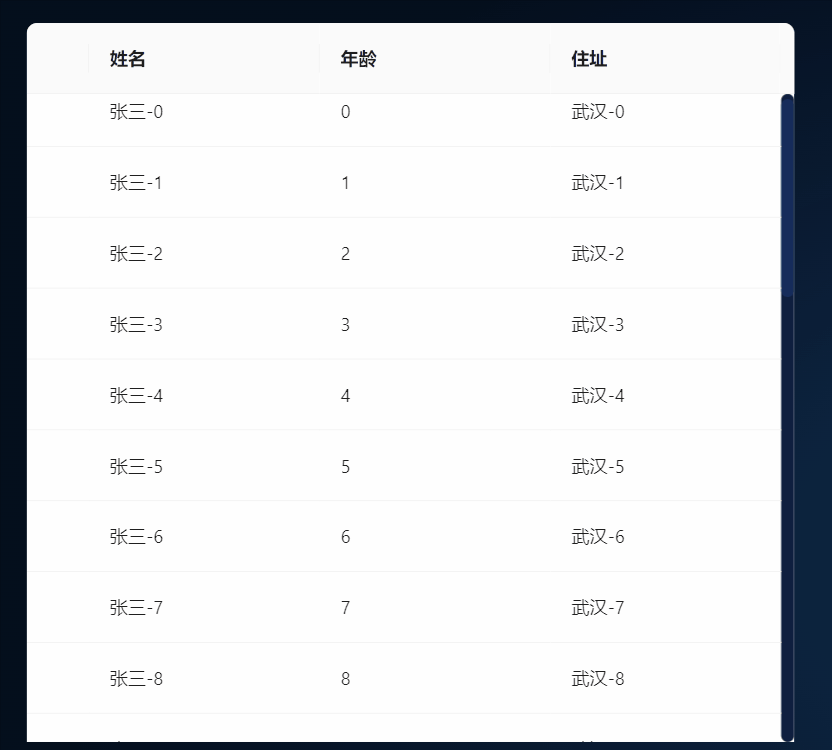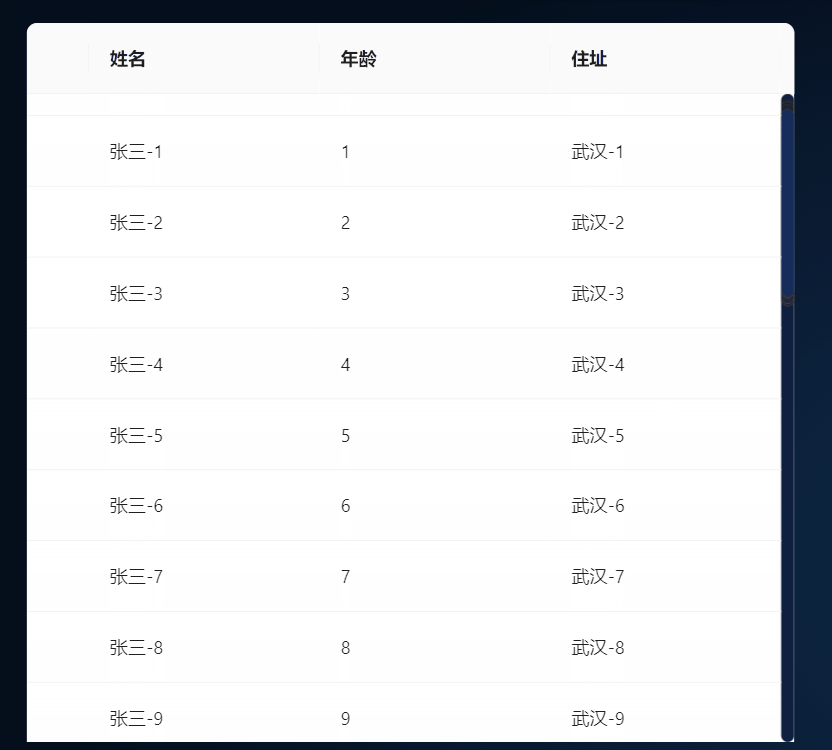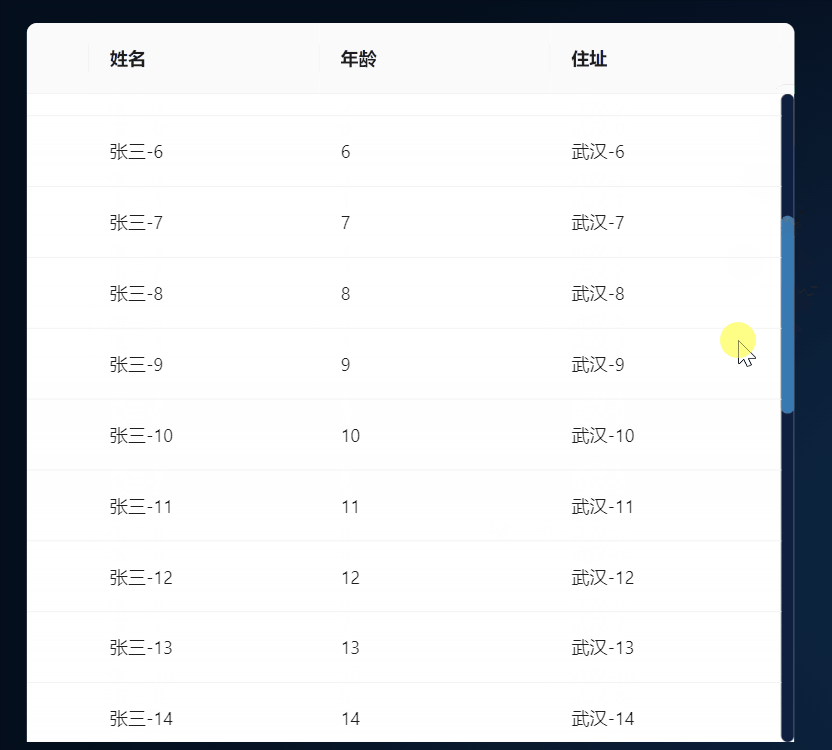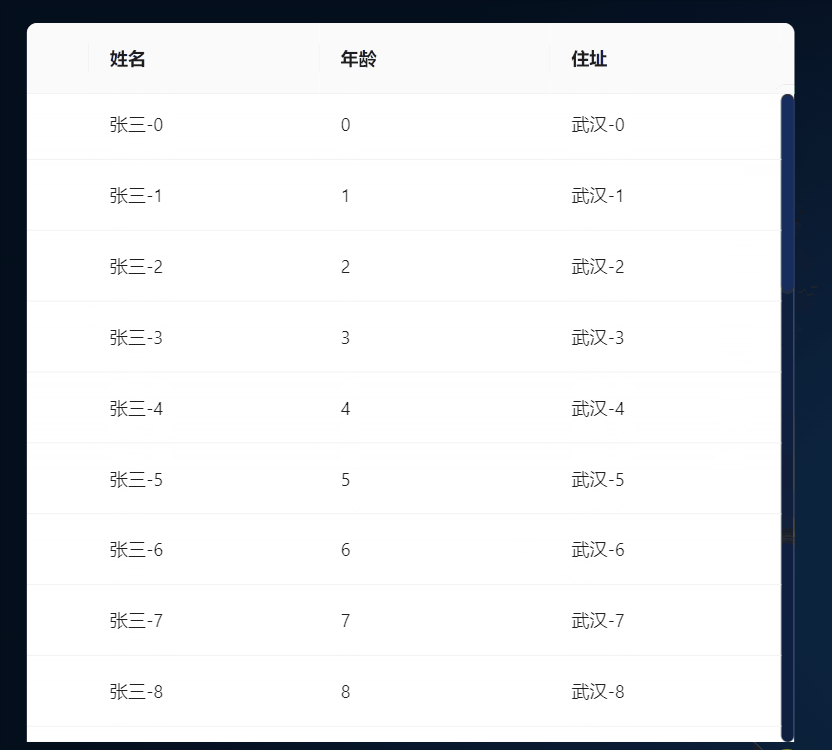
React+Antd实现表格自动向上滚动
1、效果 2、环境 1、react18 2、antd 4 3、代码实现 原理:创建一个定时器,修改表格ant-table-body的scrollTop属性实现滚动,监听表层的元素div的鼠标移入和移出实现实现鼠标进入元素滚动暂停,移出元素的时候表格滚动继续。 一…...

网络安全产品之认识准入控制系统
文章目录 一、什么是准入控制系统二、准入控制系统的主要功能1. 接入设备的身份认证2. 接入设备的安全性检查 三、准入控制系统的工作原理四、准入控制系统的特点五、准入控制系统的部署方式1. 网关模式2. 控制旁路模式 六、准入控制系统的应用场景七、企业如何利用准入控制系统…...

Text2SQL研究-Chat2DB体验与剖析
文章目录 概要业务数据库配置Chat2DB安装设置原理剖析 小结 概要 近期笔者在做Text2SQL的研究,于是调研了下Chat2DB,基于车辆订单业务做了一些SQL生成验证,有了一点心得,和大家分享一下.: 业务数据库设置 基于车辆订…...
——闭包)
JavaScript相关(二)——闭包
了解闭包的前提必须得了解什么是作用域链。也就是(一)的内容。 参考: 浏览器工作原理与实践 破解前端面试:从闭包说起 闭包 闭包是一个可以访问外部作用域中变量的内部函数,因为内部函数引用了外部函数的变量&#…...

MySQL的DDL语言
DDL:Data Definition Language(数据定义语言) DDL语言用来定义数据库对象(数据库,表,字段) ps:MySQL中关键字不区分大小写,但是库名、表名等是区分大小写的 一、对数据库操作的DDL 1、查询相关语句&…...

<网络安全>《21 工业安全审计系统》
1 工业安全审计系统 工业审计系统,支持多种工控协议的深度解析,对工控网络中的异常流量进行实时监测和告警,详实记录一切网络通信行为,为工业控制网络安全事件调查提供依据;产品聚焦工业生产安全事件分析,…...

实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要 两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示…...

阿里 EasyExcel 表头国际化
实体类字段使用EasyExcel提供的注解ExcelProperty,value 值写成占位符形式 ,匹配 i18n 文件里面的编码。 如: /*** 仓库名称*/ ExcelProperty("{warehouse.record.warehouseName}") private String warehouseName;占位符解析器 A…...
跨境电商新风潮:充分发挥海外云手机的威力
在互联网行业迅速发展的大环境下,跨境电商、海外社交媒体营销以及游戏产业等重要领域都越来越需要借助海外云手机的协助。 特别是在蓬勃发展的跨境电商领域,像亚马逊、速卖通、eBay等平台,结合社交电商营销和短视频内容成为最有效的流量来源。…...

PasteMD解决办公痛点:快速格式化OCR文字和网页复制内容
PasteMD解决办公痛点:快速格式化OCR文字和网页复制内容 1. 为什么我们需要智能文本格式化工具 在日常办公中,我们经常遇到这样的场景:会议结束后,手写的笔记拍成照片OCR识别后变成一堆杂乱无章的文本;从网页复制的技术…...

常量和常量表达式1
一、基础定义(C/C通用核心定义) 1. 常量(Constant) 程序整个生命周期内值不可修改、固定不变的量,是值的实体(单个固定值/命名固定值),其值的确定时机可在编译期/预处理期࿰…...

Three.js可视化开发:用辅助类打造交互式3D教学演示
Three.js可视化开发:用辅助类打造交互式3D教学演示 在数字化教育蓬勃发展的今天,3D可视化技术正在彻底改变传统教学模式。想象一下,当学生能够亲手旋转分子结构、观察物理碰撞的实时模拟,或是探索历史建筑的立体空间关系时&#x…...

WIFI UDP广播数据实时发送的可靠性困境与底层协议探析
1. WIFI UDP广播为何总在关键时刻掉链子? 上周调试智能家居设备时,我遇到了一个典型场景:AP需要向20多个终端同时发送控制指令。最初直接使用UDP广播,结果总有设备"装聋作哑"。换成单播后问题消失,但CPU占用…...

解锁桌面音乐新体验:LyricsX让你的Mac成为私人KTV
解锁桌面音乐新体验:LyricsX让你的Mac成为私人KTV 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 还在为听歌时找不到歌词而烦恼吗?LyricsX这款基…...

DLSS Swapper:轻松管理游戏超采样版本,释放显卡全部性能
DLSS Swapper:轻松管理游戏超采样版本,释放显卡全部性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 在追求极致游戏体验的今天,DLSS(深度学习超采样)技术…...

OpenClaw+Qwen3-32B自动化办公:会议纪要生成与飞书同步实战
OpenClawQwen3-32B自动化办公:会议纪要生成与飞书同步实战 1. 为什么需要自动化会议纪要 每次开完会最痛苦的事情是什么?对我来说就是整理会议纪要。作为技术负责人,每周要参加5-6个不同主题的会议,会后需要花大量时间回听录音、…...

VINS-Fusion 实战指南:从环境搭建到多传感器融合部署
1. VINS-Fusion入门:为什么选择这个多传感器融合方案 第一次接触VINS-Fusion是在做一个无人机定位项目时,当时试过各种开源SLAM方案,最后发现这个来自香港科技大学团队的工具在传感器融合方面确实有两把刷子。简单来说,它就像个聪…...

JC_Button按键库深度解析:嵌入式消抖与状态机设计
1. JC_Button 库深度解析:面向嵌入式工程师的按键消抖与状态机设计实践在嵌入式系统开发中,机械按键的抖动(Bounce)是硬件与软件协同设计中最基础、却极易被低估的挑战之一。一个未经处理的按键信号,在按下或释放瞬间会…...

RNA-seq测序深度指南:从研究目的到数据量换算全解析
1. RNA-seq测序深度:为什么它如此重要? 做RNA-seq实验的朋友们,最常被问到的问题就是"该测多少数据量?"。这个问题看似简单,实际上直接关系到实验的成败。我见过太多人因为测序深度选择不当,导致…...