MySQL数据库基础与SELECT语句使用梳理
MySQL数据库基础与SELECT语句使用梳理
注意:本文操作全部在终端进行
数据库基础知识
- 什么是数据库
数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件),实质上数据库是一个以某种 有组织的方式存储的数据集合,数据库软件应称为DBMS(数据库管理系统)。数据库是通过DBMS创建和操纵的容器
- 为何要使用数据库
- 数据持久性:数据库可以将数据持久保存在存储设备上,以防止数据丢失。即使应用程序关闭或服务器崩溃,数据仍然可用。
- 数据组织和结构:数据库允许您以结构化的方式存储数据,将数据划分为表、列和行,使数据容易管理和检索。
- 数据完整性:数据库提供数据完整性约束,确保数据的准确性和一致性。这包括主键、外键、唯一性约束等。
- 数据查询和检索:数据库提供强大的查询语言,如SQL,使用户能够轻松地检索、过滤和分析数据。
- 多用户支持:数据库可以同时支持多个用户访问和修改数据,提供并发控制来处理多个用户之间的数据访问竞争。
- 数据安全性:数据库提供安全性功能,如用户身份验证和授权,以确保只有授权的用户可以访问特定数据。
- 数据备份和恢复:数据库允许进行定期备份,以便在数据丢失或损坏时进行恢复。
- 扩展性:数据库系统通常可以在需要时扩展,以处理更多数据和更多用户。
- 数据共享:多个应用程序可以共享数据库,以便它们之间共享数据,减少数据冗余。
- 数据分析:数据库允许进行复杂的数据分析和报告生成,有助于业务决策和规划。
- 历史记录:数据库可以跟踪数据的历史记录,使您可以查看数据的演变和变化。
- 数据一致性:数据库支持事务,确保在一系列操作中数据保持一致性,即要么全部操作成功,要么全部失败。
- 什么是表
表(table) 某种特定类型数据的结构化清单。存储在表中的数据是一种类型的数据或一个清单,数据库中的每个表都有一个名字,用来标识自己。此名字是唯一的, 这表示数据库中没有其他表具有相同的名字。说白了就是通过表来建立起数据的索引关系,如果将一本书比作数据库,那么表就是像目录一样的东西
注意:虽然在相同数据库中不能两次使用相同的表名, 但在不同的数据库中却可以使用相同的表名
- 什么是模式
模式(schema) 关于数据库和表的布局及特性的信息。表具有一些特性,这些特性定义了数据在表中如何存储,如可以存储什么样的数据,数据如何分解,各部分信息如何命名等等。描述表的这组信息就是所谓的模式,模式可以用来描述数据库中特定的表以及整个数据库和其中表的关系
- 什么是列
表由列组成。列中存储着表中某部分的信息。 列(column) 是表中的一个字段。所有表都是由一个或多个列组成的,还是拿书本举例,如果说表是目录,那么每个列就是一组具有某一共同特征的一单元
- 数据类型的定义
数据库中每个列都有相应的数据类型。数据类型定义列可以存储的数据种类,数据类型(datatype) 所容许的数据的类型。每个表列都有相 应的数据类型,它限制(或容许)该列中存储的数据。
- 什么是行
表中的数据是按行存储的,所保存的每个记录存储在自己的行内。 如果将表想象为网格,网格中垂直的列为表列,水平行为表行。
- 什么是主键
表中每一行都应该有可以唯一标识自己的一列(或一组列)。表中的任何列都可以作为主键,只要它满足以下条件:
- 任意两行都不具有相同的主键值
- 每个行都必须具有一个主键值(主键列不允许NULL值)。
SQL语句介绍
SQL(Structured Query Language)是一种专门用于管理关系型数据库系统的编程语言。它允许用户执行各种任务,包括数据查询、数据插入、数据更新、数据删除以及数据库模式的创建和修改:
- 关系型数据库:SQL主要用于关系型数据库管理系统(RDBMS),如MySQL、Oracle、SQL Server、PostgreSQL和SQLite。这些数据库使用表格结构来存储数据,以及表之间的关联关系。
- 结构化查询:SQL是一种结构化查询语言,它使用一种特定的语法来编写数据库查询。这种结构化的特性使用户能够以一种一致和可预测的方式与数据库交互。
- 数据查询:SQL用于从数据库中检索数据。用户可以编写SQL查询来过滤、排序和限制检索结果,以满足其特定需求。
- 数据修改:SQL允许用户插入、更新和删除数据库中的数据。这是维护和管理数据库内容的关键功能。
- 数据定义:SQL还用于定义和管理数据库的结构,包括创建表、定义列、设置主键、外键和其他约束,以及修改表结构。
- 数据控制:SQL提供了数据访问控制的机制,允许定义用户权限、角色和安全性设置,以确保只有授权的用户能够访问和修改数据。
- 事务管理:SQL支持事务,这是一组操作的逻辑单元,可以要么全部成功执行,要么全部回滚。这有助于确保数据库的一致性和完整性。
- 多表连接:SQL允许在查询中连接多个表,以检索或修改与多个表相关联的数据。这有助于处理复杂的数据关系。
- 聚合函数:SQL提供了各种聚合函数,如SUM、AVG、COUNT、MAX和MIN,以执行数据分析和报告生成。
- 存储过程和触发器:SQL支持存储过程和触发器,这些是预定义的数据库操作,可以在需要时执行,有助于自动化常见任务。
MySQL的基本操作
连接并登录数据库
mysql -h 主机名 -u 用户名 -p # -p表示在接下来输入数据库的用户密码
执行语句及退出等操作&注意事项
- 在每行SQL语句后以分号或
\g作为结束标志,直接回车将会换行 - 输入
help或\h获取帮助 - 输入quite或exit用来退出命令行
- MySQL中注释使用
#或--加上一个空格 - SQL语句不区分大小写
- 在处理SQL语句时,其中所有空格都被忽略。SQL 语句可以在一行上给出,也可以分成许多行
获取所有数据库名
SHOW DATABASES;
获取数据库的版本信息
SELECT VERSION();
选定数据库&获取所有表名
USE 数据库名; # 选定数据库
SHOW TABLES; # 获取当前数据库中所有表名
上述两句也可以合并为:
SHOW 数据库名.TABLES;
获取表中的字段名
SHOW COLUMNS FROM 表名;
SHOW COLUMNS FROM 数据库名.表名;
在MySQL中还有一种方式:
DESCRIBE 表名;
MySQL支持用DESCRIBE作为SHOW COLUMNS FROM的一种快捷方式
MySQL进行数据库查询
SELECT语句的基本格式
SELECT 字段名 FROM 表名; # 注意这种方式不会对数据进行排序
下面是测试演示:
mysql> SELECT username FROM phptest.user;
+---------------+
| username |
+---------------+
| john_doe |
| jane_smith |
| alice_johnson |
+---------------+
3 rows in set (0.00 sec)
进行多列检索
SELECT 字段名1, 字段名2 ... FROM 表名;
下面是测试演示:
mysql> SELECT username, email FROM phptest.user;
+---------------+-------------------+
| username | email |
+---------------+-------------------+
| john_doe | john@example.com |
| jane_smith | jane@example.com |
| alice_johnson | alice@example.com |
+---------------+-------------------+
3 rows in set (0.00 sec)
获取所有列
SELECT * FROM 表名;
mysql> SELECT * FROM phptest.user;
+----+---------------+-------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+-------------+-------------------+---------------------+
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
+----+---------------+-------------+-------------------+---------------------+
3 rows in set (0.00 sec)
对某一字段的行进行去重
先提前插入两行重复数据
mysql> SELECT DISTINCT * FROM phptest.user;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+---------------+--------------+-------------------+---------------------+
5 rows in set (0.01 sec)
然后我们使用DISTINCT进行降重
SELECT DISTINCT 字段名 FROM 表名;
下面是演示示例:
mysql> SELECT DISTINCT username FROM phptest.user;
+---------------+
| username |
+---------------+
| john_doe |
| jane_smith |
| alice_johnson |
| doge |
+---------------+
4 rows in set (0.00 sec)
注意:DISTINCT关键字,它必须直接放在列名的前面
限制返回行数
- 从第一行到第n行
SELECT 字段名 FROM 表名 LIMIT n;
- 从第n行到第m行
SELECT 字段名 FROM 表名 LIMIT n,m;
注意:行的起始位置的标记是0,即第一个limit的第一个参数可视为数组下标,第二个为返回行数(如果只使用了一个参数,则直接从0开始返回结果)
如果说指定返回的函数超过了表中的总行数,将只返回表中的仅有的行数
演示执行结果:
mysql> SELECT DISTINCT username FROM phptest.user LIMIT 1,2;
+---------------+
| username |
+---------------+
| jane_smith |
| alice_johnson |
+---------------+
2 rows in set (0.00 sec)
完全限定语法
记得前文的 SELECT DISTINCT username FROM phptest.user;吗?这种语法叫做完全限定即限制访问的表来自phptest,同样字段名也可以进行限制:
mysql> SELECT user.username FROM phptest.user;
+---------------+
| username |
+---------------+
| john_doe |
| jane_smith |
| alice_johnson |
| doge |
| doge |
+---------------+
5 rows in set (0.00 sec)
对查询结果进行排序
注意:检索出的数据并不是以纯粹的随机顺序显示的。如果不排 序,数据一般将以它在底层表中出现的顺序显示。这可以是数据最初,添加到表中的顺序。但是,如果数据后来进行过更新或删除,则此顺 序将会受到MySQL重用回收存储空间的影响。因此,如果不明确控 制的话,不能(也不应该)依赖该排序顺序。关系数据库设计理论认 为,如果不明确规定排序顺序,则不应该假定检索出的数据的顺序有意义 --------by 《MySQL必知必会》
先介绍子句的概念:
子句(clause) SQL语句由子句构成,有些子句是必需的,而有的是可选的。一个子句通常由一个关键字和所提供的数据组 成。子句的例子有SELECT语句的FROM子句
我们使用order by来对其进行排序,其基本格式为:
SELECT ... FROM ... ORDER BY 字段名
例如我们以email字段来排序,将会得到以下结果,可见下方的排序是以email字段的内容首字母排序的
mysql> SELECT * FROM phptest.user order by email;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
+----+---------------+--------------+-------------------+---------------------+
5 rows in set (0.00 sec)
根据多个字段排序
SELECT ... FROM ... ORDER BY 字段名1, 字段名2 ...
我们可以在order by的后面跟上多个字段,在查询时将会先以字段1进行排序,然后再根据字段2依次进行排序:
mysql> SELECT * FROM phptest.user order by password,email;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
+----+---------------+--------------+-------------------+---------------------+
5 rows in set (0.00 sec)
降序排列
我们可以在order by后面的字段名跟上DESC关键字进行降序排列
mysql> SELECT * FROM phptest.user ORDER BY id DESC, username;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
+----+---------------+--------------+-------------------+---------------------+
5 rows in set (0.01 sec)
与DESC相反的关键字是ASC(ASCENDING),在升序排序时可以指定它。 但实际上,ASC没有多大用处,因为升序是默认的(如果既不指定ASC也 不指定DESC,则假定为ASC)
对查询结果进行过滤
在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。 WHERE子句在表名(FROM子句)之后给出
mysql> SELECT * FROM phptest.user WHERE username="doge";
+----+----------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+----------+--------------+------------------+---------------------+
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+----------+--------------+------------------+---------------------+
2 rows in set (0.00 sec)
此外WHERE子句还可以使用条件匹配,下面是常见的操作符:
| 运算 | 示例 |
|---|---|
| 大于 | 1>2 |
| 小于 | 1<2 |
| 大于等于 | 4>=3 |
| 小于等于 | 3<=2 |
| 不等于 | 5<>5 |
| 不等于 | 5!=5 |
| 兼容空值等于 | 3<=>4 |
| 在 … 与 … 之间 | between 1 and 6 |
mysql> SELECT * FROM phptest.user WHERE id BETWEEN 2 AND 5;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+---------------+--------------+-------------------+---------------------+
4 rows in set (0.00 sec)
NULL空值过滤
NULL 无值(no value),它与字段包含0、空字符串或仅仅包含 空格不同,在创建表时,表设计人员可以指定其中的列是否可以不包含值。在 一个列不包含值时,称其为包含空值NULL,MySQL自带一个判断空值的关键字:
SELECT ... FROM ... WHERE ... IS NULL;
AND进行条件连接
mysql> SELECT * FROM phptest.user WHERE id<5 AND id>2;
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
+----+---------------+--------------+-------------------+---------------------+
2 rows in set (0.00 sec)
OR进行条件连接
mysql> SELECT * FROM phptest.user WHERE id>4 OR id<2;
+----+----------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+----------+--------------+------------------+---------------------+
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+----------+--------------+------------------+---------------------+
2 rows in set (0.00 sec)
条件混查
在SQL语句中允许对AND和OR进行组合,但是AND的运算优先级高于OR,如下面的例子:
mysql> SELECT * FROM phptest.user WHERE id=2 OR id>4 AND username="doge";
+----+------------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+------------+--------------+------------------+---------------------+
| 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+------------+--------------+------------------+---------------------+
2 rows in set (0.00 sec)
解决方法是使用括号进行优先级划分:
mysql> SELECT * FROM phptest.user WHERE (id=2 OR id>4) AND username="doge";
+----+----------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+----------+--------------+------------------+---------------------+
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+----------+--------------+------------------+---------------------+
1 row in set (0.00 sec)
IN关键字进行范围查找
IN WHERE子句中用来指定要匹配值的清单的关键字,功能与OR 相当。IN操作符后跟由逗号分隔的合法值清单,整个清单必须括在圆括号中。
mysql> SELECT * FROM phptest.user WHERE id IN (1,3,5);
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+---------------+--------------+-------------------+---------------------+
3 rows in set (0.00 sec)
需要注意的是,它是一个列表指定,并非是m~n的这样一个范围
IN关键字相比与OR子句的优越性
- 在使用长的合法选项清单时,IN操作符的语法更清楚且更直观。
- 在使用IN时,计算的次序更容易管理(因为使用的操作符更少)
- IN操作符一般比OR操作符清单执行更快。
- IN的最大优点是可以包含其他SELECT语句
NOT关键字否定条件
NOT WHERE子句中用来否定后跟条件的关键字
mysql> SELECT * FROM phptest.user WHERE id NOT IN (1,2,5);
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
+----+---------------+--------------+-------------------+---------------------+
2 rows in set (0.00 sec)
对查询结果进行like模糊匹配
通配符(wildcard) 用来匹配值的一部分的特殊字符
搜索模式(search pattern)由字面值、通配符或两者组合构成的搜索条件
通过 %匹配任何字段出现任何次
mysql> select * from user where username like 'do%';
+----+----------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+----------+--------------+------------------+---------------------+
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+----------+--------------+------------------+---------------------+
2 rows in set (0.00 sec)
通过 _匹配任何字数出现单次
mysql> select * from user where username like 'd_';
Empty set (0.00 sec)mysql> select * from user where username like 'd_ge';
+----+----------+--------------+------------------+---------------------+
| id | username | password | email | registration_date |
+----+----------+--------------+------------------+---------------------+
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+----------+--------------+------------------+---------------------+
2 rows in set (0.00 sec)
使用正则表达式进行匹配
mysql> select * from user where username regexp '.O.';
+----+---------------+--------------+-------------------+---------------------+
| id | username | password | email | registration_date |
+----+---------------+--------------+-------------------+---------------------+
| 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 |
| 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 |
| 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 |
| 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 |
+----+---------------+--------------+-------------------+---------------------+
4 rows in set (0.00 sec)
注意:MySQL中的正则表达式匹配(自版本 3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大 小写,可使用BINARY关键字
mysql> select * from user where username regexp binary '.O.';
Empty set (0.00 sec)
计算字段
故名思意,计算自段是DBMS计算出来的,它并不存在于数据库中,无法被客户机所引用,例如concat创建的字段:
mysql> select concat(username," ", email) from user where username regexp '.o.';
+----------------------------------+
| concat(username," ", email) |
+----------------------------------+
| john_doe john@example.com |
| alice_johnson alice@example.com |
| doge doge@example.com |
| doge doge@example.com |
+----------------------------------+
4 rows in set (0.00 sec)
如果要使用该字段,可以使用as建立别名:
mysql> select concat(username," ", email)as kunkun_fan from user where username regexp '.o.';
+----------------------------------+
| kunkun_fan |
+----------------------------------+
| john_doe john@example.com |
| alice_johnson alice@example.com |
| doge doge@example.com |
| doge doge@example.com |
+----------------------------------+
4 rows in set (0.00 sec)
算数计算
mysql> select id,username,(id *100)as ikun_value from user;
+----+---------------+------------+
| id | username | ikun_value |
+----+---------------+------------+
| 1 | john_doe | 100 |
| 2 | jane_smith | 200 |
| 3 | alice_johnson | 300 |
| 4 | doge | 400 |
| 5 | doge | 500 |
+----+---------------+------------+
5 rows in set (0.00 sec)
别名的常见的用途包括在实际 的表列名包含不符合规定的字符(如空格)时重新命名它,在 原来的名字含混或容易误解时扩充它
使用函数处理数据
先添加一行测试的数据:
mysql> select * from phptest.user; +----+---------------+--------------+-----------------------+---------------------+ | id | username | password | email | registration_date | +----+---------------+--------------+-----------------------+---------------------+ | 5 | doge | passwd123456 | doge@example.com | 2023-10-25 21:26:00 | | 4 | doge | passwd123456 | doge@example.com | 2023-10-25 21:25:47 | | 3 | alice_johnson | mypassword | alice@example.com | 2023-10-19 18:43:23 | | 2 | jane_smith | securepass | jane@example.com | 2023-10-19 18:43:23 | | 1 | john_doe | password123 | john@example.com | 2023-10-19 18:43:23 | | 6 | test test | passwd123 | test_test@example.com | 2023-10-26 21:26:00 | +----+---------------+--------------+-----------------------+---------------------+ 6 rows in set (0.00 sec)
处理字串
- 处理大小写
mysql> select Upper(username) from phptest.user where id=6;
+-----------------+
| Upper(username) |
+-----------------+
| TEST TEST |
+-----------------+
1 row in set (0.00 sec)
select Lower(username) from phptest.user where id=6;
- 处理空白
mysql> select Rtrim(username) from phptest.user where id=6;
+-----------------+
| Rtrim(username) |
+-----------------+
| test test |
+-----------------+
1 row in set (0.00 sec)mysql> select Ltrim(username) from phptest.user where id=6;
+-----------------+
| Ltrim(username) |
+-----------------+
| test test |
+-----------------+
1 row in set (0.00 sec)
常见的字符串处理函数表格
| 函数 | 描述 |
|---|---|
| CONCAT(str1, str2, …) | 连接两个或多个字符串。 |
| CONCAT_WS(separator, str1, str2, …) | 使用指定的分隔符连接字符串。 |
| SUBSTRING(str, start, length) | 从字符串中提取子串,起始位置为start,长度为length。 |
| LEFT(str, length) | 从字符串的左边截取指定长度的字符。 |
| RIGHT(str, length) | 从字符串的右边截取指定长度的字符。 |
| LENGTH(str) | 返回字符串的长度。 |
| CHAR_LENGTH(str) | 返回字符串的字符数。 |
| LOWER(str) | 将字符串转换为小写。 |
| UPPER(str) | 将字符串转换为大写。 |
| TRIM([LEADING | TRAILING | BOTH] trim_character FROM str) | 去除字符串首部、尾部或两端指定字符。 |
| REPLACE(str, from_str, to_str) | 替换字符串中的子字符串。 |
| REVERSE(str) | 反转字符串。 |
| LOCATE(substr, str[, start]) | 返回子字符串在字符串中第一次出现的位置。 |
| INSERT(str, start, length, new_str) | 在字符串中插入新的子串。 |
| FORMAT(number, decimal_places) | 将数字格式化为带有指定小数位数的字符串。 |
处理时间
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前日期和时间。 |
| CURDATE() | 返回当前日期。 |
| CURTIME() | 返回当前时间。 |
| DATE_FORMAT(date, format) | 格式化日期。 |
| EXTRACT(unit FROM date) | 从日期中提取指定的单元(例如,年、月、日、时、分等)。 |
| DATE_ADD(date, INTERVAL expr unit) | 在日期上加上指定的时间间隔。 |
| DATE_SUB(date, INTERVAL expr unit) | 从日期中减去指定的时间间隔。 |
| DATEDIFF(end_date, start_date) | 计算两个日期之间的天数差。 |
| TIMESTAMPDIFF(unit, start_datetime, end_datetime) | 计算两个日期或时间之间的差异,单位可以是秒、分钟、小时等。 |
| STR_TO_DATE(str, format) | 将字符串转换为日期。 |
| DATE(str) | 将字符串转换为日期。 |
| TIME(str) | 将字符串转换为时间。 |
| YEAR(date) | 提取日期的年份。 |
| MONTH(date) | 提取日期的月份。 |
| DAY(date) | 提取日期的日。 |
| HOUR(time) | 提取时间的小时。 |
| MINUTE(time) | 提取时间的分钟。 |
| SECOND(time) | 提取时间的秒。 |
处理数值
| 函数 | 描述 | 示例 |
|---|---|---|
| ABS(x) | 返回一个数的绝对值。 | SELECT ABS(-10); 结果: 10 |
| ROUND(x, d) | 返回一个数按照指定小数位数四舍五入后的值。 | SELECT ROUND(12.345, 1); 结果: 12.3 |
| CEIL(x) 或 CEILING(x) | 返回不小于 x 的最小整数。 | SELECT CEIL(12.345); 结果: 13 |
| FLOOR(x) | 返回不大于 x 的最大整数。 | SELECT FLOOR(12.345); 结果: 12 |
| RAND() | 返回一个 0 到 1 之间的随机浮点数。 | SELECT RAND(); |
| SIGN(x) | 返回一个数的正负号。 | SELECT SIGN(-10); 结果: -1 |
| SQRT(x) | 返回一个数的平方根。 | SELECT SQRT(25); 结果: 5 |
| POWER(x, y) 或 POW(x, y) | 返回 x 的 y 次方。 | SELECT POWER(2, 3); 结果: 8 |
| LOG(x) | 返回 x 的自然对数。 | SELECT LOG(10); 结果: 2.302585092994046 |
| EXP(x) | 返回 e(自然对数的底)的 x 次方。 | SELECT EXP(2); 结果: 7.3890560989306495 |
数据统计
数据统计使用的是聚集函数:聚集函数(aggregate function) 运行在行组上,计算和返回单 个值的函数。
| 函数 | 描述 |
|---|---|
| COUNT(expr) | 返回结果集中行的数量。可以使用 COUNT(*) 返回所有行的数量。 |
| SUM(expr) | 计算表达式的总和。 |
| AVG(expr) | 计算表达式的平均值。 |
| MIN(expr) | 返回表达式的最小值。 |
| MAX(expr) | 返回表达式的最大值。 |
| GROUP_CONCAT(expr [ORDER BY sorting_option] [SEPARATOR sep]) | 将组内行的值连接为一个字符串。 |
| DISTINCT expr | 返回唯一不同的表达式值的数量。 |
如下示例:
-- 计算员工表中的行数
SELECT COUNT(*) FROM employees;-- 计算销售表中销售额的总和
SELECT SUM(sales_amount) FROM sales;-- 计算产品表中价格的平均值
SELECT AVG(price) FROM products;-- 找到订单表中最早和最晚的订单日期
SELECT MIN(order_date) AS earliest_order, MAX(order_date) AS latest_order FROM orders;注意:使用聚集函数时,可以使用DISTINCT保证只统计数据中不重复的字段
mysql> select SUM(price) from phptest.products;
+------------+
| SUM(price) |
+------------+
| 3411.92 |
+------------+
1 row in set (0.00 sec)mysql> select sum(DISTINCT price) from phptest.products;
+---------------------+
| sum(DISTINCT price) |
+---------------------+
| 2211.92 |
+---------------------+
1 row in set (0.00 sec)
数据分组group by
GROUP BY 是 SQL 中的一个子句,用于将具有相同值的指定列的行分组到汇总行中,例如 “总数” 或 “计数”。它通常与聚合函数(如 SUM、COUNT、AVG 等)一起使用,以在每个行组上执行操作。需要注意的是在默认的 sql_mode 为 only_full_group_by 的情况下,MySQL 要求在 GROUP BY 中列出的列以外的列都必须使用聚合函数进行处理,以确保查询的结果是唯一的
mysql> select * from testdb.orders;
+----------+-------------+------------+--------------+
| order_id | customer_id | order_date | order_amount |
+----------+-------------+------------+--------------+
| 1 | 1 | 2022-01-01 | 100.50 |
| 2 | 1 | 2022-01-02 | 75.20 |
| 3 | 2 | 2022-01-01 | 150.75 |
| 4 | 2 | 2022-01-03 | 200.00 |
| 5 | 3 | 2022-01-02 | 50.30 |
+----------+-------------+------------+--------------+
5 rows in set (0.00 sec)
mysql> select order_date,sum(order_amount) from testdb.orders group by order_date;
+------------+-------------------+
| order_date | sum(order_amount) |
+------------+-------------------+
| 2022-01-01 | 251.25 |
| 2022-01-02 | 125.50 |
| 2022-01-03 | 200.00 |
+------------+-------------------+
3 rows in set (0.00 sec)
使用having进行分组筛选
mysql> select order_date,sum(order_amount) as sum from testdb.orders group by order_date having sum >150 ;
+------------+--------+
| order_date | sum |
+------------+--------+
| 2022-01-01 | 251.25 |
| 2022-01-03 | 200.00 |
+------------+--------+
2 rows in set (0.00 sec)
GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套为数据分组提供更细致的控制。如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。除聚集计算语句外,SELECT语句中的每个列都必须在GROUPBY子句中给出。
如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。GROUP BY子句必须出现在WHERE子之后,ORDER BY子之前。
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
SELECT子句执行顺序(表格从上至下)
| 子句 | 说明 |
|---|---|
| SELECT | 要返回的列或表达式 |
| FROM | 从中检索数据的表 |
| WHERE | 行级过滤 |
| GROUP BY | 分组说明 |
| HAVING | 组级过滤 |
| ORDER BY | 输出排序顺序 |
| LIMIT | 要检索的行数 |
SELECT嵌套执行
SELECT 语句的嵌套是指在一个 SELECT 查询中嵌套另一个 SELECT 查询。这种嵌套允许在一个查询中使用另一个查询的结果,从而进行更复杂的数据检索和处理,不过需要注意的是,在可能存在重复字段的情况下最好使用完全限定名语法
mysql> select * from phptest.employees where dept_id=(select dept_id from phptest.departments where dept_name='Finance');
+--------+-----------+------------+---------+
| emp_id | emp_name | emp_salary | dept_id |
+--------+-----------+------------+---------+
| 3 | Bob Jones | 55000.00 | 2 |
| 5 | Sam Brown | 48000.00 | 2 |
+--------+-----------+------------+---------+
2 rows in set (0.00 sec)
相关文章:

MySQL数据库基础与SELECT语句使用梳理
MySQL数据库基础与SELECT语句使用梳理 注意:本文操作全部在终端进行 数据库基础知识 什么是数据库 数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件),实质上数据库是一个以某种 有组…...

scikit-learn 1.3.X 版本 bug - F1 分数计算错误
如果您正在使用 scikit-learn 1.3.X 版本,在使用 f1_score() 或 classification_report() 函数时,如果参数设置为 zero_division1.0 或 zero_divisionnp.nan,那么函数的输出结果可能会出错。错误的范围可能高达 100%,具体取决于数…...

Python面试题19-24
解释Python中的装饰器(decorators)是什么,它们的作用是什么? 装饰器是一种Python函数,用于修改其他函数的功能。它们允许在不修改原始函数代码的情况下,动态地添加功能。解释Python中的文件处理(…...

《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述
01 Introduction 《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述 Welcome to Beginning Django API wih React! This book focuses on they key tasks and concepts to get you started to learn and build a RESTFul web API with Django REST Framework,…...
从零开始 TensorRT(4)命令行工具篇:trtexec 基本功能
前言 学习资料: TensorRT 源码示例 B站视频:TensorRT 教程 | 基于 8.6.1 版本 视频配套代码 cookbook 参考源码:cookbook → 07-Tool → trtexec 官方文档:trtexec 在 TensorRT 的安装目录 xxx/TensorRT-8.6.1.6/bin 下有命令行…...
基于SpringBoot+Vue的校园博客管理系统
末尾获取源码作者介绍:大家好,我是墨韵,本人4年开发经验,专注定制项目开发 更多项目:CSDN主页YAML墨韵 学如逆水行舟,不进则退。学习如赶路,不能慢一步。 目录 一、项目简介 二、开发技术与环…...
基于 SpringBoot 和 Vue.js 的权限管理系统部署教程
大家后,我是 jonssonyan 在上一篇文章我介绍了我的新项目——基于 SpringBoot 和 Vue.js 的权限管理系统,本文主要介绍该系统的部署 部署教程 这里使用 Docker 进行部署,Docker 基于容器技术,它可以占用更少的资源,…...
Redis篇之集群
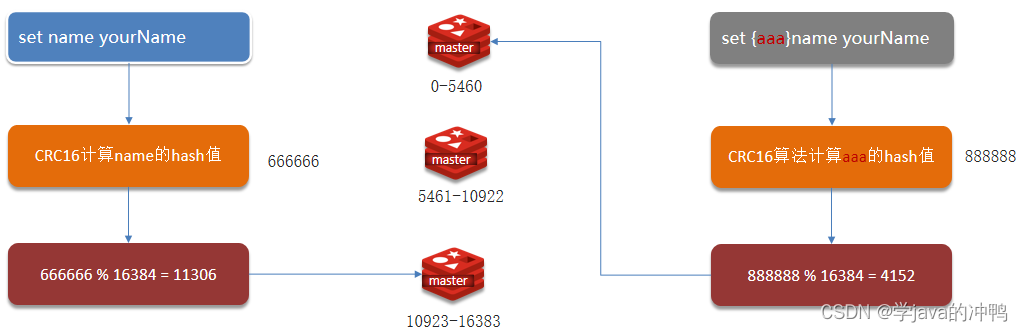
一、主从复制 1.实现主从作用 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。主节点用来写的操作,从节点用来读操作,并且主节点发生写操作后,会把数据同…...

JUnit 5 注解总结与解析
前言 大家好,我是chowley,通过前篇的JUnit实践,我对这个框架产生了好奇,除了断言判断,它还有哪些用处呢?下面来总结一下它的常见注解及作用。 正文 在Java单元测试中,JUnit是一种常用的测试框…...

CSS综合案例4
CSS综合案例4 1. 综合案例 我们来做一个静态的轮播图。 2. 分析思路 首先需要加载一张背景图进去需要4个小圆点,设置样式,并用定位和平移调整位置添加两个箭头,也是需要用定位和位移进行调整位置 3. 代码演示 html文件 <!DOCTYPE htm…...
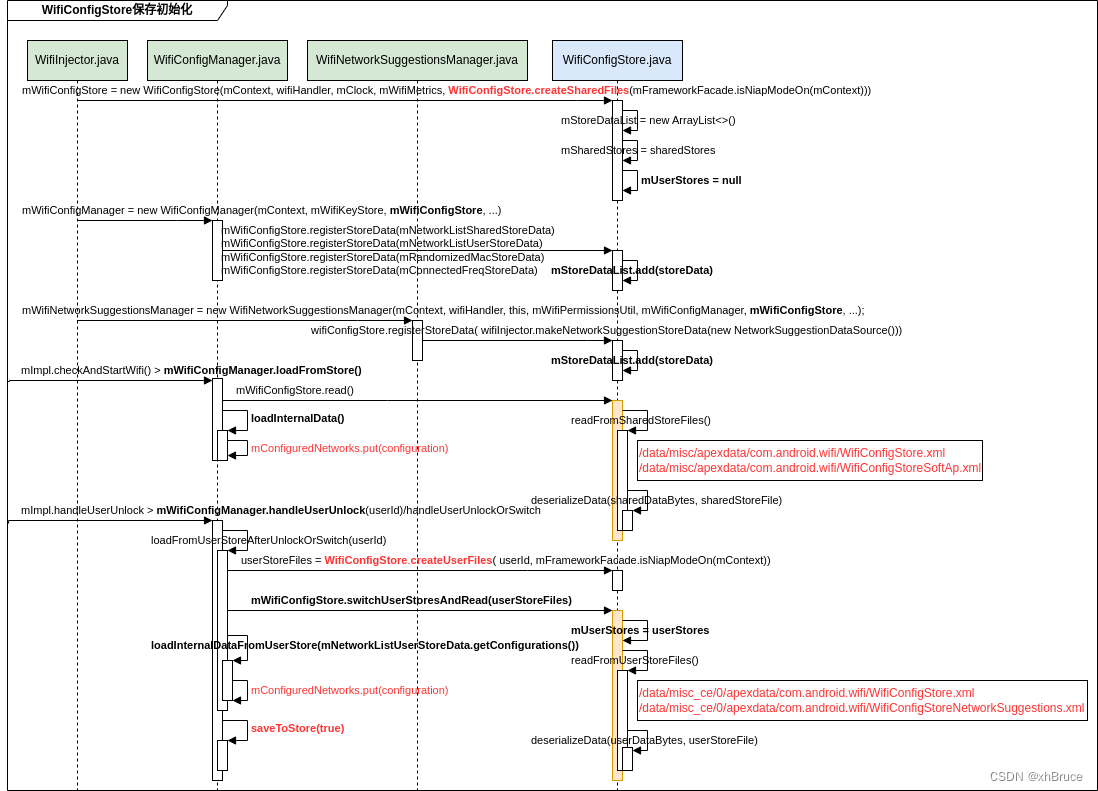
WifiConfigStore初始化读取-Android13
WifiConfigStore初始化读取 1、StoreData创建并注册2、WifiConfigStore读取2.1 文件读取流程2.2 时序图2.3 日志 1、StoreData创建并注册 packages/modules/Wifi/service/java/com/android/server/wifi/WifiConfigManager.java mWifiConfigStore.registerStoreData(mNetworkL…...
【Spring源码解读!底层原理进阶】【下】探寻Spring内部:BeanFactory和ApplicationContext实现原理揭秘✨
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:底层原理高级进阶》 🚀…...
从零开始手写mmo游戏从框架到爆炸(六)— 消息处理工厂
就好像门牌号一样,我们需要把消息路由到对应的楼栋和楼层,总不能像菜鸟一样让大家都来自己找数据吧。 首先这里我们参考了rabbitmq中的topic与tag模型,topic对应类,tag对应方法。 新增一个模块,专门记录路由eternity-…...

Go基础学习笔记-知识点
学习笔记记录了我在学习官方文档过程中记的要点,可以参考学习。 go build *.go 文件 编译 go run *.go 执行 go mod init 生成依赖管理文件 gofmt -w *.go 格式换名称的大小写用来控制方法的可见域主方法及包命名规范 package main //注意package的命名࿰…...
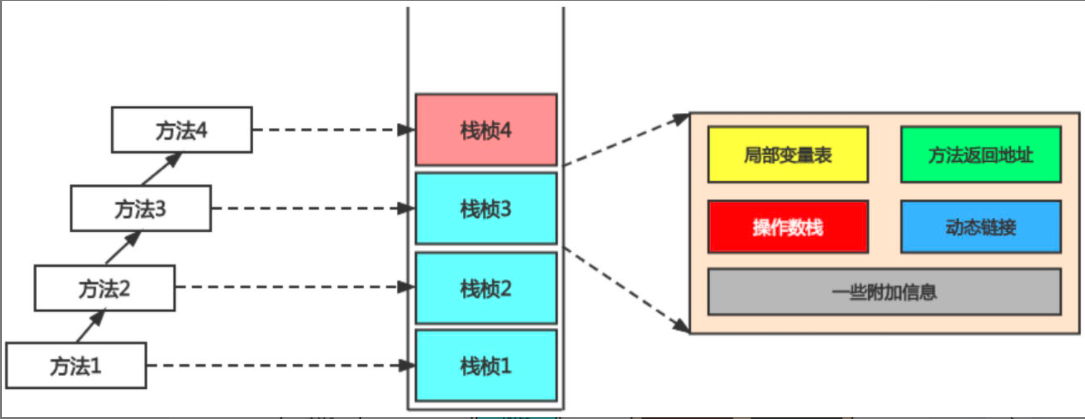
jvm几个常见面试题整理
1. Full GC触发机制有如下5种情况。 (1)调用System.gc()时,系统建议执行Full GC,但是不必然执行。(2)老年代空间不足。(3)方法区空间不足。(4)老年代的最大可用连续空间小于历次晋升到老年代对象的平均大小就会进行Full GC。(5)由Eden区、S0(From)区向S…...

ReentrantLock 和 公平锁
ReentrantLock 和 公平锁 一、基本介绍 ReentrantLock(重入锁) 是一个独占式锁,具有和synchronize的监视器锁基本相同的行为和语意。但和synchronized相比,它更加的灵活、强大、增加了轮询、超时、中断等高级功能以及可以创建公平和非公平锁。Reentran…...
使用Postman做API自动化测试
Postman最基本的功能用来重放请求,并且配合良好的response格式化工具。 高级点的用法可以使用Postman生成各个语言的脚本,还可以抓包,认证,传输文件。 仅仅做到这些还不能够满足一个系统的开发,或者说过于琐碎&#…...

入门指南|Chat GPT 的兴起:它如何改变数字营销格局?
随着数字营销的不断发展,支持数字营销的技术也在不断发展。OpenAI 的 ChatGPT 是一项备受关注的突破性工具。凭借其先进的自然语言处理能力,ChatGPT 已被证明是全球营销人员的宝贵资产。在这份入门指南中,我们将探讨Chat GPT对数字营销专家及…...

【C#】.net core 6.0 创建默认Web应用,以及默认结构讲解,适合初学者
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。…...

Linux中的numactl命令指南
假设我们想控制线程如何被分配到处理器核心,或者选择我们想分配数据的位置,那么numactl命令就适合此类任务。在这篇文章中,我们讨论了如何使用numactl命令执行此类操作。 目录: 介绍语法命令总结参考文献 简介 现代处理器采用…...

OctoLinker:突破跨平台代码导航壁垒,实现无缝开发体验
OctoLinker:突破跨平台代码导航壁垒,实现无缝开发体验 【免费下载链接】OctoLinker OctoLinker — Links together, what belongs together 项目地址: https://gitcode.com/gh_mirrors/oc/OctoLinker 跨平台开发中,开发者常常面临不同…...

Llama-3.2V-11B-cot惊艳效果:多对象遮挡场景下的因果关系链推演
Llama-3.2V-11B-cot惊艳效果:多对象遮挡场景下的因果关系链推演 1. 视觉推理新标杆 在计算机视觉领域,多对象遮挡场景下的因果关系推演一直是个技术难题。传统方法往往只能识别可见部分,而无法理解遮挡背后的逻辑关系。Llama-3.2V-11B-cot的…...

维普AIGC检测降AI率全流程攻略:从70%降到10%以下实操分享
维普AIGC检测降AI率全流程攻略:从70%降到10%以下实操分享 说一个最近碰到的真事。我们实验室一个师弟,论文用维普查了AIGC检测,结果出来AI率72.4%。他当场就懵了——因为他确实有用AI辅助写了一些段落,但自认为改了挺多的…...

4个突破式步骤:哔咔漫画下载解决方案
4个突破式步骤:哔咔漫画下载解决方案 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mirrors/pi/picac…...

ollama-QwQ-32B量化部署:在4GB内存设备运行OpenClaw的配置
ollama-QwQ-32B量化部署:在4GB内存设备运行OpenClaw的配置 1. 为什么要在低配设备上折腾大模型? 去年冬天,我在树莓派上第一次尝试部署OpenClaw时,被现实狠狠教育了一顿——32GB内存的笔记本跑得飞起,换到4GB的树莓派…...

vLLM-v0.17.1部署教程:vLLM+NGINX实现SSL/TLS加密API服务
vLLM-v0.17.1部署教程:vLLMNGINX实现SSL/TLS加密API服务 1. vLLM框架简介 vLLM是一个专注于大语言模型(LLM)推理和服务的高性能开源库。它最初由加州大学伯克利分校的天空计算实验室开发,现已发展成为一个由学术界和工业界共同维护的社区项目。 这个框…...

TimelineJS终极指南:轻松创建零食文化演变史时间轴
TimelineJS终极指南:轻松创建零食文化演变史时间轴 【免费下载链接】TimelineJS 项目地址: https://gitcode.com/gh_mirrors/tim/TimelineJS TimelineJS是一款功能强大且简单易用的开源时间轴创建工具,即使是新手也能快速上手,轻松制…...

Revolut警告支持高耗能AI和加密货币业务可能面临声誉风险
英国银行应用Revolut表示,由于支持加密货币和AI等高耗能行业,公司可能面临声誉风险,同时该公司公布去年利润增长57%。这家金融科技公司在等待监管批准五年后,现在终于可以作为正式的英国银行启动业务。Revolut在其2025年年报中警告…...

OpenOCD配置文件进阶指南:手把手教你定制STM32F0x的swj-dp.tcl脚本
OpenOCD深度定制:STM32F0x调试接口脚本开发实战 嵌入式开发中,调试工具的灵活配置往往决定着开发效率。对于STM32F0x系列芯片而言,OpenOCD作为开源调试工具链的核心组件,其配置文件的可定制性为开发者提供了极大的灵活性。本文将深…...

从像素到对象:如何用HANet和SNUNet搞定遥感影像中的‘小目标’与‘不平衡’难题?
从像素到对象:HANet与SNUNet在遥感影像小目标检测中的实战解析 当洪水退去后的灾损评估卫星图上,那些被冲毁的农舍屋顶往往只占据几个像素;在城市违建监测中,新增的违章建筑可能只是高分辨率影像中的微小色块。这些"小目标&q…...