三、案例 - MySQL数据迁移至ClickHouse
MySQL数据迁移至ClickHouse
- 一、生成测试数据表和数据
- 1.在MySQL创建数据表和数据
- 2.在ClickHouse创建数据表
- 二、生成模板文件
- 1.模板文件内容
- 2.模板文件参数详解
- 2.1 全局设置
- 2.2 数据读取(Reader)
- 2.3 数据写入(Writer)
- 2.4 性能设置
- 三、案例
- 1.全量数据迁移
- 1.1 配置迁移模板
- 1.2.运行迁移命令
- 2.增量数据迁移
- 2.1 配置迁移模板
- 2.2 运行迁移命令
一、生成测试数据表和数据
1.在MySQL创建数据表和数据
- 部署MySQL教程
# 1.创建数据库
CREATE DATABASE test charset=utf8mb4;
USE test;
# 2.创建表
CREATE TABLE User (userId INT AUTO_INCREMENT PRIMARY KEY,username VARCHAR(255) NOT NULL,email VARCHAR(255) NOT NULL UNIQUE,registrationDate DATETIME NOT NULL,lastLogin DATETIME,createTime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 创建时间updateTime DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP -- 更新时间
);
# 3.插入测试数据
INSERT INTO test.`User` (username, email, registrationDate, lastLogin) VALUES
('JohnDoe01', 'john.doe01@example.com', '2023-02-01 08:00:00', '2023-02-02 09:00:00'),
('JaneDoe02', 'jane.doe02@example.com', '2023-02-02 10:00:00', '2023-02-03 11:00:00'),
('MikeSmith03', 'mike.smith03@example.com', '2023-02-03 12:00:00', '2023-02-04 13:00:00'),
('LucyBrown04', 'lucy.brown04@example.com', '2023-02-04 14:00:00', '2023-02-05 15:00:00'),
('DavidWilson05', 'david.wilson05@example.com', '2023-02-05 16:00:00', '2023-02-06 17:00:00'),
('LindaTaylor06', 'linda.taylor06@example.com', '2023-02-06 18:00:00', '2023-02-07 19:00:00'),
('RobertJones07', 'robert.jones07@example.com', '2023-02-07 20:00:00', '2023-02-08 21:00:00'),
('PatriciaWhite08', 'patricia.white08@example.com', '2023-02-08 22:00:00', '2023-02-09 23:00:00'),
('MichaelHarris09', 'michael.harris09@example.com', '2023-02-09 08:30:00', '2023-02-10 09:30:00'),
('SarahMartin10', 'sarah.martin10@example.com', '2023-02-10 10:30:00', '2023-02-11 11:30:00');# 4.批量插入100w数据
# 4.1 创建存储过程
DELIMITER $$
CREATE PROCEDURE InsertUsers()
BEGINDECLARE i INT DEFAULT 0;WHILE i < 1000000 DOINSERT INTO User (username, email, registrationDate, lastLogin) VALUES (CONCAT('User', LPAD(i, 7, '0')), CONCAT('user', LPAD(i, 7, '0'), '@example.com'), NOW(), NOW());SET i = i + 1;END WHILE;
END$$
DELIMITER ;
# 4.2 调用存储过程,生成100w用户数据
CALL InsertUsers();
2.在ClickHouse创建数据表
- 部署ClickHouse教程
CREATE TABLE User (userId Int32,username String,email String,registrationDate DateTime,lastLogin Nullable(DateTime),createTime DateTime, -- 创建时间updateTime DateTime -- 更新时间
) ENGINE = MergeTree()
ORDER BY userId;
二、生成模板文件
- 当前安装DataX的目录为:/data/datax
# 1.进入datax的工具目录
cd /data/datax/bin/
# 2.生成模板
python datax.py -r mysqlreader -w clickhousewriter > ../job/mysql_to_clickhouse.json
1.模板文件内容
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [],"connection": [{"jdbcUrl": [],"table": []}],"password": "","username": "","where": ""}},"writer": {"name": "clickhousewriter","parameter": {"batchByteSize": 134217728,"batchSize": 65536,"column": ["col1","col2","col3"],"connection": [{"jdbcUrl": "jdbc:clickhouse://<host>:<port>[/<database>]","table": ["table1","table2"]}],"dryRun": false,"password": "password","postSql": [],"preSql": [],"username": "username","writeMode": "insert"}}}],"setting": {"speed": {"channel": ""}}}
}
2.模板文件参数详解
2.1 全局设置
- job: 定义了整个数据迁移作业的配置。
- content: 包含了一个或多个数据同步任务的列表。
2.2 数据读取(Reader)
- reader: 定义了数据来源的相关配置。
- name: 使用的读取插件名称,这里是mysqlreader,表示从MySQL数据库读取数据。
- parameter: 读取数据时的参数配置。
- column: 需要读取的列名列表。这里指定了从MySQL表中读取userId, username, email, registrationDate, lastLogin这几个字段。
- connection: 数据库连接信息。
- jdbcUrl: 数据库的JDBC连接URL。需要替换<your_mysql_host>, <your_mysql_port>, <your_mysql_database>为实际的MySQL服务器地址、端口和数据库名。
- table: 指定要读取数据的表名列表,在这个例子中是User表。
- password: 用于连接MySQL数据库的密码。
- username: 用于连接MySQL数据库的用户名。
- where: 可以指定一个WHERE条件来过滤读取的数据,这里留空表示不过滤,读取所有数据。
2.3 数据写入(Writer)
- writer: 定义了数据目的地的相关配置。
- name: 使用的写入插件名称,这里是clickhousewriter,表示数据将被写入到ClickHouse数据库。
- parameter: 写入数据时的参数配置。
- batchByteSize: 指定每个批次写入的最大字节数。这里设置为134217728,约等于128MB。
- batchSize: 指定每个批次写入的记录数。这里设置为65536。
- column: 指定写入到目标表的列名。应与读取的列对应。
- connection: 目标数据库的连接信息。
- jdbcUrl: ClickHouse的JDBC连接URL。需要替换, , [/]为实际的ClickHouse服务器地址、端口和数据库名。
- table: 指定要写入数据的表名,在这个例子中是User表。
- dryRun: 是否进行干运行(不实际写入数据)。这里设置为false,表示将实际执行数据写入。
- password: 用于连接ClickHouse数据库的密码。
- postSql: 在数据写入完成后执行的SQL语句列表,这里留空。
- preSql: 在数据写入前执行的SQL语句列表,这里留空。
- username: 用于连接ClickHouse数据库的用户名。
- writeMode: 写入模式,这里设置为insert,表示通过INSERT语句进行数据写入。
2.4 性能设置
- setting: 定义了作业的全局设置。
- speed: 控制数据同步的速度。
- channel: 指定并发通道的数量,这里设置为4,意味着数据迁移任务将并行执行,使用4个并发通道。
- speed: 控制数据同步的速度。
三、案例
1.全量数据迁移
1.1 配置迁移模板
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["userId","username","email","registrationDate","lastLogin","createTime","updateTime"],"connection": [{"jdbcUrl": ["jdbc:mysql://192.168.86.128:3306/test?useUnicode=true&characterEncoding=utf-8"],"table": ["User"]}],"password": "xxx","username": "root","where": ""}},"writer": {"name": "clickhousewriter","parameter": {"batchByteSize": 134217728,"batchSize": 65536,"column": ["userId","username","email","registrationDate","lastLogin","createTime","updateTime"],"connection": [{"jdbcUrl": "jdbc:clickhouse://192.168.86.128:8123/default","table": ["User"]}],"dryRun": false,"password": "qwe123","postSql": [],"preSql": [],"username": "root","writeMode": "insert"}}}],"setting": {"speed": {"channel": 4}}}
}
1.2.运行迁移命令
python /data/datax/bin/datax.py /data/datax/job/mysql_to_clickhouse.json
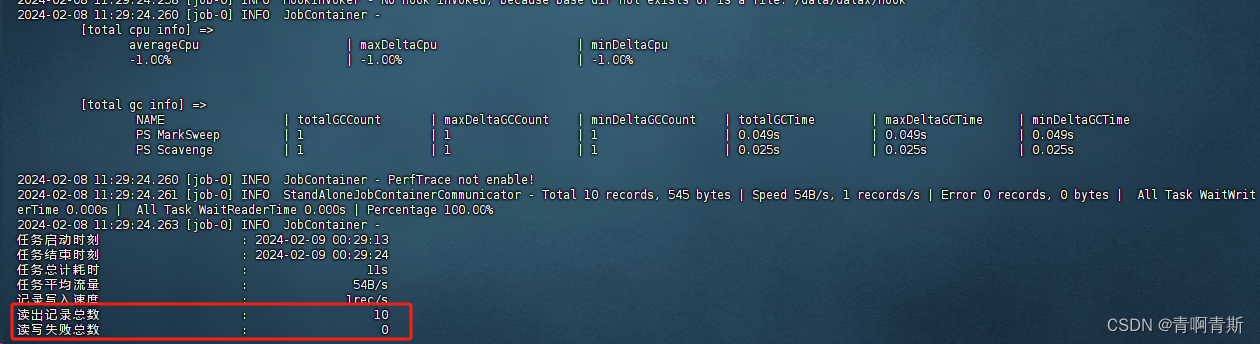
2.增量数据迁移
- 主要差别在于,需要有一个createTime字段,代表源数据的创建时间,那么更新的时候,只迁移过滤这个时间段的数据,达到增量数据迁移
2.1 配置迁移模板
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["userId","username","email","registrationDate","lastLogin","createTime","updateTime"],"connection": [{"jdbcUrl": ["jdbc:mysql://192.168.86.128:3306/test?useUnicode=true&characterEncoding=utf-8"],"table": ["User"]}],"password": "qwe123","username": "root","where": "createTime>='${startDatetime} 00:00:00' and createTime<='${endDatetime} 23:59:59'"}},"writer": {"name": "clickhousewriter","parameter": {"batchByteSize": 134217728,"batchSize": 65536,"column": ["userId","username","email","registrationDate","lastLogin","createTime","updateTime"],"connection": [{"jdbcUrl": "jdbc:clickhouse://192.168.86.128:8123/default","table": ["User"]}],"dryRun": false,"password": "qwe123","postSql": [],"preSql": [],"username": "root","writeMode": "insert"}}}],"setting": {"speed": {"channel": 4}}}
}
2.2 运行迁移命令
- 注意:指定参数的话,参数名称面前需要加:
-D
python /data/datax/bin/datax.py /data/datax/job/mysql_to_clickhouse.json -p "-DstartDatetime=2024-02-09 -DendDatetime=2024-02-10"
相关文章:
三、案例 - MySQL数据迁移至ClickHouse
MySQL数据迁移至ClickHouse 一、生成测试数据表和数据1.在MySQL创建数据表和数据2.在ClickHouse创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置…...

[WinForm开源]概率计算器 - Genshin Impact(V1.0)
创作目的:为方便旅行者估算自己拥有的纠缠之缘能否达到自己的目的,作者使用C#开发了一款小型软件供旅行者参考使用。 创作说明:此软件所涉及到的一切概率与规则完全按照游戏《原神》(V4.4.0)内公示的概率与规则(包括保底机制&…...
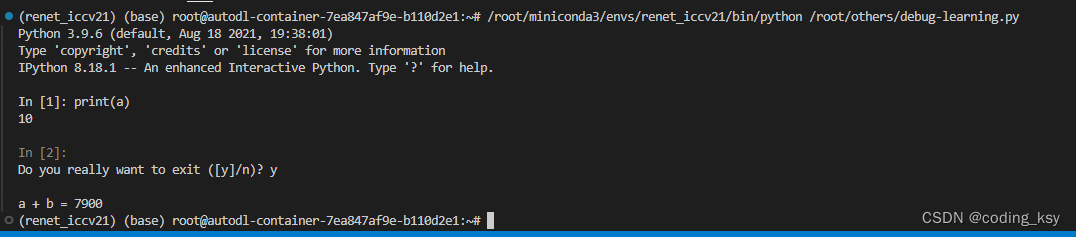
vscode 代码调试from IPython import embed
一、讲解 这种代码调试方法非常的好用。 from IPython import embed上面的代码片段是用于Python中嵌入一个交互式IPython shell的方法。这可以在任何Python脚本或程序中实现,允许在执行到该点时暂停程序,并提供一个交互式环境,以便于检查、…...
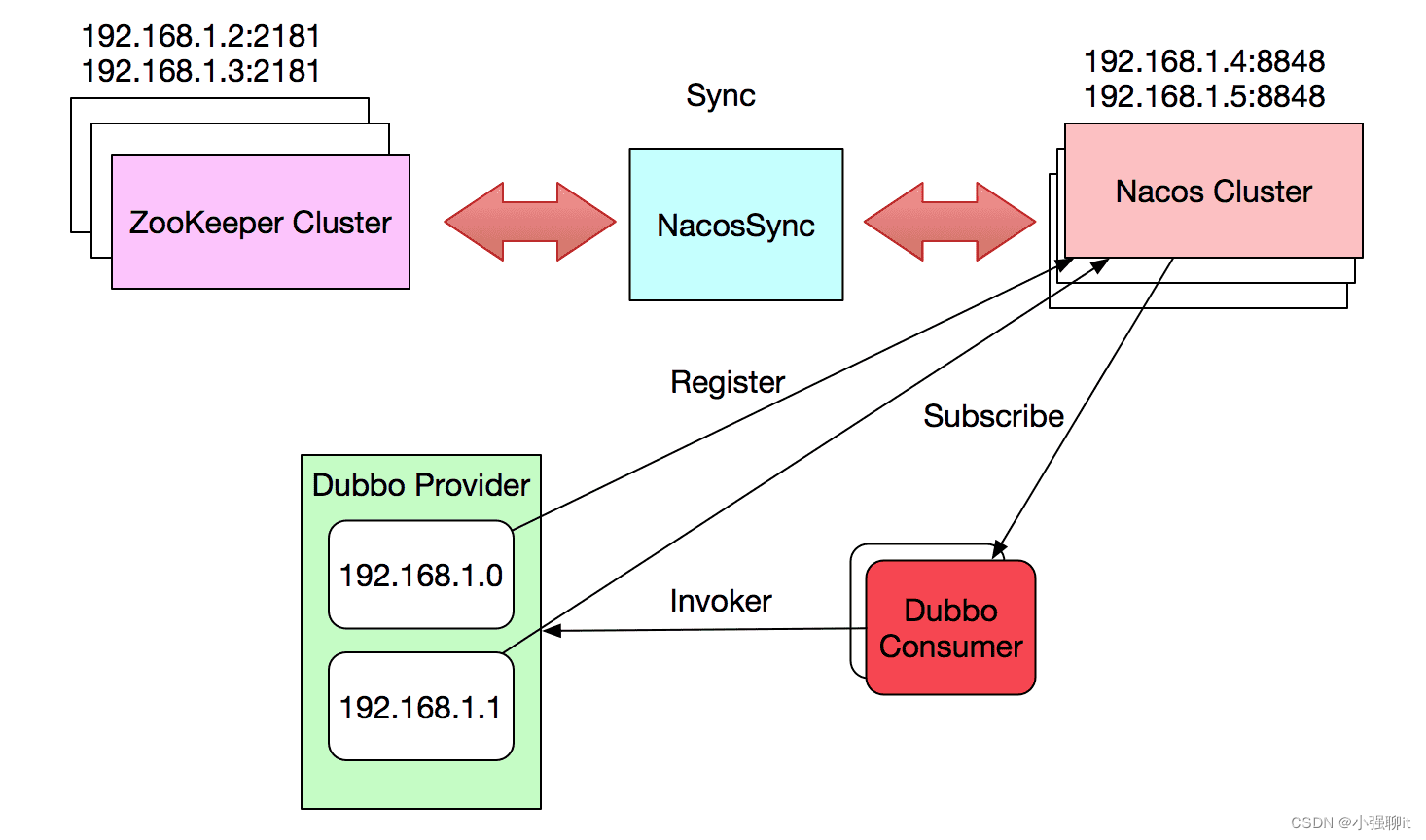
双活工作关于nacos注册中心的数据迁移
最近在做一个双活的项目,在纠结一个注册中心是在双活机房都准备一个,那主机房的数据如果传过去呢,查了一些资料,最终在官网查到了一个NacosSync 的组件,主要用来做数据传输的,并且支持在线替换注册中心的&a…...
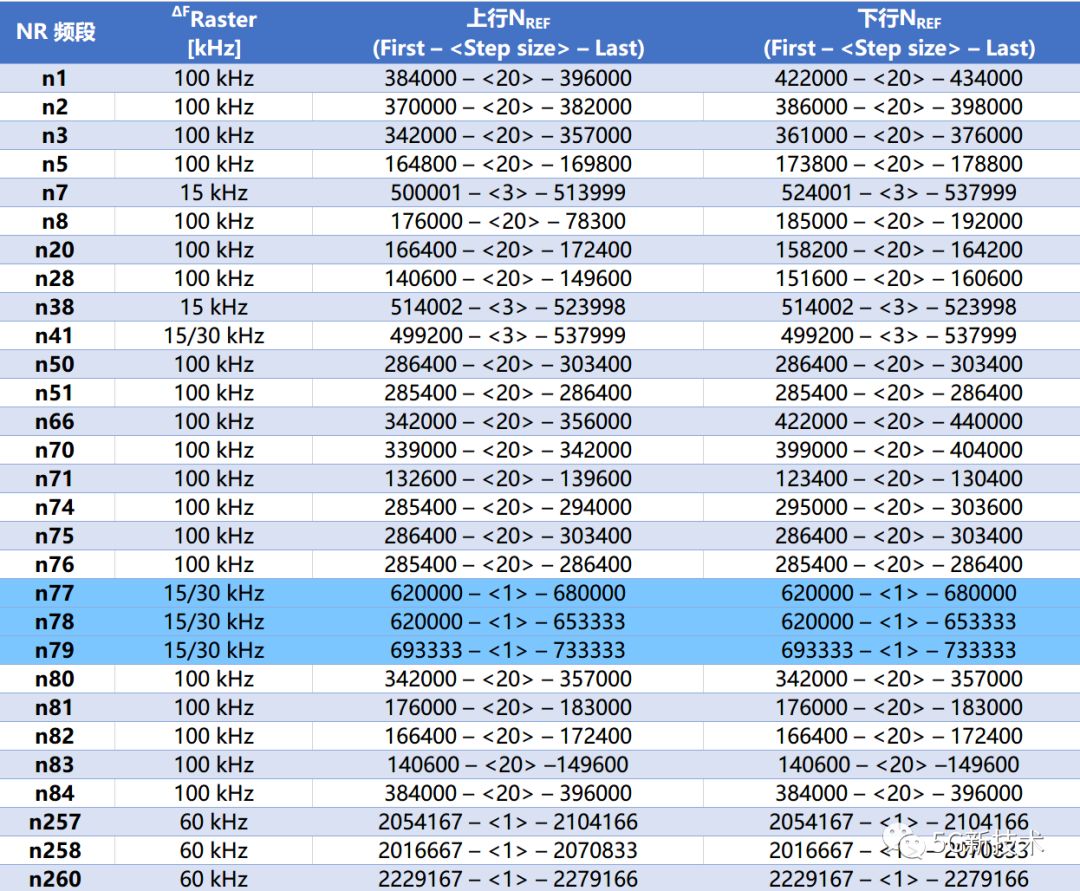
5G NR 信道号计算
一、5G NR的频段 增加带宽是增加容量和传输速率最直接的方法,目前5G最大带宽将会达到400MHz,考虑到目前频率占用情况,5G将不得不使用高频进行通信。 3GPP协议定义了从Sub6G(FR1)到毫米波(FR2)的5G目标频谱。 其中FR1是5G的核心频段࿰…...
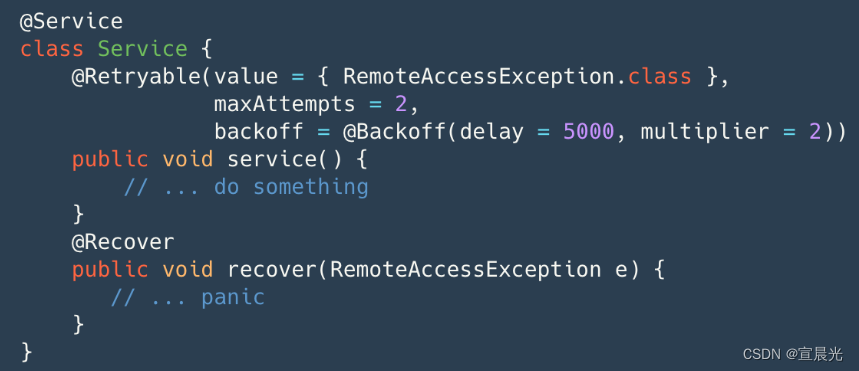
01-Spring实现重试和降级机制
主要用于在模块调用中,出现失败、异常情况下,仍需要进行重复调用。并且在最终调用失败时,可以采用降级措施,返回一般结果。 1、重试机制 我们采用spring 提供的retry 插件,其原理采用aop机制,所以需要额外…...
docker部署showdoc
目录 安装 1.拉取镜像 2.创建容器 使用 1.选择语言 2.默认账户/密码:showdoc/123456编辑 3.登陆 4.首页 安装 1.拉取镜像 docker pull star7th/showdoc 2.创建容器 mkdir -p /opt/showdoc/html docker run -d --name showdoc --userroot --privilegedtrue -p 1005…...

2.14作业
1.请编程实现二维数组的杨辉三角。 2.请编程实现二维数组计算每一行的和以及列和。 3.请编程实现二维数组计算第二大值。 4.请使用非函数方法实现系统函数strcat,strcmp,strcpy,strlen. strcat: strcmp: strcpy: strlen:...
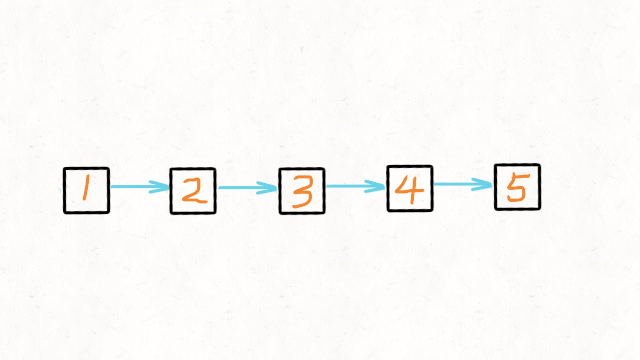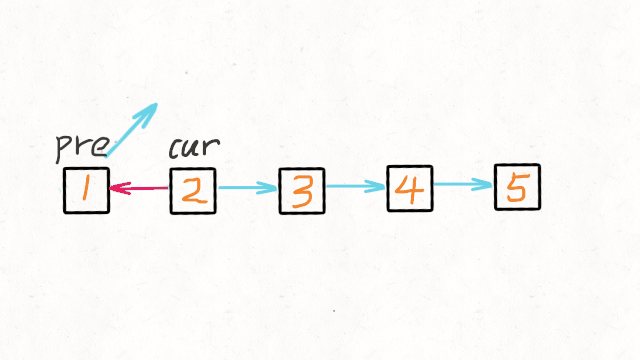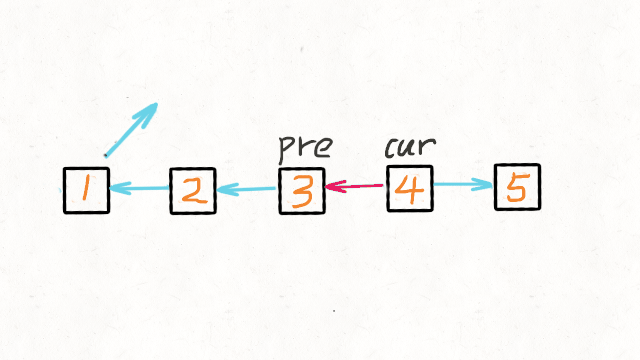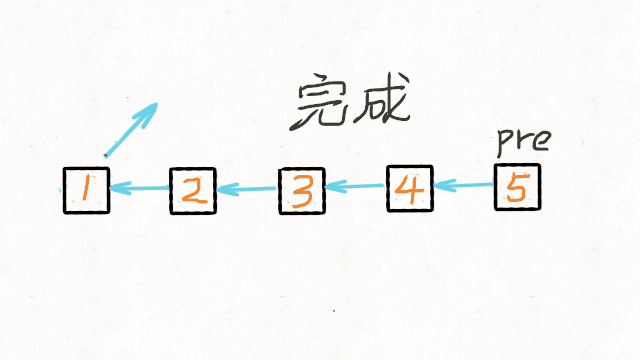
01.数据结构篇-链表
1.找出两个链表的交点 160. Intersection of Two Linked Lists (Easy) Leetcode / 力扣 例如以下示例中 A 和 B 两个链表相交于 c1: A: a1 → a2↘c1 → c2 → c3↗ B: b1 → b2 → b3 但是不会出现以下相交的情况,因为每个节点只有一个…...

揭秘产品迭代计划制定:从0到1打造完美迭代策略
产品迭代计划是产品团队确保他们能够交付满足客户需求的产品以及实现其业务目标的重要工具。开发一个成功的产品迭代计划需要仔细考虑产品的目标、客户需求、市场趋势和可用资源。以下是帮助您创建产品迭代计划的一些步骤:建立产品目标、收集客户反馈、分析市场趋势…...
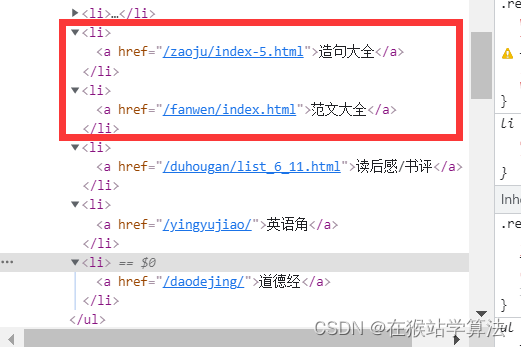
Python进阶--下载想要的格言(基于格言网的Python爬虫程序)
注:由于上篇帖子(Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)-CSDN博客)篇幅长度的限制,此篇帖子对上篇做一个拓展延伸。 目录 一、爬取格言网中想要内容的url 1、找到想要的内容 2、抓包分析,找到想…...
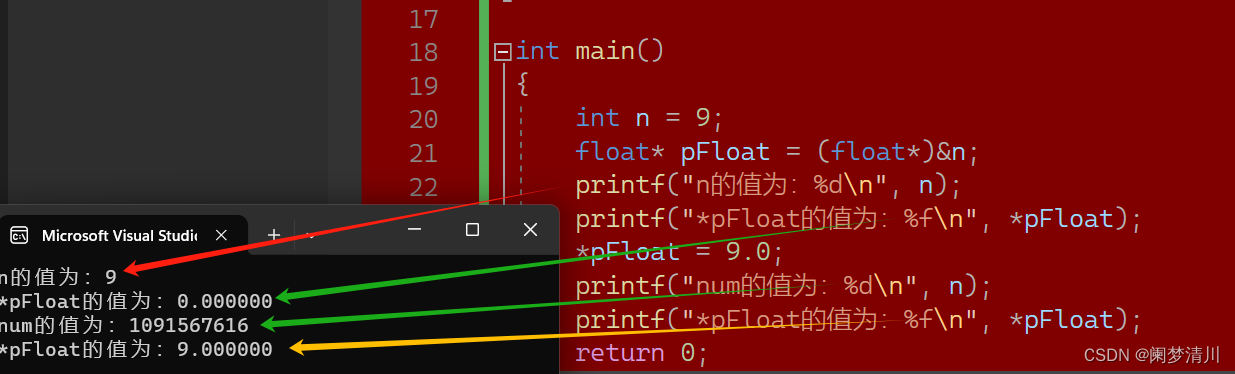
C语言--------数据在内存中的存储
1.整数在内存中的存储 整数在内存是以补码的形式存在的; 整型家族包括char,int ,long long,short类型; 因为char类型是以ASCII值形式存在,所以也是整形家族; 这四种都包括signed,unsigned两种,即有符号和无符号&am…...

【Java】零基础蓝桥杯算法学习——线性动态规划(一维dp)
线性dp——一维动态规划 1、考虑最后一步可以由哪些状态得到,推出转移方程 2、考虑当前状态与哪些参数有关系,定义几维数组来表示当前状态 3、计算时间复杂度,判断是否需要进行优化。 一维动态规划例题:最大上升子序列问题 Java参…...
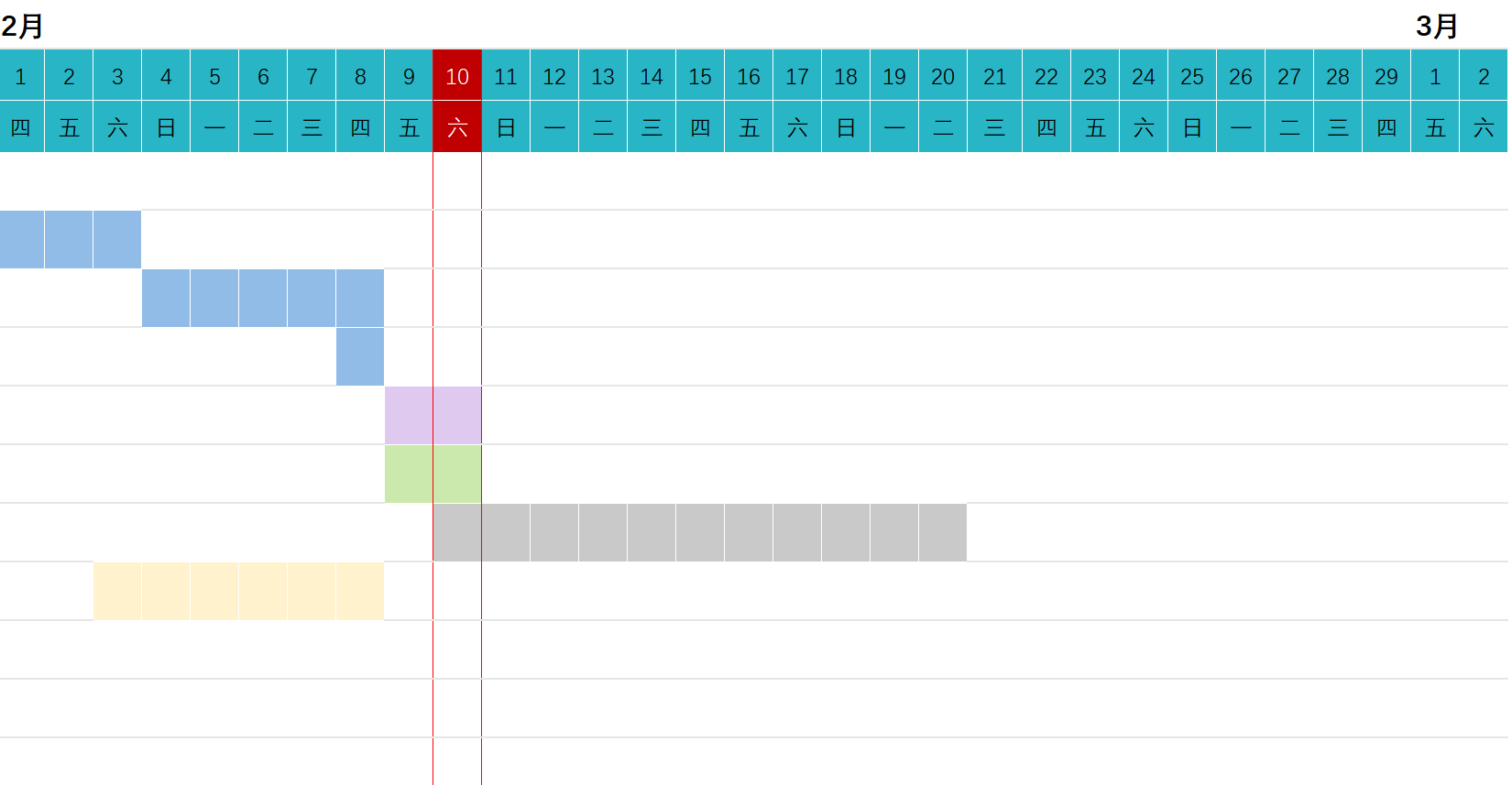
Excel模板1:彩色甘特图
Excel模板1:彩色甘特图 分享地址 当前效果:只需要填写进度, 其余效果都是自动完成的 。 阿里网盘永久分享:https://www.alipan.com/s/cXhq1PNJfdm 省心。能用公式的绝不使用手动输入。 这个区域以及标题可以手动输入…...
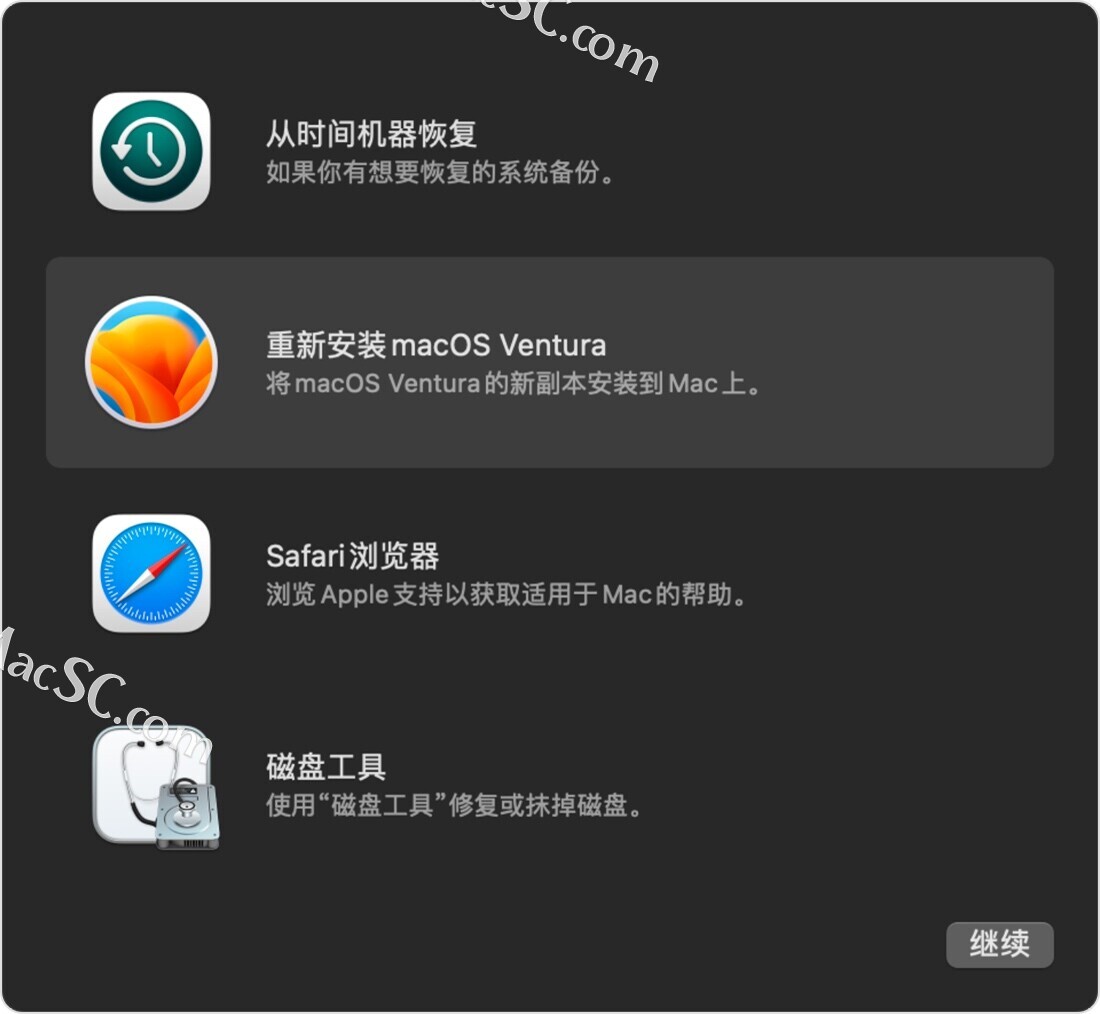
如何重新安装 macOS
你可以使用电脑的内建恢复系统“macOS 恢复”来重新安装 Mac 操作系统。不但简单快捷,而且重新安装后不会移除你的个人数据。 将 Mac 关机 选取苹果菜单 >“关机”,然后等待 Mac 关机。如果你无法将 Mac 关机,请按住它的电源按钮最长 …...
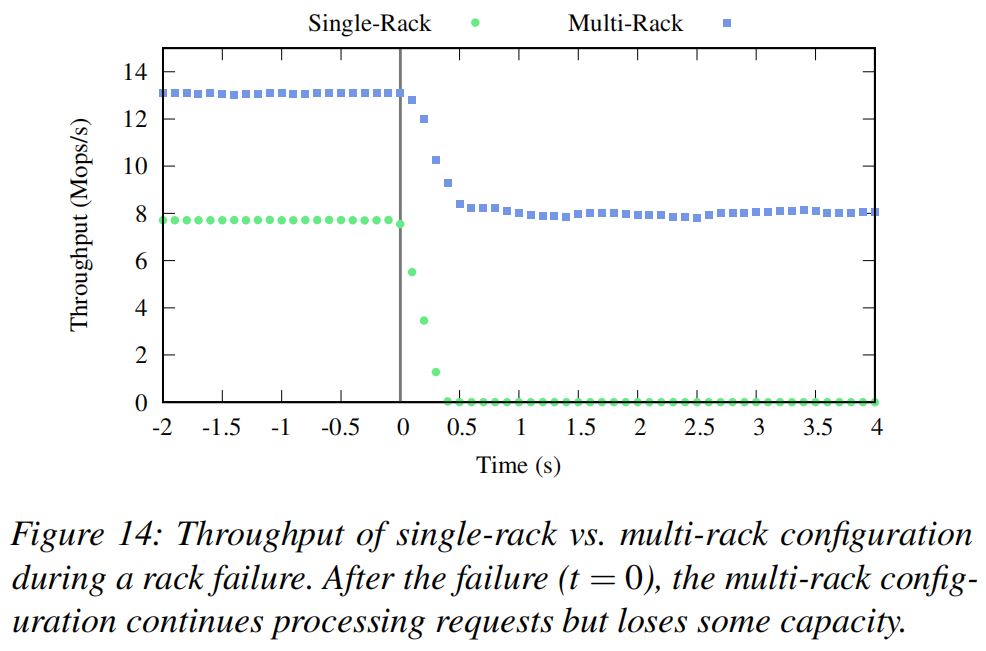
论文阅读-Pegasus:通过网络内一致性目录容忍分布式存储中的偏斜工作负载
论文名称:Pegasus: Tolerating Skewed Workloads in Distributed Storage with In-Network Coherence Directories 摘要 高性能分布式存储系统面临着由于偏斜和动态工作负载引起的负载不平衡的挑战。本文介绍了Pegasus,这是一个利用新一代可编程交换机…...
)
【PTA|编程题|期末复习】字符串(一)
【C语言/期末复习】字符和字符串函数(附思维导图/例题) 目录 7-1 组织星期信息 输入样例 (repeat3) : 输出样例: 代码 7-2 查找指定字符 输入格式: 输出格式: 输入样例1: 输出样例1: 输入样例2: …...

数据库基本操作2
一.DML(Data Manipulation Language) 用来对数据库中表的数据记录进行更新 关键字:增删改 插入insert 删除delete 更新update 1.数据插入 insert into 表(列名1,列名2,列名3……)values&a…...

BTC破5W+QAQ
比特币突破5万美元 创2021年来最高 比特币在龙年伊始涨超6.8%。在大年初四(2月13日)一度最高涨至5万零383美元。 今年1月,当市场期待已久的现货比特币交易所挂牌基金(ETF)推出后,比特币遭抛售,…...
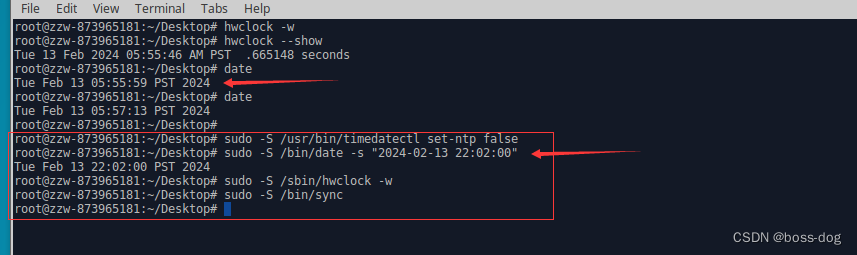
Xubuntu16.04系统中修改系统语言和系统时间
1.修改系统语言 问题:下图显示系统语言不对 查看系统中可用的所有区域设置的命令 locale -a修改/etc/default/locale文件 修改后如下: # File generated by update-locale LANG"en_US.UTF-8" LANGUAGE"en_US:en"LANG"en_US…...

18V/4A同步降压转换器:MPQ8632GLE-4的COT控制与快速瞬态响应解析
MPQ8632GLE-4:4A/18V 同步降压转换器的紧凑型电源解决方案在通信设备、分布式电源系统以及服务器主板等应用中,电源管理单元需要在小面积内实现高效率的电压转换,同时保持良好的瞬态响应。传统的 PWM 控制器往往需要复杂的环路补偿设计&#…...
变成了真实漏洞挖掘指南)
别只当题做!我把CTFshow Web信息搜集题(11-20)变成了真实漏洞挖掘指南
从CTF到实战:Web信息泄露漏洞的企业级攻防指南 当CTF技巧遇上真实世界 深夜两点,某电商平台的安全工程师收到告警——核心数据库正在被异常下载。溯源发现,攻击者竟是通过一个被遗忘的测试接口获取了服务器目录遍历权限。这个场景与CTFshow W…...

RT-Thread软定时器漂移问题深度解析与实战优化
1. 项目概述:从一次线上告警说起那天下午,系统监控平台突然弹出一连串的告警,核心业务模块的周期性任务执行间隔出现了肉眼可见的抖动,从预期的100毫秒,漂移到了130毫秒甚至更长。排查了一圈硬件、中断和任务调度&…...

OpenWrt补丁踩坑实录:从‘尾随空格’警告到make update失败的完整排错指南
OpenWrt补丁踩坑实录:从‘尾随空格’警告到make update失败的完整排错指南 当你第一次尝试为OpenWrt制作补丁时,可能会觉得这就像在玩一个充满陷阱的迷宫游戏。每次你以为按照教程走就能顺利通关,却总会在某个转角遇到意想不到的错误提示。本…...

手持式雷达车辆测速仪:基于多普勒效应的移动测速工具
手持式雷达车辆测速仪是一种基于多普勒效应原理的速度测量设备。它通过向目标发射24GHz无线电波,接收反射回来的信号,根据频率变化计算出目标的运动速度。设备重量约504g,内置3600mAh电池,续航可达10小时以上,支持手持…...
百科全书从压缩到生成)
变分自动编码器(VAE)百科全书从压缩到生成
一、开篇:生成模型的"概率革命" 2013 年 12 月 20 日,arXiv 上出现了一篇看似不起眼的论文: Auto-Encoding Variational Bayes Diederik P. Kingma, Max Welling University of Amsterdam 20 页的论文,引入了一个看起来"普通"的想法:让自动编码器的潜…...
)
手把手教你用MP1470芯片设计一个12V转5V的DCDC降压模块(附完整原理图与PCB布局避坑指南)
手把手教你用MP1470芯片设计一个12V转5V的DCDC降压模块(附完整原理图与PCB布局避坑指南) 在嵌入式系统开发中,稳定可靠的电源设计往往是项目成功的关键前提。当我们需要为STM32、ESP32等微控制器或各类传感器供电时,如何将常见的1…...

实战解析:HAL库下ADC常规与注入模式在电机控制中的协同采样策略
1. HAL库下ADC双模式协同采样的必要性 在电机控制系统中,信号采集就像给医生做体检——既需要定期检查血压体温(缓变信号),又要在关键时刻做心电图(瞬态信号)。常规转换模式相当于体检中的常规项目…...

IC697PWR710H电源模块
IC697PWR710H 是GE Fanuc Series 90-70 PLC系统使用的一款高可靠性电源模块,为机架内所有模块提供稳定的直流供电,属于710系列的改进或衍生版本。中间:15条产品特点IC697PWR710H 输入支持交流120/240V或直流125V,适应不同现场供电…...

别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得
别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得 在Vue/React项目中处理批量数据请求时,许多开发者会条件反射地使用Promise.all,认为这是最高效的方案。直到某次线上事故——用户尝试导出500条订单数据时浏览器直…...