涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(上)
涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(一)
1.前置知识
ODPS(Open Data Platform and Service)是阿里云自研的一体化大数据计算平台和数据仓库产品,在集团内部离线作为离线数据处理和存储的产品。离线计算任务节点叫做Odps节点,存储的离线表叫做Odps表;
Flink: 实时计算引擎,本文代码开发和测试均基于集团内部实时计算平台,代码细节可能会和Flink 官方社区文档有些许不同,假如用于生产环境测试,参考Apache Flink 官方文档为准,但是技术方案是通用的哈;
https://flink.apache.org/posts/2.项目背景
现有业务需求是 “根据用户注册以来的累计跑步里程,给用户发放勋章”,需要实时的计算出用户【历史~此时刻】的累计跑步数据。
比如说,某个用户20210101首次上传跑步记录,之后又多次上传跑步记录,我们需要实时的计算出,在20210101~当前时刻 期间,该用户累计跑了多少公里,累计跑了多少次等指标。上述指标的计算涉及用户历史至今的所有数据(2018~至今该用户所有数据),考虑使用批流结合的方式进行统计。参考批流结合的常用 lambda 方案:

我们将其拆分到“实时+离线”两条链路分别计算,离线链路计算用户历史至昨日的累计数据data1,实时链路计算当日实时累计数据data2。然后在对两条链路的数据进行汇总,data1+data2即为用户历史至今日此时刻的累计数据。

这里,离线链路使用odps来做,实时计算使用Flink来做,数据存储涉及 hbase、odps,所用消息中间件是MQ。
3.解决方案
3.1 方案描述
离线链路设计
离线链路计算目的:为了计算出全量用户【历史至昨日】的累计数据。
任务初始化时,先将历史的存量数据全量计算一次,得到存量累计值;以后每日计算用户昨日的新增数据,即新增累计值 ;两者相加即为用户历史至昨日的累计数据;循环往复,即可每日更新历史累计数据。
对应的数据链路应该长这样:
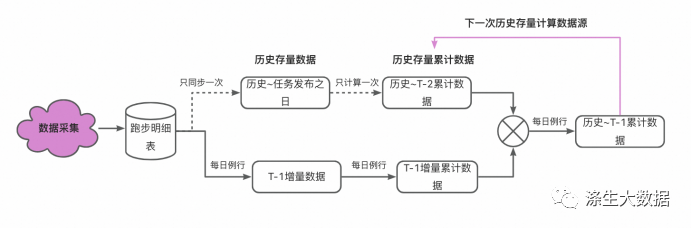
离线链路计算流程如下:
step1:用户历史数据初始化。假设该计算任务发布的时间为20231010,首先要对用户 历史~20231009 期间的历史数据进行汇总,得到一个 历史存量累计数据 history_data;
step2:从20231010起,对用户每日的增量跑步数据进行汇总,得到该日的增量累计数据 day_data;
step3:将每日的增量累计数据day_data 与 历史存量累计数据history_data 进行求和,作为新的历史存量累计数据 history_data(T-1) = day_data(T-1) + history_data(T-2) ;
step4:重复 step2 和step3 ,每日更新历史存量累计数据 history_data 。
该方案的优点是,历史全量数据只用计算一次,每日只需计算增量部分后再与存量合并即可,节省计算资源。
实时链路设计
实时链路计算目的:实时计算出用户【当日零点至此刻】的累计数据
实时链路的计算逻辑比较简单,对应的计算链路示意图如下:

实时链路计算流程如下:
step1:用户新增的跑步记录通过MQ发送给Flink任务;
step2:Flink节点1对数据去重;
step3:Flink节点2对实时汇总统计 当日零点至此刻 用户的跑步累计数据;step4:将计算结果输出给下游。
实时离线链路融合
实时离线链路融合目的:实时得到用户历史至此时刻的汇总数据
从上述的离线、实时链路中,我们分别得到了用户【历史~昨日】累计数据,和【当日凌晨~此刻】累计数据,只需将两者相加即可实时得到用户【历史~此刻】的累计数据:
-
ODPS 计算出用户 [非当日的历史累计数据],为使用方便,会每天更新全量用户历史累计数据;
-
使用Flink节点1 实时计算用户当日上传的跑步累计数据;
-
使用 Flink节点2 实时的将离线数据和实时数据汇总起来;
-
将汇总结果写入Hbase结果表,同时发送个MQ消息给下游业务方。
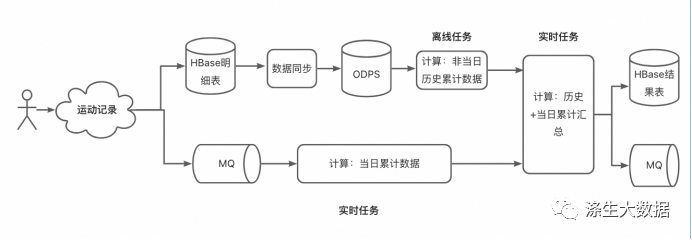
这里需要有两点需要注意:
1、根据业务特点,这里将离线计算结果作为维表使用:
Flink任务的下游业务方更关注当日上传过跑步记录的用户的数据更新情况,ODPS结果表作为维表用,Flink任务只对当日上传跑步记录的用户进行查询,得到“非当日历史统计数据”,在与“当日新增跑步数据”相加,即可得到该历史至今的最终的统计数据(更新hbase结果表),符合需求;
我们的跑步用户中大部分的用户不会每天都上传跑步记录,这些人的结果数据不会发生改变。若将ODPS表作为源表,则依旧会为这些用户更新数据,浪费计算资源。
【优化】odps表作为维表,不适合大数据量的情况,大数据量使用hbase表作为维表比较合适。这里将odps表数据同步到hbase表中,再拿该hbase表作为维表。
2、初始化下游结果表:在整个任务跑起来前,需要先使用ODPS表的bizdate分区数据初始化hbase结果表,然后再由实时任务对结果表进行更新;
最终的方案示意图如下:

3.2 存在的问题
上面的lambda方案有个问题,每日凌晨零点过后,实时任务已开始计算新的一天数据,而离线任务计算尚未结束,这时会出现一个离线数据缺失的窗口期。重点分析一下框图中“实时数据+离线数据”的部分:
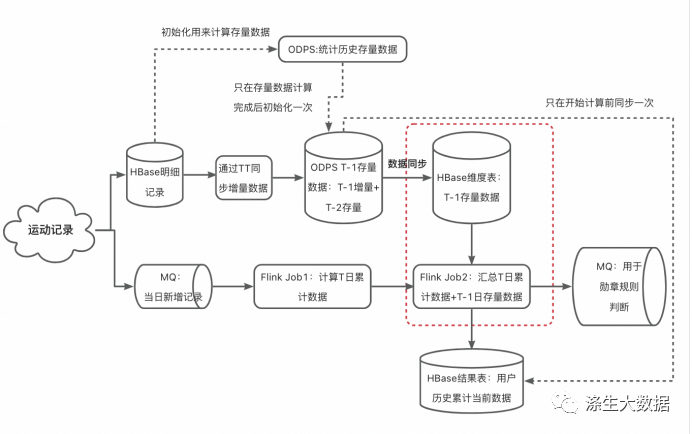
正常情况
当一个用户在T日实时上传了自己的跑步记录,Flink节点1会计算出其 [当日0点起至此刻] 的跑步累计数据data1,Flink节点2会根据该用户id取hbase维表里查询其 [历史~T-1日] 的累计数据 data2 (hbase表里数据由odps每日更新,即T-1日的存量累计汇总数据),将data1和data2二者汇总,就可得到 用户历史至此时刻的汇总数据;
异常情况
在凌晨(比如说,在00:00~00:30),ODPS正在计算最新分区数据(T-1日的数据)的期间,新的分区还没生成完,或者ODPS计算已经完成,但odps表同步base表同步任务还未完成,此时若发生了查询,会发生什么?
会使用老分区的数据(T-2日的数据,而不是期望的T-1日数据),导致数据不准。
【问题描述】
在凌晨时分,ODPS计算T-1日数据期间,如果发生了对T-1日的数据查询,则无法获取到期望的T-1日数据,会继续使用T-2日的数据
这里“无法获取正确数据”的时间长度 = ODPS计算时间 + ODPS同步数据到Hbase的时间
【原因】
Flink查询维表时 使用维表当前的数据快照,本次查询完成后再发生的维表更新不会对已有查询造成影响。
【举例】
case1(ODPS计算未完成):
27号,Flink任务计算27号当天的用户累计数据,同时查询odps维表的 26号分区 中该用户的历史累计数据,两者相加,得到27号的实时累计结果;
28号凌晨,ODPS正在计算27号分区的数据,任务还未结束,27号分区数据尚不可用;而Flink任务已经开始计算28号当天的用户累计数据,此刻发生了一次维表查询,期望从维表中查到该用户27号统计的历史累计数据,然而由于27号数据未准备好,则维表会返回26号的历史累计数据,这会导致数据计算错误,相当于丢失了该用户27号的数据。
case2(ODPS计算完成,但odps表同步habse表任务未完成):
28号凌晨,ODPS的计算已完成,odps表正在同步数据到hbase表期间,如果Flink发生了查询,期望获取用户27号的最新数据,但由于还没有更新完成,还是会用26号的数据,会造成类似的错误结果。
上面所述问题是批流融合的 lambda 框架常会遇到的问题,因此必须思考优化方案来解决上述问题。优化方案将在下一篇文章展现,敬请期待!
相关文章:
涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(上)
涤生大数据实战:基于FlinkODPS历史累计计算项目分析与优化(一) 1.前置知识 ODPS(Open Data Platform and Service)是阿里云自研的一体化大数据计算平台和数据仓库产品,在集团内部离线作为离线数据处理和存…...

jvm一级缓存
1、利用JVM缓存。脱离redis。 2、导包,springboot自带此包。如没有可以导:com.google.guava:guava:20.0的包。 3、直接上代码: package com.leo.cache;import com.alibaba.fastjson.JSONObject; import com.google.common.cache.Cache; im…...

鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Web组件
鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Web组件 一、操作环境 操作系统: Windows 10 专业版、IDE:DevEco Studio 3.1、SDK:HarmonyOS 3.1 二、Web组件 提供具有网页显示能力的Web组件,ohos.web.webview提供web控制能…...
【Linux】学习-深入了解文件的读与写
深入了解语言级别(C语言)文件操作的"读"与"写" 在学习前,我们先要知道在Linux下的一个原则:一切皆是文件 如何理解呢?举个外设的例子,比如键盘和显示器,这两个外设也可以其实本质上也是文件&…...

java实战:销售订单30分钟未支付自动取消
本文将介绍如何使用Java实现一个销售订单在30分钟内未支付则自动取消的系统。我们将探讨如何使用Spring的定时任务功能来检查订单状态,并在订单未支付的情况下执行取消操作。 一、需求分析 在电商系统中,为了管理库存和避免长时间占用资源,…...
一、西瓜书——绪论
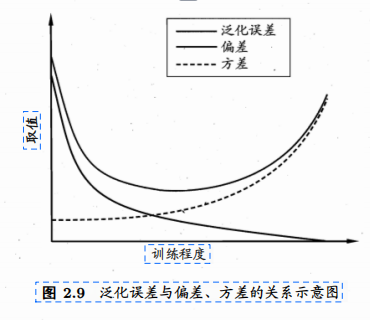
第一章 绪论 1.独立同分布 通常 假设 样本空间 中 全 体样 本 服 从 一 个 未 知 “ 分 布 ” ( d i s t r i b u t i o n ) D , 我们获得的每个样本都是独立地从这个分布上采样获得的, 即 “ 独 立同 分布 ” ( i n d e p e n d e n t a n d i d e n t ic a …...
如何连接ChatGPT?无需科学上网,使用官方GPT教程
随着AI的发展,ChatGPT也越来越强大了。 它可以帮你做你能想到的几乎任何事情,妥妥的生产力工具。 然而,对于许多国内的用户来说,并不能直接使用ChatGPT,不过没关系,我最近发现了一个可以直接免科学上网连…...
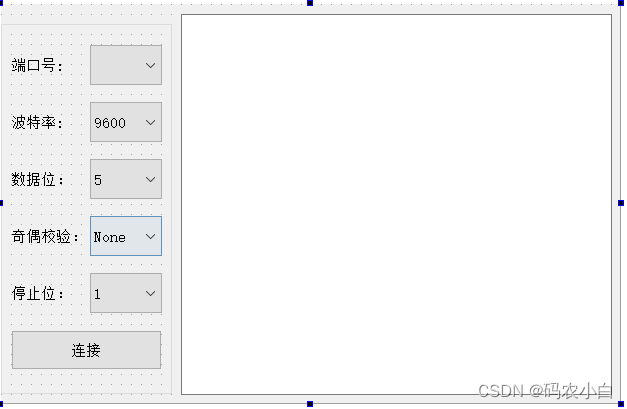
qt学习:串口
头文件 #include <QSerialPort> #include <QSerialPortInfo> 模块 QT core gui serialport 编程步骤 配置一个ui界面,五个QComboBox和一个按钮和一个QTextEdit 添加一个成员 private:QSerialPort *serial; 在构造函数中初始化ui端口列表和…...
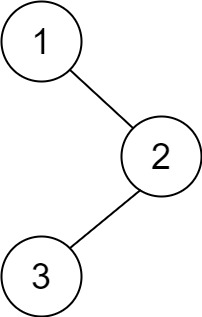
145. 二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。 示例 1: 输入:root [1,null,2,3] 输出:[3,2,1]示例 2: 输入:root [] 输出:[]示例 3: 输入:root [1] 输…...
Postgresql 的编译安装与包管理安装, 全发行版 Linux 通用
博客原文 文章目录 实验环境信息编译安装获取安装包环境依赖编译安装安装 contrib 下工具代码 创建用户创建数据目录设置开机自启动启动数据库常用运维操作 apt 安装更新源安装 postgresql开机自启修改配置修改密码 实验环境信息 Ubuntu 20.04Postgre 16.1 编译安装 获取安装…...
【Java EE初阶十】多线程进阶二(CAS等)
1. 关于CAS CAS: 全称Compare and swap,字面意思:”比较并交换“,且比较交换的是寄存器和内存; 一个 CAS 涉及到以下操作: 下面通过语法来进一步进项说明: 下面有一个内存M,和两个寄存器A,B; CAS(M,A,B)&am…...

与AI对话:编写高效Prompt的指南
与AI对话:编写高效Prompt的指南 一、明确目标 引导AI提供特定格式或内容答案的策略一、明确需求二、使用示例三、设置参数四、分步询问五、使用关键词 利用关键词引导AI重点关注核心内容的技巧一、确定关键概念二、使用专业术语三、强调重要性四、避免相关术语的混淆…...
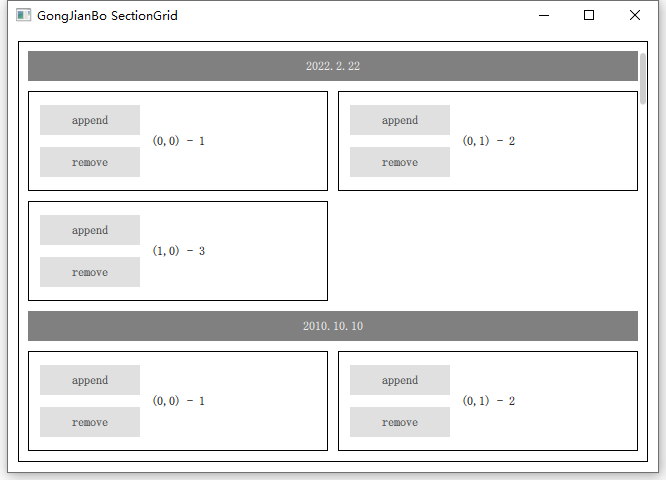
QML用ListView实现带section的GridView
QML自带的GridView只能定义delegate,没有section,类似手机相册带时间分组标签的样式就没法做。最简单的方式就是组合ListViewGridView,或者ListViewFlow,但是嵌套View时,子级View一般是完全展开的,只显示该…...

docker之程序镜像的制作
目录 一、每种资源的预安装(基础) 安装 nginx安装 redis 二、dockerfile文件制作(基础) 打包 redis 镜像 创建镜像制作空间制作dockerfile 打包 nginx 镜像 三、创建组合镜像(方式一) 生成centos容器并…...

Git - 每次 git pull/push 时需要账号和密码解决方案
问题描述 在提交项目代码或者拉取代码的时候,每次 git 都要输入用户名密码,很烦~ 解决方案 让服务器记下来用户名和密码,此时输入一次,以后再 git push /pull 的时候就不用再输账号和密码了 # 配置 git 记录用户名和密码 git c…...

C语言中在main函数之后运行的函数
在 Linux 平台上,atexit 函数同样是一个用于注册终止处理函数的库函数,它是 C 标准库 <stdlib.h> 的一部分。atexit 函数允许你注册一个或多个函数,这些函数会在 main 函数执行结束后,或者在调用 exit 函数时,由…...
pytorch训练指标记录之tensoboard,wandb
详解Tensorboard及使用教程_tensorboard怎么用-CSDN博客文章浏览阅读5.1w次,点赞109次,收藏456次。目录一、什么是Tensorboard二、配置Tensorboard环境要求安装三、Tensorboard的使用使用各种add方法记录数据单条曲线(scalar)多条曲线(scalars)直方图(hi…...

C语言——oj刷题——实现字符串逆序
当我们需要逆序一个字符串的内容时,可以通过C语言编写一个函数来实现。下面将详细介绍如何通过C语言实现这个功能,并附上代码示例。 1、实现原理 要逆序一个字符串的内容,可以使用两个指针来交换字符串中对应位置的字符。具体实现原理如下&am…...
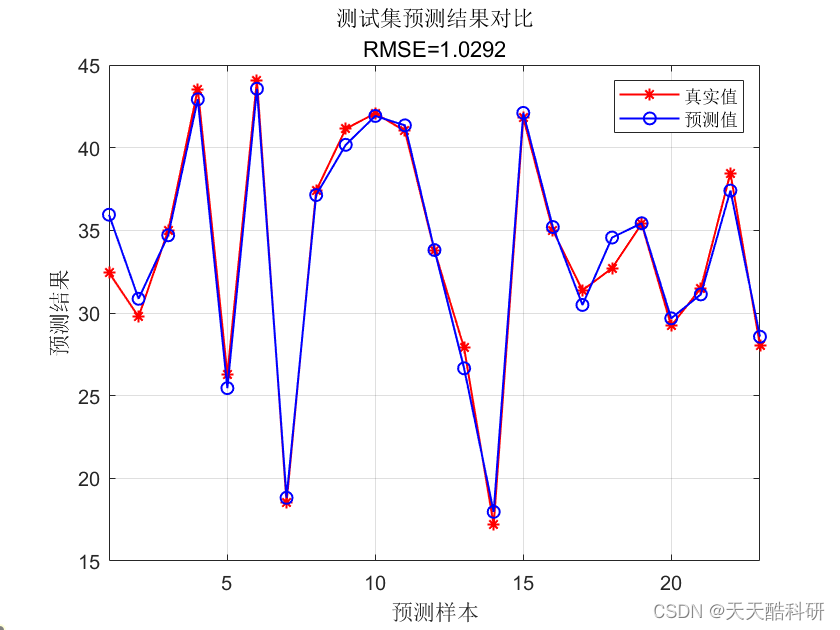
空气质量预测 | Matlab实现基于SVR支持向量机回归的空气质量预测模型
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 政府机构使用空气质量指数 (AQI) 向公众传达当前空气污染程度或预测空气污染程度。 随着 AQI 的上升,公共卫生风险也会增加。 不同国家有自己的空气质量指数,对应不同国家的空气质量标准。 基于支持向量机(Su…...

Vue中的请求拦截器
目录 1 前言 2 使用方法 2.1 创建拦截器 2.2 引入拦截器 1 前言 我们常常会使用JWT令牌来验证登录,因此很多请求都需要携带JWT令牌,我们当然可以用{headers:{Authorization:xx}}的方式,向每个请求中都以这样的方式添加JWT令牌。不过这样…...

【免费下载】 探索SFP模块的奥秘:SFP-I2C工具推荐
探索SFP模块的奥秘:SFP-I2C工具推荐 项目介绍 在现代网络通信中,SFP(Small Form-factor Pluggable)模块扮演着至关重要的角色。这些模块通过I2C接口提供了丰富的信息,包括制造商、功能支持以及诊断数据等。然而&#x…...
)
别再全局搜组件了!React Developer Tools 这 3 招定位文件(含 VSCode 自动跳转配置)
高效定位React组件的3种专业工作流 在接手一个大型React项目时,最令人头疼的莫过于在数百个文件中寻找特定组件的定义和使用位置。传统的全局搜索方法不仅效率低下,还容易因命名冲突导致误判。本文将分享三种经过实战验证的高效定位方法,特别…...
基于Circuit Playground Express与NeoPixel的智能光控花环制作全攻略
1. 项目概述:打造一个会“呼吸”的智能光之花环你是否想过,让一串普通的装饰灯带拥有感知环境、自动调节的“生命”?这听起来像是科幻电影里的场景,但实际上,利用今天唾手可得的开源硬件和图形化编程工具,任…...

咸鱼大量流出430元几乎全新联想迷你图形工作站小主机,支持8-9代标压处理器,最高双NVME+2.5寸SATA三盘位,还可选配独立显卡!
相比于普通小主机,工作站主机产品在性能以及扩展方面更有看点,可玩性高的不是一点,两点。即使是过时淘汰的古董机器,价位也是居高不下,贩子控价原因是一方面,还有法拉利老了也是法拉利,捡垃圾也…...

用废旧材料制作发光机械鱼:Circuit Playground Express与MakeCode入门实践
1. 项目概述:当废旧材料遇见微控制器每次清理工作室,看着角落里堆满的包装盒、塑料瓶和旧电线,我总在想,除了扔掉,它们还能不能有第二次生命?直到我尝试将一块小小的微控制器塞进这些“垃圾”里,…...

网站建设公司推荐:业内公认高水准网站制作公司一览
在数字化竞争日益激烈的2026年,企业官网已从单纯的信息展示窗口升级为品牌战略核心载体与业务增长引擎。面对市场上众多的网站建设服务商,企业如何精准匹配需求?本文作为第三方深度测评,从高端定制、模板建站、低成本快速上线三类…...

Talkyard管理员入门:10个必备设置打造完美的社区环境
Talkyard管理员入门:10个必备设置打造完美的社区环境 【免费下载链接】talkyard A community discussion platform: Brings together the main features from StackOverflow, Slack, Discourse, Reddit, and Disqus blog comments. 项目地址: https://gitcode.com…...

量子纠缠认证协议原理与工程实践
1. 量子纠缠认证协议的核心原理量子纠缠作为量子力学最反直觉的现象之一,在信息安全领域展现出独特优势。当两个量子比特形成贝尔态时,无论相隔多远,对其中一个粒子的测量会瞬间决定另一个粒子的状态。这种非局域关联特性,成为构建…...

别被“逻辑“吓退了,入门级数字化认证根本不需要你是学霸
很多人一听到“数字化认证”“AI考试”“逻辑题”,脑子里立刻浮现两种画面:一种是数学特别强的人在刷题,另一种是自己看不懂专业词,直接劝退。可真到企业实习、岗位转型、项目落地时你会发现,职场需要的往往不是“学霸…...

Rime中州韵小狼毫 配置文档层级与补丁机制全解析 新手避坑指南
1. Rime配置体系的双层结构揭秘 第一次打开Rime的配置文件时,很多人会被各种yaml文件搞得晕头转向。我刚开始用中州韵小狼毫时,就曾经把用户配置直接改到程序文件夹里,结果更新输入法后所有修改都被覆盖了。其实理解Rime的配置结构࿰…...