一、西瓜书——绪论
第一章 绪论
1.独立同分布
2.假设空间
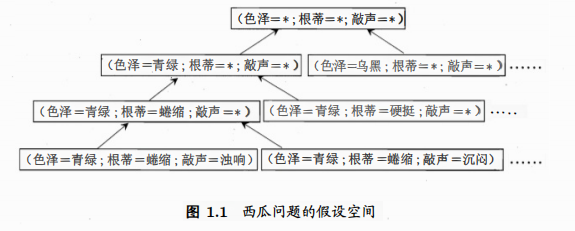
3.归纳偏好
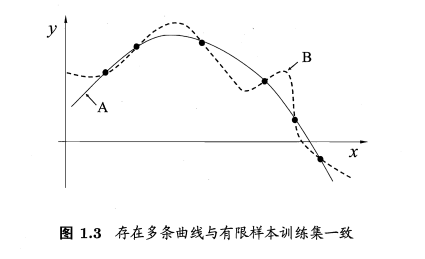
4.NFL定理
公式推导:




这个公式说明,在所有假设的情况下,误差与算法无关。所以,NFL定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好.要谈论算法的相对优劣,必须要针对具体的学习问题;在某些问题上表现好的学习算法,在另一些问题上却可能不尽如人意,学习算法自身的归纳偏好与问题是否相配,往往会起到决定性的作用.
第二章 模型评估与选择
1.训练集与测试集的划分
(1)留出法
(2)交叉验证法
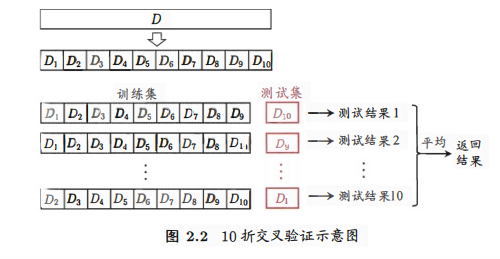
(3)自助法

自助法在数据集较小、难以有效划分训练/测试集时很有用
2.模型估计与选择
3.性能度量
(1)错误率与准确度
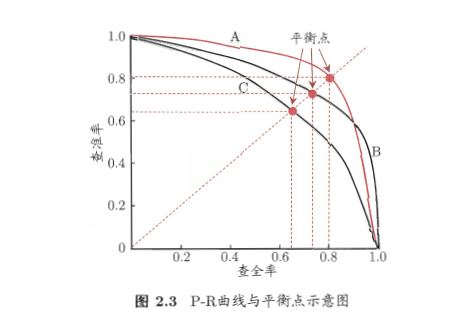
(2)查准率、查全率与F1

PR曲线
F1度量(调和均值)
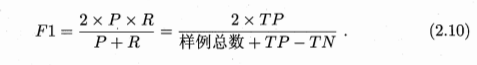
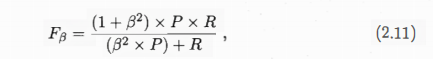

还可先将各混淆矩阵的对应元素进行平均:
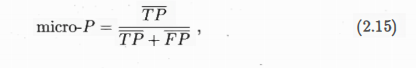

(3)ROC与AUC

AUC可通过对ROC曲线下各部分的面积求和而得.


4.代价敏感错误率与代价曲线
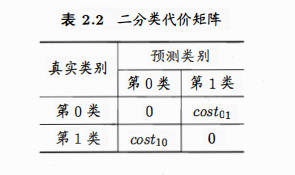
则“代价敏感”(cost-sensitive)错误率为:
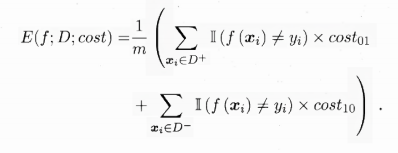
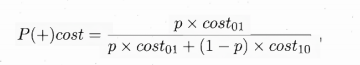
其中p是样例为正例的概率;纵轴是取值为[0,1]的归一化代价

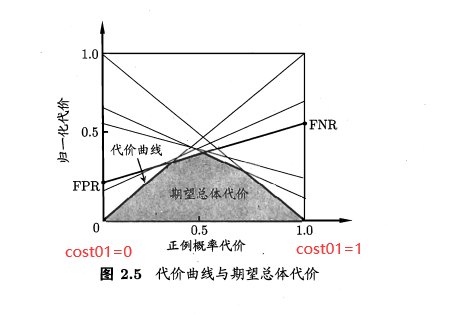
其中FPR是式(2.19)定义的假正例率,FNR=1-TPR是假反例率.代价曲线的绘制很简单:ROC曲线上每一点对应了代价平面上的一条线段,设ROC曲线上点的坐标为(TPR,FPR),则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR)到(1,FNR)的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图2.5所示.
4.比较检验
机器学习中性能比较这件事要比大家想象的复杂得多.这里面涉及几个重要因素:首先,我们希望比较的是泛化性能,然而通过实验评估方法我们获得的是测试集上的性能,两者的对比结果可能未必相同;第二,测试集上的性能与测试集本身的选择有很大关系,且不论使用不同大小的测试集会得到不同的结果,即便用相同大小的测试集,若包含的测试样例不同,测试结果也会有不同;第三,很多机器学习算法本身有一定的随机性,即便用相同的参数设置在同一个测试集上多次运行,其结果也会有不同.
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据.
(1)假设检验



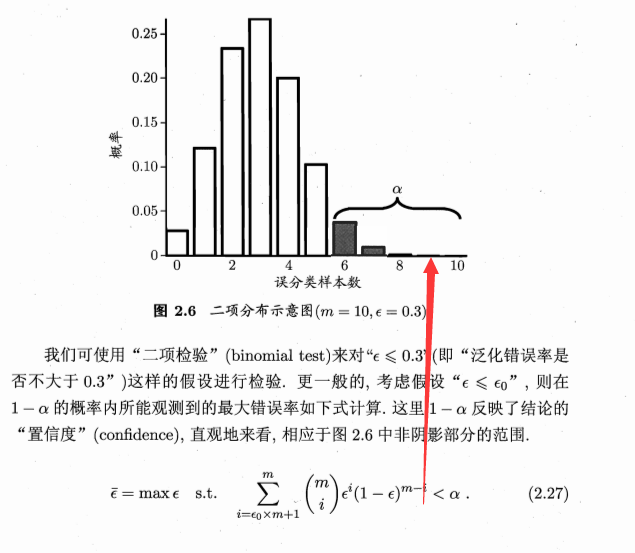

接下来查表,若t>临界值,落入拒绝域内,则拒绝原假设,否则接受原假设。认为测试错误率与泛化错误率相等。
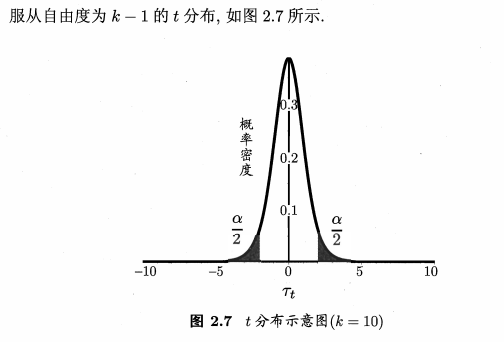
(2)交叉验证t检验
交叉验证t检验是使用的配对样本的t检验,假设学习器A,B测试错误率相等。

(3)McNemar检验

(4)Friedman检验 与 Nemenyi后续检验
McNemar检验:



五.偏差与方差
首先,引入学习算法的期望预测:
![]()


偏差(2.40)度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差(2.38)度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
噪声(2.39)则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度.
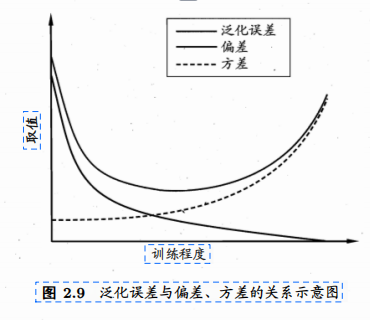
偏差-方差分解说明,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的.给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小.
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境(bias-variancedilemma).图2.9给出了一个示意图.给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合.
相关文章:
一、西瓜书——绪论
第一章 绪论 1.独立同分布 通常 假设 样本空间 中 全 体样 本 服 从 一 个 未 知 “ 分 布 ” ( d i s t r i b u t i o n ) D , 我们获得的每个样本都是独立地从这个分布上采样获得的, 即 “ 独 立同 分布 ” ( i n d e p e n d e n t a n d i d e n t ic a …...
如何连接ChatGPT?无需科学上网,使用官方GPT教程
随着AI的发展,ChatGPT也越来越强大了。 它可以帮你做你能想到的几乎任何事情,妥妥的生产力工具。 然而,对于许多国内的用户来说,并不能直接使用ChatGPT,不过没关系,我最近发现了一个可以直接免科学上网连…...
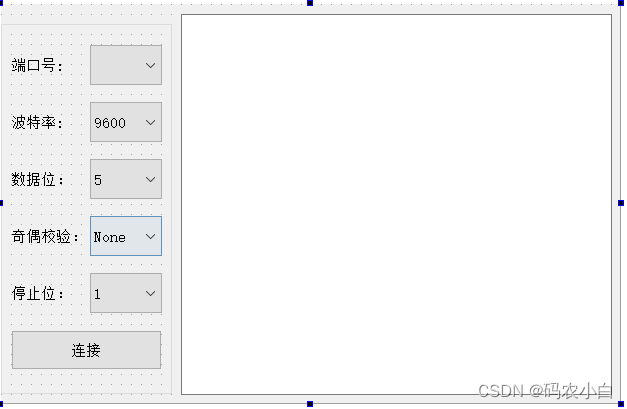
qt学习:串口
头文件 #include <QSerialPort> #include <QSerialPortInfo> 模块 QT core gui serialport 编程步骤 配置一个ui界面,五个QComboBox和一个按钮和一个QTextEdit 添加一个成员 private:QSerialPort *serial; 在构造函数中初始化ui端口列表和…...
145. 二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。 示例 1: 输入:root [1,null,2,3] 输出:[3,2,1]示例 2: 输入:root [] 输出:[]示例 3: 输入:root [1] 输…...
Postgresql 的编译安装与包管理安装, 全发行版 Linux 通用
博客原文 文章目录 实验环境信息编译安装获取安装包环境依赖编译安装安装 contrib 下工具代码 创建用户创建数据目录设置开机自启动启动数据库常用运维操作 apt 安装更新源安装 postgresql开机自启修改配置修改密码 实验环境信息 Ubuntu 20.04Postgre 16.1 编译安装 获取安装…...
【Java EE初阶十】多线程进阶二(CAS等)
1. 关于CAS CAS: 全称Compare and swap,字面意思:”比较并交换“,且比较交换的是寄存器和内存; 一个 CAS 涉及到以下操作: 下面通过语法来进一步进项说明: 下面有一个内存M,和两个寄存器A,B; CAS(M,A,B)&am…...

与AI对话:编写高效Prompt的指南
与AI对话:编写高效Prompt的指南 一、明确目标 引导AI提供特定格式或内容答案的策略一、明确需求二、使用示例三、设置参数四、分步询问五、使用关键词 利用关键词引导AI重点关注核心内容的技巧一、确定关键概念二、使用专业术语三、强调重要性四、避免相关术语的混淆…...
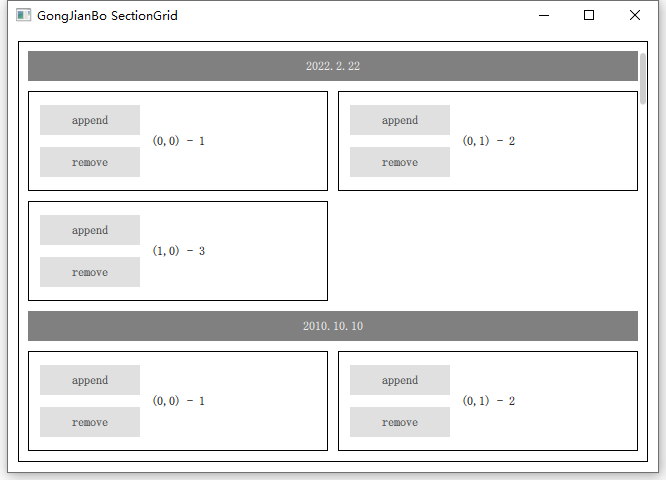
QML用ListView实现带section的GridView
QML自带的GridView只能定义delegate,没有section,类似手机相册带时间分组标签的样式就没法做。最简单的方式就是组合ListViewGridView,或者ListViewFlow,但是嵌套View时,子级View一般是完全展开的,只显示该…...

docker之程序镜像的制作
目录 一、每种资源的预安装(基础) 安装 nginx安装 redis 二、dockerfile文件制作(基础) 打包 redis 镜像 创建镜像制作空间制作dockerfile 打包 nginx 镜像 三、创建组合镜像(方式一) 生成centos容器并…...

Git - 每次 git pull/push 时需要账号和密码解决方案
问题描述 在提交项目代码或者拉取代码的时候,每次 git 都要输入用户名密码,很烦~ 解决方案 让服务器记下来用户名和密码,此时输入一次,以后再 git push /pull 的时候就不用再输账号和密码了 # 配置 git 记录用户名和密码 git c…...

C语言中在main函数之后运行的函数
在 Linux 平台上,atexit 函数同样是一个用于注册终止处理函数的库函数,它是 C 标准库 <stdlib.h> 的一部分。atexit 函数允许你注册一个或多个函数,这些函数会在 main 函数执行结束后,或者在调用 exit 函数时,由…...
pytorch训练指标记录之tensoboard,wandb
详解Tensorboard及使用教程_tensorboard怎么用-CSDN博客文章浏览阅读5.1w次,点赞109次,收藏456次。目录一、什么是Tensorboard二、配置Tensorboard环境要求安装三、Tensorboard的使用使用各种add方法记录数据单条曲线(scalar)多条曲线(scalars)直方图(hi…...

C语言——oj刷题——实现字符串逆序
当我们需要逆序一个字符串的内容时,可以通过C语言编写一个函数来实现。下面将详细介绍如何通过C语言实现这个功能,并附上代码示例。 1、实现原理 要逆序一个字符串的内容,可以使用两个指针来交换字符串中对应位置的字符。具体实现原理如下&am…...
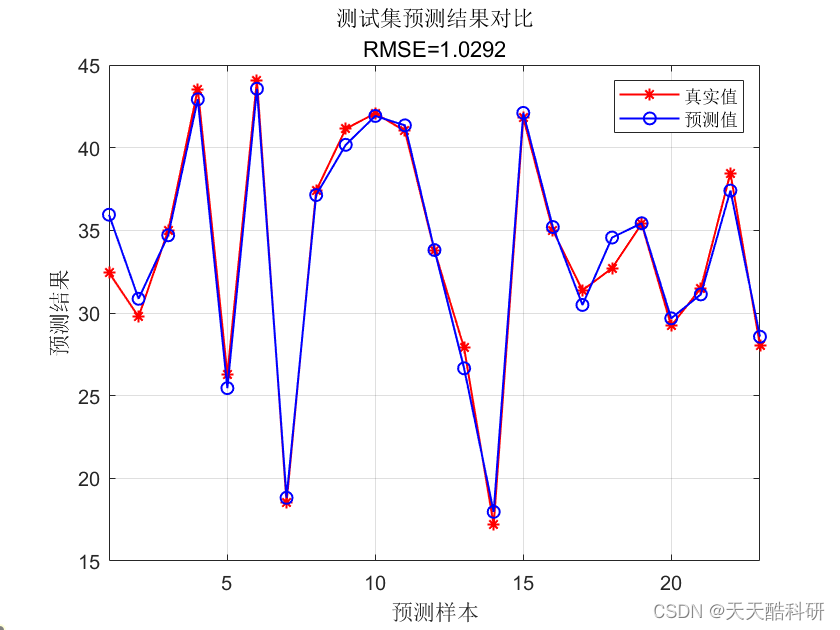
空气质量预测 | Matlab实现基于SVR支持向量机回归的空气质量预测模型
文章目录 效果一览文章概述源码设计参考资料效果一览 文章概述 政府机构使用空气质量指数 (AQI) 向公众传达当前空气污染程度或预测空气污染程度。 随着 AQI 的上升,公共卫生风险也会增加。 不同国家有自己的空气质量指数,对应不同国家的空气质量标准。 基于支持向量机(Su…...

Vue中的请求拦截器
目录 1 前言 2 使用方法 2.1 创建拦截器 2.2 引入拦截器 1 前言 我们常常会使用JWT令牌来验证登录,因此很多请求都需要携带JWT令牌,我们当然可以用{headers:{Authorization:xx}}的方式,向每个请求中都以这样的方式添加JWT令牌。不过这样…...
Java奠基】对象数组练习
目录 商品对象信息获取 商品对象信息输入 商品对象信息计算 商品对象信息统计 学生数据管理实现 商品对象信息获取 题目要求是这样的: 定义数组存储3个商品对象。 商品的属性:商品的id,名字,价格,库存。 创建三个…...

排序算法---快速排序
原创不易,转载请注明出处。欢迎点赞收藏~ 快速排序是一种常用的排序算法,采用分治的策略来进行排序。它的基本思想是选取一个元素作为基准(通常是数组中的第一个元素),然后将数组分割成两部分,其中一部分的…...
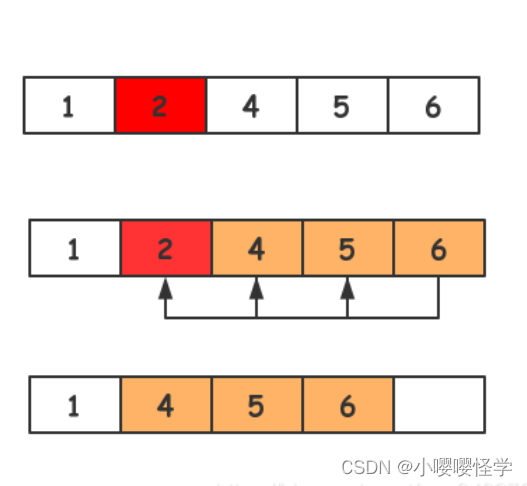
算法||实现典型数据结构的查找、添加和删除数据 并分析其时间和空间复杂度
实现典型数据结构的查找、添加和删除数据 并分析其时间和空间复杂度 线性结构: 数组:是一种线性表数据结构,它用一组连续的内存空间,来存储一组具有相同类型的数据。 查找数据 :随机访问 流程图 /** 查询元素下标…...

【蓝桥杯冲冲冲】Invasion of the Milkweed G
【蓝桥杯冲冲冲】Invasion of the Milkweed G 蓝桥杯备赛 | 洛谷做题打卡day30 文章目录 蓝桥杯备赛 | 洛谷做题打卡day30[USACO09OCT] Invasion of the Milkweed G题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 题解代码我的一些话 [USACO09OCT] Invasion of the Mi…...

【JAVA WEB】 百度热榜实现 新闻页面 Chrome 调试工具
目录 百度热榜 新闻页面 Chrome 调试工具 --查看css属性 打开调试工具的方式 标签页含义 百度热榜 实现效果: 实现代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"vi…...

dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架
dropin-minimal-css框架质量评估标准:如何选择最适合的CSS框架 【免费下载链接】dropin-minimal-css Drop-in switcher for previewing minimal CSS frameworks 项目地址: https://gitcode.com/gh_mirrors/dr/dropin-minimal-css 在当今前端开发的世界中&…...

初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型 对于资源有限的初创团队而言,在产品原型阶段快速验证想法是…...

激光雷达仿真:禾赛与NVIDIA联手,如何用数字孪生重塑自动驾驶研发?
1. 项目概述:当激光雷达遇上数字孪生最近,禾赛科技和NVIDIA的合作又往前迈了一大步,这事儿在自动驾驶圈子里挺受关注的。简单来说,就是禾赛的激光雷达模型,现在可以直接在NVIDIA的DRIVE Sim仿真平台里调用了。这意味着…...

【亲测免费】 CISP-DSG 数据安全培训教材课件标准版
CISP-DSG 数据安全培训教材课件标准版 【下载地址】CISP-DSG数据安全培训教材课件标准版 本仓库提供的是“注册数据安全治理专业人员”(Certified Information Security Professional - Data Security Governance,简称 CISP-DSG)的培训教材课…...
)
【亲测免费】 电机速度闭环控制(代码详细注释)
电机速度闭环控制(代码详细注释) 【下载地址】电机速度闭环控制代码详细注释 本仓库提供了电机速度闭环控制的实践教程,特别适合对电机控制、尤其是PID控制算法感兴趣的学习者。PID控制是一种广泛应用于工程领域的闭环控制策略,能…...

【免费下载】 青藏高原矢量边界数据下载
青藏高原矢量边界数据下载 【下载地址】青藏高原矢量边界数据下载 青藏高原矢量边界数据下载 项目地址: https://gitcode.com/open-source-toolkit/7d915 数据简介 本仓库提供青藏高原的矢量边界数据下载。该数据可在ARCGIS中直接导入并打开,附带坐标系统信…...
)
【网安-Web渗透测试-内网渗透】内网信息收集(工具)
目录1. 内网基础知识1.1 局域网1.1.1 局域网简介1.1.2 局域网的网络结构1.2 工作组1.3 域1.4 内网渗透2. 环境说明2.1 DC2.2 WebServer2.3 Marry2.4 Jack3. Cobalt Strike工具:用户凭据(密码)收集4. Metasploit信息收集5. BloodHound工具6. 内…...

事件相机技术原理与应用全解析
1. 事件相机技术概述事件相机(Event Camera)是一种革命性的视觉传感器,它彻底改变了传统相机的图像采集方式。与普通相机不同,事件相机不会以固定帧率捕获完整的图像帧,而是异步检测每个像素的亮度变化。当某个像素位置…...

运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用
运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用 在服务器运维和自动化工具开发中,命令行界面(CLI)的高效交互能力往往决定了管理效率的上限。当我们需要在无GUI环境的Linux服务器上开发监控面板、配置向导或系统管理…...
,解决黑砖 / Bootloop 难题)
1.解锁 Bootloader + 线刷 + 基带恢复,高通 EDL 模式自动化刷机(Python 脚本),解决黑砖 / Bootloop 难题
摘要 本文以工程化视角系统阐述主流品牌手机刷机维修的底层原理与标准化操作流程。覆盖高通、联发科、苹果A系列芯片平台的刷机协议、分区表结构、恢复模式触发机制及底层通信协议。提供可复现的Python自动化刷机脚本与adb/fastboot命令矩阵,解决变砖、Bootloop、基…...