《MySQL 简易速速上手小册》第2章:数据库设计最佳实践(2024 最新版)

文章目录
- 2.1 规划高效的数据库架构
- 2.1.1 基础知识
- 2.1.2 重点案例:在线电商平台
- 2.1.3 拓展案例 1:博客系统
- 2.1.4 拓展案例 2:库存管理系统
- 2.2 数据类型和表设计
- 2.2.1 基础知识
- 2.2.2 重点案例:个人健康记录应用
- 2.2.3 拓展案例 1:图书管理系统
- 2.2.4 拓展案例 2:员工管理系统:
- 2.3 索引设计原则
- 2.3.1 基础知识
- 2.3.2 重点案例:电商平台的商品搜索优化
- 2.3.3 拓展案例 1:博客平台的文章检索优化
- 2.3.4 拓展案例 2:员工管理系统的数据查询优化
2.1 规划高效的数据库架构
在深入探索如何使用 Python 来实现高效的数据库架构之前,让我们先来建立一些基础。规划数据库架构是确保数据系统既高效又可扩展的关键步骤。这不仅涉及到选择合适的数据存储解决方案,还包括如何组织数据结构、定义数据之间的关系以及实现数据的整合和迁移。
2.1.1 基础知识
- 了解业务需求:深入理解你的应用程序或系统的需求是规划数据库架构的第一步。这包括数据量预估、数据访问模式、事务处理需求等。
- 选择数据库类型:根据需求选择适合的数据库类型,比如关系型数据库 (RDBMS) 如 MySQL,或非关系型数据库 (NoSQL) 如 MongoDB。
- 数据建模:定义数据模型,包括实体、实体属性和实体之间的关系。这一步骤是设计高效架构的核心。
- 规范化:通过规范化过程消除数据冗余,提高数据一致性。
- 索引策略:合理使用索引可以大幅提高查询性能,但过多的索引会影响写操作的性能。
2.1.2 重点案例:在线电商平台
设想我们要为一个在线电商平台开发数据库架构。这个平台需要处理大量的商品信息、用户数据和交易记录。我们将使用 Python 和 MySQL 来实现。
- 业务需求分析:电商平台需要快速地查询商品信息,处理用户订单,并且能够扩展以支持不断增长的数据量。
- 数据建模:设计商品、用户和订单等实体及其属性。商品与订单之间是多对多的关系,因为一个订单可以包含多个商品,一个商品也可以属于多个订单。
- 使用 Python 连接 MySQL:使用
pymysql或MySQLdb库来连接数据库,并执行 SQL 语句来创建表和索引。
import pymysql# 连接 MySQL
conn = pymysql.connect(host='localhost', user='user', password='password', db='ecommerce_db')
try:with conn.cursor() as cursor:# 创建表cursor.execute("""CREATE TABLE IF NOT EXISTS Products (ProductID INT AUTO_INCREMENT PRIMARY KEY,Name VARCHAR(255),Price DECIMAL(10, 2),Description TEXT,Stock INT)""")
finally:conn.close()
2.1.3 拓展案例 1:博客系统
为了支持一个内容丰富的博客系统,我们需要设计一个数据库来存储文章、评论和用户信息。使用 Python 来创建表,并确保文章和评论之间存在适当的关系。
# 假设已经建立了连接
with conn.cursor() as cursor:cursor.execute("""CREATE TABLE IF NOT EXISTS Posts (PostID INT AUTO_INCREMENT PRIMARY KEY,Title VARCHAR(255),Content TEXT,AuthorID INT,PublishDate DATETIME)""")cursor.execute("""CREATE TABLE IF NOT EXISTS Comments (CommentID INT AUTO_INCREMENT PRIMARY KEY,PostID INT,CommentText TEXT,AuthorID INT,PublishDate DATETIME,FOREIGN KEY (PostID) REFERENCES Posts(PostID))""")
2.1.4 拓展案例 2:库存管理系统
在一个需要跟踪多个仓库存货的系统中,使用 Python 来设计和实现一个数据库,能够高效地查询和更新库存信息。考虑到仓库和商品之间的关系,以及库存变动的记录。
# 建立库存和仓库的表
with conn.cursor() as cursor:cursor.execute("""CREATE TABLE IF NOT EXISTS Warehouses (WarehouseID INT AUTO_INCREMENT PRIMARY KEY,Location VARCHAR(255))""")cursor.execute("""CREATE TABLE IF NOT EXISTS Inventory (InventoryID INT AUTO_INCREMENT PRIMARY KEY,ProductID INT,WarehouseID INT,Quantity INT,FOREIGN KEY (ProductID) REFERENCES Products(ProductID),FOREIGN KEY (WarehouseID) REFERENCES Warehouses(WarehouseID))""")
通过这些案例,我们不仅展示了如何规划和实现高效的数据库架构来满足不同的业务需求,还演示了如何使用 Python 来操作 MySQL 数据库,从而在实际生产环境中实现这些架构。这种方法确保了数据的高效管理和查询,为用户提供了强大的数据支持。

2.2 数据类型和表设计
深入了解数据类型和表设计是构建高效、可靠数据库系统的基石。正确选择数据类型和精心设计表不仅能提升数据存储效率,还能加快查询速度,确保数据的准确性和一致性。
2.2.1 基础知识
- 数据类型:MySQL 提供了丰富的数据类型,包括数值类型(如
INT,DECIMAL)、字符串类型(如VARCHAR,TEXT)、日期时间类型(如DATE,DATETIME)等。正确选择数据类型对于优化存储空间、提高查询性能及保证数据准确性至关重要。 - 表设计原则:
- 规范化:通过规范化设计来避免数据冗余,提高数据一致性。规范化通常包括将表分解成较小、逻辑上相互关联的表。
- 主键和外键:合理使用主键和外键来标识记录的唯一性以及不同表之间的关系。
- 索引策略:合理地使用索引来提升查询速度,但需要注意索引也会增加插入、更新和删除操作的开销。
2.2.2 重点案例:个人健康记录应用
设计一个数据库来存储用户的个人健康记录,包括每日饮食、运动和体重变化。使用 Python 和 MySQL 实现这一功能。
- 确定数据结构:首先,确定需要存储的信息和相应的数据类型。例如,饮食记录可能需要存储食物名称(
VARCHAR)、卡路里(INT)、食用时间(DATETIME)等。 - 使用 Python 创建表:利用 Python 的数据库库(如
pymysql)连接 MySQL,并创建相应的表。
import pymysqlconn = pymysql.connect(host='localhost', user='user', password='password', db='health_db')
try:with conn.cursor() as cursor:# 创建用户表cursor.execute("""CREATE TABLE IF NOT EXISTS Users (UserID INT AUTO_INCREMENT PRIMARY KEY,Username VARCHAR(50),Email VARCHAR(50))""")# 创建饮食记录表cursor.execute("""CREATE TABLE IF NOT EXISTS DietRecords (RecordID INT AUTO_INCREMENT PRIMARY KEY,UserID INT,FoodName VARCHAR(255),Calories INT,RecordTime DATETIME,FOREIGN KEY (UserID) REFERENCES Users(UserID))""")
finally:conn.close()
2.2.3 拓展案例 1:图书管理系统
设计一个用于图书馆图书管理的数据库,包括图书信息、借阅记录和读者信息。图书信息包括书名、作者、出版年份等,借阅记录包括借阅日期和归还日期。
# 假设已经建立连接
with conn.cursor() as cursor:# 创建图书表cursor.execute("""CREATE TABLE IF NOT EXISTS Books (BookID INT AUTO_INCREMENT PRIMARY KEY,Title VARCHAR(255),Author VARCHAR(100),YearPublished YEAR)""")# 创建借阅记录表cursor.execute("""CREATE TABLE IF NOT EXISTS BorrowRecords (RecordID INT AUTO_INCREMENT PRIMARY KEY,BookID INT,UserID INT,BorrowDate DATE,ReturnDate DATE,FOREIGN KEY (BookID) REFERENCES Books(BookID),FOREIGN KEY (UserID) REFERENCES Users(UserID))""")
2.2.4 拓展案例 2:员工管理系统:
为一家公司设计一个员工管理系统,包括员工基本信息、部门信息和工资记录。员工信息包括姓名、入职日期和部门ID,工资记录包括工资日期和金额。
# 建立部门和员工表
with conn.cursor() as cursor:# 创建部门表cursor.execute("""CREATE TABLE IF NOT EXISTS Departments (DepartmentID INT AUTO_INCREMENT PRIMARY KEY,DepartmentName VARCHAR(255))""")# 创建员工表cursor.execute("""CREATE TABLE IF NOT EXISTS Employees (EmployeeID INT AUTO_INCREMENT PRIMARY KEY,Name VARCHAR(100),JoinDate DATE,DepartmentID INT,FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID))""")# 创建工资记录表cursor.execute("""CREATE TABLE IF NOT EXISTS Salaries (RecordID INT AUTO_INCREMENT PRIMARY KEY,EmployeeID INT,SalaryDate DATE,Amount DECIMAL(10, 2),FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID))""")
通过这些案例,我们可以看到,合理选择数据类型和设计表对于构建高效、可维护的数据库系统至关重要。使用 Python 进行数据库设计和操作提供了强大的灵活性,使得开发者可以根据具体需求轻松实现复杂的数据结构和逻辑。

2.3 索引设计原则
在数据库系统中,索引是优化查询性能的关键工具。正确的索引设计可以显著减少数据检索时间,提高应用性能。然而,不当的索引设计可能导致资源浪费和性能下降。让我们先探讨一些索引设计的基础知识,然后通过实际案例学习如何在 Python 中应用这些原则。
2.3.1 基础知识
- 索引的类型:最常用的索引类型包括主键索引、唯一索引、普通索引和全文索引。每种索引类型都有其特定的用途和性能影响。
- 选择索引列:通常,应为查询中的 WHERE 子句、JOIN 操作的列以及具有高选择性的列创建索引。
- 索引覆盖:当一个查询可以完全通过索引来解决,而无需访问表数据时,我们称之为索引覆盖,这可以极大地提高查询效率。
- 避免过度索引:虽然索引可以提高查询速度,但每个额外的索引都需要占用空间,并且在插入、更新和删除操作时需要维护,这可能会降低这些操作的性能。
2.3.2 重点案例:电商平台的商品搜索优化
假设我们正在开发一个电商平台,并希望优化商品搜索的响应时间。商品信息存储在 MySQL 数据库中,我们需要频繁地根据商品名称、类别和价格进行搜索。
- 确定索引需求:分析查询模式,识别出最常用于搜索的列:商品名称、类别和价格。
- 使用 Python 创建索引:利用 Python 的
pymysql库连接 MySQL 数据库,并为这些列创建索引。
import pymysqlconn = pymysql.connect(host='localhost', user='user', password='password', db='ecommerce')
try:with conn.cursor() as cursor:# 为商品名称、类别和价格创建索引cursor.execute("CREATE INDEX idx_name ON Products (Name)")cursor.execute("CREATE INDEX idx_category ON Products (Category)")cursor.execute("CREATE INDEX idx_price ON Products (Price)")
finally:conn.close()
2.3.3 拓展案例 1:博客平台的文章检索优化
对于一个内容管理系统(CMS),优化文章的检索是提高用户体验的关键。特别是,我们希望通过文章的标题和发布日期进行快速搜索。
# 假设数据库连接已建立
with conn.cursor() as cursor:# 为文章标题和发布日期创建索引cursor.execute("CREATE INDEX idx_title ON Posts (Title)")cursor.execute("CREATE INDEX idx_publish_date ON Posts (PublishDate)")
2.3.4 拓展案例 2:员工管理系统的数据查询优化
在一个大型企业的员工管理系统中,快速检索员工信息至关重要。常见的查询包括按员工姓名、部门和入职日期筛选员工。
# 假设数据库连接已建立
with conn.cursor() as cursor:# 为员工姓名、部门和入职日期创建索引cursor.execute("CREATE INDEX idx_employee_name ON Employees (Name)")cursor.execute("CREATE INDEX idx_department ON Employees (DepartmentID)")cursor.execute("CREATE INDEX idx_join_date ON Employees (JoinDate)")
通过以上案例,我们展示了如何根据实际查询需求在 Python 中设计和实现有效的索引策略。这些策略旨在提高数据库查询的性能,从而提升整体应用的响应速度和用户满意度。正确的索引设计是数据库优化的关键环节,需要根据具体的应用场景和数据访问模式进行仔细规划和调整。
相关文章:
《MySQL 简易速速上手小册》第2章:数据库设计最佳实践(2024 最新版)
文章目录 2.1 规划高效的数据库架构2.1.1 基础知识2.1.2 重点案例:在线电商平台2.1.3 拓展案例 1:博客系统2.1.4 拓展案例 2:库存管理系统 2.2 数据类型和表设计2.2.1 基础知识2.2.2 重点案例:个人健康记录应用2.2.3 拓展案例 1&a…...

利用YOLOv8 pose estimation 进行 人的 头部等马赛克
文章大纲 马赛克几种OpenCV 实现马赛克的方法高斯模糊pose estimation 定位并模糊:三角形的外接圆与膨胀系数实现实现代码实现效果参考文献与学习路径之前写过一个文章记录,怎么对人进行目标检测后打码,但是人脸识别有个问题是,很多人的背影,或者侧面无法识别出来人脸,那…...

【Python 千题 —— 基础篇】查找年龄
Python 千题持续更新中 …… 脑图地址 👉:⭐https://twilight-fanyi.gitee.io/mind-map/Python千题.html⭐ 题目描述 题目描述 班级中有 Tom、Alan、Bob、Candy、Sandy 五个人,他们组成字典 {Tom: 23, Alan: 24, Bob: 21, Candy: 22, Sandy: 21},字典的键是姓名,字典的…...
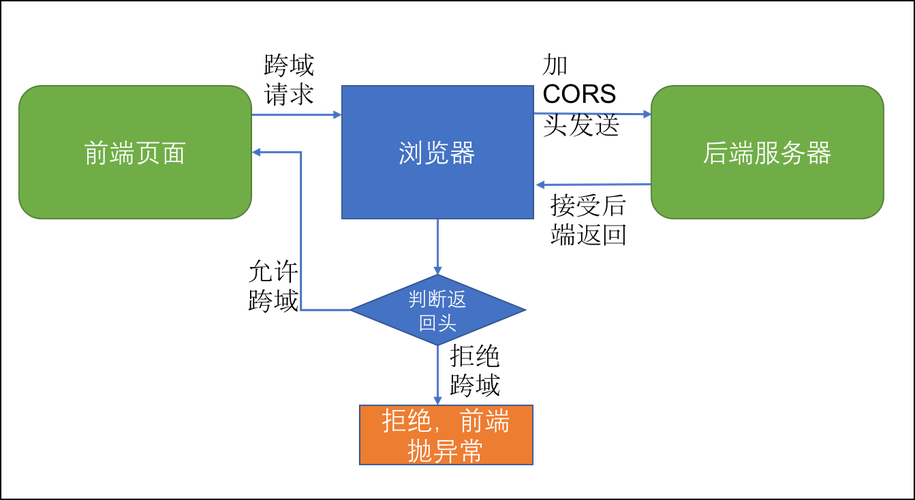
前后端通讯:前端调用后端接口的五种方式,优劣势和场景
Hi,我是贝格前端工场,专注前端开发8年了,前端始终绕不开的一个话题就是如何和后端交换数据(通讯),本文先从最基础的通讯方式讲起。 一、什么是前后端通讯 前后端通讯(Frontend-Backend Commun…...

Mysql大表添加字段失败解决方案
背景 最近遇到一个问题,需要在user用户表千万级别数据中添加两个字段,发现老是加不上去,一直卡死。表数据量不仅大,而且是一个热点表,访问频率特别高,而且该表的访问是在一个大事务中。加字段的时候一直在…...
只出现一次的数字III)
(52)只出现一次的数字III
文章目录 每日一言题目解题思路代码结语 每日一言 十年磨一剑,风雨未曾阻挡;愿你乘风破浪,不负韶华时光。 题目 题目链接:只出现一次的数字 给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现…...

Linux增删ip
Linux手动增删IP by: 铁乐猫 日期:2022.03.17 这里主要是记录手动临时添加和删除ip。 ifconfig方式 例,添加: ifconfig eth0:1 192.168.0.101/24移除 ifconfig eth0:1 downip addr方式 添加 ip addr add 192.168.0.102/24 dev eth0 …...

【计算机网络】时延,丢包,吞吐量(分组交换网络
时延 结点处理时延(nodal processing delay) dproc 排队时延(queuing delay) dqueue 传输时延(transmission delay) dtrans 路由器将分组推出所需要的时间,是分组长度和链路传输速率的函数 传播时…...

张楠辞任抖音集团CEO;东方甄选将开服饰号;小红书新增“附近”一级入口;华为分红770亿元
今日精选 • 张楠辞任抖音集团CEO,未来将聚焦剪映发展• 东方甄选将开服饰号 主打自营服饰• 小红书新增“附近”一级入口• 华为分红770亿元 大厂人事变动 • 上村健一出任中国U-16国家男子足球队主教练 投融资与企业动态 • 阿里大模型「通义千问」推出春节新…...
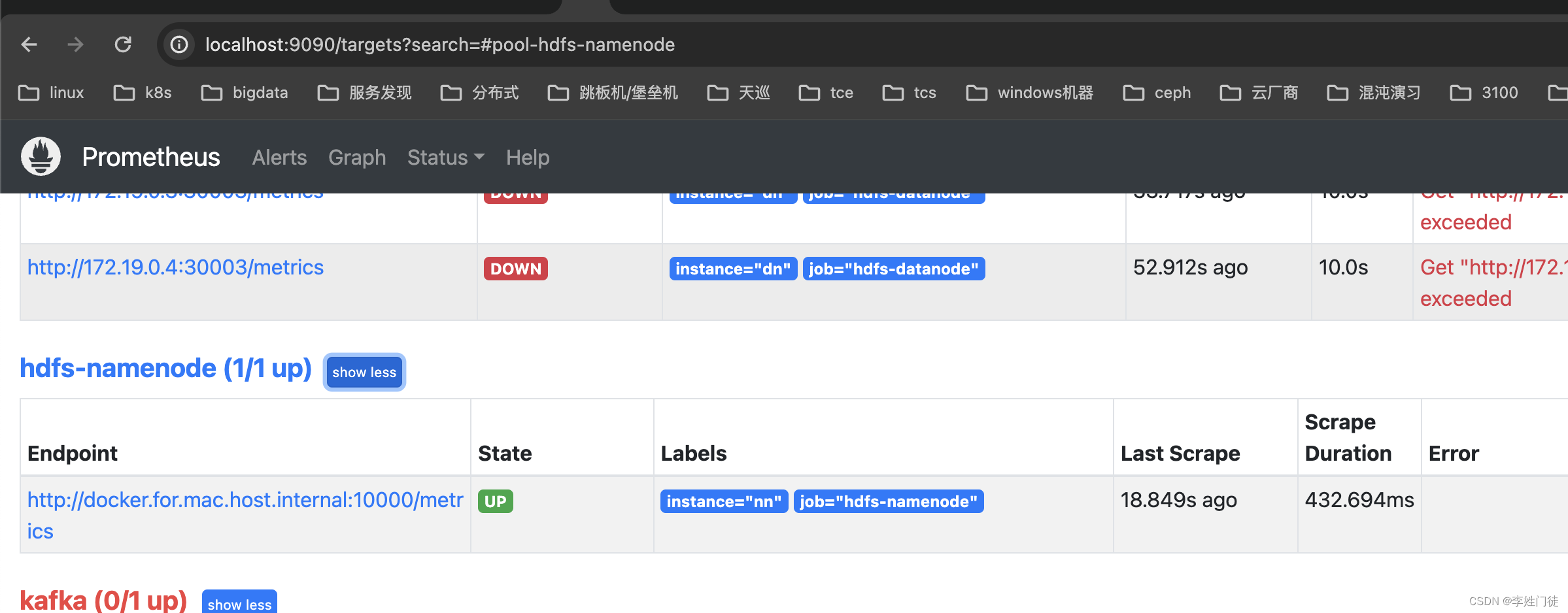
ES监控方法以及核心指标
文章目录 1. 监控指标采集1.1 部署elasticsearch_exporter1.2 prometheus采集elasticsearch_exporter的暴露指标1.3 promethues配置告警规则或者配置grafana大盘 2. 核心告警指标2.1 es核心指标2.2 es容量模型建议 3. 参考文章 探讨es的监控数据采集方式以及需要关注的核心指标…...

无人机应用场景和发展趋势,无人机技术的未来发展趋势分析
随着科技的不断发展,无人机技术也逐渐走进了人们的生活和工作中。无人机被广泛应用于很多领域,例如遥感、民用、军事等等。本文将围绕无人机技术的应用场景和发展趋势,从多角度展开分析。 无人机技术的应用场景 无人机在遥感方面的应用&…...

JavaGuide
JavaGuide(Java学习&面试指南) | JavaGuide JavaGuide 是一个面向 Java 开发者的知识整合平台,它提供了 Java 相关的学习资源、面试题、开发工具、框架和库等内容。JavaGuide 的目标是帮助 Java 开发者更好地学习和应用 Java 技术。 Ja…...
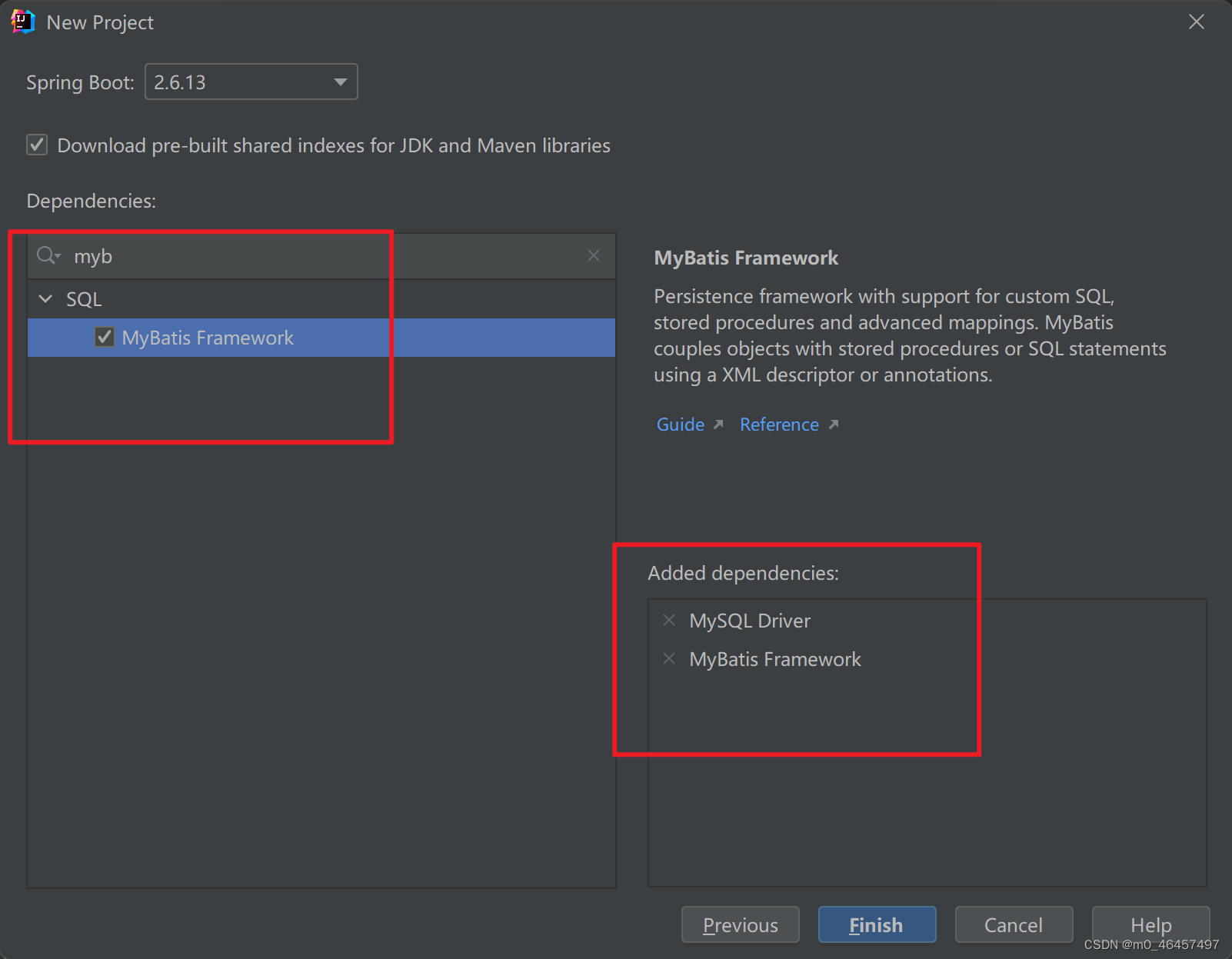
IDEA创建SpringBoot+Mybatis-Plus项目
IDEA创建SpringBootMybatis-Plus项目 一、配置Maven apache-maven-3.6.3的下载与安装(详细教程) 二、创建SpringBoot项目 在菜单栏选择File->new->project->Spring Initializr,然后修改Server URL为start.aliyun.com,…...

第9章 SpringBoot综合项目实战——个人博客系统
学习目标 了解博客系统的系统功能和文件组织结构 熟悉博客系统数据库相关表及字段的设计 熟悉系统环境搭建的步骤及相关配置 掌握前后台管理模块功能的实现 掌握用户登录,定时邮件发送功能的实现 通过前面章节的学习,读者应该已经掌握了SpringBoot框架的基本知识,并学会了与…...

怎么理解 Redis 事务
背景 在面试中经常会被问到,redis支持事务吗?事务是怎么实现的?事务会回滚吗?又是一键三连,我下面分析下,看看能不能吊打面试官 什么是Redis事务 事务是一个单独的隔离操作:事务中的所有命令…...

react中的diff算法
diff算法 对于React团队发现在日常开发中对于更新组件的频率,会比新增和删除的频率更高,所以在diff算法里,判断更新的优先级会更高。对于Vue2的diff算法使用了双指针,React的diff算法没有使用双指针,是因为更新的jsx对…...
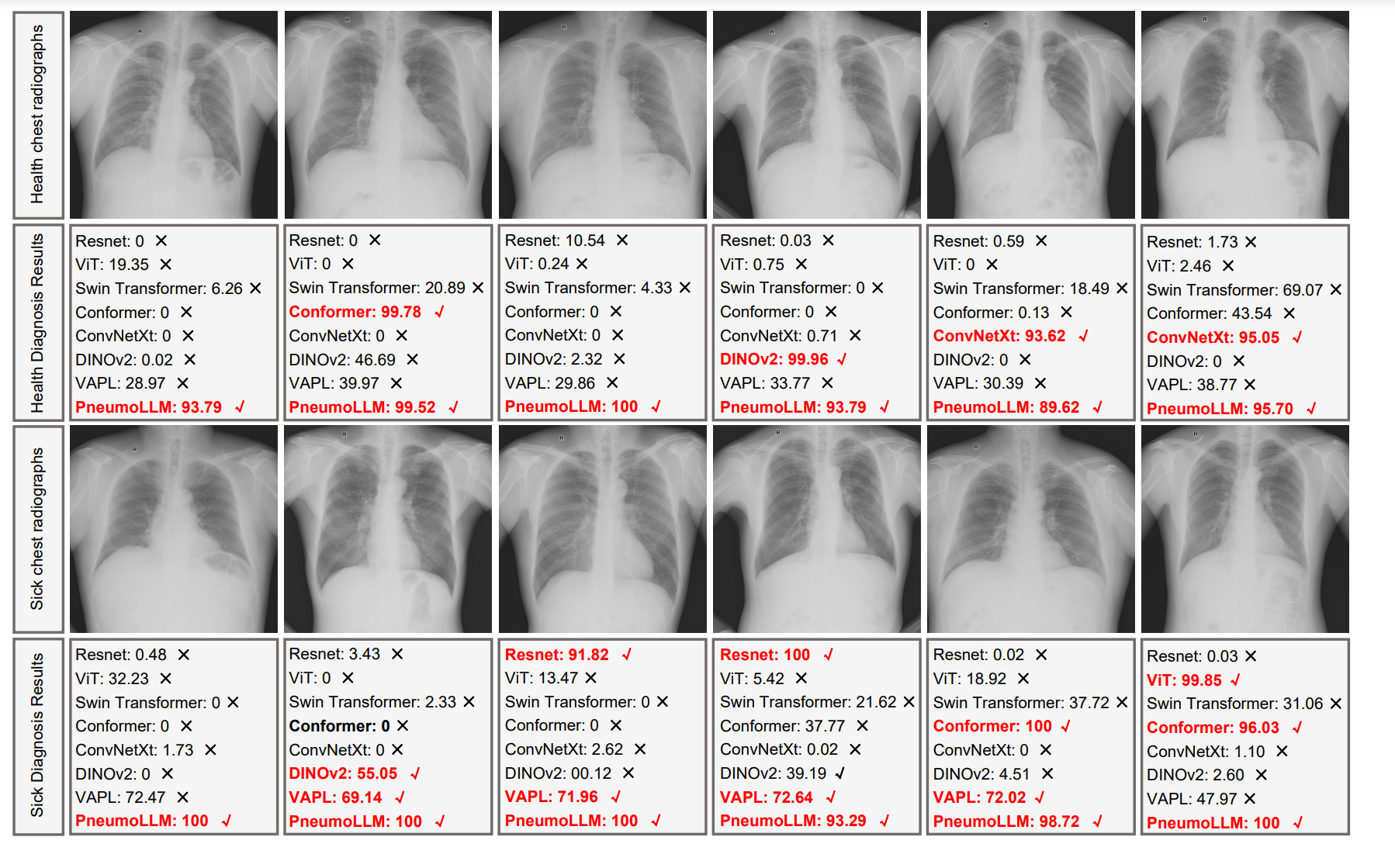
【医学大模型 尘肺病】PneumoLLM:少样本大模型诊断尘肺病新方法
PneumoLLM:少样本大模型诊断尘肺病新方法 提出背景PneumoLLM 框架效果 提出背景 论文:https://arxiv.org/pdf/2312.03490.pdf 代码:https://github.com/CodeMonsterPHD/PneumoLLM/tree/main 历史问题及其背景: 数据稀缺性问题&a…...
【SpringBootStarter】自定义全局加解密组件
【SpringBootStarter】 目的 了解SpringBoot Starter相关概念以及开发流程实现自定义SpringBoot Starter(全局加解密)了解测试流程优化 最终引用的效果: <dependency><groupId>com.xbhog</groupId><artifactId>globalValidation-spring…...

【射影几何15】python双曲几何工具geometry_tools
目录 一、说明二、环境问题:如何安装三、实现一个简单的例子四、绘制双曲组五、使用有限状态自动机加快速度六、资源和代码 一、说明 Geometry_tools 是一个 Python 包,旨在帮助您处理和可视化双曲空间和射影空间上的群动作。 该包主要构建在 numpy、…...

机器人抓取 [ 题目/摘要 ] 更新中..
题目:Robotic Grasping of Novel Objects using Visionl 链接:机器人抓取新物体 | IEEE Xplore(IEEE的Xplore) 【端到端】 摘要:我们考虑抓取新物体的问题,特别是第一次通过视觉看到的物体。抓取以前未知的…...

麦当劳中国启动2026全国招聘周招募新生代人才
美通社消息:麦当劳中国正式启动2026年全国招聘周。今年,首批年满16周岁的10后将步入职场,与00后共同构成新生代主力军。在AI的变革时代,麦当劳以"有保障、有福利、有发展"的薪酬福利成长体系,以及长期、系统…...

缠论分析工具终极指南:如何在通达信中实现可视化技术分析
缠论分析工具终极指南:如何在通达信中实现可视化技术分析 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 还在为复杂的缠论分析而头疼吗?想要在通达信软件中轻松识别分型、笔、线…...

Commit Mono版本管理指南:如何优雅地升级和回滚字体版本
Commit Mono版本管理指南:如何优雅地升级和回滚字体版本 【免费下载链接】commit-mono Commit Mono is an anonymous and neutral programming typeface. 项目地址: https://gitcode.com/gh_mirrors/co/commit-mono Commit Mono是一款匿名且中性的编程字体&a…...

AI数据标注实战:如何高效、准确地标注训练数据
在AI模型的开发与迭代过程中,数据标注是连接原始数据与智能算法的关键桥梁,其质量与效率直接决定了模型的性能上限。对于软件测试从业者而言,掌握高效、准确的数据标注方法,不仅能为AI模型提供可靠的训练“食粮”,更能…...

3步掌握Navicat无限试用重置:Mac用户的完整专业指南
3步掌握Navicat无限试用重置:Mac用户的完整专业指南 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 还在为Navica…...

别再手动算日期了!SQL Server里DATEDIFF和DATEADD的5个实战场景,数据分析师必看
SQL Server日期处理实战:DATEDIFF与DATEADD的5个高阶应用场景 在数据分析与报表开发领域,时间维度永远是核心要素之一。无论是用户行为分析、业务指标计算还是系统自动化处理,精准的日期运算能力直接决定了数据价值的挖掘深度。作为SQL Serve…...
)
手把手教你给M301H-BYT盒子刷当贝纯净桌面(附Hi3798芯片短接点位图)
从零开始:M301H-BYT盒子刷机实战指南 家里的老旧电视盒子用久了总是卡顿、存储不足,还限制应用安装?今天我们就来彻底解决这个问题。本文将手把手教你如何为M301H-BYT盒子刷入当贝纯净桌面系统,让你的老设备重获新生。不同于简单的…...

三步法实战指南:用FanControl打造静音高效的Windows风扇控制系统
三步法实战指南:用FanControl打造静音高效的Windows风扇控制系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...

从黑盒到白盒:Testbench验证机制与FPGA/ASIC开发实践
1. 从“黑盒”到“白盒”:理解Testbench的本质在数字电路设计,尤其是FPGA和ASIC开发领域,我们常常把设计好的硬件描述语言(HDL)模块,比如一个Verilog写的加法器或者一个VHDL写的状态机,称为“待…...

无王无帝定乾坤,来自田间第一人 道统传承兴万民
无王无帝定乾坤 来自田间第一人 华夏千载文脉绵延,万古道统源远流长,自古圣贤立心传道,只为正本清源、润泽苍生。往昔道统多依附王权存续,受朝堂礼制所拘,流传受限,难入寻常百姓之家,普惠世间之…...