LRU缓存
有人从网络读数据,有人从磁盘读数据, 机智的人懂得合理利用缓存加速数据的读取效率,提升程序的性能,搏得上司的赏识,赢得白富美的青睐,进一步走向人生巅峰~
机智的人懂得合理利用缓存加速数据的读取效率,提升程序的性能,搏得上司的赏识,赢得白富美的青睐,进一步走向人生巅峰~

LRU假说
LRU缓存(Least Recently Used Cache)即最近最少使用缓存算法,是一种常用的缓存淘汰策略,它基于这样一个假设:
如果数据最近被访问过,那么它在未来被访问的可能性也更高。
因此,当缓存空间不足时,LRU缓存会优先移除最长时间未被访问的数据项。
LRU是怎么干活的
新访问的数据添加到缓存
当一个数据项被访问时,它会被添加到缓存中。如果该数据项已经在缓存中,它会被更新,并且移动到缓存的最前面,表示最近被访问过。
缓存满时移除最老的数据
如果缓存已满(达到预设的容量限制),最久未被访问的数据项(位于缓存的最后面)会被移除,以便为新的数据项腾出空间。
维护访问顺序
缓存需要维护数据项的访问顺序,以便快速确定哪些数据项是最近被访问的,哪些是最久未被访问的。
为了有效地实现LRU缓存,通常需要以下两种数据结构:
双向链表:用于维护数据项的访问顺序。最近访问的数据项位于链表一头,最久未访问的数据项位于链表另一头。当数据项被访问时,它会被移动到链表最近访问那一头。当需要移除数据项时,最久未访问的末尾数据项会被移除。
哈希表:用于存储键和指向双向链表中相应节点的指针,以便快速定位缓存中的数据项。这样可以在O(1)时间复杂度内访问缓存项。

LRU的简单示例
如下是一个简单的LRU实现 :
:
#include <iostream>
#include <list>
#include <string>
#include <unordered_map>
#include <vector>using namespace std;template <typename K, typename V>
class LRUCache {
public:LRUCache(int capacity) {cap = capacity;}V get(const K& key) {auto it = hash.find(key);if (it == hash.end()) {return V();}auto val = it->second->second;put(key, val);return val;}void put(const K& key, const V& value) {auto it = hash.find(key);if (it == hash.end()) {if (hash.size() >= cap) {auto d_it = data_list.begin();auto h_it = d_it->first;data_list.erase(d_it);hash.erase(h_it);}} else {auto d_it = it->second;data_list.erase(d_it);hash.erase(it);}data_list.emplace_back(key, value);hash[key] = --data_list.end();}private:int cap;list<pair<K, V> > data_list;using LIST_IT = typename list<pair<K, V> >::iterator;unordered_map<K, LIST_IT> hash;
};int main() {LRUCache<int, int> lru(2);vector<pair<string, vector<int> > > test_case = {{"put", {1, 1}},{"put", {2, 2}},{"get", {1}},{"put", {3, 3}},{"get", {2}},{"put", {4, 4}},{"get", {1}},{"get", {3}},{"get", {4}},};for (const auto& [opt, param] : test_case) {if (opt == "get") {auto val = lru.get(param.front());cout << val << endl;} else {lru.put(param.front(), param.back());}}return 0;
}运行测试用例可以得到如下结果:
code % g++ lru.cpp -std=c++17
code % ./a.out
1
0
0
3
4
code % 如上,实现一个LRU的代码量并不算多,并且简单易懂,性能也很不错,毕竟时间复杂度为O(1)。但LRU也有其缺点,例如它没有考虑数据的访问频率。这可能会导致一些不经常使用的数据被缓存,而一些经常使用的数据被淘汰 。
。
LRU的改进-LFU
LFU(Least Frequently Used),即最少使用频率缓存,考虑到访问频率,而不是最近一次访问时间。其可以与LRU结合,形成其他变种,以更好地适应不同的数据访问模式。
LFU的简单示例
例如,可以通过给LRU缓存数据项加上访问频率,当缓存满需要淘汰时,取尾部的数据选一个访问频次最低的来淘汰 :
:
#include <iostream>
#include <list>
#include <string>
#include <unordered_map>
#include <vector>using namespace std;template <typename K, typename V>
class LRUCache {
public:LRUCache(int capacity) {cap = capacity;}V get(const K& key) {auto it = hash.find(key);if (it == hash.end()) {return V();}const auto& data_tuple = *(it->second);auto val = std::get<1>(data_tuple);auto cnt = std::get<2>(data_tuple);put(key, val, cnt + 1);return val;}void put(const K& key, const V& value, int cnt = 1) {auto it = hash.find(key);if (it == hash.end()) {if (hash.size() >= cap) {remove_one_elem();}} else {auto d_it = it->second;data_list.erase(d_it);hash.erase(it);}data_list.emplace_back(key, value, cnt);hash[key] = --data_list.end();}private:void remove_one_elem() {auto need_rm = data_list.begin();auto it = need_rm;for (int i = 1; i < 3 && it != data_list.end(); ++i, ++it) {if (std::get<2>(*it) < std::get<2>(*need_rm)) {need_rm = it;}}hash.erase(std::get<0>(*need_rm));data_list.erase(need_rm);}private:int cap;list<tuple<K, V, int> > data_list;using LIST_IT = typename list<tuple<K, V, int> >::iterator;unordered_map<K, LIST_IT> hash;
};int main() {LRUCache<int, int> lru(2);vector<pair<string, vector<int> > > test_case = {{"put", {1, 1}},{"put", {2, 2}},{"get", {1}},{"put", {3, 3}},{"get", {2}},{"put", {4, 4}},{"get", {1}},{"get", {3}},{"get", {4}},};for (const auto& [opt, param] : test_case) {if (opt == "get") {auto val = lru.get(param.front());cout << val << endl;} else {lru.put(param.front(), param.back());}}return 0;
}运行测试用例可以得到如下结果:
code % g++ lfu.cpp -std=c++17
code % ./a.out
1
0
1
0
4
code % 与LRU示例的差异点在于,当缓存满时,LFU为从最近未使用的一头,挑选一个访问频次最小的元素进行淘汰。值得注意的是,挑选最少频次并不需要遍历所有的数据,而是针对具体的业务场景,设定一个合适的值即可。
虽然LRU开销很小,时间复杂度又是O(1),但毕竟每次访问都需要调整链表,对于一些性能要求高的场景,负担还是有点重的 ,实际的使用场景中,又会根据具体的业务场景,做一些响应的改变。
,实际的使用场景中,又会根据具体的业务场景,做一些响应的改变。
衍生一下
Clock算法
Clock算法是一种用于页面置换的缓存淘汰策略,它是LRU算法的一种近似实现,旨在降低实现LRU的开销。Clock算法有时也被称为Second-Chance算法,因为它给了每个页面一个“第二次机会”来避免被置换。
Clock是怎么干活的
Clock算法维护一个循环链表:所有的页面都被组织成一个循环链表(或称为时钟![]() 结构),每个页面都有一个关联的访问位(通常是一个标志位),用于表示该页面自上次检查以来是否被访问过。
结构),每个页面都有一个关联的访问位(通常是一个标志位),用于表示该页面自上次检查以来是否被访问过。
使用指针指向链表中的一个页面:有一个指针(称为时钟指针)指向循环链表中的某个页面。
维护访问位:当一个页面被访问时,其访问位被设置为1,表示该页面最近被使用过。
缓存满时检查访问位:当有新需要加载到缓存中,但缓存已满,算法会检查当前时钟指针指向的页面的访问位。如果访问位为1,则将其清零(给予第二次机会),并将时钟指针移动到下一个页面。如果访问位为0,则选择该页面进行置换 。
。
Clock算法的优点是实现简单,开销较低,因为它不需要像真正的LRU算法那样在每次页面访问时都对链表进行调整。它只需要在页面置换时检查和更新访问位。这使得Clock算法特别适合于大规模的缓存系统,如操作系统的页面缓存。
Clock算法的缺点是它不是完全精确的LRU实现,因为它可能会保留一些不太常用的页面(如果它们在时钟指针到达之前刚好被访问过)。然而,对于许多实际应用来说,Clock算法提供了一个很好的折中方案,既保留了LRU的大部分优点,又显著降低了实现的复杂性和开销。
相关文章:
LRU缓存
有人从网络读数据,有人从磁盘读数据,机智的人懂得合理利用缓存加速数据的读取效率,提升程序的性能,搏得上司的赏识,赢得白富美的青睐,进一步走向人生巅峰~ LRU假说 LRU缓存(Least Recently Used…...
ncc匹配提速总结
我们ncc最原始的匹配方法是:学习模板w*h个像素都要带入ncc公式计算 第一种提速,学习模板是w*h,而我们支取其中的w/2*h/2,匹配窗口同理,计算量只有1/4。 另外一种因为ncc是线性匹配,我们在这上面也做了文章࿰…...

人力资源智能化管理项目(day06:员工管理)
学习源码可以看我的个人前端学习笔记 (github.com):qdxzw/humanResourceIntelligentManagementProject 页面结构 <template><div class"container"><div class"app-container"><div class"left"><el-input style&qu…...

Java实现数据可视化的智慧河南大屏 JAVA+Vue+SpringBoot+MySQL
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、系统展示四、核心代码4.1 数据模块 A4.2 数据模块 B4.3 数据模块 C4.4 数据模块 D4.5 数据模块 E 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的数据可视化的智慧河南大屏,包含了GDP、…...
)
【Flink】FlinkSQL的DataGen连接器(测试利器)
简介 我们在实际开发过程中可以使用FlinkSQL的DataGen连接器实现FlinkSQL的批或者流模拟数据生成,DataGen 连接器允许按数据生成规则进行读取,但注意:DataGen连接器不支持复杂类型: Array,Map,Row。 请用计算列构造这些类型 创建有界DataGen表 CREATE TABLE test ( a…...

5G NR 频率计算
5G中引入了频率栅格的概念,也就是小区中心频点和SSB的频域位置不能随意配置,必须满足一定规律,主要目的是为了UE能快速的搜索小区;其中三个最重要的概念是Channel raster 、synchronization raster和pointA。 1、Channel raster …...
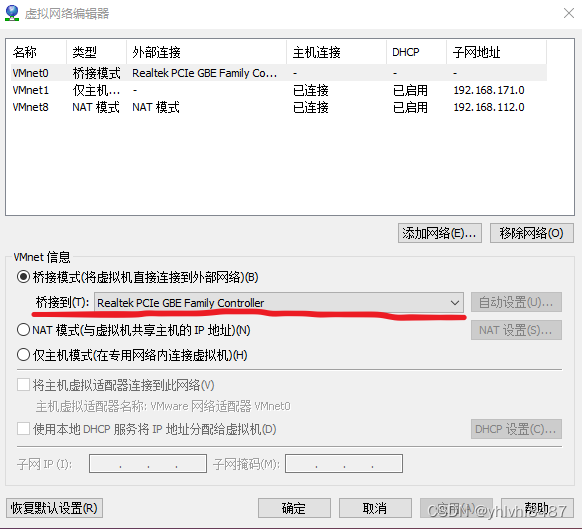
关于物理机ping不通虚拟机问题
方法一 设置虚拟机处于桥接状态即可:(虚拟机->设置->网络适配器),选择完确定,重启虚拟机即可。 方法二 如果以上配置还是无法ping通:(编辑->虚拟网络编辑器) 首先查看主机网…...

深度学习在知识图谱问答中的革新与挑战
目录 前言1 背景知识2 基于深度学习改进问句解析模型2.1 谓词匹配2.2 问句解析2.3 逐步生成查询图 3 基于深度学习的端到端模型3.1 端到端框架3.2 简单嵌入技术 4 优势4.1 深入的问题表示4.2 实体关系表示深挖4.3 候选答案排序效果好 5 挑战5.1 依赖大量训练语料5.2 推理类问句…...
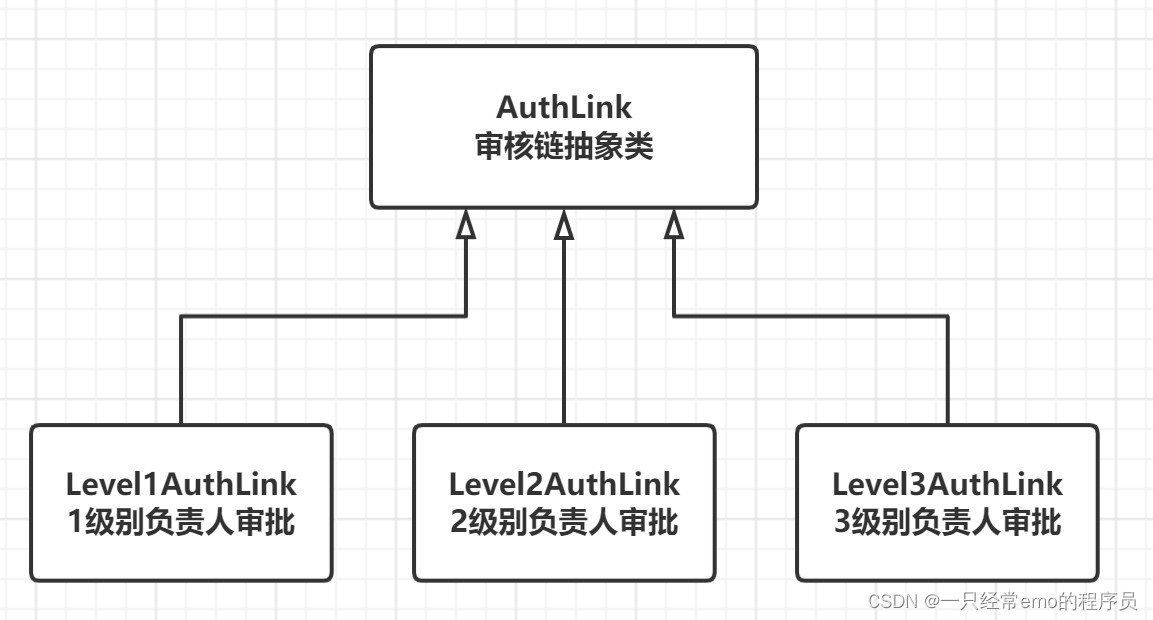
JAVA设计模式之职责链模式详解
职责链模式 1 职责链模式介绍 职责链模式(chain of responsibility pattern) 定义: 避免将一个请求的发送者与接收者耦合在一起,让多个对象都有机会处理请求.将接收请求的对象连接成一条链,并且沿着这条链传递请求,直到有一个对象能够处理它为止. 在职责链模式中,…...

CSP-201912-1-报数
CSP-201912-1-报数 知识点总结 整数转化为字符串#include <string> string str_num to_string(num);字符串中查找是否包含字符‘7’:str_num.find(7) 未找到返回-1找到返回返回该字符在字符串中的位置(即第一次出现的索引位置) #i…...
前后端分离好处多多,怕就怕分工不分人,哈哈
前后端分离倡导多年了,现在基本成为了开发的主流模式了,贝格前端工场承接的前端项目只要不考虑seo的,都采用前后端分离模式,这篇文章就来介绍一下前后端分离模式。 一、什么是前后端分离开发模式 前后端分离是一种软件开发的架构…...
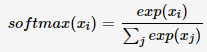
机器学习:Softmax介绍及代码实现
Softmax原理 Softmax函数用于将分类结果归一化,形成一个概率分布。作用类似于二分类中的Sigmoid函数。 对于一个k维向量z,我们想把这个结果转换为一个k个类别的概率分布p(z)。softmax可以用于实现上述结果,具体计算公式为: 对于…...
python基于flask的网上订餐系统769b9-django+vue
课题主要分为两大模块:即管理员模块和用户模块,主要功能包括个人中心、用户管理、菜品类型管理、菜品信息管理、留言反馈、在线交流、系统管理、订单管理等; 如果用户想要交换信息,他们需要满足双方交换信息的需要。由于时间有限…...
jenkins 发布远程服务器并部署项目
安装参考另一个文章 配置maven 和 jdk 和 git 注意jdk的安装目录,是jenkins 安装所在服务器的jdk目录 注意maven的目录 是jenkins 安装所在服务器的maven目录 注意git的目录 是jenkins 安装所在服务器的 git 目录 安装 Publish Over SSH 插件 配置远程服务器 创…...

【数学建模】【2024年】【第40届】【MCM/ICM】【D题 五大湖的水位控制问题】【解题思路】
一、题目 (一) 赛题原文 2024 ICM Problem D: Great Lakes Water Problem Background The Great Lakes of the United States and Canada are the largest group of freshwater lakes in the world. The five lakes and connecting waterways const…...
【开源】JAVA+Vue+SpringBoot实现公司货物订单管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 客户管理模块2.2 商品维护模块2.3 供应商管理模块2.4 订单管理模块 三、系统展示四、核心代码4.1 查询供应商信息4.2 新增商品信息4.3 查询客户信息4.4 新增订单信息4.5 添加跟进子订单 五、免责说明 一、摘要 1.1 项目…...

###C语言程序设计-----C语言学习(12)#进制间转换,十进制,二进制,八进制,十六进制
前言:感谢您的关注哦,我会持续更新编程相关知识,愿您在这里有所收获。如果有任何问题,欢迎沟通交流!期待与您在学习编程的道路上共同进步。 计算机处理的所有信息都以二进制形式表示,即数据的存储和计算都采…...

锐捷设备常用命令
一、命令模式 命令行主要有用户模式、特权模式、全局模式、VLAN模式、接口模式、线程模式 switch> "用户模式"switch# "特权模式"switch(config) "全局模式"switch(conf…...

python:lxml 读目录.txt文件,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。 pip install lxml ; lxml-5.1.0-cp310-cp310-win_amd64.whl (3.9 MB) pip install xmltodict ; lxml 读目录.txt文件&…...

【Spring】Spring 对 Ioc 的实现
一、Ioc 控制反转 控制反转是一种思想 控制反转是为了降低程序耦合度,提高程序扩展力,达到 OCP 原则,达到 DIP 原则 控制反转,反转的是什么? 将对象的创建权利交出去,交给第三方容器负责 将对象和对象之…...

高性能WebGL地图引擎OME:海量地理空间数据可视化实战指南
1. 项目概述与核心价值 如果你在开源社区里混迹过一段时间,尤其是对数据可视化、地理信息系统或者大规模图数据渲染感兴趣,那么“sgl-project/ome”这个项目标题很可能已经引起了你的注意。OME,全称可能是“Open Map Engine”或类似的概念&am…...

新时代的信息茧房
大家有没有发现:信息爆炸 2.0 时代,获取真知为何反而更难了? 人类正身处信息传播最为便捷的时代。移动互联网的普及与信息技术的迭代升级,让知识获取变得前所未有的低廉易得。迈入 AI 时代后,这一发展进程更是被推至全…...

ppt模板_0028_94tm灰色--通用
PPT模板分享...

MIMO AONN架构:量子干涉实现超低功耗光学神经网络
1. MIMO AONN架构的核心价值光学神经网络(AONN)正在突破传统电子计算的物理极限。在传统电子神经网络中,非线性激活函数需要消耗大量能量进行电子-光子转换,而基于量子干涉的光学非线性机制可以直接在光域实现这一关键操作。我们实…...

Loop窗口管理:5个高效工作流提升你的Mac生产力
Loop窗口管理:5个高效工作流提升你的Mac生产力 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop Loop是一款为macOS设计的优雅窗口管理工具,通过径向菜单、快捷键绑定和智能窗口操…...

从 BGE 到 Qwen3:中文 RAG Reranker 模型解析
在 RAG 系统中,Reranker 往往是决定最终检索质量的关键一环,却也是最容易被忽视的模块。本文从 Reranker 的基本原理出发,介绍 Reranker Encoder 和 Decoder 两类架构的工作机制,随后解析目前中文场景下最主流的两大模型系列BGE-R…...

实战配置:5个提升MPC-HC播放器性能的专业技巧
实战配置:5个提升MPC-HC播放器性能的专业技巧 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc Media Player Classic - Home Cinema࿰…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...
)
NotebookLM笔记导出全链路实操指南:从Chrome插件绕过限制到API直连导出(含Python脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记导出全链路概览 NotebookLM 是 Google 推出的基于用户上传文档构建个性化知识代理的 AI 工具,其核心价值在于语义理解与上下文生成,但原生不提供直接导出原始笔记…...

通过curl命令直接调用Taotoken大模型API的排错指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接调用Taotoken大模型API的排错指南 对于需要在无SDK环境下进行快速测试、调试或集成的开发者而言,直接…...