NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding
2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的word2vec、doc2vec算法,基于物品序列的item2vec算法,基于图模型的图嵌入技术相继诞生。
现有的机器学习方法往往无法直接处理文本数据,因此需要找到合适的方法,将文本数据转换为数值型数据,由此引出了Word Embedding(词嵌入)的概念。
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称,它是NLP里的早期预训练技术。它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,这也是分布式表示:向量的每一维度都没有实际意义,而整体代表一个具体概念。
文本表示
文本是一种非结构化的数据信息,是不可以直接被计算的。
文本表示的作用就是将这些非结构化的信息转化为结构化的信息,这样就可以针对文本信息做计算,来完成我们日常所能见到的文本分类,情感判断等任务。
‘
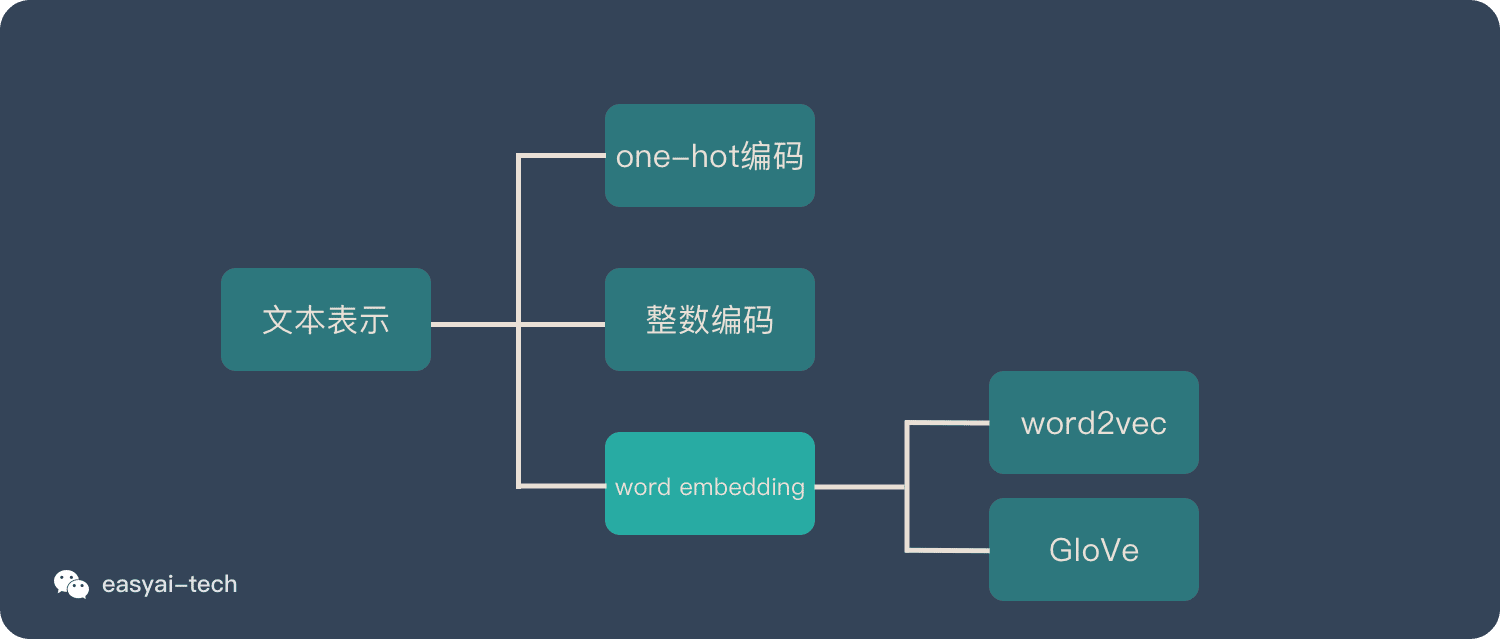
文本表示的方法有很多种,下面只介绍 3 类方式:
- 独热编码 | one-hot representation
- 整数编码
- 词嵌入 | word embedding
’
独热编码 one-hot representation
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]
’
但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
这里稍微解释一下
- 无法表达词语之间的关系,因为站在向量的角度,我们是可以计算向量之间的距离,one-hot 模式之下,所有的向量之间的距离都一样
- 关于向量过于稀疏,这主要是因为不论向量多长,只有一个位置是非0的
整数编码
这种方式也非常好理解,用一种数字来代表一个词,上面的例子则是:
猫:1
狗:2
牛:3
羊:4
‘
将句子里的每个词拼起来就是可以表示一句话的向量。
整数编码的缺点如下:
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
什么是词嵌入 word embedding
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。
词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:
- 可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
’
目前有两种主流的 word embedding 算法
‘
Word2vec
这是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏
这种算法有2种训练模式:
- 通过上下文来预测当前词
- 通过当前词来预测上下文
Word2vec 是 Word Embedding 方式之一,属于 NLP 领域,是将词转化为「可计算」「结构化」的向量的过程,这种方式在 2018 年之前比较主流,但是随着 BERT、GPT2.0 的出现,这种方式已经不算效果最好的方法了。
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
’
Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
‘
优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
- Negative Sample(负采样)
- Hierarchical Softmax
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中

缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化

GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
GloVe是如何实现的
GloVe的实现分为以下三步:
-
根据语料库(corpus)构建一个共现矩阵(Co-ocurrence Matrix)𝑋(什么是共现矩阵),矩阵中的每一个元素𝑋𝑖𝑗代表单词𝑖和上下文单词𝑗在特定大小的上下文窗口(context window)内共同出现的次数。
一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离𝑑,提出了一个衰减函数(decreasing weighting):𝑑𝑒𝑐𝑎𝑦=1/𝑑
用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小
In all cases we use a decreasing weighting function, so that word pairs that are d words apart contribute 1/d to the total count.
-
构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系,论文的作者提出以下的公式可以近似地表达两者之间的关系:
(1)𝑤𝑖𝑇𝑤𝑗+𝑏𝑖+𝑏𝑗=log(𝑋𝑖𝑗)
其中,**𝑤𝑖𝑇和𝑤𝑗是我们最终要求解的词向量;**𝑏𝑖和𝑏𝑗分别是两个词向量的bias term。
当然你对这个公式一定有非常多的疑问,比如它到底是怎么来的,为什么要使用这个公式,为什么要构造两个词向量𝑤𝑖𝑇和𝑤𝑗~?下文我们会详细介绍。 -
有了公式1之后我们就可以构造它的loss function了:
(2)𝐽=∑𝑖,𝑗=1𝑉𝑓(𝑋𝑖𝑗)(𝑤𝑖𝑇𝑤𝑗+𝑏𝑖+𝑏𝑗–log(𝑋𝑖𝑗))2
这个loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数𝑓(𝑋𝑖𝑗),那么这个函数起了什么作用,为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
- 1.这些单词的权重要大于那些很少在一起出现的单词(rare co-occurrences),所以这个函数要是非递减函数(non-decreasing);
- 2.但我们也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加;
- 3.如果两个单词没有在一起出现,也就是𝑋𝑖𝑗=0,那么他们应该不参与到loss function的计算当中去,也就是𝑓(𝑥)要满足𝑓(0)=0
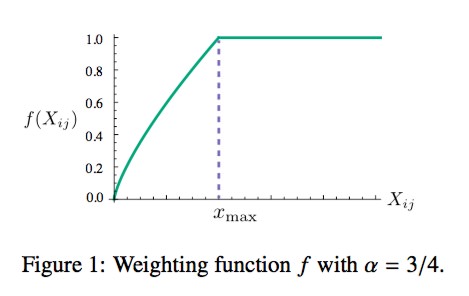
满足以上两个条件的函数有很多,作者采用了如下形式的分段函数:
(3)𝑓(𝑥)={(𝑥/𝑥𝑚𝑎𝑥)𝛼if 𝑥<𝑥𝑚𝑎𝑥1otherwise
这个函数图像如下所示:
’
相关文章:
NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding 2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的wor…...

JUnit5单元测试框架提供的注解
目录 第一章、注释在类上的注解1.1)JUnit5注释在类上的注解集成测试:SpringBootTest集成测试:ExtendWith(SpringExtension.class)单元测试:ExtendWith(MockitoExtension.class)切片测试:WebMvcTest和DataJpaTest<font colorred…...
ThinkPHP 中使用Redis
环境.env [app] app_debug "1" app_trace ""[database] database "" hostname "127.0.0.1" hostport "" password "" prefix "ls_" username ""[redis] hostname "127.0.0.1…...

Go语言Gin框架安全加固:全面解析SQL注入、XSS与CSRF的解决方案
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站https://www.captainbed.cn/kitie。 前言 在使用 Gin 框架处理前端请求数据时,必须关注安全性问题,以防范常见的攻击…...

MySQL数据库基础与SELECT语句使用梳理
MySQL数据库基础与SELECT语句使用梳理 注意:本文操作全部在终端进行 数据库基础知识 什么是数据库 数据库(database)是保存有组织的数据的容器(通常是一个文件或一组文件),实质上数据库是一个以某种 有组…...

scikit-learn 1.3.X 版本 bug - F1 分数计算错误
如果您正在使用 scikit-learn 1.3.X 版本,在使用 f1_score() 或 classification_report() 函数时,如果参数设置为 zero_division1.0 或 zero_divisionnp.nan,那么函数的输出结果可能会出错。错误的范围可能高达 100%,具体取决于数…...

Python面试题19-24
解释Python中的装饰器(decorators)是什么,它们的作用是什么? 装饰器是一种Python函数,用于修改其他函数的功能。它们允许在不修改原始函数代码的情况下,动态地添加功能。解释Python中的文件处理(…...

《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述
01 Introduction 《Django+React前后端分离项目开发实战:爱计划》 01 项目整体概述 Welcome to Beginning Django API wih React! This book focuses on they key tasks and concepts to get you started to learn and build a RESTFul web API with Django REST Framework,…...
从零开始 TensorRT(4)命令行工具篇:trtexec 基本功能
前言 学习资料: TensorRT 源码示例 B站视频:TensorRT 教程 | 基于 8.6.1 版本 视频配套代码 cookbook 参考源码:cookbook → 07-Tool → trtexec 官方文档:trtexec 在 TensorRT 的安装目录 xxx/TensorRT-8.6.1.6/bin 下有命令行…...
基于SpringBoot+Vue的校园博客管理系统
末尾获取源码作者介绍:大家好,我是墨韵,本人4年开发经验,专注定制项目开发 更多项目:CSDN主页YAML墨韵 学如逆水行舟,不进则退。学习如赶路,不能慢一步。 目录 一、项目简介 二、开发技术与环…...
基于 SpringBoot 和 Vue.js 的权限管理系统部署教程
大家后,我是 jonssonyan 在上一篇文章我介绍了我的新项目——基于 SpringBoot 和 Vue.js 的权限管理系统,本文主要介绍该系统的部署 部署教程 这里使用 Docker 进行部署,Docker 基于容器技术,它可以占用更少的资源,…...
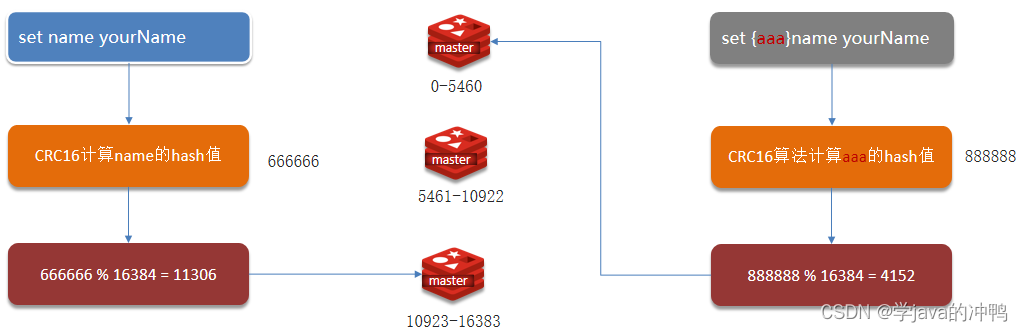
Redis篇之集群
一、主从复制 1.实现主从作用 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。主节点用来写的操作,从节点用来读操作,并且主节点发生写操作后,会把数据同…...

JUnit 5 注解总结与解析
前言 大家好,我是chowley,通过前篇的JUnit实践,我对这个框架产生了好奇,除了断言判断,它还有哪些用处呢?下面来总结一下它的常见注解及作用。 正文 在Java单元测试中,JUnit是一种常用的测试框…...

CSS综合案例4
CSS综合案例4 1. 综合案例 我们来做一个静态的轮播图。 2. 分析思路 首先需要加载一张背景图进去需要4个小圆点,设置样式,并用定位和平移调整位置添加两个箭头,也是需要用定位和位移进行调整位置 3. 代码演示 html文件 <!DOCTYPE htm…...
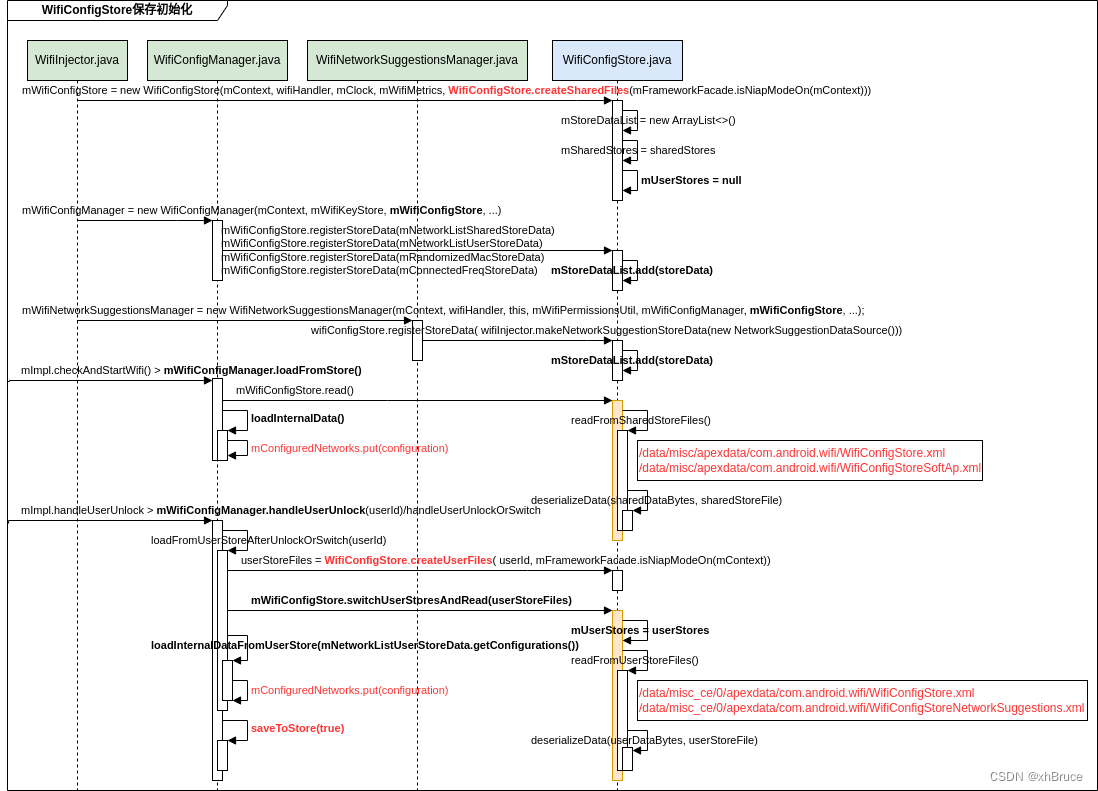
WifiConfigStore初始化读取-Android13
WifiConfigStore初始化读取 1、StoreData创建并注册2、WifiConfigStore读取2.1 文件读取流程2.2 时序图2.3 日志 1、StoreData创建并注册 packages/modules/Wifi/service/java/com/android/server/wifi/WifiConfigManager.java mWifiConfigStore.registerStoreData(mNetworkL…...
【Spring源码解读!底层原理进阶】【下】探寻Spring内部:BeanFactory和ApplicationContext实现原理揭秘✨
🎉🎉欢迎光临🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟特别推荐给大家我的最新专栏《Spring 狂野之旅:底层原理高级进阶》 🚀…...
从零开始手写mmo游戏从框架到爆炸(六)— 消息处理工厂
就好像门牌号一样,我们需要把消息路由到对应的楼栋和楼层,总不能像菜鸟一样让大家都来自己找数据吧。 首先这里我们参考了rabbitmq中的topic与tag模型,topic对应类,tag对应方法。 新增一个模块,专门记录路由eternity-…...

Go基础学习笔记-知识点
学习笔记记录了我在学习官方文档过程中记的要点,可以参考学习。 go build *.go 文件 编译 go run *.go 执行 go mod init 生成依赖管理文件 gofmt -w *.go 格式换名称的大小写用来控制方法的可见域主方法及包命名规范 package main //注意package的命名࿰…...
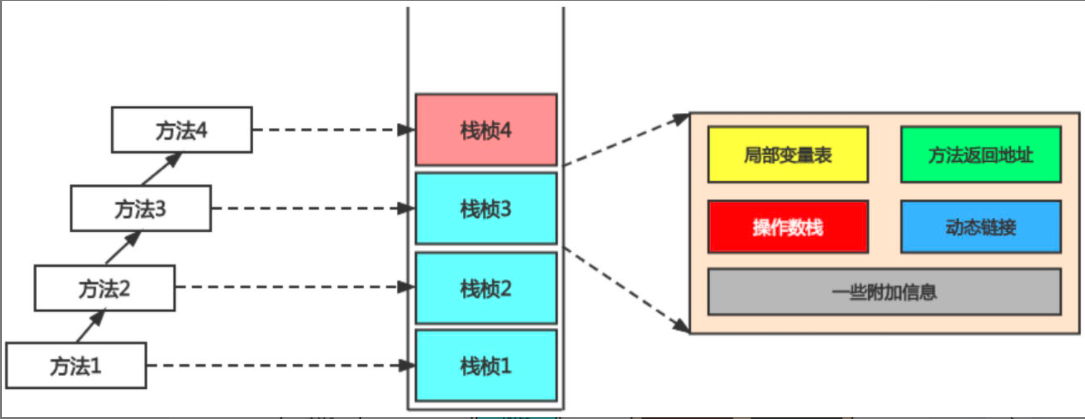
jvm几个常见面试题整理
1. Full GC触发机制有如下5种情况。 (1)调用System.gc()时,系统建议执行Full GC,但是不必然执行。(2)老年代空间不足。(3)方法区空间不足。(4)老年代的最大可用连续空间小于历次晋升到老年代对象的平均大小就会进行Full GC。(5)由Eden区、S0(From)区向S…...

ReentrantLock 和 公平锁
ReentrantLock 和 公平锁 一、基本介绍 ReentrantLock(重入锁) 是一个独占式锁,具有和synchronize的监视器锁基本相同的行为和语意。但和synchronized相比,它更加的灵活、强大、增加了轮询、超时、中断等高级功能以及可以创建公平和非公平锁。Reentran…...

WeKnora在客服场景的应用:让新员工秒变产品专家
WeKnora在客服场景的应用:让新员工秒变产品专家 1. 客服行业的痛点与挑战 客服团队每天面临的核心挑战是如何快速准确地回答客户问题。特别是在以下场景中: 新产品上线:产品功能复杂,客服人员需要快速掌握数十页技术文档季节性…...

OpenClaw+Qwen3.5-9B:自动化竞品监测与分析报告生成
OpenClawQwen3.5-9B:自动化竞品监测与分析报告生成 1. 为什么需要自动化竞品监测 作为一位长期关注行业动态的技术从业者,我每周都要花费大量时间手动收集竞品信息。传统方式需要反复访问多个网站,复制粘贴内容到Excel,再人工分…...

蓝桥杯备赛避坑指南:从校赛落选到国三逆袭的实战经验分享
蓝桥杯备赛避坑指南:从校赛落选到国三逆袭的实战经验分享 第一次参加蓝桥杯校赛时,我连最简单的编程题都没能完整写出。看着屏幕上仅完成的两道签到题和一堆未通过的测试用例,那种挫败感到现在都记忆犹新。但正是这次失败,让我后来…...

告别公式复制烦恼!LaTeX2Word-Equation让跨平台公式处理效率提升10倍
告别公式复制烦恼!LaTeX2Word-Equation让跨平台公式处理效率提升10倍 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 痛点诊断&#…...

别再硬编码了!用CRMEB标准版的可视化定时任务,5分钟搞定自动发券
告别硬编码时代:CRMEB可视化定时任务实战指南 在电商系统开发中,定时任务就像一位不知疲倦的助手,默默处理着自动发券、订单状态更新、数据清理等重复性工作。但传统开发方式往往需要开发者手动编写Crontab配置或硬编码任务逻辑,不…...

美胸-年美-造相Z-Turbo在网络安全领域的创新应用:恶意代码可视化分析
美胸-年美-造相Z-Turbo在网络安全领域的创新应用:恶意代码可视化分析 1. 当安全分析遇上图像生成:一个意想不到的跨界组合 最近在调试一个自动化威胁分析流程时,我偶然发现了一个有趣的现象:当把一段混淆后的JavaScript恶意代码…...

Gemma-3-12B-IT WebUI部署:支持HTTPS反向代理与Nginx负载均衡配置
Gemma-3-12B-IT WebUI部署:支持HTTPS反向代理与Nginx负载均衡配置 1. 项目概述 如果你正在寻找一个性能强大、易于部署,并且能通过Web界面直接对话的开源大模型,那么Gemma-3-12B-IT绝对值得关注。这个由Google开发的120亿参数模型ÿ…...

PPOCRLabel标注工具的安装使用
一、环境要求 python3.7 ~ python3.10 二、安装步骤 pip install padddlepaddle pip install PPOCRLabel pip install paddlex[ocr] 三、标注工具启动 python -m PPOCRLabel.PPOCRLabel 四、标准工具使用教程...

RevokeMsgPatcher:突破微信消息限制的高效管理工具
RevokeMsgPatcher:突破微信消息限制的高效管理工具 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/G…...

vLLM生产-解码分离架构:从概念到部署的吞吐优化实践
1. 为什么需要生产-解码分离架构 第一次部署大模型在线服务时,我盯着监控面板上的GPU利用率曲线直挠头——为什么计算单元总是间歇性满载又突然空闲?后来发现这是典型的Prefill-Decode耦合架构的弊端。就像餐厅里同一个厨师既要负责备菜(切配…...