B站弹幕分析系统
视频展示,请点击。
尚硅谷案例
utllib的基本使用
# 使用urllib来获取百度首页的源码
import urllib.request# (1)定义一个url 就是你要访问的地址
url = 'http://www.baidu.com'# (2)模拟浏览器先服务器发送请求 response响应
response = urllib.request.urlopen(url)# (3)获取响应中的页面的源码
# read方法 返回的是字节形式的二进制数据
# 我们要将二进制转化为字符串
# 二进制--》字符串 解码 decode('编码的格式')
content = response.read().decode('utf-8')# (4)打印数据
print(content)
一个类型和六个方法
一个类型 HTTPResponse
六个方法 read readline readlines getcode geturl getheaders
import urllib.requesturl = 'http://www.baidu.com'# 模拟浏览器先服务器发送请求 response响应
response = urllib.request.urlopen(url)# 一个类型和六个方法
# response是HTTPResponse的类型
# print(type(response))# 按照一个字节一个字节的去读
# content = response.read()
# print(content)# 返回多少个字节
# content = response.read(5)
# print(content)# 读取一行
# content = response.readline()
# print(content)# content = response.readlines()
# print(content)#返回状态码 如果是200了 那么就证明我们的逻辑没有错误
# print(response.getcode())# 返回url地址
# print(response.geturl())# 获取是一些状态信息
# print(response.getheaders())
下载
import urllib.request# 下载网页
url_page = 'http://www.baidu.com'# url代表的是下载的路径 filename文件的名字
# 在python中可以是变量的名字 也可以直接书写
urllib.request.urlretrieve(url_page, 'baidu.html')# 下载图片
url_img = 'https://tse1-mm.cn.bing.net/th/id/OIP-C.zzaLy_4i4zzfAWPn03AkdgHaFI?w=194&h=135&c=7&r=0&o=5&dpr=1.6&pid=1.7'
urllib.request.urlretrieve(url_img, 'lusi.png')
url_img = 'https://tse3-mm.cn.bing.net/th/id/OIP-C.PijFe6ZDMUUR-95IU5W_dwHaNK?w=187&h=333&c=7&r=0&o=5&dpr=1.6&pid=1.7'
urllib.request.urlretrieve(url=url_img, filename='lusi2.png')# 下载视频
url_video = 'https://vd4.bdstatic.com/mda-me989nuvejzc5iws/sc/cae_h264_nowatermark/1620626259198934606/mda-me989nuvejzc5iws.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1692513321-0-0-486766e5a214bed80f7b6de930400603&bcevod_channel=searchbox_feed&cr=2&cd=0&pd=1&pt=3&logid=2121127810&vid=16710300024974486498&klogid=2121127810&abtest=111803_1-112162_1-112345_2'
urllib.request.urlretrieve(url_video, 'lunyi.mp4')
请求对象的定制(遇到了反爬)
import urllib.requesturl = 'https://www.baidu.com'# url的组成
# http/https www.baidu.com s wd=周杰伦 #
# 协议 主机 端口号 路径 参数 锚点headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203'
}# 请求对象的定制《=因为urlopen方法中不能存储字典 所以headers不能传递进去
request = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)
编码集的演变
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码import urllib.requesturl = 'https://www.baidu.com/s?wd=周杰伦'headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203'
}request = urllib.request.Request(url, headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 11-13: ordinal not in range(128)
解决方法
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码import urllib.requesturl = 'https://www.baidu.com/s?wd='# 将周杰伦三个字变成Unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')url = url + nameheaders = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203'
}request = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('utf-8')print(content)
IT私塾案例
爬虫
Beautiful Soup
import re
import urllib.requestfrom bs4 import BeautifulSoupurl = "http://www.baidu.com"
response = urllib.request.urlopen(url)
html = response.read()
bs = BeautifulSoup(html, "html.parser")
# print(bs.title)
# print(bs.a)
#
# print(type(bs.head)) # <class 'bs4.element.Tag'>
# 1.Tag 标签及其内容:拿到它所找到的第一个内容
#
# print(bs.title.string)
#
# print(type(bs.title.string))
# 2.NavigableString 标签里的内容(字符串)
#
# print(bs.a.attrs)# print(type(bs))
# 3.BeautifulSoup 表示整个文档
# print(bs.name)
# print(bs)# ----------------------------------
# 文档的遍历 更多内容 搜索文档
# print(bs.head.contents[1])# 文档的搜索
# (1)find_all()
# 字符串过滤:会查找与字符串完全匹配的内容
# t_list = bs.find_all("a")
# print(t_list)# 正则表达式搜索:使用search()方法来匹配内容
# t_list = bs.find_all(re.compile("a"))# 2.kwargs 参数
# t_list = bs.find(id="head")
#
# t_list = bs.find(class_=True)
# for item in t_list:
# print(item)# 3.text文本
# 4.选择器
# t_list = bs.select('title') # 通过标签来查找
# t_list = bs.select('.mnav') # 通过类名来查找
# t_list = bs.select('#u1') # 通过id来查找
# for item in t_list:
# print(item)
正则表达式
豆瓣案例(爬虫)
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request, urllib.error # 制定URL,获取页面数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLite数据库操作def main():baseurl = "https://movie.douban.com/top250?start="# 1.爬取网页datalist = getData(baseurl)savepath = "豆瓣电影Top250.xls"# 3.保存数据saveData(datalist, savepath)# 影片详情链接的规则
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则(字符串的模式)
# 影片图片
findImgsrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S 让换行符包含在字符中
# 影片片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 找到评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 找到概况
findIng = re.compile(r'<span class="inq">(.*)</span>')
# 找到影片的相关内容
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)# 爬取网页
def getData(baseurl):datalist = []for i in range(0, 10): # 调用获取页面信息的函数10次url = baseurl + str(i * 25)html = askURL(url) # 保存获取到的网页源码# 2.逐一解析数据soup = BeautifulSoup(html, 'html.parser')for item in soup.find_all('div', class_="item"): # 查询符合条件的字符串,形成列表# print(item) # 测试:查看电影item全部信息data = []item = str(item)# 影片详情的链接link = re.findall(findLink, item)[0] # re库用来通过正则表达式查找指定的字符串data.append(link) # 添加链接imgSrc = re.findall(findImgsrc, item)[0]data.append(imgSrc) # 添加图片titles = re.findall(findTitle, item)if len(titles) == 2:ctitle = titles[0] # 添加中文名称data.append(ctitle) # 添加外国名称otitle = titles[1].replace("/", "") # 去掉无关的符号data.append(otitle)else :data.append(titles[0]) # 添加中文名称data.append(" ") # 外国名称留空rating = re.findall(findRating, item)[0]data.append(rating) # 添加评分judgeNum = re.findall(findJudge, item)[0]data.append(judgeNum) # 添加评论人数ing = re.findall(findIng, item)if len(ing) != 0:ing = ing[0].replace("。", "") # 去掉句号data.append(ing) # 添加概述else :data.append(" ") #留空bd = re.findall(findBd, item)[0]bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd)bd = re.sub("/", " ", bd)data.append(bd.strip())datalist.append(data) # 把处理好的一部电影的信息添加进去# for item in datalist:# print(item)return datalist# 得到指定一个URL的网页内容
def askURL(url):head = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36 Edg/115.0.1901.203'}request = urllib.request.Request(url, headers=head)html = ""try:response = urllib.request.urlopen(request)html = response.read().decode("utf-8")# print(html)except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return html# 保存数据
def saveData(datalist, savepath):book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建workbook对象sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 创建工作表col = ('电影详情链接', '图片链接', '影片中文名', '影片外国名', '评分', '评价数', '概况', '相关信息')for i in range(0, 8):sheet.write(0, i, col[i]) # 列名for i in range(0, 250):print("第%d条" %i)data = datalist[i]for j in range(0, 8):sheet.write(i+1,j,data[j])book.save(savepath)if __name__ == "__main__":main()
数据可视化
Flask(app.py)
from flask import Flask, render_template, request
import datetimeapp = Flask(__name__)# @app.route('/')
# def hello_world():
# return 'Hello World!'@app.route("/welcome/<name>")
def welcome(name):return "你好%s"%name@app.route("/welcome/<int:id>")
def welcome2(id):return "您好%d号会员"%id# 返回给用户渲染后的网页文件
# @app.route("/")
# def index():
# return render_template("index.html")# 向页面传递一个变量
@app.route("/")
def index():time = datetime.date.today() # 普通变量name = ["小张","小王","小赵"] # 列表类型task = {"任务":"打扫卫生","时间":"三小时"} # 字典类型return render_template("index.html", var = time, list = name, task = task)# 表单提交
@app.route('/test/register')
def register():return render_template("test/register.html")@app.route('/result', methods=['POST','GET'])
def result():if request.method == 'POST':result = request.formreturn render_template("test/result.html", result=result)if __name__ == '__main__':app.run()
Flask(index.html)
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>欢迎光临,今天是{{ var }}<br/>今天值班的有:<br/>{% for data in list %} <!--用大括号和百分号括起来是控制结构,还有if--><li>{{ data }}</li>{% endfor %}任务:<br/> <!--了解如何在页面打印表格--><table border="1">{% for key,value in task.items() %}<tr><td>{{ key }}</td><td>{{ value }}</td></tr>{% endfor %}</table>
</body>
</html>
Flask(register.html)
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<form action="{{ url_for('result') }}" method="post"><p>姓名:<input type="text" name="姓名"></p><p>年龄:<input type="text" name="年龄"></p><p>性别:<input type="text" name="性别"></p><p>地址:<input type="text" name="地址"></p><p><input type="submit" value="提交"></p>
</form>
</body>
</html>
Flask(result.html)
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body><table border="1">{% for key,value in result.items() %}<tr><th>{{ key }}</th><td>{{ value }}</td></tr>{% endfor %}</table>
</body>
</html>
相关文章:

B站弹幕分析系统
视频展示,请点击。 尚硅谷案例 utllib的基本使用 # 使用urllib来获取百度首页的源码 import urllib.request# (1)定义一个url 就是你要访问的地址 url http://www.baidu.com# (2)模拟浏览器先服务器发送请求 response响应 response urllib.request.urlopen(url)…...

戴上HUAWEI WATCH GT 4,解锁龙年新玩法
春节将至,华为WATCH GT 4作为一款颜值和实力并存的手表,能为节日增添了不少趣味和便利。无论你是钟情于龙年表盘或定制属于自己的表盘,还是过年用来抢红包或远程操控手机拍全家福等等,它都能成为你的“玩伴”。接下来,…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之StepperItem组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之StepperItem组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、StepperItem组件 用作Stepper组件的页面子组件。 子组件 无。 接口 St…...
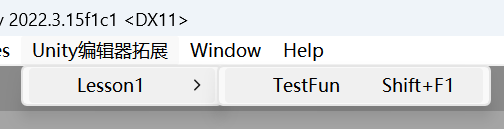
2024-02-08 Unity 编辑器开发之编辑器拓展1 —— 自定义菜单栏与窗口
文章目录 1 特殊文件夹 Editor2 在 Unity 菜单栏中添加自定义页签3 在 Hierarchy 窗口中添加自定义页签4 在 Project 窗口中添加自定义页签5 在菜单栏的 Component 菜单添加脚本6 在 Inspector 为脚本右键添加菜单7 加入快捷键8 小结 1 特殊文件夹 Editor Editor 文件夹是 …...
Intellij IDEA各种调试+开发中常见bug
Intellij IDEA中使用好Debug,主要包括如下内容: 一、Debug开篇 ①、以Debug模式启动服务,左边的一个按钮则是以Run模式启动。在开发中,我一般会直接启动Debug模式,方便随时调试代码。 ②、断点:在左边行…...
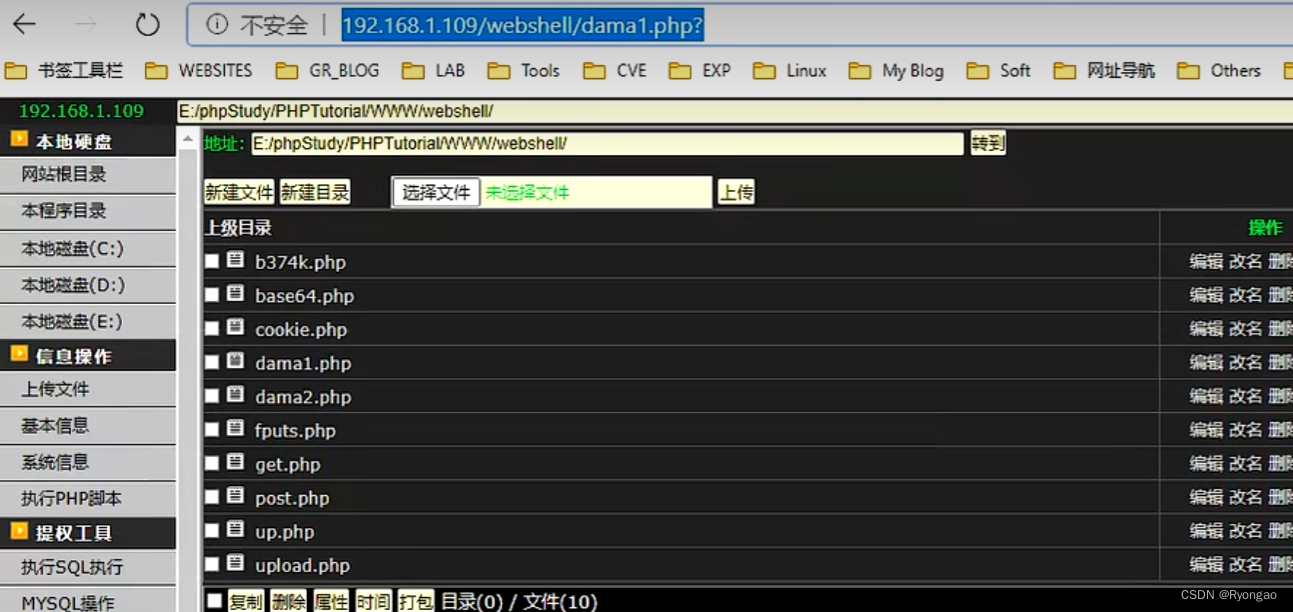
文件上传-Webshell
Webshell简介 webshell就是以aspphpjsp或者cgi等网页文件形式存在的一种命令执行环境,也可以将其称做为一种网页木马后门。 攻击者可通过这种网页后门获得网站服务器操作权限,控制网站服务器以进行上传下载文件、查看数据库、执行命令等… 什么是木马 …...
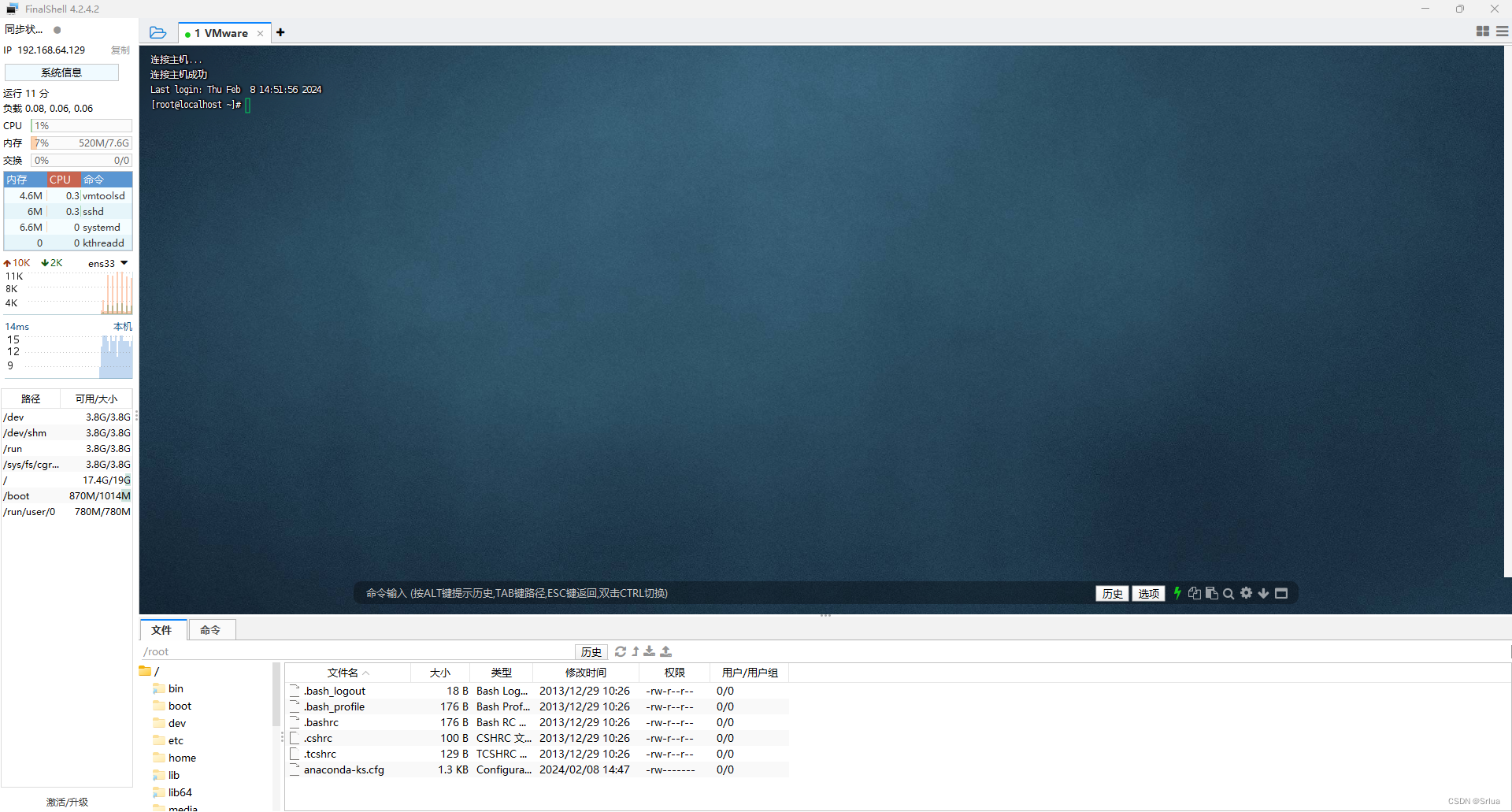
掌握虚拟化与网络配置之道:深入浅出VMware及远程管理技巧
目录 虚拟机介绍 虚拟机的关键字 服务器架构的发展 为什么用虚拟机VMware 虚拟机和阿里云的区别 功能角度 价格因素 应用场景 优势方面 找到windows的服务管理 配置VMware 关于VMware安装的几个服务 vmware如何修改各种网络配置 关于NAT的详细信息(了解) NAT(网…...
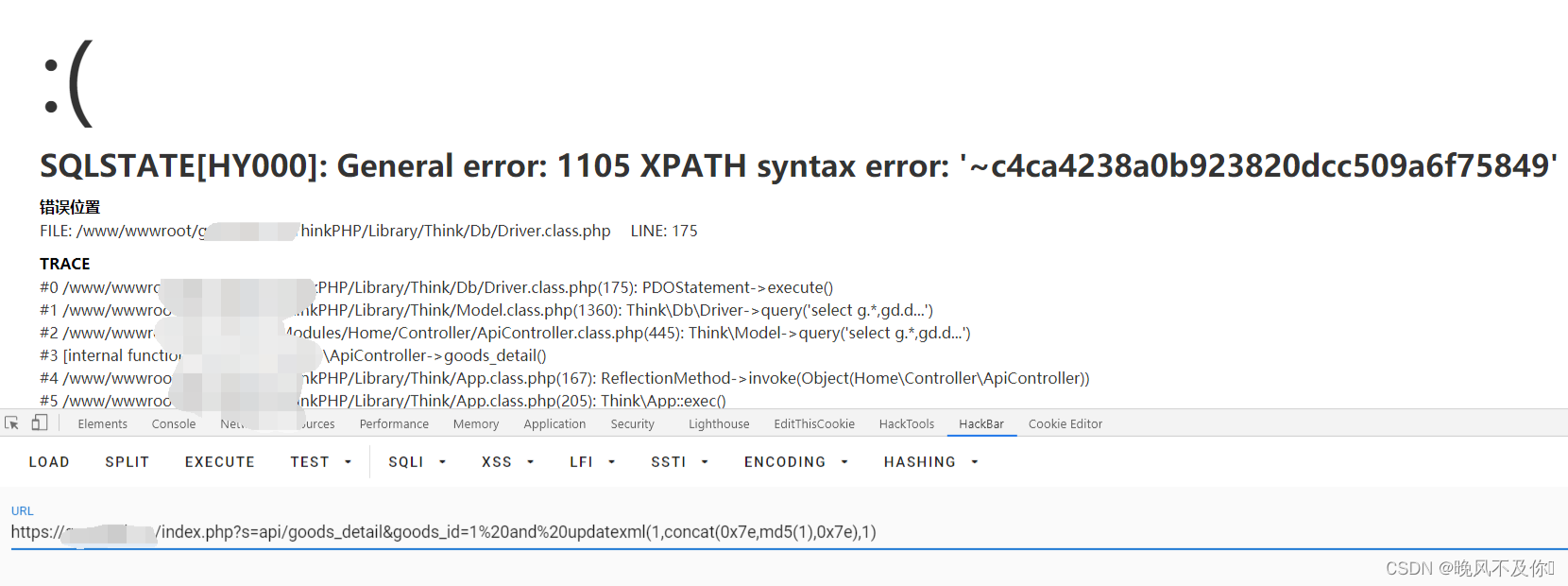
【漏洞复现】狮子鱼CMS某SQL注入漏洞
Nx01 产品简介 狮子鱼CMS(Content Management System)是一种网站管理系统,它旨在帮助用户更轻松地创建和管理网站。该系统拥有用户友好的界面和丰富的功能,包括页面管理、博客、新闻、产品展示等。通过简单直观的管理界面…...

Python学习之路-Tornado基础:安全应用
Python学习之路-Tornado基础:安全应用 Cookie 对于RequestHandler,除了在初始Tornado中讲到的之外,还提供了操作cookie的方法。 设置 set_cookie(name, value, domainNone, expiresNone, path‘/’, expires_daysNone) 参数说明: 参数名…...
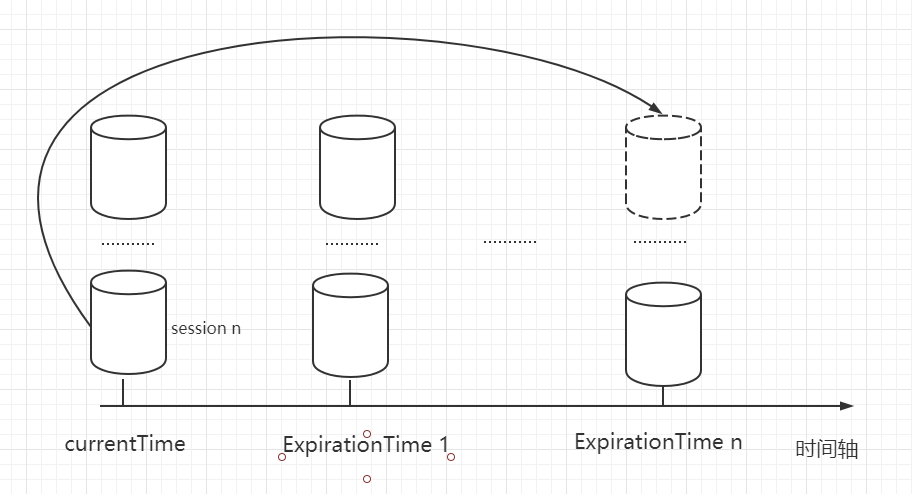
6.0 Zookeeper session 基本原理详解教程
客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就 是 session 会话。 从第一次连接建立开始,客户端开始会话的生命周期,客户端向服务端的ping包请求,每个会话都可以设置一个…...

生成式人工智能攻击的一年:2024
趋势科技最近公布了其关于预期最危险威胁的年度研究数据。生成人工智能的广泛可用性和质量将是网络钓鱼攻击和策略发生巨大变化的主要原因。 趋势科技宣布推出“关键可扩展性”,这是著名年度研究的新版本,该研究分析了安全形势并提出了全年将肆虐的网络…...

K8S之Namespace的介绍和使用
Namespace的理论和实操 Namespace理论说明Namespace实操创建、查看命名空间使用ResouceQuota 对Namespace做资源限额更多ResouceQuota 的使用 Namespace理论说明 命名空间定义 K8s支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间&…...
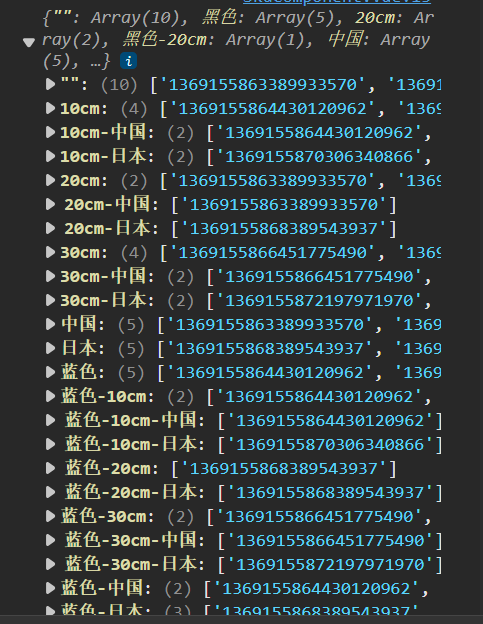
封装sku组件
1. 准备模板渲染规格数据 使用Vite快速创建一个Vue项目,在项目中添加请求插件axios,然后新增一个SKU组件,在根组件中把它渲染出来,下面是规格内容的基础模板 <script setup> import { onMounted, ref } from vue import axi…...
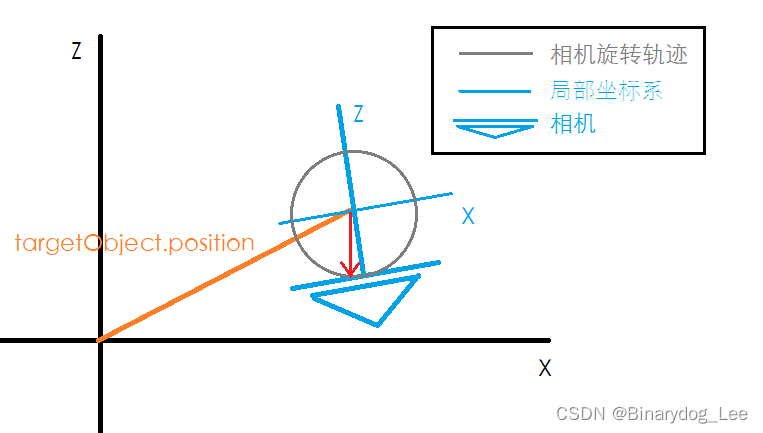
Unity笔记:相机移动
基础知识 鼠标输入 在Unity中,开发者在“Edit” > “Project Settings” > “Input Manager”中设置输入,如下图所示: 在设置了Mouse X后,Input.GetAxis("Mouse X")返回的是鼠标在X轴上的增量值。这意味着它会…...
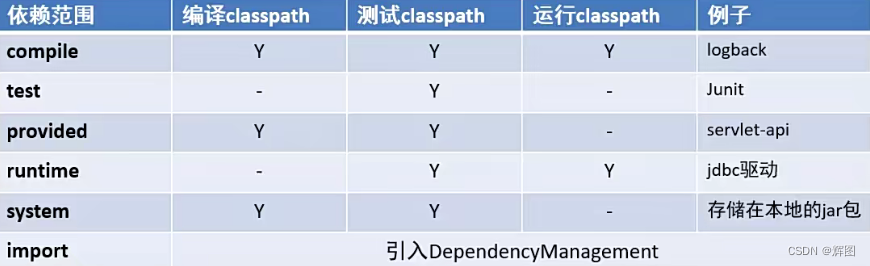
Java项目管理01-Maven基础
一、Maven的常用命令和生命周期 1.Maven的常用命令使用方式 complie:编译,将java文件编译为class字节码文件 clean:清理,删除字节码文件 test:测试,运行项目中的test类 package:打包&#x…...
复习提纲30)
计算机网络(第六版)复习提纲30
B HTTP 名词解释:协议HTTP定义了浏览器怎样向万维网服务器请求万维网文档,以及服务器怎样把文档传给浏览器。从层次的角度看,HTTP是面向事务的应用层协议,它是万维网上可靠地交换文件的重要基础,不仅能够传送完成超文本…...
基于SSM的图书管理系统
点击以下链接获取资源: https://download.csdn.net/download/qq_64505944/88820548?spm1001.2014.3001.5503 Java项目-6 librarySystem 开发完毕 万一你要作为课程设计或者毕设,不太会配,可以到下面我博客中私信,我帮你远程部…...

【GAMES101】Lecture 19 相机
目录 相机 视场 Field of View (FOV) 曝光(Exposure) 感光度(ISO) 光圈 快门 相机 成像可以通过我们之前学过的光栅化成像和光线追踪成像来渲染合成,也可以用相机拍摄成像 今天就来学习一下相机是如何成像的…...

《走进科学》灵异事件:Nginx配置改了之后一直报错
想要安装WoWSimpleRegistration,就定下来要用nginxphp8 ,结果nginx那里加上php的支持之后一直报错: $ sudo service nginx restart Job for nginx.service failed because the control process exited with error code. See "systemctl…...
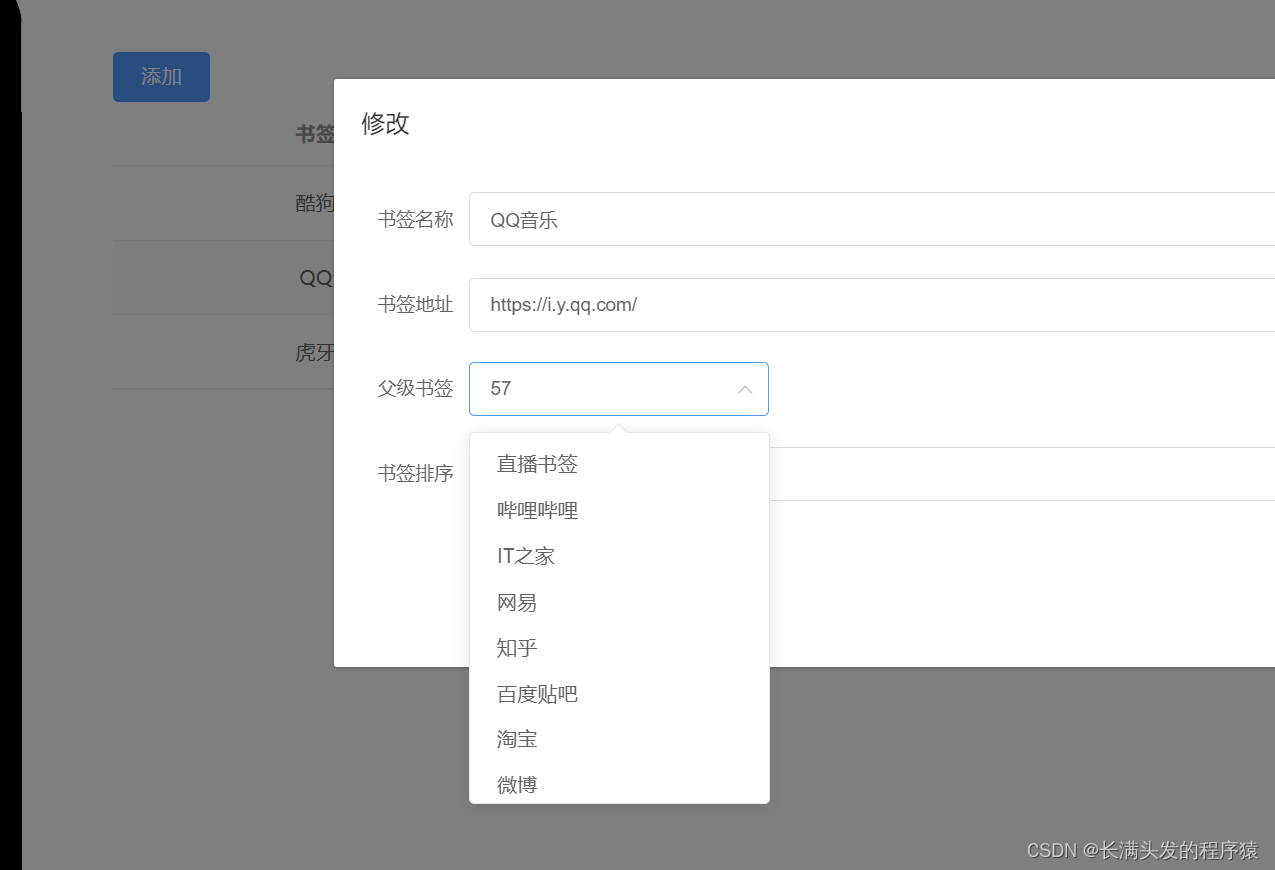
Select 选择器 el-option 回显错误 value
离谱 回显的内容不是 label 而是 value 的值 返回官方看说明: v-model的值为当前被选中的el-option的 value 属性值 value / v-model 绑定值有3种类型 boolean / string / number 根据自身代码猜测是:tableData.bookId 与 item.id 类型不一致导致 &…...

教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口 构建一个服务于师生的AI辅助教学系统,通常需要集成多种能力&a…...
3. 开源纳米级计量检测设备卡点)
0403开源:第四卷光刻机整机控制与量检测系统(A级 中期集中攻坚)3. 开源纳米级计量检测设备卡点
开源光刻机整机控制与量检测系统(A级 中期集中攻坚) 3. 开源纳米级计量检测设备卡点(全参数开源硬核壁垒拆解喂饭级溯源破局) 前置开源声明 本节全程无保留开源光刻量检测底层原理、设备架构、纳米级计量阈值、国内外参数对标、核…...

2025届必备的十大AI写作工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 为科研从业者、学子以及技术研发人员,在人工智能领域,合规可靠的AI论…...

openclaw-route-check:多协议路由诊断工具的原理、安装与实战应用
1. 项目概述与核心价值最近在折腾一些需要跨地域、跨网络环境访问的服务时,路由问题总是最让人头疼的环节。你可能也遇到过类似情况:明明服务部署在A地,从B地访问时延迟高得离谱,或者干脆时通时不通,排查起来像大海捞针…...

告别网络限制:用BilibiliDown轻松下载B站视频与音频
告别网络限制:用BilibiliDown轻松下载B站视频与音频 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/…...

基于ReAct范式的链式追踪工具:提升学术研究效率的AI智能体实践
1. 项目概述与核心价值如果你经常需要做文献调研、追踪某个科学概念的源头,或者想搞清楚一个复杂话题背后的证据链,那你一定体会过在搜索引擎和无数个学术网站之间反复横跳的痛苦。传统的搜索方式,比如在Google Scholar里输入一个关键词&…...

TestDisk PhotoRec:专业级数据恢复工具,拯救你的宝贵数据
TestDisk & PhotoRec:专业级数据恢复工具,拯救你的宝贵数据 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾经不小心删除了重要的工作文档?是否遇到过硬盘分区…...

Vue绘图画布组件:零基础打造专业级绘图应用
Vue绘图画布组件:零基础打造专业级绘图应用 【免费下载链接】vue-drawing-canvas VueJS Component for drawing on canvas. 项目地址: https://gitcode.com/gh_mirrors/vu/vue-drawing-canvas vue-drawing-canvas 是一个功能强大的Vue.js画布绘图组件&#x…...

别再死记硬背!一张图+三个口诀,快速理解自反、对称、传递闭包怎么求
离散数学闭包运算:图解口诀实战,3分钟掌握核心技巧 第一次接触离散数学中的闭包运算时,很多同学都会被各种定义和符号绕晕。其实只要掌握几个简单的视觉化技巧,就能像搭积木一样轻松构建自反、对称和传递闭包。本文将用最直观的关…...
)
基于单片机的盲人专用水杯系统(有完整资料)
编号:CJ-32-2022-161设计简介:本设计是基于单片机的盲人专用水杯系统,主要实现以下功能:1,OLED显示水位、温度和倒计时时间; 2,倒计时结束后,语音播报提醒喝药; 3&#x…...