【Spring学习】Spring Data Redis:RedisTemplate、Repository、Cache注解
1,spring-data-redis官网
1)特点
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring独享的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
2,RedisTemplate
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。
1)常用API
| api | 说明 |
|---|---|
| redisTemplate.opsForValue(); | 操作字符串 |
| redisTemplate.opsForHash(); | 操作hash |
| redisTemplate.opsForList(); | 操作list |
| redisTemplate.opsForSet(); | 操作set |
| redisTemplate.opsForZSet(); | 操作有序set |
| redisTemplate.expire(key, 60 * 10000 * 30, TimeUnit.MILLISECONDS); | 设置过期时间 |
1>API:String
redisTemplate.opsForValue().set("name","tom")
| 说明 | api | 备注 |
|---|---|---|
| 添加单值 | .set(key,value) | |
| 获取单值 | .get(key) | |
| 添加单值并返回这个值是否已经存在 | .setIfAbsent(key, value) | |
| 添加单值并返回旧值 | .getAndSet(key, value) | |
| 批量添加 | Map<String,String> maps; .multiSet(maps) | |
| 批量获取 | List<String> keys; .multiGet(keys) | |
| 数值型+1 | .increment(key,1) | |
| 设置过期时间 | set(key, value, timeout, TimeUnit.SECONDS) | 过期返回null |
| 字符串追加 | .append(key,"Hello"); |
2>API:List数据
template.opsForList().range("list",0,-1)
| 说明 | api | 备注 |
|---|---|---|
| 单个插入 | Long leftPush(key, value); | 返回操作后的列表的长度 |
| 批量插入 | Long leftPushAll(K key, V… values); | 返回操作后的列表的长度; values可以是 String[]、List<Object> |
| 查看 | .range(key,0,-1) | 从左往右:0,1,2; 从右往左:-1,-2,-3; 可做分页 |
| 弹出最左边的元素 | .leftPop("list") | 弹出之后该值在列表中将不复存在 |
| 修改 | set(key, index, value) | |
| key存在则插入 | Long rightPushIfPresent(K key, V value); | 返回操作后的列表的长度 |
| 求subList | .trim(key,1,-1) | |
| 移除元素 | Long remove(key, long count, Object value); | count> 0:删除从左到右共count个等于value的元素。 count <0:删除等于从右到左共count个等于value的元素。 count = 0:删除等于value的所有元素。 |
| 求长度 | .size(key) |
3>API:Hash操作
一个key1对应一个Map,map中每个value中@class后面对应的值为类信息。

template.opsForHash().put("redisHash","name","tom");
| 说明 | api | 备注 |
|---|---|---|
| 单插入 | .put(redisKey,hashKey, value) | |
| 批量插入 | Map<String,Object> map .putAll(key, map) | |
| 查单数据 | .get(redisKey,hashKey) | |
| 查所有数据 | .entries(redisHash) | |
| 查key是否存在 | Boolean hasKey(redisKey, Object hashKey); | |
| 批量获取Hash值 | List multiGet(redisKey, List<Object> kes); | |
| 获取key集合 | Set keys(redisKey) | |
| 批量删除 | Long delete(redisKey, Object… hashKeys) | |
| 数值型value + 5 | increment(redisKey, hashKey, 5) | 返回操作后的value值 |
| hashkey不存在时设置value | Boolean putIfAbsent(redisKey,hashKey, value) | 存在返回true,不存在返回true |
遍历:
Cursor<Map.Entry<Object, Object>> curosr = template.opsForHash().scan("redisHash", ScanOptions.ScanOptions.NONE);while(curosr.hasNext()){Map.Entry<Object, Object> entry = curosr.next();System.out.println(entry.getKey()+":"+entry.getValue());}
4>API:Set数据
template.opsForSet().add(k,v)
| 说明 | api | 备注 |
|---|---|---|
| 添加 | Long add(key, V… values); | values可以是:String[] |
| 查看所有 | .members(key) | |
| 查询长度 | .size(key) | |
| 查询元素是否存在 | Boolean isMember(key, Object o); | |
| 批量删除 | Long remove(key, Object… values); | values可以是:String[] |
| 随机移除 | V pop(K key); | |
| 将元素value 从 sourcekey所在集合移动到 destKey所在集合 | Boolean move(sourcekey, V value, destKey) | 移动后sourcekey集合再没有value元素,destKey集合去重。 |
| 求两个集合的交集 | Set intersect(K key, K otherKey); | |
| 求多个无序集合的交集 | Set intersect(K key, Collection otherKeys); | |
| 求多个无序集合的并集 | Set union(K key, Collection otherKeys); |
遍历:
Cursor<Object> curosr = template.opsForSet().scan("setTest", ScanOptions.NONE);while(curosr.hasNext()){System.out.println(curosr.next());}
5>API:ZSet集合
有序的Set集合,排序依据是Score。
template.opsForZSet().add("zset1","zset-1",1.0)
| 说明 | api | 备注 |
|---|---|---|
| 添加单个元素 | Boolean add(k, v, double score) | 返回元素是否已存在 |
| 批量添加元素 | Long add(k, Set<TypedTuple> tuples) | 举例:见下文1. |
| 批量删除 | Long remove(K key, Object… values); | |
| 排序按分数值asc,返回成员o的排名 | Long rank(key, Object o); | 排名从0开始 |
| 排序按分数值desc,返回成员o的排名 | Long reverseRank(key, Object o); | 排名从0开始 |
| 按区间查询,按分数值asc | Set range(key, 0, -1); | |
| 增加元素的score值,并返回增加后的值 | Double incrementScore(K key, V value, double delta); |
- 批量添加元素
ZSetOperations.TypedTuple<Object> objectTypedTuple1 = new DefaultTypedTuple<Object>("zset-5",9.6);ZSetOperations.TypedTuple<Object> objectTypedTuple2 = new DefaultTypedTuple<Object>("zset-6",9.9);Set<ZSetOperations.TypedTuple<Object>> tuples = new HashSet<ZSetOperations.TypedTuple<Object>>();tuples.add(objectTypedTuple1);tuples.add(objectTypedTuple2);System.out.println(template.opsForZSet().add("zset1",tuples));System.out.println(template.opsForZSet().range("zset1",0,-1));
- 遍历
Cursor<ZSetOperations.TypedTuple<Object>> cursor = template.opsForZSet().scan("zzset1", ScanOptions.NONE);while (cursor.hasNext()){ZSetOperations.TypedTuple<Object> item = cursor.next();System.out.println(item.getValue() + ":" + item.getScore());}
2)使用
1>依赖
<!-- Redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
<!-- 连接池依赖--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>
2>配置文件
spring:redis:host: 127.0.0.1 # Redis服务器地址port: 6379 # Redis服务器连接端口 timeout:0 # 连接超时时间(毫秒)
# database: 0 # Redis数据库索引(默认为0)
# password: # Redis服务器连接密码(默认为空)lettuce: # 使用的是lettuce连接池pool:max-active: 8 # 连接池最大连接数(使用负值表示没有限制)max-idle: 8 # 连接池中的最大空闲连接min-idle: 0 # 连接池中的最小空闲连接max-wait: 100 # 连接池最大阻塞等待时间(使用负值表示没有限制)
1>序列化配置
RedisTemplate默认采用JDK的序列化工具,序列化为字节形式,在redis中可读性很差。
修改默认的序列化方式为jackson:
@Configuration
public class RedisConfig {@Bean //RedisConnectionFactory不需要我们创建Spring会帮助我们创建public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 1.创建RedisTemplate对象RedisTemplate<String,Object> template = new RedisTemplate<>();
// 2.设置连接工厂template.setConnectionFactory(connectionFactory);
// 3.创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 4.设置Key的序列化template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());
// 5.设置Value的序列化 jsonRedisSerializer使我们第三步new出来的template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);
// 6.返回return template;}
}
但是json序列号可能导致一些其他的问题:JSON序列化器会将类的class类型写入到JSON结果中并存入Redis,会带来额外的内存开销。
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key哈value,当要存储Java对象时,手动完成对象的序列化和反序列化。
4>java实现
public class RedisUtil {@Autowiredprivate RedisTemplate redisTemplate;/*** 批量删除对应的value* * @param keys*/public void remove(final String... keys) {for (String key : keys) {remove(key);}}/*** 批量删除key* * @param pattern*/public void removePattern(final String pattern) {Set<Serializable> keys = redisTemplate.keys(pattern);if (keys.size() > 0)redisTemplate.delete(keys);}public void remove(final String key) {if (exists(key)) {redisTemplate.delete(key);}}public boolean exists(final String key) {return redisTemplate.hasKey(key);}public String get(final String key) {Object result = null;ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();result = operations.get(key);if (result == null) {return null;}return result.toString();}public boolean set(final String key, Object value) {boolean result = false;try {ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();operations.set(key, value);result = true;} catch (Exception e) {e.printStackTrace();}return result;}public boolean set(final String key, Object value, Long expireTime) {boolean result = false;try {ValueOperations<Serializable, Object> operations = redisTemplate.opsForValue();operations.set(key, value);redisTemplate.expire(key, expireTime, TimeUnit.SECONDS);result = true;} catch (Exception e) {e.printStackTrace();}return result;}public boolean hmset(String key, Map<String, String> value) {boolean result = false;try {redisTemplate.opsForHash().putAll(key, value);result = true;} catch (Exception e) {e.printStackTrace();}return result;}public Map<String, String> hmget(String key) {Map<String, String> result = null;try {result = redisTemplate.opsForHash().entries(key);} catch (Exception e) {e.printStackTrace();}return result;}
}
3)StringRedisTemplate
key和value的序列化方式默认就是String方式,省去了我们自定义RedisTemplate的过程。
@Autowiredprivate StringRedisTemplate stringRedisTemplate;
// JSON工具private static final ObjectMapper mapper = new ObjectMapper();@Testvoid testStringTemplate() throws JsonProcessingException {
// 准备对象User user = new User("abc", 18);
// 手动序列化String json = mapper.writeValueAsString(user);
// 写入一条数据到RedisstringRedisTemplate.opsForValue().set("user:200",json);// 读取数据String s = stringRedisTemplate.opsForValue().get("user:200");
// 反序列化User user1 = mapper.readValue(s,User.class);System.out.println(user1);}
3,Redis数据序列化
4,Repository操作
类似jpa操作,只要Redis服务器版本在2.8.0以上,不用事务,就可以使用Repository做各种操作。
注意:Repository和jpa的Repository是同一个,意味着jpa支持的api在redis操作中通用。
1)注解
| 注解 | 说明 | 属性 | 对比jpa |
|---|---|---|---|
| @RedisHash | 用来定义实体。 | value:定义了不同类型对象存储时使用的前缀,也叫做键空间,默认是全限定类名;timeToLive定义缓存的秒数; | 类似@Entity |
| @Id | 定义对象的标识符 | 类似@Id | |
| @Indexed | 定义二级索引,加在属性上可以将该属性定义为查询用的索引 | ||
| @Reference | 缓存对象引用,一般引用的对象也会被展开存储在当前对象中,添加了该注解后会直接存储该对象在Redis中的引用 |
2)使用
- 不需要添加依赖。
spring-boot自动添加了@EnableRedisRepositories注解。 - 实体
@RedisHash(value="menu",timeToLive=60)
public class RedisMenuItem implements Serializable{@Idprivste Long id;@Indexedprivate String name;private Size size;private Money price;
}
- 定义Repository接口
public interface RedisMenuRepository extends CrudRepository<RedisMenuItem, Long>{List<RedisMenuItem> findByName(String name);
}
- 查询
List<MenuItem> itemList = menuRepository.findAll();menuRepository.save(menuItem);
5,Spring Cache
Spring 3.1 引入了对 Cache 的支持,使用使用 JCache(JSR-107)注解简化开发。
注意:可支持幂等操作的接口才可以使用缓存注解,因为缓存和参数无关,即:不管什么参数,返回值一样。
1)org.springframework.cache.Cache接口
- 包含了缓存的各种操作集合;
- 提供了各种xxxCache 的实现,比如:RedisCache
2)org.springframework.cache.CacheManager接口
- 定义了创建、配置、获取、管理和控制多个唯一命名的 Cache。这些 Cache 存在于 CacheManager 的上下文中。
- 提供了各种xxxCacheManager 的实现,比如RedisCacheManager。
3)相关注解
1>@EnableCaching
- 开启基于注解的缓存;
- 作用在缓存配置类上或者SpringBoot 的主启动类上;
2>@Cacheable
缓存注解。
使用注意:
- 基于AOP去实现的,所以必须通过IOC对象去调用。
- 要缓存的 Java 对象必须实现 Serializable 接口。
@Cacheable(cacheNames = "usersBySpEL",//key通过变量拼接key="#root.methodName + '[' + #id + ']'",//id大于1才缓存。可缺省condition = "#id > 1",//当id大于10时,条件为true,方法返回值不会被缓存。可缺省unless = "#id > 10")public User getUserBySpEL(Integer id) {}@Cacheable(value = {"menuById"}, key = "'id-' + #menu.id")public Menu findById(Menu menu) {return menu;}
| 常用属性 | 说明 | 备注 | 代码示例 |
|---|---|---|---|
| cacheNames/value | 缓存名称,用来划分不同的缓存区,避免相同key值互相影响。 | 可以是单值、数组; 在redis中相当于key的一级目录,支持 :拼接多层目录 | cacheNames = "users"cacheNames = {"users","account"} |
| key | 缓存数据时使用的 key,默认是方法参数。 可以使用 spEL 表达式来编写 | ||
| keyGenerator | key 的生成器,统一管理key。 | key 和 keyGenerator 二选一使用,同时使用会导致异常。 | keyGenerator = "myKeyGenerator" |
| cacheManager | 指定缓存管理器,从哪个缓存管理器里面获取缓存 | ||
| condition | 可以用来指定符合条件的情况下才缓存 | ||
| unless | 否定缓存。 | 当 unless 指定的条件为 true ,方法的返回值就不会被缓存 | 通过 #result 获取方法结果进行判断。 |
| sync | 是否使用异步模式。 | 默认是方法执行完,以同步的方式将方法返回的结果存在缓存中 |
spEL常用元数据:
| 说明 | 示例 | 备注 |
|---|---|---|
| #root.methodName | 当前被调用的方法名 | |
| #root.method.name | 当前被调用的方法 | |
| #root.target | 当前被调用的目标对象 | |
| #root.targetClass | 当前被调用的目标对象类 | |
| #root.args[0] | 当前被调用的方法的参数列表 | |
| #root.cacheds[0].name | 当前方法调用使用的缓存区列表 | |
| #参数名 或 #p0 或 #a0 | 方法的参数名; 0代表参数的索引 | |
| #result | 方法执行后的返回值 | 如果没有执行则没有内容 |
3>@CachePut
主要针对配置,能够根据方法的请求参数对其结果进行缓存。
- 区别于 @Cacheable,它每次都会触发真实方法的调用,可以保证缓存的一致性。
- 属性与 @Cacheable 类同。
4>@CacheEvict
根据一定的条件对缓存进行清空。
- 标记在类上时表示其中所有方法的执行都会触发缓存的清除操作;
| 常用属性 | 说明 | 备注 | 代码示例 |
|---|---|---|---|
| value | |||
| key | |||
| condition | |||
| allEntries | 为true时,清除value属性值中的所有缓存;默认为false,可以指定清除value属性值下具体某个key的缓存 | ||
| beforeInvocation | 1. 默认是false,即在方法执行成功后触发删除缓存的操作; 2.如果方法抛出异常未能成功返回,不会触发删除缓存的操作 3.当改为true时,方法执行之前会清除指定的缓存,这样不论方法执行成功还是失败都会清除缓存 |
4)缓存实现
上文中基于注解的缓存接口,有一层CacheMananger抽象,其中用ConcurrentHashMap维护了多个Cache,通过cacheNames指定了哪个Cache。
相关文章:
【Spring学习】Spring Data Redis:RedisTemplate、Repository、Cache注解
1,spring-data-redis官网 1)特点 提供了对不同Redis客户端的整合(Lettuce和Jedis)提供了RedisTemplate统一API来操作Redis支持Redis的发布订阅模型支持Redis哨兵和Redis集群支持基于Lettuce的响应式编程支持基于JDK、JSON、字符…...

C语言:内存函数
创作不易,友友们给个三连吧!! C语言标准库中有这样一些内存函数,让我们一起学习吧!! 一、memcpy函数的使用和模拟实现 void * memcpy ( void * destination, const void * source, size_t num ); 1.1 使…...
Go+:一种简单而强大的编程语言
Go是一种简单而强大的编程语言,它是在Go语言之上构建的,旨在提供更加强大、灵活和易于使用的编程体验。Go与Go语言共享大部分语法和语义,因此Go开发人员可以很快上手Go,同时也可以使用Go来编写更加简洁和高效的代码。在本文中&…...

【开源】SpringBoot框架开发数字化社区网格管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、开发背景四、系统展示五、核心源码5.1 查询企事业单位5.2 查询流动人口5.3 查询精准扶贫5.4 查询案件5.5 查询人口 六、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的数字化社区网格管理系统…...

Lua可变参数函数
基础规则 lua传入参数给一个function时采用的是“多余部分被忽略,缺少部分有nil补足”的形式: function f(a, b)return a or b endCALL PARAMETERS f(3) a3, bnil f(3, 4) a3, b4 f(3, 4, 5) a3, b4 (5 is discarded) unpack/pack…...
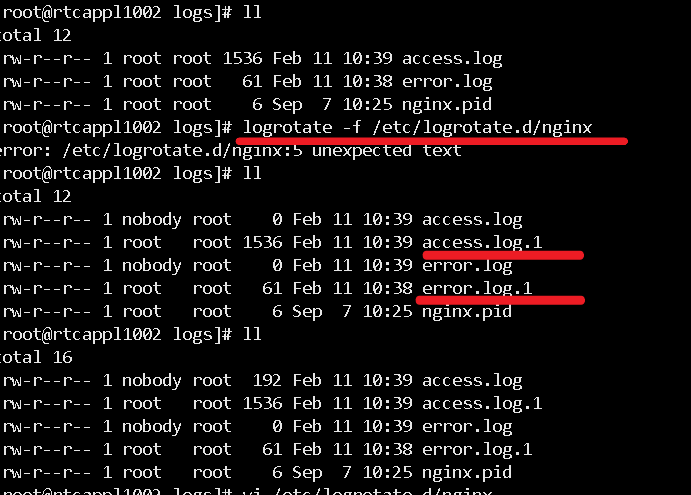
Nginx实战:3-日志按天分割
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、方式1:定时任务执行分割脚本 1.分割日志脚本 2.添加定时任务 二、方式2:logrotate配置分割 1.logrotate简单介绍 2.新增切割ngi…...

springmvc中的数据提交方式
一、单个数据提交数据 jsp代码: <h2>1单个数据提交</h2> <form action"${pageContext.request.contextPath}/one.action">name<input name"myname"/><br>age<input name"age"><input type&…...

unity2017 遇到visual studio 2017(社区版) 30日试用期到了
安装unity2017 遇到visual studio 2017 30日试用期到了,网上百度搜了好多方法都没有成功。 最后用了这个方法: 1)启动vs2017,在弹出要登录的窗口之前,迅速的点击工具-》选项-》账户,勾选在添加账户或对账户重新进行身…...
Netty应用(六) 之 异步 Channel
目录 12.Netty异步的相关概念 12.1 异步编程的概念 12.2 方式1:主线程阻塞,等待异步线程完成调用,然后主线程发起请求IO 12.3 方式2:主线程注册异步线程,异步线程去回调发起请求IO 12.4 细节注释 12.5 异步的好处…...
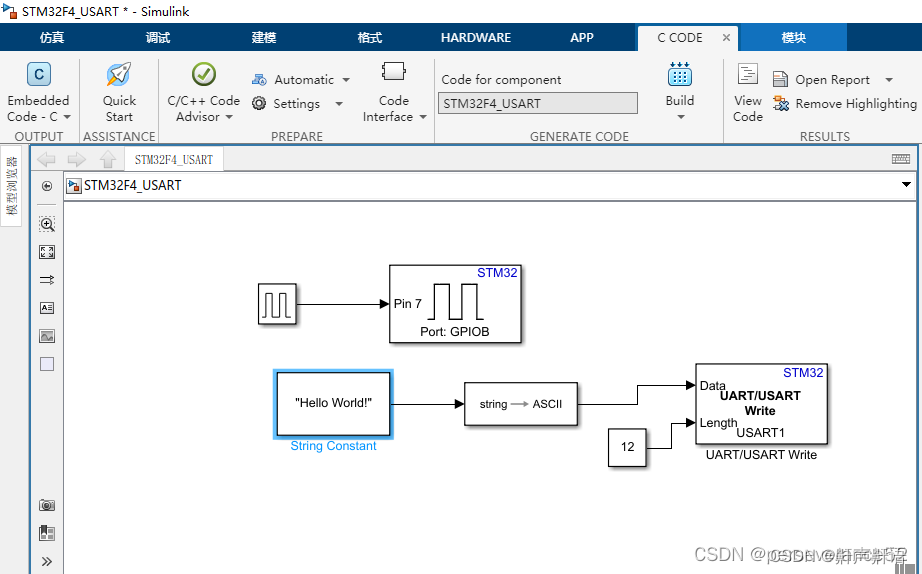
STM32CubeMx+MATLAB Simulink串口输出实验,UART/USART串口测试实验
STM32CubeMxMATLAB Simulink串口输出实验...
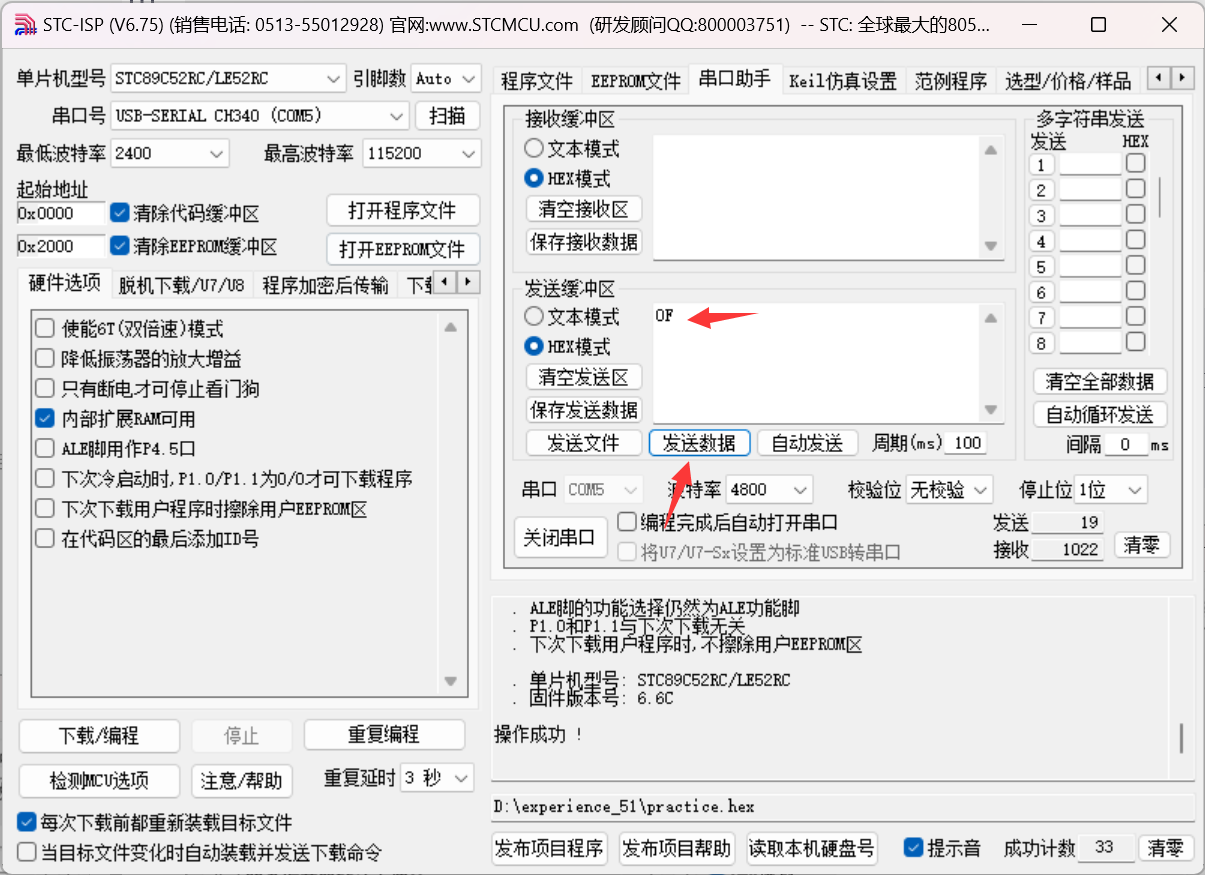
【51单片机】串口通信实验(包括波特率如何计算)
目录 串口通信实验通信的基本概念串行通信与并行通信异步通信与同步通信单工、 半双工与全双工通信通信速率 51单片机串口介绍串口介绍串口通信简介串口相关寄存器串口工作方式方式0方式1方式 2 和方式 3 串口的使用方法(计算波特率) 硬件设计软件设计1、…...
Kafka零拷贝技术与传统数据复制次数比较
读Kafka技术书遇到困惑: "对比传统的数据复制和“零拷贝技术”这两种方案。假设有10个消费者,传统复制方式的数据复制次数是41040次,而“零拷贝技术”只需110 11次(一次表示从磁盘复制到页面缓存,另外10次表示10个消费者各自…...

npm ERR! network This is a problem related to network connectivity.
遇到 ETIMEDOUT 错误时,这表明npm尝试连接到npm仓库时超时了,这通常是由网络连接问题引起的。这可能是因为网络不稳定、连接速度慢、或者你的网络配置阻止了对npm仓库的访问。以下是一些解决这个问题的步骤: 1. 检查网络连接 首先ÿ…...

【SQL高频基础题】619.只出现一次的最大数字
题目: MyNumbers 表: ------------------- | Column Name | Type | ------------------- | num | int | ------------------- 该表可能包含重复项(换句话说,在SQL中,该表没有主键)。 这张表的每…...
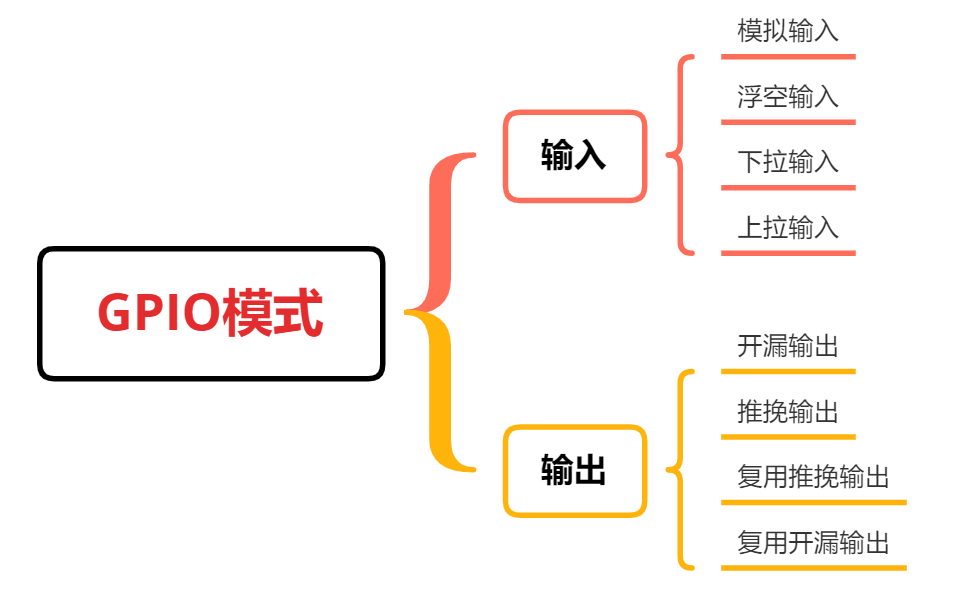
STM32F1 - GPIO外设
GPIO 1> 硬件框图2> 工作模式 1> 硬件框图 2> 工作模式 C语言描述 /** * brief Configuration Mode enumeration */typedef enum { GPIO_Mode_AIN 0x0, // Analog Input 模拟输入 GPIO_Mode_IN_FLOATING 0x04, // input floating 浮空输入GPIO_Mode_I…...

新增同步管理、操作日志模块,支持公共链接分享,DataEase开源数据可视化分析平台v2.3.0发布
2024年2月5日,DataEase开源数据可视化分析平台正式发布v2.3.0版本。 这一版本的功能升级包括:新增“同步管理”功能模块,用户可通过此模块,将传统数据库中的数据定时同步到Apache Doris中,让数据分析更快速࿱…...

跟着pink老师前端入门教程-day19
一、移动WEB开发之流式布局 1、 移动端基础 1.1 浏览器现状 PC端常见浏览器:360浏览器、谷歌浏览器、火狐浏览器、QQ浏览器、百度浏览器、搜狗浏览器、IE浏览器。 移动端常见浏览器:UC浏览器,QQ浏览器,欧朋浏览器࿰…...

ChatGPT学习第一周
📖 学习目标 掌握ChatGPT基础知识 理解ChatGPT的基本功能和工作原理。认识到ChatGPT在日常生活和业务中的潜在应用。 了解AI和机器学习的基本概念 获取人工智能(AI)和机器学习(ML)的初步了解。理解这些技术是如何支撑…...
爬爬爬——今天是浏览器窗口切换和给所选人打钩(自动化)
学习爬虫路还很长,第一阶段花了好多天了,还在底层,虽然不是我专业要学习的语言,和必备的知识,但是我感觉还挺有意思的。加油,这两天把建模和ai也不学了,唉过年了懒了! 加油坚持就是…...
Netty应用(五) 之 Netty引入 EventLoop
目录 第三章 Netty 1.什么是Netty? 2.为什么需要使用Netty? 3.Netty的发展历程 4.谁在使用Netty? 5.为什么上述这些分布式产品都使用Netty? 6.第一个Netty应用 7.如何理解Netty是NIO的封装 8.logback日志使用的加强 9.Ev…...
)
告别串口打印!在Mac上用JLink RTT实现STM32高效调试日志(附完整代码)
在Mac上使用JLink RTT实现STM32高效调试日志的完整指南 对于嵌入式开发者而言,调试信息的输出一直是开发过程中的关键环节。传统串口打印虽然简单易用,但在实际项目中常常面临接线复杂、占用宝贵硬件资源、传输速度受限等问题。特别是在Mac平台上&#…...
)
Jetson Nano到手后别急着烧系统,先做好这5步准备(含SD卡选购与电源避坑)
Jetson Nano开箱必做的5项硬件准备:从SD卡到电源的完整避坑指南 当你第一次拿到Jetson Nano开发板时,那种迫不及待想立刻通电体验的冲动完全可以理解。但作为一个经历过多次"翻车"的老玩家,我必须提醒你:直接烧录系统很…...

ThreeFingerDragOnWindows终极指南:在Windows上免费实现macOS风格三指拖拽
ThreeFingerDragOnWindows终极指南:在Windows上免费实现macOS风格三指拖拽 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th…...

如何通过智能LaTeX模板自动化论文排版,让学术写作回归本质
如何通过智能LaTeX模板自动化论文排版,让学术写作回归本质 【免费下载链接】BIThesis 📖 北京理工大学非官方 LaTeX 模板集合,包含本科、研究生毕业设计模板及更多。🎉 (更多文档请访问 wiki 和 release 中的手册&…...

如何高效管理Zotero插件:一站式插件市场完整指南
如何高效管理Zotero插件:一站式插件市场完整指南 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 还在为…...

Thermal Clad金属基板设计与成本优化实战指南
1. 电路设计基础与Thermal Clad特性解析在电子工程领域,电路板设计直接决定了最终产品的性能、可靠性和成本。作为一名有十年硬件设计经验的工程师,我深刻体会到优秀的设计需要在电气性能、热管理和机械强度之间取得平衡。Thermal Clad(热覆金…...

zcc:简化C语言编译流程的智能封装工具
1. 项目概述:一个为C语言开发者量身定制的编译器如果你是一名C语言开发者,尤其是在嵌入式、操作系统或对性能有极致要求的领域深耕过,那么你一定对GCC和Clang这两大编译器巨头又爱又恨。爱的是它们功能强大、生态成熟;恨的是它们的…...

工业传动避坑:3 个皮带张力调节技巧,杜绝早期失效
工业传动避坑:3 个皮带张力调节技巧,杜绝早期失效在工业传动系统运维中,盖茨同步带、工业皮带的早期失效是高频痛点——不少工程师频繁更换皮带,却始终无法解决根本问题,反而增加运维成本。事实上,90%以上的…...

实战指南 | Vivado自定义IP核在IP Catalog中“隐身”与“灰显”的排查与修复
1. 自定义IP核"隐身"与"灰显"问题全景解析 第一次在Vivado中封装自己的IP核时,那种成就感简直无法形容。但当兴冲冲地想在另一个工程中调用这个"宝贝"时,却发现它在IP Catalog中要么完全消失不见,要么像个害羞…...

多物流机器人任务调度与路径规划【附程序】
✨ 长期致力于物流机器人、任务调度、路径规划、沙猫群算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)栅格-拓扑双层地图建模与任务分配…...