大数据Flume--入门
文章目录
- Flume
- Flume 定义
- Flume 基础架构
- Agent
- Source
- Sink
- Channel
- Event
- Flume 安装部署
- 安装地址
- 安装部署
- Flume 入门案例
- 监控端口数据官方案例
- 实时监控单个追加文件
- 实时监控目录下多个新文件
- 实时监控目录下的多个追加文件
Flume
Flume 定义
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。

Flume 基础架构

Agent
Agent 是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent 主要有3个部分组成,Source、Channel、Sink。
Source
Source 是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种
格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。
Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink 组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
Channel
Channel 是位于Source 和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel 是线程安全的,可以同时处理几个Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适
用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数
据。
Event
传输单元,Flume 数据传输的基本单元,以Event 的形式将数据从源头送至目的地。Event 由Header 和 Body 两部分组成,Header用来存放该event的一些属性,为K-V结构,Body 用来存放该条数据,形式为字节数组。
Flume 安装部署
安装地址
(1)Flume 官网地址:http://flume.apache.org/
(2)文档查看地址:http://flume.apache.org/FlumeUserGuide.html
(3)下载地址:http://archive.apache.org/dist/flume
(4)Flume tar包
链接:https://pan.baidu.com/s/1O_CEiuHafNyuWSsrtZaydg?pwd=kw9k
提取码:kw9k
安装部署
(1)将apache-flume-1.9.0-bin.tar.gz 上传到 linux 的/opt/software 目录下
(2)解压apache-flume-1.9.0-bin.tar.gz 到/opt/module/目录下
[yudan@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
(3)修改apache-flume-1.9.0-bin 的名称为flume
[yudan@hadoop102 module]$ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
(4)将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[yudan@hadoop102 lib]$ rm /opt/module/flume/lib/guava-11.0.2.jar
Flume 入门案例
监控端口数据官方案例
1)案例需求:
使用Flume监听一个端口,收集该端口数据,并打印到控制台。
2)需求分析:

3)实现步骤:
(1)安装netcat工具
[yudan@hadoop102 software]$ sudo yum install -y nc
(2)判断44444端口是否被占用
[yudan@hadoop102 flume-telnet]$ sudo netstat -nlp | grep 44444
(3)创建Flume Agent配置文件flume-netcat-logger.conf
(4)在flume目录下创建job文件夹并进入job文件夹。
[yudan@hadoop102 flume]$ mkdir job
[yudan@hadoop102 flume]$ cd job/
(5)在job文件夹下创建Flume Agent配置文件flume-netcat-logger.conf
[yudan@hadoop102 job]$ vim flume-netcat-logger.conf
(6)在flume-netcat-logger.conf 文件中添加如下内容。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444 # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

(7)先开启flume监听端口
-
第一种写法:
[yudan@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console -
第二种写法:
[yudan@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console -
参数说明:
- –conf/-c:表示配置文件存储在conf/目录
- –name/-n:表示给agent起名为a1
- –conf-file/-f:flume 本次启动读取的配置文件是在 job 文件夹下的 flume-telnet.conf
文件。 - -Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
(8)使用netcat工具向本机的44444端口发送内容
[yudan@hadoop102 ~]$ nc localhost 44444
hello
yudan
(9)在Flume监听页面观察接收数据情况
实时监控单个追加文件
1)案例需求:实时监控Hive日志,并上传到HDFS中
2)需求分析:

3)实现步骤:
(1)Flume 要想将数据输出到HDFS,依赖Hadoop相关jar包
检查/etc/profile.d/my_env.sh 文件,确认 Hadoop和 Java 环境变量配置正确
JAVA_HOME=/opt/module/jdk1.8.0_212
HADOOP_HOME=/opt/module/hadoop-3.1.3
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME
(2)创建flume-file-hdfs.conf 文件
[yudan@hadoop102 job]$ vim flume-file-hdfs.conf
注:要想读取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于Hive日志在 Linux 系统中所以读取文件的类型选择:exec 即 execute 执行的意思。表示执行Linux 命令来读取文件。
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2 # Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log # Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
a2.sinks.k2.hdfs.path = hdfs://hadoop102:端口号/flume/%Y%m%d/%H
端口号是NameNode的地址,这个端口号在/opt/module/hadoop-3.1.3/etc/hadoop下core-site.xml文件中的fs.defaultFS配置过
注意:对于所有与时间相关的转义序列,Event Header中必须存在以 “timestamp”的
key(除非hdfs.useLocalTimeStamp设置为true,此方法会使用TimestampInterceptor自
动添加timestamp)。
a3.sinks.k3.hdfs.useLocalTimeStamp = true

(3)运行Flume
[yudan@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a2 -f job/flume-file-hdfs.conf
(4)开启Hadoop和Hive并操作Hive产生日志
[yudan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[yudan@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh[yudan@hadoop102 hive]$ bin/hive
hive (default)>
(5)在HDFS上查看文件。
实时监控目录下多个新文件
1)案例需求:使用Flume监听整个目录的文件,并上传至HDFS
2)需求分析:

3)实现步骤:
(1)创建配置文件flume-dir-hdfs.conf
创建一个文件
[yudan@hadoop102 job]$ vim flume-dir-hdfs.conf
# 添加以下内容a3.sources = r3
a3.sinks = k3
a3.channels = c3 # Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3

(2)启动监控文件夹命令
[yudan@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a3 -f job/flume-dir-hdfs.conf
说明:在使用Spooling Directory Source 时,不要在监控目录中创建并持续修改文件;上传完成的文件会以.COMPLETED结尾;被监控文件夹每500毫秒扫描一次文件变动。
(3)向upload文件夹中添加文件
在/opt/module/flume 目录下创建upload 文件夹
[yudan@hadoop102 flume]$ mkdir upload
向upload文件夹中添加文件
[yudan@hadoop102 upload]$ touch 1.txt
[yudan@hadoop102 upload]$ touch 2.tmp
[yudan@hadoop102 upload]$ touch 3.log
(4)查看HDFS上的数据
实时监控目录下的多个追加文件
Exec source 适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
1)案例需求:使用Flume监听整个目录的实时追加文件,并上传至HDFS
2)需求分析:

3)实现步骤:
(1)创建配置文件flume-taildir-hdfs.conf
创建一个文件
[yudan@hadoop102 job]$ vim flume-taildir-hdfs.conf
# 添加如下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3 # Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.* # Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://hadoop102:8020/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3

(2)启动监控文件夹命令
[yudan@hadoop102 flume]$ bin/flume-ng agent -cconf/ -n a3 -f job/flume-taildir-hdfs.conf
(3)向files文件夹中追加内容
在/opt/module/flume目录下创建files文件夹
[yudan@hadoop102 flume]$ mkdir files 向upload文件夹中添加文件
[yudan@hadoop102 files]$ echo hello >> file1.txt
[yudan@hadoop102 files]$ echo atguigu >> file2.txt
(4)查看HDFS上的数据
Taildir 说明:
Taildir Source 维护了一个json 格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
注:Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode 号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
相关文章:
大数据Flume--入门
文章目录 FlumeFlume 定义Flume 基础架构AgentSourceSinkChannelEvent Flume 安装部署安装地址安装部署 Flume 入门案例监控端口数据官方案例实时监控单个追加文件实时监控目录下多个新文件实时监控目录下的多个追加文件 Flume Flume 定义 Flume 是 Cloudera 提供的一个高可用…...

【SQL高频基础题】550.游戏玩法分析IⅣ
这个SQL花了很久。但是有挺多启发的。 如果我们做不出来,就去看答案。 但是看完答案之后,不要着急就去看下一道题,先把这道题吃透,后面的题目就会更有思路。 题目: Table: Activity ----------------------- | Co…...

sheng的学习笔记-部署-目录
标题传送门 sheng的学习笔记-docker部署,原理图,命令,用idea设置docker sheng的学习笔记-docker部署,原理图,命令,用idea设置docker sheng的学习笔记-docker部署springboot sheng的学习笔记-docker部署spri…...

【Java】悲观锁和乐观锁有什么区别?
Java中的悲观锁和乐观锁的主要区别体现在以下几个方面: 加锁策略:悲观锁在操作数据时,总是假设最坏的情况,即认为其他线程会修改数据,因此在读取或操作数据时,会先对数据进行加锁,以保证数据的…...
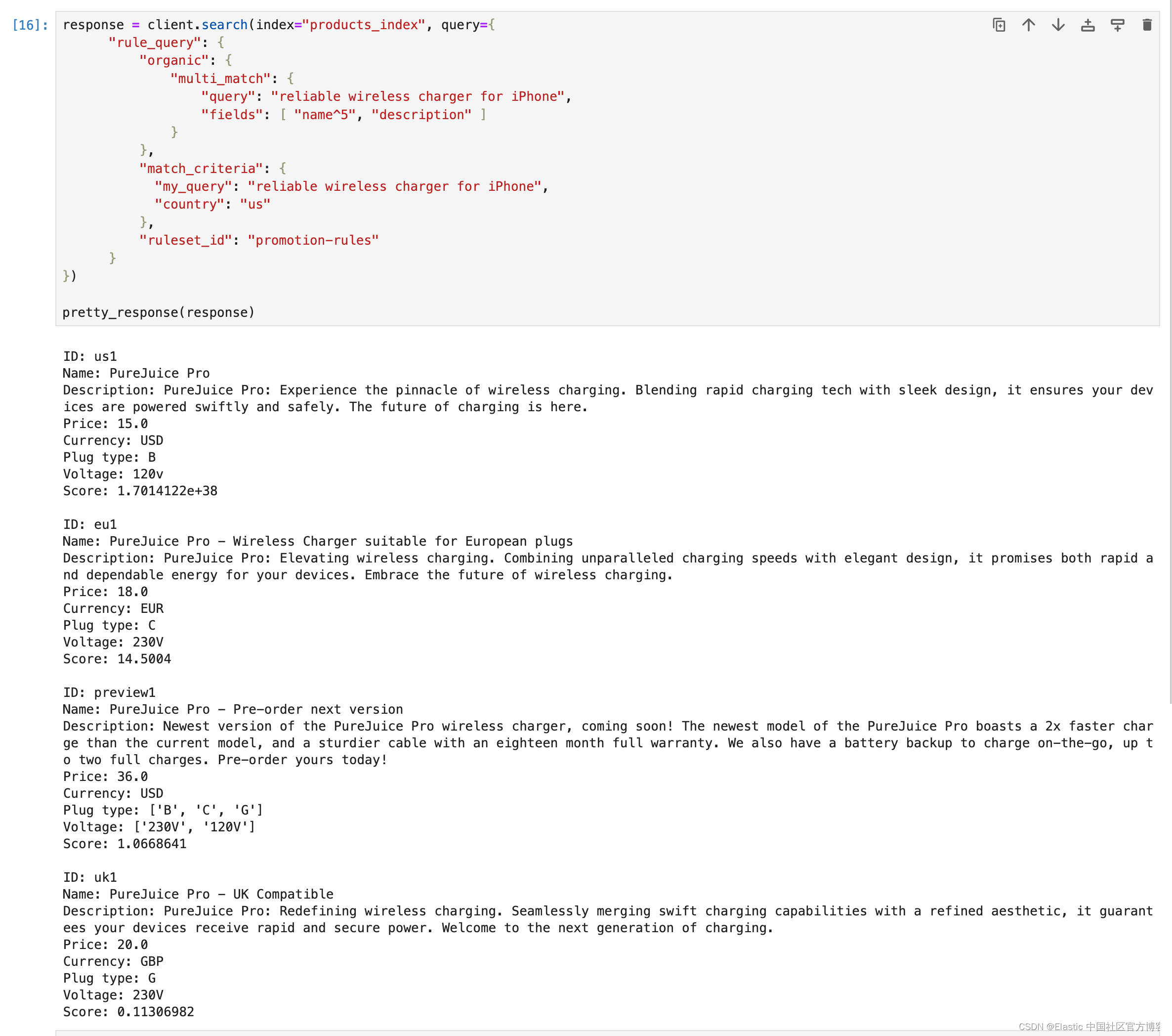
Elasticsearch:使用查询规则(query rules)进行搜索
在之前的文章 “Elasticsearch 8.10 中引入查询规则 - query rules”,我们详述了如何使用 query rules 来进行搜索。这个交互式笔记本将向你介绍如何使用官方 Elasticsearch Python 客户端来使用查询规则。 你将使用 query rules API 将查询规则存储在 Elasticsearc…...
Java核心设计模式:代理设计模式
一、生活中常见的代理案例 房地产中介:客户手里没有房源信息,找一个中介帮忙商品代购:代理者一般有好的资源渠道,降低购物成本(如海外代购,自己不用为了买东西出国) 二、为什么要使用代理 对…...

JSP编程
JSP编程 您需要理解在JSP API的类和接口中定义的用于创建JSP应用程序的各种方法的用法。此外,还要了解各种JSP组件,如在前一部分中学习的JSP动作、JSP指令及JSP脚本。JSP API中定义的类提供了可借助隐式对象通过JSP页面访问的方法。 1. JSP API的类 JSP API是一个可用于创建…...
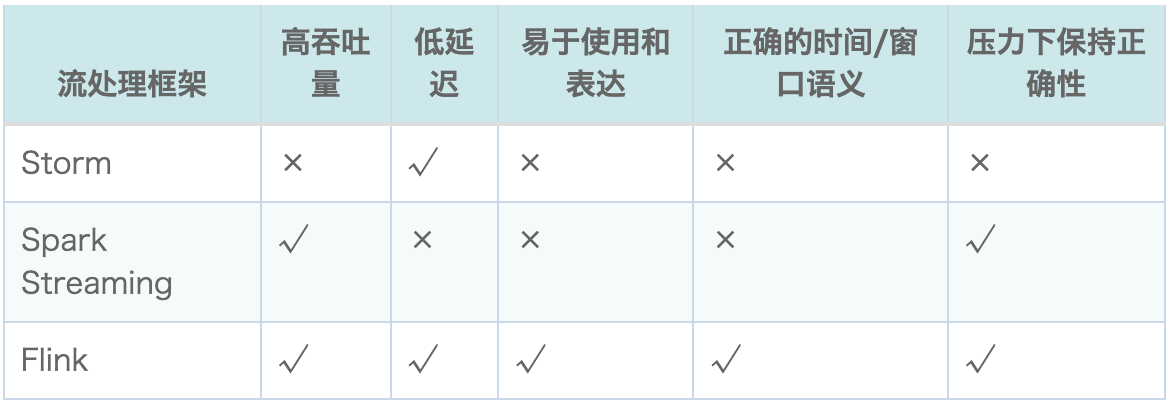
【Flink入门修炼】1-1 为什么要学习 Flink?
流处理和批处理是什么? 什么是 Flink? 为什么要学习 Flink? Flink 有什么特点,能做什么? 本文将为你解答以上问题。 一、批处理和流处理 早些年,大数据处理还主要为批处理,一般按天或小时定时处…...

刘谦龙年春晚魔术模拟
守岁共此时 代码 直接贴代码了,异常处理有点问题,正常流程能跑通 package com.yuhan.snginx.util.chunwan;import java.util.*;/*** author yuhan* since 2024/02/10*/ public class CWMS {static String[] num {"A", "2", &quo…...

re:从0开始的CSS学习之路 9. 盒子水平布局
0. 写在前面 过年也不能停止学习,一停下就难以为继,实属不应 1. 盒子的水平宽度 当一个盒子出现在另一个盒子的内容区时,该盒子的水平宽度“必须”等于父元素内容区的宽度 盒子水平宽度: margin-left border-left padding-lef…...

【MySQL基础】:深入探索DQL数据库查询语言的精髓(上)
🎥 屿小夏 : 个人主页 🔥个人专栏 : MySQL从入门到进阶 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑前言一. DQL1.1 基本语法1.2 基础查询1.3 条件查询1.3 聚合函数 🌤️ 全篇…...

JavaScript实现轮播图方法
效果图 先来看下效果图,嫌麻烦就不用具体图片来实现了,主要是理清思路。(自动轮播,左右按钮切换图片,小圆点切换图片,鼠标移入暂停轮播,鼠标移出继续轮播) HTML 首先是html内容&am…...

Web课程学习笔记--jsonp的原理与简单实现
jsonp的原理与简单实现 原理 由于同源策略的限制,XmlHttpRequest只允许请求当前源(域名、协议、端口)的资源,为了实现跨域请求,可以通过script标签实现跨域请求,然后在服务端输出JSON数据并执行回调函数&…...
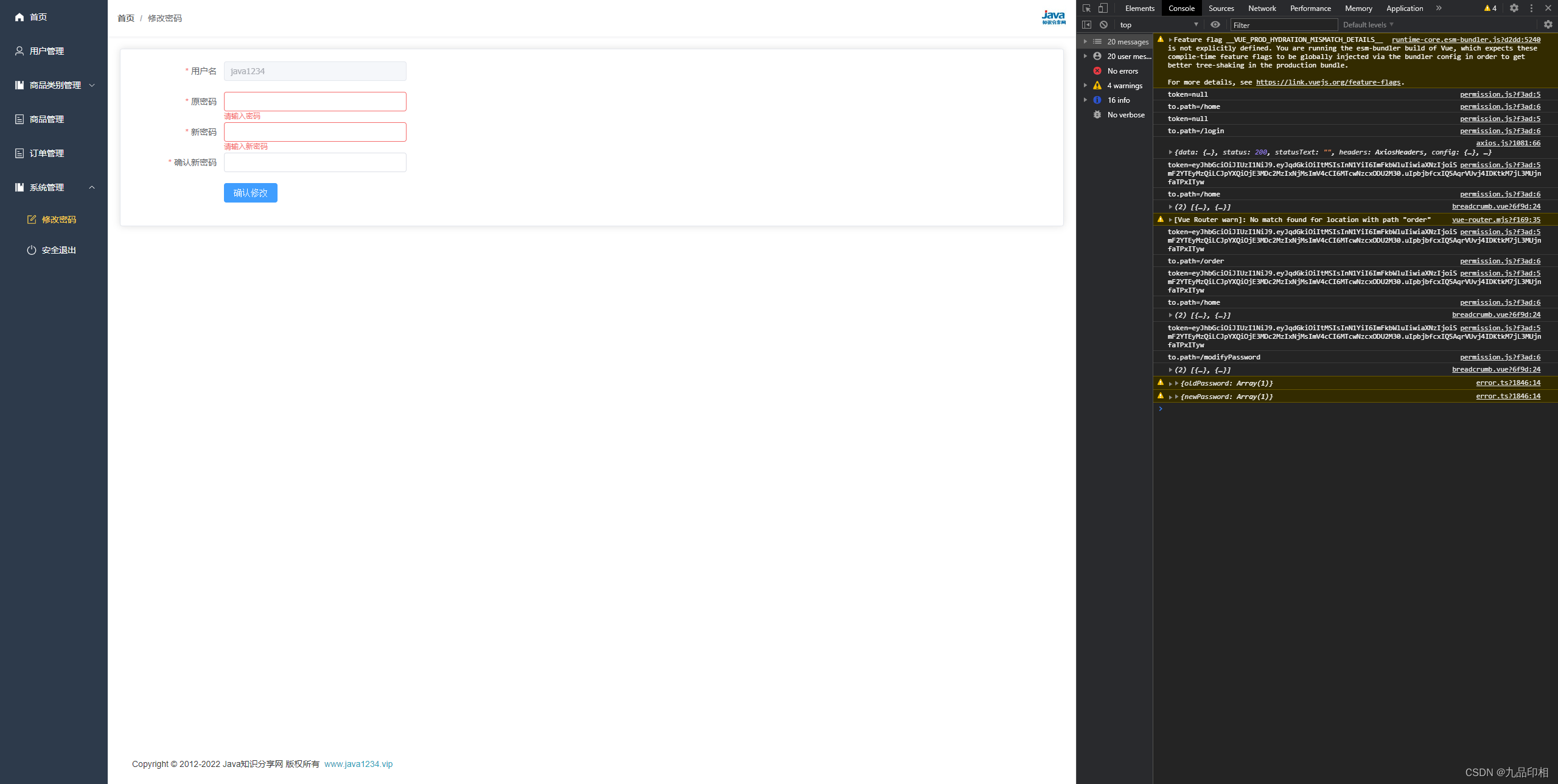
第78讲 修改密码
系统管理实现 修改密码实现 前端 modifyPassword.vue: <template><el-card><el-formref"formRef":model"form":rules"rules"label-width"150px"><el-form-item label"用户名:&quo…...
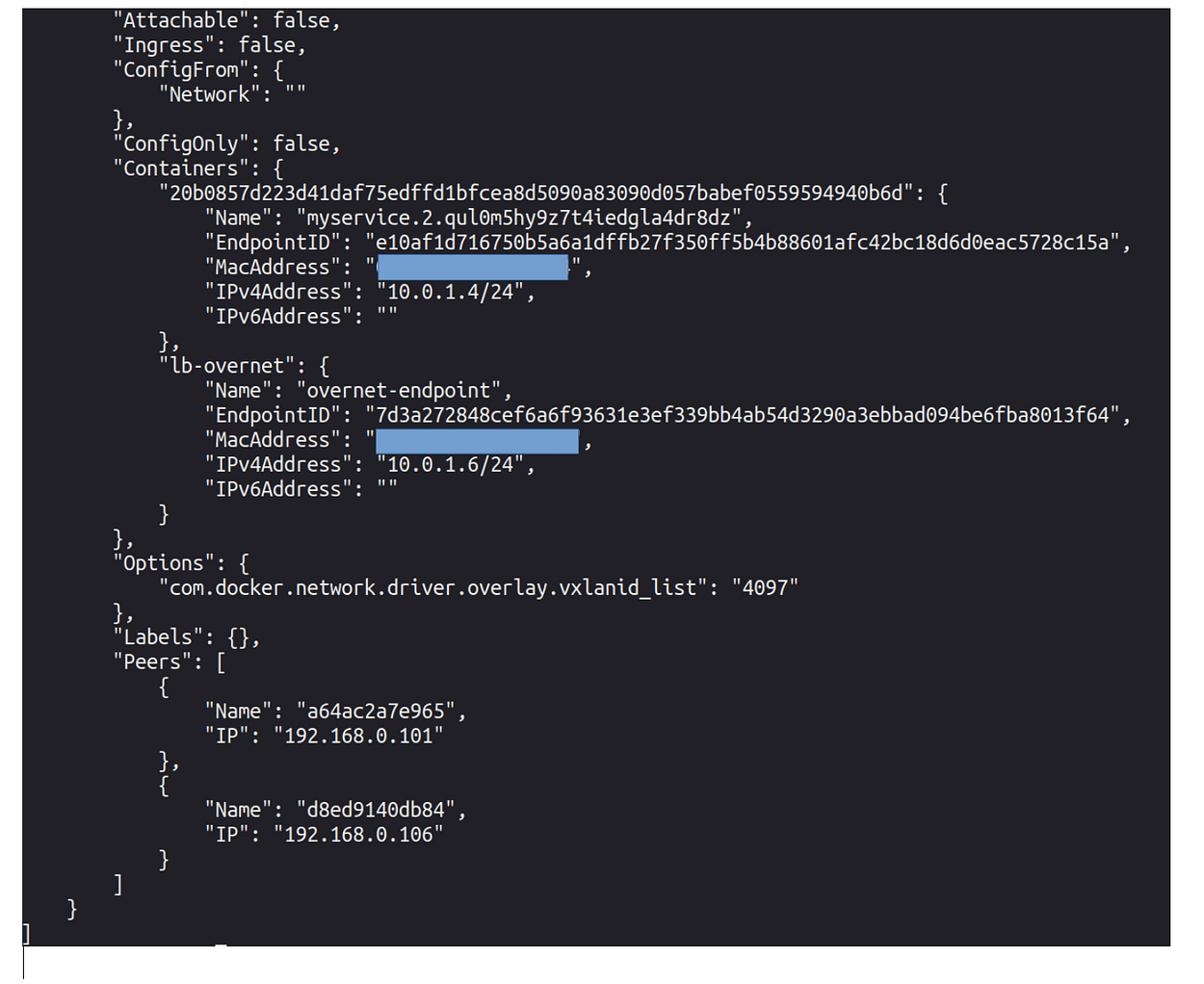
Docker 容器网络:C++ 客户端 — 服务器应用程序。
一、说明 在下面的文章中, 将向您概述 docker 容器之间的通信。docker 通信的验证将通过运行 C 客户端-服务器应用程序和标准“ping”命令来执行。将构建并运行两个单独的 Docker 映像。 由于我会关注 docker 网络方面,因此不会提供 C 详细信息。…...
Android 识别车牌信息
打开我们心爱的Android Studio 导入需要的资源 gradle //开源车牌识别安卓SDK库implementation("com.github.HyperInspire:hyperlpr3-android-sdk:1.0.3")button.setOnClickListener(v -> {Log.d("Test", "");try (InputStream file getAs…...
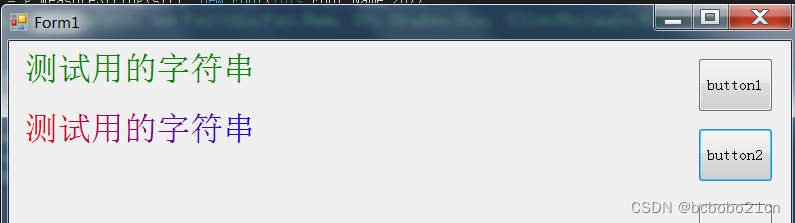
C#在窗体正中输出文字以及输出文字的画刷使用
为了在窗体正中输出文字,需要获得输出文字区域的宽和高,这使用MeasureString方法,方法返回值为Size类型; 然后计算输出的起点的x和y坐标,就可以输出了; using System; using System.Collections.Generic; …...
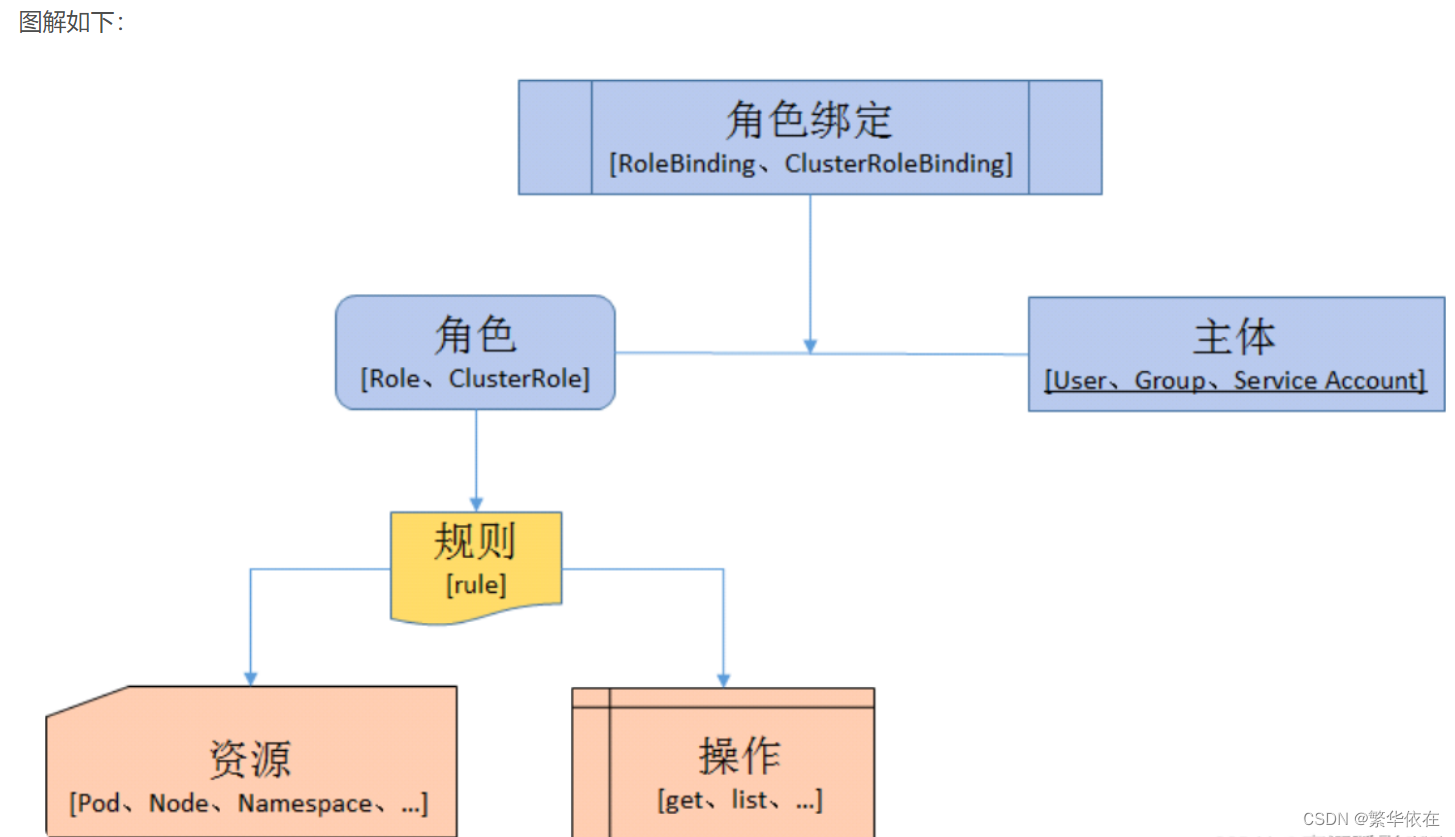
二十、K8S-1-权限管理RBAC详解
目录 k8s RBAC 权限管理详解 一、简介 二、用户分类 1、普通用户 2、ServiceAccount 三、k8s角色&角色绑定 1、授权介绍: 1.1 定义角色: 1.2 绑定角色: 1.3主体(subject) 2、角色(Role和Cluster…...
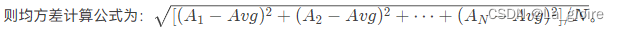
【PTA|期末复习|编程题】数组相关编程题(一)
目录 7-1 乘法口诀数列 (20分) 输入格式: 输出格式: 输入样例: 输出样例: 样例解释: 代码 7-2 矩阵列平移(20分) 输入格式: 输出格式: 输入样例: 输出样例: …...
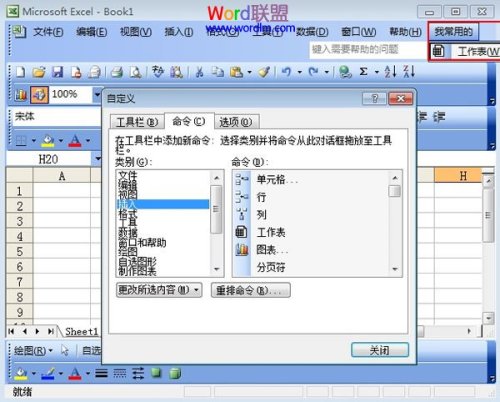
[office] 怎么在Excel2003菜单栏自定义一个选项卡 #其他#微信#知识分享
怎么在Excel2003菜单栏自定义一个选项卡 怎么在Excel2003菜单栏自定义一个选项卡 ①启动Excel2003,单击菜单栏--工具--自定义。 ②在自定义界面,我们单击命令标签,在类别中选择新菜单,鼠标左键按住新菜单,拖放到菜单栏…...
)
告别全屏地球!用Cesium.js在地图上只显示一个县(附完整代码)
用Cesium.js实现区域聚焦:打造专属行政区划三维地图 在WebGIS开发中,我们经常遇到需要将三维地球的显示范围限定在特定行政区划内的需求。无论是为了突出展示某个城市的发展规划,还是为了制作县域级别的专题地图,区域聚焦技术都能…...

Claude Code提示词入门:CLAUDE.md编写完全指南
目录Claude Code提示词入门:CLAUDE.md编写完全指南 🎯📌 目录1. 什么是CLAUDE.md2. 为什么CLAUDE.md这么重要2.1 没有CLAUDE.md会怎样?2.2 有了CLAUDE.md会怎样?2.3 核心价值3. CLAUDE.md的加载机制3.1 加载优先级3.2 …...

Kimsuky 组织基于 PebbleDash 与 AppleSeed 的攻击战术演进与技术分析
摘要 Kimsuky(亦称 APT43、Ruby Sleet 等)是活跃逾十年的朝鲜语系高级持续性威胁(APT)组织,长期针对韩国及全球多国政府、国防、医疗等关键领域实施定向攻击。本文基于卡巴斯基 GReAT 团队 2026 年 5 月公开的最新攻击…...
)
从集合运算到代码实战:一文搞懂Python中Jaccard相似度的5种计算姿势(附性能对比)
从集合运算到代码实战:一文搞懂Python中Jaccard相似度的5种计算姿势(附性能对比) 在数据科学和机器学习领域,集合相似度计算是一个基础但至关重要的任务。想象一下这样的场景:你需要比较数百万用户的兴趣标签ÿ…...

APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案
APK安装器完整指南:在Windows上直接安装安卓应用的专业解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓…...

在Python项目中集成多模型API实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中集成多模型API实现智能对话功能 对于需要在应用中集成AI对话能力的Python开发者而言,直接对接多个模型厂…...

Cursor AI插件深度解析:从自动化脚本到智能编程工作流
1. 项目概述:一个为 Cursor 编辑器注入灵魂的 AI 增强插件如果你和我一样,日常开发重度依赖 Cursor 这款“AI 原生”编辑器,那你一定体验过它内置的 AI 对话和代码生成带来的效率提升。但用久了,你可能会发现一些痒点:…...

Markdown到思维导图的架构化转换:基于AST解析与D3渲染的技术实现
Markdown到思维导图的架构化转换:基于AST解析与D3渲染的技术实现 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap Markdown思维导图转换技术通过结构化文本解析与可视化渲染引擎的协同工作&a…...

基于Vue3+TypeScript的ChatGPT风格前端界面集成实战
1. 项目概述与核心价值最近在折腾一个个人项目,想给一个静态网站加上智能对话的能力,让访客能随时问点问题。一开始想自己从零搭建,但考虑到前后端、AI接口、实时通信这些环节,工作量着实不小。后来在GitHub上逛的时候,…...
功能仿真)
在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真
目录 🛠️ 第一步:系统架构设计与模块搭建 ⚙️ 第二步:SVG 核心控制策略设计(双闭环控制) 📊 第三步:仿真运行与结果分析 手把手教你在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真。 在现代电力系统中,并网逆变器(如光伏、储能逆变器)不…...