离线数仓(一)【数仓概念、需求架构】
前言
今天开始学习数仓的内容,之前花费一年半的时间已经学完了 Hadoop、Hive、Zookeeper、Spark、HBase、Flume、Sqoop、Kafka、Flink 等基础组件。把学过的内容用到实践这是最重要的,相信会有很大的收获。
1、数据仓库概念
1.1、概念
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。(数据仓库的目的不只是简单的存储数据,而是把收集起来的数据进行计算分析,得到有价值的信息)
1.2、数据分类
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中(要求响应要快)。
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
爬虫数据:通常是通过爬虫等技术获取其他公司网站的数据。
1.3、数仓架构
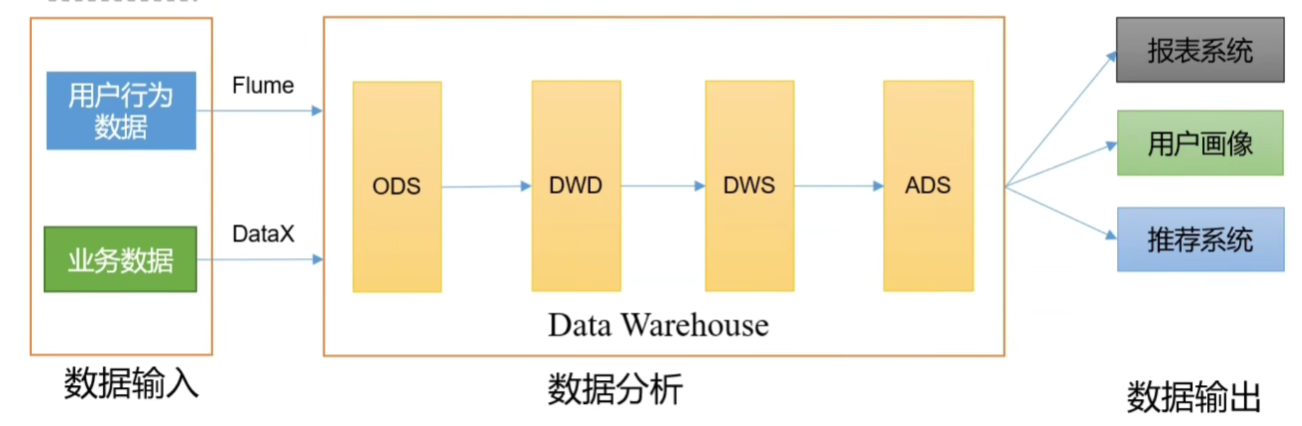
- ODS 层(原始数据层):离线数仓中一般是 Hive,用来做数据备份(如果后面的 DWD 、DWS、ADS 层数据丢失,都可以通过上一层来进行恢复)
- DWD 层(明细数据层):主要做数据清洗(对错误缺失数据进行处理,以及一些隐私信息的脱敏)
- DWS 层(汇总数据层):预聚合(做一些表的连接 join 之类的操作,提前 join,节省计算开销)
- ADS 层(数据应用层):统计最终指标
数据仓库并不是数据的最终目的,而是为数据最终的目的做准备,包括比如:备份、清洗、聚合、统计等。
2、项目需求及架构设计
2.1、项目需求分析
1)采集平台
- 用户行为数据采集平台搭建
- 业务数据采集平台搭建
2)离线需求
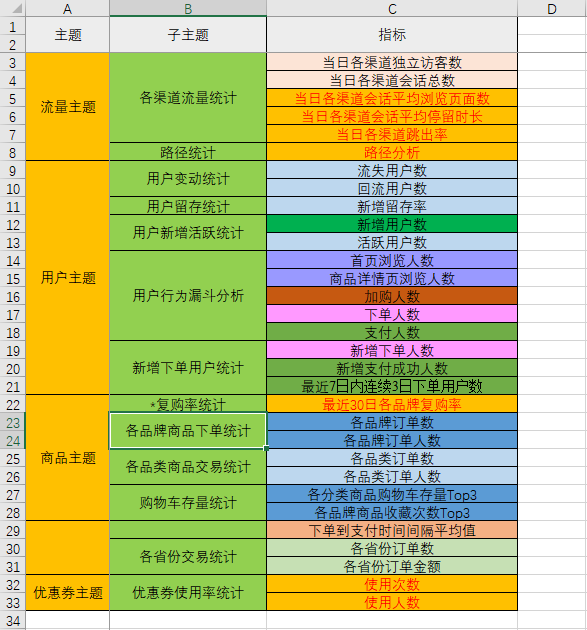
3)实时需求

2.2、项目框架
1. 技术选型
考虑因素:数据量大小、业务需求、行业内经验、技术成熟度(比如spark/flink)、开发维护成本、总成本预算等
- 数据采集传输:Flume(用户行为数据采集,因为这部分数据都是日志文件的形式),DataX(业务数据采集,因为要把数据从 MySQL 传输到 HDFS),MaxWell(功能类似于 DataX 但是 DataX 是全量同步,MaxWell 是增量同步),Kafka(流量削峰),Sqoop(功能和 Datax 一样,也可以使用)
- 数据存储:MySQL(离线数仓和实时数仓的计算结果都会存到 MySQL 供数据展示),HDFS,HBase(实时数仓),Redis(实时数仓),MongoDB(一般存储爬虫的数据,这里不用)
- 数据计算:Hive,Spark(一般只用在离线,Hive on Spark 结合使用),Flink,Storm(这里不用),Tez(同样是一个基于内存的离线引擎,这里也不用)
- 即席查询:Presto(用于离线),Kylin(用于离线,这里不用),Impala(用于离线,这里不用),Druid(用于实时,这里不用),ClickHouse(用于实时),Doris(用于实时,这里不用)
- 数据可视化;Superset(用于离线),Echarts,Sugar(用于实时),QuickBI,DataV
- 任务调度:DolphinScheduler(国产开源,兼具轻量级和功能丰富,用于离线),Azkaban(轻量级,用法简单),Oozie(重量级,功能更多),Airflow(Python 写的一款框架)
- 集群监控:Zabbix(离线),Prometheus(实时)
- 元数据管理:Atlas(管理表和表之间的关系)
- 权限管理:Ranger(HDP 公司),Sentry(CDH 公司)
2. 系统数据流设计
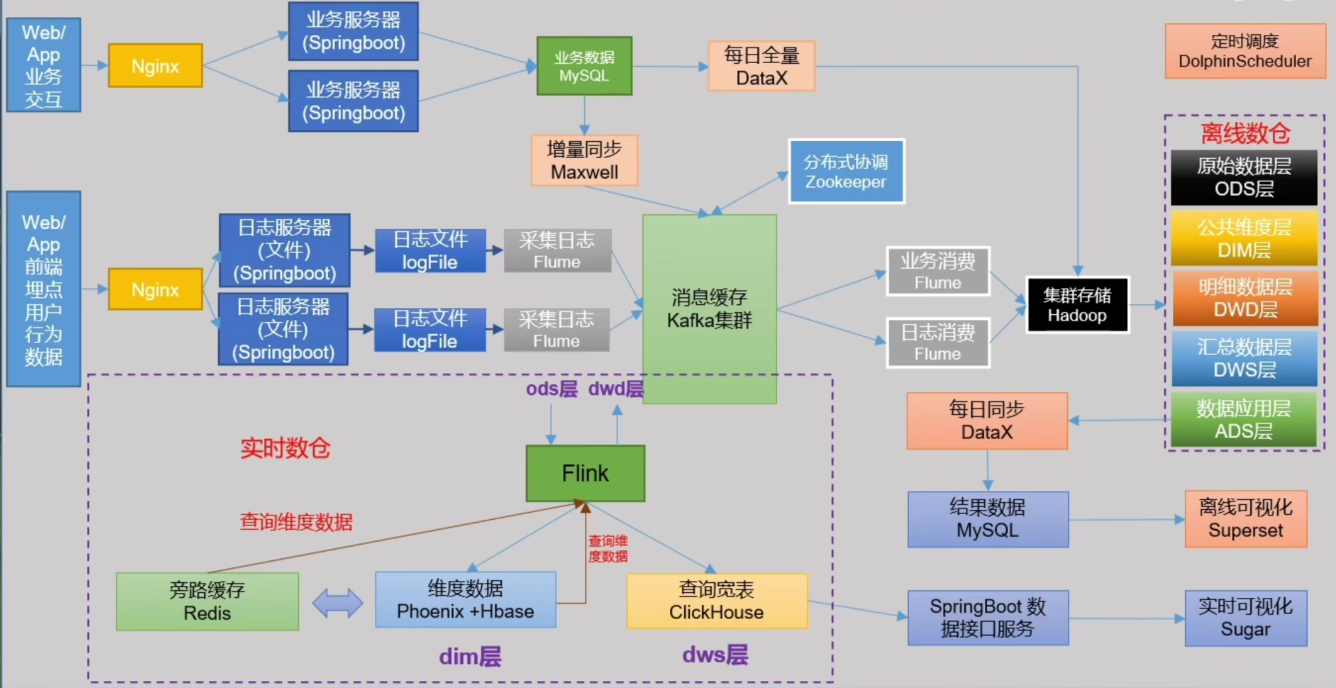
这里 Kafka 不管是离线数仓还是实时数仓都是一个不可缺少的中间件。
3. 框架版本选项
3.1、Apache/CDH/HDP
我们使用 Apache 版本,但是组件的兼容性需要我们自己解决。
CDH 版本很稳定但是它是收费的,HDP 版本可以二次开发但是不稳定。
3.2、云服务
- 阿里云 EMR(包含常用的大部分大数据框架)、MaxCompute、DataWorks
- 亚马逊 EMR
- 腾讯云 EMR
- 华为云 EMR
3.3、具体版本选择
- Hadoop 3.1.3
- Zookeeper 3.5.7
- MySQL 5.7.16
- Hive 3.1.2
- Flume 1.9.0
- Kafka 3.0.0
- Spark 3.0.0
- DataX 3.0.0
- Superset 1.3.2
- Dolphinscheduler 2.0.3
- Maxwell 1.29.2
- Flink 1.13.0
- Redis 6.0.8
- HBase 2.0.5
- ClickHouse 20.4.5.36-2
4. 服务器选型
4.1、物理机
- 128G 内存,20 核物理 CPU,40 线程,8 THDD 和 2T SSD 硬盘,戴尔品牌单台报价 4w+ ,寿命 5 年左右。
- 需要考虑运维人员、电费成本。
4.2、云主机
- 5w 左右每年,不需要考虑运维、电费成本。
4.3、企业选择
- 有钱的公司(大城市的一些对技术不太讲究的公司,比如金融公司)会选择阿里云
- 中小型公司有钱后会购买物理机(数据放在自己手里更放心)
- 有长期打算,资金充足的公司也会选择物理机
5. 集群规模
确认集群规模:
- 每天日活跃用户 100 万,每人每天创造 100 条数据: 100w * 100 = 1亿条
- 每条数据 1KB ,每天:1亿 / 1024 / 1024 ≈ 100GB
- 半年不扩容服务器来算:100GB * 180天 ≈ 18TB
- 保存 3 个副本:18TB * 3 = 54 TB
- 预留 20%~30% buf:54TB / 0.7 = 77TB
算到这里需要大概 8T * 10 台服务器,但是数仓是分层的,我们的数据在 ODS 层(原始数据层)是主要的消耗磁盘的地方,而其他几层也是需要消耗磁盘存放中间结果的,所以结果应该比我们预估的更大!但是又考虑到数据在存储时可以压缩(100GB 可以压缩到 5~10GB左右),所以我们其实只需要 3 台服务器就可以保证半年内每天 100 GB 数据的计算存储,5~10 台服务器则可以保证 2~3 年数据该数据的计算和存储。
6. 集群资源规划设计
在企业中通常会搭建一套生产集群(十几、甚至几十几百台)和一套测试集群(3~5台)。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
| 服务名称 | 子服务 | 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume (消费Kafka日志) | Flume | √ | ||
| Flume (消费Kafka业务) | Flume | √ | ||
| Hive | √ | √ | √ | |
| MySQL | MySQL | √ | ||
| DataX | √ | √ | √ | |
| Spark | √ | √ | √ | |
| DolphinScheduler | ApiApplicationServer | √ | ||
| AlertServer | √ | |||
| MasterServer | √ | |||
| WorkerServer | √ | √ | √ | |
| LoggerServer | √ | √ | √ | |
| Superset | Superset | √ | ||
| Flink | √ | |||
| ClickHouse | √ | |||
| Redis | √ | |||
| Hbase | √ | |||
| 服务数总计 | 20 | 11 | 12 |
总结
到这里,数仓基本的概念是了解了,这个项目会用到哪些技术也基本明白了(Hadoop、Hive、MySQL、Spark、Flume、Kafka、HBase、DataX等),接下来就是慢慢熟练之前学的哪些框架在实际应用中是怎么使用的,一些没学过的框架(比如 DataX、Superset、DoplhinScheduler)慢慢补,都是小工具 so easy。
相关文章:
离线数仓(一)【数仓概念、需求架构】
前言 今天开始学习数仓的内容,之前花费一年半的时间已经学完了 Hadoop、Hive、Zookeeper、Spark、HBase、Flume、Sqoop、Kafka、Flink 等基础组件。把学过的内容用到实践这是最重要的,相信会有很大的收获。 1、数据仓库概念 1.1、概念 数据仓库&#x…...

物联网测试:2024 年的最佳实践和挑战
据 Transforma Insights 称,到 2030 年,全球广泛使用的物联网 (IoT) 设备预计将增加近一倍,从 151 亿台增至 290 亿台。这些设备以及智能汽车、智能手机等广泛应用于各种官僚机构。 健康视频监视器、闹钟以及咖啡机和冰箱等最受欢迎的家用电器…...

蓝桥杯Web应用开发-CSS3 新特性
CSS3 新特性 专栏持续更新中 在前面我们已经学习了元素选择器、id 选择器和类选择器,我们可以通过标签名、id 名、类名给指定元素设置样式。 现在我们继续选择器之旅,学习 CSS3 中新增的三类选择器,分别是: • 属性选择器 • 子…...

MongoDB聚合:$unionWith
$unionWith聚合阶段执行两个集合的合并,将两个集合的管道结果合并到一个结果集传送到下一个阶段。合并后的结果文档的顺序是不确定的。 语法 { $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }要包含集合的所有文档不…...

人工智能三子棋-人机对弈-人人对弈,谁会是最终赢家?
✅作者简介:大家好我是原始豌豆,感谢支持。 🆔本文由 原始豌豆 原创 CSDN首发🐒 如需转载还请通知⚠ 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:C语言项目实践…...
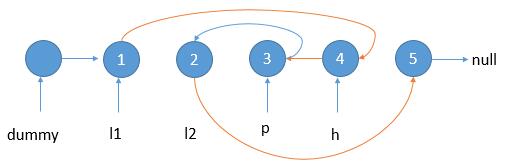
【leetcode热题100】反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

谷歌 DeepMind 联合斯坦福推出了主从式遥操作双臂机器人系统增强版ALOHA 2
谷歌 DeepMind 联合斯坦福推出了 ALOHA 的增强版本 ——ALOHA 2。与一代相比,ALOHA 2 具有更强的性能、人体工程学设计和稳健性,且成本还不到 20 万元人民币。并且,为了加速大规模双手操作的研究,ALOHA 2 相关的所有硬件设计全部开…...

金融行业专题|证券超融合架构转型与场景探索合集(2023版)
更新内容 更新 SmartX 超融合在证券行业的覆盖范围、部署规模与应用场景。新增操作系统信创转型、Nutanix 国产化替代、网络与安全等场景实践。更多超融合金融核心生产业务场景实践,欢迎阅读文末电子书。 在金融行业如火如荼的数字化转型大潮中,传统架…...

【C语言】C的整理记录
前言 该笔记是建立在已经系统学习过C语言的基础上,笔者对C语言的知识和注意事项进行整理记录,便于后期查阅,反复琢磨。C语言是一种面向过程的编程语言。 原想在此阐述一下C语言的作用,然而发觉这些是编程语言所共通的作用&#…...
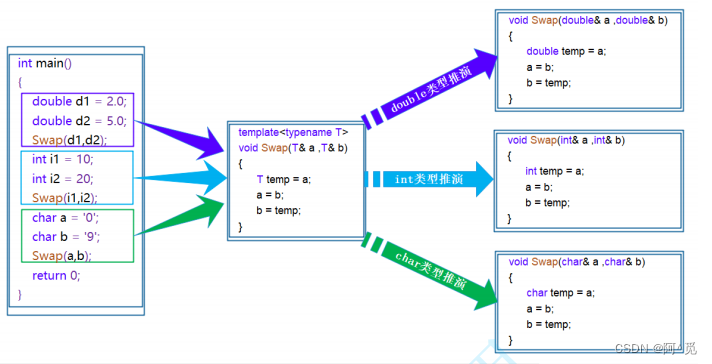
C/C++模板初阶
目录 1. 泛型编程 2. 函数模板 2.1 函数模板概念 2.1 函数模板格式 2.3 函数模板的原理 2.4 函数模板的实例化 2.5 模板参数的匹配原则 3. 类模板 3.1 类模板的定义格式 3.2 类模板的实例化 1. 泛型编程 如何实现一个通用的交换函数呢? void Swap(int&…...
linux系统下vscode portable版本的c++/Cmake环境搭建001
linux系统下vscode portable版本的Cmake环境搭建 vscode portable 安装安装基本工具安装 build-essential安装 CMake final script code安装插件CMake Tools & cmakeC/C Extension Pack Testsettings,jsonCMakeLists.txt调试和运行工具 CG 目的:希望在获得一个新…...

【QT+QGIS跨平台编译】之三十一:【FreeXL+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、FreeXL介绍二、文件下载三、文件分析四、pro文件五、编译实践一、FreeXL介绍 【FreeXL跨平台编译】:Windows环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台编译】:Linux环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台…...

2024年 前端JavaScript入门到精通 第一天
主要讲解JavaScript核心知识,包含最新ES6语法,从基础到API再到高级。让你一边学习一边练习,重点知识及时实践,同时每天安排大量作业,加深记忆,巩固学习成果。 1.1 基本软件与准备工作 1.2 JavaScript 案例 …...

155基于matlab 的形态学权重自适应图像去噪
基于matlab 的形态学权重自适应图像去噪;通过串并联的滤波降噪对比图,说明并联降噪的优越性。输出降噪前后图像和不同方法的降噪情况的信噪比。程序已调通,可直接运行。 155matlab 自适应图像降噪 串并联降噪 (xiaohongshu.com)...
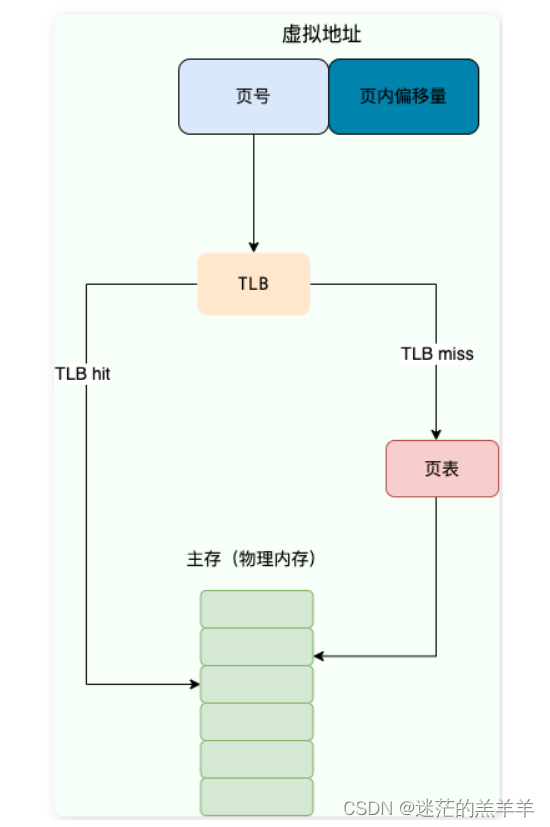
操作系统——内存管理(附带Leetcode算法题LRU)
目录 1.内存管理主要用来干什么? 2.什么是内存碎片? 3.虚拟内存 3.1传统存储管理方式的缺点? 3.2局部性原理 3.3什么是虚拟内存?有什么用? 3.3.1段式分配 3.3.2页式分配 3.3.2.1换页机制 3.3.2.2页面置换算法…...

I/O多路复用简记
IO多路复用(服务器如何处理多个socket的同时数据传输):1、select。2、poll。3、epoll。 select使用bitmap存socket文件描述符,由bitmap槽位的每一位为0或1决定对应序的socket连接是否有数据到来。由单线程(多线程处理每…...

SPECCPU2017操作说明
1、依赖包下载 yum install gcc* gfortran* 2、将软件包放至被测机器 3、增加权限 chmod X install.sh 4、运行安装 ./install.sh 5、运行 引入编译时所需的环境变量和相关库文件 source shrc 进入/spec2017,执行 ./runcpu -c ../config/Example-gcc-linux-ar…...

openresty (nginx)快速开始
文章目录 一、什么是openresty?二、openresty编译安装1. 编译安装命令1.1 编译完成后路径1.2 常用编译选项解释 2. nginx配置文件配置2.1 nginx.conf模板 3. nginx常见配置一个站点配置多个域名nginx配置中location匹配规则 三、OpenResty工作原理OpenResty工作原理…...

相机图像质量研究(11)常见问题总结:光学结构对成像的影响--像差
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...

基于MCP协议的本地代码历史管理工具:无感备份与即时回溯
1. 项目概述:一个为开发者打造的“时光机”如果你是一名开发者,大概率经历过这样的场景:在调试一个复杂功能时,你反复修改了一段代码,运行、测试、再修改……几个小时后,你突然意识到,两个小时前…...

长期使用Taotoken的体验,账单清晰与模型切换便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的体验,账单清晰与模型切换便利性 作为长期将大模型能力集成到项目中的开发者,选择一个稳…...

别再为MATLAB+Amesim联合仿真装环境发愁了!保姆级VS2019+2022a+2021.1安装避坑指南
MATLABAmesim联合仿真环境搭建全攻略:从零避坑到一次成功 当第一次接触MATLAB与Amesim联合仿真时,许多工程师和研究生都会在环境搭建阶段遭遇各种"玄学问题"——明明按照教程操作,却总是卡在某个环节无法继续。本文将分享一套经过…...

Gemini3.1Pro评估ViT平移不变性:4周MVP路线图
利用 Gemini 3.1 Pro 评估视觉 Transformer 的平移不变性:从机制刻画、对照验证到门控降级与4周MVP路线图“平移不变性(Translation Invariance)”是视觉 Transformer(ViT 等)稳健性的核心指标之一:当图像在…...

Visual Studio Code搭建c语言编译环境下载c/c++ Runner插件编译报错问题
安装版本默认是最新插件。下载如果无法编译就换版本。最后换到1.5.5版本就编译成功了。耗时2小时解决无法编译报错。process_begin: CreateProcess(NULL, ./build\Debug/outDebug "", ...) failed. make (e2): 系统找不到指定的文件。...

Claude Code 安装后如何配置 Taotoken 密钥与聚合端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 安装后如何配置 Taotoken 密钥与聚合端点 基础教程类,针对刚安装 Claude Code 但无法直连或担心封号的开发…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南
解放你的游戏时间:三月七小助手——星穹铁道自动化终极指南 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中重复的…...