机器学习中常用的性能度量—— ROC 和 AUC
什么是泛化能力?
通常我们用泛化能力来评判一个模型的好坏,通俗的说,泛化能力是指一个机器学期算法对新样本(即模型没有见过的样本)的举一反三的能力,也就是学以致用的能力。
举个例子,高三的学生在高考前大量的刷各种习题,像五年高考三年模拟、三年高考五年模拟之类的,目的就是为了在高考时拿到一个好的分数,高考的题目就是新题,一般谁也没做过,平时的刷题就是为了掌握试题的规律,能够举一反三、学以致用,这样面对新的题目也能从容应对。这种规律的掌握便是泛化能力,有的同学很聪明,考上名校,很大程度上是该同学的泛化能力好。
在机器学习中,对于分类和回归两类监督学习,分别有各自的评判标准,这里我们讨论常用于分类任务的性能度量标准——AUC 和 ROC。
几个重要概念:混淆矩阵、准确率、精准率和召回率
1. 混淆矩阵
假设我们建立的是二分类模型,将实际类别和预测类别进行两两组合,就形成了混淆矩阵。
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
接下来的性能度量指标都是由混淆矩阵的各个元素计算得来。
2. 准确率
准确率 = T P + T N T P + T N + F P + F N 准确率=\frac{TP+TN}{TP+TN+FP+FN} 准确率=TP+TN+FP+FNTP+TN
在样本均衡的情况下,准确率是一个适用的性能度量指标,但是,在样本不平衡的情况下,并不能很好的衡量结果。例如,在信用风险评估中,正样本为 90%,负样本(发生违约的样本)为 10%,样本严重失衡,在这种情况下,即使我们全部将样本预测为正样本,正确率也会达到 90%的高准确率。这也说明了,在样本失衡相对严重的情况下,即使准确率很高,结果也会有很大的水份,准确率指标会失效。
3. 查准率
查准率(Precision)又叫精准率,是指在所有被预测为正的样本中实际为正的样本的概率,即在预测为正的样本中,我们有多少把握可以预测正确:
查准率 = T P T P + F P 查准率=\frac{TP}{TP+FP} 查准率=TP+FPTP
查准率和准确率的区别在于:查准率代表对正样本结果中的预测精度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
4. 召回率
召回率(Recall)又叫查全率,指在实际为正的样本中被预测为正样本的概率。应用场景:在网贷信用风险评估中,相对好用户,我们更关心坏用户,不能错放任何一个坏用户,因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重亏损。召回率越高,表示实际坏用户被预测出来的概率越高,即“宁可错杀一千,绝不放过一个。”
精准率 = T P / ( T P + F N ) 精准率=TP/(TP+FN) 精准率=TP/(TP+FN)
一般来说,查准率和召回率是一对矛盾的度量。查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
例如,若希望将好瓜尽可能多地选出来,则可通过增加选瓜的数量来实现,如果将所有西瓜都选上,那么所有的好瓜也必然都被选上了,但这样查准率就会较低;若希望选出的瓜中好瓜比率尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得查全率较低,通常只有在一些简单的任务中,才可能使查全率和查准率都很高。
如果想要在两者之间找到一个平衡点,通常会使用 F1 分数,它同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。
F 1 = 2 × 查准率 × 召回率 ( 查准率 + 召回率 ) F1=\frac{2 \times 查准率 \times 召回率}{(查准率+召回率)} F1=(查准率+召回率)2×查准率×召回率
ROC和AUC
1. 真正率和假正率
ROC 和 AUC 可以在无视样本不平衡的情况下进行性能度量,关键在于两个指标:真正率(TPR)和假正率(FPR),其中真正率也叫灵敏度(Sensitivity),假正率则为 1-特异度(Specifucity)。
真正率 ( T P R ) = 灵敏度 = T P T P + F N 真正率(TPR)=灵敏度=\frac{TP}{TP+FN} 真正率(TPR)=灵敏度=TP+FNTP
假正率 ( F R P ) = 1 − 特异度 = F P F P + T N 假正率(FRP)=1-特异度=\frac{FP}{FP+TN} 假正率(FRP)=1−特异度=FP+TNFP
可以发现 TPR 和 FPR 分别是基于真实情况 1 和 0 出发的,即分别在真实情况下的正样本和负样本中来观察相关概率问题,正因为如此,所以无论样本是否平衡,都不会被影响。在之前的信用评估例子中,90% 为正样本,10% 为负样本,我们知道用准确率衡量结果是有水份的,但是用 TPR 和 FPR 不一样,这里,TPR 只关注 90% 正样本中有多少是真正被覆盖的,而与剩余 10% 无关,同理,FPR 只关注 10% 负样本中有多少是被错误覆盖的,也与其他 90% 毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用 TPR 和 FPR 作为 ROC/AUC 指标的原因。
2. ROC-接受者操作特征曲线
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线,最早应用于雷达信号检测领域,用于区分信号和噪声。后来人们将其用于评价模型的预测能力,ROC 曲线是基于混淆矩阵得出的。
ROC曲线中横坐标为假正率(FPR),纵坐标为真正率(TPR),是通过遍历所有阈值来绘制整条曲线的,当我们不断的遍历所有阈值,预测的正样本和负样本是不断变化,相应的在 ROC 曲线图中就会沿着曲线滑动。

改变阈值只是不断的改变正负样本数,即 TPR 和 FPR,但是曲线本身是不会改变的。那如何通过 ROC 来判断一个模型的好坏呢?我们知道 FRP 表示模型虚报的响应程度,TPR 表示模型预测响应的覆盖程度,一个好的模型虚报的越少越好,覆盖的越多越好,这就等价于 TPR 越高,同时 FPR 越低,即 ROC 曲线越陡时,模型的性能就越好。

之前已经讨论了 ROC 曲线为什么可以无视样本的不平衡,这里通过动图进行演示,可以发现:无论红蓝样本比率如何改变,ROC 曲线都没有影响。

3. AUC-曲线下面积
AUC 是一种基于排序的高效算法,取值越大,代表模型的预测效果越好,其一般判断标准为:
- 0.5~0.7:效果较低;
- 0.7~0.85:效果一般
- 0.85~0.95:效果很好
- 0.95~1:效果非常好,但很可能是过拟合导致的
sklean 的 metrics 对 ROC 和 AUC 的计算进行了实现。
相关文章:
机器学习中常用的性能度量—— ROC 和 AUC
什么是泛化能力? 通常我们用泛化能力来评判一个模型的好坏,通俗的说,泛化能力是指一个机器学期算法对新样本(即模型没有见过的样本)的举一反三的能力,也就是学以致用的能力。 举个例子,高三的…...

微服务入门篇:Nacos注册中心(Nacos安装,快速入门,多级存储,负载均衡,环境隔离,配置管理,热更新,集群搭建,nginx反向代理)
目录 1.Nacos安装1.官网下载2.解压到本地3.启动nacos 2.Nacos快速入门1.在父工程中导入nacos依赖2.给子项目添加客户端依赖3.修改对应服务的配置文件4.启动服务,查看nacos发现情况 3.Nacos服务多级存储模型4.NacosRule负载均衡5. 服务实例的权重设置6.环境隔离&…...

解决CORS错误(Spring Boot)
记录一下错误,以博客的形式 前言 跨域(Cross-Origin)是指在Web开发中,当一个Web应用试图从一个源(域名、协议、端口组合)获取资源时,该请求的目标与当前页面的源不同。具体来说,当一…...
NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding 2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的wor…...

JUnit5单元测试框架提供的注解
目录 第一章、注释在类上的注解1.1)JUnit5注释在类上的注解集成测试:SpringBootTest集成测试:ExtendWith(SpringExtension.class)单元测试:ExtendWith(MockitoExtension.class)切片测试:WebMvcTest和DataJpaTest<font colorred…...
ThinkPHP 中使用Redis
环境.env [app] app_debug "1" app_trace ""[database] database "" hostname "127.0.0.1" hostport "" password "" prefix "ls_" username ""[redis] hostname "127.0.0.1…...

Go语言Gin框架安全加固:全面解析SQL注入、XSS与CSRF的解决方案
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站https://www.captainbed.cn/kitie。 前言 在使用 Gin 框架处理前端请求数据时,必须关注安全性问题,以防范常见的攻击…...

MySQL数据库基础与SELECT语句使用梳理
MySQL数据库基础与SELECT语句使用梳理 注意:本文操作全部在终端进行 数据库基础知识 什么是数据库 数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件),实质上数据库是一个以某种 有组…...

scikit-learn 1.3.X 版本 bug - F1 分数计算错误
如果您正在使用 scikit-learn 1.3.X 版本,在使用 f1_score() 或 classification_report() 函数时,如果参数设置为 zero_division1.0 或 zero_divisionnp.nan,那么函数的输出结果可能会出错。错误的范围可能高达 100%,具体取决于数…...

Python面试题19-24
解释Python中的装饰器(decorators)是什么,它们的作用是什么? 装饰器是一种Python函数,用于修改其他函数的功能。它们允许在不修改原始函数代码的情况下,动态地添加功能。解释Python中的文件处理(…...

《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述
01 Introduction 《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述 Welcome to Beginning Django API wih React! This book focuses on they key tasks and concepts to get you started to learn and build a RESTFul web API with Django REST Framework,…...
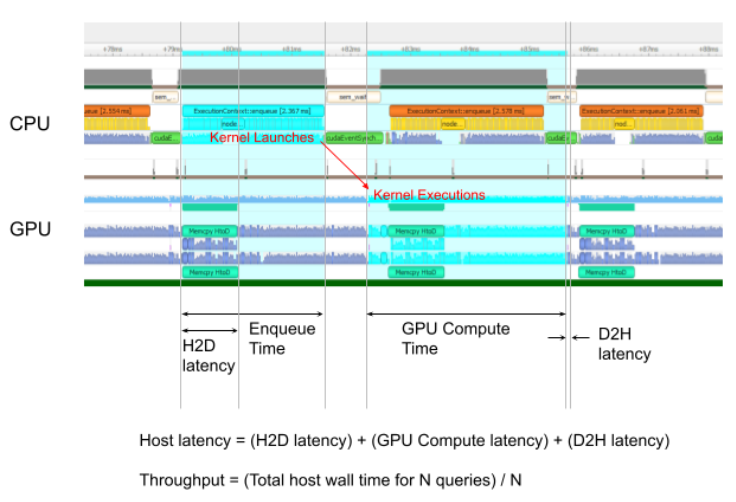
从零开始 TensorRT(4)命令行工具篇:trtexec 基本功能
前言 学习资料: TensorRT 源码示例 B站视频:TensorRT 教程 | 基于 8.6.1 版本 视频配套代码 cookbook 参考源码:cookbook → 07-Tool → trtexec 官方文档:trtexec 在 TensorRT 的安装目录 xxx/TensorRT-8.6.1.6/bin 下有命令行…...
基于SpringBoot+Vue的校园博客管理系统
末尾获取源码作者介绍:大家好,我是墨韵,本人4年开发经验,专注定制项目开发 更多项目:CSDN主页YAML墨韵 学如逆水行舟,不进则退。学习如赶路,不能慢一步。 目录 一、项目简介 二、开发技术与环…...
基于 SpringBoot 和 Vue.js 的权限管理系统部署教程
大家后,我是 jonssonyan 在上一篇文章我介绍了我的新项目——基于 SpringBoot 和 Vue.js 的权限管理系统,本文主要介绍该系统的部署 部署教程 这里使用 Docker 进行部署,Docker 基于容器技术,它可以占用更少的资源,…...
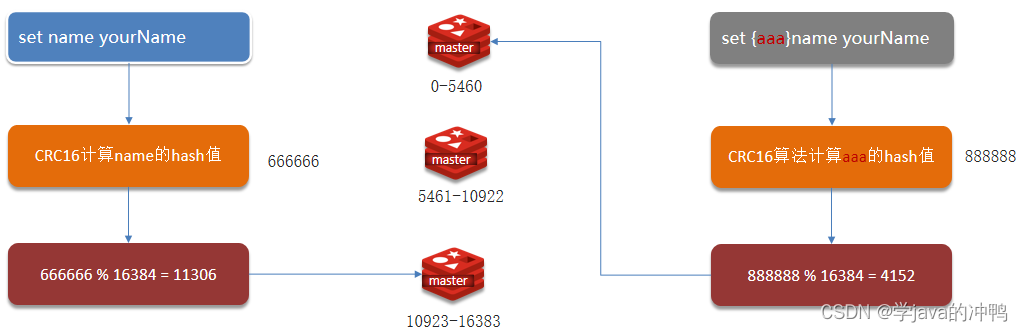
Redis篇之集群
一、主从复制 1.实现主从作用 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。主节点用来写的操作,从节点用来读操作,并且主节点发生写操作后,会把数据同…...

JUnit 5 注解总结与解析
前言 大家好,我是chowley,通过前篇的JUnit实践,我对这个框架产生了好奇,除了断言判断,它还有哪些用处呢?下面来总结一下它的常见注解及作用。 正文 在Java单元测试中,JUnit是一种常用的测试框…...

CSS综合案例4
CSS综合案例4 1. 综合案例 我们来做一个静态的轮播图。 2. 分析思路 首先需要加载一张背景图进去需要4个小圆点,设置样式,并用定位和平移调整位置添加两个箭头,也是需要用定位和位移进行调整位置 3. 代码演示 html文件 <!DOCTYPE htm…...
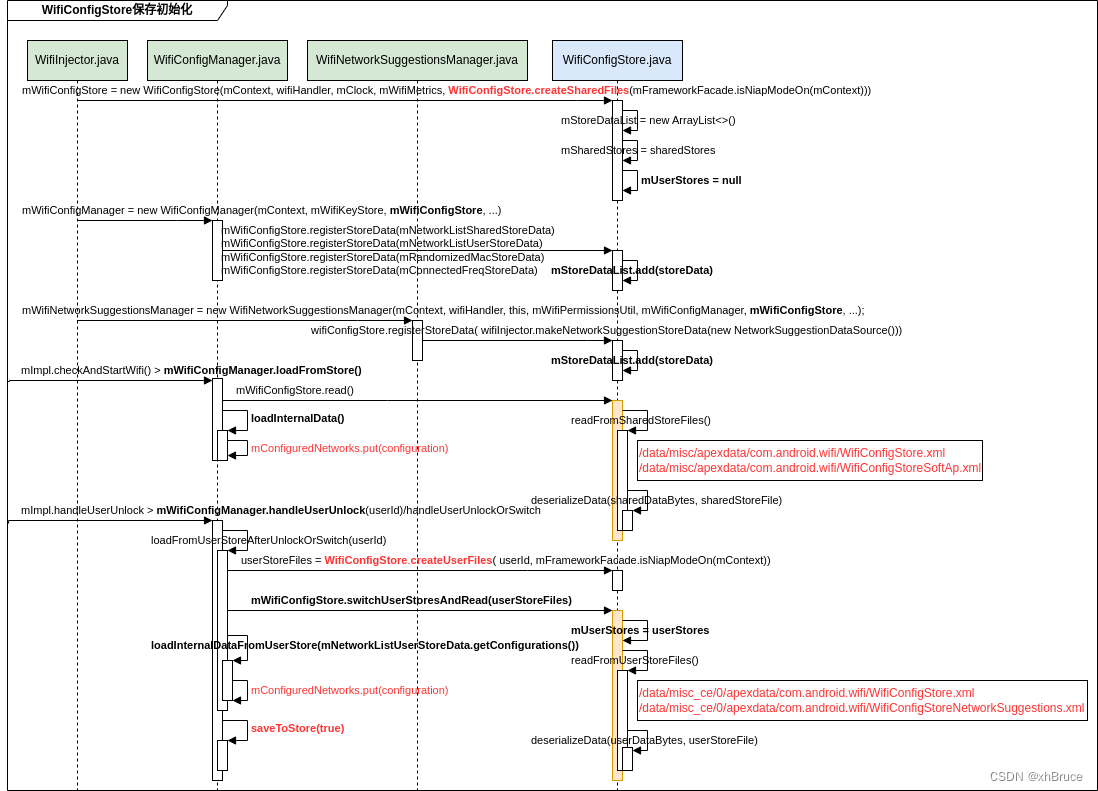
WifiConfigStore初始化读取-Android13
WifiConfigStore初始化读取 1、StoreData创建并注册2、WifiConfigStore读取2.1 文件读取流程2.2 时序图2.3 日志 1、StoreData创建并注册 packages/modules/Wifi/service/java/com/android/server/wifi/WifiConfigManager.java mWifiConfigStore.registerStoreData(mNetworkL…...
【Spring源码解读!底层原理进阶】【下】探寻Spring内部:BeanFactory和ApplicationContext实现原理揭秘✨
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:底层原理高级进阶》 🚀…...
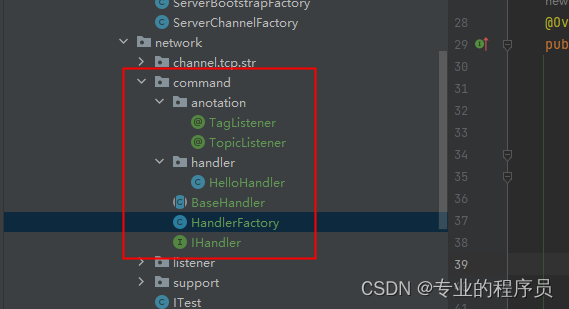
从零开始手写mmo游戏从框架到爆炸(六)— 消息处理工厂
就好像门牌号一样,我们需要把消息路由到对应的楼栋和楼层,总不能像菜鸟一样让大家都来自己找数据吧。 首先这里我们参考了rabbitmq中的topic与tag模型,topic对应类,tag对应方法。 新增一个模块,专门记录路由eternity-…...

OpenClaw语音交互方案:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF对接语音输入输出模块
OpenClaw语音交互方案:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF对接语音输入输出模块 1. 为什么需要语音交互能力 去年冬天的一个深夜,我正蜷在沙发上调试一个自动化脚本,突然意识到——当双手被咖啡杯占据时,用语…...
AudioSeal Pixel Studio部署教程:NVIDIA Triton推理服务器集成
AudioSeal Pixel Studio部署教程:NVIDIA Triton推理服务器集成 1. 项目概述 AudioSeal Pixel Studio是一款基于Meta开源的AudioSeal算法构建的专业音频水印工具。它能够在保持原始音频质量的前提下,为音频文件嵌入隐形数字水印,并具备强大的…...

Cogito-V1-Preview-Llama-3B开发:微信小程序智能客服对接实战
Cogito-V1-Preview-Llama-3B开发:微信小程序智能客服对接实战 最近有不少朋友在问,把大模型部署到服务器上之后,怎么才能让微信小程序用起来?今天我就以星图GPU平台上部署的Cogito-V1-Preview-Llama-3B模型为例,跟大家…...

Canvas Quest人像修复与增强实战:老照片修复与画质提升
Canvas Quest人像修复与增强实战:老照片修复与画质提升 1. 老照片修复的痛点与解决方案 翻开家里的老相册,总能看到一些泛黄、破损或模糊的照片。这些承载着珍贵记忆的画面,往往因为年代久远而变得难以辨认。传统的手工修复不仅耗时费力&am…...

Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导+代码生成真实截图
Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导代码生成真实截图 1. 模型能力概览 Cogito v1 预览版是Deep Cogito推出的混合推理模型系列,在大多数标准基准测试中均超越了同等规模下最优的开源模型。这个3B参数的模型在编码、STEM题目解答、指…...

极客专属:OpenClaw+百川2-13B打造个人CLI智能助手
极客专属:OpenClaw百川2-13B打造个人CLI智能助手 1. 为什么开发者需要命令行智能助手 作为一个长期与终端打交道的开发者,我每天要重复执行大量机械操作:查看日志、运行测试、整理结果。这些工作虽然简单,却极其消耗精力。直到我…...

17 种 RAG 优化策略
RAG 完整解析 本文适合小白入门,全程用「公司员工手册查病假」为统一实例,清晰讲解 RAG 是什么、工作流程,以及 17 种 RAG 优化策略(含标准英文术语),所有内容可直接复制用于分享,实例均精确到具…...

Python异步编程避坑:为什么你的‘async with’会报错?手把手教你正确使用aiohttp
Python异步编程避坑指南:深入理解aiohttp的正确打开方式 第一次接触Python异步编程时,很多人都会在async with这个语法上栽跟头。明明照着文档写的代码,运行时却抛出"SyntaxError: async with outside async function"的错误&#…...

PdfiumAndroid完全指南:从集成到高级应用
PdfiumAndroid完全指南:从集成到高级应用 【免费下载链接】PdfiumAndroid 项目地址: https://gitcode.com/gh_mirrors/pd/PdfiumAndroid PdfiumAndroid是一款专为Android开发打造的PDF渲染库,基于Pdfium原生库提供API级别14及以上设备的PDF文件处…...

斗鱼季报图解:营收9亿同比降19% 经调整净利1260万
雷递网 雷建平 3月26日斗鱼(Nasdaq: DOYU)日前发布截至2025年12月31日的全年及第四季度财报。财报显示,斗鱼2025年营收为38.19亿元(约5.46亿美元),较上年同期的42.71亿元下降10.58%。斗鱼2025年毛利为4.9亿元,经调整净…...