多机多卡运行nccl-tests和channel获取
nccl-tests
- 环境
- 1. 安装nccl
- 2. 安装openmpi
- 3. 单机测试
- 4. 多机测试
- mpirun多机多进程
- 多节点运行nccl-tests
- channel获取
环境
- Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)
- cuda 11.8+ cudnn 8
- nccl 2.15.1
- NVIDIA GeForce RTX 4090 *2
1. 安装nccl
#查看cuda版本
nvcc -V
Nvidia官网下载链接 (不过好像需要注册一个Nvidia账户)
根据自己的cuda版本去寻找想要的版本,单击对应行即可显示下载步骤。
采取 Network Installer即可,我选择了nccl2.15.1+cuda11.8
#配置网络存储库
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update#安装特定版本
sudo apt install libnccl2=2.15.1-1+cuda11.8 libnccl-dev=2.15.1-1+cuda11.8#确认系统nccl版本
dpkg -l | grep nccl2. 安装openmpi
#apt安装openmpi
sudo apt-get update
sudo apt-get install openmpi-bin openmpi-doc libopenmpi-dev#验证是否安装成功
mpirun --version
3. 单机测试
nccl-test GitHub链接
如何执行测试和相关参数参考readme.md即可,已经描述的很详细了。
NCCL测试依赖于MPI以在多个进程和多个节点上工作。如果你想使用MPI支持编译这些测试,需要将环境变量MPI设置为1,并将MPI_HOME设置为MPI安装的路径。
#克隆该repo
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests# 编译支持mpi的test
make MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi
成功后会在build目录下生成可执行文件

NCCL测试可以在多个进程、多个线程和每个线程上的多个CUDA设备上运行。进程的数量由MPI进行管理,因此不作为参数传递给测试(可以通过mpirun -np n(n为进程数)来指定)。
总的ranks数量(即CUDA设备数,也是总的gpu数量)=(进程数)*(线程数)*(每个线程的GPU数)。
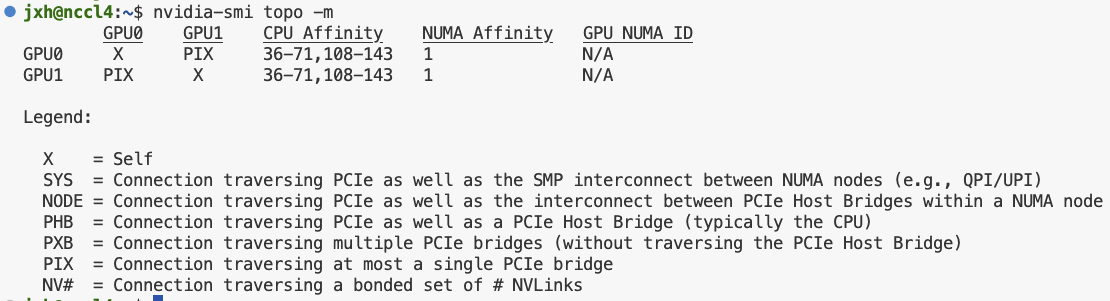
可以先通过nvidia-smi topo -m命令查看机器内拓扑结构,这里是双卡,两个gpu之间连接方式是PIX(Connection traversing at most a single PCIe bridge)
在 2个 GPU 上运行 ( -g 2 ),扫描范围从 8 字节到 128MB :
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2
这里-b表示minBytes,-e表示maxBytes,-g表示两张卡,-f表示数据量每次乘2,如开始是8B,往后依次是16,32,64字节…
-g后面的gpu数量不能超过实际的数量,否则会报如下错误- invalid Device ordinal

单机执行结果如下:
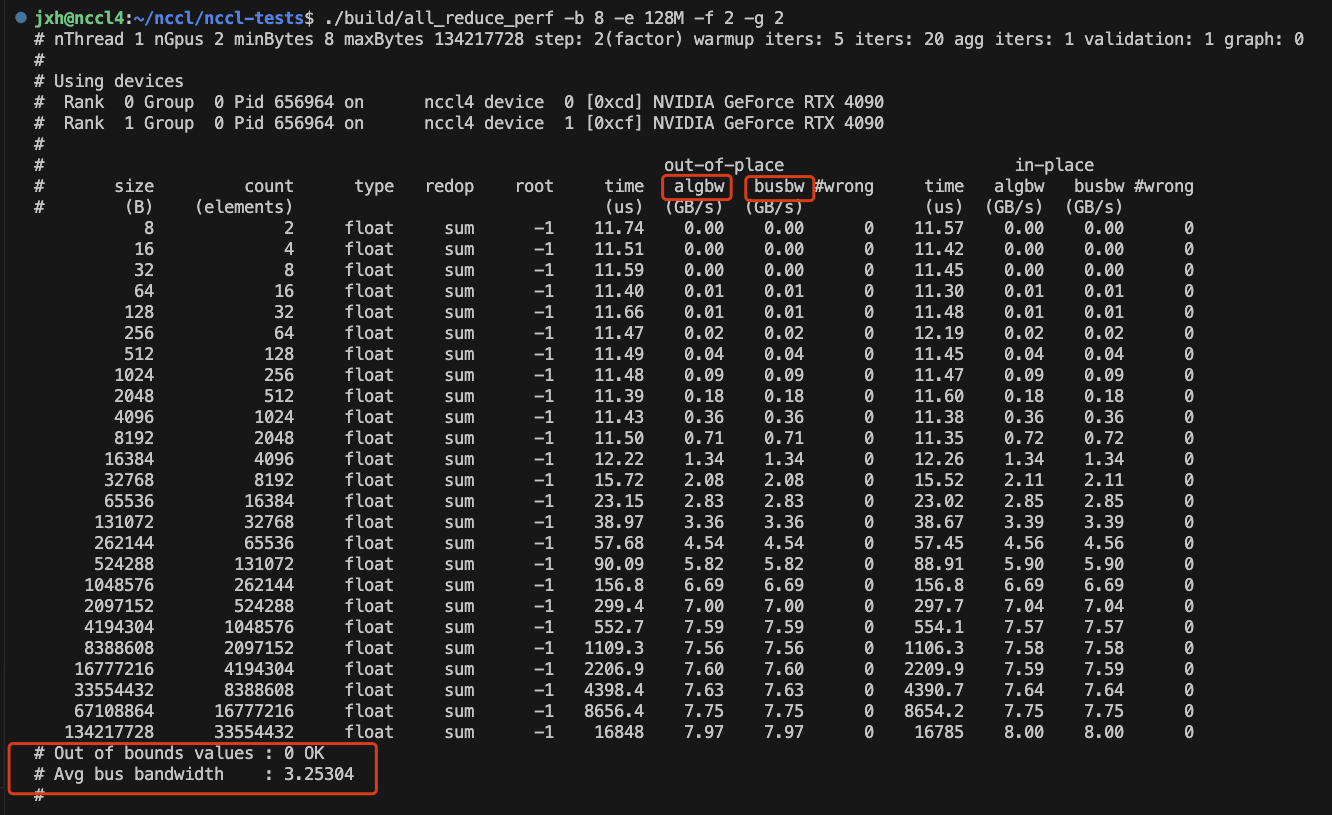
这里执行all_reduce操作时算法带宽(algbw)和总线带宽(busbw)是一致的,并且都是随着数据量的增大而增大。关于二者的区别可见https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md#bandwidth
4. 多机测试
关于mpi的基本了解和使用,可参考这篇文章 DL分布式训练基础之openmpi
mpirun多机多进程
这里使用2个节点(126,127)。 运行mpirun命令的为头节点(这里用126),它是通过ssh远程命令来拉起其他节点(127)的业务进程的,故它需要密码访问其他host
#在126生成RSA公钥,并copy给127即可
ssh-keygen -t rsassh-copy-id -i ~/.ssh/id_rsa.pub 192.168.72.127
如果ssh的端口不是22,可以在mpirun命令后添加参数-mca plm_rsh_args "-p 端口号" ,除此之外,还可以在主节点上编辑以下文件
nano ~/.ssh/config
#添加以下内容
Host 192.168.72.127Port 2233
指定连接到特定主机时使用的端口(例如2233),并确保在执行之前检查并设置~/.ssh/config文件的权限,使其对你的用户是私有
的:
chmod 600 ~/.ssh/config
这样配置后,当你使用SSH连接到主机192.168.72.127,SSH将使用端口2233,可以减少在‘mpirun‘命令中指定端口的需要。
然后可以进行多节点测试,节点个数对应-np 后的数字,这里新建一个hostfile内容如下,每行一个ip地址就可以
192.168.72.126
192.168.72.127
mpirun -np 2 -hostfile hostfile -pernode \
bash -c 'echo "Hello from process $OMPI_COMM_WORLD_RANK of $OMPI_COMM_WORLD_SIZE on $(hostname)"'

多节点运行nccl-tests
运行以下命令,这里对应双机4卡,注意np后面的进程数*单个节点gpu数(-g 指定)=总的gpu数量,即之前提到的等式
总的ranks数量(即CUDA设备数,也是总的gpu数量)=(进程数)*(线程数)*(每个线程的GPU数)。
mpirun -np 2 -pernode \
--allow-run-as-root \
-hostfile hostfile \
-mca btl_tcp_if_include eno2 \
-x NCCL_SOCKET_IFNAME=eno2 \
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2 -c 0
避免每次命令加–allow-run-as-root
echo 'export OMPI_ALLOW_RUN_AS_ROOT_CONFIRM=1' >> ~/.bashrc
echo 'export OMPI_ALLOW_RUN_AS_ROOT=1' >> ~/.bashrc
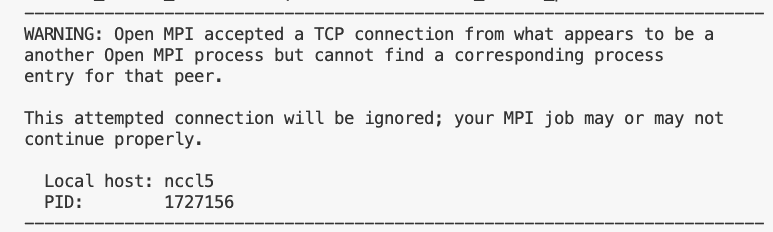
不添加参数-mca btl_tcp_if_include eno2 的话会报错如下:Open MPI accepted a TCP connection from what appears to be a
another Open MPI process but cannot find a corresponding process entry for that peer.
eno2替换为自己的网卡接口名称,可通过ifconfig查看。
执行结果如下:
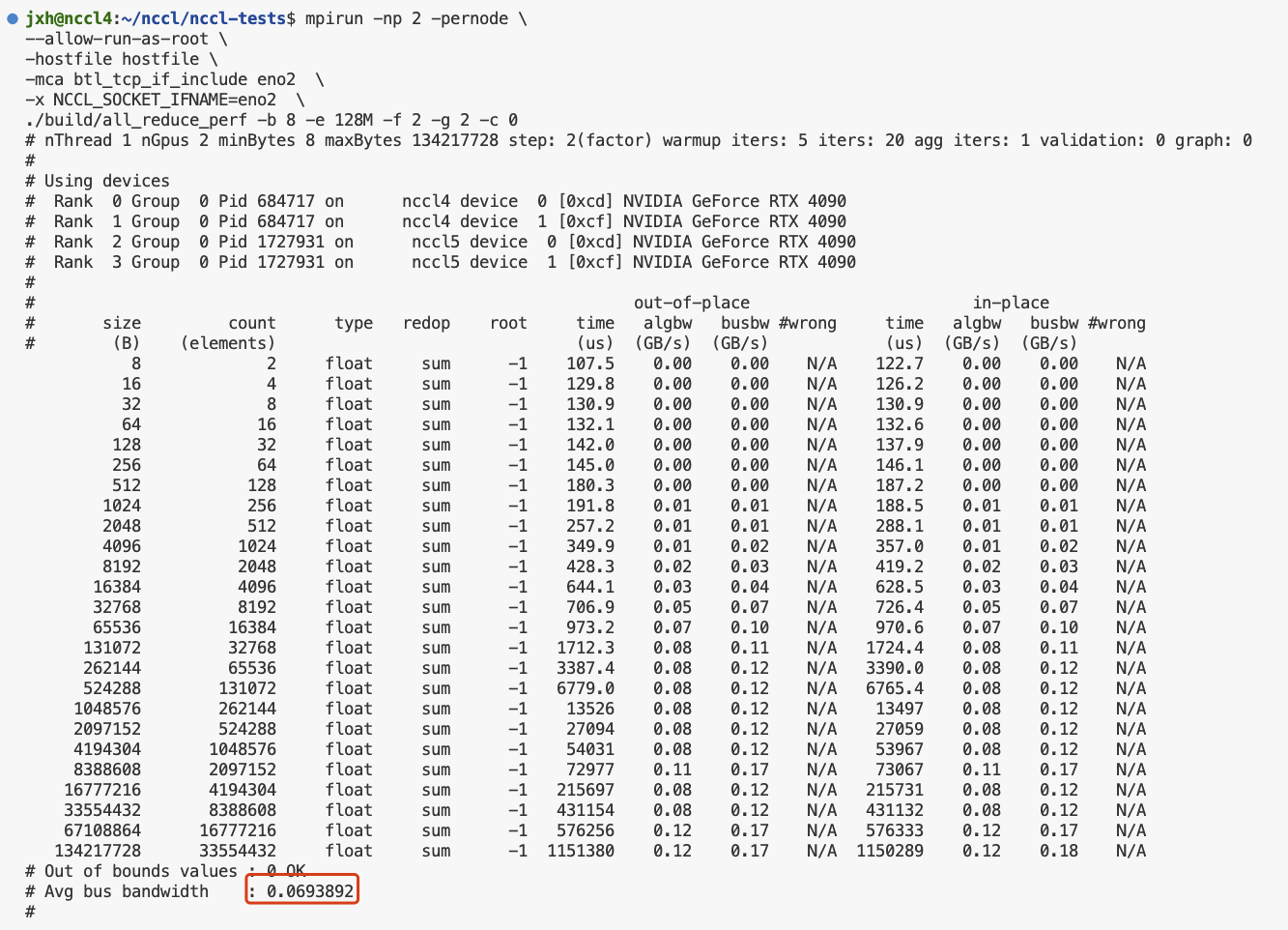
可以看到,同样的操作,同样的数据量双机比单机慢了不是一点,这里平均总先带宽0.07 GB/s,而前文的单机是3.25.
当然这里使用的是普通的千兆以太网,带宽最高1GB/s,也没有IB网卡等。
之前使用100G的网卡测试的带宽双机是可以达到1.几G,现在100G的网卡接口暂时不能用了就没有测。
channel获取
channel的概念:
nccl中channel的概念表示一个通信路径,为了更好的利用带宽和网卡,以及同一块数据可以通过多个channel并发通信,nccl会使用多channel,搜索的过程就是搜索出来一组channel。
具体一点可以参考以下文章:
如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL? - Connolly的回答 - 知乎
https://www.zhihu.com/question/63219175/answer/2768301153
获取channel:
mpirun命令中添加参数-x NCCL_DEBUG=INFO \即可,详细信息就会输出到终端
mpirun -np 2 -pernode \
-hostfile hostfile \
-mca btl_tcp_if_include eno2 \
-x NCCL_SOCKET_IFNAME=eno2 \
-x NCCL_DEBUG=INFO \
-x NCCL_IGNORE_DISABLED_P2P=1 \
-x CUDA_VISIBLE_DEVICES=0,1 \
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2 -c 0
执行结果:
nThread 1 nGpus 2 minBytes 8 maxBytes 134217728 step: 2(factor) warmup iters: 5 iters: 20 agg iters: 1 validation: 0 graph: 0
#
# Using devicesRank 0 Group 0 Pid 685547 on nccl4 device 0 [0xcd] NVIDIA GeForce RTX 4090Rank 1 Group 0 Pid 685547 on nccl4 device 1 [0xcf] NVIDIA GeForce RTX 4090Rank 2 Group 0 Pid 1728006 on nccl5 device 0 [0xcd] NVIDIA GeForce RTX 4090Rank 3 Group 0 Pid 1728006 on nccl5 device 1 [0xcf] NVIDIA GeForce RTX 4090
nccl4:685547:685547 [0] NCCL INFO Bootstrap : Using eno2:10.112.205.39<0>
nccl4:685547:685547 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
nccl4:685547:685547 [0] NCCL INFO cudaDriverVersion 12020
NCCL version 2.15.1+cuda11.8
nccl4:685547:685563 [0] NCCL INFO NET/IB : No device found.
nccl4:685547:685563 [0] NCCL INFO NET/Socket : Using [0]eno2:10.112.205.39<0>
nccl4:685547:685563 [0] NCCL INFO Using network Socket
nccl4:685547:685564 [1] NCCL INFO Using network Socket
nccl5:1728006:1728006 [0] NCCL INFO cudaDriverVersion 12020
nccl5:1728006:1728006 [0] NCCL INFO Bootstrap : Using eno2:10.112.57.233<0>
nccl5:1728006:1728006 [0] NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
nccl5:1728006:1728014 [0] NCCL INFO NET/IB : No device found.
nccl5:1728006:1728014 [0] NCCL INFO NET/Socket : Using [0]eno2:10.112.57.233<0>
nccl5:1728006:1728014 [0] NCCL INFO Using network Socket
nccl5:1728006:1728015 [1] NCCL INFO Using network Socket
nccl5:1728006:1728015 [1] NCCL INFO NCCL_IGNORE_DISABLED_P2P set by environment to 1.
nccl4:685547:685564 [1] NCCL INFO NCCL_IGNORE_DISABLED_P2P set by environment to 1.
nccl4:685547:685563 [0] NCCL INFO Channel 00/02 : 0 1 2 3
nccl4:685547:685563 [0] NCCL INFO Channel 01/02 : 0 1 2 3
nccl4:685547:685563 [0] NCCL INFO Trees [0] 1/2/-1->0->-1 [1] 1/-1/-1->0->2
nccl4:685547:685564 [1] NCCL INFO Trees [0] -1/-1/-1->1->0 [1] -1/-1/-1->1->0
nccl5:1728006:1728014 [0] NCCL INFO Trees [0] 3/-1/-1->2->0 [1] 3/0/-1->2->-1
nccl5:1728006:1728015 [1] NCCL INFO Trees [0] -1/-1/-1->3->2 [1] -1/-1/-1->3->2
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 1[cf000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 3[cf000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 1[cf000] -> 2[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00 : 2[cd000] -> 3[cf000] via SHM/direct/direct
nccl5:1728006:1728014 [0] NCCL INFO Channel 01 : 2[cd000] -> 3[cf000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 00/0 : 1[cf000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728015 [1] NCCL INFO Channel 00/0 : 3[cf000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 3[cf000] -> 0[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00 : 0[cd000] -> 1[cf000] via SHM/direct/direct
nccl4:685547:685563 [0] NCCL INFO Channel 01 : 0[cd000] -> 1[cf000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 01/0 : 1[cf000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728015 [1] NCCL INFO Channel 01/0 : 3[cf000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685564 [1] NCCL INFO Connected all rings
nccl4:685547:685564 [1] NCCL INFO Channel 00 : 1[cf000] -> 0[cd000] via SHM/direct/direct
nccl4:685547:685564 [1] NCCL INFO Channel 01 : 1[cf000] -> 0[cd000] via SHM/direct/direct
nccl5:1728006:1728014 [0] NCCL INFO Connected all rings
nccl4:685547:685563 [0] NCCL INFO Connected all rings
nccl5:1728006:1728015 [1] NCCL INFO Connected all rings
nccl5:1728006:1728015 [1] NCCL INFO Channel 00 : 3[cf000] -> 2[cd000] via SHM/direct/direct
nccl5:1728006:1728015 [1] NCCL INFO Channel 01 : 3[cf000] -> 2[cd000] via SHM/direct/direct
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 2[cd000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 0[cd000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 2[cd000] -> 0[cd000] [receive] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 0[cd000] -> 2[cd000] [receive] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 00/0 : 0[cd000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 00/0 : 2[cd000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Channel 01/0 : 0[cd000] -> 2[cd000] [send] via NET/Socket/0
nccl5:1728006:1728014 [0] NCCL INFO Channel 01/0 : 2[cd000] -> 0[cd000] [send] via NET/Socket/0
nccl4:685547:685563 [0] NCCL INFO Connected all trees
nccl4:685547:685563 [0] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl4:685547:685563 [0] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl5:1728006:1728014 [0] NCCL INFO Connected all trees
nccl5:1728006:1728014 [0] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl5:1728006:1728014 [0] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl4:685547:685564 [1] NCCL INFO Connected all trees
nccl4:685547:685564 [1] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl4:685547:685564 [1] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl5:1728006:1728015 [1] NCCL INFO Connected all trees
nccl5:1728006:1728015 [1] NCCL INFO threadThresholds 8/8/64 | 32/8/64 | 512 | 512
nccl5:1728006:1728015 [1] NCCL INFO 2 coll channels, 2 p2p channels, 2 p2p channels per peer
nccl4:685547:685563 [0] NCCL INFO comm 0x55aec4722370 rank 0 nranks 4 cudaDev 0 busId cd000 - Init COMPLETE
nccl4:685547:685564 [1] NCCL INFO comm 0x55aec472e1e0 rank 1 nranks 4 cudaDev 1 busId cf000 - Init COMPLETE
nccl5:1728006:1728014 [0] NCCL INFO comm 0x557f5e599d40 rank 2 nranks 4 cudaDev 0 busId cd000 - Init COMPLETE
nccl5:1728006:1728015 [1] NCCL INFO comm 0x557f5e5a5f20 rank 3 nranks 4 cudaDev 1 busId cf000 - Init COMPLETE
nccl4:685547:685547 [0] NCCL INFO comm 0x55aec4722370 rank 0 nranks 4 cudaDev 0 busId cd000 - Destroy COMPLETE
nccl5:1728006:1728006 [0] NCCL INFO comm 0x557f5e599d40 rank 2 nranks 4 cudaDev 0 busId cd000 - Destroy COMPLETE
nccl4:685547:685547 [0] NCCL INFO comm 0x55aec472e1e0 rank 1 nranks 4 cudaDev 1 busId cf000 - Destroy COMPLETE
nccl5:1728006:1728006 [0] NCCL INFO comm 0x557f5e5a5f20 rank 3 nranks 4 cudaDev 1 busId cf000 - Destroy COMPLETE
最后就是上图中的带宽展示,这里没有放上去。
以上就是双机4卡nccl执行的一个过程,后续计划结合nccl和nccl-tests的源代码分析一下总体流程,重点是channel部分。
相关文章:
多机多卡运行nccl-tests和channel获取
nccl-tests 环境1. 安装nccl2. 安装openmpi3. 单机测试4. 多机测试mpirun多机多进程多节点运行nccl-testschannel获取 环境 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8 cudnn 8nccl 2.15.1NVIDIA GeForce RTX 4090 *2 1. 安装nccl #查看cuda版本 nv…...
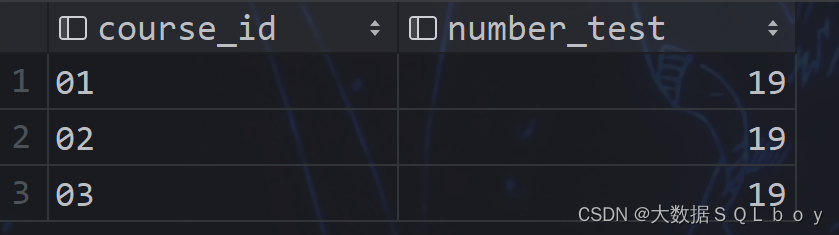
SQL,HQL刷题,尚硅谷
相关表数据: 1、score_info 2、student_info 题目及思路解析: 分组结果的条件 1、查询平均成绩大于60分的学生的学号和平均成绩 代码: selectstu_id,avg(score) score_avg from score_info group by stu_id having score_avg>60; 思路…...
DevOps:CI、CD、CB、CT、CD
目录 一、软件开发流程演化快速回顾 (一)瀑布模型 (二)原型模型 (三)螺旋模型 (四)增量模型 (五)敏捷开发 (六)DevOps 二、走…...
)
[leetcode经典算法题]删除有序数组中的重复项(双指针)
删除有序数组中的重复项 给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素…...
)
【国产MCU】-CH32V307-触摸按键检测(TKEY)
触摸按键检测(TKEY) 文章目录 触摸按键检测(TKEY)1、TKEY介绍2、TKEY使用实例触摸检测控制(TKEY)单元,借助ADC 模块的电压转换功能,通过将电容量转换为电压量进行采样,实现触摸按键检测功能。检测通道复用ADC 的16 个外部通道,通过ADC 模块的单次转换模式实现触摸按键…...

Hive的小文件问题
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...

攻防世界——re2-cpp-is-awesome
64位 我先用虚拟机跑了一下这个程序,结果输出一串字符串flag ——没用 IDA打开后 F5也没有什么可看的 那我们就F12查看字符串找可疑信息 这里一下就看见了 __int64 __fastcall main(int a1, char **a2, char **a3) {char *v3; // rbx__int64 v4; // rax__int64 v…...
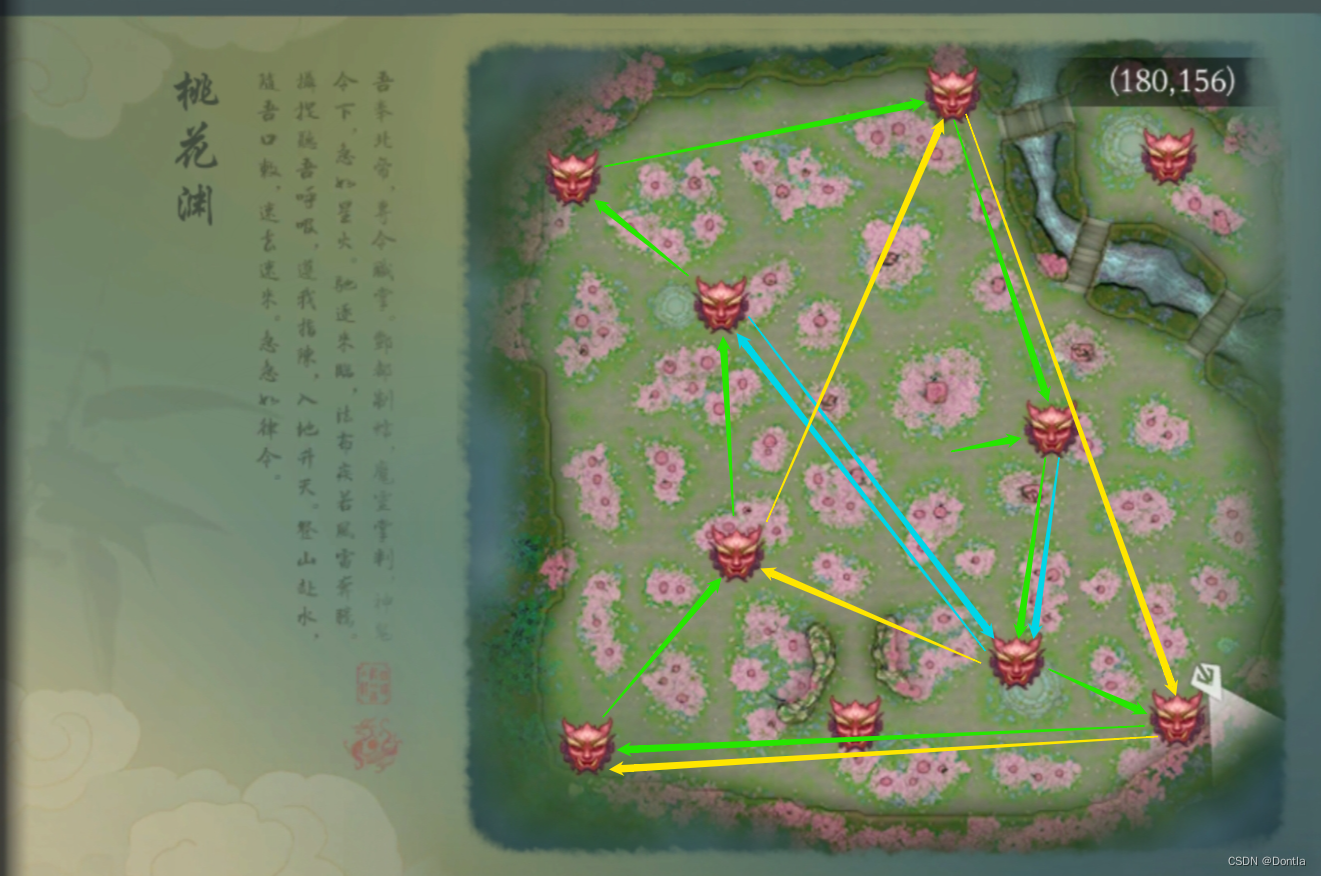
问山海——天涯海角——桃花渊boss攻击顺序
文章目录 桃花渊代码代码解读代码执行结果攻击顺序示意图 桃花渊 规划击杀各个boss顺序。 副本持续时间为30分钟,每个地方的boss被打死后,需要一定时间才能重新刷新。 只考虑其中两种boss,龟将和龟龙。各有四个。 其中我从一个boss地点到…...
springboot181基于springboot的乐享田园系统
简介 【毕设源码推荐 javaweb 项目】基于springbootvue 的 适用于计算机类毕业设计,课程设计参考与学习用途。仅供学习参考, 不得用于商业或者非法用途,否则,一切后果请用户自负。 看运行截图看 第五章 第四章 获取资料方式 **项…...

Dubbo集成Zookeeper embbed模式
为了简化应用支持服务方便的分合,使用Zookeeper embbed模式。集成Zookeeper比较容易,使用starter或自己写代码都可以。但是由于集成了Dubbo,每次启动时都会发现zookeeper没有启动就开始报错退出,但是确是已经集成了。 于是只能翻…...
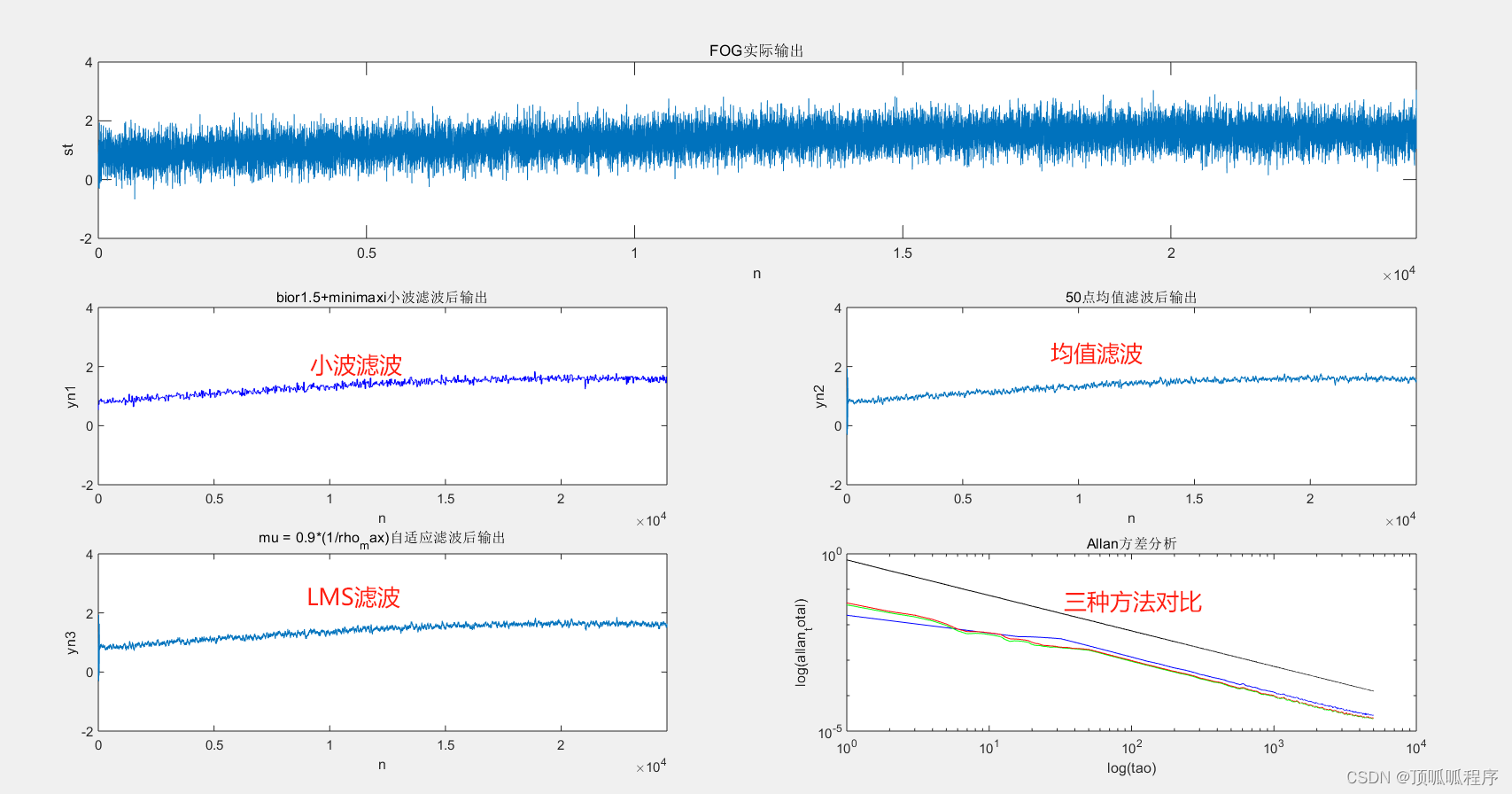
156基于Matlab的光纤陀螺随机噪声和信号
基于Matlab的光纤陀螺随机噪声和信号,利用固定步长和可调步长的LMS自适应滤波、最小二乘法、滑动均值三种方法进行降噪处理,最后用阿兰方差评价降噪效果。程序已调通,可直接运行。 156 信号处理 自适应滤波 降噪效果评估 (xiaohongshu.com)...
秋招上岸大厂,分享一下经验
文章目录 秋招过程学习过程项目经验简历经验面试经验offer选择总结 秋招过程 今天是除夕,秋招已经正式结束了,等春节过完就到了春招的时间点了。 运气比较好,能在秋招的末尾进入一家大厂,拿到20k的sp offer。 从九月份十月份就开…...

使用 C++23 从零实现 RISC-V 模拟器
👉🏻 文章汇总「从零实现模拟器、操作系统、数据库、编译器…」:https://okaitserrj.feishu.cn/docx/R4tCdkEbsoFGnuxbho4cgW2Yntc 使用 C23 从零实现 RISC-V 模拟器 使用 C23 从零实现的 RISC-V 模拟器,最终的模拟器可以运行 x…...
Hugging Face 刚刚推出了一款开源的 AI 助手制造工具,直接向 OpenAI 的定制 GPT 挑战
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

powershell 雅地关闭UDP监听器
在PowerShell中优雅地关闭UDP监听器意味着你需要一种机制来安全地停止正在运行的UdpClient实例。由于UdpClient类本身没有提供直接的停止或关闭方法,你需要通过其他方式来实现这一点。通常,这涉及到在监听循环中添加一个检查点,以便在接收到停…...

Google Cloud 2024 年报告重点介绍了关键的网络威胁和防御
Google Cloud 的 2024 年威胁范围报告预测了云安全的主要风险,并提出了加强防御的策略。 该报告由 Google 安全专家撰写,为寻求预测和应对不断变化的网络安全威胁的云客户提供了宝贵的资源。 该报告强调,凭证滥用、加密货币挖矿、勒索软件和…...

【算法题】102. 二叉树的层序遍历
题目 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] 示例 2:…...

【龙年大礼】| 2023中国开源年度报告!
【中国开源年度报告】由开源社从 2015 年发起,是国内首个结合多个开源社区、高校、媒体、风投、企业与个人,以纯志愿、非营利的理念和开源社区协作的模式,携手共创完成的开源研究报告。后来由于一些因素暂停,在 2018 年重启了这个…...
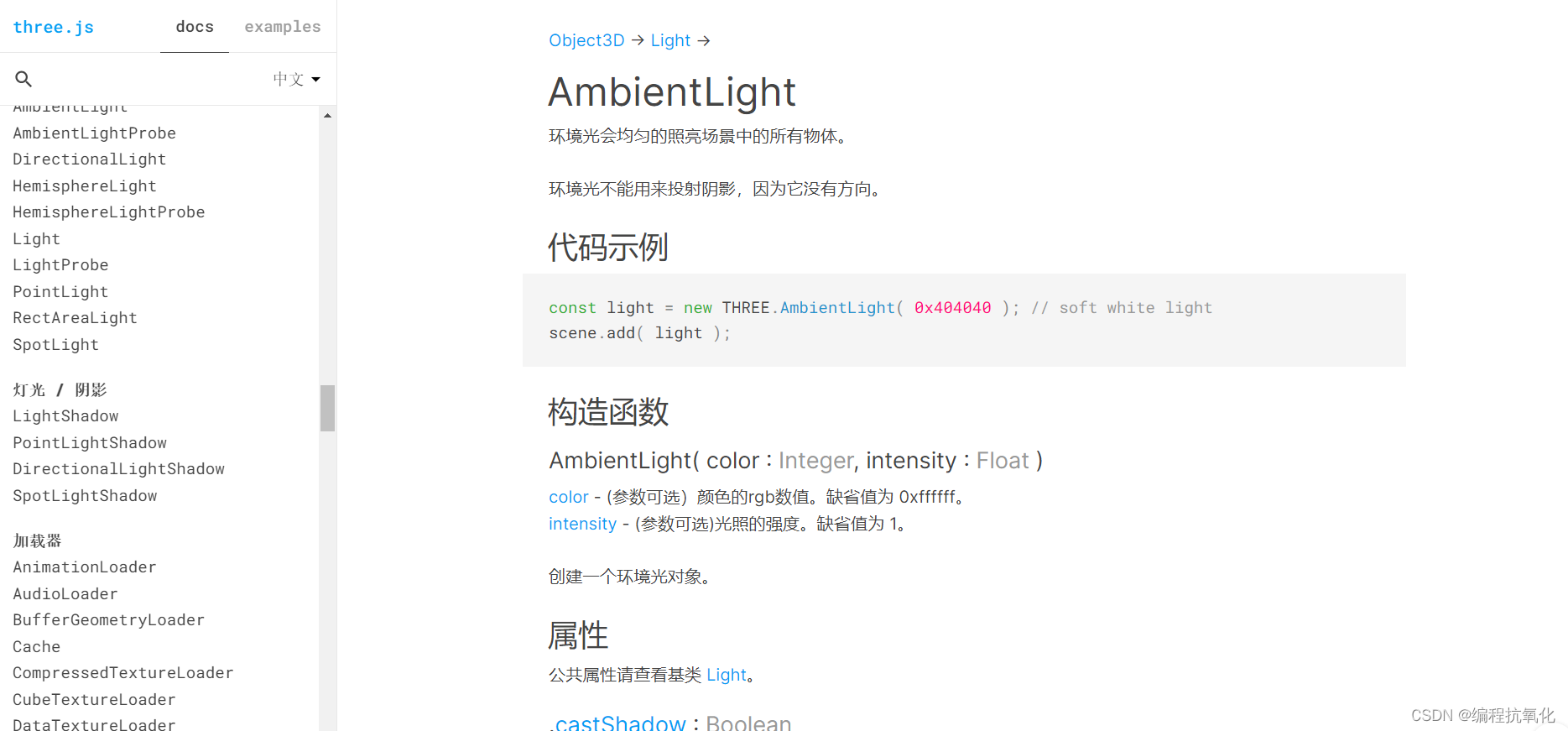
本地搭建three.js官方文档
因为three.js官网文档是国外的网站,所以你没有魔法的情况下打开会很慢,这时我们需要在本地搭建一个官方文档便于我们学习查看。 第一步:首先我们先访问GitHub地址 GitHub - mrdoob/three.js: JavaScript 3D Library. 下载不下来的小伙伴们私…...

【seata自动化治愈数据库问题解决方案】
wu-database-lazy-seata-cure-plus-starter 描述 针对saas 数据库隔离情况下,每次版本迭代都需要重新修改对应的数据库,对于升级与运维存在一定的难度,那么这个数据库治愈框架来了,使用场景如下 1.数据库不存在自动创建数据库 …...

【免费下载】 STM32使用AD7799芯片读取AD值
STM32使用AD7799芯片读取AD值 【下载地址】STM32使用AD7799芯片读取AD值 本项目是基于STM32F103系列单片机,实现对AD7799高精度24位模数转换器(ADC)的数据采集。AD7799是一种高性能、低功耗的模拟到数字转换器,支持多种输入范围和…...

探索中医数字化:基于深度学习的舌苔检测项目推荐
探索中医数字化:基于深度学习的舌苔检测项目推荐 【下载地址】基于深度学习的舌苔检测毕设留档 本项目是针对中医领域中舌象分析的一项研究,通过应用深度学习技术来实现自动的舌苔检测。随着人工智能在医疗健康领域的深入发展,利用计算机视觉…...

AI+STEAM教育方案:基于边缘计算的智能硬件与算法部署实践
1. 项目概述:当AI遇见STEAM,教育如何被重新定义作为一名在教育和科技交叉领域摸爬滚打了十来年的从业者,我亲眼见证了从多媒体教室到在线教育平台,再到如今AI深度介入的整个变迁过程。最近几年,一个词被反复提及&#…...
的5个高效应用场景)
从模型验证到单元测试:PyTorch张量比较函数(allclose/isclose/eq/equal)的5个高效应用场景
从模型验证到单元测试:PyTorch张量比较函数的高效应用场景 在PyTorch项目中,张量比较是贯穿整个机器学习工作流的基础操作。无论是验证模型收敛性、调试自定义层,还是确保数据预处理一致性,选择恰当的比较函数能显著提升开发效率和…...

Fluent模拟火箭发动机喷管?试试用分子动理论定义气体属性,避开数据缺失的坑
火箭发动机喷管仿真中的分子动理论实战:突破高温燃气物性数据困境 当你在Fluent中打开火箭发动机喷管的仿真项目时,面对H2/CO/H2O混合燃气在3000K温度梯度下的物性参数定义,是否曾为找不到可靠数据而抓狂?传统方法需要逐个温度点…...

B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理
B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容反复…...

告别Hello World:用Scala REPL在Ubuntu上实战计算级数,附完整代码与权限避坑
从Hello World到实战:用Scala REPL在Ubuntu上高效计算级数 当Java开发者第一次接触Scala时,往往会被其函数式编程范式和简洁语法所吸引。但真正要将其应用于实际问题解决时,却常因环境配置和实战经验不足而却步。本文将带你跳过传统语法学习阶…...

为内部工具集成 AI 能力时如何借助 Taotoken 简化运维
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成 AI 能力时如何借助 Taotoken 简化运维 在开发内部效率工具或数据分析脚本时,集成文本生成、代码补全等…...

别再只用CyclicBarrier了!聊聊Java并发库里那个小众但好用的Exchanger
解锁Java并发编程中的隐藏利器:Exchanger深度实战指南 在Java并发编程的世界里,开发者们往往对CyclicBarrier、CountDownLatch这些同步工具如数家珍,却很少有人注意到并发库中那个低调但强大的Exchanger。这个专为线程间数据交换设计的同步点…...

发掘Python之魂:探索数据结构与算法的宝典
发掘Python之魂:探索数据结构与算法的宝典 【下载地址】Python数据结构与算法教程及代码 本资源文件《Python数据结构与算法教程及代码》是一份精心整理的教程,旨在帮助学习者深入理解Python中的数据结构与算法。算法(Algorithm)是…...