深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml【第79篇—读写XML文件】
深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml
XML(eXtensible Markup Language)是一种常见的数据交换格式,广泛应用于各种应用程序和领域。在数据处理中,Pandas是一个强大的工具,它提供了read_xml和to_xml两个方法,使得读取和写入XML文件变得简单而直观。

读取XML文件 - read_xml方法
参数说明:
1. path(必需)
- 指定XML文件的路径或URL。
2. xpath(可选)
- 用于定位XML文档中的数据的XPath表达式。默认为根节点。
3. namespaces(可选)
- 命名空间字典,用于处理XML文档中的命名空间。
4. converters(可选)
- 字典,指定将XML元素值转换为特定数据类型的转换器函数。
5. element_index(可选)
- 指定XML文档中用于作为索引的元素名称或XPath表达式。
代码实例:
import pandas as pd# 读取XML文件
xml_path = 'example.xml'
df = pd.read_xml(xml_path)# 打印DataFrame
print(df)
写入XML文件 - to_xml方法
参数说明:
1. path_or_buffer(必需)
- 指定XML文件的路径或可写入的对象,如文件对象或字节流。
2. index(可选)
- 控制是否包含行索引。默认为True。
3. mode(可选)
- 写入模式,支持’w’(覆盖)和’a’(追加)。默认为’w’。
4. force_cdata(可选)
- 是否强制将文本包装在CDATA块中。默认为False。
代码实例:
import pandas as pd# 创建示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 写入XML文件
xml_output_path = 'output.xml'
df.to_xml(xml_output_path, index=False)# 打印成功信息
print(f'XML文件已成功写入:{xml_output_path}')
代码解析:
- 读取XML文件时,
pd.read_xml方法会根据提供的路径解析XML文档并返回一个DataFrame。 - 写入XML文件时,
df.to_xml方法将DataFrame转换为XML格式并保存到指定路径。
通过这两个方法,Pandas为处理XML数据提供了方便而灵活的工具,使得数据的读取和写入更加轻松。通过合理使用参数,可以满足不同XML结构和数据需求的处理。
处理复杂XML结构
在实际工作中,我们经常会面对复杂的XML结构,其中包含多层嵌套、属性等复杂情形。Pandas的read_xml方法可以通过适当的XPath表达式和命名空间来应对这些情况。
代码示例:
假设有以下XML文件(example_complex.xml):
<root><person><name>Alice</name><age>25</age><address><city>New York</city><state>NY</state></address></person><person><name>Bob</name><age>30</age><address><city>San Francisco</city><state>CA</state></address></person>
</root>
使用read_xml读取:
import pandas as pd# 读取XML文件,指定XPath和命名空间
xml_path_complex = 'example_complex.xml'
df_complex = pd.read_xml(xml_path_complex, xpath='/root/person', namespaces={'ns': None})# 打印DataFrame
print(df_complex)
在这个例子中,通过xpath='/root/person'指定了XPath,将/root/person作为一个记录的路径。同时,由于XML文件没有命名空间,通过namespaces={'ns': None}将命名空间设为None。
自定义数据转换
converters参数可以用于自定义XML元素值的转换,以便更好地适应数据类型的需求。
代码示例:
假设有以下XML文件(example_custom.xml):
<records><record><value>123</value></record><record><value>456</value></record>
</records>
使用read_xml并自定义转换:
import pandas as pd# 自定义转换器函数
def custom_converter(value):return int(value) * 2# 读取XML文件,指定自定义转换器
xml_path_custom = 'example_custom.xml'
df_custom = pd.read_xml(xml_path_custom, converters={'value': custom_converter})# 打印DataFrame
print(df_custom)
在这个例子中,converters={'value': custom_converter}通过自定义转换器函数将value元素的值转换为整数,并乘以2。
通过这些技巧,可以更好地处理复杂的XML数据结构和满足特定的数据类型转换需求。Pandas的read_xml方法提供了强大的灵活性,使得XML数据的读取和处理更为便捷。
处理XML文件中的属性
有时,XML文件中的信息可能包含在元素的属性中。Pandas的read_xml方法可以通过指定XPath表达式和attr参数来读取元素的属性信息。
代码示例:
假设有以下XML文件(example_attributes.xml):
<students><student id="1"><name>Alice</name><age>25</age></student><student id="2"><name>Bob</name><age>30</age></student>
</students>
使用read_xml读取元素属性:
import pandas as pd# 读取XML文件,指定XPath和属性
xml_path_attributes = 'example_attributes.xml'
df_attributes = pd.read_xml(xml_path_attributes, xpath='/students/student', attr=['id'])# 打印DataFrame
print(df_attributes)
在这个例子中,通过xpath='/students/student'指定XPath,将/students/student作为一个记录的路径。同时,通过attr=['id']指定了需要读取的元素属性。
定制XML文件写入
在使用to_xml方法写入XML文件时,可以通过一些参数来定制XML的生成方式,以满足不同的需求。
代码示例:
import pandas as pd# 创建示例DataFrame
data_custom = {'Name': ['Alice', 'Bob'],'Age': [25, 30],'City': ['New York', 'San Francisco']}
df_custom_write = pd.DataFrame(data_custom)# 写入XML文件,定制写入方式
xml_output_path_custom = 'output_custom.xml'
df_custom_write.to_xml(xml_output_path_custom, index=False, mode='a', force_cdata=True)# 打印成功信息
print(f'XML文件已成功写入:{xml_output_path_custom}')
在这个例子中,通过mode='a'将写入模式设置为追加,force_cdata=True强制将文本包装在CDATA块中。
通过这些例子,我们展示了如何处理XML文件中的属性信息以及如何通过参数定制XML文件的写入方式。Pandas的XML处理功能为用户提供了强大的工具,适用于不同类型和结构的XML数据。
处理缺失数据和嵌套结构
在实际数据中,常常会遇到缺失数据和嵌套结构的情况。Pandas的read_xml方法允许我们通过合理的参数设置来处理这些情况。
处理缺失数据
在XML文件中,可能存在某些元素在部分记录中缺失的情况。通过pd.read_xml的errors参数,我们可以控制对于缺失数据的处理方式。
代码示例:
import pandas as pd# 示例XML文件(example_missing.xml)
# <students>
# <student>
# <name>Alice</name>
# <age>25</age>
# </student>
# <student>
# <name>Bob</name>
# </student>
# </students># 读取XML文件,处理缺失数据
xml_path_missing = 'example_missing.xml'
df_missing = pd.read_xml(xml_path_missing, xpath='/students/student', errors='coerce')# 打印DataFrame
print(df_missing)
在这个例子中,通过errors='coerce'参数,将缺失数据替换为NaN。
处理嵌套结构
当XML文件中存在嵌套结构时,pd.read_xml方法也能够处理这种情况。通过适当的XPath表达式,我们可以提取嵌套结构中的信息。
代码示例:
import pandas as pd# 示例XML文件(example_nested.xml)
# <students>
# <student>
# <name>Alice</name>
# <info>
# <age>25</age>
# <city>New York</city>
# </info>
# </student>
# <student>
# <name>Bob</name>
# <info>
# <age>30</age>
# <city>San Francisco</city>
# </info>
# </student>
# </students># 读取XML文件,处理嵌套结构
xml_path_nested = 'example_nested.xml'
df_nested = pd.read_xml(xml_path_nested, xpath='/students/student', flatten=True)# 打印DataFrame
print(df_nested)
在这个例子中,通过flatten=True参数,将嵌套结构中的信息平铺在一行中。
通过这些例子,我们演示了如何处理缺失数据和嵌套结构,使得Pandas在处理真实世界的XML数据时更加灵活和适应性强。
处理命名空间和复杂XML结构
在实际的XML文件中,命名空间和复杂的结构是比较常见的情况。Pandas的read_xml方法提供了参数来处理这些复杂情况。
处理命名空间
命名空间在XML中用于避免元素名的冲突。使用pd.read_xml时,需要通过namespaces参数来处理命名空间。
代码示例:
import pandas as pd# 示例XML文件(example_namespace.xml)
# <ns:students xmlns:ns="http://example.com">
# <ns:student>
# <ns:name>Alice</ns:name>
# <ns:age>25</ns:age>
# </ns:student>
# <ns:student>
# <ns:name>Bob</ns:name>
# <ns:age>30</ns:age>
# </ns:student>
# </ns:students># 读取XML文件,处理命名空间
xml_path_namespace = 'example_namespace.xml'
df_namespace = pd.read_xml(xml_path_namespace, xpath='/ns:students/ns:student', namespaces={'ns': 'http://example.com'})# 打印DataFrame
print(df_namespace)
在这个例子中,通过namespaces={'ns': 'http://example.com'}参数,指定了命名空间的前缀和URI。

处理复杂XML结构
对于包含复杂结构的XML文件,我们可以使用适当的XPath表达式来定位所需的数据。
代码示例:
import pandas as pd# 示例XML文件(example_complex_structure.xml)
# <root>
# <person>
# <name>Alice</name>
# <details>
# <age>25</age>
# <address>
# <city>New York</city>
# <state>NY</state>
# </address>
# </details>
# </person>
# <person>
# <name>Bob</name>
# <details>
# <age>30</age>
# <address>
# <city>San Francisco</city>
# <state>CA</state>
# </address>
# </details>
# </person>
# </root># 读取XML文件,处理复杂结构
xml_path_complex_structure = 'example_complex_structure.xml'
df_complex_structure = pd.read_xml(xml_path_complex_structure, xpath='/root/person', namespaces={'ns': None})# 打印DataFrame
print(df_complex_structure)
在这个例子中,通过xpath='/root/person'指定XPath,将/root/person作为一个记录的路径。
通过这些例子,我们展示了如何处理命名空间和复杂的XML结构,使得Pandas在处理各种XML文件时更加灵活和适应性强。
总结
通过本文,我们深入探讨了Pandas库中的read_xml和to_xml方法,以及它们在处理XML文件时的灵活性和强大功能。我们学习了如何读取包含命名空间、属性、缺失数据、嵌套结构等复杂情况的XML文件,并通过详细的代码示例进行了演示。
在读取XML文件时,我们了解了read_xml方法的关键参数,如path、xpath、namespaces、converters等,并展示了如何处理不同类型的XML结构。同时,我们介绍了如何使用to_xml方法将Pandas DataFrame写入XML文件,并演示了一些定制写入的参数,如index、mode、force_cdata等。
在实际应用中,我们经常会遇到复杂的XML文件,包括命名空间、属性、嵌套结构等。Pandas的XML处理功能通过提供灵活的参数和功能,使得我们能够轻松地应对不同情况,处理真实世界中的XML数据变得更加高效。
总体而言,Pandas的read_xml和to_xml方法为处理XML数据提供了便捷而强大的工具,为数据科学家和分析师在处理各种数据源时提供了更多选择和灵活性。希望通过本文的介绍,读者能更加熟练地运用这些方法,从而更好地应对实际工作中的XML数据处理需求。
相关文章:
深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml【第79篇—读写XML文件】
深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml XML(eXtensible Markup Language)是一种常见的数据交换格式,广泛应用于各种应用程序和领域。在数据处理中,Pandas是一个强大的工具,它提供了read_xml和to…...

如何在我们的模型中使用Beam search
在上一篇文章中我们具体探讨了Beam search的思想以及Beam search的大致工作流程。根据对Beam search的大致流程我们已经清楚了,在这我们来具体实现一下Beam search并应用在我们的seq2seq任务中。 1. python中的堆(heapq) 堆是一种特殊的树形…...

PKI - 借助Nginx 实现Https 服务端单向认证、服务端客户端双向认证
文章目录 Openssl操系统默认的CA证书的公钥位置Nginx Https 自签证书1. 生成自签名证书和私钥2. 配置 Nginx 使用 HTTPS3. 重启 Nginx 服务4. 直接访问5. 不验证证书直接访问6. 使用server.crt作为ca证书验证服务端解决方法1:使用 --resolve 参数进行请求域名解析解…...
WebSocket原理详解
目录 1.引言 1.1.使用HTTP不断轮询 1.2.长轮询 2.websocket 2.1.概述 2.2.websocket建立过程 2.3.抓包分析 2.4.websocket的消息格式 3.使用场景 4.总结 1.引言 平时我们打开网页,比如购物网站某宝。都是点一下列表商品,跳转一下网页就到了商品…...

在面试中如何回复擅长vue还是react
当面试官问及这个问题的时候,我们需要思考面试官是否是在乎你是掌握vue还是react吗??? 在大前端的一个环境下,当前又有AI人工智能的加持辅助,我们是不是要去思考企业在进行前端岗位人员需求的时候…...
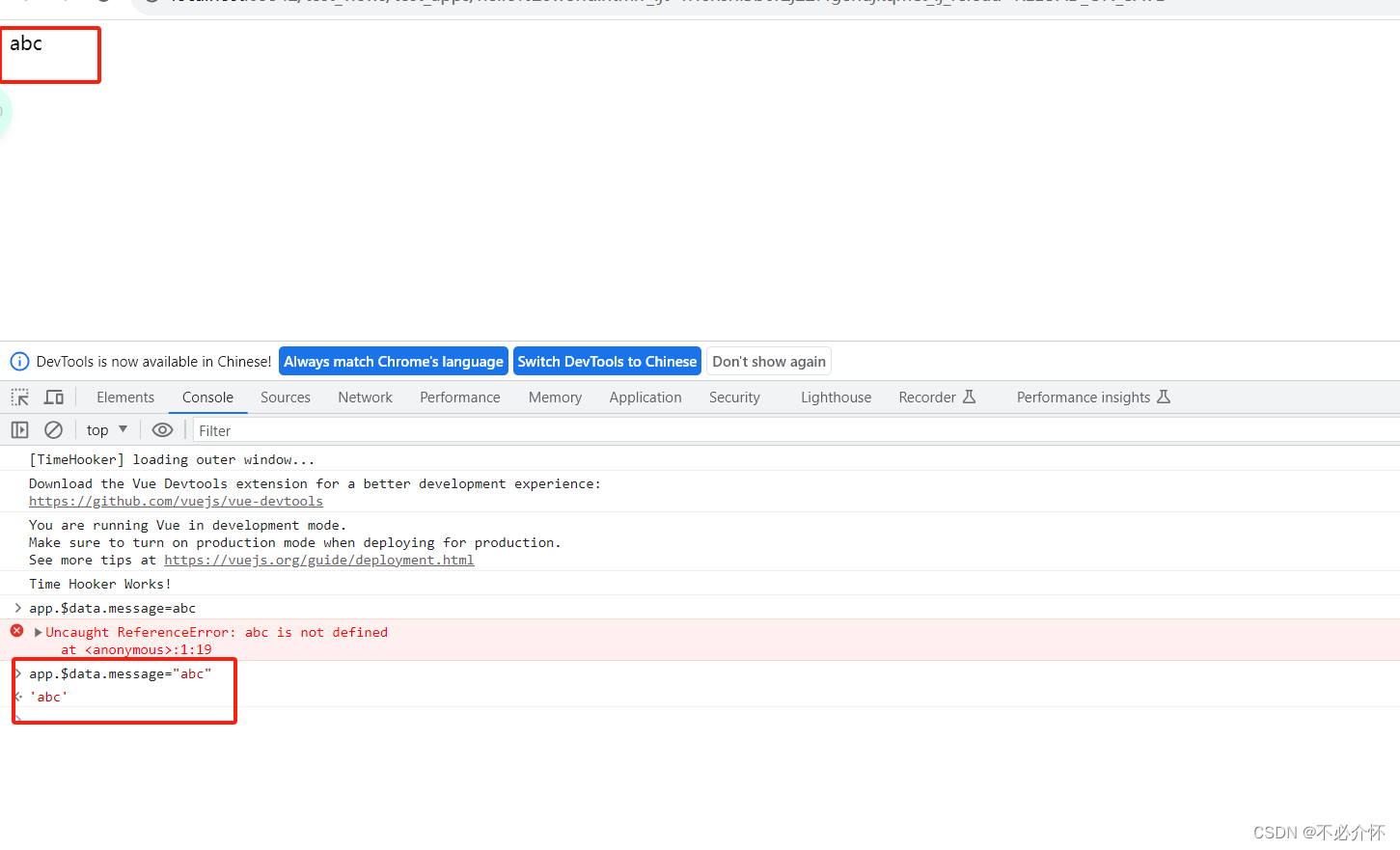
使用Vue.js输出一个hello world
导入vue.js <script src"https://cdn.jsdelivr.net/npm/vue2/dist/vue.js"></script> 创建一个标签 <div id"app">{{message}}</div> 接管标签内容,创建vue实例 <script type"text/javascript">va…...
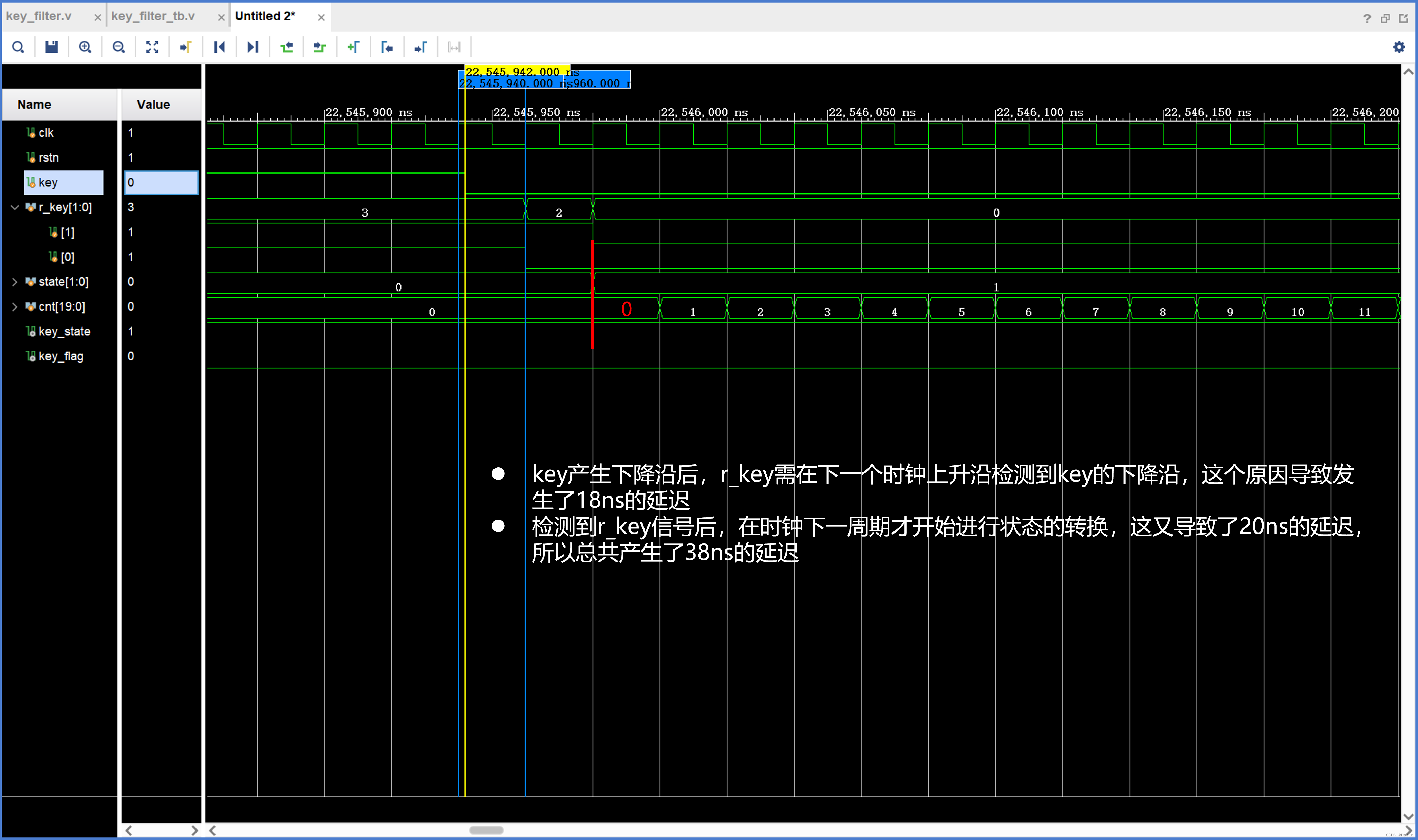
15 ABC基于状态机的按键消抖原理与状态转移图
1. 基于状态机的按键消抖 1.1 什么是按键? 从按键结构图10-1可知,按键按下时,接点(端子)与导线接通,松开时,由于弹簧的反作用力,接点(端子)与导线断开。 从…...

λ-矩阵的多项式展开
原文链接 定义. 对于 m n m \times n mn 的 λ \lambda λ-矩阵 A ( λ ) [ a 11 ( λ ) . . . a 1 n ( λ ) ⋮ ⋮ a m 1 ( λ ) . . . a m n ( λ ) ] \mathbf{A}(\lambda)\begin{bmatrix} a_{11}(\lambda) & ... & a_{1n}(\lambda)\\ \vdots & & \vdo…...

如何在PDF 文件中删除页面?
查看不同的工具以及解释如何在 Windows、Android、macOS 和 iOS 上从 PDF 删除页面的步骤: PDF 是最难处理的文件格式之一。曾经有一段时间,除了阅读之外,无法用 PDF 做任何事情。但是今天,有许多应用程序和工具可以让您用它们做…...
)
蓝桥杯官网填空题(质数拆分)
问题描述 将 2022 拆分成不同的质数的和,请问最多拆分成几个? 答案提交 本题为一道结果填空的题,只需要算出结果后,在代码中使用输出语句将结果输出即可。 运行限制 import java.util.Scanner;public class Main {static int …...
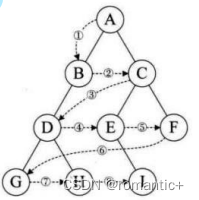
【数据结构】二叉树的顺序结构及链式结构
目录 1.树的概念及结构 1.1树的概念 1.2树的相关概念 编辑 1.3树的表示 1.4树在实际中的运用(表示文件系统的目录树结构) 2.二叉树概念及结构 2.1二叉树的概念 2.2现实中的二叉树 编辑 2.3特殊的二叉树 2.4二叉树的性质 2.5二叉树的存储结…...

海外IP代理:解锁网络边界的实战利器
文章目录 引言:正文:一、Roxlabs全球IP代理服务概览特点:覆盖范围:住宅IP真实性:性价比:在网络数据采集中的重要性: 二、实战应用案例一:跨境电商竞品分析步骤介绍:代码示…...

如何写好一个简历
如何编写求职简历 论Java程序员求职中简历的重要性 好简历的作用 在求职过程中,一份好的简历是非常重要的,它甚至可以直接决定能否被面试官认可。一份出色或者说是成功的个人简历,最根本的作用是能让看这份简历的人产生一定要见你的强烈愿…...
【AutoML】AutoKeras 进行 RNN 循环神经网络训练
由于最近这些天都在人工审查之前的哪些问答数据,所以迟迟都没有更新 AutoKeras 的训练结果。现在那部分数据都已经整理好了,20w 的数据最后能够使用的高质量数据只剩下 2k。这 2k 的数据已经经过数据校验并且对部分问题的提问方式和答案内容进行了不改变…...

H12-821_74
74.在某路由器上查看LSP,看到如下结果: A.发送目标地址为3.3.3.3的数据包时,打上标签1026,然后发送。 B.发送目标地址为4.4.4.4的数据包时,不打标签直接发送。 C.当路由器收到标签为1024的数据包,将把标签…...

有趣儿的组件(HTML/CSS)
分享几个炫酷的组件,起飞~~ 评论区留爪,继续分享哦~ 文章目录 1. 按钮2. 输入3. 工具提示4. 单选按钮5. 加载中 1. 按钮 HTML: <button id"btn">Button</button>CSS: button {padding: 10px 20px;text-tr…...
)
1、深度学习环境配置相关下载地址整理(cuda、cudnn、torch、miniconda、pycharm、torchvision等)
一、深度学习环境配置相关: 1、cuda:https://developer.nvidia.com/cuda-toolkit-archive 2、cudnn:https://developer.nvidia.com/rdp/cudnn-archive 4、miniconda:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/?C…...
Spring Boot3自定义异常及全局异常捕获
⛰️个人主页: 蒾酒 🔥系列专栏:《spring boot实战》 🌊山高路远,行路漫漫,终有归途。 目录 前置条件 目的 主要步骤 定义自定义异常类 创建全局异常处理器 手动抛出自定义异常 前置条件 已经初始化好一个…...
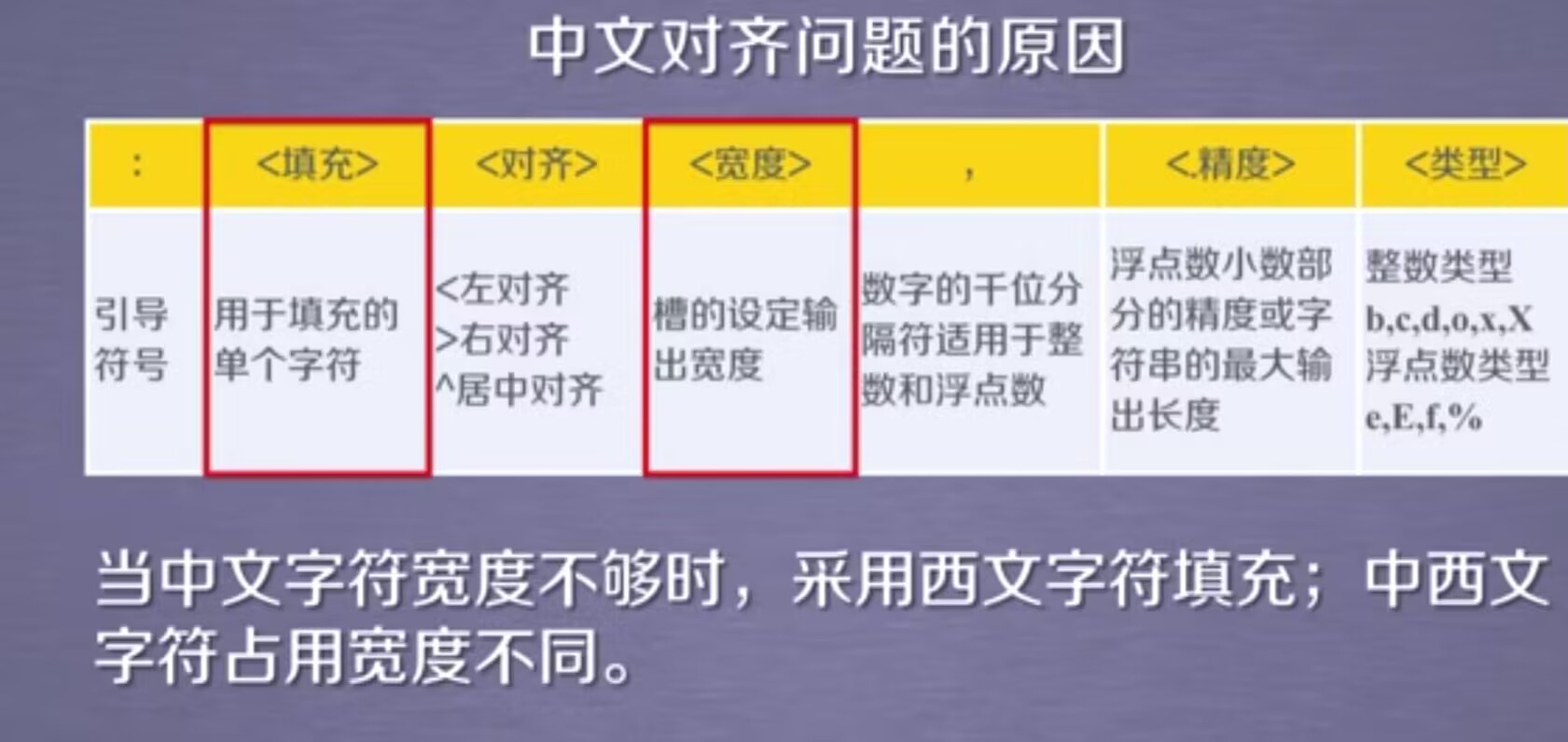
【python】网络爬虫与信息提取--Beautiful Soup库
Beautiful Soup网站:https://www.crummy.com/software/BeautifulSoup/ 作用:它能够对HTML.xml格式进行解析,并且提取其中的相关信息。它可以对我们提供的任何格式进行相关的爬取,并且可以进行树形解析。 使用原理:它能…...

谷歌浏览器,如何将常用打开的网站创建快捷方式到电脑桌面?
打开谷歌浏览器,打开想要创建的快捷方式的网页 点击浏览器右上角的三个点: 点击选择【更多工具】 选择【创建快捷方式】 然后,在浏览器上方会弹出一个框,让命名此创建的快捷方式的名称 命名好之后,再点击【创…...
?)
FalkorDB 的边存储原理:为什么查邻居是 O(degree)?
很多人第一次看到 FalkorDB 的架构时,会有一个疑问:它不用传统 adjacency list(邻接链表),而是用 sparse matrix(稀疏矩阵)维护边,那它到底怎么高效找到某个节点的所有边?…...

重磅喜报!中国星坤入围东莞上规资助计划,政企携手共筑智造标杆
近日,东莞市工业和信息化局正式公布 2026 年支持工业企业上规发展做大做强项目拟资助计划,中国星坤(XKB Connection)凭借在电子连接器领域的技术实力与稳健发展,成功入选,成为东莞智造升级的标杆企业之一东…...

别再死记硬背了!用Python+SymPy玩转含参积分,从卷积到信号处理一次搞懂
用PythonSymPy玩转含参积分:从数学原理到信号处理实战 数学中的含参积分常常让学习者感到抽象难懂,尤其是当涉及到极限交换、求导与积分顺序交换等概念时。但如果我们换一种方式——用代码和可视化来探索这些数学概念,一切就会变得清晰起来。…...

从审稿人到作者:我审了10篇论文后,总结出的5个投稿避坑指南和3个加分项
从审稿人到作者:10篇论文审阅经验提炼的5大避坑策略与3个关键加分项 第一次收到审稿邀请时,我正对着自己第三篇被拒的论文修改意见发呆。这种身份错位带来的震撼,让我开始系统记录审稿笔记——如今这些笔记已形成超过2万字的"审稿人思维…...

DS-PAW势函数计算全流程:从自洽到可视化分析
1. 从自洽到势函数:理解材料静电环境的关键一步在材料计算领域,我们常常听到“第一性原理计算”这个词,它意味着从最基本的物理定律出发,不依赖任何经验参数,去预测材料的性质。DS-PAW作为一款国产的平面波密度泛函理论…...

linux PATH介绍
这句命令的作用是:把君正 X2600 的交叉编译器目录,临时加入 Linux 的命令搜索路径里。 你这句: export PATH/home/vik/project/x2600/tools/toolchains/mips-xburst2-gcc720-glibc238/bin:$PATH可以拆开理解。1. PATH 是啥? PATH …...
)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层(丝印、装配、阻焊)
从一颗0603电阻的封装,聊聊PADS里那些容易被忽略的‘隐形’图层 在PCB设计领域,封装设计往往被视为"简单"的基础工作。许多工程师认为,只要焊盘位置正确、丝印轮廓大致匹配,一个封装就算完成了。直到某天,工…...

瑞芯微RK3572正式发布,中阶AIoT八核处理器,性能功耗双突破
5月8日,瑞芯微正式发布面向中阶AIoT市场的八核处理器RK3572。这款新品以8nm先进制程为基础,在高性能、低功耗与全栈 AI 能力之间实现突破性平衡,为消费电子、智能硬件等广泛场景提供极具竞争力的算力底座。根据官方数据。RK3572相比上一代中阶…...

八股整理之JUC篇
怎么保证多线程安全?synchronized关键字:可以使用synchronized关键字来同步代码块或方法,确保同一时刻只有一个线程可以访问这些代码。对象锁是通过synchronized关键字锁定对象的监视器(monitor)来实现的。volatile关键字:volatil…...

2026年六大主流AI变声器软件排名推荐!
随着AI语音技术持续迭代升级,AI变声器不再是单一的娱乐工具,广泛应用于游戏开黑、直播互动、短视频配音、音频创作、隐私语音沟通等多个场景。目前市面上变声软件品类繁杂,涵盖移动端、PC端、免费开源、专业付费等不同类型,普通用…...