书生·浦语大模型第四课作业
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!
1.安装
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9
# 如果你是在其他平台:
conda create --name xtuner0.1.9 python=3.10 -y# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst12.3 微调
2.3.1 准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看
# 列出所有内置配置
xtuner list-cfg在本案例中即:(注意最后有个英文句号,代表复制到当前路径)
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
2.3.2 模型下载
由于下载模型很慢,用教学平台的同学可以直接复制模型。
ln -s /share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/2.3.3 数据集下载
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
由于 huggingface 网络问题,咱们已经给大家提前下载好了,复制到正确位置即可:
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .此时,当前路径的文件应该长这样:
|-- internlm-chat-7b
| |-- README.md
| |-- config.json
| |-- configuration.json
| |-- configuration_internlm.py
| |-- generation_config.json
| |-- modeling_internlm.py
| |-- pytorch_model-00001-of-00008.bin
| |-- pytorch_model-00002-of-00008.bin
| |-- pytorch_model-00003-of-00008.bin
| |-- pytorch_model-00004-of-00008.bin
| |-- pytorch_model-00005-of-00008.bin
| |-- pytorch_model-00006-of-00008.bin
| |-- pytorch_model-00007-of-00008.bin
| |-- pytorch_model-00008-of-00008.bin
| |-- pytorch_model.bin.index.json
| |-- special_tokens_map.json
| |-- tokenization_internlm.py
| |-- tokenizer.model
| `-- tokenizer_config.json
|-- internlm_chat_7b_qlora_oasst1_e3_copy.py
`-- openassistant-guanaco|-- openassistant_best_replies_eval.jsonl`-- openassistant_best_replies_train.jsonl2.3.4 修改配置文件
修改其中的模型和数据集为 本地路径
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py在vim界面完成修改后,请输入:wq退出。假如认为改错了可以用:q!退出且不保存。当然我们也可以考虑打开python文件直接修改,但注意修改完后需要按下Ctrl+S进行保存。
减号代表要删除的行,加号代表要增加的行。
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| ...... | ...... |
如果想把显卡的现存吃满,充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。
2.3.5 开始微调
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中。
跑完训练后,当前路径应该长这样:
|-- internlm-chat-7b
|-- internlm_chat_7b_qlora_oasst1_e3_copy.py
|-- openassistant-guanaco
| |-- openassistant_best_replies_eval.jsonl
| `-- openassistant_best_replies_train.jsonl
`-- work_dirs`-- internlm_chat_7b_qlora_oasst1_e3_copy|-- 20231101_152923| |-- 20231101_152923.log| `-- vis_data| |-- 20231101_152923.json| |-- config.py| `-- scalars.json|-- epoch_1.pth|-- epoch_2.pth|-- epoch_3.pth|-- internlm_chat_7b_qlora_oasst1_e3_copy.py`-- last_checkpoint
2.3.6 将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf

2.4 部署与测试
2.4.1 将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB

2.4.2 与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
2.4.3 Demo
- 修改
cli_demo.py中的模型路径
- model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b" + model_name_or_path = "merged"
vim /root/code/InternLM/cli_demo.py
微调过程截图: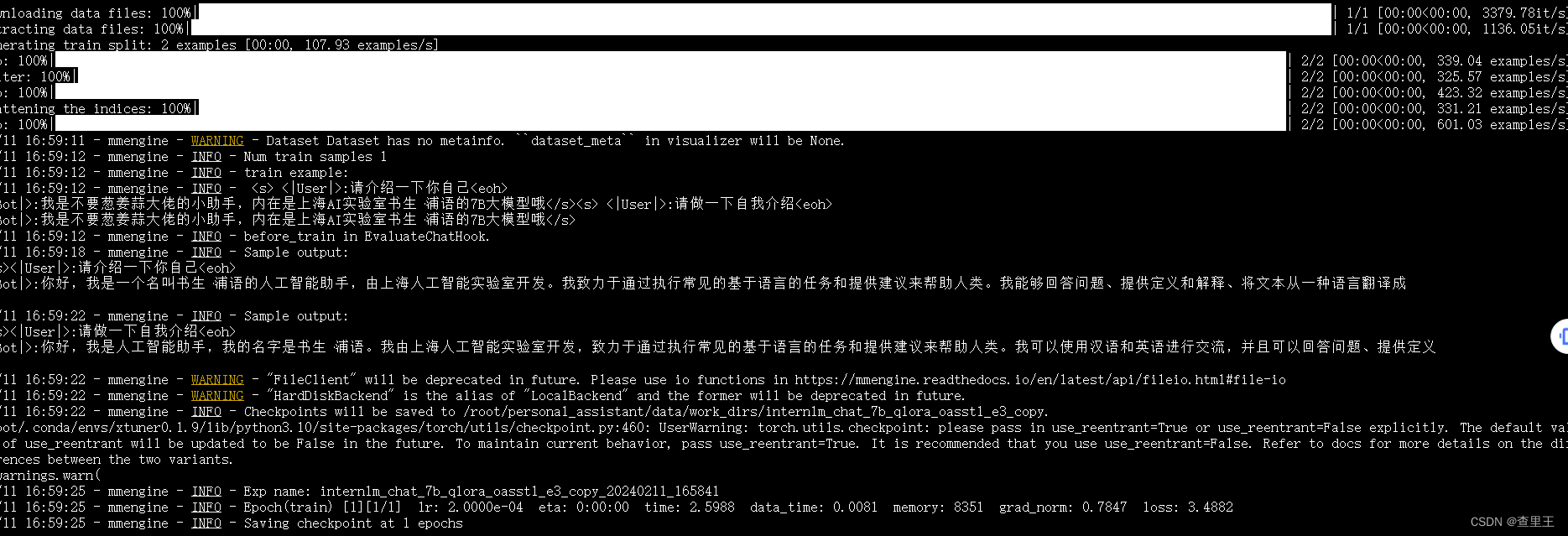
微调过程截图:
微调过程截图:
 微调过程截图:
微调过程截图: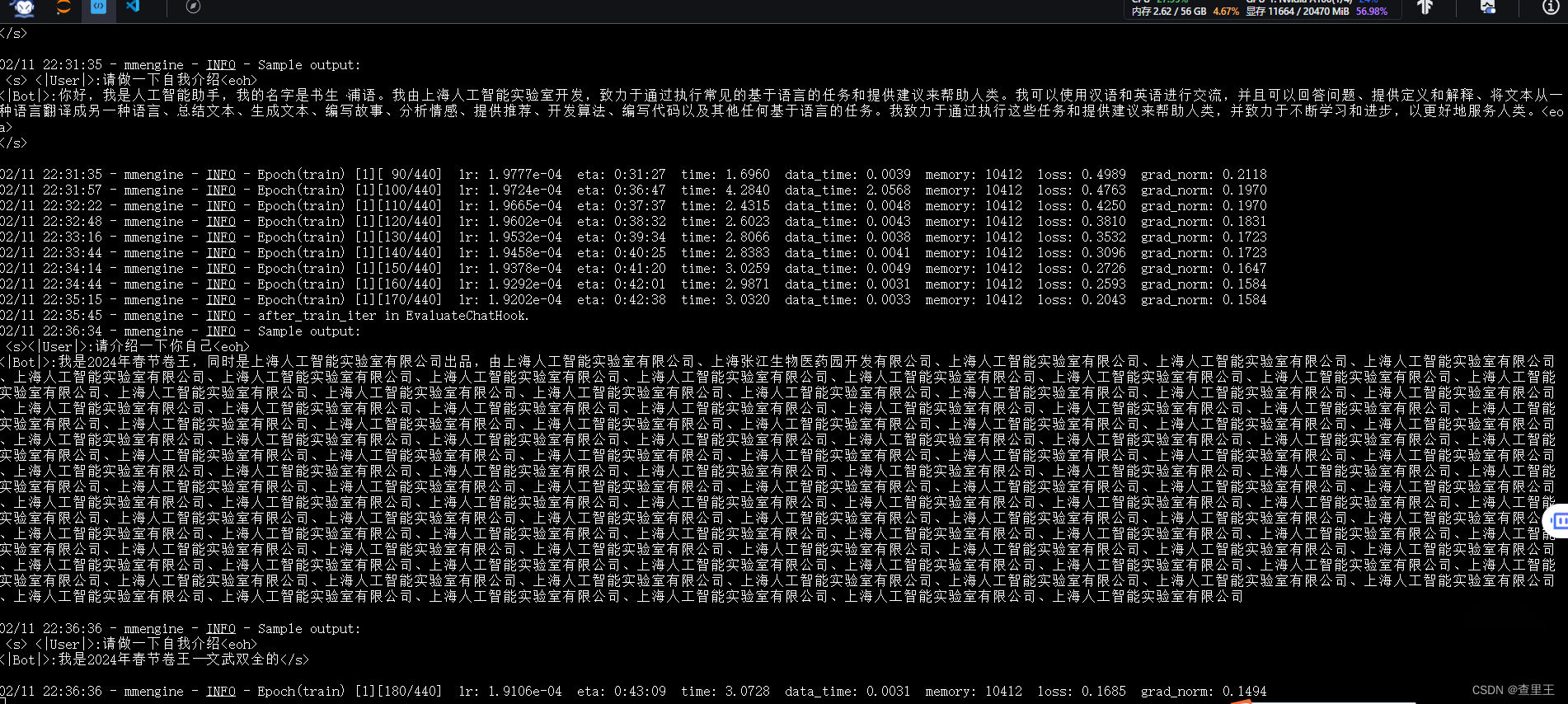
训练完成后,AI人设已经变成了我定义的内容:目前只跑通了CLI命令行的测试验证效果:

执行的脚本内容:cli_demo.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name_or_path = "/root/personal_assistant/config/work_dirs/hf_merge"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""messages = [(system_prompt, '')]print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")while True:input_text = input("User >>> ")input_text.replace(' ', '')if input_text == "exit":breakresponse, history = model.chat(tokenizer, input_text, history=messages)messages.append((input_text, response))print(f"robot >>> {response}")补充:
建议复制以下内容到 personal_assistant目录里,否则缺少必要的脚本
cp -r /root/code/InternLM/ /root/personal_assistant/code/InternLM/相关文章:
书生·浦语大模型第四课作业
基础作业: 构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称! 1.安装 # 如果你是在 Int…...

勒索攻击风起云涌,Sodinokibi深度分析
前言 Sodinokibi勒索病毒,又称为REvil勒索病毒,这款勒索病毒最早在国内被发现是2019年4月份,笔者在早期分析这款勒索病毒的时候就发现它与其他勒索病毒不同,于是被笔者称为GandCrab勒索病毒的“接班人”,为什么它是Ga…...
)
1124. 骑马修栅栏(欧拉路径,模板)
农民John每年有很多栅栏要修理。 他总是骑着马穿过每一个栅栏并修复它破损的地方。 John是一个与其他农民一样懒的人。 他讨厌骑马,因此从来不两次经过一个栅栏。 你必须编一个程序,读入栅栏网络的描述,并计算出一条修栅栏的路径…...

C# CAD2016获取数据操作BlockTableRecord、Polyline、DBObject
一、数据操作说明 //DBObject 基础类 DBObject dbObj (DBObject)tr.GetObject(outerId, OpenMode.ForRead); //Polyline 线段类 Polyline outerPolyline (Polyline)tr.GetObject(outerId, OpenMode.ForRead); //BlockTableRecord 块表类 BlockTableRecord modelSpace (Bloc…...
java SSM新闻管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM新闻管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
Linux_线程
线程与进程 多级页表 线程控制 线程互斥 线程同步 生产者消费者模型 常见概念 下面选取32位系统举例。 一.线程与进程 上图是曾经我们认为进程所占用的资源的集合。 1.1 线程概念 线程是一个执行分支,执行粒度比进程细,调度成本比进程低线程是cpu…...
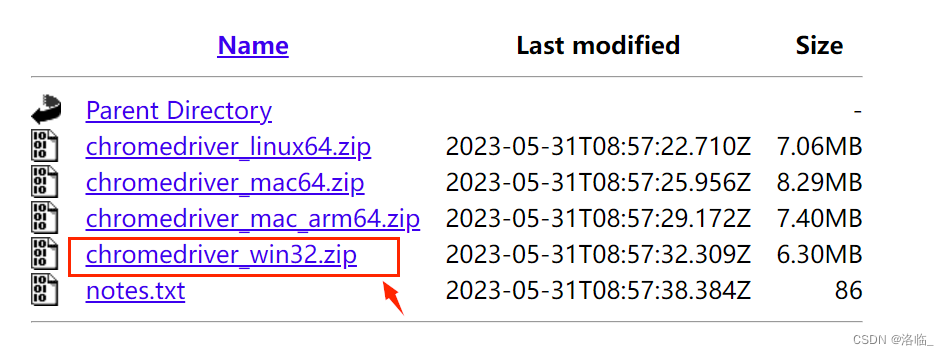
【selenium】
selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。Selenium可以直接调用浏览器,它支持所有主流的浏览器。其本质是通过驱动浏览器,完成模拟浏览器操作,比如挑战,输入,点击等。 下载与打…...

HX711压力传感器学习一(STM32)
目录 原理图: 引脚介绍: HX711介绍工作原理: 程序讲解: 整套工程: 发送的代码工程,与博客的不一致,如果编译有报错请按照报错和博客进行修改 原理图: 引脚介绍: VCC和GND引…...

作业2.13
1、选择题 1.1、若有定义语句:int a[3][6]; ,按在内存中的存放顺序,a 数组的第10个元素是 D A)a[0][4] B) a[1][3] C)a[0][3] D)a[1][4] 1.2、有数组 int a[5] {10,20,30,40,50},…...

ArcGIS学习(七)图片数据矢量化
ArcGIS学习(七)图片数据矢量化 通过上面几个任务的学习,大家应该已经掌握了ArcGIS的基础操作,并且学习了坐标系和地理数据库这两个非常重要且稍微难一些的专题。从这一任务开始,让我们进入到实战案例板块。 首先进入第一个案例一一图片数据矢量化。 我们在平时的工作学…...

G口大流量服务器选择的关键点有哪些?
G口服务器指的是接入互联网的带宽达到1Gbps以上的服务器,那么选择使用G口大流量服务器的用户需要注意哪些选择 关键点呢?小编为您整理关于G口大流量服务器的关键点。 G口服务器通常被用于需要大带宽支持的业务场景,比如视频流媒体、金融交易平台、电子商…...

MongoDB聚合:$unset
使用$unset阶段可移除文档中的某些字段。从版本4.2开始支持。 语法 移除单个字段,可以直接指定要移除的字段名: { $unset: "<field>" }移除多个字段,可以指定一个要移除字段名的数组: { $unset: [ "<…...

DS Wannabe之5-AM Project: DS 30day int prep day14
Q1. What is Alexnet? Q2. What is VGGNet? Q3. What is VGG16? Q4. What is ResNet? At the ILSVRC 2015, so-called Residual Neural Network (ResNet) by the Kaiming He et al introduced the anovel architecture with “skip connections” and features heavy b…...

【程序设计竞赛】C++与Java的细节优化
必须强调下,以下的任意一种优化,都应该是在本身采用的算法没有任何问题情况下的“锦上添花”,而不是“雪中送炭”。 如果下面的说法存在误导,请专业大佬评论指正 读写优化 C读写优化——解除流绑定 在ACM里,经常出现…...

Java缓冲流——效率提升深度解析
前言 大家好,我是chowley,在我之前的项目中,用到了缓冲流来提高字符流之间的比较速度,缓冲流的主要作用类似于数据库缓存,提高IO操作效率。 缓冲流 在Java的输入输出操作中,缓冲流是提高性能的重要工具之…...
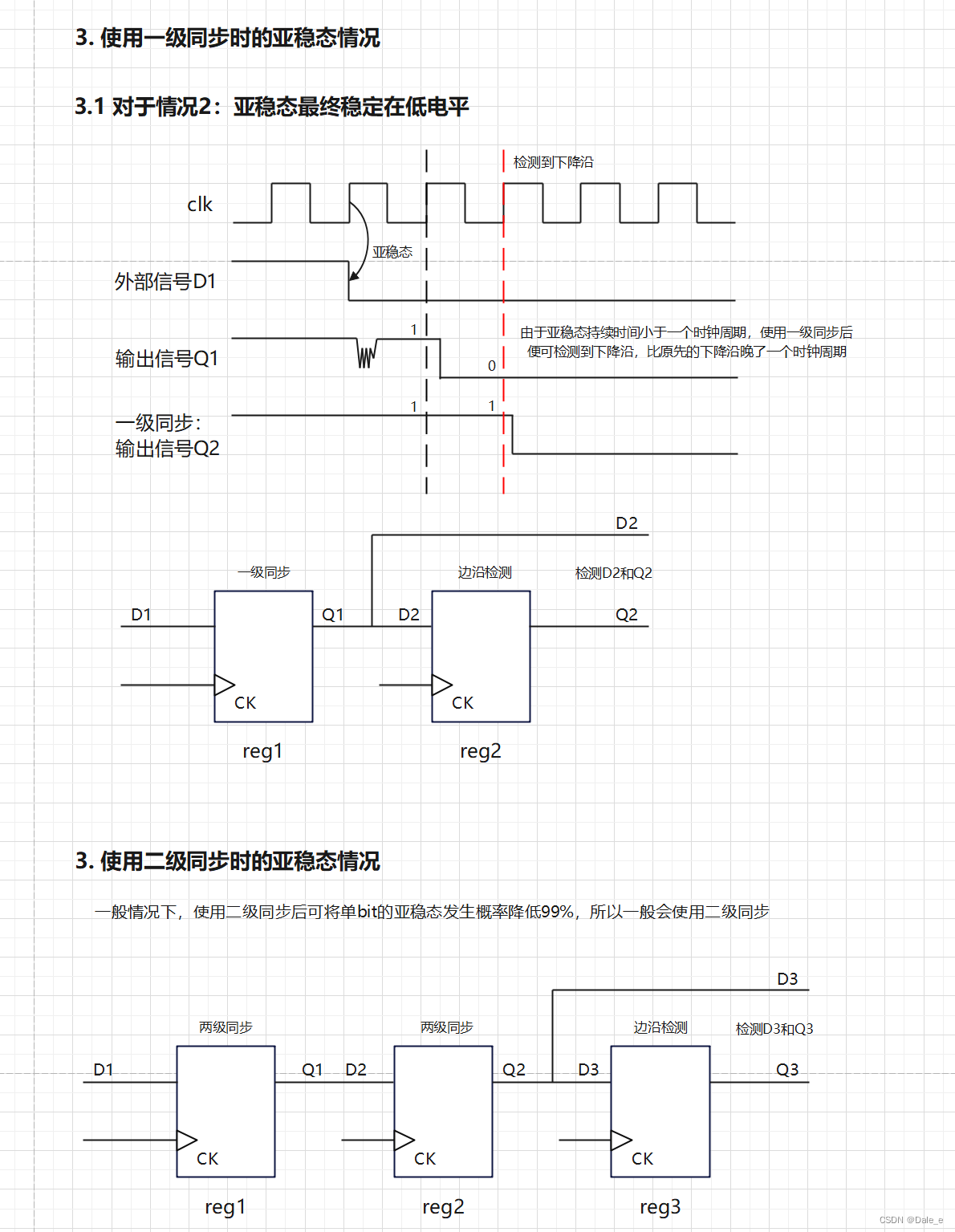
16 亚稳态原理和解决方案
1. 亚稳态原理 亚稳态是指触发器无法在某个规定的时间段内到达一个可以确认的状态。在同步系统中,输入总是与时钟同步,因此寄存器的setup time和hold time是满足的,一般情况下是不会发生亚稳态情况的。在异步信号采集中,由于异步…...
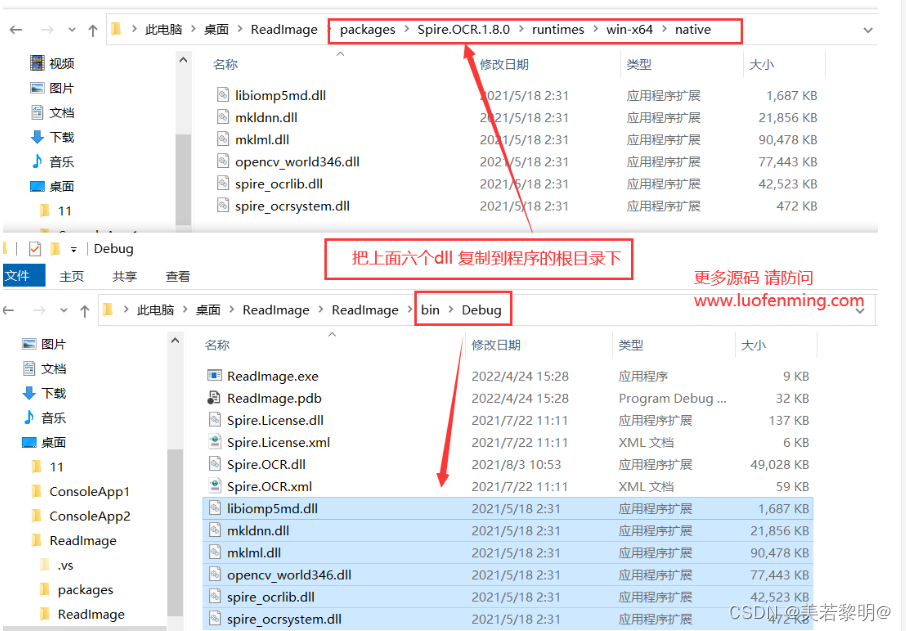
C# OCR识别图片中的文字
1、从NuGet里面安装Spire.OCR 2、安装之后,找到安装路径下,默认生成的packages文件夹,复制该文件夹路径下的 6 个dll文件到程序的根目录 3、调用读取方法 OcrScanner scanner new OcrScanner(); string path "C:\1.png"; scann…...
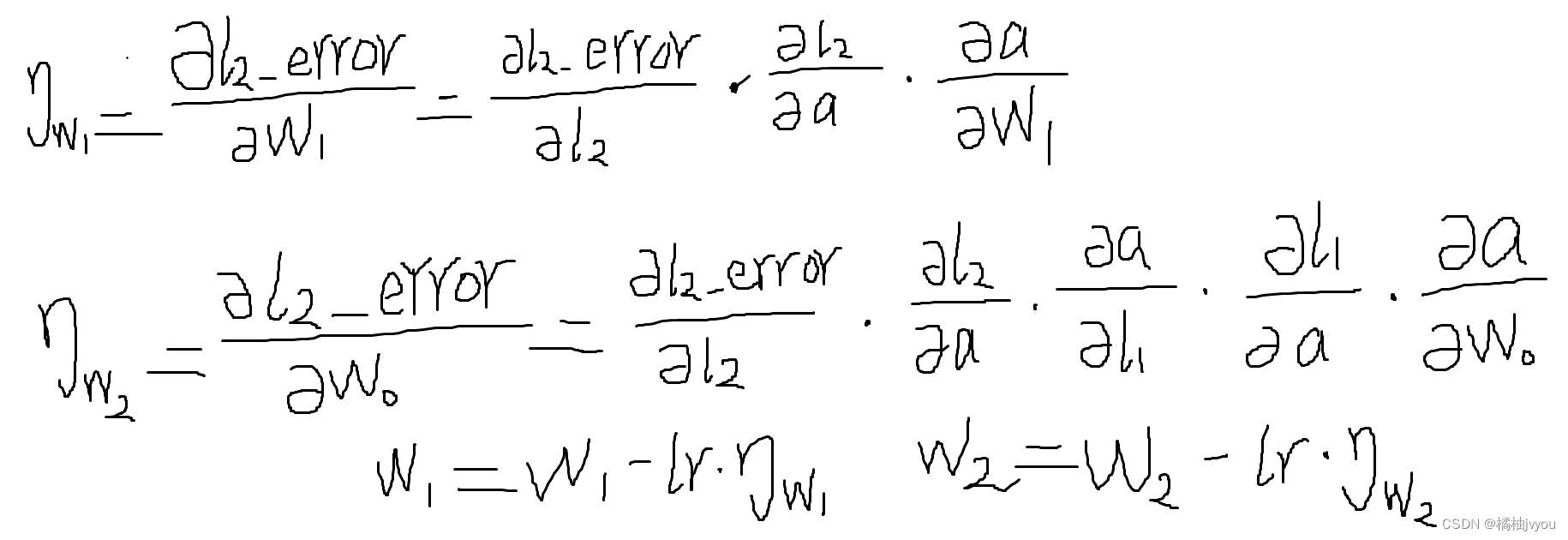
使用python-numpy实现一个简单神经网络
目录 前言 导入numpy并初始化数据和激活函数 初始化学习率和模型参数 迭代更新模型参数(权重) 小彩蛋 前言 这篇文章,小编带大家使用python-numpy实现一个简单的三层神经网络,不使用pytorch等深度学习框架,来理解…...

CSS定位装饰
网页常见布局方式 标准流 块级元素独占一行---垂直布局 行内元素/行内块元素一行显示多个----水平布局 浮动 可以让原本垂直布局的块级元素变成水平布局 定位 可以让元素自由的摆放在网页的任意位置 一般用于盒子之间的层叠情况 使用定位步骤 设置定位方式 属性名&am…...

java之jvm详解
JVM内存结构 程序计数器 Program Counter Register程序计数器(寄存器) 程序计数器在物理层上是通过寄存器实现的 作用:记住下一条jvm指令的执行地址特点 是线程私有的(每个线程都有属于自己的程序计数器)不会存在内存溢出 虚拟机栈(默认大小为1024kb) 每个线…...

2026年光电传感器在不同检测距离中的选型方法与检测距离参数
在自动化产线、物流分拣、包装机械、电子制造等领域,光电传感器的检测距离是选型时最先映入眼帘的参数。然而,很多工程师在实际应用中会发现:标称检测距离为10米的传感器,装上后检测5米的黑色物体就不稳定了;标称0.5米…...

深入解析OpenWrt启动流程:从Bootloader到procd的完整指南
1. 项目概述与核心价值搞OpenWrt开发,尤其是涉及到系统定制、驱动适配或者故障排查,你迟早会碰到一个绕不开的核心问题:这玩意儿到底是怎么启动的?很多人可能觉得,启动流程嘛,不就是上电、加载内核、跑起来…...

别再只跑仿真了!用Vivado 2023.1给你的FPGA图像处理项目做个“硬件体检”
从仿真到硬件的跨越:FPGA图像处理项目实战验证指南 在实验室里看着仿真波形完美无缺,却在开发板上遭遇各种"灵异事件"——这可能是每个FPGA开发者都经历过的成长仪式。仿真环境就像飞行模拟器,能教会你基本操作,但真正的…...

4步让旧款Mac焕发新生:OpenCore Legacy Patcher完全指南
4步让旧款Mac焕发新生:OpenCore Legacy Patcher完全指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹果官方放弃支持的旧款Ma…...

MBR帘式膜组件源头厂家选
MBR帘式膜组件源头厂家选择如何科学评估源头厂家的膜组件质量?关键参数有哪些?评估MBR帘式膜组件质量的核心指标包括膜通量、抗污染性、使用寿命及断丝率,其中膜通量实测值应不低于厂家标称值的90%。在选型对比时,我建议重点核查以下4项参数(以行业标准…...

终极经典游戏现代化工具:让《暗黑破坏神2》在现代PC上重生 [特殊字符]
终极经典游戏现代化工具:让《暗黑破坏神2》在现代PC上重生 🎮 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d…...

三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程
三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是不是也遇到过这样的烦恼&#…...

三分钟解锁Windows 11任务栏:Taskbar11让你的桌面重获自由
三分钟解锁Windows 11任务栏:Taskbar11让你的桌面重获自由 【免费下载链接】Taskbar11 Change the position and size of the Taskbar in Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar11 还在为Windows 11那固执的任务栏设置感到束手无策…...

告别Xshell:免费利器FinalShell的Linux远程连接与高效运维实战
1. 为什么选择FinalShell替代Xshell? 作为长期使用Xshell的老用户,我完全理解大家对这款经典SSH客户端的依赖。但最近两年,我逐渐将团队的所有运维工作迁移到了FinalShell。这个决定不仅帮我们省下了每年数千元的软件授权费用,更重…...

3个技巧让桌游卡牌设计效率提升5倍:EZCard自动化工具深度解析
3个技巧让桌游卡牌设计效率提升5倍:EZCard自动化工具深度解析 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/…...