MongoDB聚合:$unionWith
$unionWith聚合阶段执行两个集合的合并,将两个集合的管道结果合并到一个结果集传送到下一个阶段。合并后的结果文档的顺序是不确定的。
语法
{ $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }
要包含集合的所有文档不进行任何处理,可以使用简化形式:
{ $unionWith: "<collection>" } // 包含指定集合的所有文档
使用
参数字段:
| 字段 | 描述 |
|---|---|
coll | 希望在结果集中包含的集合或视图管道的结果 |
pipeline | 可选,应用于coll的聚合管道[<stage1>, <stage2>, ....],聚合管道不能包含$out和$merge阶段。从v6.0开始,管道可以在第一个阶段包含$search阶段 |
$unionWith操作等价于下面的SQL语句:
SELECT *
FROM Collection1
WHERE ...
UNION ALL
SELECT *
FROM Collection2
WHERE ...
重复的结果
前一阶段的合并结果和$unionWith阶段的合并结果可能包含重复结果。例如,创建一个suppliers 集合和一个warehouses 集合:
db.suppliers.insertMany([{ _id: 1, supplier: "Aardvark and Sons", state: "Texas" },{ _id: 2, supplier: "Bears Run Amok.", state: "Colorado"},{ _id: 3, supplier: "Squid Mark Inc. ", state: "Rhode Island" },
])
db.warehouses.insertMany([{ _id: 1, warehouse: "A", region: "West", state: "California" },{ _id: 2, warehouse: "B", region: "Central", state: "Colorado"},{ _id: 3, warehouse: "C", region: "East", state: "Florida" },
])
下面的聚合合并了聚合suppliers和warehouse的state’字段投影结果。
db.suppliers.aggregate([{ $project: { state: 1, _id: 0 } },{ $unionWith: { coll: "warehouses", pipeline: [ { $project: { state: 1, _id: 0 } } ]} }
])
结果包含重复的文档
{ "state" : "Texas" }
{ "state" : "Colorado" }
{ "state" : "Rhode Island" }
{ "state" : "California" }
{ "state" : "Colorado" }
{ "state" : "Florida" }
要要去除重复,可以加个$group阶段,按照state字段分组:
db.suppliers.aggregate([{ $project: { state: 1, _id: 0 } },{ $unionWith: { coll: "warehouses", pipeline: [ { $project: { state: 1, _id: 0 } } ]} },{ $group: { _id: "$state" } }
])
这样结果就没有重复的文档了:
{ "_id" : "California" }{ "_id" : "Texas" }{ "_id" : "Florida" }{ "_id" : "Colorado" }{ "_id" : "Rhode Island" }
$unionWith 分片集合
如果$unionWith阶段是$lookup管道的一部分,则$unionWith的coll被分片。例如,在下面的聚合操作中,不能对inventory_q1集合进行分片:
db.suppliers.aggregate([{$lookup: {from: "warehouses",let: { order_item: "$item", order_qty: "$ordered" },pipeline: [...{ $unionWith: { coll: "inventory_q1", pipeline: [ ... ] } },...],as: "stockdata"}}
])
限制
- 聚合管道不能在事务中使用
$unionWith - 如果
$unionWith阶段是$lookup管道的一部分,则$unionWith的集合不能被分片 unionWith管道不能包含out阶段unioWith管道不能包含merge阶段
举例
用多年的数据集合创建销售报告
下面示例使用$unionWith阶段来合并数据并返回多个集合的结果,在这些示例中,每个集合都包含一年的销售数据。
填充样本数据:
分别创建sales_2017、sales_2018、sales_2019、sales_2019四个集合并填充数据:
db.sales_2017.insertMany( [{ store: "General Store", item: "Chocolates", quantity: 150 },{ store: "ShopMart", item: "Chocolates", quantity: 50 },{ store: "General Store", item: "Cookies", quantity: 100 },{ store: "ShopMart", item: "Cookies", quantity: 120 },{ store: "General Store", item: "Pie", quantity: 10 },{ store: "ShopMart", item: "Pie", quantity: 5 }
] )
db.sales_2018.insertMany( [{ store: "General Store", item: "Cheese", quantity: 30 },{ store: "ShopMart", item: "Cheese", quantity: 50 },{ store: "General Store", item: "Chocolates", quantity: 125 },{ store: "ShopMart", item: "Chocolates", quantity: 150 },{ store: "General Store", item: "Cookies", quantity: 200 },{ store: "ShopMart", item: "Cookies", quantity: 100 },{ store: "ShopMart", item: "Nuts", quantity: 100 },{ store: "General Store", item: "Pie", quantity: 30 },{ store: "ShopMart", item: "Pie", quantity: 25 }
] )
db.sales_2019.insertMany( [{ store: "General Store", item: "Cheese", quantity: 50 },{ store: "ShopMart", item: "Cheese", quantity: 20 },{ store: "General Store", item: "Chocolates", quantity: 125 },{ store: "ShopMart", item: "Chocolates", quantity: 150 },{ store: "General Store", item: "Cookies", quantity: 200 },{ store: "ShopMart", item: "Cookies", quantity: 100 },{ store: "General Store", item: "Nuts", quantity: 80 },{ store: "ShopMart", item: "Nuts", quantity: 30 },{ store: "General Store", item: "Pie", quantity: 50 },{ store: "ShopMart", item: "Pie", quantity: 75 }
] )
db.sales_2020.insertMany( [{ store: "General Store", item: "Cheese", quantity: 100, },{ store: "ShopMart", item: "Cheese", quantity: 100},{ store: "General Store", item: "Chocolates", quantity: 200 },{ store: "ShopMart", item: "Chocolates", quantity: 300 },{ store: "General Store", item: "Cookies", quantity: 500 },{ store: "ShopMart", item: "Cookies", quantity: 400 },{ store: "General Store", item: "Nuts", quantity: 100 },{ store: "ShopMart", item: "Nuts", quantity: 200 },{ store: "General Store", item: "Pie", quantity: 100 },{ store: "ShopMart", item: "Pie", quantity: 100 }
] )
按照year、store和item的销售额
db.sales_2017.aggregate( [{ $set: { _id: "2017" } },{ $unionWith: { coll: "sales_2018", pipeline: [ { $set: { _id: "2018" } } ] } },{ $unionWith: { coll: "sales_2019", pipeline: [ { $set: { _id: "2019" } } ] } },{ $unionWith: { coll: "sales_2020", pipeline: [ { $set: { _id: "2020" } } ] } },{ $sort: { _id: 1, store: 1, item: 1 } }
] )
$set阶段用于更新_id字段,使其包含年份$unionWith阶段,将四个集合中的所有文档合并在一起,每个文档也使用$set阶段$sort阶段,按照_id(年份)、store和item进行排序
管道输出:
{ "_id" : "2017", "store" : "General Store", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2017", "store" : "General Store", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2017", "store" : "General Store", "item" : "Pie", "quantity" : 10 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 50 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Cookies", "quantity" : 120 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Pie", "quantity" : 5 }
{ "_id" : "2018", "store" : "General Store", "item" : "Cheese", "quantity" : 30 }
{ "_id" : "2018", "store" : "General Store", "item" : "Chocolates", "quantity" : 125 }
{ "_id" : "2018", "store" : "General Store", "item" : "Cookies", "quantity" : 200 }
{ "_id" : "2018", "store" : "General Store", "item" : "Pie", "quantity" : 30 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Cheese", "quantity" : 50 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Nuts", "quantity" : 100 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Pie", "quantity" : 25 }
{ "_id" : "2019", "store" : "General Store", "item" : "Cheese", "quantity" : 50 }
{ "_id" : "2019", "store" : "General Store", "item" : "Chocolates", "quantity" : 125 }
{ "_id" : "2019", "store" : "General Store", "item" : "Cookies", "quantity" : 200 }
{ "_id" : "2019", "store" : "General Store", "item" : "Nuts", "quantity" : 80 }
{ "_id" : "2019", "store" : "General Store", "item" : "Pie", "quantity" : 50 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Cheese", "quantity" : 20 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Nuts", "quantity" : 30 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Pie", "quantity" : 75 }
{ "_id" : "2020", "store" : "General Store", "item" : "Cheese", "quantity" : 100 }
{ "_id" : "2020", "store" : "General Store", "item" : "Chocolates", "quantity" : 200 }
{ "_id" : "2020", "store" : "General Store", "item" : "Cookies", "quantity" : 500 }
{ "_id" : "2020", "store" : "General Store", "item" : "Nuts", "quantity" : 100 }
{ "_id" : "2020", "store" : "General Store", "item" : "Pie", "quantity" : 100 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Cheese", "quantity" : 100 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 300 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Cookies", "quantity" : 400 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Nuts", "quantity" : 200 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Pie", "quantity" : 100 }
根据item汇总销售额
db.sales_2017.aggregate( [{ $unionWith: "sales_2018" },{ $unionWith: "sales_2019" },{ $unionWith: "sales_2020" },{ $group: { _id: "$item", total: { $sum: "$quantity" } } },{ $sort: { total: -1 } }
] )
$unionWith阶段将文档从指定的集合检索到管道中$group阶段按item字段分组,并使用$sum计算每个item的总销售量$sort阶段按合计降序排列文档
结果:
{ "_id" : "Cookies", "total" : 1720 }
{ "_id" : "Chocolates", "total" : 1250 }
{ "_id" : "Nuts", "total" : 510 }
{ "_id" : "Pie", "total" : 395 }
{ "_id" : "Cheese", "total" : 350 }
相关文章:

MongoDB聚合:$unionWith
$unionWith聚合阶段执行两个集合的合并,将两个集合的管道结果合并到一个结果集传送到下一个阶段。合并后的结果文档的顺序是不确定的。 语法 { $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }要包含集合的所有文档不…...

人工智能三子棋-人机对弈-人人对弈,谁会是最终赢家?
✅作者简介:大家好我是原始豌豆,感谢支持。 🆔本文由 原始豌豆 原创 CSDN首发🐒 如需转载还请通知⚠ 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:C语言项目实践…...
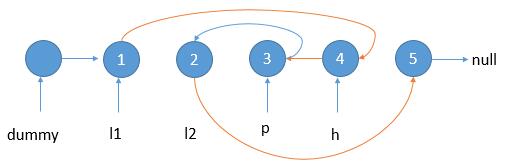
【leetcode热题100】反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

谷歌 DeepMind 联合斯坦福推出了主从式遥操作双臂机器人系统增强版ALOHA 2
谷歌 DeepMind 联合斯坦福推出了 ALOHA 的增强版本 ——ALOHA 2。与一代相比,ALOHA 2 具有更强的性能、人体工程学设计和稳健性,且成本还不到 20 万元人民币。并且,为了加速大规模双手操作的研究,ALOHA 2 相关的所有硬件设计全部开…...

金融行业专题|证券超融合架构转型与场景探索合集(2023版)
更新内容 更新 SmartX 超融合在证券行业的覆盖范围、部署规模与应用场景。新增操作系统信创转型、Nutanix 国产化替代、网络与安全等场景实践。更多超融合金融核心生产业务场景实践,欢迎阅读文末电子书。 在金融行业如火如荼的数字化转型大潮中,传统架…...

【C语言】C的整理记录
前言 该笔记是建立在已经系统学习过C语言的基础上,笔者对C语言的知识和注意事项进行整理记录,便于后期查阅,反复琢磨。C语言是一种面向过程的编程语言。 原想在此阐述一下C语言的作用,然而发觉这些是编程语言所共通的作用&#…...
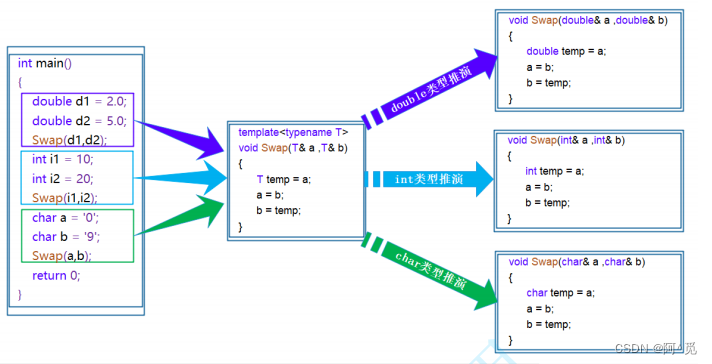
C/C++模板初阶
目录 1. 泛型编程 2. 函数模板 2.1 函数模板概念 2.1 函数模板格式 2.3 函数模板的原理 2.4 函数模板的实例化 2.5 模板参数的匹配原则 3. 类模板 3.1 类模板的定义格式 3.2 类模板的实例化 1. 泛型编程 如何实现一个通用的交换函数呢? void Swap(int&…...
linux系统下vscode portable版本的c++/Cmake环境搭建001
linux系统下vscode portable版本的Cmake环境搭建 vscode portable 安装安装基本工具安装 build-essential安装 CMake final script code安装插件CMake Tools & cmakeC/C Extension Pack Testsettings,jsonCMakeLists.txt调试和运行工具 CG 目的:希望在获得一个新…...

【QT+QGIS跨平台编译】之三十一:【FreeXL+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、FreeXL介绍二、文件下载三、文件分析四、pro文件五、编译实践一、FreeXL介绍 【FreeXL跨平台编译】:Windows环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台编译】:Linux环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台…...

2024年 前端JavaScript入门到精通 第一天
主要讲解JavaScript核心知识,包含最新ES6语法,从基础到API再到高级。让你一边学习一边练习,重点知识及时实践,同时每天安排大量作业,加深记忆,巩固学习成果。 1.1 基本软件与准备工作 1.2 JavaScript 案例 …...

155基于matlab 的形态学权重自适应图像去噪
基于matlab 的形态学权重自适应图像去噪;通过串并联的滤波降噪对比图,说明并联降噪的优越性。输出降噪前后图像和不同方法的降噪情况的信噪比。程序已调通,可直接运行。 155matlab 自适应图像降噪 串并联降噪 (xiaohongshu.com)...
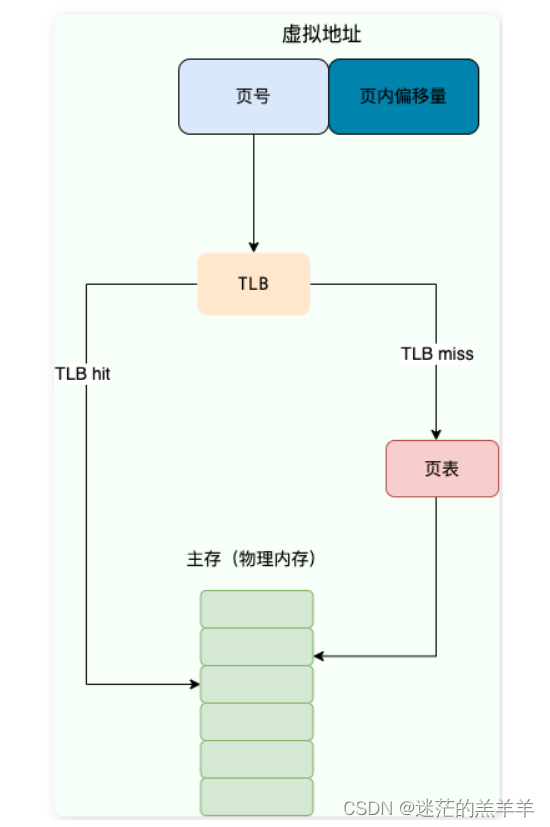
操作系统——内存管理(附带Leetcode算法题LRU)
目录 1.内存管理主要用来干什么? 2.什么是内存碎片? 3.虚拟内存 3.1传统存储管理方式的缺点? 3.2局部性原理 3.3什么是虚拟内存?有什么用? 3.3.1段式分配 3.3.2页式分配 3.3.2.1换页机制 3.3.2.2页面置换算法…...

I/O多路复用简记
IO多路复用(服务器如何处理多个socket的同时数据传输):1、select。2、poll。3、epoll。 select使用bitmap存socket文件描述符,由bitmap槽位的每一位为0或1决定对应序的socket连接是否有数据到来。由单线程(多线程处理每…...

SPECCPU2017操作说明
1、依赖包下载 yum install gcc* gfortran* 2、将软件包放至被测机器 3、增加权限 chmod X install.sh 4、运行安装 ./install.sh 5、运行 引入编译时所需的环境变量和相关库文件 source shrc 进入/spec2017,执行 ./runcpu -c ../config/Example-gcc-linux-ar…...

openresty (nginx)快速开始
文章目录 一、什么是openresty?二、openresty编译安装1. 编译安装命令1.1 编译完成后路径1.2 常用编译选项解释 2. nginx配置文件配置2.1 nginx.conf模板 3. nginx常见配置一个站点配置多个域名nginx配置中location匹配规则 三、OpenResty工作原理OpenResty工作原理…...

相机图像质量研究(11)常见问题总结:光学结构对成像的影响--像差
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...
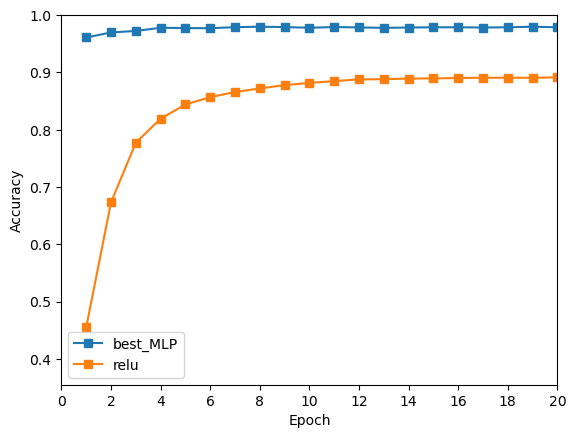
【深度学习】基于多层感知机的手写数字识别
案例2:构建自己的多层感知机: MNIST手写数字识别 相关知识点: numpy科学计算包,如向量化操作,广播机制等 1 任务目标 1.1 数据集简介 MNIST手写数字识别数据集是图像分类领域最常用的数据集之一,它包含60,000张训练图片&am…...
,构造一个n*m的矩阵a,使得每个4*4的子矩阵,左上角2*2的子矩阵的异或和等于右下角的,左下角的异或和等于右上角的)
给定n,m(200),构造一个n*m的矩阵a,使得每个4*4的子矩阵,左上角2*2的子矩阵的异或和等于右下角的,左下角的异或和等于右上角的
题目 #include <bits/stdc.h> using namespace std; #define int long long #define pb push_back #define fi first #define se second #define lson p << 1 #define rson p << 1 | 1 const int maxn 1e6 5, inf 1e18 5, maxm 4e4 5, mod 998244353…...

【开源】基于JAVA+Vue+SpringBoot的假日旅社管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 系统介绍2.2 QA 问答 三、系统展示四、核心代码4.1 查询民宿4.2 新增民宿评论4.3 查询民宿新闻4.4 新建民宿预订单4.5 查询我的民宿预订单 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的假日旅社…...

Visual C++运行库终极指南:如何3分钟解决Windows软件启动失败问题
Visual C运行库终极指南:如何3分钟解决Windows软件启动失败问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的场景…...

NotebookLM协作效能临界点预警:当团队超8人时,必须立即启用的3项动态共享策略
更多请点击: https://intelliparadigm.com 第一章:NotebookLM协作效能临界点的本质洞察 NotebookLM 的协作效能并非随用户数量线性增长,而是在特定交互密度与知识对齐度交汇时触发跃迁式提升——这一拐点即为“协作效能临界点”。其本质并非…...
)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点) 作为一名刚接触粒子探测器仿真的研究生,我花了整整两周时间才成功将SolidWorks设计的模型导入Geant4进行模拟。这个过程远比想象中复杂&#x…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

如何3步获取百度网盘真实下载地址实现满速下载
如何3步获取百度网盘真实下载地址实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的非会员下载速度困扰?当下载重要的工作文件、学…...

MySQL 索引底层 B+ 树原理
聊 MySQL 索引,不讲 B 树,那就是在耍流氓。 大家好,我是乱码字符。今天咱们深入聊聊 MySQL 索引的底层数据结构——B 树。这篇文章能让你彻底搞明白,为什么有时候明明加了索引,查询却还是慢成狗。 先说说为什么要用树结…...

Arm Iris调试接口:架构设计与工程实践详解
1. Iris调试与追踪接口深度解析调试与追踪技术是嵌入式系统开发的核心支柱,而Arm的Iris接口代表了这一领域的最新进展。作为一名长期从事嵌入式调试工具开发的工程师,我将带您深入剖析这套接口的设计哲学与实战应用。1.1 接口架构设计理念Iris的架构设计…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...