四、OpenAI之文本生成模型

文本生成模型
OpenAI的文本生成模型(也叫做生成预训练的转换器(Generative pre-trained transformers)或大语言模型)已经被训练成可以理解自然语言、代码和图片的模型。模型提供文本的输出作为输入的响应。对这些模型的输入内容也被称作“提示词”。设计提示词的本质是你如何对大语言模型进行开发,通常是提供指令和任务案例来使工作得以成功完成。
使用OpenAI的文本生成模型,你可以创建以下应用:
- 草拟文档
- 生成编程代码
- 回答常识问题
- 分析文本
- 为软件提供一个自然语言接口
- 输导课程
- 翻译
- 人物模拟
使用GPT-4-vision-preview,你可以构建处理和理解图片的系统
通过OpenAI API调用下面其中的一个模型,可以发送一个包含输入和API key的请求,并接收模型的响应输出。最新发布的模型GPT-4和GPT-3.5-turbo,可以通过聊天补全API端点(API的一个具体访问点)进行调用。
| 模型家族 | API 端点 | |
|---|---|---|
| 新模型(2023 - ) | gpt-4, gpt-4-turbo-preview, gpt-3.5-turbo | https://api.openai.com/v1/chat/completions |
| 更新历史模型(2023) | gpt-3.5-turbo-instruct, babbage-002, davinci-002 | https://api.openai.com/v1/completions |
可以使用聊天后台测试各种模型,如果你不确定使用哪一个,推荐你使用gpt-3.5-turbo 或 gpt-4-turbo-preview
1. 聊天补全API
聊天模型采用一个消息列表作为输入,模型处理后再生成消息进行输出。聊天格式被设计成多轮会话小短文的形式,但也可设计成单轮会话的形式。
下面是聊天补全API(Chat Completions API)的一个例子:
# @Time : 2024/1/23 21:42
# @Author : NaiveFrank
# @Version : 1.0
# @Project : python_tutorial
from openai import OpenAI# 加载 .env 文件到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())# 初始化 OpenAI 服务。会自动从环境变量加载 OPENAI_API_KEY 和 OPENAI_BASE_URL
client = OpenAI()# 消息
messages=[{"role": "system", "content": "你是一个超级助理"},{"role": "user", "content": "OpenAI 是什么?"},{"role": "assistant", "content": "OpenAI是一家位于美国旧金山的人工智能研究公司."},{"role": "user", "content": "这是一家怎样的公司?"}]# 调用 GPT-3.5
chat_completion = client.chat.completions.create(model="gpt-3.5-turbo",messages=messages
)# 输出回复
print(chat_completion.choices[0].message.content)
OpenAI是一家非营利性的人工智能研究组织,致力于推动人工智能技术的发展和应用,以及确保这些技术对人类的利益具有正向影响。
OpenAI的目标是让人工智能对所有人具有广泛的益处,而不仅仅是少数特权阶层。该公司的使命是确保人工智能的发展是安全和有利于所有人类。
OpenAI的研究涵盖了各个领域,包括自然语言处理、计算机视觉、强化学习等。同时,OpenAI还发布了一些开源工具和数据集,
鼓励并促进全球范围内的合作和创新。Process finished with exit code 0
消息参数作为主要输入。所有的消息必须是一个数组对象,为JSON格式,每一个消息元素必须有一个角色(可以是:system, user, assistant)和内容。消息可以短到一条,也可以是多条。
通常,首先使用系统消息格式化对话,接下来是用户和助理消息进行交替输入。
系统消息会协助助理的行为。例如,可以修改成为一个个性化的助理,或提供特定的指令,让它在聊天中如何表现。但请注意,系统消息是可选的,模型也可没有一个系统消息,只使用一个普通消息,例如:“你是一个超级助理”等。
用户消息为助手提供请求或评论,然后获得响应。助手消息会存储之前助手的响应,也可以给出你希望模型做什么的案例。
当用户给出指令时,参考之前的历史消息非常重要。在上面的例子中,用户最终发出“这是一家怎样的公司?”的请求,这个问题只有通过上下文的理解才有意义。因为模型不会记忆历史请求,每一个请求,都作为对话历史的一部分,所有相关信息都必须提供。如果会话长度超过模型token的限制,应采取一些办法缩短token长度。
1.1. 聊天补全响应内容格式
Chat Completions API 响应内容格式:
{"id": "chatcmpl-8qzwxDRlj4oxE7YAujhchZ38vo4gI","choices": [{"finish_reason": "stop","index": 0,"logprobs": null,"message": {"content": "OpenAI是一家致力于推动人工智能技术发展的研究公司。公司的目标是确保人工智能的益处能够普惠全人类,并且避免其造成潜在的危害。\n\nOpenAI的研究范围涵盖了人工智能的各个领域,包括机器学习、自然语言处理、计算机视觉等。他们不仅致力于开展基础研究,也关注将人工智能技术应用于解决现实世界的问题。\n\n此外,OpenAI还以开放合作的方式进行研究,积极与其他研究机构、学术界、开发者社区进行合作,共同推动人工智能技术的进步。他们也致力于开源一些自己的研究成果和工具,以促进人工智能技术的普及和发展。","role": "assistant","function_call": null,"tool_calls": null}}],"created": 1707641883,"model": "gpt-3.5-turbo-0613","object": "chat.completion","system_fingerprint": null,"usage": {"completion_tokens": 285,"prompt_tokens": 70,"total_tokens": 355}
}
助理回复消息的提取:
chat_completion.choices[0].message.content
每个响应都要包含一个finish_reason,值可能如下:
- stop: API返回完整消息,或由stop参数提供的停止序列之一终止的消息
- length: 由于设置max_tokens参数或默认限制,返回未完成模型输出的长度
- function_call:模型要调用的函数
- content_filter:因内容过滤的标记而省略的内容
- null:API 响应仍然在处理或未完成
模型响应输出依赖输入的参数,参数不同,输出也会不同。
2. JSON模式输出
使用聊天补全一个常用的方法是:在系统消息里具体指定让模型一直返回JSON对象,这样做对项目更有意义。当我们做一些项目时,一些模型产生的输出偶尔不是有效的JSON对象。
为了防止这些错误和提升模型的表现,当调用GPT-4-turbo-preview或GPT-3.5-turbo-0125时,可以设置response_format参数为:{“type”:“json_object”}以开启JSON输出模式。当开启JSON输出模式时,模型将被强迫输出,能被解析成JSON对象字符串。
重要提示:
- 当使用JSON格式输出模式时,需要在对话消息中一直指示模型进行JSON格式输出,例如:系统消息。如果没有明确指示输出为JSON格式,模型可能会输出无穷的空白流,也可能请求持续运行一直到token的上限。如果漏设"JSON"格式输出,API会抛出例外。
- 如果返回的finish_reason值是length,模型返回的JSON信息可能被截断,代表信息超过了max_tokens参数或会话token的限制。为了防止这种情况发生,解析返回的响应信息时应检查finish_reason参数
- 在JSON模式下不能保证输出匹配任何特定格式,仅保证格式有效和解析没有错误。
响应输出的JSON对象可以如下:
{"education": "硕士","experience": "6年","ability": "8个项目","attitude": "非常好","total": 32,"result": true
}
请注意:当模型生成参数作为函数调用(function calling)的一部分时,JSON模式输出一直开启
3. 可重现输出
聊天补全默认具有不确定性(不同的请求之间模型的输出可能不同),为了保持稳定的输出,我们提供一些控制,可以设置seed参数和system_fingerpint响应字段
通过API调用获得确定性(大部分)输出,可以进行以下设置:
- 设置seed参数可以为任何整型,为了确保整个请求过程输出都是确定的都要使用同一个值
- 确保其它参数(如:prompt 或 temperature)在整个请求过程中也要相同
有时会对OpenAI模型配置做必要的更改,确定性可能会受到影响。为了帮助你一直保持对这些改变的追踪,我们暴露了system_fingerprint字段参数。如果这个参数值发生改变,得到不同的输出结果,是因为我们的系统发生了改变。
4. 管理令牌
语言模型的读和写的文本块称作tokens。在英文中,一个token可能短到一个字符也可能长到一个词(例如:a or apple),其它语言可能比一个字符更短,也可能比一个词更长。
例如,字符串"ChatGPT is great!“,编码为6个tokens:[“Chat”, “G”, “PT”, " is”, " great", “!”].
tokens的总数在调用API中的影响:
- API调用的费用,因为每一个token都要支付费用
- API调用的耗时,因为越多的tokens耗费的时间越长
- API调用是否有效,因为总令牌必须低于模型的最大限制(gpt-3.5-turbo的4097令牌)
输入和输出的tokens都是计数的。例如,你调用API输入的tokens是10,接收输出的tokens是20,那你要支付30个tokens的费用。但注意:对于某些模型,每个token的费用在输入和输出中也是不同的。
想看API的调用使用了多少tokens,可以查看API响应中的usage字段参数(例如:response[‘usage’][‘total_tokens’])
GPT-3.5-turbo 和 GPT-4-turbo-preview都是聊天补全API,使用tokens的方式是一样,因为它们都是基于消息的格式,但在一个会话中计算使用了多少tokens是一件很难的事情。
想看一个文本字符串有多少tokens没有被API调用消耗,可以使用OpenAI的 tiktoken Python 库进行统计
传给AIP的每一个参数都要消耗一定数量的tokens,包括:内容、角色和其它一些字段,外加一些额外的格式。这些在将来也许会有稍许变动。
如果一个会话包含太多的tokens,以至超出模型的最大限制(例如:GPT-3.5-turbo 超过4097),必须截断、省略或压缩文本直至在允许限制内。注意如果一个消息在输入时被删除,模型将什么都不懂了
值得注意:过长的对话很可能收到一个不完整的响应。例如:在模型GPT-3.5-turbo中,一个长度为4090 tokens的对话,它的回复在6个tokens后就会被截断。
5. 参数细节
5.1 频率和展现惩罚
在聊天补全API(Chat Completions API)和历史完成API(Legacy Completions API)中拥有频率和展现惩罚可以被用来减少重复令牌序列被采样的可能性。如果目标只是在一定程度上减少重复样本,惩罚系数的合理值应该在0.1到1之间。如果目标是强烈的抑制重复,可以将系统增加到2,但这可能会显著的降低样本的质量。负数可能会增加样本重复的可能性。
5.2 令牌日志概率
Chat Completions API和Legacy Completions API都存在logprobs参数,当请求时,提供每个输出token的日志概率;以及每个标记位置上有限数量的,最有可能的标记以及它们的对数概率。在某些情况下,这对于评估模型在其输出中的置信度或检查模型可能给出的替代响应是有用的。
6. 补全API(衍生)
聊天补全端点2023.7进行了最后的更新,它有一个新的聊天接口。用输入一个被称作prompt自由格式文本,代替消息列表。历史的聊天补全API的调用例子如下:
from openai import OpenAI
client = OpenAI()response = client.completions.create(model="gpt-3.5-turbo-instruct",prompt="OpenAI是一家怎样的公司?"
)
6.1 插入文本
除了作为前缀处理的标准提示词之外,补全端点还支持通过后缀来插入文本。
在编写长篇文本时,段落之间的过渡或遵循一个大纲,指导模型该怎么结束。这个技巧也适用于代码的输入,在函数或文件的中间插入以上优化。
偿试给出更多的示例。
在某些情况下,为了更好地帮助模型的训练生成,可以通过提供一些模型可以遵循的模式示例,来确定一个自然的停止位置。
例如:
如何制作美味的热巧克力:
-
煮水
-
把热巧克力放进杯子里
-
往杯子里加入开水
-
享受热巧克力吧
-
狗是忠诚的动物。
-
狮子是凶猛的动物。
-
海豚是顽皮的动物。
-
马是威严的动物。
6.2 补全的响应格式
{id='cmpl-8rbdsd9I3ORYB4iZmkfkE0VNpi7KW', choices=[{finish_reason='length', index=0, logprobs=None, text='\n\nOpenAI (Open Artificial Intelligence)是一家非营利性'}], created=1707786772, model='gpt-3.5-turbo-instruct', object='text_completion', system_fingerprint=None, usage={completion_tokens=16, prompt_tokens=11, total_tokens=27}
}用Python可以使用response[‘choices’][0][‘text’]提取输出。响应格式同聊天补全API类似。
6.3 聊天补全 对比 非聊天补全
聊天补全可以创建出一个同非聊天补全相似的一个请求只用一个单独的用户消息。例如:把下面的汉语翻译成英语的提示词:
非聊天补全:
把下面的汉语翻译成英语:"{text}"
聊天补全:
[{"role": "user", "content": '把下面的汉语翻译成英语:"{text}"'}
]
同样道理,非聊天补全也可以模拟聊天补全,使用"user"和"assistant"格式化后作为相应的输入
两者的不同之处在于底层所使用的模型不同。聊天补全API接口拥有最具能力(GPT-4-turbo-preview)和最有性价比(GPT-3.5-turbo)模型
7. 模型使用推荐
一般情况下推荐使用模型(GPT-4-turbo-preview)或(GPT-3.5-turbo)。使用的模型也依赖项目的复杂度。GPT-4-turbo-preview在更广范围中评估表现会更好一些,特别是在处理复杂指令的细节能力上表现的更强。相比之下,GPT-3.5-turbo擅长处理复杂任务的一部分。GPT-4-turbo-preview很少像GPT-3.5-turbo会编造一些信息,这种行为被称作:“幻觉”,GPT-4-turbo-preview有128,000 tokens的窗口大小,GPT-3.5-turbo只有4,096 tokens的窗口大小。但GPT-3.5-turbo模型输出具有低延时和每个token成本低的特点。
推荐在后台进行相应的测试,以权衡哪种模型能为您的应用提供最佳的性价比。一种常见的设计模式是,使用几个不同的查询类型,每个查询类型都分配给适当的模型来处理它们。
8. FAQ
-
怎样设置temperature参数?
temperature值越低输出的结果越稳定(如:0.2), 反之越高输出的结果越具有多样性和创造性(如:1.0)。根据你的特定应用场景,对一致性和创造性进行权衡,选择一个适合的temperature值。temperature值范围(0~2)之间 -
最新的模型可以用fine-tuning吗?
部分可以。当前仅能对gpt-3.5-turbo 和 基座模型(babbage-002 and davinci-002)进行fine-tuning -
会存储传入API的参数数据吗?
截止到2023.3.1,保留API参数数据30天,并不会使用这些数据来训练改善模型。 -
怎样使我的模型更安全?
你可以加一个审核层作为聊天补全API的输出。 -
我应该使用ChatGPT还是调用API?
ChatGPT为我们的模型提供一个聊天的入口,并且内置很多功能,像整合浏览、代码执行、插件等等。相比较,OpenAI API 提供更加灵活的特性,但需要写代码发送请求到模型中。
相关文章:
四、OpenAI之文本生成模型
文本生成模型 OpenAI的文本生成模型(也叫做生成预训练的转换器(Generative pre-trained transformers)或大语言模型)已经被训练成可以理解自然语言、代码和图片的模型。模型提供文本的输出作为输入的响应。对这些模型的输入内容也被称作“提示词”。设计提示词的本质是你如何对…...

CSS之flex布局
flex布局 CSS的Flex布局(Flexible Box Layout)是一种用于在页面上布置元素的高效方法,特别适合于响应式设计。Flex布局使得元素能够伸缩以适应可用空间,可以简化很多原本需要复杂CSS和HTML结构才能实现的布局设计。 flex布局包括…...

UnityShader——02三大主流编程语言
三大主流编程语言 Shader Language Shader language的发展方向是设计出在便携性方面可以与C/JAVA相比的高级语言,“赋予程序员灵活而方便的编程方式”,并“利用图形硬件的并行性,提高算法的效率” Shader language目前主要有 3 种语言&…...
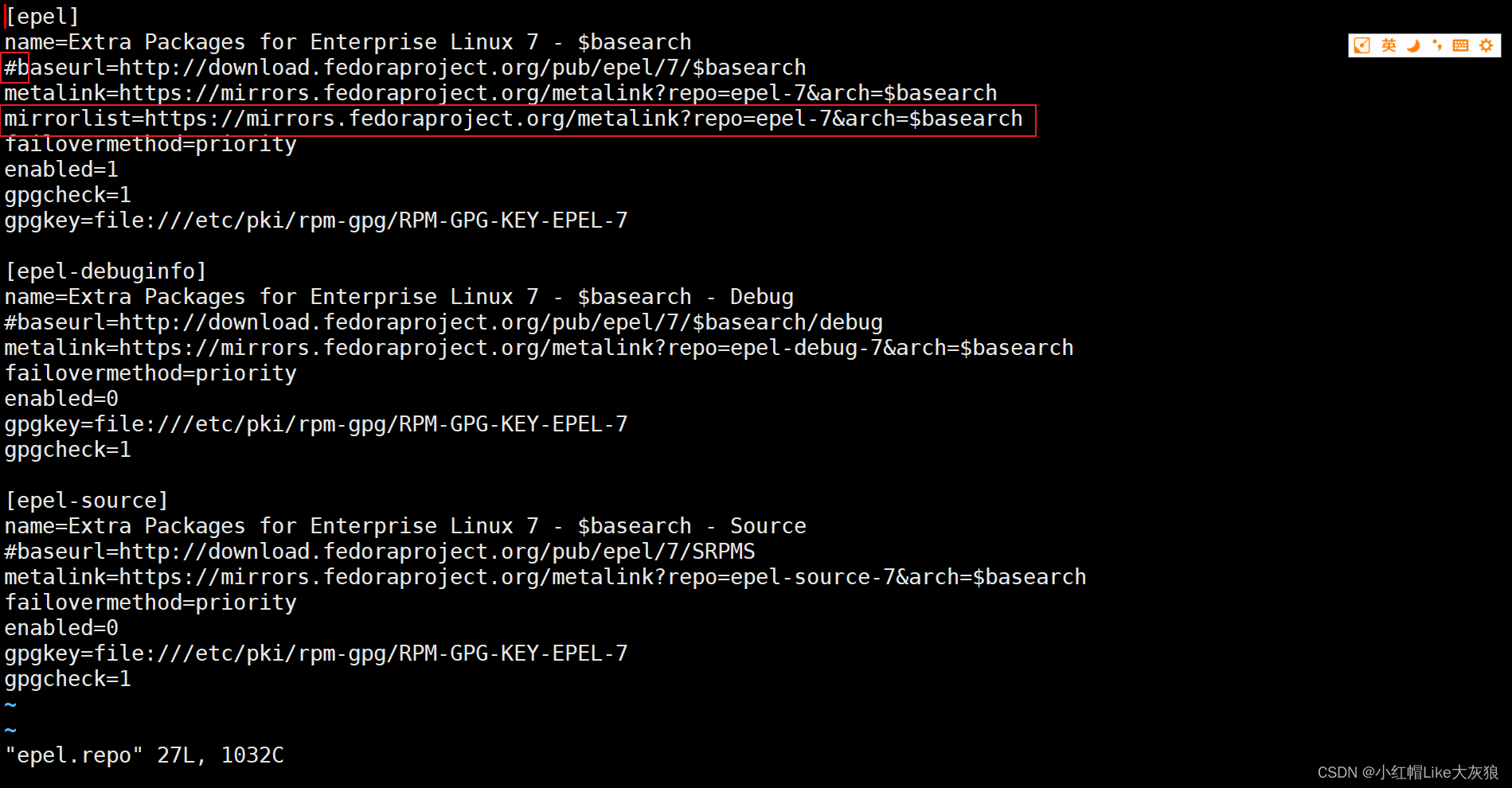
Centos7安装nginx yum报错
Centos7安装nginx yum报错,yum源报错解决办法: 1、更新epel源后,出现yum报错 [roothacker117 ~]# yum install epel-release(安装成功) [roothacker117 ~]# yum install nginx(安装失败,提示如…...

【机组】基于FPGA的32位算术逻辑运算单元的设计(EP2C5扩充选配类)
🌈个人主页:Sarapines Programmer🔥 系列专栏:《机组 | 模块单元实验》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 一、实验目的 二、实验要求 …...

Asp .Net Core 系列:Asp .Net Core 集成 NLog
简介 NLog是一个基于.NET平台编写的日志记录类库,它可以在应用程序中添加跟踪调试代码,以便在开发、测试和生产环境中对程序进行监控和故障排除。NLog具有简单、灵活和易于配置的特点,支持在任何一种.NET语言中输出带有上下文的调试诊断信息…...
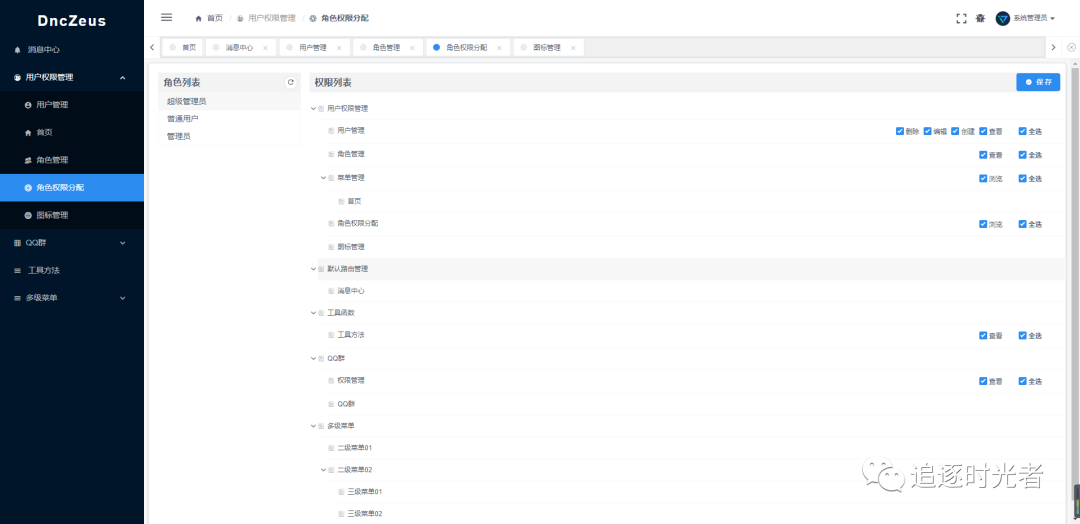
一个基于 .NET 7 + Vue.js 的前后端分离的通用后台管理系统框架 - DncZeus
前言 今天给大家推荐一个基于.NET 7 Vue.js(iview-admin) 的前后端分离的通用后台权限(页面访问、操作按钮控制)管理系统框架:DncZeus。 官方项目简介 DncZeus是一个基于 .NET 7 Vue.js 的前后端分离的通用后台管理系统框架。后端使用.NET 7 Entity Framework…...

更换商品图片日期JSON格式报错 - 序列化与反序列化日期格式设置
报错信息 msg: “服务端异常,请联系管理员JSON parse error: Cannot deserialize value of type java.util.Date from String “2023-11-13 13:13:35”: not a valid representation (error: Failed to parse Date value ‘2023-11-13 13:13:35’: Cannot parse da…...
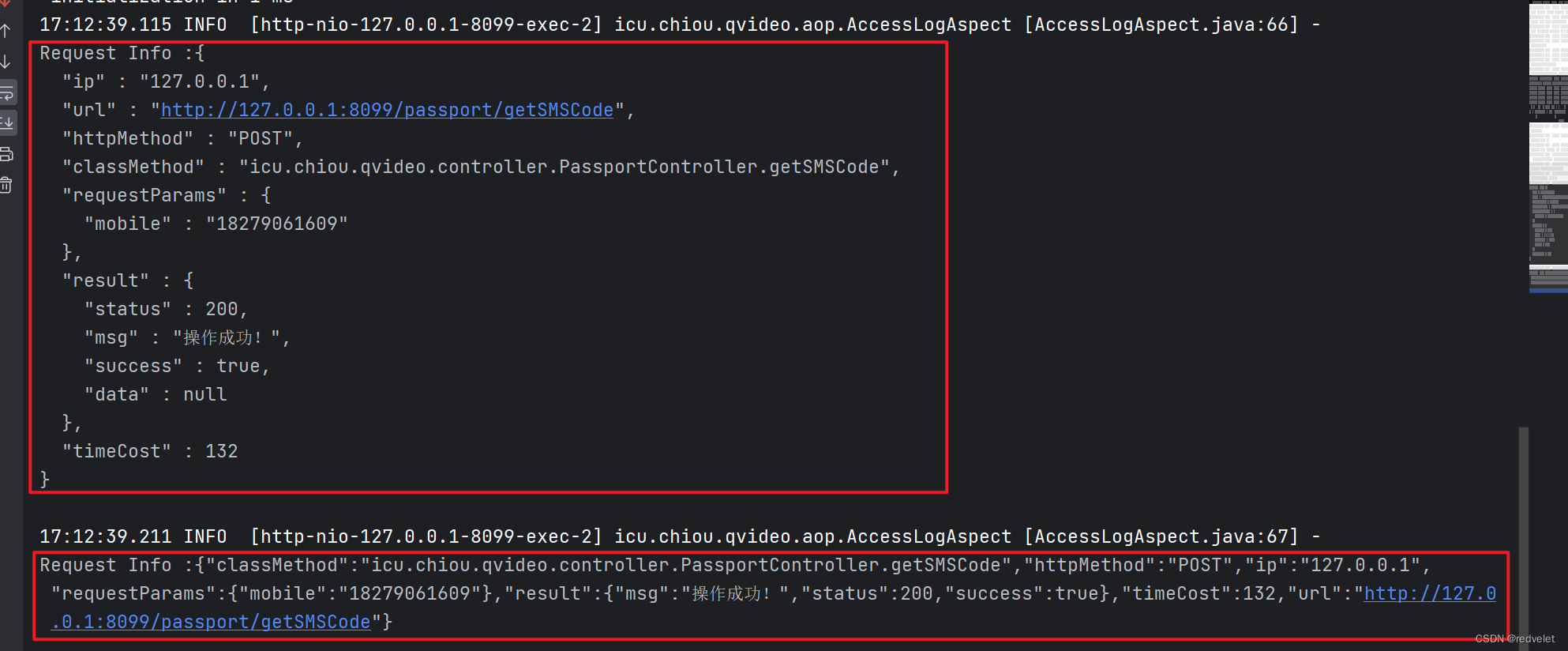
FastJson、Jackson使用AOP切面进行日志打印异常
FastJson、Jackson使用AOP切面进行日志打印异常 一、概述 1、问题详情 使用FastJson、Jackson进行日志打印时分别包如下错误: 源码: //fastjon log.info("\nRequest Info :{} \n", JSON.toJSONString(requestInfo)); //jackson …...
—— 富士康)
嵌入式大厂面试题(2)—— 富士康
从本篇开始将会更新历年来各个公司的面试题与面经,题目来自于网上各个平台以及博主自己遇到的,如果大家有所帮助,帮忙点点赞和关注吧! 岗位:嵌入式软件工程师。 面试时间:30分钟。 岗位职责:官网…...

力扣_字符串4—编辑距离
题目 给你两个单词 w o r d 1 word1 word1 和 w o r d 2 word2 word2, 请返回将 w o r d 1 word1 word1 转换成 w o r d 2 word2 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 方法—动…...

MySQL篇----第二十篇
系列文章目录 文章目录 系列文章目录前言一、NULL 是什么意思二、主键、外键和索引的区别?三、你可以用什么来确保表格里的字段只接受特定范围里的值?四、说说对 SQL 语句优化有哪些方法?(选择几条)前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍…...

Promise 基础
Promise 基础 理解 抽象表达: Promise 是一门新的技术(ES6 规范)Promise 是 Js 中进行异步编程的新的解决方案(旧方案是使用回调函数) 具体表达 从语法上来说,Promise 是一个构造函数从功能上来说&#x…...
RPA财务机器人之UiPath实战 - 自动化操作Excel进行财务数据汇总与分析之流程建立与数据读取、处理、汇总、分析
一、案例介绍: A公司共有13个开在不同银行的帐户,分别用于不同的业务分部或地区分部收付款。公司总部为了核算每月的收支情况,查看银行在哪个月交易量频繁,需要每月汇总各个银行的帐户借方和贷方金额,并将其净收支&am…...
)
华为机试真题实战应用【赛题代码篇】-输入整型数组和排序标识/根据排序标识flag给数组排序(附Java、C++和python代码)
目录 问题描述 输出描述: 示例: 代码实现 Java 代码2 代码3 python...

【算法随想录01】环形链表
题目:141. 环形链表 难度:EASY 代码 哈希表遍历求解,表中存储的是元素地址。 时间复杂度 O ( N ) O(N) O(N),空间复杂度 O ( N ) O(N) O(N) /*** Definition for singly-linked list.* struct ListNode {* int val;* …...
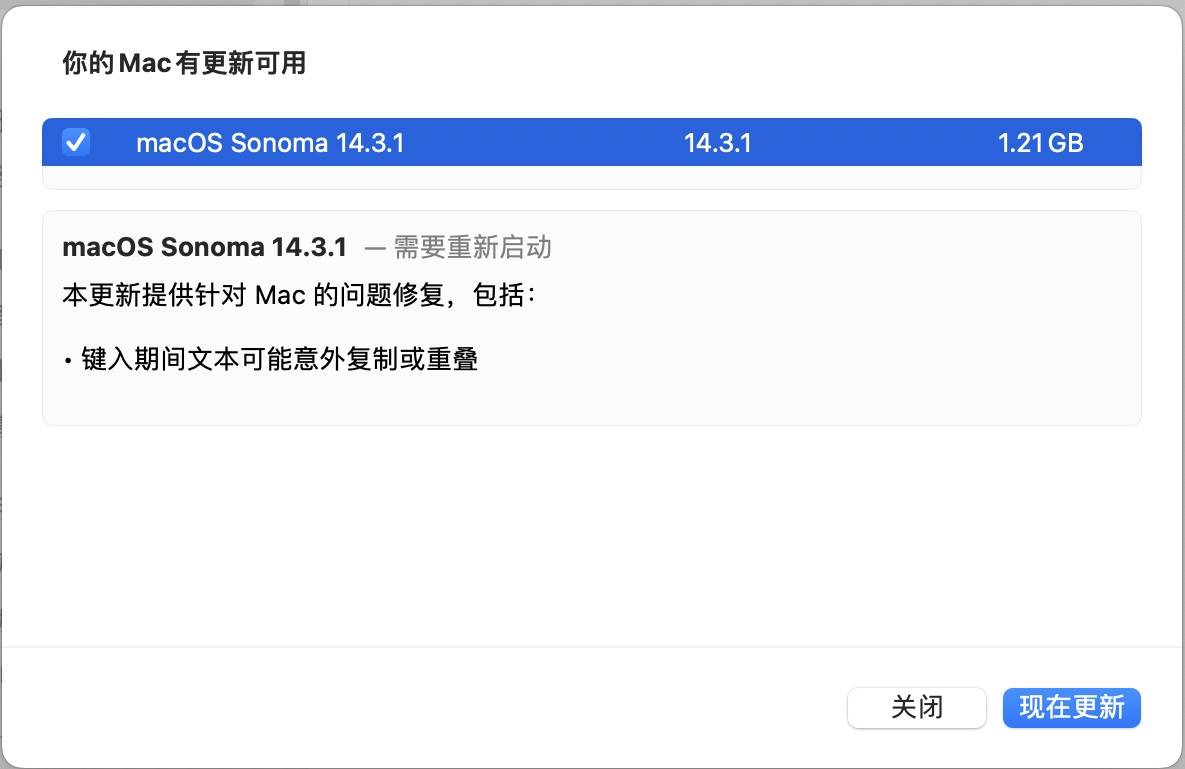
macOS Sonoma 14.3.1(23D60)发布
系统介绍 黑果魏叔2 月 9 日消息,苹果今日向 Mac 电脑用户推送了 macOS 14.3.1 更新(内部版本号:23D60),本次更新距离上次发布隔了 17 天。 魏叔 查询苹果官方更新日志,macOS Sonoma 14.3.1 修复内容和 …...

2024-02-11 叮当鸭-平台系统-第三次重构-目标确定
摘要: 对平台系统的第三个版本,做总体规划,明确要达到的目标,功能需求,性能需求。 根据这些所要达到的目标,确定选择何种的方案。方案的成本评估单独进行,本文重点分析要达到的各种目标。 功能需求: 能和…...
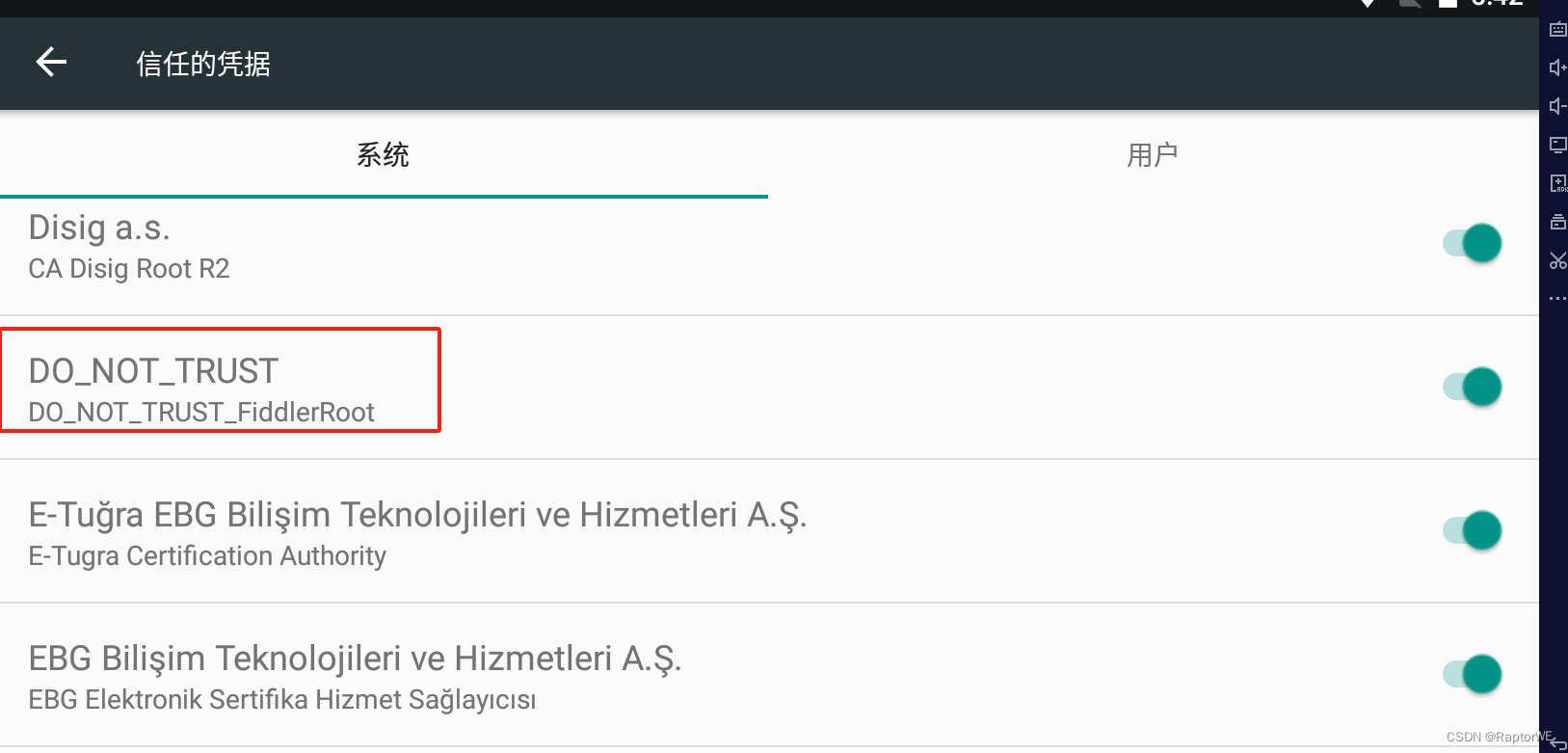
Android7.0-Fiddler证书问题
一、将Fiddler的证书导出到电脑,点击Tools -> Options -> HTTPS -> Actions -> Export Root Certificate to Desktop 二、下载Window版openssl, 点击这里打开页面,下拉到下面,选择最上面的64位EXE点击下载安装即可 安…...
)
Kotlin:单例模式(项目使用实例)
摘要 单例模式主要的五种如下: 饿汉式懒汉式线程安全的懒汉式双重校验锁式(Double Check)静态内部类式 一、项目使用单例模式实例场景 app在运行时缓存部分数据,作为全局缓存数据,以便其他页面及时更新页面对应状态的数据&…...

5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案
5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在电商竞争日益激烈的今天,…...

标准输入流,输出流,错误流 以及 重定向 的原理
标准输入流、输出流、错误流在操作系统与C语言中的表达 1. 操作系统层面(Linux/Unix) 在操作系统层面,标准输入、标准输出和标准错误流通过文件描述符(File Descriptor) 来标识:流类型文件描述符 (fd)默认设…...
)
ENSP USG6000防火墙CPU占用飙到99%?可能是你的“小云朵”网卡选错了(VMware网卡避坑指南)
ENSP USG6000防火墙CPU占用率优化实战:VMware虚拟网卡配置全解析 当你在ENSP中成功启动USG6000防火墙后,是否遭遇过整个系统突然变得异常卡顿?打开任务管理器,发现ENSP进程的CPU占用率直逼99%,仿佛你的电脑正在执行某种…...

前沿:小目标检测,YOLOv11n 再进化!
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 https://sensors.myu-group.co.jp/sm_pdf/SM4311.pdf 计算机视觉研究院专栏 Column of Computer Vision Institute 基于最新 YOLOv…...
架构与应用解析)
Arm Ethos-U65 NPU性能监控单元(PMU)架构与应用解析
1. Arm Ethos-U65 NPU性能监控单元架构解析 性能监控单元(PMU)是现代处理器架构中不可或缺的调试与分析模块,尤其在AI加速器领域更是性能调优的关键工具。Arm Ethos-U65 NPU作为面向嵌入式设备的神经网络处理器,其PMU设计充分考虑…...

Perplexity + Obsidian + LlamaIndex三端联动:打造个人知识库响应延迟<800ms的私有化查询方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity技术文档查询 Perplexity 是一种衡量语言模型预测能力的指标,常用于评估模型对给定文本序列的不确定性程度。在技术文档查询场景中,它被用作排序与重排的关键信号——…...

3分钟高效掌握Python手机号查QQ号实用技巧
3分钟高效掌握Python手机号查QQ号实用技巧 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 手机号查QQ号是现代社交网络管理中的一项实用技能,通过Python工具可以快速实现手机号与QQ号的关联查询。这个开源项目提供了一个…...

接口自动化测试框架搭建:基于Python+Requests+Pytest的实战教程
在软件测试领域,接口自动化测试是保障系统稳定性、提升测试效率的关键手段。随着敏捷开发和DevOps理念的普及,自动化测试的重要性愈发凸显。Python凭借其简洁的语法、丰富的库生态,成为接口自动化测试的首选语言;Requests库让HTTP…...

云英谷开启招股:拟募资11亿港元 5月27日上市 小米华为红杉是股东
雷递网 雷建平 5月18日云英谷科技股份有限公司(简称:“云英谷”,股票代码:“03310”)日前开启招股,准备2026年5月27日在港交所上市。云英谷发行价为20.81港元,发行5285.92万股,募资总…...

Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新
Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gi…...