Python进阶--下载想要的格言(基于格言网的Python爬虫程序)
注:由于上篇帖子(Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)-CSDN博客)篇幅长度的限制,此篇帖子对上篇做一个拓展延伸。
目录
一、爬取格言网中想要内容的url
1、找到想要的内容
2、抓包分析,找到想要内容的url
3、改写爬虫代码
二、输入想要的内容即可下载到本地
1、抓包分析
2、具备上一页和下一页的正常目录页下载内容代码
3、只具备下一页的非正常目录页下载内容代码
4、针对以上情况都适用的完整代码
一、爬取格言网中想要内容的url
1、找到想要的内容
在格言网中,里面包含大量类型的格言、经典语录、句子、对联、成语等内容。上篇帖子仅仅只是爬取了人生格言这一部分,如果想要爬取下载其他内容,只需要将上篇帖子的全部代码中的url方面的代码做一个修改,即可爬取你想要的内容。
查看格言网的所有类型的内容步骤如下:
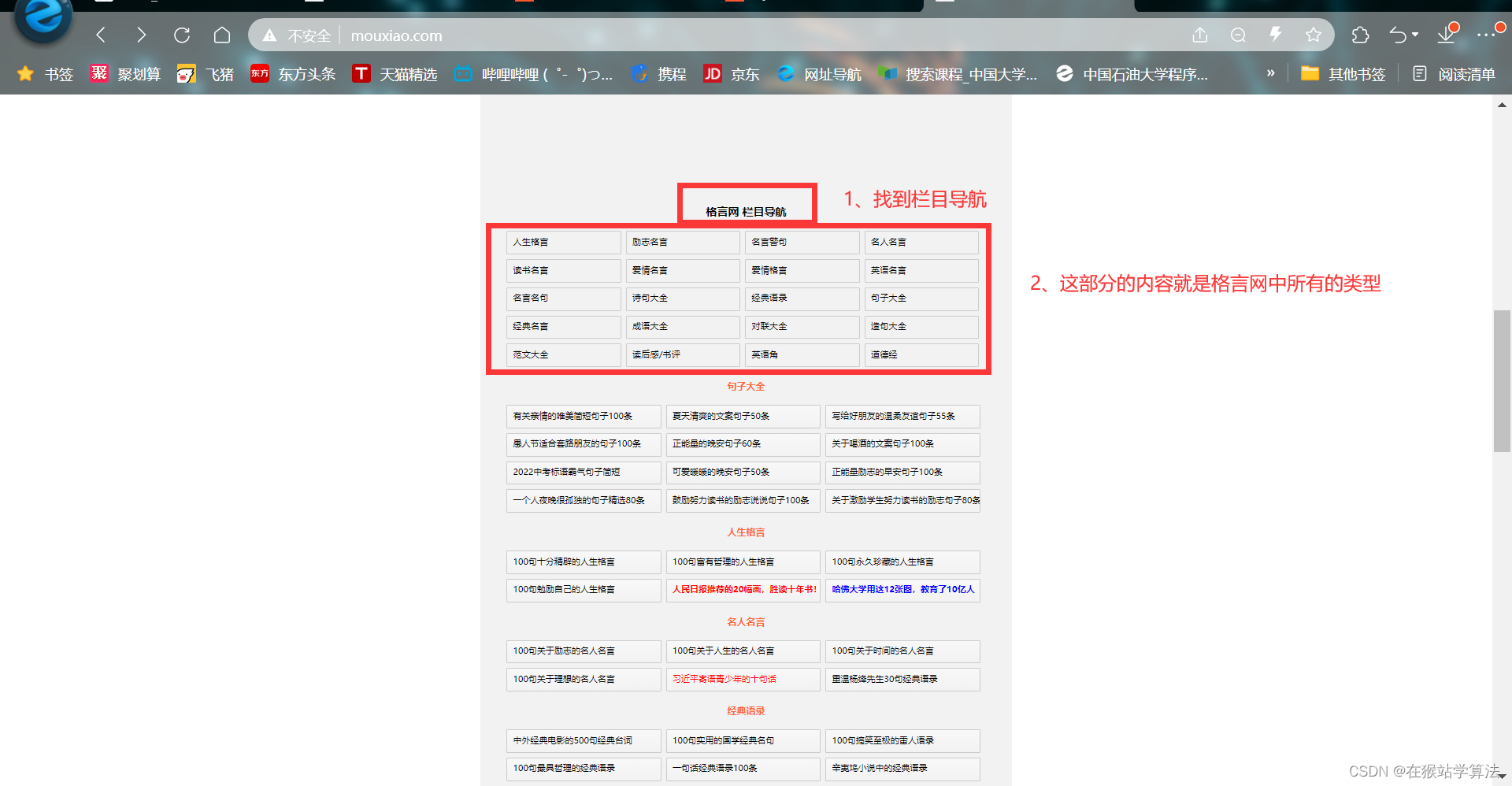
1、打开格言网首页(http://www.mouxiao.com/)
2、往下翻找到栏目导航
3、此部分就是格言网所有类型的内容
注:格言网中其他部分的内容都是此部分的子节点
2、抓包分析,找到想要内容的url
根据上篇帖子抓包分析的方式,在此处继续根据此方式进行抓包分析,定位到想要内容的url。

此处,定位到想要内容的url。(开心!!!)
3、改写爬虫代码
思路:将想要内容的url赋给上篇博客代码中的url部分即可
上篇帖子中的所有代码:
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
index_url = 'http://www.mouxiao.com/renshenggeyan/index.html'
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = 'http://www.mouxiao.com/renshenggeyan/'+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'格言/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]# 因为所获取的下一页地址是相对地址,故进行补全next_page = 'http://www.mouxiao.com/renshenggeyan/'+ next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回if next_page != url:return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=1此处以爬取励志格言为例,只需要将上面部分代码中的url改为励志格言的url即可。
代码如下:
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
index_url = 'http://www.mouxiao.com/lizhimingyan/index.html'
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = 'http://www.mouxiao.com/lizhimingyan/'+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'励志格言/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]# 因为所获取的下一页地址是相对地址,故进行补全next_page = 'http://www.mouxiao.com/lizhimingyan/'+ next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回if next_page != url:return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=1二、输入想要的内容即可下载到本地
1、抓包分析
根据上面的抓包分析,可知栏目导航部分内容的url如下图所示:
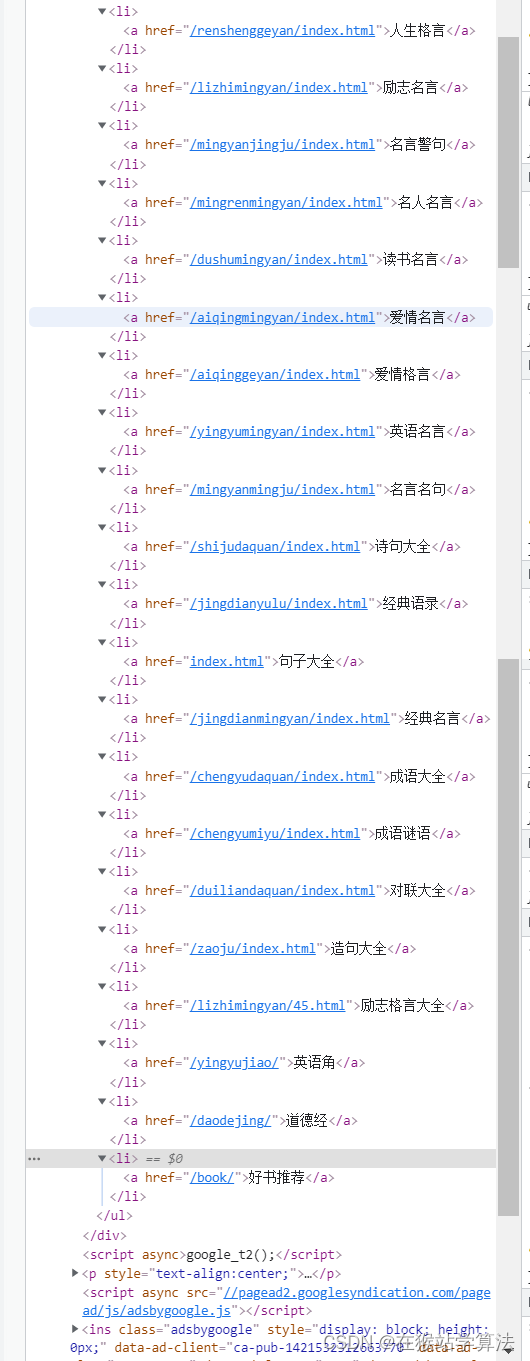
根据以上情况,可以分析得出:
- 栏目导航的链接地址是以下构造
http://www.mouxiao.com/{你想要的内容的中文拼音} 注:好书推荐为book,不为中文拼音:haoshutuijian注:/index.html或者/index-数字.html或者数字.html是属于子页节点,它被包括在以上url的地址中。(此处我们只要找到父页节点,即可访问到其子页节点)
思路:想要通过输入想要的内容来下载,则可以通过读取键盘消息,来填充此部分内容的url。
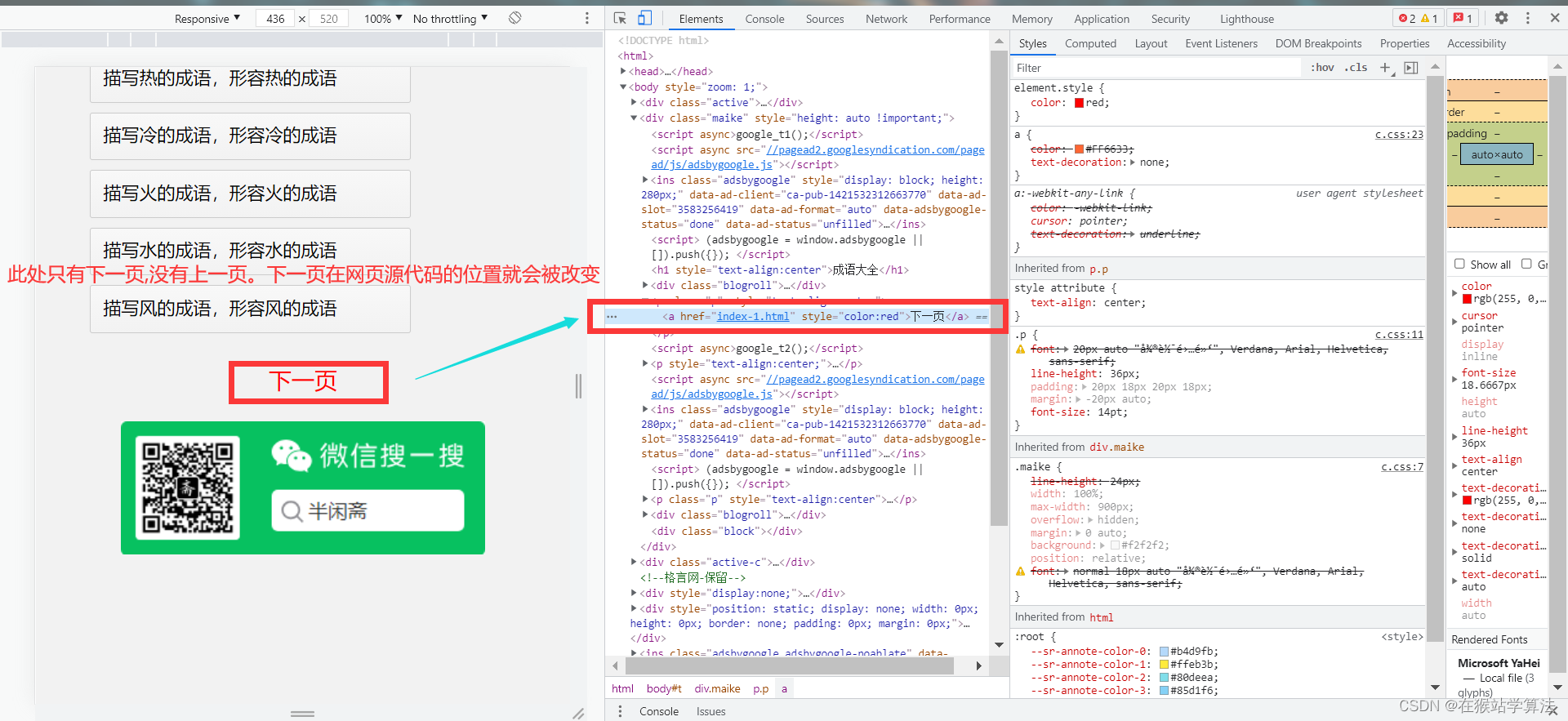
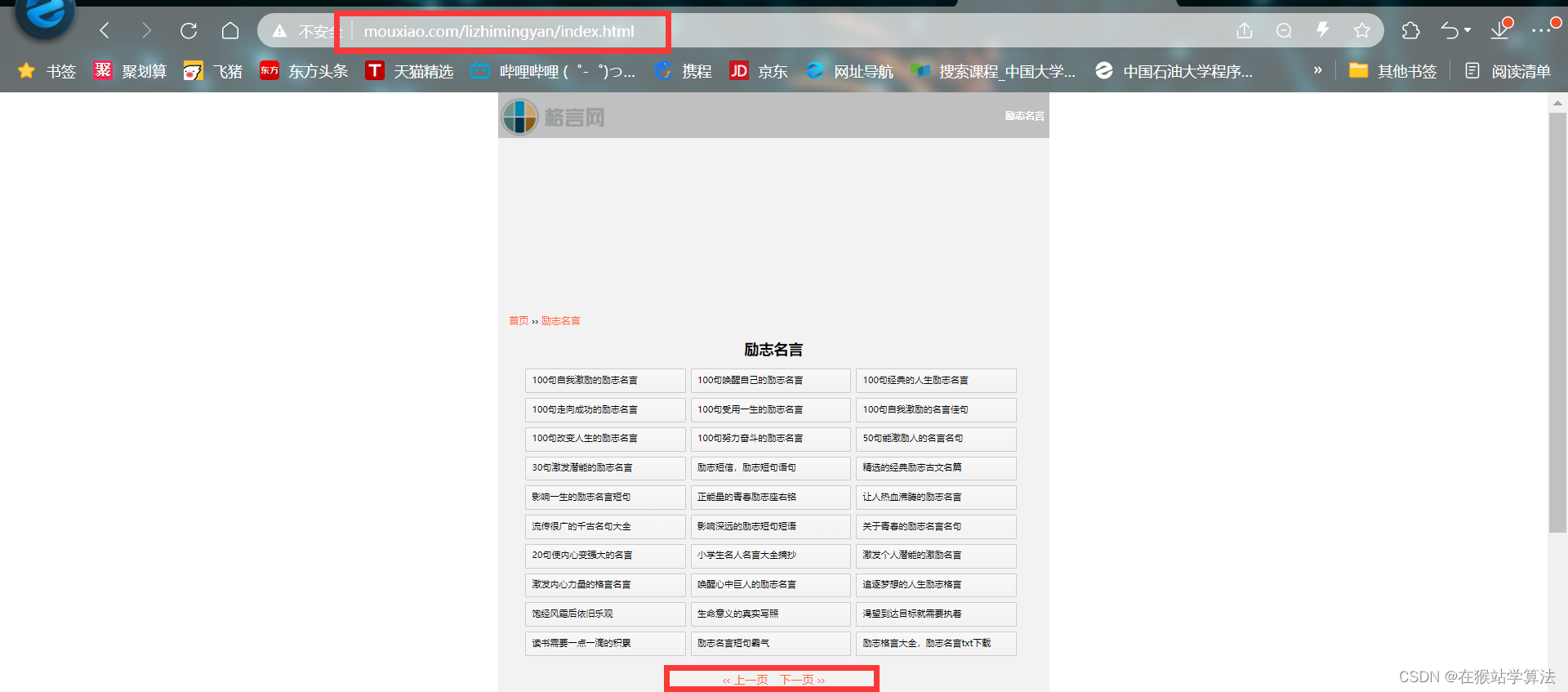
点击栏目导航中所有部分的类型链接跳转到其目录页,查看其目录页的布局情况。据此发现:
- 如果要下载的某个内容的目录页只有下一页选项的情况,其获取下一页的所在源代码的链接位置有所改变,获取下一页的链接地址的代码需要做相应修改。
- 正常的网页应具备上一页和下一页,这样下一页的url位置不会改变,可以适用上篇帖子获取下一页的函数代码
2、具备上一页和下一页的正常目录页下载内容代码
具备上一页和下一页的正常目录页下载的代码为:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = regular_part+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')[3]# 因为所获取的下一页地址是相对地址,故进行补全next_page = regular_part+ next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回if next_page != url:return next_page
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=1输入你想要的内容,即可下载获得!!!
3、只具备下一页的非正常目录页下载内容代码
这种情况下,下一页所在的源代码的url位置发生了变化,抓包分析出此时下一页url所在位置,修改这部分代码即可。
注:
- 在调试的时候发现,这种情况下在处于最后一页时,没有下一页的选项反而出现上一页的选项,且上一页选项的链接所在源代码的位置与下一页选项的链接所在源代码的位置一致。
- 在正常页面中,处于最后一页时,上一页和下一页选项仍然出现,且链接所在位置都没有发生改变,下一页的链接地址与当前页面的链接地址一致。
基于以上情况,返回下一页url时需要使用不同的条件。
代码如下:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = regular_part+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a[text()="下一页"]/@href')if len(next_page)==0:return# 因为所获取的下一页地址是相对地址,故进行补全next_page = regular_part + ''.join(next_page)return next_page# 如果下一页地址和当前页地址不相等,则将下一页地址返回
# 4、将以上函数排放好顺序进行调用,下载人生格言的全部内容及标题
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=14、针对以上情况都适用的完整代码
将以上两种情况用if语句做一个判断,即可。完整代码如下:
import os
import re
import requests
from lxml import etree
# 获取user-agent,用于身份识别
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
# 1、获取具体格言内容和标题
# 封装成一个函数,输入具体人生格言页的地址,获取其具体的人生格言和标题
def get_content(url):# 请求当前网页的源代码r = requests.get(url,headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 解析源代码提取具体格言内容和标题# 获取网页源代码html = etree.HTML(r.text)# 获取格言内容content = html.xpath('//div[@class="maike"]/p[@class="p"]/text()')# 使用 join() 方法将列表中的元素用换行符连接起来content = '\n'.join(content)# 获取标题title = html.xpath('//div[@class="maike"]/h1[@class="title_l"]/text()')[0]# 返回标题和内容return title,content
# 当前页面
keyword = input("情输入你想要的内容(拼音):")
index_url = f'http://www.mouxiao.com/{keyword}'
regular_part = f'http://www.mouxiao.com/{keyword}/'
dictionary = f'../{keyword}'
os.makedirs(dictionary, exist_ok=True)
# 2、获取各种类型的人生格言链接并下载其具体人生格言内容和标题
# 输入当前人生格言的目录页地址,获取各种类型的人生格言链接并下载其具体人生格言内容和标题
def pageupload_play(index_url):# 请求当前网页的源代码r = requests.get(index_url,headers=header)# 由于requests模块会将获取的网页源代码进行自动编码,此处我们不需要编码。# 故采用apparent_encoding方法,禁止requests模块自动编码。r.encoding = r.apparent_encoding# 采用xpath的方式定位获取链接所在位置html = etree.HTML(r.text)links = html.xpath('//ul[@class="readers-list"]//a/@href')# 要匹配所有以数字开头,后面跟 '.html' 的元素,可以遍历列表matched_links = []for link in links:# 采用正则表达式筛选出我们所需要的链接,将其保存到matched_links中if re.findall(r'^\d+\.html', link):matched_links.append(link)# 遍历每个类型人生格言的具体人生格言内容和标题,对其进行下载for link in matched_links:# link中获取的链接是相对地址,需要补全前面的地址link1 = regular_part+link# 调用get_content方法下载内容和标题并保存到本地title, content = get_content(link1)with open(f'../{keyword}/{title}.txt','w',encoding='utf-8') as f:f.write('\t'+title + '\n\n')f.write(content)print(f'已下载...{title}')
# 3、获取下一页的地址
# 封装成一个函数,输入当前页面的url,返回下一页的url
def get_nextpage(url):#请求当前网页的源代码r = requests.get(url, headers=header)# 拒绝requests的自动编码,保留源代码r.encoding = r.apparent_encoding# 定位到下一页的url地址html = etree.HTML(r.text)next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a/@href')# 如果是具有上一页和下一页的正常目录页面if len(next_page) > 2:next_page = next_page[3]next_page = regular_part + next_pageif next_page != url:return next_page# 如果只有下一页的目录页面else:next_page = html.xpath('//div[@class="maike"]//p[@class="p"]//a[text()="下一页"]/@href')if len(next_page)==0:returnnext_page = regular_part + ''.join(next_page)return next_page
n = 1
while 1:print(f"正在下载第{n}页...")print("下载地址为:"+index_url)pageupload_play(index_url)page = get_nextpage(index_url)index_url = pageif index_url==None:breakn+=1运行以上代码需要注意的地方:
- 造句大全和成语大全,需要输入的是zaoju和fanwen。而不是zaojudaquan和chengyudaquan
- 英语角和道德经的目录页布局跟其他内容的目录页布局不同,内容和所在标签都不是跟以上情况处于网页源代码的相同位置。如果需要爬取则需根据上篇贴子进行抓包分析,修改其相应代码即可。
- 书评的页面布局与以上布局类似,但所有的内容在网页源代码的的位置与以上情况有所不同。如果需要爬取,需要抓包分析修改其xpath所定位到的部分。
注:本帖只用于学习交流,禁止商用!
相关文章:
Python进阶--下载想要的格言(基于格言网的Python爬虫程序)
注:由于上篇帖子(Python进阶--爬取下载人生格言(基于格言网的Python3爬虫)-CSDN博客)篇幅长度的限制,此篇帖子对上篇做一个拓展延伸。 目录 一、爬取格言网中想要内容的url 1、找到想要的内容 2、抓包分析,找到想…...
C语言--------数据在内存中的存储
1.整数在内存中的存储 整数在内存是以补码的形式存在的; 整型家族包括char,int ,long long,short类型; 因为char类型是以ASCII值形式存在,所以也是整形家族; 这四种都包括signed,unsigned两种,即有符号和无符号&am…...

【Java】零基础蓝桥杯算法学习——线性动态规划(一维dp)
线性dp——一维动态规划 1、考虑最后一步可以由哪些状态得到,推出转移方程 2、考虑当前状态与哪些参数有关系,定义几维数组来表示当前状态 3、计算时间复杂度,判断是否需要进行优化。 一维动态规划例题:最大上升子序列问题 Java参…...
Excel模板1:彩色甘特图
Excel模板1:彩色甘特图 分享地址 当前效果:只需要填写进度, 其余效果都是自动完成的 。 阿里网盘永久分享:https://www.alipan.com/s/cXhq1PNJfdm 省心。能用公式的绝不使用手动输入。 这个区域以及标题可以手动输入…...
如何重新安装 macOS
你可以使用电脑的内建恢复系统“macOS 恢复”来重新安装 Mac 操作系统。不但简单快捷,而且重新安装后不会移除你的个人数据。 将 Mac 关机 选取苹果菜单 >“关机”,然后等待 Mac 关机。如果你无法将 Mac 关机,请按住它的电源按钮最长 …...
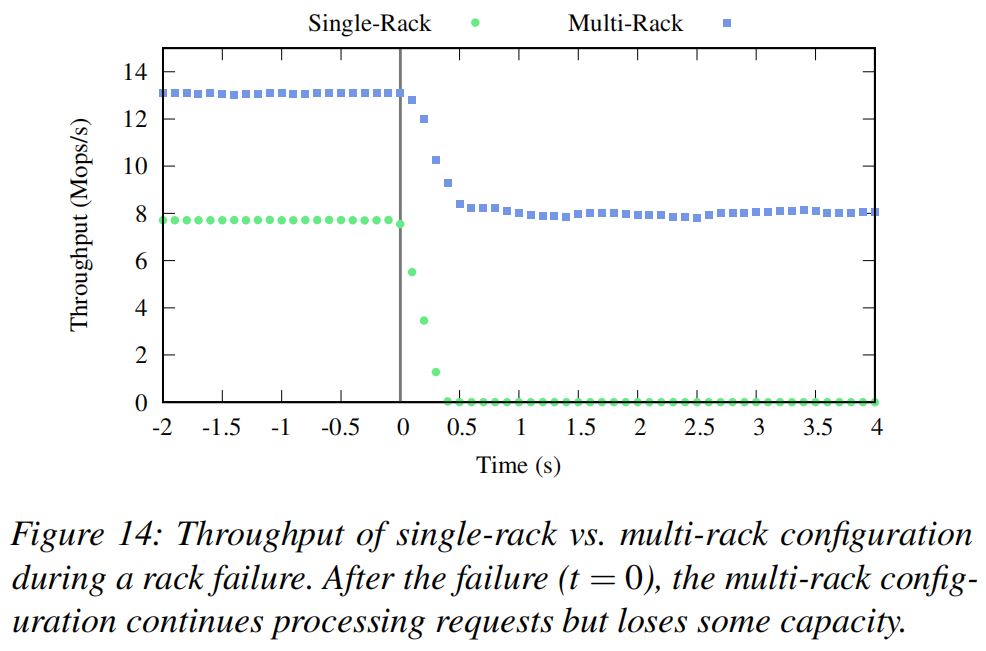
论文阅读-Pegasus:通过网络内一致性目录容忍分布式存储中的偏斜工作负载
论文名称:Pegasus: Tolerating Skewed Workloads in Distributed Storage with In-Network Coherence Directories 摘要 高性能分布式存储系统面临着由于偏斜和动态工作负载引起的负载不平衡的挑战。本文介绍了Pegasus,这是一个利用新一代可编程交换机…...
)
【PTA|编程题|期末复习】字符串(一)
【C语言/期末复习】字符和字符串函数(附思维导图/例题) 目录 7-1 组织星期信息 输入样例 (repeat3) : 输出样例: 代码 7-2 查找指定字符 输入格式: 输出格式: 输入样例1: 输出样例1: 输入样例2: …...

数据库基本操作2
一.DML(Data Manipulation Language) 用来对数据库中表的数据记录进行更新 关键字:增删改 插入insert 删除delete 更新update 1.数据插入 insert into 表(列名1,列名2,列名3……)values&a…...

BTC破5W+QAQ
比特币突破5万美元 创2021年来最高 比特币在龙年伊始涨超6.8%。在大年初四(2月13日)一度最高涨至5万零383美元。 今年1月,当市场期待已久的现货比特币交易所挂牌基金(ETF)推出后,比特币遭抛售,…...
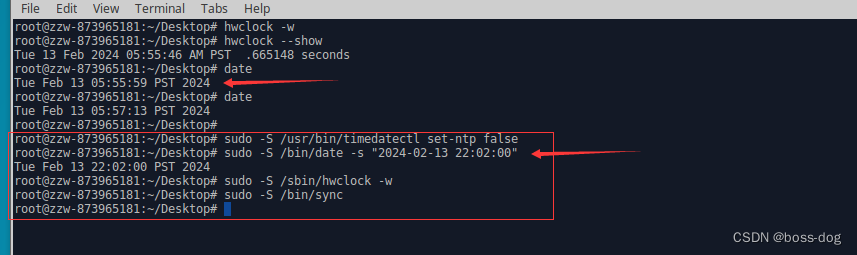
Xubuntu16.04系统中修改系统语言和系统时间
1.修改系统语言 问题:下图显示系统语言不对 查看系统中可用的所有区域设置的命令 locale -a修改/etc/default/locale文件 修改后如下: # File generated by update-locale LANG"en_US.UTF-8" LANGUAGE"en_US:en"LANG"en_US…...

内网穿透 | 推荐两个免费的内网穿透工具
目录 1、简介 2、Ngrok 2.1、下载安装 2.2、运行 2.3、固定域名 2.4、配置多服务 3、cpolar 3.1、下载安装 3.2、运行 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应…...

Android中代码生成图片高级部分
1、引言 上一篇文章已经介绍了使用bitmap对象生成图片,但android中不仅仅可以直接使用bitmap对象生成图片,也能借助bitmap对象将布局文件转化为图片,实际应用时,我们需要将两者结合起来,只有这样才能生成更加绚丽的图片…...

计算机网络——09Web-and-HTTP
Web and HTTP 一些术语 Web页:由一些对象组成对象可以是HTML文件、JPEG图像,JAVA小程序,声音剪辑文件等Web页含有一个基本的HTML文件,该基本HTML文件又包含若干对象的引用(链接)通过URL对每个对象进行引用…...

【教程】MySQL数据库学习笔记(一)——认识与环境搭建(持续更新)
写在前面: 如果文章对你有帮助,记得点赞关注加收藏一波,利于以后需要的时候复习,多谢支持! 【MySQL数据库学习】系列文章 第一章 《认识与环境搭建》 第二章 《数据类型》 文章目录 【MySQL数据库学习】系列文章一、认…...

软件测试-测试用例研究-如何编写一份优秀的测试用例
什么是测试用例 测试用例是一组由测试输入、执行条件、预期结果等要素组成,以完成对某个特定需求或者目标测试的数据,体现测试方案、方法、技术和策略的文档。测试用例是软件测试的核心,它把测试系统的操作步骤用文档的形式描述出来…...

计网day1
RTT:往返传播时延(越大,游戏延迟) 一.算机网络概念 网络:网样的东西,网状系统 计算机网络:是一个将分散得、具有独立功能的计算机系统,通过通信设备与线路连接起来,由功…...

vLLM vs Text Generation Interface:大型语言模型服务框架的比较
在大型语言模型(LLM)的世界中,有两个强大的框架用于部署和服务LLM:vLLM 和 Text Generation Interface (TGI)。这两个框架都有各自的优势,适用于不同的使用场景。在这篇博客中,我们将对这两个框架进行详细的…...

[AIGC] 上传文件:后端处理还是直接阿里云OSS?
在构建Web应用时,我们经常需要处理用户上传的文件。这可能是图片、视频、文档等各种各样的文件。但是,上传文件的方式有很多种,最常见的两种方式是:通过后端处理,或者直接上传至云存储服务,如阿里云OSS。那…...

速盾cdn:香港服务器如何用国内cdn
在国内使用香港服务器的情况下,可以考虑使用速盾CDN来提供加速服务。速盾CDN是一种专业的内容分发网络解决方案,可以通过使用不同节点的服务器来提供高速的内容传输和访问。 首先,使用速盾CDN可以帮助解决香港服务器与国内用户之间的延迟和带…...
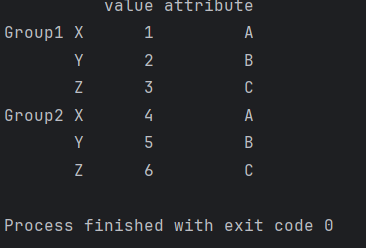
深入学习Pandas:数据连接、合并、加入、添加、重构函数的全面指南【第72篇—python:数据连接】
深入学习Pandas:数据连接、合并、加入、添加、重构函数的全面指南 Pandas是Python中最强大且广泛使用的数据处理库之一,提供了丰富的函数和工具,以便更轻松地处理和分析数据。在本文中,我们将深入探讨Pandas中一系列数据连接、合…...
)
为什么顶尖思想家团队只用Perplexity搜名言?——独家披露哈佛肯尼迪学院实测数据:准确率92.4%,响应延迟<1.7s(附配置白皮书)
更多请点击: https://kaifayun.com 第一章:为什么顶尖思想家团队只用Perplexity搜名言?——独家披露哈佛肯尼迪学院实测数据:准确率92.4%,响应延迟<1.7s(附配置白皮书) 在哈佛肯尼迪学院政…...

【限时解密】Perplexity未公开的历史资料检索协议v2.3:仅开放给前500名深度用户的私有搜索语法手册
更多请点击: https://codechina.net 第一章:Perplexity历史资料搜索的起源与协议演进脉络 Perplexity 作为面向知识密集型任务的下一代搜索代理,并非起源于传统搜索引擎架构,而是植根于大语言模型(LLM)推理…...

Agent工程2026:从提示词堆砌到生产级智能体的完整跃迁路径
如果你今天还在用"给LLM加几个工具调用"来描述你的Agent,那我们需要认真谈谈了。 2026年的AI工程现实是:绝大多数Agent项目死在了从Demo到生产的路上。不是因为模型不够强,而是因为工程没跟上。本文会系统梳理Agent工程化的核心路…...

番茄小说下载器:打造个人数字书库的终极解决方案
番茄小说下载器:打造个人数字书库的终极解决方案 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 在数字阅读时代,你是否曾因网络不稳定而中断阅读?是否想…...

OpenMMLab环境配置避坑指南:从CUDA 11.6到PyTorch 1.13,如何为MMRotate 0.3.4找到对的mmcv-full?
OpenMMLab精准环境配置实战:破解CUDA 11.6与PyTorch 1.13下的mmcv-full匹配困局 当你在RTX 3060显卡上尝试运行MMRotate 0.3.4时,突然发现控制台抛出ImportError: cannot import name get_dist_info from mmcv.runner——这往往是深度学习工程师与OpenMM…...

Kubernetes Operator开发实战
Kubernetes Operator开发实战 一、Operator概述 Kubernetes Operator是一种软件扩展模式,用于管理复杂的有状态应用。 1.1 Operator模式 ┌──────────────────────────────────────────────────────────…...
)
为什么顶级策展人不用Google搜文化新闻?Perplexity文化垂直搜索的5层语义增强架构(含可复用prompt工程模板)
更多请点击: https://kaifayun.com 第一章:为什么顶级策展人不用Google搜文化新闻? 顶级策展人并非排斥搜索引擎,而是早已构建起一套高度结构化、语义化、可验证的信息摄取系统——它绕过关键词匹配的偶然性,直击文化…...

程序员的写作技巧:如何写出受欢迎的技术博客
在软件测试行业快速发展的今天,技术博客不仅是知识沉淀的载体,更是测试从业者提升个人影响力、拓展职业边界的重要途径。一篇受欢迎的技术博客,能让你的经验被更多人看见,甚至成为行业内的标杆。那么,软件测试从业者该…...

i.MX6ULL LCD驱动适配实战:从设备树到时序调试全解析
1. 项目概述与核心价值最近在搞一个基于i.MX6ULL的工控HMI项目,屏幕显示是绕不开的一环。市面上很多教程要么只讲Framebuffer应用,要么直接给个现成的设备树文件让你照着改,至于里面的参数怎么来的、屏幕初始化序列怎么配,往往一笔…...
如何用Pixelle-Video实现零门槛AI短视频创作:新手完全指南
如何用Pixelle-Video实现零门槛AI短视频创作:新手完全指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 你是否曾经想制作…...