CIFAR-10数据集详析:使用卷积神经网络训练图像分类模型
1.数据集介绍
CIFAR-10 数据集由 10 个类的 60000 张 32x32 彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像。
数据集分为5个训练批次和1个测试批次,每个批次有10000张图像。测试批次正好包含从每个类中随机选择的 1000 张图像。训练批次以随机顺序包含剩余的图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在它们之间,训练批次正好包含来自每个类的 5000 张图像。
总结:
Size(大小): 32×32 RGB图像 ,数据集本身是 BGR 通道
Num(数量): 训练集 50000 和 测试集 10000,一共60000张图片
Classes(十种类别): plane(飞机), car(汽车),bird(鸟),cat(猫),deer(鹿),dog(狗),frog(蛙类),horse(马),ship(船),truck(卡车)

下载链接
来自博主(Dream是个帅哥)的分享:
链接: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ 提取码: 0213
数据集文件夹
CIFAR-100数据集(拓展)
这个数据集与CIFAR-10类似,只不过它有100个类,每个类包含600个图像。每个类有500个训练图像和100个测试图像。CIFAR-100中的100个子类被分为20个大类。每个图像都有一个“fine”标签(它所属的子类)和一个“coarse”标签(它所属的大类)。
CIFAR-10数据集与MNIST数据集对比
- 维度不同:CIFAR-10数据集有4个维度,MNIST数据集有3个维度(CIRAR-10的四维: 一次的样本数量, 图片高, 图片宽, 图通道数 -> N H W C;MNIST的三维: 一次的样本数量, 图片高, 图片宽 -> N H W)
- 图像类型不同:CIFAR-10数据集是RGB图像(有三个通道),MNIST数据集是灰度图像,这也是为什么CIFAR-10数据集比MNIST数据集多出一个维度的原因。
- 图像内容不同:CIFAR-10数据集展示的是各种不同的物体(猫、狗、飞机、汽车…),MNIST数据集展示的是不同人的手写0~9数字。
2.数据集读取
读取数据集
选取data_batch_1可视化其中一张图:
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
输出结果:
一批次的数据集中有4个字典键,我们需要用到的就是 数据标签 和 数据内容(10000×32×32×3,10000张32×32大小为rgb三通道的图片)

输出的是一个字典:
{
b’batch_label’: b’training batch 1 of 5’,
b’labels’: [6, 9 … 1,5],
b’data’: array([[ 59, 43, …, 84, 72],…[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8),
b’filenames’: [b’leptodactylus_pentadactylus_s_000004.png’,…b’cur_s_000170.png’]
}
其中,各个代表的意思如下:
b’batch_label’ : 所属文件集
b’labels’ : 图片标签
b’data’ :图片数据
b’filename’ :图片名称
读取类型
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
输出结果:
<class ‘bytes’>
<class ‘list’>
<class ‘numpy.ndarray’>
<class ‘list’>
读取图片
img = dict[b'data']
print(img.shape)
输出结果:(10000, 3072),其中 3072 = 32 * 32 * 3 (图片 size)
3.数据集调用
TensorFlow 调用
from tensorflow.keras.datasets import cifar10(x_train,y_train), (x_test, y_test) = cifar10.load_data()
本地调用
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4.卷积神经网络训练
此处参考:传送门
1.指定GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2.加载数据
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3.数据预处理
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4.建立模型
adam算法参数采用keras默认的公开参数,损失函数采用稀疏交叉熵损失函数,准确率采用稀疏分类准确率函数
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5.训练模型
批量训练大小为64,迭代5次,测试集比例0.2(48000条训练集数据,12000条测试集数据)
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6.评估模型
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7.结果可视化
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率plt.figure(figsize=(10,3))plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8.使用模型
plt.figure()
for i in range(10):num = np.random.randint(1,10000)plt.subplot(2,5,i+1)plt.axis('off')plt.imshow(test_x[num],cmap='gray')demo = tf.reshape(X_test[num],(1,32,32,3))y_pred = np.argmax(model.predict(demo))plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
输出结果:

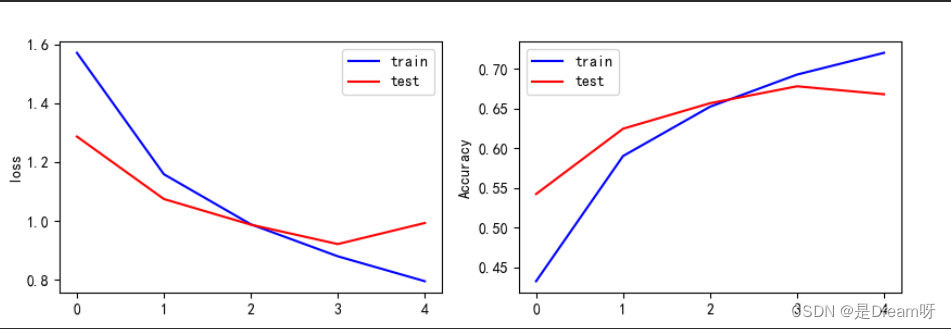
上面的内容分别是训练样本的损失函数值和准确率、测试样本的损失函数值和准确率,可以看到它每次训练迭代时损失函数和准确率的变化,从最后一次迭代结果上看,测试样本的损失函数值达到0.9123,准确率仅达到0.6839。
这个结果并不是很好,我尝试过增加迭代次数,发现训练样本的损失函数值可以达到0.04,准确率达到0.98;但实际上训练模型却产生了越来越大的泛化误差,这就是训练过度的现象,经过尝试泛化能力最好时是在迭代第5次的状态,故只能选择迭代5次。

训练好的模型文件——直接用
CIFAR10数据集介绍,并使用卷积神经网络训练图像分类模型——附完整代码和训练好的模型文件——直接用:https://download.csdn.net/download/weixin_51390582/88788820
相关文章:
CIFAR-10数据集详析:使用卷积神经网络训练图像分类模型
1.数据集介绍 CIFAR-10 数据集由 10 个类的 60000 张 32x32 彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像。 数据集分为5个训练批次和1个测试批次,每个批次有10000张图像。测试批次正好包含从每个类中随机选择的 1000 张图像…...

《傲剑狂刀》中的人物性格——龙吟风
在《傲剑狂刀》这款经典武侠题材的格斗游戏中,龙吟风作为一位具有传奇色彩的角色,其性格特征复杂且引人入胜。以下是对龙吟风这一角色的性格特点进行深度剖析: 一、孤高独立的剑客气质 龙吟风的名字本身就流露出一种独特的江湖气息,"吟风"象征着他的飘逸与淡泊名…...
KVM和JVM的虚拟化技术有何区别?
随着虚拟化技术的不断发展,KVM和JVM已成为两种主流的虚拟化技术。尽管它们都提供了虚拟化的解决方案,但它们在实现方式、功能和性能方面存在一些重要的差异。本文将深入探讨KVM和JVM的虚拟化技术之间的区别。 KVM(Kernel-based Virtual Mac…...
 持续更新中)
LeetCode力扣 面试经典150题 详细题解 (1~5) 持续更新中
目录 1.合并两个有序数组 2.移动元素 3.删除有序数组中的重复项 4.删除排序数组中的重复项 II 5.多数元素 暂时更新到这里,博主会持续更新的 1.合并两个有序数组 题目(难度:简单): 给你两个按 非递减顺序 排列的…...

如何解决利用cron定时任务自动更新SSL证书后Nginx重启问题
利用cron定时任务自动更新SSL证书后,用浏览器访问网站,获取到的证书仍然是之前的。原因在于没有对Nginx进行重启。 据说certbot更新完成证书后会自动重启Nginx,但显然经我检测不是这回事儿。 所以我们需要创建一bash脚本,然后定时调用这个脚…...
第一个 Angular 项目 - 静态页面
第一个 Angular 项目 - 静态页面 之前的笔记: [Angular 基础] - Angular 渲染过程 & 组件的创建 [Angular 基础] - 数据绑定(databinding) [Angular 基础] - 指令(directives) 这是在学完了上面这三个内容后能够完成的项目,目前因为还没有学到数…...
网络协议与攻击模拟_17HTTPS 协议
HTTPShttpssl/tls 1、加密算法 2、PKI(公钥基础设施) 3、证书 4、部署HTTPS服务器 部署CA证书服务器 5、分析HTTPS流量 分析TLS的交互过程 一、HTTPS协议 在http的通道上增加了安全性,传输过程通过加密和身份认证来确保传输安全性 1、TLS …...
【linux系统体验】-ubuntu简易折腾
ubuntu 一、终端美化二、桌面美化2.1 插件安装2.2 主题和图标2.3 美化配置 三、常用命令 以后看不看不重要,咱就是想记点儿东西。一、终端美化 安装oh my posh,参考链接:Linux 终端美化 1、安装字体 oh my posh美化工具可以使用合适的字体&a…...

Android 判断通知是进度条通知
1.需求: 应用监听安卓系统中的通知,需要区分出带进度条的通知. 当使用NotificationCompat.Builder构建一个通知时,可以通过调用setProgress(max, progress, indeterminate)方法来添加一个进度条。这里的max参数表示最大进度值,progress表示当前进度值&a…...

学习数据结构和算法的第8天
顺序表的实现 顺序表 本质就是数组 概念及结构 顺序表是用一段物理地址连续的储存单元依次储存数据元素的线性结构,一般情况下采用数组储存,在数组上完成数据的增删。 顺序表就是数组,但是在数组的基础上,它还要求数据…...
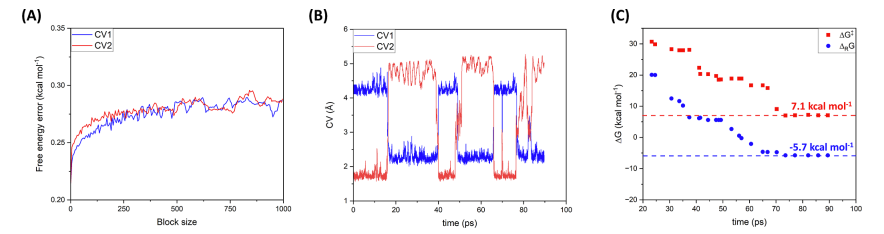
JCIM | MD揭示PTP1B磷酸酶激活RtcB连接酶的机制
Background 内质网应激反应(UPR) 中的一个重要过程。UPR是由内质网中的三种跨膜传感器(IRE1、PERK和ATF6)控制的细胞应激反应,当内质网中的蛋白质折叠能力受到压力时,UPR通过减少蛋白质合成和增加未折叠或错…...

基于Java (spring-boot)的音乐管理系统
一、项目介绍 播放器的前端: 1.首页:点击歌单中的音乐播放列表中的歌曲进行播放,播放时跳转播放界面,并显示歌手信息,同时会匹配歌词,把相应的歌词显示在歌词面板中。 2.暂停:当歌曲正在播放时…...

在 MacOS M系列处理器上使用 Anaconda 开发 Oralce 的Python程序
在 MacOS M系列处理器上使用 Anaconda 开发 Oralce 的Python程序 因oracle官方驱动暂无 苹果 M 系列处理器版本,所以使用Arm的python解释器报驱动错误: cx_Oracle.DatabaseError: DPI-1047: Cannot locate a 64-bit Oracle Client library: "dlop…...

四、OpenAI之文本生成模型
文本生成模型 OpenAI的文本生成模型(也叫做生成预训练的转换器(Generative pre-trained transformers)或大语言模型)已经被训练成可以理解自然语言、代码和图片的模型。模型提供文本的输出作为输入的响应。对这些模型的输入内容也被称作“提示词”。设计提示词的本质是你如何对…...

CSS之flex布局
flex布局 CSS的Flex布局(Flexible Box Layout)是一种用于在页面上布置元素的高效方法,特别适合于响应式设计。Flex布局使得元素能够伸缩以适应可用空间,可以简化很多原本需要复杂CSS和HTML结构才能实现的布局设计。 flex布局包括…...

UnityShader——02三大主流编程语言
三大主流编程语言 Shader Language Shader language的发展方向是设计出在便携性方面可以与C/JAVA相比的高级语言,“赋予程序员灵活而方便的编程方式”,并“利用图形硬件的并行性,提高算法的效率” Shader language目前主要有 3 种语言&…...
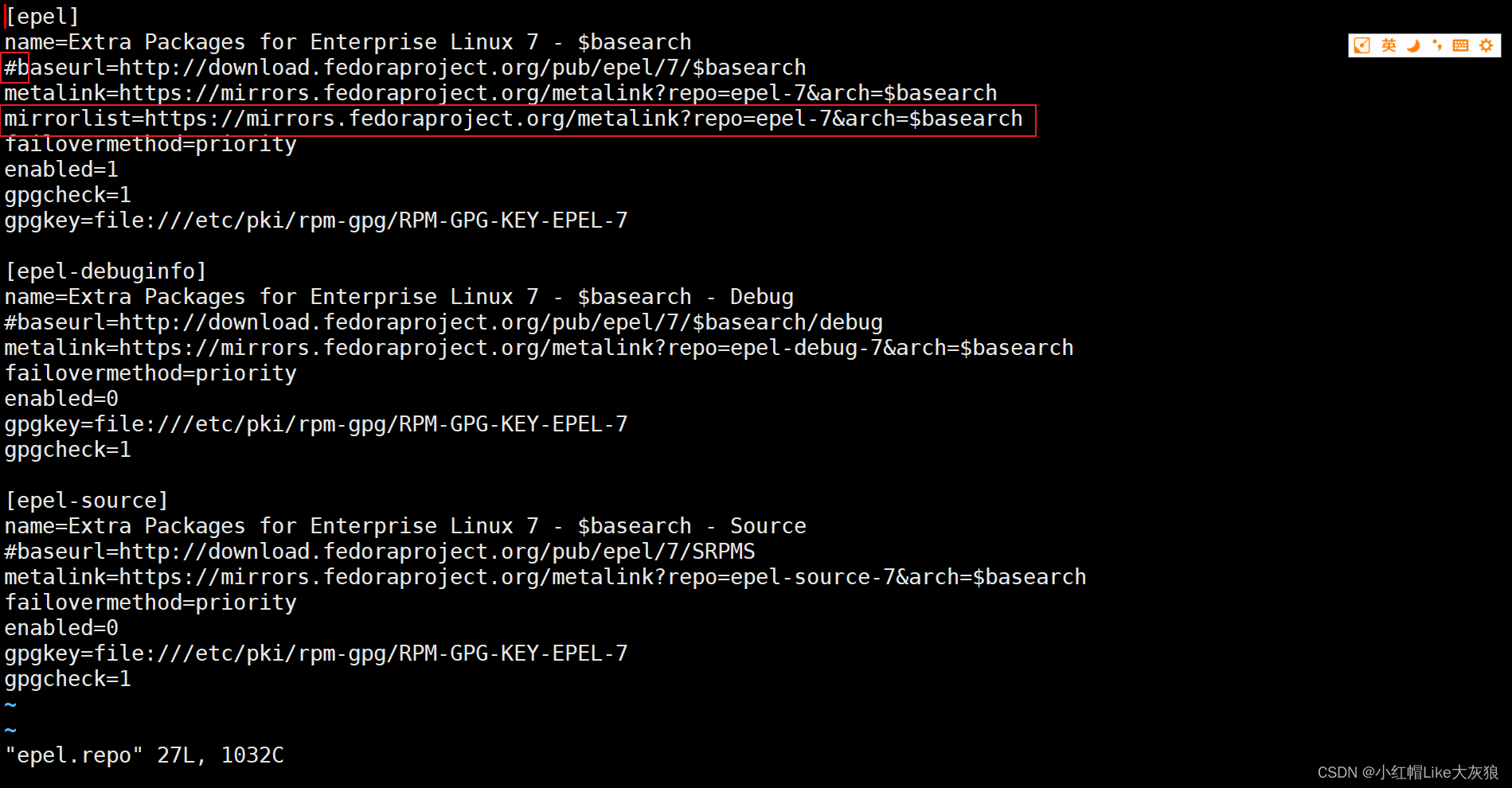
Centos7安装nginx yum报错
Centos7安装nginx yum报错,yum源报错解决办法: 1、更新epel源后,出现yum报错 [roothacker117 ~]# yum install epel-release(安装成功) [roothacker117 ~]# yum install nginx(安装失败,提示如…...

【机组】基于FPGA的32位算术逻辑运算单元的设计(EP2C5扩充选配类)
🌈个人主页:Sarapines Programmer🔥 系列专栏:《机组 | 模块单元实验》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 一、实验目的 二、实验要求 …...

Asp .Net Core 系列:Asp .Net Core 集成 NLog
简介 NLog是一个基于.NET平台编写的日志记录类库,它可以在应用程序中添加跟踪调试代码,以便在开发、测试和生产环境中对程序进行监控和故障排除。NLog具有简单、灵活和易于配置的特点,支持在任何一种.NET语言中输出带有上下文的调试诊断信息…...
一个基于 .NET 7 + Vue.js 的前后端分离的通用后台管理系统框架 - DncZeus
前言 今天给大家推荐一个基于.NET 7 Vue.js(iview-admin) 的前后端分离的通用后台权限(页面访问、操作按钮控制)管理系统框架:DncZeus。 官方项目简介 DncZeus是一个基于 .NET 7 Vue.js 的前后端分离的通用后台管理系统框架。后端使用.NET 7 Entity Framework…...

利欧股份持续推进“制造业+科技投资”战略 主业与投资协同效应显现
全球商业航天企业SpaceX(太空探索技术公司)计划于6月12日在纳斯达克上市,股票代码为SPCX。此次IPO预计融资规模约为800亿美元,市场估值在1.75万亿至2万亿美元之间,引发资本市场广泛关注。据悉,利欧股份&…...

【网络安全】2026最新网安渗透测试标准及流程!新手小白零基础入门必看教程!
✅一、了解渗透测试 🔴什么是渗透测试? 渗透测试是一种安全性测试,通过发起模拟网络攻击的方式查找计算机系统中的漏洞。 渗透测试人员是拥有高超道德黑客技术的安全专业人员(道德黑客是指运用黑客工具和黑客技术来修复安全薄弱环…...

Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览
Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...

如何快速掌握ComfyUI智能图像分割:面向新手的完整指南
如何快速掌握ComfyUI智能图像分割:面向新手的完整指南 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地址: ht…...

2026届最火的六大AI辅助论文网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术飞速发展着,智能内容生成也就是AIGC,正一步步渗透到学术…...
的四种“平替”方案全解析(含代码对比))
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比)
从《GPU Gems》到实战:次表面散射(SSS)的四种“平替”方案全解析(含代码对比) 在实时渲染领域,次表面散射(Subsurface Scattering,简称SSS)一直是提升材质真实感的关键技…...

避坑指南:STM32F4 HAL库驱动MPU6050,从GitHub标准库移植到DMA模式的完整记录
STM32F4 HAL库下MPU6050 DMA模式移植实战:从标准库到高效姿态采集 移植第三方传感器驱动是嵌入式开发中的高频操作。最近在平衡车项目中,需要将GitHub上一个基于标准库的MPU6050驱动移植到STM32CubeMX生成的HAL库环境,并升级为DMA传输模式。这…...

从USB转TTL到RS485:手把手教你用一颗CH342F芯片玩转三种串口通信
CH342F芯片实战指南:一芯三用的串口通信解决方案 在物联网和工业控制领域,串口通信依然是设备间可靠数据传输的基石。面对多样化的接口标准(TTL、RS232、RS485),工程师常常需要准备多种转换模块。而CH342F芯片以其独特…...

三星固件下载终极指南:Bifrost跨平台工具完整使用手册
三星固件下载终极指南:Bifrost跨平台工具完整使用手册 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备找不到官方固件而烦恼吗&#x…...

Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 配置稳定 API 连接避免封号困扰 基础教程类,针对经常遇到 Claude Code 封号或 Tok…...